

Deep Neural Network for 3D Shape Classification Based on Mesh Feature

Abstract
:1. Introduction
2. Related Works
3. Methods
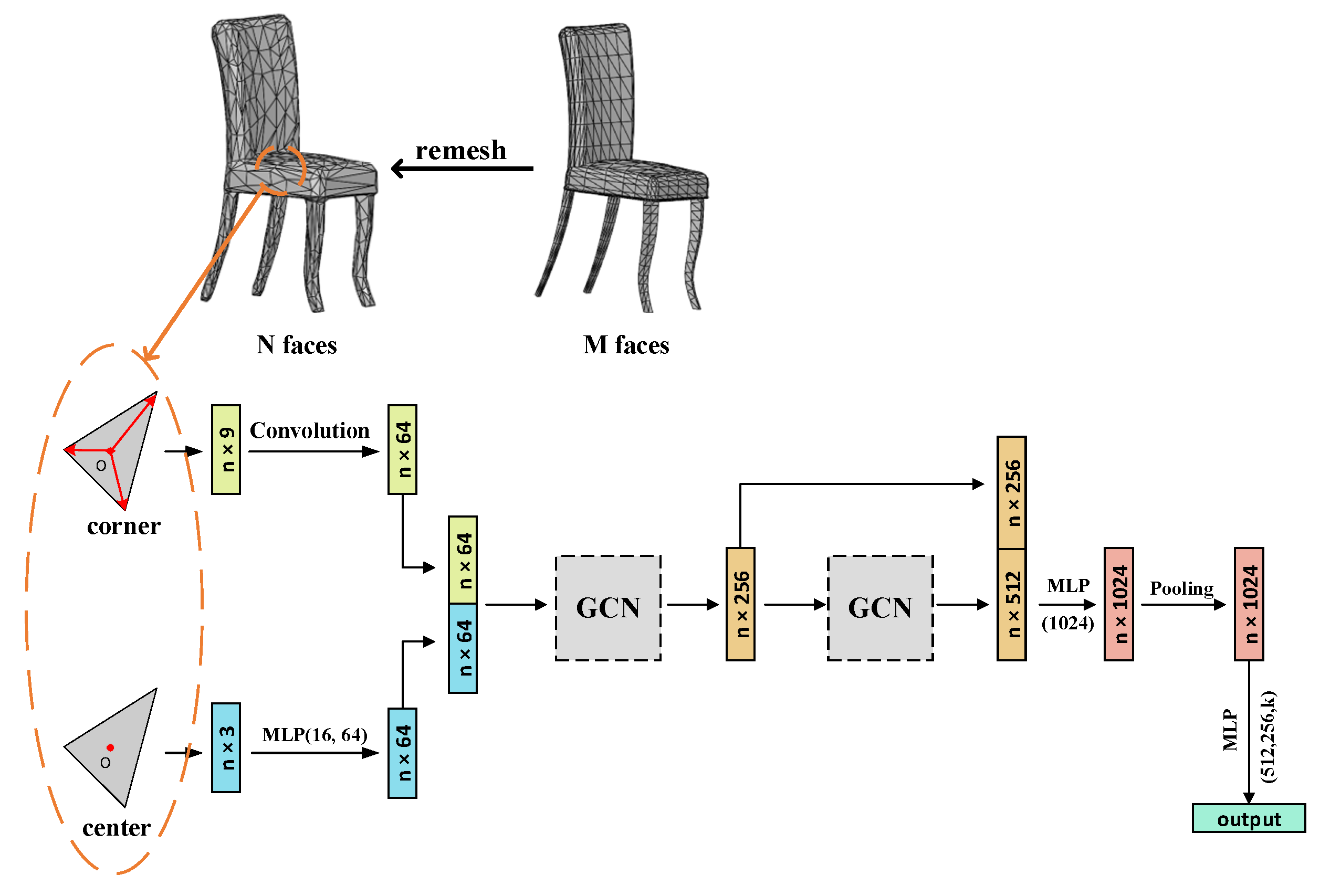
3.1. Overview
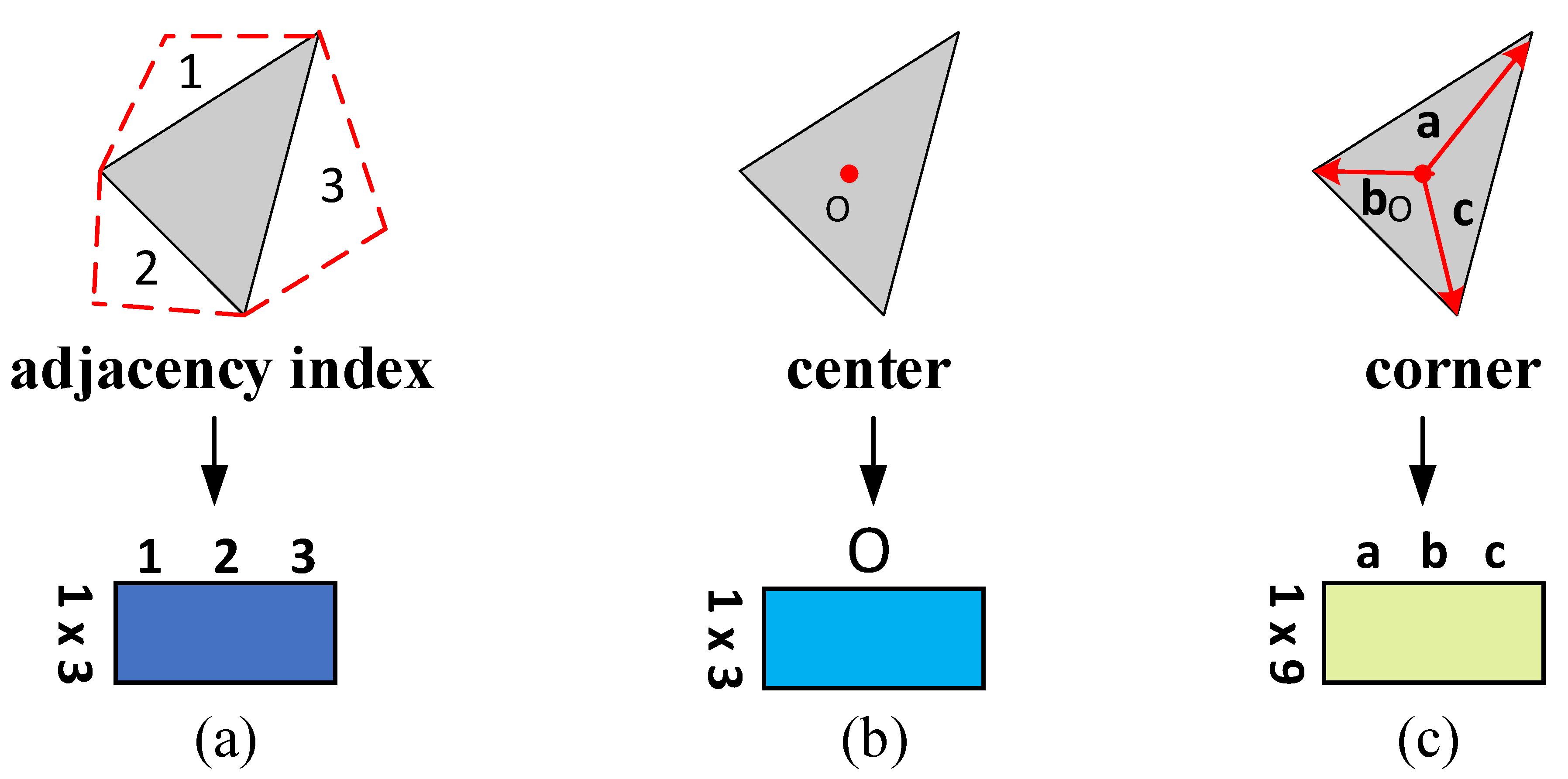
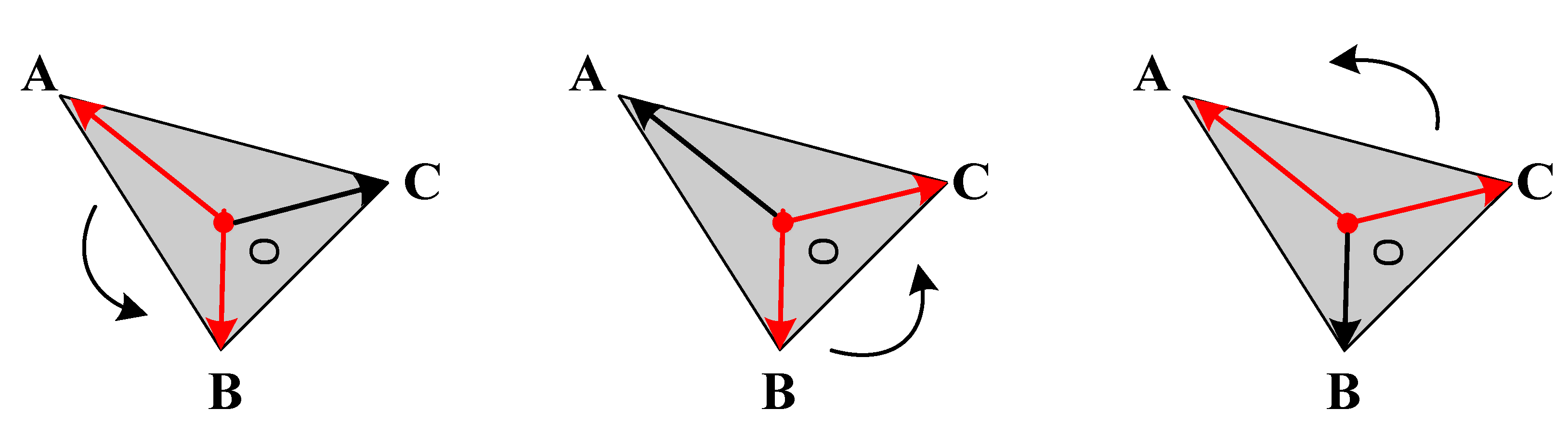
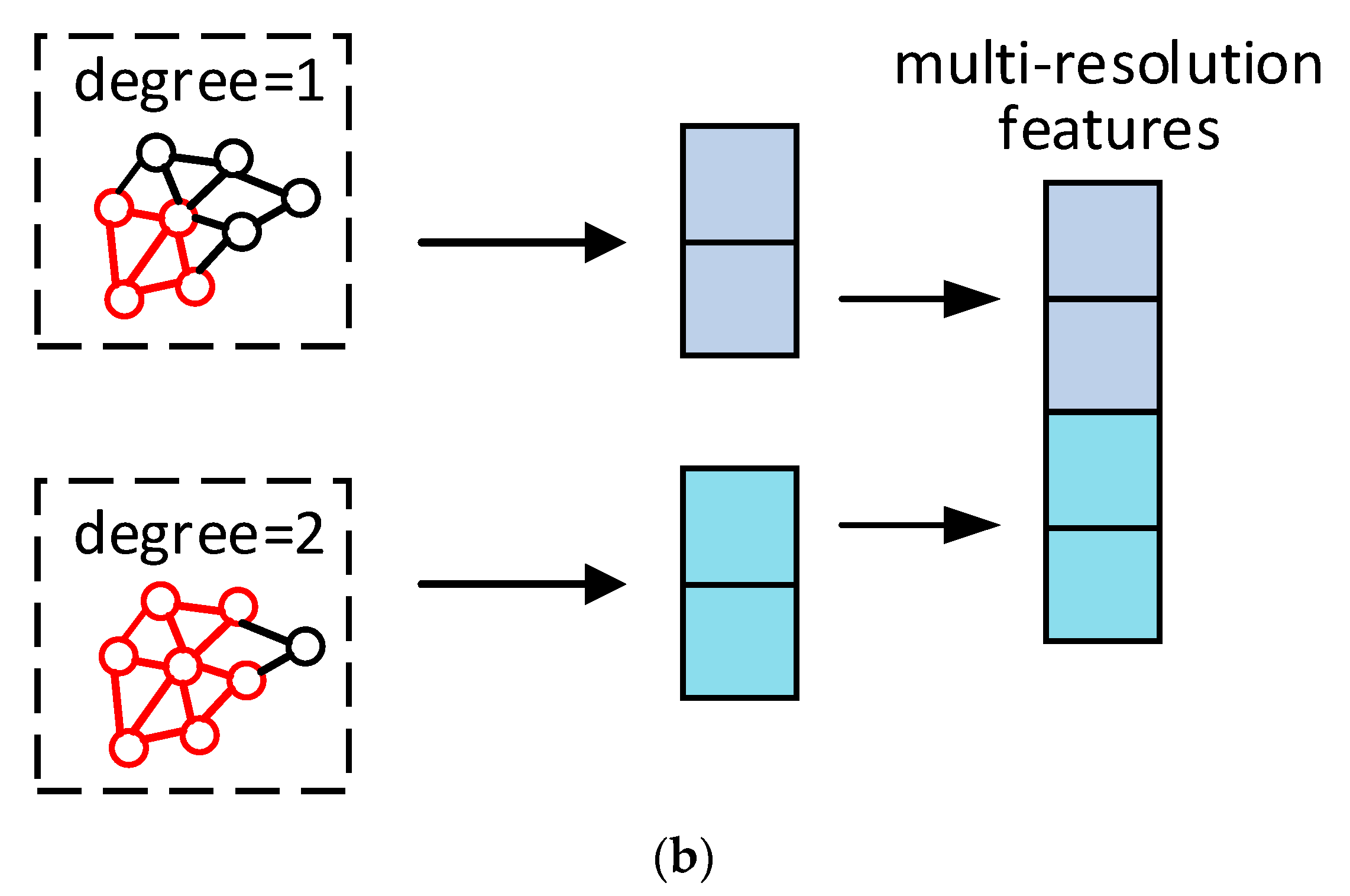
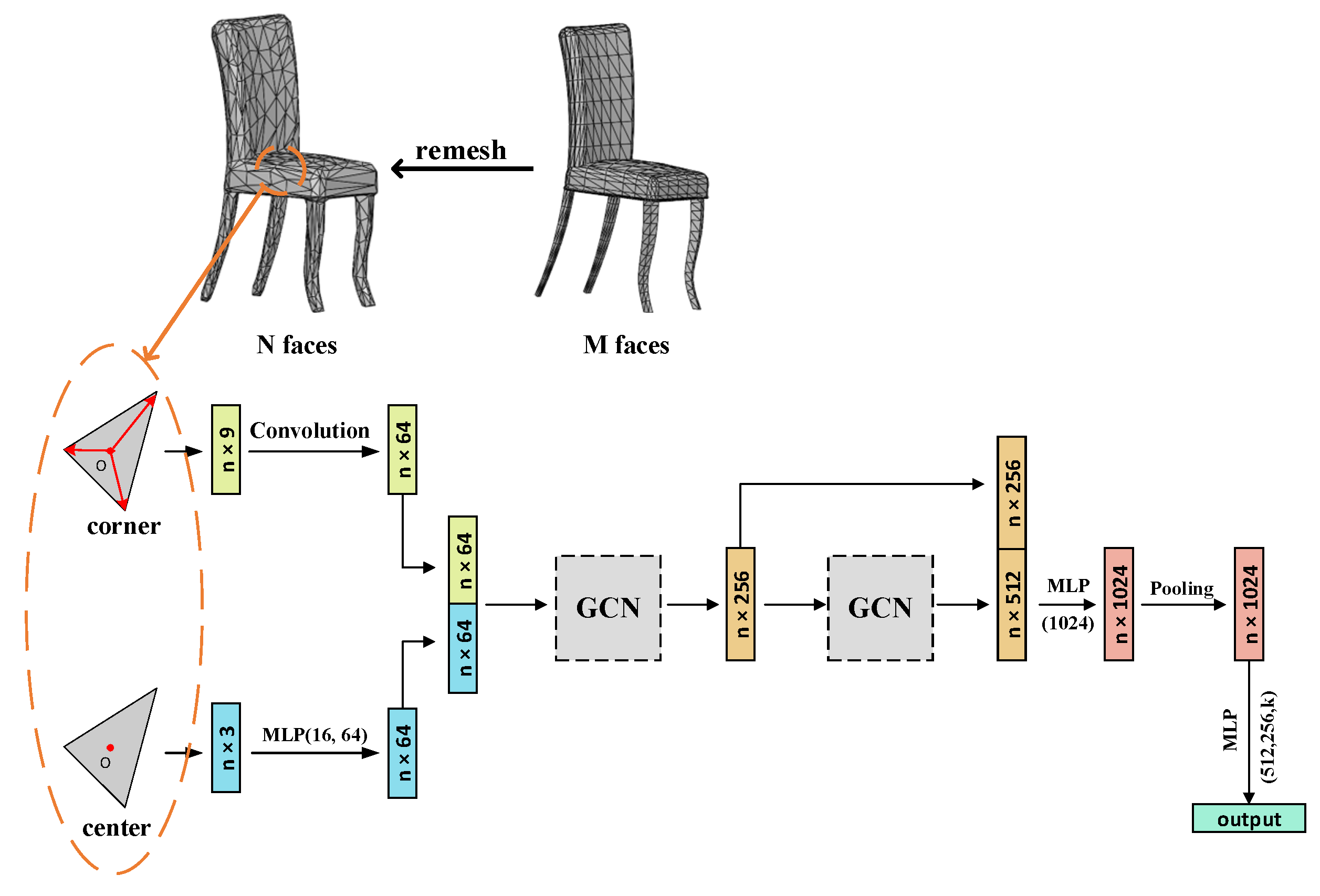
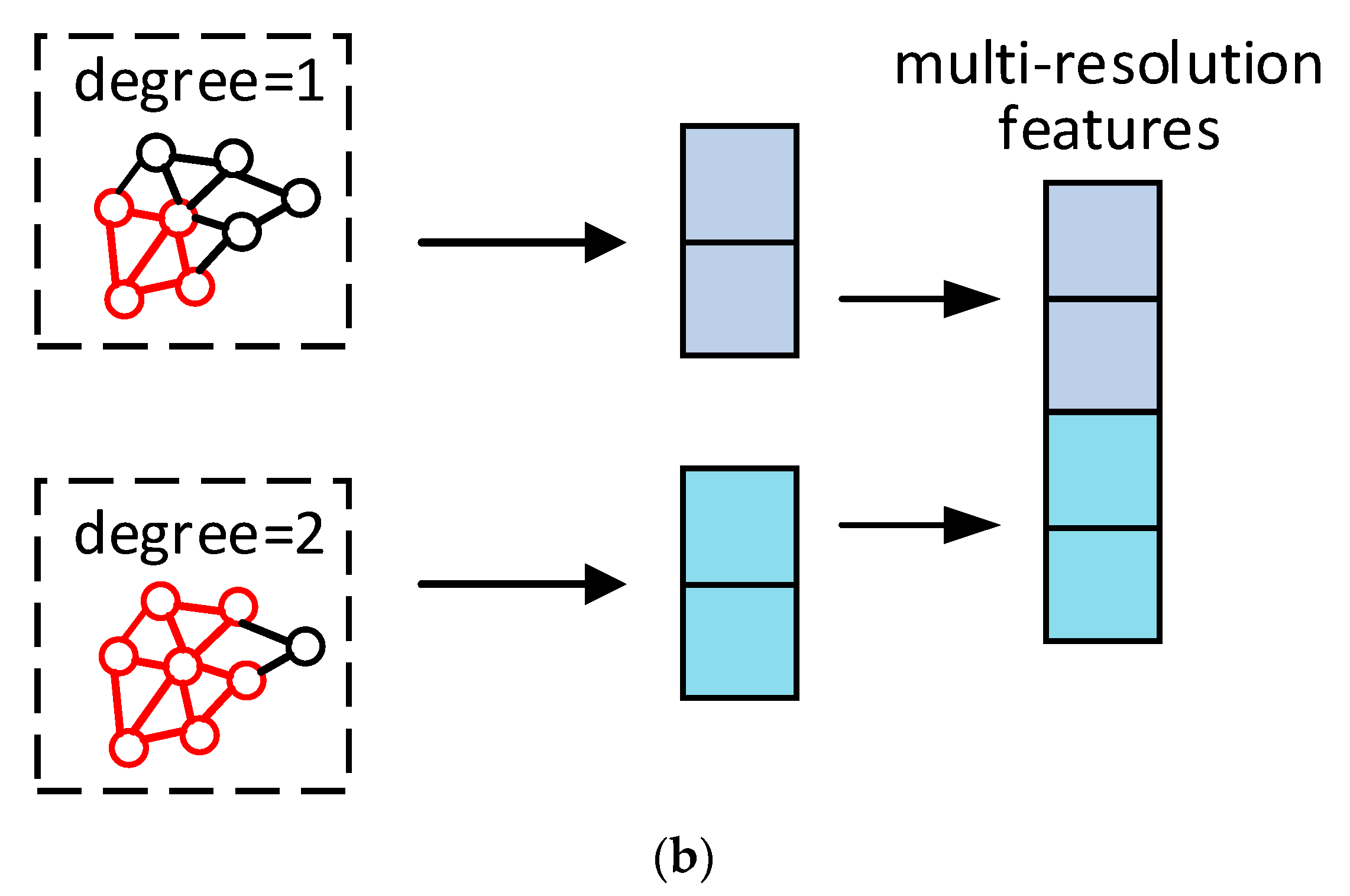
3.2. Processing Mesh
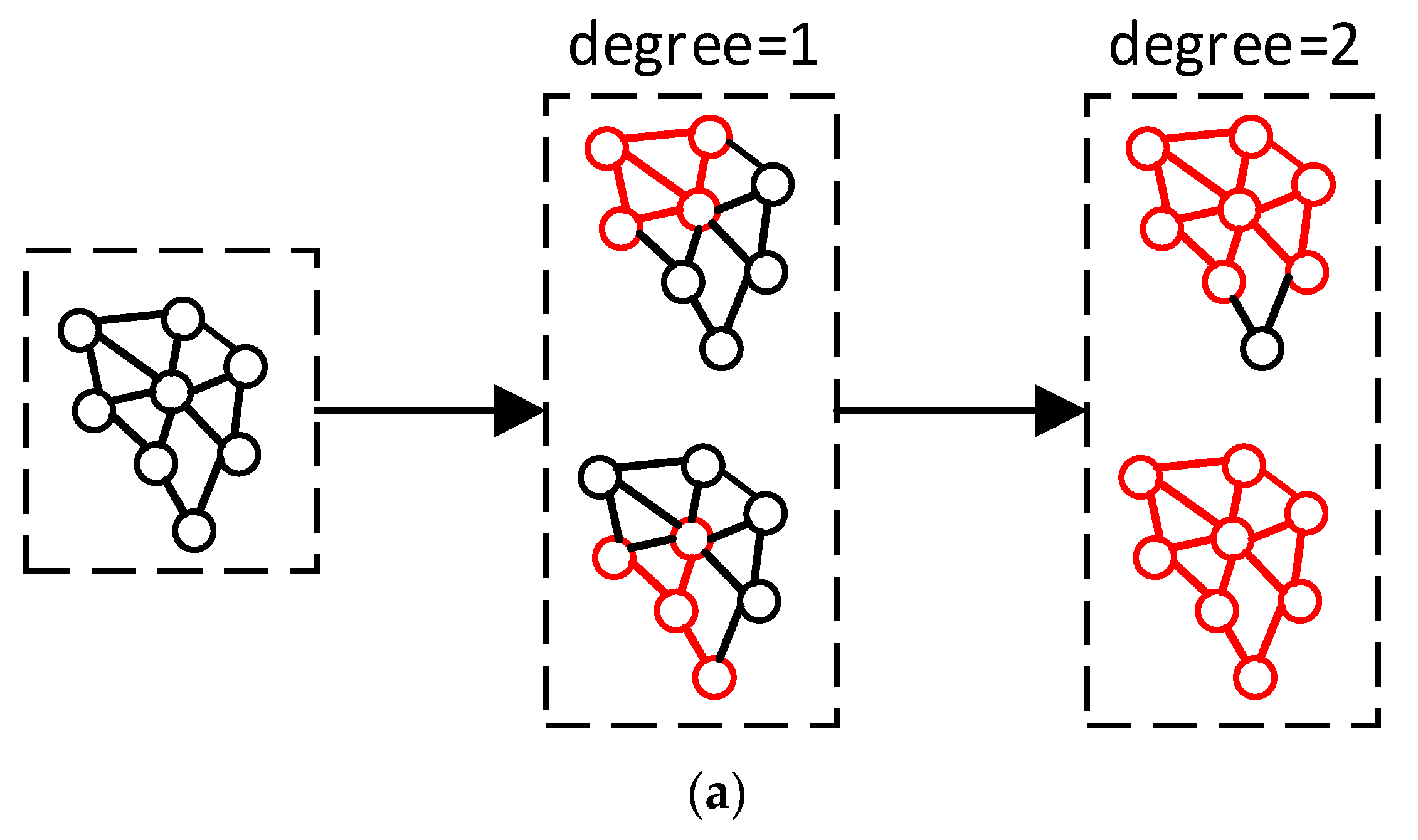
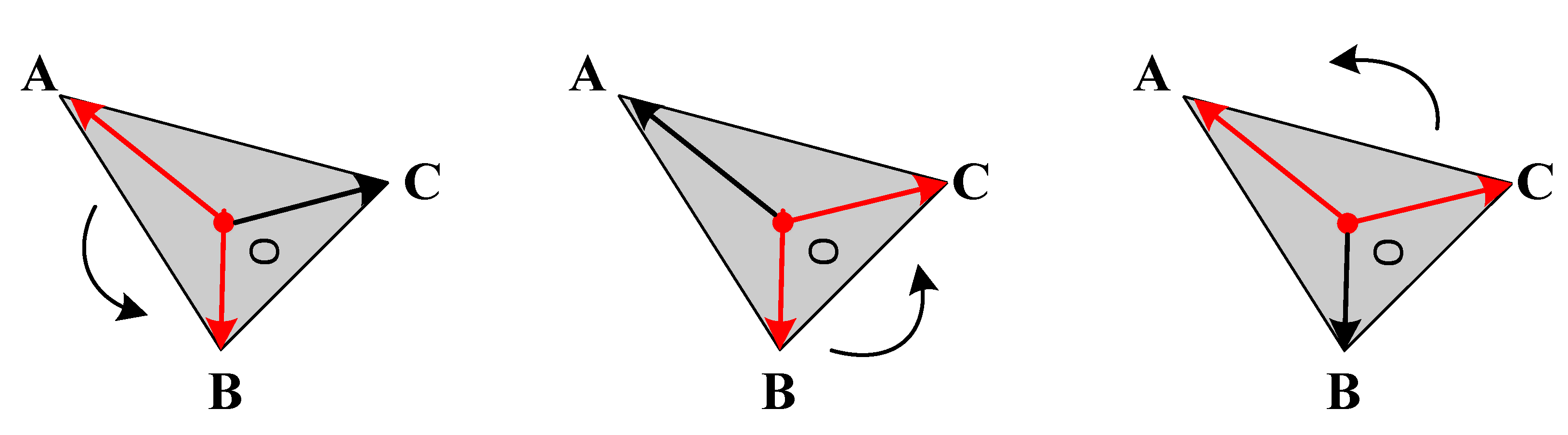
3.3. Model Design
4. Experiments and Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Representation | Overall Accuracy (%) | Mean Class Accuracy (%) |
|---|---|---|---|
| MVCNN [7] | view | 90.1 | 79.5 |
| VoxNet [21] | volume | 83.0 | 85.9 |
| PointNet [24] | point | 89.2 | 86.2 |
| PointNet++ [25] | point | 90.7 | - |
| Kd-Net [22] | point | 90.6 | 88.5 |
| SO-Net [36] | point | 90.8 | - |
| Momenet [37] | point | 89.3 | 86.1 |
| LKPO-GNN [38] | point | 90.9 | 88.2 |
| ReebGCN [39] | point | 89.9 | 87.1 |
| Ours | mesh | 91.0 | 89.1 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ulrich, L.; Nonis, F.; Vezzetti, E.; Moos, S.; Caruso, G.; Shi, Y.; Marcolin, F. Can ADAS Distract Driver’s Attention? An RGB-D Camera and Deep Learning-Based Analysis. Appl. Sci. 2021, 11, 11587. [Google Scholar] [CrossRef]
- Sasaki, S.; Premachandra, C. Head Posture Estimation by Deep Learning Using 3-D Point Cloud Data from a Depth Sensor. IEEE Sens. Lett. 2021, 5, 7002604. [Google Scholar] [CrossRef]
- Zheng, G.; Song, Y.; Chen, C. Height Measurement with Meter Wave Polarimetric MIMO Radar: Signal Model and MUSIC-like Algorithm. Signal Process. 2022, 190, 108344. [Google Scholar] [CrossRef]
- Hooda, R.; Pan, W.D.; Syed, T.M. A Survey on 3D Point Cloud Compression Using Machine Learning Approaches. In Proceedings of the SoutheastCon 2022, Mobile, AL, USA, 26 March 2022; pp. 522–529. [Google Scholar]
- Guo, W.; Hu, W.; Liu, C.; Lu, T. 3D Object Recognition from Cluttered and Occluded Scenes with a Compact Local Feature. Mach. Vis. Appl. 2019, 30, 763–783. [Google Scholar] [CrossRef]
- Wang, F.; Liang, C.; Ru, C.; Cheng, H. An Improved Point Cloud Descriptor for Vision Based Robotic Grasping System. Sensors 2019, 19, 2225. [Google Scholar] [CrossRef] [PubMed]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans Graph 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:abs/1609.02907. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Jiao, X.; Bayyana, N.R. Identification of C1 and C2 Discontinuities for Surface Meshes in CAD. Comput Aided Des 2008, 40, 160–175. [Google Scholar] [CrossRef]
- Kim, V.G.; Lipman, Y.; Funkhouser, T. Blended Intrinsic Maps. ACM Trans. Comput. Syst. 2011, 30, 1–12. [Google Scholar] [CrossRef]
- Kim, V.G.; Lipman, Y.; Chen, X.; Funkhouser, T. Möbius Transformations for Global Intrinsic Symmetry Analysis. Comput. Graph. Forum 2010, 29, 1689–1700. [Google Scholar] [CrossRef]
- Wu, J.; Shen, X.; Zhu, W.; Liu, L. Mesh Saliency with Global Rarity. Graph. Models 2013, 75, 255–264. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-View CNNs for Object Classification on 3D Data. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Zhang, L.; Sun, J.; Zheng, Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors 2018, 18, 3681. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Li, Y.; Wan, S. Exploring Deep Learning for View-Based 3D Model Retrieval. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–21. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6620–6629. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. 7. In Proceedings of the 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Cohen, T.; Geiger, M.; Köhler, J.; Welling, M. Spherical CNNs. arXiv 2018, arXiv:abs/1801.10130. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5105–5114. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Wang, C.; Samari, B.; Siddiqi, K. Local Spectral Graph Convolution for Point Set Feature Learning. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Thomas, H.; Qi, C.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar]
- Guerrero, P.; Kleiman, Y.; Ovsjanikov, M.; Mitra, N.J. PCPN et Learning Local Shape Properties from Raw Point Clouds. Comput. Graph. Forum 2018, 37, 75–85. [Google Scholar] [CrossRef]
- Simonovsky, M.; Komodakis, N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 29–38. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4548–4557. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1708–1716. [Google Scholar]
- Xu, Q.; Sun, X.; Wu, C.-Y.; Wang, P.; Neumann, U. Grid-GCN for Fast and Scalable Point Cloud Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020; pp. 5660–5669. [Google Scholar]
- Huang, J.; Su, H.; Guibas, L.J. Robust Watertight Manifold Surface Generation Method for ShapeNet Models. arXiv 2018, arXiv:abs/1802.01698. [Google Scholar]
- Feng, Y.; Feng, Y.; You, H.; Zhao, X.; Gao, Y. MeshNet: Mesh Neural Network for 3D Shape Representation. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8279–8286. [Google Scholar] [CrossRef]
- Li, J.; Chen, B.M.; Lee, G.H. SO-Net: Self-Organizing Network for Point Cloud Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Joseph-Rivlin, M.; Zvirin, A.; Kimmel, R. Momen^et: Flavor the Moments in Learning to Classify Shapes. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27 October–2 November 2019; pp. 4085–4094. [Google Scholar]
- Zhang, W.; Su, S.; Wang, B.; Hong, Q.; Sun, L. Local K-NNs Pattern in Omni-Direction Graph Convolution Neural Network for 3D Point Clouds. Neurocomputing 2020, 413, 487–498. [Google Scholar] [CrossRef]
- Wang, W.; You, Y.; Liu, W.; Lu, C. Point Cloud Classification with Deep Normalized Reeb Graph Convolution. Image Vis. Comput. 2021, 106, 104092. [Google Scholar] [CrossRef]
- Chang, A.X.; Funkhouser, T.A.; Guibas, L.J.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]



| Optimizer | Lr | Batch | Weight Decay | Epoch |
|---|---|---|---|---|
| ADAM | 0.001 | 128 | 0.0005 | 250 |
| Model | Params (M) | FLOPs (G) |
|---|---|---|
| PointNet [24] | 3.48 | 0.44 |
| PointNet++ [25] | 1.48 | - |
| Kd-NET [22] | 7.44 | - |
| MVCNN [7] | 60.00 | 62.06 |
| Ours | 1.47 | 1.61 |
| Model | GCN Layers | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Ours | 90.2% | 91.0% | 86.8% | 83.6% |
| Number of Faces | 512 | 1024 | 2048 | 4096 |
| Accuracy | 90.3% | 91.0% | 90.8% | 91.0% |
| Center Module | √ | √ | √ |
| Corner Module | √ | √ | |
| GCN | √ | √ | |
| Accuracy | 91.0% | 89.6% | 87.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Ruan, N.; Shi, J.; Zhou, W. Deep Neural Network for 3D Shape Classification Based on Mesh Feature. Sensors 2022, 22, 7040. https://doi.org/10.3390/s22187040
Gao M, Ruan N, Shi J, Zhou W. Deep Neural Network for 3D Shape Classification Based on Mesh Feature. Sensors. 2022; 22(18):7040. https://doi.org/10.3390/s22187040
Chicago/Turabian StyleGao, Mengran, Ningjun Ruan, Junpeng Shi, and Wanli Zhou. 2022. "Deep Neural Network for 3D Shape Classification Based on Mesh Feature" Sensors 22, no. 18: 7040. https://doi.org/10.3390/s22187040
APA StyleGao, M., Ruan, N., Shi, J., & Zhou, W. (2022). Deep Neural Network for 3D Shape Classification Based on Mesh Feature. Sensors, 22(18), 7040. https://doi.org/10.3390/s22187040