

The Role of Artificial Intelligence in Decoding Speech from EEG Signals: A Scoping Review

 and
and
Abstract
:1. Introduction
2. Method
2.1. Search Strategy
2.1.1. Search Sources
2.1.2. Search Terms
2.2. Study Eligibility Criteria
- (1)
- AI-based approach used for decoding speech.
- (2)
- EEG signal data used to build the AI model.
- (3)
- Prediction labels/classes must be words or sentences.
- (4)
- Written in English.
- (5)
- Published between 1 January 2000 to 23 October 2021.
- (6)
- Peer-reviewed articles, conference proceedings, dissertations, thesis, and preprints were included, and conference abstracts, reviews, overviews, and proposals were excluded.
2.3. Study Selection
2.4. Data Extraction and Data Synthesis
3. Results
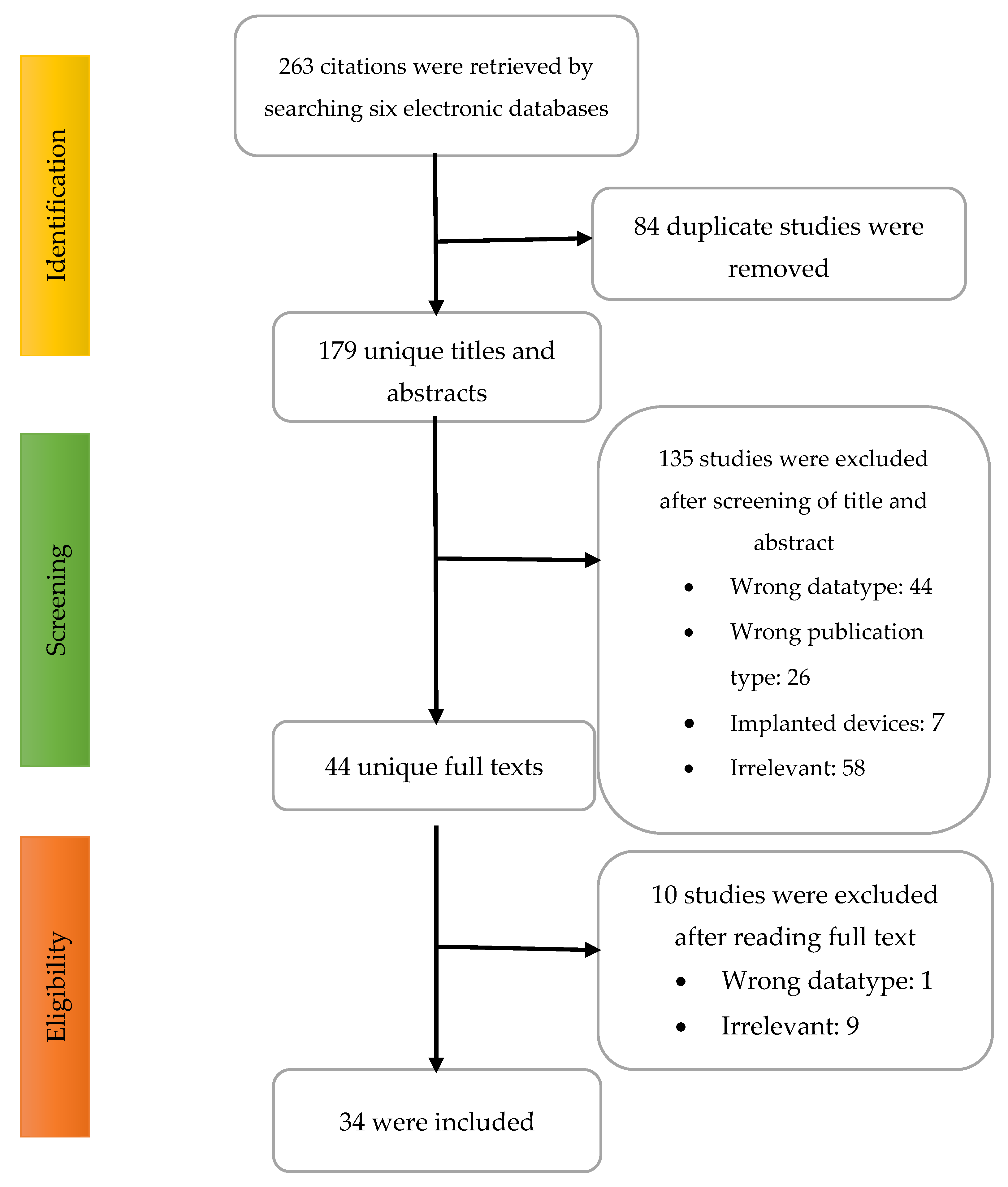
3.1. Search Results
3.2. Studies’ Characteristics
3.3. AI-Enabled Technique for Speech Decoding from EEG Signals
3.4. Characteristics of Dataset
3.5. Characteristics of Data Acquisition from EEG Signal
4. Discussion
4.1. Principal Findings
4.2. Practical and Research Implications
4.2.1. Practical Implications
4.2.2. Research Implications
4.3. Strengths and Limitations
4.3.1. Strengths
4.3.2. Limitations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
| Search String | Database | Number of Hits | Downloaded Citation | Date |
|---|---|---|---|---|
| (“All Metadata”:imagined speech OR “All Metadata”:covert speech OR “All Metadata”:silent speech OR “All Metadata”:inner speech OR “All Metadata”:implicit speech) AND (“All Metadata”:*decoding OR “All Metadata”:neural network OR “All Metadata”:artificial intelligent OR “All Metadata”:machine learning OR “All Metadata”:deep learning) AND (“All Metadata”:electromyography OR “All Metadata”:electroencephalography OR “All Metadata”:electropalatographic) | IEEE | 59 | All | 23/09/2021 |
| ((imagined speech[Title/Abstract] OR covert speech[Title/Abstract] OR silent speech[Title/Abstract] OR speech imagery[Title/Abstract] OR inner speech[Title/Abstract] OR endophasia[Title/Abstract] OR implicit speech[Title/Abstract] AND (2000/1/1:2021/9/21[pdat])) AND (electromyography OR electroencephalography OR electropalatographic OR electromagnetic[MeSH Terms] AND (2000/1/1:2021/9/21[pdat]))) AND (encoding decoding[Title/Abstract] OR neural network[Title/Abstract] OR recurrent neural network[Title/Abstract] OR artificial intelligent[Title/Abstract] OR seq-seq model[Title/Abstract] OR machine learning[Title/Abstract] OR deep learning[Title/Abstract] AND (2000/1/1:2021/9/21[pdat])) AND (2000/1/1:2021/9/21[pdat]) | PubMed | 20 | All | 23/09/2021 |
| TITLE-ABS-KEY (((“imagined speech” OR “inner speech” OR “covert speech” OR “implicit speech” OR “silent speech”) AND (electromyography OR electroencephalography OR electropalatographic) AND (“artificial intelligent” OR “machine learning” OR “deep learning” OR “neural network” OR “*decoding”))) | Scopus | 64 | All | 23/09/2021 |
| [[Abstract: imagined speech] OR [Abstract: covert speech] OR [Abstract: inner speech]] AND [[Abstract: electromyography] OR [Abstract: electroencephalography] OR [Abstract: electropalatographic]] AND [[Abstract: machine learning] OR [Abstract: deep learning] OR [Abstract: neural network] OR [Abstract: artificial intelligent] OR [Abstract: *decoding]] AND [Publication Date: (01/01/2000 TO 09/30/2021)] | ACM | 13 | All | 23/06/2021 |
| date_range: from 2000-01-01 to 2021-12-31; include_cross_list: True; terms: AND all=“imagined speech” OR “inner speech” OR “covert speech” OR “silent speech”; AND all =“electromyography” OR “electroencephalography” OR “electropalatographic “; AND all =“artificial intelligent” OR “machine learning” OR “deep learning” OR “neural network” OR “encoding-decoding” OR “decoding” | arXiv | 7 | All | 25/09/2021 |
| ((imagined speech OR covert speech OR inner speech) AND (electromyography OR electroencephalography) AND (machine learning OR deep learning OR neural network OR artificial intelligence OR *decoding)) | Google Scholar | 3510 | First 100, sorted by relevance | 25/09/2021 |
References
- Choi, H.; Park, J.; Lim, W.; Yang, Y.M. Active-beacon-based driver sound separation system for autonomous vehicle applications. Appl. Acoust. 2021, 171, 107549. [Google Scholar] [CrossRef]
- Mohanchandra, K.; Saha, S. A communication paradigm using subvocalized speech: Translating brain signals into speech. Augment. Hum. Res. 2016, 1, 3. [Google Scholar] [CrossRef]
- Koctúrová, M.; Juhár, J. A Novel Approach to EEG Speech Activity Detection with Visual Stimuli and Mobile BCI. Appl. Sci. 2021, 11, 674. [Google Scholar] [CrossRef]
- Lee, D.-Y.; Lee, M.; Lee, S.-W. Decoding Imagined Speech Based on Deep Metric Learning for Intuitive BCI Communication. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1363–1374. [Google Scholar] [CrossRef]
- Sereshkeh, A.R.; Yousefi, R.; Wong, A.T.; Rudzicz, F.; Chau, T. Development of a ternary hybrid fNIRS-EEG brain–computer interface based on imagined speech. Brain-Comput. Interfaces 2019, 6, 128–140. [Google Scholar] [CrossRef]
- Sereshkeh, A.R.; Trott, R.; Bricout, A.; Chau, T. EEG Classification of Covert Speech Using Regularized Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Processing 2017, 25, 2292–2300. [Google Scholar] [CrossRef]
- Lee, S.-H.; Lee, M.; Lee, S.-W. EEG Representations of Spatial and Temporal Features in Imagined Speech and Overt Speech. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany; Volume 12047, pp. 387–400. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85081641795&doi=10.1007%2f978-3-030-41299-9_30&partnerID=40&md5=33070c92b68e46c3ec38ef065c17a89a (accessed on 24 June 2022).
- Bakhshali, M.A.; Khademi, M.; Ebrahimi-Moghadam, A.; Moghimi, S. EEG signal classification of imagined speech based on Riemannian distance of correntropy spectral density. Biomed. Signal Processing Control. 2020, 59, 101899. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85079830821&doi=10.1016%2fj.bspc.2020.101899&partnerID=40&md5=1db1813bbfa9f186b7d6f3a3d0492daf (accessed on 24 June 2022). [CrossRef]
- Balaji, A.; Haldar, A.; Patil, K.; Ruthvik, T.S.; Valliappan, C.A.; Jartarkar, M.; Baths, V. EEG-based classification of bilingual unspoken speech using ANN. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017; pp. 1022–1025. [Google Scholar]
- Cooney, C.; Korik, A.; Folli, R.; Coyle, D. Evaluation of Hyperparameter Optimization in Machine and Deep Learning Methods for Decoding Imagined Speech EEG. Sensors 2020, 20, 4629. Available online: https://pubmed.ncbi.nlm.nih.gov/32824559/ (accessed on 24 June 2022). [CrossRef]
- Torres-García, A.A.; Reyes-García, C.A.; Villaseñor-Pineda, L.; García-Aguilar, G. Implementing a fuzzy inference system in a multi-objective EEG channel selection model for imagined speech classification. Expert Syst. Appl. 2016, 59, 1–12. [Google Scholar] [CrossRef]
- Nguyen, C.H.; Karavas, G.K.; Artemiadis, P. Inferring imagined speech using EEG signals: A new approach using Riemannian manifold features. J. Neural Eng. 2017, 15, 016002. [Google Scholar] [CrossRef]
- Cooney, C.; Folli, R.; Coyle, D. Mel Frequency Cepstral Coefficients Enhance Imagined Speech Decoding Accuracy from EEG. In Proceedings of the 2018 29th Irish Signals and Systems Conference (ISSC), Belfast, UK, 21–22 June 2018; pp. 1–7. [Google Scholar]
- Qureshi, M.N.I.; Min, B.; Park, H.; Cho, D.; Choi, W.; Lee, B. Multiclass Classification of Word Imagination Speech With Hybrid Connectivity Features. IEEE Trans. Biomed. Eng. 2018, 65, 2168–2177. [Google Scholar] [CrossRef] [PubMed]
- Pawar, D.; Dhage, S. Multiclass covert speech classification using extreme learning machine. Biomed. Eng. Lett. 2020, 10, 217–226. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85081557774&doi=10.1007%2fs13534-020-00152-x&partnerID=40&md5=ce6dbf7911aee9a8fabad5cf11fbbcfd (accessed on 24 June 2022). [CrossRef] [PubMed]
- Sharon, R.A.; Narayanan, S.; Sur, M.; Hema, A. Murthy Neural Speech Decoding During Audition, Imagination and Production. IEEE Access 2020, 8, 149714–149729. [Google Scholar] [CrossRef]
- Hashim, N.; Ali, A.; Mohd-Isa, W.-N. Word-based classification of imagined speech using EEG. In Proceedings of the International Conference on Computational Science and Technology, Kuala Lumpur, Malaysia, 29–30 November 2017; pp. 195–204. [Google Scholar]
- Li, F.; Chao, W.; Li, Y.; Fu, B.; Ji, Y.; Wu, H.; Shi, G. Decoding imagined speech from EEG signals using hybrid-scale spatial-temporal dilated convolution network. J. Neural Eng. 2021, 18, 0460c4. [Google Scholar] [CrossRef]
- Lee, D.Y.; Lee, M.; Lee, S.W. Classification of Imagined Speech Using Siamese Neural Network. IEEE Trans. Syst. Man Cybern. Syst. 2020, 2020, 2979–2984. [Google Scholar]
- Cooney, C.; Korik, A.; Raffaella, F.; Coyle, D. Classification of imagined spoken word-pairs using convolutional neural networks. In Proceedings of the 8th Graz BCI Conference, Graz, Austria, 16–20 September 2019; pp. 338–343. [Google Scholar]
- Panachakel, J.T.; Ramakrishnan, A.G. Decoding Covert Speech From EEG-A Comprehensive Review. Front. Neurosci. 2021, 15, 392. [Google Scholar] [CrossRef]
- Alsaleh, M.M.; Arvaneh, M.; Christensen, H.; Moore, R.K. Brain-computer interface technology for speech recognition: A review. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, APSIPA 2016, Jeju, Korea, 13–16 December 2016. [Google Scholar] [CrossRef]
- Herff, C.; Schultz, T. Automatic speech recognition from neural signals: A focused review. Front. Neurosci. 2016, 10, 429. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. Prisma extension for scoping reviews (PRISMA-SCR): Checklist and explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef]
- Lee, S.-H.; Lee, M.; Lee, S.-W. Neural Decoding of Imagined Speech and Visual Imagery as Intuitive Paradigms for BCI Communication. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2647–2659. [Google Scholar] [CrossRef]
- Krishna, G.; Tran, C.; Carnahan, M.; Tewfik, A. Advancing speech recognition with no speech or with noisy speech. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Zhao, S.; Rudzicz, F. Classifying phonological categories in imagined and articulated speech. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 992–996. [Google Scholar]
- Rusnac, A.-L.; Grigore, O. Convolutional Neural Network applied in EEG imagined phoneme recognition system. In Proceedings of the 2021 12th International Symposium on Advanced Topics in Electrical Engineering (ATEE), Bucharest, Romania, 25–27 March 2021; pp. 1–4. [Google Scholar]
- Sharon, R.A.; Murthy, H.A. Correlation based Multi-phasal models for improved imagined speech EEG recognition. arXiv 2020, arXiv:2011.02195. [Google Scholar]
- Panachakel, J.T.; Ramakrishnan, A.G.; Ananthapadmanabha, T.V. Decoding Imagined Speech using Wavelet Features and Deep Neural Networks. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019; pp. 1–4. [Google Scholar]
- Saha, P.; Fels, S.; Abdul-Mageed, M. Deep Learning the EEG Manifold for Phonological Categorization from Active Thoughts. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2762–2766. [Google Scholar]
- Islam, M.M.; Shuvo, M.M.H. DenseNet Based Speech Imagery EEG Signal Classification using Gramian Angular Field. In Proceedings of the 2019 5th International Conference on Advances in Electrical Engineering (ICAEE), Dhaka, Bangladesh, 26–28 September 2019; pp. 149–154. [Google Scholar]
- Alsaleh, M.; Moore, R.; Christensen, H.; Arvaneh, M. Examining Temporal Variations in Recognizing Unspoken Words Using EEG Signals. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 976–981. [Google Scholar]
- Hamedi, N.; Samiei, S.; Delrobaei, M.; Khadem, A. Imagined Speech Decoding From EEG: The Winner of 3rd Iranian BCI Competition (iBCIC2020). In Proceedings of the 2020 27th National and 5th International Iranian Conference on Biomedical Engineering (ICBME), Tehran, Iran, 26–27 November 2020; pp. 101–105. [Google Scholar]
- Kim, T.; Lee, J.; Choi, H.; Lee, H.; Kim, I.Y.; Jang, D.P. Meaning based covert speech classification for brain-computer interface based on electroencephalography. In Proceedings of the International IEEE/EMBS Conference on Neural Engineering, NER, San Diego, CA, USA, 6–8 November 2013; pp. 53–56. [Google Scholar] [CrossRef]
- Lee, B.H.; Kwon, B.H.; Lee, D.Y.; Jeong, J.H. Speech Imagery Classification using Length-Wise Training based on Deep Learning. In Proceedings of the 9th IEEE International Winter Conference on Brain-Computer Interface, BCI, Gangwon, Korea, 22–24 February 2021. [Google Scholar]
- Krishna, G.; Tran, C.; Carnahan, M.; Tewfik, A. Continuous Silent Speech Recognition using EEG. arXiv 2020, arXiv:2002.03851. [Google Scholar]
- Krishna, G.; Han, Y.; Tran, C.; Carnahan, M.; Tewfik, A.H. State-of-the-art speech recognition using eeg and towards decoding of speech spectrum from eeg. arXiv 2019, arXiv:1908.05743. [Google Scholar]
- Lee, S.-H.; Lee, Y.-E.; Lee, S.-W. Voice of Your Brain: Cognitive Representations of Imagined Speech, Overt Speech, and Speech Perception Based on EEG. arXiv 2021, arXiv:2105.14787. [Google Scholar]
- Min, B.; Kim, J.; Park, H.J.; Lee, B. Vowel Imagery Decoding toward Silent Speech BCI Using Extreme Learning Machine with Electroencephalogram. BioMed Res. Int. 2016, 2016, 2618265. [Google Scholar] [CrossRef] [PubMed]
- Brigham, K.; Kumar, B.V.K.V. Imagined speech classification with EEG signals for silent communication: A preliminary investigation into synthetic telepathy. In Proceedings of the 2010 4th International Conference on Bioinformatics and Biomedical Engineering, iCBBE 2010, Chengdu, China, 18–20 June 2010. [Google Scholar] [CrossRef]
- Thomas, K.P.; Lau, C.T.; Vinod, A.P.; Guan, C.; Ang, K.K. A New Discriminative Common Spatial Pattern Method for Motor Imagery Brain—Computer Interfaces. IEEE Trans. Biomed. Eng. 2009, 56, 2730–2733. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Guan, C.; Chua, K.S.G.; Ang, B.T.; Kuah, C.W.K.; Wang, C.; Phua, K.S.; Chin, Z.Y.; Zhang, H. A large clinical study on the ability of stroke patients to use an EEG-based motor imagery brain-computer interface. Clin. EEG Neurosci. 2011, 42, 253–258. [Google Scholar] [CrossRef]
- Hüsken, M.; Stagge, P. Recurrent neural networks for time series classification. Neurocomputing 2003, 50, 223–235. [Google Scholar] [CrossRef]
- Watrous, R.; Kuhn, G. Induction of Finite-State Automata Using Second-Order Recurrent Networks. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; Volume 4. Available online: https://proceedings.neurips.cc/paper/1991/file/a9a6653e48976138166de32772b1bf40-Paper.pdf (accessed on 24 June 2022).
| Characteristics | Studies (n) | |
|---|---|---|
| Publication type | ||
| Peer-reviewed article | 15 | |
| Conference paper | 16 | |
| Preprint | 3 | |
| Year of publication | ||
| 2021 | 6 | |
| 2020 | 12 | |
| 2019 | 5 | |
| 2018 | 2 | |
| 2017 | 5 | |
| 2016 | 2 | |
| 2015 | 1 | |
| 2013 | 1 | |
| Country of publication | ||
| Korea | 8 | |
| India | 6 | |
| United States | 4 | |
| Canada | 3 | |
| United Kingdom | 3 | |
| Iran | 2 | |
| Bangladesh | 1 | |
| China | 1 | |
| Slovakia | 1 | |
| Malaysia | 1 | |
| Mexico | 1 | |
| Saudi | 1 | |
| Rumania | 1 | |
| Columbia | 1 | |
| Characteristics | Study n | |
|---|---|---|
| AI branch | ||
| Machine learning (ML) | 15 | |
| Deep learning (DL) | 13 | |
| Both (ML & DL) | 6 | |
| Algorithm | ||
| Support vector machine | 10 | |
| Linear discriminant analysis | 9 | |
| K-nearest neighbor | 7 | |
| Random forest | 5 | |
| Decision tree | 2 | |
| Naive Bayes | 2 | |
| Convolutional neural network | 9 | |
| Recurrent neural network | 4 | |
| Artificial neural network | 6 | |
| Hidden Markov model | 2 | |
| Framework | ||
| TensorFlow | 7 | |
| PyTorch | 1 | |
| Scikit learn | 1 | |
| Programming language | ||
| Python | 8 | |
| MATLAB | 5 | |
| Performance metrics | ||
| Accuracy | 29 | |
| Kappa Score | 5 | |
| Word/character error rates | 4 | |
| F1-score | 3 | |
| Precision and recall | 3 | |
| Sensitivity and specificity | 1 | |
| Model validation | ||
| K-fold cross-validation | 20 | |
| Train test split | 10 | |
| Leave-one-out cross-validation | 1 | |
| Loss function | ||
| Cross-entropy | 9 | |
| Mean square error | 4 | |
| Contrastive loss | 1 | |
| Hinge loss | 1 | |
| Euclidian, cosine, and correlation distance | 1 | |
| Characteristics | Study (n) | |
|---|---|---|
| Dataset Availability | ||
| Public | 13 | |
| Private | 21 | |
| Dataset Size | ||
| <500 samples | 8 | |
| ≥500 & <1000 | 11 | |
| ≥1000 & <1500 | 4 | |
| ≥1500 & <2500 | 3 | |
| ≥2500 & >5000 | 1 | |
| ≥5000 | 3 | |
| Signal Filtering and Normalization | ||
| Bandpass filter | 13 | |
| Bandpass and notch filter | 9 | |
| Bandpass and ICA | 8 | |
| Kernel principal component analysis (KPCA) | 1 | |
| Min–max scaling | 1 | |
| Common average reference | 1 | |
| Cropped decoding technique, frequency-specific spatial filters | 1 | |
| Feature extraction | ||
| Common spatial patterns | 5 | |
| Simple features (i.e., min, max, average, std, var, etc.) | 5 | |
| Wavelet-vased features | 7 | |
| Convolutional neural network | 3 | |
| Mel-Cepstral coefficient | 3 | |
| Spectral entropy | 3 | |
| Covariance-based features | 3 | |
| Siamese neural network | 1 | |
| Spectrogram | 1 | |
| Daubechies | 1 | |
| Average power on moving window | 1 | |
| Principal representative feature | 1 | |
| Training set | ||
| ≥90% | 11 | |
| ≥80% | 7 | |
| ≥70% | 2 | |
| <70% | 3 | |
| Testing set | ||
| ≥30% | 2 | |
| ≥20% | 8 | |
| <20% | 7 | |
| Validation set | ||
| ≥20% | 2 | |
| <20% | 5 | |
| Characteristics | Study (n) | |
|---|---|---|
| Subject’s condition | ||
| Healthy | 27 | |
| Not mentioned in the paper | 7 | |
| Language of the Dataset | ||
| English | 26 | |
| Spanish | 4 | |
| Chinese | 1 | |
| Korean | 1 | |
| Slovak | 1 | |
| Persian | 1 | |
| Prediction labels | ||
| Words | 30 | |
| Sentences | 4 | |
| Types of speech | ||
| Covert speech | 21 | |
| Overt speech | 2 | |
| Both | 11 | |
| Visual/audio stimuli | ||
| Yes | 33 | |
| No | 1 | |
| Background noise | ||
| Yes | 7 | |
| No | 4 | |
| Initial rest | ||
| ≥5 s | 8 | |
| 3–4 s | 4 | |
| 1–2 s | 9 | |
| Rest between trails | ||
| ≥5 s | 7 | |
| 3–4 s | 7 | |
| 1–2 s | 9 | |
| Toolbox for recording | ||
| EEGLAB | 14 | |
| PyEEG | 1 | |
| E-Prime | 2 | |
| OpenBMI & BBCI | 2 | |
| NeuroScan | 1 | |
| Setting | ||
| Office | 5 | |
| Lab | 3 | |
| Isolated room | 2 | |
| Devices | ||
| NeuroScan | 8 | |
| Brain Products | 9 | |
| Emotive | 3 | |
| OpenBCI | 1 | |
| Biosemi Active Two | 1 | |
| Number of electrodes | ||
| 128 electrodes | 1 | |
| 64 electrodes | 19 | |
| 32 electrodes | 4 | |
| Less than 32 electrodes | 6 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, U.; Alzubaidi, M.; Mohsen, F.; Abd-Alrazaq, A.; Alam, T.; Househ, M. The Role of Artificial Intelligence in Decoding Speech from EEG Signals: A Scoping Review. Sensors 2022, 22, 6975. https://doi.org/10.3390/s22186975
Shah U, Alzubaidi M, Mohsen F, Abd-Alrazaq A, Alam T, Househ M. The Role of Artificial Intelligence in Decoding Speech from EEG Signals: A Scoping Review. Sensors. 2022; 22(18):6975. https://doi.org/10.3390/s22186975
Chicago/Turabian StyleShah, Uzair, Mahmood Alzubaidi, Farida Mohsen, Alaa Abd-Alrazaq, Tanvir Alam, and Mowafa Househ. 2022. "The Role of Artificial Intelligence in Decoding Speech from EEG Signals: A Scoping Review" Sensors 22, no. 18: 6975. https://doi.org/10.3390/s22186975
APA StyleShah, U., Alzubaidi, M., Mohsen, F., Abd-Alrazaq, A., Alam, T., & Househ, M. (2022). The Role of Artificial Intelligence in Decoding Speech from EEG Signals: A Scoping Review. Sensors, 22(18), 6975. https://doi.org/10.3390/s22186975