


Unsupervised Person Re-Identification with Attention-Guided Fine-Grained Features and Symmetric Contrast Learning


Abstract
:1. Introduction
- 1.
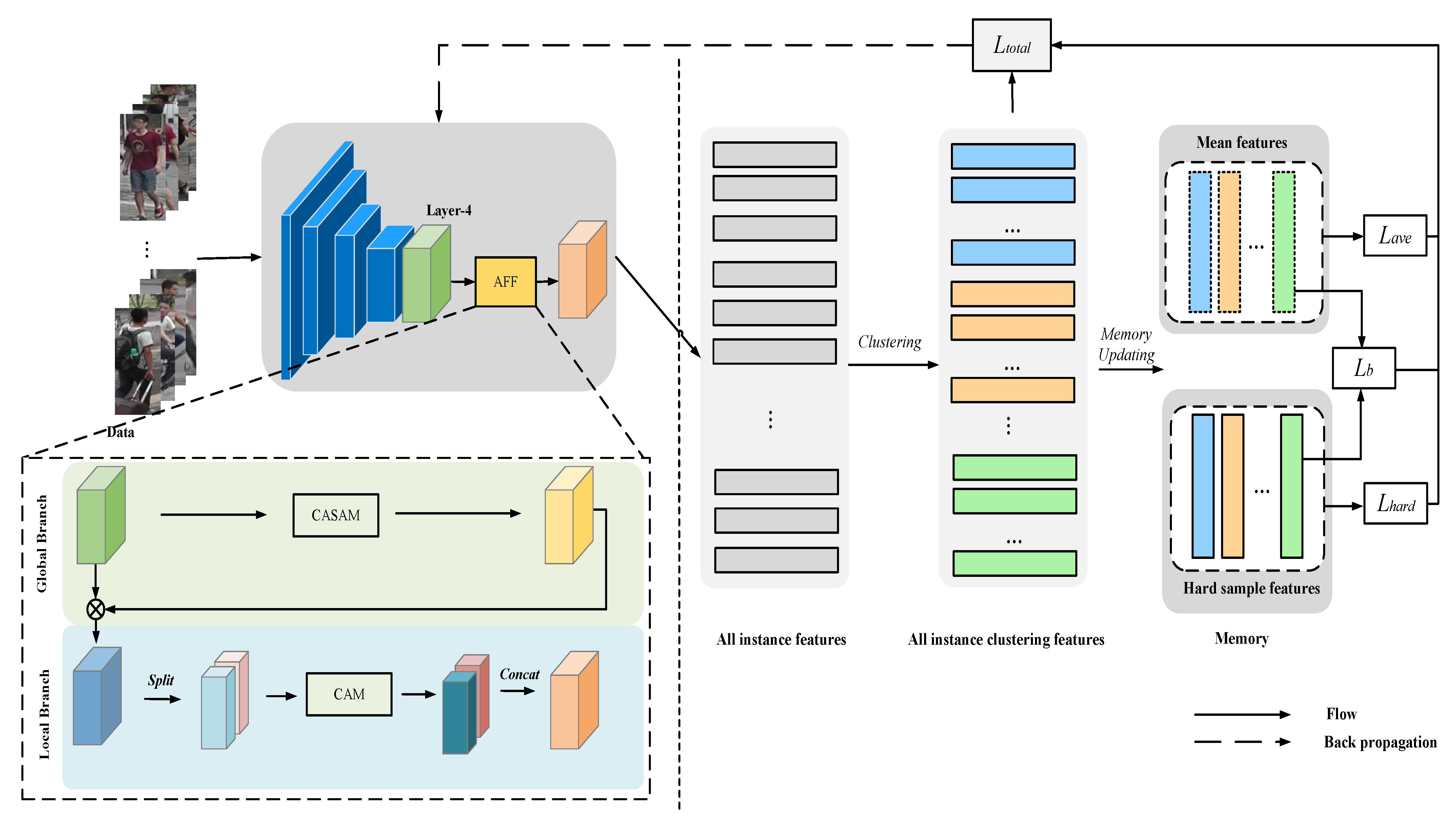
- For the feature-extraction stage, i.e., how to obtain “effective” people features from the model and avoid the interference of background and other noise in the people images, so as to prepare for better clustering, this paper introduces an AFF network. By combining the fine-grained features of people images with the attention mechanism, we can improve the distinguishability of people features and thus enhance the discriminative power of the model.
- 2.
- For the unsupervised learning stage, i.e., how to reduce the influence of “invalid” data in the clustering process, reduce the clustering error and improve the robustness of the model, this paper introduces a SCL method. Instead of adopting a single feature in the selection of clustering representatives in the storage unit, a combination of mean features and hard sample features is adopted to design a symmetric contrast loss to improve the generalization ability of the model.
- 3.
- Combining the methods proposed in the two stages, we construct an unsupervised person-re-identification framework AFF_SCL and conduct performance tests on the Market-1501 and DukeMTMC-reID datasets from both the Unsupervised Learning(USL) and Unsupervised Domain Adaptation(UDA) methods. Additionally, the results show the superiority of the person-re-identification framework designed in this paper.
2. Related Work
2.1. Supervised Person Re-Identification
2.2. Unsupervised Person Re-Identification
2.2.1. Unsupervised Learning Person Re-Identification
2.2.2. Unsupervised Domain Adaptive Person Re-Identification
3. Methods
3.1. Overview
3.2. Preliminary
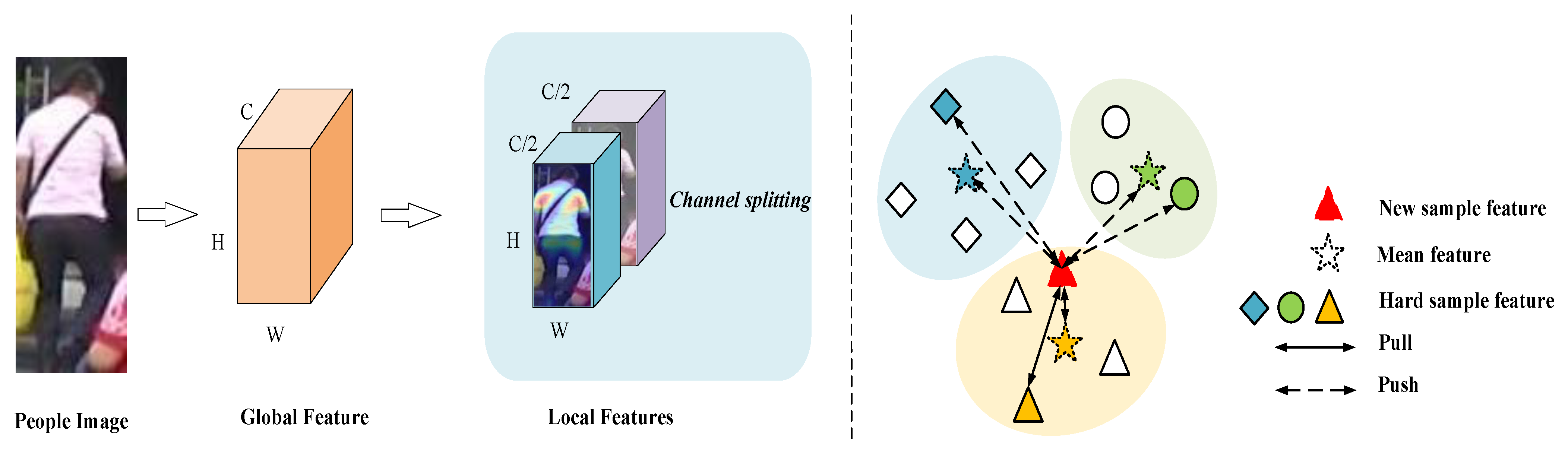
3.3. Attention-Guided Fine-Grained Feature Network
3.3.1. CASAM
3.3.2. CAM
3.4. Symmetric Contrast Learning
3.4.1. Mean-Feature Contrast Loss
3.4.2. Hard-Sample Feature Contrast Loss
3.4.3. Balance Loss
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison with Existing Methods
4.4. Ablation Studies
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Wei, W.; Yang, W.; Zuo, E.; Qian, Y.; Wang, L. Person Re-Identification Based on Deep Learning—An Overview. J. Vis. Commun. Image Represent. 2022, 82, 103418. [Google Scholar] [CrossRef]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 2018 26th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 12–15 June 2018; pp. 274–282. [Google Scholar]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; Huang, T. Horizontal Pyramid Matching for Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8295–8302. [Google Scholar]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A Bottom-Up Clustering Approach to Unsupervised Person Re-Identification. In Proceedings of the 2019 AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8738–8745. [Google Scholar]
- Zeng, K. Hierarchical Clustering with Hard-batch Triplet Loss for Person Re-identification. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13657–13665. [Google Scholar]
- Ding, Y.; Fan, H.; Xu, M.; Yang, Y. Adaptive Exploration for Unsupervised Person Re-Identification. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–19. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling (and a Strong Convolutional Baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Chen, H.; Lagadec, B.; Bremond, F. Learning Discriminative and Generalizable Representations by Spatial-Channel Partition for Person Re-Identification. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 2472–2481. [Google Scholar]
- Chen, G.; Gu, T.; Lu, J.; Bao, J.A.; Zhou, J. Person Re-identification via Attention Pyramid. IEEE Trans. Image Process. 2021, 30, 7663–7676. [Google Scholar] [CrossRef]
- Chen, B.; Deng, W.; Hu, J. Mixed High-Order Attention Network for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 371–381. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]
- Fan, H.; Zheng, L.; Yan, C.; Yang, Y. Unsupervised Person Re-identification: Clustering and Fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–18. [Google Scholar] [CrossRef]
- Wu, J.; Liao, S.; Lei, Z.; Wang, X.; Yang, Y.; Li, S.Z. Clustering and Dynamic Sampling Based Unsupervised Domain Adaptation for Person Re-Identification. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 886–891. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Uiuc, U.; Huang, T. Self-Similarity Grouping: A Simple Unsupervised Cross Domain Adaptation Approach for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6111–6120. [Google Scholar]
- Yang, F.; Zhong, Z.; Luo, Z.; Cai, Y.; Lin, Y.; Li, S.; Sebe, N. Joint Noise-Tolerant Learning and Meta Camera Shift Adaptation for Unsupervised Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4855–4864. [Google Scholar]
- Yang, Q.; Yu, H.X.; Wu, A.; Zheng, W.S. Patch-Based Discriminative Feature Learning for Unsupervised Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3628–3637. [Google Scholar]
- Xuan, S.; Zhang, S. Intra-Inter Camera Similarity for Unsupervised Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11926–11935. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 97–105. [Google Scholar]
- Peng, P.; Xiang, T.; Wang, Y.; Pontil, M.; Gong, S.; Huang, T.; Tian, Y. Unsupervised Cross-Dataset Transfer Learning for Person Re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1306–1315. [Google Scholar]
- Ge, Y.; Chen, D.; Li, H. Mutual Mean-teaching: Pseudo Label Refinery For Unsupervised Domain Adaptation On Person Re-identification. In Proceedings of the 2020 International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020; p. 15. [Google Scholar]
- Zhai, Y.; Ye, Q.; Lu, S.; Jia, M.; Ji, R.; Tian, Y. Multiple Expert Brainstorming for Domain Adaptive Person Re-identification. arXiv 2020, arXiv:2007.01546. [Google Scholar]
- Huang, Y.; Peng, P.; Jin, Y.; Li, Y.; Xing, J. Domain Adaptive Attention Learning for Unsupervised Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11069–11076. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Instance-Guided Context Rendering for Cross-Domain Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 232–242. [Google Scholar]
- Qi, L.; Wang, L.; Huo, J.; Zhou, L.; Shi, Y.; Gao, Y. A Novel Unsupervised Camera-Aware Domain Adaptation Framework for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8079–8088. [Google Scholar]
- Wang, M.; Lai, B.; Huang, J.; Gong, X.; Hua, X.S. Camera-Aware Proxies for Unsupervised Person Re-Identification. arXiv 2020, arXiv:2012.10674. [Google Scholar] [CrossRef]
- Luo, C.; Song, C.; Zhang, Z. Generalizing Person Re-Identification by Camera-Aware Invariance Learning and Cross-Domain Mixup. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Swizterland, 2020; Volume 12360, pp. 224–241. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Yang, Q.; Wu, A.; Zheng, W.S. Deep SemiSupervised Person ReIdentification with External Memory. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1096–1101. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R.; Li, H. Self-Paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID. In Proceedings of the Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 11309–11321. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Dai, Z.; Wang, G.; Yuan, W.; Liu, X.; Zhu, S.; Tan, P. Cluster Contrast for Unsupervised Person Re-Identification. arXiv 2021, arXiv:2103.11568. [Google Scholar]
- Hu, Z.; Zhu, C.; He, G. Hard-Sample Guided Hybrid Contrast Learning for Unsupervised Person Re-Identification. In Proceedings of the 7th IEEE International Conference on Network Intelligence and Digital Content (IC-NIDC), Beijing, China, 17–19 November 2021; pp. 91–95. [Google Scholar]
- Yao, H.; Xu, C. Dual Cluster Contrastive Learning for Person Re-Identification. arXiv 2021, arXiv:2112.04662. [Google Scholar]
- van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.S.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 17–35. [Google Scholar]
- Ding, G.; Khan, S.; Tang, Z.; Zhang, J.; Porikli, F. Towards Better Validity: Dispersion Based Clustering for Unsupervised Person Re-identification. arXiv 2019, arXiv:1906.01308. [Google Scholar]
- Wang, D.; Zhang, S. Unsupervised Person Re-Identification via Multi-Label Classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10978–10987. [Google Scholar]
- Li, J.; Zhang, S. Joint Visual and Temporal Consistency for Unsupervised Domain Adaptive Person Re-Identification. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 483–499. [Google Scholar]
- Lin, Y.; Xie, L.; Wu, Y.; Yan, C.; Tian, Q. Unsupervised Person Re-identification via Softened Similarity Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 3390–3399. [Google Scholar]
- Wang, Z.; Zhang, J.; Zheng, L.; Liu, Y.; Sun, Y.; Li, Y.; Wang, S. CycAs: Self-supervised Cycle Association for Learning Re-identifiable Descriptions. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2022; pp. 72–88. [Google Scholar]
- Wang, G.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Yu, G.; Zhou, E.; Sun, J. High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6449–6458. [Google Scholar]
- Wang, H.; Bi, X. Person Re-Identification Based on Graph Relation Learning. Neural Process. Lett. 2021, 53, 1401–1415. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C.H. Deep Learning for Person Re-identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train Sets (IDs/Images) | Test Sets (IDs/Images) | Query Images | Cameras | Total Images |
|---|---|---|---|---|---|
| Market-1501 [40] | 751/12,936 | 750/19,732 | 3368 | 6 | 32,668 |
| DukeMTMC-reID [41] | 702/16,522 | 702/19,889 | 2228 | 8 | 36,441 |
| Methods | Year | Market-1501 | DukeMTMC-reID | ||
|---|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | ||
| SSL [45] | 2020 | 37.8 | 71.7 | 28.6 | 52.5 |
| BUC [5] | 2019 | 38.3 | 66.2 | 27.5 | 47.4 |
| DBC [42] | 2019 | 41.3 | 69.2 | 30.0 | 51.5 |
| MMCL [43] | 2020 | 45.5 | 80.3 | 40.2 | 65.2 |
| JVTC [44] | 2020 | 41.8 | 72.9 | 42.2 | 67.6 |
| HCT [6] | 2020 | 56.4 | 80.0 | 50.7 | 69.6 |
| DSCE [16] | 2021 | 61.7 | 83.9 | 53.8 | 73.8 |
| CycAs [46] | 2020 | 64.8 | 84.8 | 60.1 | 77.9 |
| IICS [18] | 2021 | 72.9 | 89.5 | 64.4 | 80.0 |
| SpCL [32] | 2020 | 73.1 | 88.1 | 65.3 | 81.2 |
| Ours | - | 78.8 | 90.9 | 68.6 | 82.4 |
| Methods | Year | D → M | M → D | ||
|---|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | ||
| SSG [15] | 2019 | 58.3 | 80.0 | 53.4 | 73.0 |
| AE [7] | 2020 | 58.0 | 81.6 | 46.7 | 67.9 |
| MMT [21] | 2020 | 65.1 | 78.0 | 71.2 | 87.7 |
| DAAL [23] | 2020 | 67.8 | 86.4 | 63.9 | 77.6 |
| GPR [29] | 2020 | 71.5 | 88.1 | 65.2 | 79.5 |
| MEB-Net [22] | 2020 | 76.0 | 89.0 | 66.1 | 79.6 |
| Ours | - | 77.7 | 91.0 | 66.5 | 80.7 |
| Loss | Market-1501 | |
|---|---|---|
| mAP | Rank-1 | |
| Baseline loss (cross-entropy + triples) | 55.8 | 75.3 |
| Mean feature contrast loss | 70.6 | 86.9 |
| Hard sample contrast loss | 76.3 | 89.3 |
| Total loss | 78.8 | 90.9 |
| Market-1501 | |||
|---|---|---|---|
| mAP | Rank-1 | ||
| 0 | 1 | 68.5 | 85.4 |
| 0.25 | 0.75 | 70.4 | 86.0 |
| 0.5 | 0.5 | 75.7 | 88.9 |
| 0.75 | 0.25 | 78.8 | 90.9 |
| 1 | 0 | 73.7 | 87.9 |
| Batch Size | k | Market-1501 | |
|---|---|---|---|
| mAP | Rank-1 | ||
| 64 | 4 | 75.6 | 89.0 |
| 128 | 8 | 78.8 | 90.9 |
| 256 | 16 | 79.6 | 91.4 |
| Methods | Year | Market-1501 | |||
|---|---|---|---|---|---|
| mAP | Rank-1 | Rank-5 | Rank-10 | ||
| Baseline 1 | 2019 | 81.7 | 92.0 | - | - |
| MGN [3] | 2018 | 86.9 | 95.7 | 98.3 | 99.0 |
| HPM [4] | 2019 | 82.7 | 94.2 | 97.5 | 98.5 |
| MHN-6(PCB) [11] | 2019 | 85.0 | 95.1 | 98.1 | 98.9 |
| HOReID [47] | 2020 | 84.9 | 94.2 | - | - |
| GRL [48] | 2021 | 80.5 | 91.7 | - | - |
| Baseline + L | - | 86.8 | 94.5 | 98.4 | 99.0 |
| Baseline + G | - | 87.4 | 94.9 | 98.1 | 98.9 |
| Baseline + AFF | - | 88.2 | 95.0 | 98.3 | 98.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Yang, W.; Wang, M. Unsupervised Person Re-Identification with Attention-Guided Fine-Grained Features and Symmetric Contrast Learning. Sensors 2022, 22, 6978. https://doi.org/10.3390/s22186978
Wu Y, Yang W, Wang M. Unsupervised Person Re-Identification with Attention-Guided Fine-Grained Features and Symmetric Contrast Learning. Sensors. 2022; 22(18):6978. https://doi.org/10.3390/s22186978
Chicago/Turabian StyleWu, Yongzhi, Wenzhong Yang, and Mengting Wang. 2022. "Unsupervised Person Re-Identification with Attention-Guided Fine-Grained Features and Symmetric Contrast Learning" Sensors 22, no. 18: 6978. https://doi.org/10.3390/s22186978
APA StyleWu, Y., Yang, W., & Wang, M. (2022). Unsupervised Person Re-Identification with Attention-Guided Fine-Grained Features and Symmetric Contrast Learning. Sensors, 22(18), 6978. https://doi.org/10.3390/s22186978