
Fast Temporal Graph Convolutional Model for Skeleton-Based Action Recognition



Abstract
:1. Introduction
- 1.
- We propose an efficient pipeline for solving the problem of human action recognition using skeletal data. This pipeline consists of two important modules: a data processing module and a module that contains a neural model that classifies human actions.
- 2.
- We design a small neural model, based on various types of convolutional layers, that achieves good accuracy and a high inference speed.
- 3.
- We perform an extensive analysis of the results achieved by the proposed neural model to validate its robustness. The purpose of these experiments and analyses is to show the potential of the proposed method in comparison with the existing solutions.
2. Related Work
3. Proposed Method
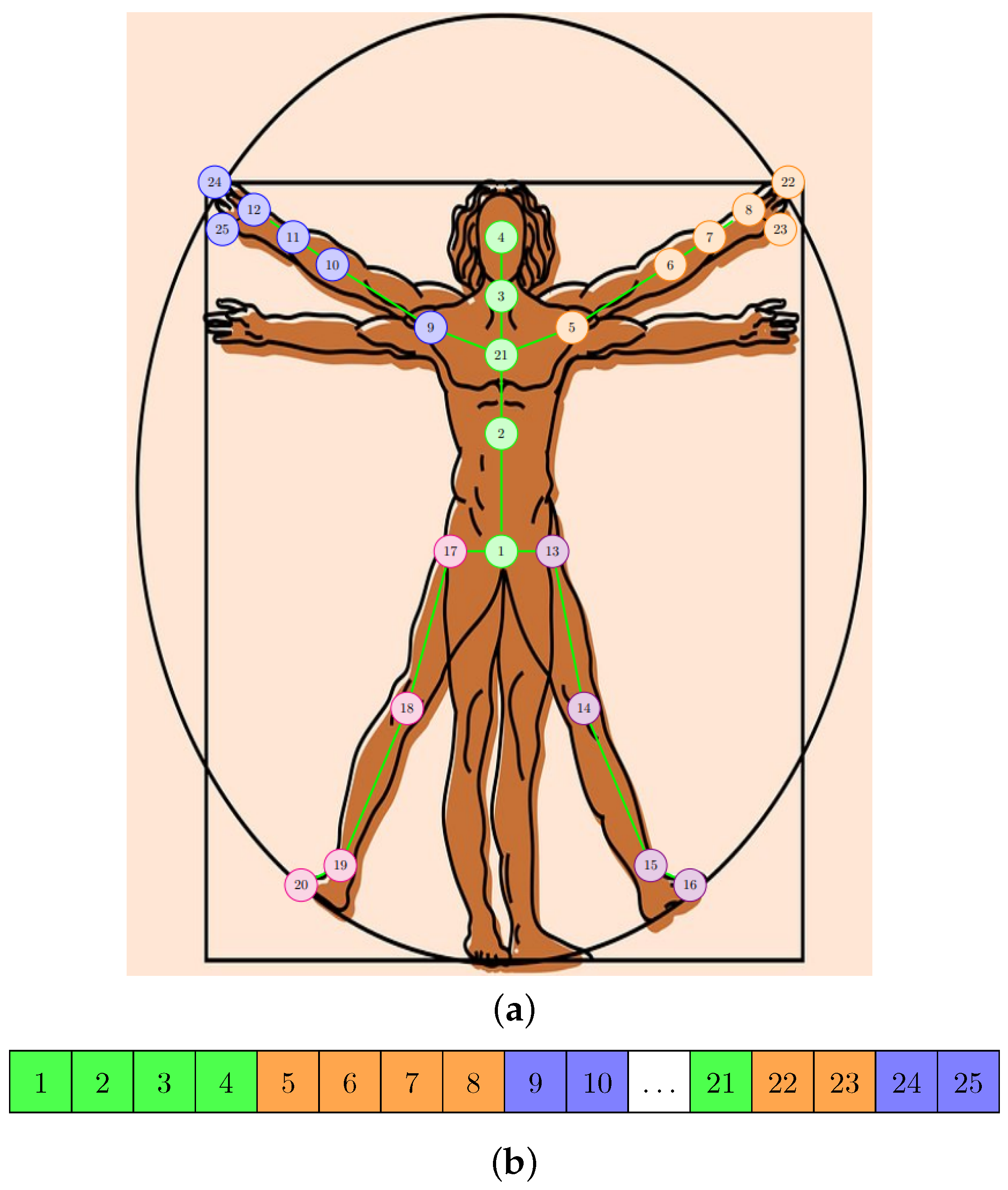
3.1. Data Preprocessing
3.2. Data Augmentation
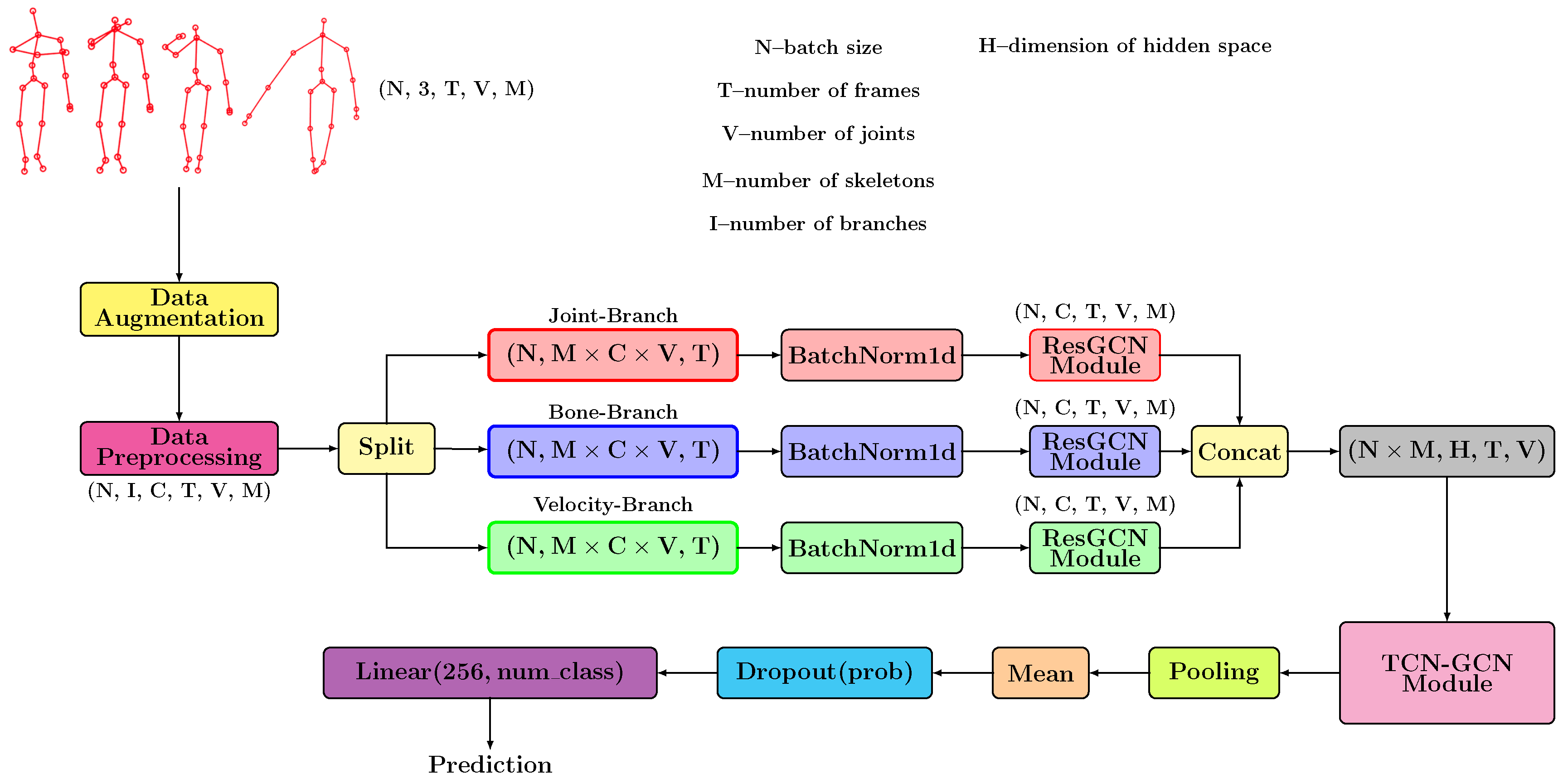
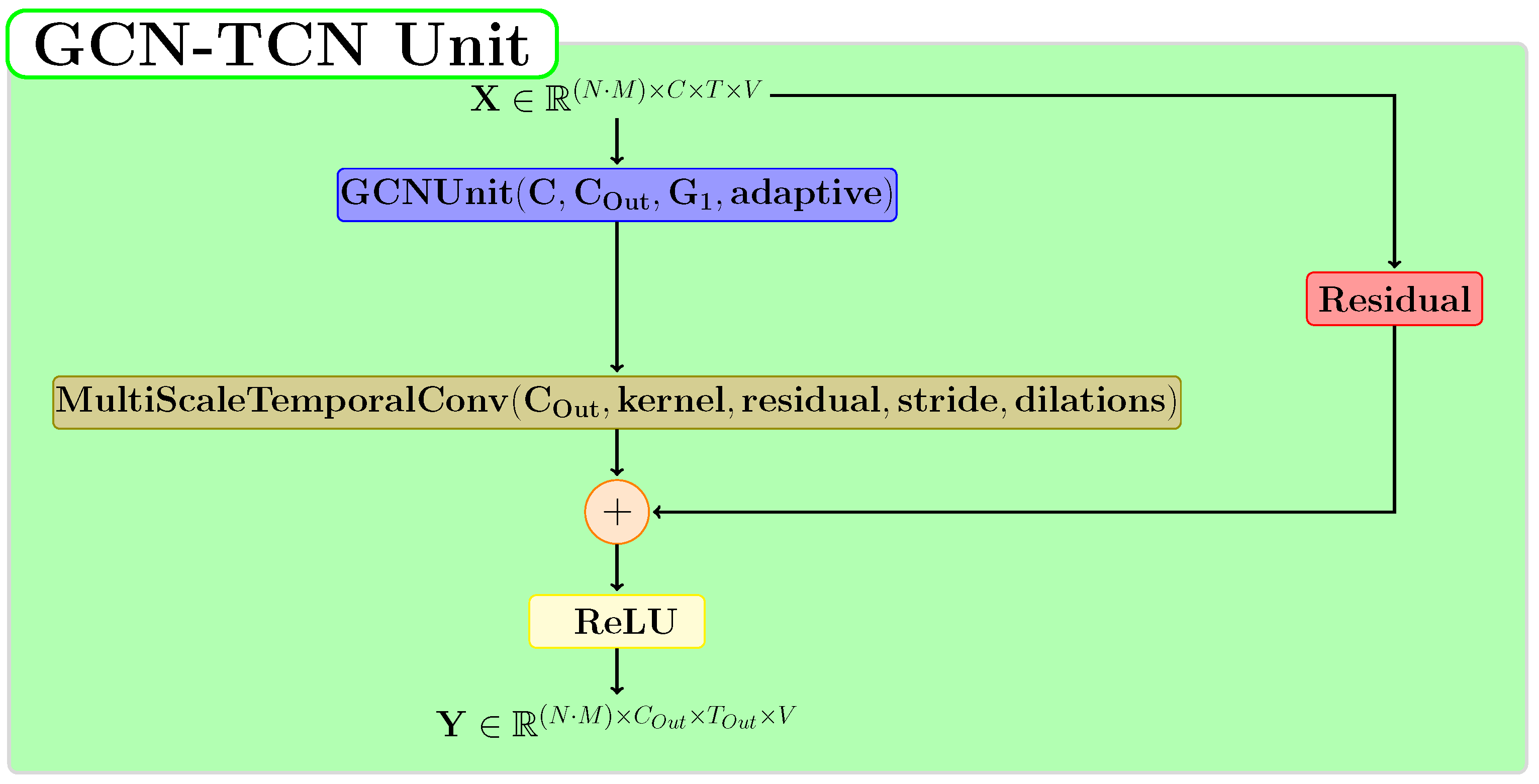
3.3. Temporal Graph Convolutional Model
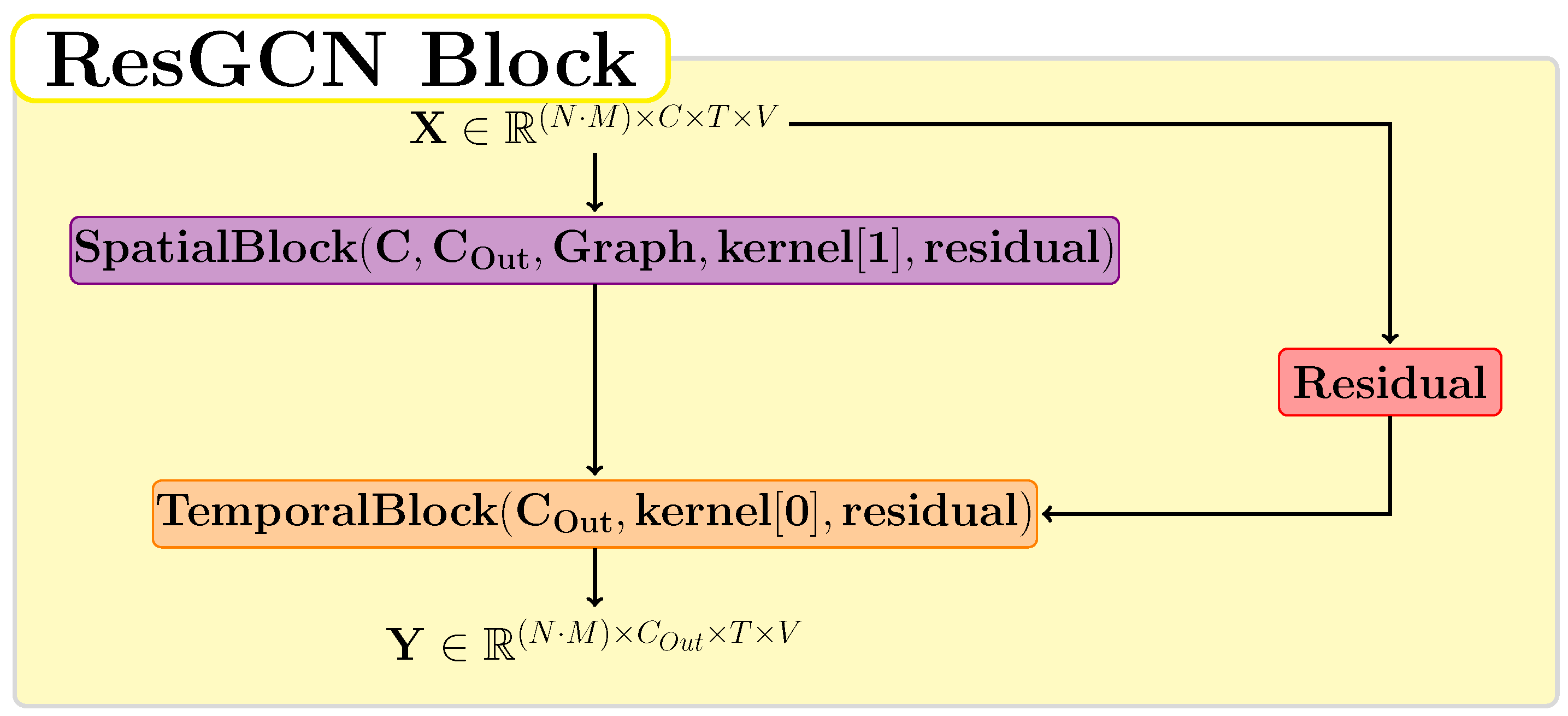
3.4. ResGCN Module
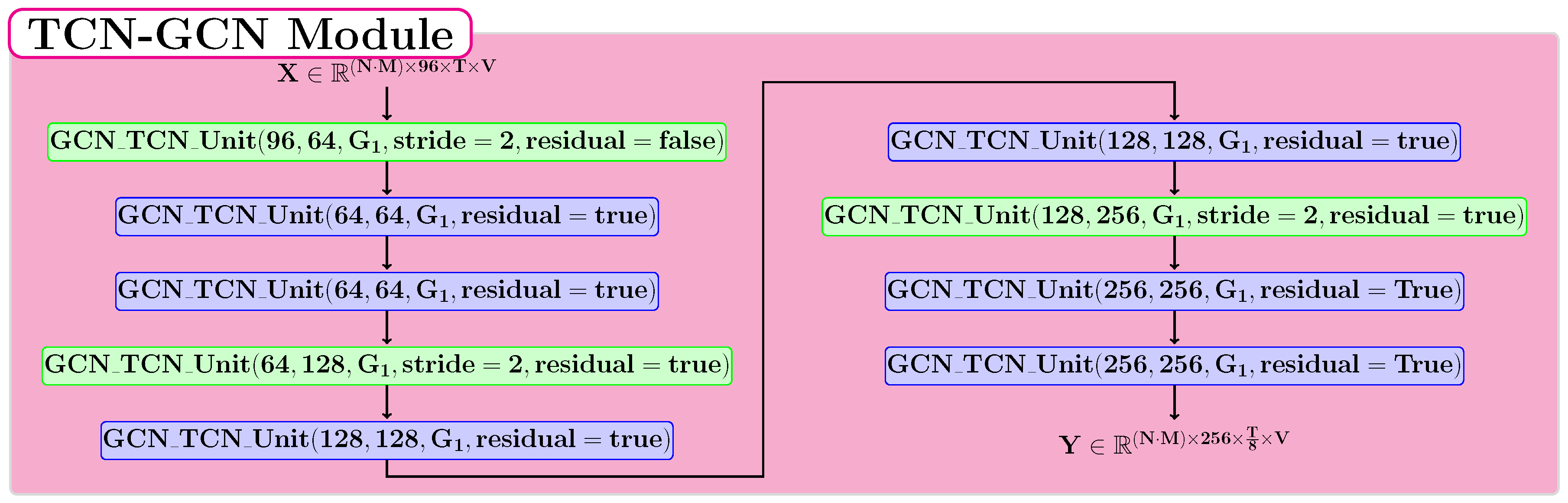
3.5. TCN-GCN Module
4. Results
4.1. NTU RGB+D Dataset
4.2. Implementation Details
4.3. Ablation Study
4.4. Experimental Results
- Top 1—checking only the action for which the neural model predicted the highest value.
- Top 5—checking if any of the first five actions predicted by the network represent the correct action.
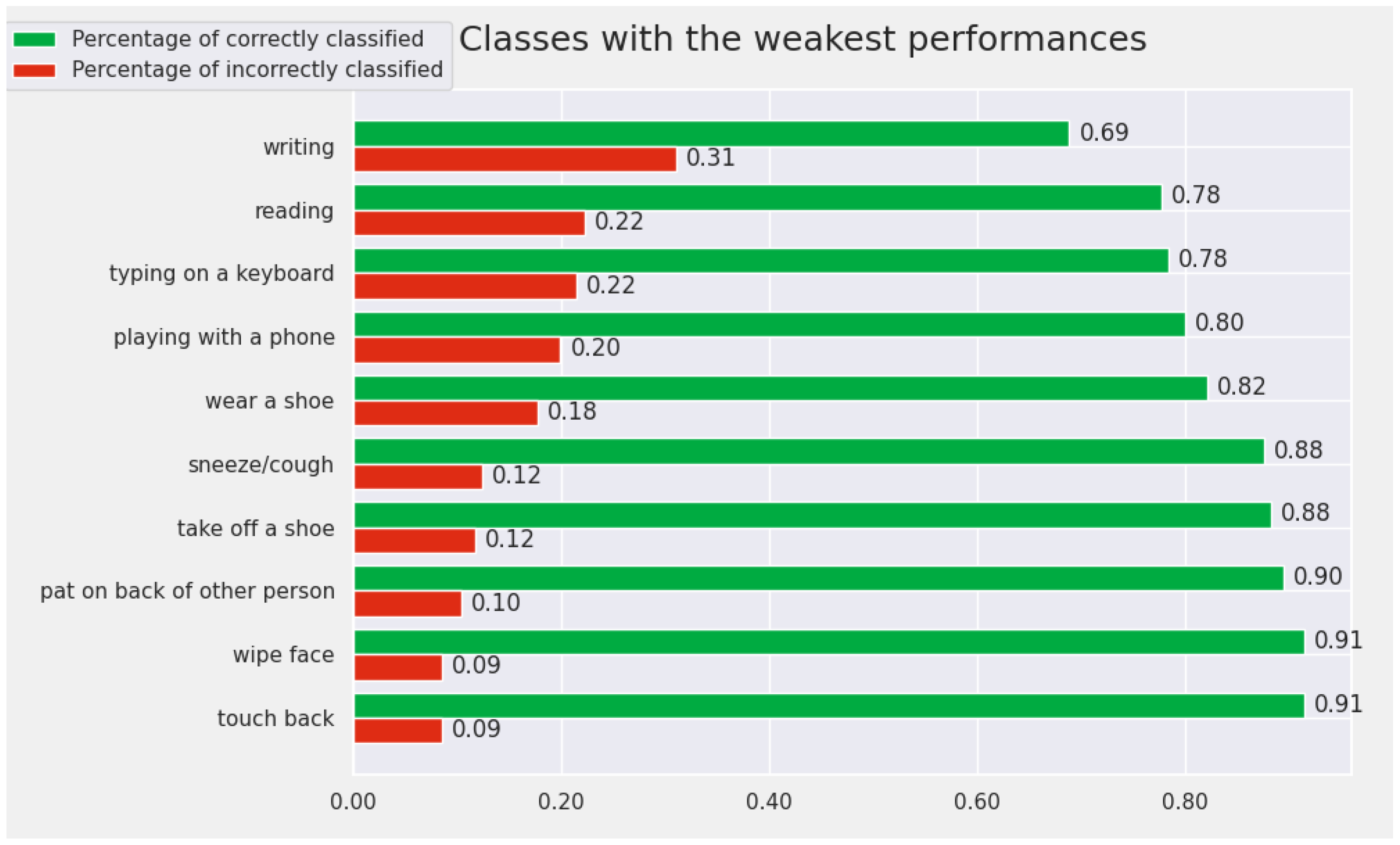
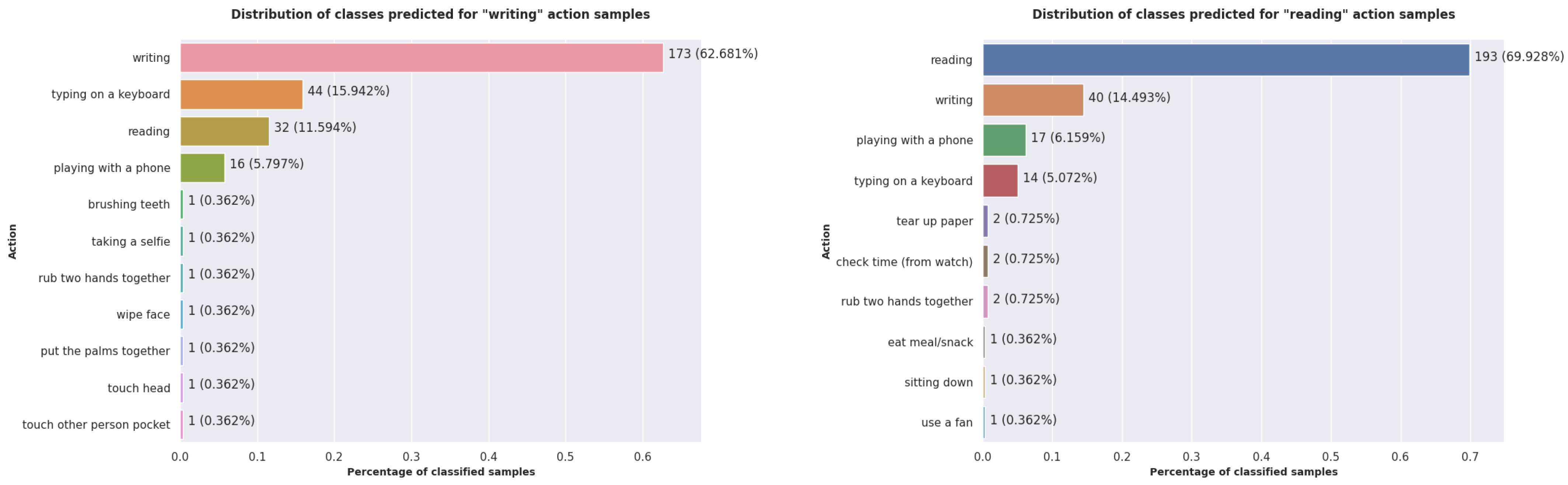
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TCN | Temporal Convolutional Network |
| GCN | Graph Convolutional Network |
| HAR | Human Action Recognition |
| AmI | Ambient Intelligent |
| RNN | Recurrent Neural Network |
| CTR-GC | Channel-wise Topology-Refinement Graph Convolution |
| ResGCN | Residual Graph Convolutional Network |
| SGD | Stochastic Gradient Descent |
| GPU | Graphics Processing Unit |
References
- Hemeren, P.; Rybarczyk, Y. The Visual Perception of Biological Motion in Adults. In Modelling Human Motion; Springer: Berlin/Heidelberg, Germany, 2020; pp. 53–71. [Google Scholar]
- Srinivasan, R.; Golomb, J.D.; Martinez, A.M. A neural basis of facial action recognition in humans. J. Neurosci. 2016, 36, 4434–4442. [Google Scholar] [CrossRef] [PubMed]
- Ziaeefard, M.; Bergevin, R. Semantic human activity recognition: A literature review. Pattern Recognit. 2015, 48, 2329–2345. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Wei, F.; Wang, K.; Zhao, M.; Jiang, Y. Skeleton-based Action Recognition via Temporal-Channel Aggregation. arXiv 2022, arXiv:2205.15936. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13359–13368. [Google Scholar]
- Xie, J.; Xin, W.; Liu, R.; Sheng, L.; Liu, X.; Gao, X.; Zhong, S.; Tang, L.; Miao, Q. Cross-channel graph convolutional networks for skeleton-based action recognition. IEEE Access 2021, 9, 9055–9065. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. arXiv 2016, arXiv:1604.02808. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.L.; Wang, G.; Duan, L.Y.; Chichung, A.K. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. arXiv 2019, arXiv:1905.04757. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, Faster and More Explainable: A Graph Convolutional Baseline for Skeleton-Based Action Recognition. In Proceedings of the 28th ACM International Conference on Multimedia (ACMMM), Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1625–1633. [Google Scholar] [CrossRef]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Constructing Stronger and Faster Baselines for Skeleton-based Action Recognition. arXiv 2021, arXiv:2106.15125. [Google Scholar] [CrossRef] [PubMed]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3595–3603. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, J.; Ye, G.; Tu, Z.; Qin, Y.; Qin, Q.; Zhang, J.; Liu, J. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 2022, 7, 46–55. [Google Scholar] [CrossRef]
- Zang, Y.; Yang, D.; Liu, T.; Li, H.; Zhao, S.; Liu, Q. SparseShift-GCN: High precision skeleton-based action recognition. Pattern Recognit. Lett. 2022, 153, 136–143. [Google Scholar] [CrossRef]
- Lee, J.; Lee, M.; Lee, D.; Lee, S. Hierarchically Decomposed Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2022, arXiv:2208.10741. [Google Scholar]
- Trivedi, N.; Sarvadevabhatla, R.K. PSUMNet: Unified Modality Part Streams are All You Need for Efficient Pose-based Action Recognition. arXiv 2022, arXiv:2208.05775. [Google Scholar]
- Nan, M.; Trăscău, M.; Florea, A.M.; Iacob, C.C. Comparison between recurrent networks and temporal convolutional networks approaches for skeleton-based action recognition. Sensors 2021, 21, 2051. [Google Scholar] [CrossRef] [PubMed]
- Si, C.; Jing, Y.; Wang, W.; Wang, L.; Tan, T. Skeleton-based action recognition with spatial reasoning and temporal stack learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–118. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Wang, L. Richly activated graph convolutional network for action recognition with incomplete skeletons. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Gao, X.; Hu, W.; Tang, J.; Liu, J.; Guo, Z. Optimized skeleton-based action recognition via sparsified graph regression. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 601–610. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nice, France, 21–25 October 2019; pp. 1227–1236. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7912–7921. [Google Scholar]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1112–1121. [Google Scholar]
- Huang, L.; Huang, Y.; Ouyang, W.; Wang, L. Part-Level Graph Convolutional Network for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11045–11052. [Google Scholar]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning Graph Convolutional Network for Skeleton-Based Human Action Recognition by Neural Searching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2669–2676. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Decoupled Spatial-Temporal Attention Network for Skeleton-Based Action Recognition. arXiv 2020, arXiv:2007.03263. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Top 1 | Top 5 | |
|---|---|---|---|
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 0.3 | 89.37 | 98.25 |
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 0.5 | 88.55 | 98.18 |
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 0.78 | 88.34 | 98.10 |
| Uniform Sample | Random Move | Random Rotation | Dropout | Cross-Subject Accuracy (%) | Speed |
|---|---|---|---|---|---|
| 200 | ✓ | ✗ | |||
| 200 | ✓ | ✓ | |||
| 200 | ✓ | ✓ | ✗ | ||
| 100 | ✓ | ✓ | |||
| 64 | ✓ | ✓ | |||
| ✗ | ✗ | ✗ |
| ResGCN | TCN | Cross-Subject Accuracy (%) | Speed | ||
|---|---|---|---|---|---|
| Temporal | Spatial | Temporal | Spatial | ||
| 9 | 2 | 9 | 1 | 88.95 | 240.06 |
| 9 | 2 | 11 | 1 | 89.36 | 235.37 |
| 11 | 3 | 5 | 1 | 89.43 | 228.33 |
| 9 | 3 | 5 | 1 | 89.22 | 230.38 |
| 9 | 2 | 5 | 3 | 89.27 | 240.29 |
| Method Name | Model Size (M) | Cross-Subject (NTU v1—60) Accuracy (%) | Cross-View (NTU v1—60) Accuracy (%) |
|---|---|---|---|
| ST-GCN [13] | 3.1 | 81.5 | 88.3 |
| SR-TSL [19] | 19.07 | 84.8 | 92.4 |
| RA-GCN [20] | 6.21 | 85.9 | 93.5 |
| GR-GCN [21] | – | 87.5 | 94.3 |
| AS-GCN [12] | 6.99 | 86.8 | 94.2 |
| 2s-AGCN [11] | 6.94 | 88.5 | 95.1 |
| AGC-LSTM [22] | 22.89 | 89.2 | 95.0 |
| DGNN [23] | 26.24 | 89.9 | 96.1 |
| SGN [24] | 1.8 | 89.0 | 94.5 |
| PL-GCN [25] | 20.7 | 89.2 | 95.0 |
| NAS-GCN [26] | 6.57 | 89.4 | 95.7 |
| ResGCN-N51 (Bottleneck) [9] | 0.77 | 89.1 | 93.5 |
| ResGCN-B19 (Basic) [9] | 3.26 | 90.0 | 94.8 |
| DSTA-Net [27] | – | 91.5 | 96.4 |
| PA-ResGCN-N51 [9] | 1.14 | 90.3 | 95.6 |
| MS-G3D Net [28] | 3.2 | 91.5 | 96.2 |
| PA-ResGCN-B19 [9] | 3.64 | 90.9 | 96.0 |
| CTR-GCN [5] | 1.46 | 92.4 | 96.8 |
| ResGCN-TCN [18] | 5.13 | 88.68 | 94.04 |
| ResGCN-LSTM [18] | 2.15 | 85.01 | 92.3 |
| Fast Convolutional (ours) | 1.58 | 89.37 | 94.86 |
| Method Name | Type | Cross-Subject (NTU RGB+D [7]) Accuracy (%) | Cross-View (NTU RGB+D [7]) Accuracy (%) |
|---|---|---|---|
| Fast Convolutional (ours) | Top 1 | 89.37 | 94.86 |
| Fast Convolutional (ours) | Top 5 | 98.17 | 99.39 |
| Method Name | Type | Cross-Subject 120 (NTU RGB+D [8]) Accuracy (%) | Cross-Setup (NTU RGB+D [8]) Accuracy (%) |
|---|---|---|---|
| Fast Convolutional (ours) | Top 1 | 85.82 | 87.14 |
| Fast Convolutional (ours) | Top 5 | 97.41 | 97.24 |
| Method Name | Model Size (M) | Cross-Subject (NTU v2—120) Accuracy (%) | Cross-Setups (NTU v2—120) Accuracy (%) |
|---|---|---|---|
| ST-GCN [13] | 3.1 | 70.7 | 73.2 |
| RA-GCN [20] | 6.21 | 74.6 | 75.3 |
| AS-GCN [12] | 6.99 | 77.9 | 78.5 |
| 2s-AGCN [11] | 6.94 | 82.5 | 84.2 |
| SGN [24] | 1.8 | 79.2 | 81.5 |
| ResGCN-N51 (Bottleneck) [9] | 0.77 | 84.0 | 84.2 |
| ResGCN-B19 (Basic) [9] | 3.26 | 85.2 | 85.7 |
| DSTA-Net [27] | – | 86.6 | 89 |
| PA-ResGCN-N51 [9] | 1.14 | 86.6 | 87.1 |
| MS-G3D Net [28] | 3.2 | 86.9 | 88.4 |
| PA-ResGCN-B19 [9] | 3.64 | 87.3 | 88.3 |
| CTR-GCN [5] | 1.46 | 88.9 | 90.6 |
| ResGCN-TCN [18] | 5.13 | 84.4 | 84.6 |
| ResGCN-LSTM [18] | 2.15 | 79.93 | 81.28 |
| Fast Convolutional (ours) | 1.58 | 85.82 | 87.14 |
| Method | Total Number of Epochs | Top 1 | Top 5 | Best Epoch |
|---|---|---|---|---|
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 100 | 89.37 | 98.25 | 97 |
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 70 | 89.37 | 98.17 | 66 |
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 50 | 89.05 | 98.20 | 49 |
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 30 | 87.65 | 98.09 | 29 |
| Fast Convolutional (200 frames, dropout = 0.3, theta = 0.3) | 10 | 82.73 | 97.13 | 10 |
| Sample | No. of Responses Reading | No. of Responses Writing | Percentage | Model Prediction |
|---|---|---|---|---|
| Reading 1 | 3 | 17 | Reading () | |
| Reading 2 | 13 | 7 | Reading () | |
| Reading 3 | 20 | 0 | Reading () | |
| Reading 4 | 15 | 5 | Eat meal () | |
| Reading 5 | 7 | 13 | Reading () | |
| Writing 1 | 10 | 10 | Writing () | |
| Writing 2 | 6 | 14 | Type on keyboard () | |
| Writing 3 | 12 | 8 | Writing () | |
| Writing 4 | 3 | 17 | Writing () | |
| Writing 5 | 7 | 13 | Writing () |
| Method | Speed | Cross-Subject (NTU RGB+D v1) Accuracy (%) | Model Size |
|---|---|---|---|
| Fast Convolutional (ours) | 233.23 | 89.37 | 1.58 |
| PA-ResGCN-N51 | 180.80 | 90.3 | 1.14 |
| CTR-GCN | 115.64 | 92.4 | 1.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nan, M.; Florea, A.M. Fast Temporal Graph Convolutional Model for Skeleton-Based Action Recognition. Sensors 2022, 22, 7117. https://doi.org/10.3390/s22197117
Nan M, Florea AM. Fast Temporal Graph Convolutional Model for Skeleton-Based Action Recognition. Sensors. 2022; 22(19):7117. https://doi.org/10.3390/s22197117
Chicago/Turabian StyleNan, Mihai, and Adina Magda Florea. 2022. "Fast Temporal Graph Convolutional Model for Skeleton-Based Action Recognition" Sensors 22, no. 19: 7117. https://doi.org/10.3390/s22197117
APA StyleNan, M., & Florea, A. M. (2022). Fast Temporal Graph Convolutional Model for Skeleton-Based Action Recognition. Sensors, 22(19), 7117. https://doi.org/10.3390/s22197117