1. Introduction
Nowadays, unmanned aerial vehicles (UAVs), or drones, are widely used in the witness of a fast-paced development [
1]. Equipped with radar, cameras and other equipment, UAVs can be used in military areas [
2] such as for tracking, positioning and battlefield detection. However, due to the limitation of fuel load, it is difficult for a single UAV to search a large area. Compared with a single UAV, multiple UAVs can perform more complex tasks. Multiple UAVs sharing information and searching cooperatively can improve the efficiency of task execution. In the process of the search task, the path planning of the multi-UAV is a crucial problem [
3].
For the above problem, many scholars have proposed some multi-UAV path planning algorithms. For instance, hierarchical decomposition is one of the effective way to solve the problem. The clustering algorithm is first used for the multi-UAV task assignment. Then the path planning is based on the Voronoi diagram [
4] or genetic algorithm [
5]. However, these path planning algorithms require a prior knowledge about the environment and centralized task assignment algorithms require a control center to communicate among UAVs, which is not suitable in dynamic scenarios. On the other hand, multi-agent reinforcement learning (MARL) is effective to solve the above problem. The essence of MARL is a stochastic game. MARL combines the Nash strategies of each state into a strategy for an agent while constantly interacting with the environment to update the Q value function in each state of the game. Nash equilibrium solution in MARL can replace the optimal solution to obtain an effective strategy [
6].
In this paper, we explicit Independent Deep Reinforcement Learning (IDRL) to solve the problem of low efficiency when multiple UAVs perform tasks simultaneously. CBBA [
7] (Consensus-Based Bundle Algorithm) is first used for task assignment for multiple UAVs under constraints of time and fuel consumption. Then the UAV chooses the best strategy to complete the task based on the states and actions of other UAVs. A new reward function is developed to guide the UAV to choose the path with high value and punish collisions between UAVs.
The main contributions of this paper are summarized as follows:
- (1)
Different from the centralized path planning algorithm that a central controller is required for task allocation, a distributed path planning algorithm is designed in this paper. UAVs can communicate with each other for task allocation and path planning in a more flexible way.
- (2)
A cooperative search method is proposed. Before selecting the next action, the UAV needs to adopt the corresponding cooperative method according to the incomplete information obtained to improve the efficiency of task execution.
- (3)
A new reward function is proposed to avoid collisions between UAVs while guiding UAVs to target points.
2. Related Work
In this section, we review the literature that settles multi-UAV target assignment and path planning (MUTAPP), figure out their pros and cons and clarify the remaining gaps and challenges for further investigations.
MUTAPP problem is an NP-hard problem in essence, which implies there is no perfect solution to an NP-hard problem. However, for small- and/or medium-sized problems, it is possible to be solved. Hierarchical decomposition is one of the effective methods to solve MUTAPP [
8], which decomposes the MUTAPP problem into task assignment and path planning.
At present, MUTAPP is mainly divided into traditional MTSP and objective function optimization problems. For traditional MTSP, Wang et al. [
9] try to use genetic algorithms for task assignment and cubic spline interpolation for path planning. In [
10], Liu et al. use Overall Partition Algorithm (OPA) for task assignment and use cycle transitions to generate shortest paths. Simulation results show that the proposed algorithm achieves better performance than traditional algorithms based on GA to solve MTSP problems. In [
11], Dubins curves are used to model the UAV kinematics model to make the generated path more realistic. The improved particle swarm optimization algorithm based on heuristic information is proposed to solve MTSP. The results show that the proposed algorithm can generate paths in a small number of iterations. However, in practical applications, the multi-UAV system not only needs to consider the total flight distance, but also the efficiency of the task which is usually evaluated by the objective function.
With a single UAV and no altitude effects, the standard coverage path planning (CPP) problem has been studied extensively in the literature [
12,
13]. The objective function of CPP is defined as the area of the covered region. Miles et al. [
14] proposes rectangle partition relaxation (RPR) algorithm to divide the UAV flight area. In [
15], based on the single UAV algorithm, a density-based sub-region of UAV coverage with a unique role is proposed to optimize the coverage area. Xie et al. [
16] provides a mixed-integer programming formula for CPP and develops two algorithms based on this method to solve the TSP-CPP problem. Based on this research, Xie extends the proposed algorithm in [
17] and proposes a branch-and-bound-based algorithm to find the optimal route. Although these algorithms continuously optimize the UAV coverage area, it is difficult to evaluate the efficiency of UAV execution with a single constraint.
In [
18], the objective function of the multi-UAV system is to minimize energy loss. K-means is used to assign tasks to multiple UAVs, and then genetic algorithm is used to generate specific paths. In [
19], simulated annealing algorithm is used to increase the coverage area of the UAV. Reference [
18] uses the more advanced k-means++; the experimental results show that the generated path is shorter than k-means. In [
20], the Minimum Spanning Tree (MST) is used to generate trajectories and simulation results show that compared with other algorithms, the generated trajectories can obtain more rewards during task execution. Also, there are some algorithms [
21,
22,
23,
24,
25] that use clustering algorithm to solve MUTAPP related problems. However, clustering algorithm is sensitive to noise points. If the task point is far from the central point, it will be assigned to the UAV separately, which is unrealistic.
Wang et al. [
26] use MST to decompose MTSP into multiple TSPs, and then Ant colony algorithm is used to solve TSP. In [
27], a fuzzy approach with a linear complexity level is used to convert the MTSP to several TSPs, then Simulated Annealing (SA) is used to solve each problem. Similarly, Cheng et al. [
28] decouples the MTSP problem into TSP and solves the subproblems through sequential convex programming. Reference [
29] propose a task allocation algorithm based on maximum entropy principle (MEP). Simulation results show that the proposed MEP algorithm achieves better performance than SA algorithm. Cao et al. [
30] introduces Voronoi diagram method into Ant colony algorithm and the unmanned aerial vehicle cooperative task scheduling strategy which conclude task allocation and path planning is gained. Compared with clustering algorithm, these algorithms are more flexible in task allocation and the number of tasks performed by each agent is reduced through reasonable task allocation, which increases the execution efficiency of the algorithm. However, since the cooperation among agents is not considered, which would affect the efficacy of these algorithms.
MARL provides a new solution for MUTAPP problems; it models the decision-making process in the multi-agent environment as a random game where each agent needs to make decisions according to the strategies of other agents. MARL has become a prevalent method to solve the problem of multi-agent cooperation.
In [
31], DRL is used to generate paths for data collected by multiple UAVs without prior knowledge. Reference [
32] uses MADDPG for the cooperative control of four agents; the experimental results show that MADDPG has good performance in complex environments and successfully learns the strategy of multi-agent collaboration. However, with the instability of the environment caused by the increase in the number of agents, the proposed algorithm has certain difficulties in the joint action space. In [
33], MADDPG is used to control the formation of multiple agents during transportation in order to prevent the agent from colliding with other agents on the way to the target point. Chen et al. [
34] use MARL for the collaborative welding of multiple robots. The way of cooperation between robots is also to prevent collisions between agents.
Han et al. [
35] use MADDPG for both task assignment and path planning, and a reward value function is designed to guide the UAV to the target point and avoid collisions between UAVs. In fact, the cooperative approach of avoiding conflict can improve the success rate of task execution but does not directly affect the efficiency of task execution. Also, the proposed algorithm only works in environments where each agent performs one task and cannot be used to solve the multiple traveling salesman problem. Moreover, the performance of value-based reinforcement learning is better than that of policy-based reinforcement learning in the task environment with few actions.
4. IDRL Based Path Planning Algorithm
Independent Reinforcement Learning (IRL) is widely and successfully applied in the field of multi-agent autonomous decision-making. This paper uses IDRL to solve Nash equilibrium in a cooperative game with incomplete information, and each UAV chooses the optimal strategy according to the states and actions of other UAVs to maximize the total rewards.
4.1. System Model
In this paper, we establish a model based on IDRL to enhance the efficiency of task execution through multi-UAV cooperation. We make the following assumptions:
- (1)
Any two UAVs with intersected flight paths can communicate with each other to know the states and actions when the distance between them is less than a threshold. The game between UAVs belongs to incomplete information games.
- (2)
Each UAV can choose the optimal strategy according to the state and action of other UAVs, so the game between UAVs belongs to cooperative games.
- (3)
The UAVs do not choose actions at the same time, so the game between UAVs belongs to dynamic games.
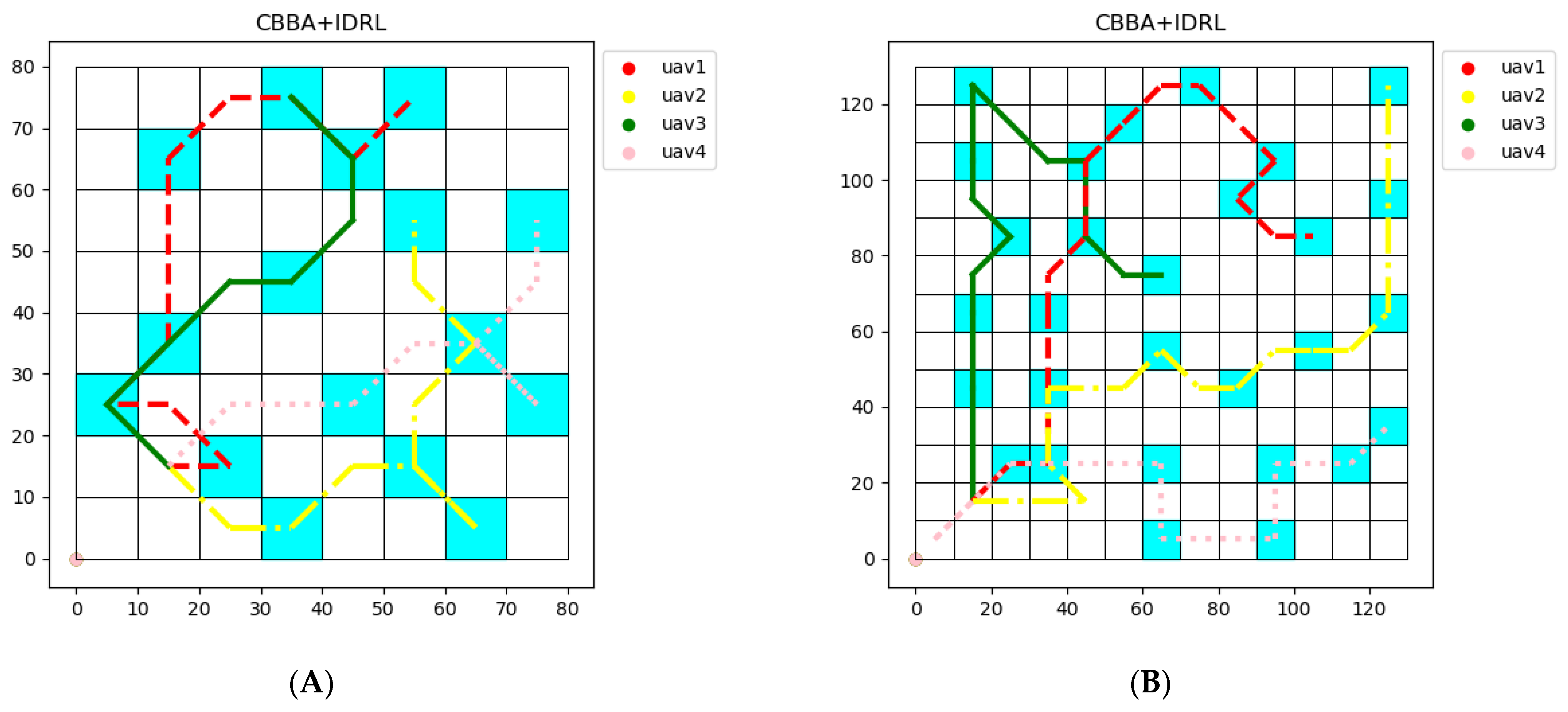
The task environment of multiple UAVs is briefly divided into two-dimensional grids, as shown in
Figure 1. The blue part represents the task area to be executed.
In the cooperative game with incomplete information, the objective function of UAVs is to maximize the search efficiency. ROR and revenue defined in [
36] are used to evaluate the search efficiency of UAVs.
The detection function is used to estimate the detection ability in a probable target grid
with time consumption
. A common exponential form of regular detection function is given as:
where
is a parameter related to the UAV equipment,
represents time consumption.
When an UAV is searching in grid
j, the revenue function defined as
where
p(
j) represents the target probability in grid
.
The efficiency of a multi-UAV system to perform a search task is assessed by the amount of reward per unit of time earned by multiple UAVs. Therefore, the ROR of grid
is introduced with a definition as:
where indicates that the ROR value decreases as the search time
z increases. In other words, a lower ROR indicates that the area is searched more thoroughly.
We assume that each UAV knows the ROR value of all grids, as shown in
Figure 1. The problem can be solved into strategies on CBBA and DRL.
4.2. Nash Equilibrium in MARL
In MARL,
represents the expected reward of
-th agent under the joint strategy
. In a matrix game, if the joint strategy satisfies Equation (9), then the strategy is a Nash equilibrium.
The essence of MARL is a stochastic game. MARL combines the Nash strategies of each state into a strategy for an agent and constantly interacts with the environment to update the Q value function in each state of the game.
The random game consists of a tuple , represents the number of agents, is the state space of the environment, and is the action space of agent , is the probability matrix of state transition, is the reward function of agent i, and 𝛾 is the discount factor. For multi-agent reinforcement learning, the goal is to solve the Nash equilibrium strategy in each stage game and combine these strategies.
The optimal strategy of multi-agent reinforcement learning can be written as
and for
, it have to satisfy Equation (10).
represents the action value function. In each phase game of state
, the Nash equilibrium strategy is solved by using
as the reward of the game. According to Bellman’s formula in reinforcement learning, MARL’s Nash strategy can be rewritten as Equation (11).
In a random game, if the reward function of each agent is the same, the game is called complete cooperative game or team game. In order to solve the random game, stage game at each state needs to be solved, and the reward obtained by taking an action is .
4.3. Path Planning Algorithm Based on IDRL
4.3.1. Environment States
In the cooperative game, UAVs need to choose the optimal strategy according to the state and action of other UAVs. Thus, at timestep
k, the state vector of the
j-UAV is represented by:
where
and
represent the abscissa and ordinate of the
j-UAV, respectively.
represent the coordinates of the nearest UAV,
represents the action of the nearest UAV at timestep
k.
represent the current task coordinates of
j-UAV. The value of
is 0 or 1, indicating whether the area surrounding the UAV has been searched by other UAVs.
4.3.2. Discrete Action Set
Since the length of the grid in the task environment is much larger than the turning radius of the UAV, it can be assumed that the UAV moves in a straight line in the grid. As shown in
Figure 2, when the UAV is in the grid 0, it can perform eight actions to go to the corresponding grid. The numbers in the grids represent eight actions, including: left up, up, right up, left, right, left down, down, and right down.
4.3.3. Reward Function
The reward function is used to evaluate the quality of the action. In fact, there are many factors that could affect the action selection of UAV, but within the scope of research, the following three factors are mainly considered:
Choosing the shortest path to the destination.
Encouraging actions passing high ROR areas.
Preventing collisions between UAVs.
Choosing the shortest path to the target area is not always optimized for path planning, but still has a very high priority in the process. In order to prevent the reward value from being too sparse and speed up the convergence of the IDRL algorithm, a continuous reward function is proposed for the discrete environment. The reward for taking the shortest path is formulated as follows:
In which,
is the integer that increases with the distance of UAV from the target point,
is the current Euclidean distance from the UAV to the target point. We set the coordinates of
-UAV as (
), and the coordinates of the target point as (
), then
In the process of reward value learning, if the reward values of adjacent states are too close, the algorithm may fall into the trap of local optimization due to insufficient training samples. Therefore, for the discovery rate ε, the discovery rate is set to 0.4 to encourage exploration at the beginning of searching for the optimal path. When the algorithm tends to converge, the discovery rate should be reduced to make it approach 0.
The reward function of
is shown in
Figure 3. By using the reward function
, the UAV can choose the shortest path to the target point according to the reward value obtained.
When UAVs perform search tasks in the same area without a preset mode of cooperation, different UAVs may detect repeated messages, causing meaningless time loss. In addition, performing search tasks in the same area can easily lead to UAV collisions.
To prevent collisions between UAVs, we add a small penalty when the distance between two UAVs is less than (
) in length.
where
is the minimum distance between the
-th UAV and the nearest UAV.
is the length of the grid in the task model.
When an UAV flies to the assigned target area, the UAV needs to choose a reasonable path. Specifically, UAVs need to make decisions before moving to target areas. As shown in
Figure 4,
is the shortest path for the UAV to the target area. If the path is always the shortest route, the UAV will sometimes miss the target grids with high ROR values. Compared with the path
, the path
is a more reasonable path. In order to improve the efficiency of UAVs to perform search tasks, the reward function needs to guide the UAV to the target point while passing through the high ROR area on the way. Thus, the reward function
is related to the ROR value of each grid. The combination of reward functions
and
is shown in
Figure 5.
When the reward function is used to train the UAV, the UAV will choose the straight path. When is combined with , the UAV will choose the detour path and will not fall into the local optimum.
However, when a task area has been searched by UAV, it will waste time for other UAVs to search this area again, so it is more reasonable to choose path
. Therefore, UAV needs to decide which path to choose according to the following formula:
Therefore, the final reward value function is the sum of the reward values of all parts, each part of the reward value multiplied by an appropriate coefficient.
where
is the coefficient for rewarding of each reward.
These coefficients represent the proportion of importance of each reward, which can be different between UAVs. Variation of these coefficients could alternate the output results. For example, getting more rewards can use a high value for the coefficient of , while avoiding collisions that can use a low value for the coefficient of .














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}