
Transportation Mode Detection Using Temporal Convolutional Networks Based on Sensors Integrated into Smartphones


Abstract
:1. Introduction
- Availability: The technology used in current transportation mode detection is generally based on GPS, but the common problem is excessive energy consumption and poor adaptability and stability. Secondly, in the process of motor vehicle driving, due to the uncertainty of road conditions and the differences in drivers’ driving habits, etc., it will also lead to the difficulty of getting the desired effect on the distinction between motor vehicles.
- Lightweight: IMU data sources have the advantage of being lightweight. Now many models have too many parameters, and we need the model parameters to be less, faster running technology.
- Expert knowledge: Transportation mode detection does not require manual extraction of features and does not rely on manual challenges.
- We identified eight specific modes of transportation: stationary, walking, running, cycling, car, bus, subway, and train. We exploit TCNs for transportation feature representation learning. Through TCNs and a parallel implementation of convolution, we alleviate the computation burden. TCNs change the receptive field by increasing the number of layers and changing the expansion coefficient and filter size. The gradient of the TCN is in the direction of network depth. For long sequences, a TCN connected by residuals is more stable.
- We use two IMU datasets, which are lightweight, and our proposed T2Trans can comprehensively identify features that differ between traffic modes by analyzing sensing data at a fine-grained level. Moreover, the T2Trans model has fewer parameters and runs faster.
- We evaluate our new approach on two large public datasets, the SHL dataset [7] and the HTC dataset [8]. Experimental results show that T2Trans is significantly better than baseline algorithms, including DT, RF, XGBOOST, CNN, MLP, MLP + LR, Bi-LSTM, CNN + LSTM, and other transportation mode detection methods. Reasonable scalability of T2Trans has also been demonstrated. Extensive results showed that T2Trans achieved the best performance on F1-scores compared to all baselines, with an improvement of 5.94% over the best baseline on the SHL dataset and a 6.40% improvement over the best baseline on the HTC dataset.
2. Related Work
3. Algorithm
3.1. Overview
3.2. T2Trans Model
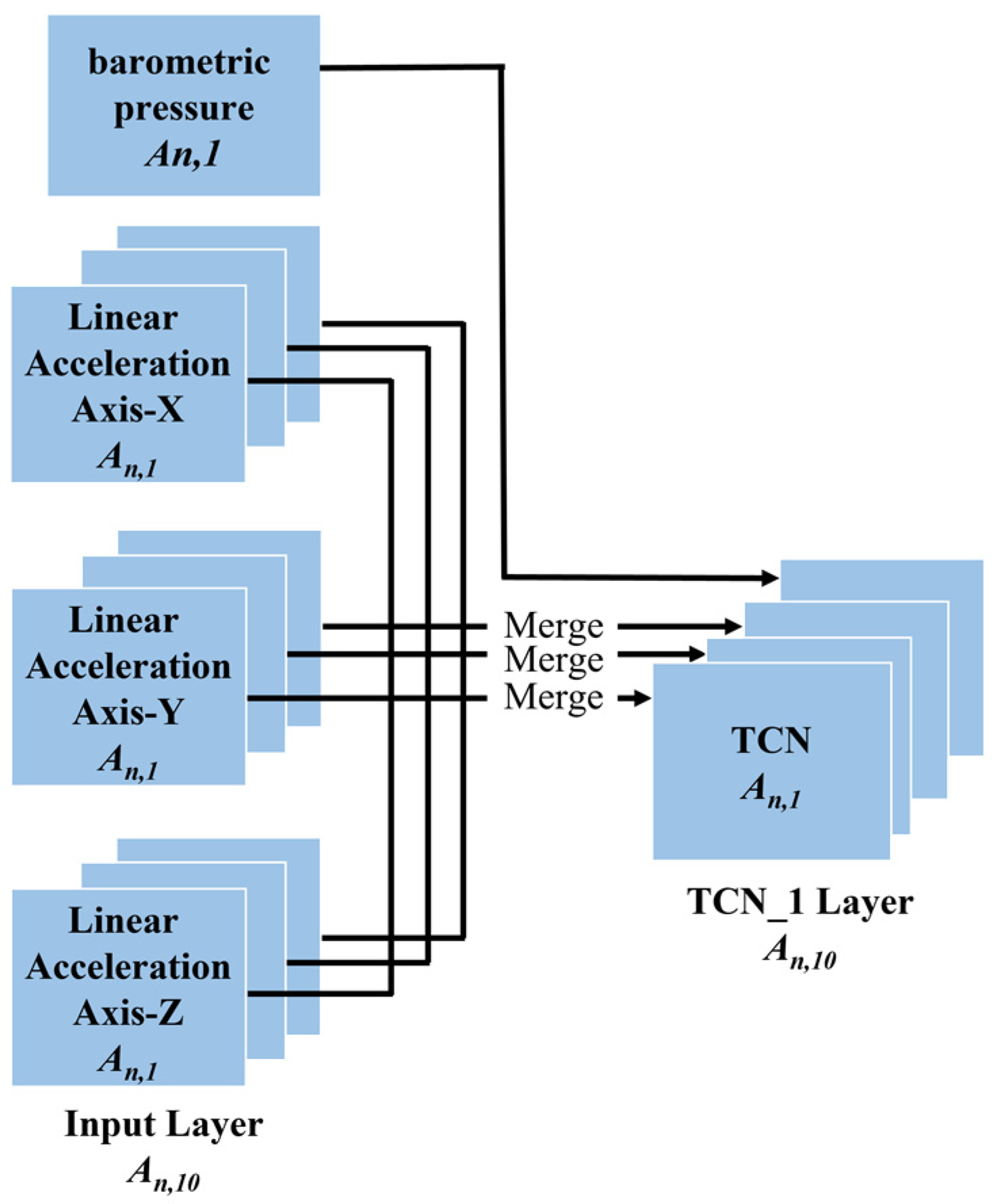
- Multimodal Input Layer. All preprocessed sensor data are fed into the model from the multimodal input layer, defined as tensors where denotes the total number of samples, k denotes the total number of units of all sensors, and denotes the length of the selected sliding window (i.e., 500 samples correspond to a sampling period of 5 s, with a sampling frequency of 100 Hz). In this paper, represents linear acceleration axis X, Y, and Z; gyroscope axis X, Y, and Z; magnetometer axis-X, Y, and Z, and barometric pressure. is converted into 10 tensors denoted by , which are fed into ten channel TCN layers, respectively. Barometric pressure is directly sent to the CTN layer, and the three elements of the other three sensors (i.e., linear acceleration, gyroscope, and magnetometer) are fused first and then fed into the channel TCN layer, as illustrated in Figure 2.
- Channel TCN Layer. A temporal convolutional network (TCN) is a variant of the convolutional neural network. A temporal convolutional network is a convolutional neural network model based on a traditional one-dimensional convolutional neural network and combined with causal convolution, extended convolution, and residual link. Preliminary empirical evaluations of TCN show that simple convolutional architectures exhibit better performance over a variety of tasks and datasets than conventional recursive networks such as LSTM [31] while demonstrating longer effective memory. TCN has flexible receptive fields and stable gradients and can map timing data to output sequences of the same length [32]. TCN uses the one-dimensional convolution kernel to sweep into the current time node and the historical time series data before the node for data processing along the network layer. We use an input sequence , …, , to predict some related outputs , …, at each time period. In order to predict the output at some time , we can only use those inputs that were previously observed: , …, . A sequence modeling network is any function that produces the mapping:
- TCN uses causal convolution. The output at this moment is only convolved with the corresponding input at the moment in the previous layer and the input at the earlier moment and has nothing to do with the future moment. As shown in Figure 3a, the size of each convolution kernel denoted by is 3. TCN adds an extra length of zero padding to keep subsequent layers the same length as previous layers.
- TCN uses extended convolution. By increasing the size of the convolution kernel and the value of the expansion coefficient, the receptive field of the data is enlarged, and the longer convolution “memory” is formed. Figure 3a depicts its structure. More formally [28], for a one-dimensional sequence input and a filter , the extended convolution operation on sequence element is defined as:
- TCN introduces a residual network. The characteristic of a residual block is that it contains a branch that produces output by a series of transformations and then adds its output to the input of the block. Its core idea is to “connect” network layers separated by one or more layers to effectively solve the problem of gradient vanishing in complex models [33]:
- 3.
- Fusion TCN Layer. The fusion TCN layer model structure is similar to that of the channel TCN layer. The size of each convolution kernel is denoted by and . The output of from the channel TCN layer is fed into the fusion TCN layer, and the output tensor of the entire fusion TCN layer is .
- 4.
- MLP Layer. In the MLP layer, feature representations from the fusion TCN layer are implicitly learned. The MLP layer consists of five fully connected networks. We use the dropout method [35] at the MLP layer to reduce the impact of overfitting problems [36] on the performance of T2Trans, and L2 regularizers further enhance the generalization capability of the model. We define the output of the i-th fully connected layer by the following formula:
4. Experimental Evaluation
4.1. Datasets
- SHL Dataset: We chose the SHL dataset [7] to evaluate the performance of the model. First, it is transformed into an matrix, where denotes the total number of samples collected and denotes the total number of elements observed by different sensors. In particular, for the SHL dataset. After preprocessing the SHL dataset, we divided it into the training part (70%) and the test part (30%). We are now in a position to elaborate on the details of the SHL dataset. In 2017, three British volunteers spent seven months collecting their traffic data to form the SHL dataset. Eight modes of transportation were tagged during daily traffic transfers. Each sample contains ambient light, temperature, GPS, WiFi, and motion data. The samples were taken with Huawei Mate 9 smartphones placed in various locations, such as bags, and hands, strapped to the chest, or in pockets. In this paper, only lightweight sensor data (i.e., accelerometers, gyroscopes, magnetometers, and barometers) are leveraged to evaluate our proposed model to identify low-power transportation. In practical application scenarios, sensor data collected in the hand or in the pocket are more often employed, and, therefore, they were chosen for performance evaluation. We chose approximately 272 h of sensor data to train and test our model. The data were collected over four months by the same volunteer. All sensor data were sampled at 100 Hz. To take advantage of time dependence in our experiments, we rearranged the SHL data in chronological order.
- HTC Dataset: To evaluate the scalability of the T2Trans model, a baro-free large-scale dataset called the HTC dataset [8] is used. The HTC dataset has been collected since 2012. A total of 8311 h and 100 GB of data were collected by 150 volunteers using HTC smartphones. Each sample contains accelerometer, gyroscope, and magnetometer data. To maintain consistency among the three evaluation datasets, motorcycle and high-speed rail data from the HTC dataset were discarded. In contrast, different sensor data with timestamp differences of less than 0.1 s were defined. After preprocessing the HTC dataset, we divided it into the training part (70%) and the test part (30%).
4.2. Data Preprocessing
- Dirty data removal: Considering the large size of the public dataset, we adopted a low-cost removal operation for the samples with incomplete sensor vector elements, that is, three-dimensional sensor data without one or two elements. For small datasets, interpolation may be more appropriate.
- Normalization: To deal with the large difference in the value range of heterogeneous sensor data, the z-fraction normalization operation [37] is applied to each element of sensor vector data, and the formula is as follows:
4.3. Baseline
- DT: Decision Tree is a commonly used classification and regression method [38].
- RF: Random Forest is a relatively new machine learning model [39].
- XGBOOST: XGBOOST is an optimization to Boosting, which integrates weak classifiers into a strong one. The XGBOOST algorithm generates a new tree to fit the residual of the previous tree through continuous iteration. With the increase in iteration time, the accuracy keeps improving [40].
- CNN: Convolutional networks learn what is actually a local pattern by convolutional operations on the local area. In this way, increasingly complex and abstract visual concepts can be learned through multiple convolutions.
- MLP: Adopt a set of multilayer perceptions. Each perceptron is trained with data from different specific smartphone locations, including small datasets of hand-held phones. An iterative reweighting scheme is proposed to combine classifiers, which considers their consistency with specialized hand classifiers.
- LR + MLP [41]: The application of LR and MLP neural network models to enhance the predictive power of the model. Logistic regression answers the “whether” question. We add a Softmax to linear regression for multiple classifications and use a cross-entropy loss function. LR is a linear model and MLP is a nonlinear model; MLP fits are more complex.
- Bi-LSTM: The recursive neural network method is used. The two-way LSTM architecture was proposed to address this challenge. The model was trained based on rotation and translational invariance to ignore the orientation and position information of the smartphone [19].
- CNN + LSTM: It combines CNN and LSTM [42]. In this method, CNN allows the learning of feature representations suitable for recognition, and these feature representations are robust for transportation mode detection. LSTM unit is applied to the output of CNN, which plays a role in structural dimension reduction on feature vectors.
4.4. Metrics
4.5. Experimental Settings
4.6. Experimental Results of Different Baselines on SHL Dataset and HTC Dataset
- 3.
- The results of CNN, CNN + LSTM, and T2Trans are generally superior to traditional machine learning methods because CNN + LSTM and T2Trans make full use of the advantages of CNN in feature extraction and give full play to the advantages of deep learning. Classic machine learning hand-extracted features may not do a good job of distinguishing between train and subway patterns. The precisions of MLP and LR + MLP are also above 70%, but the performance is similar to that of machine learning algorithms. High-level features or time dependencies may not be learned using these baselines.
- 4.
- CNN + LSTM is better than other methods, indicating that CNN can learn appropriate feature representations for identification, and these feature representations are robust to transportation mode detection. LSTM unit is used on CNN output, which plays a role in structural dimension reduction on the feature vector, thus significantly improving the performance of transportation mode detection.
- 5.
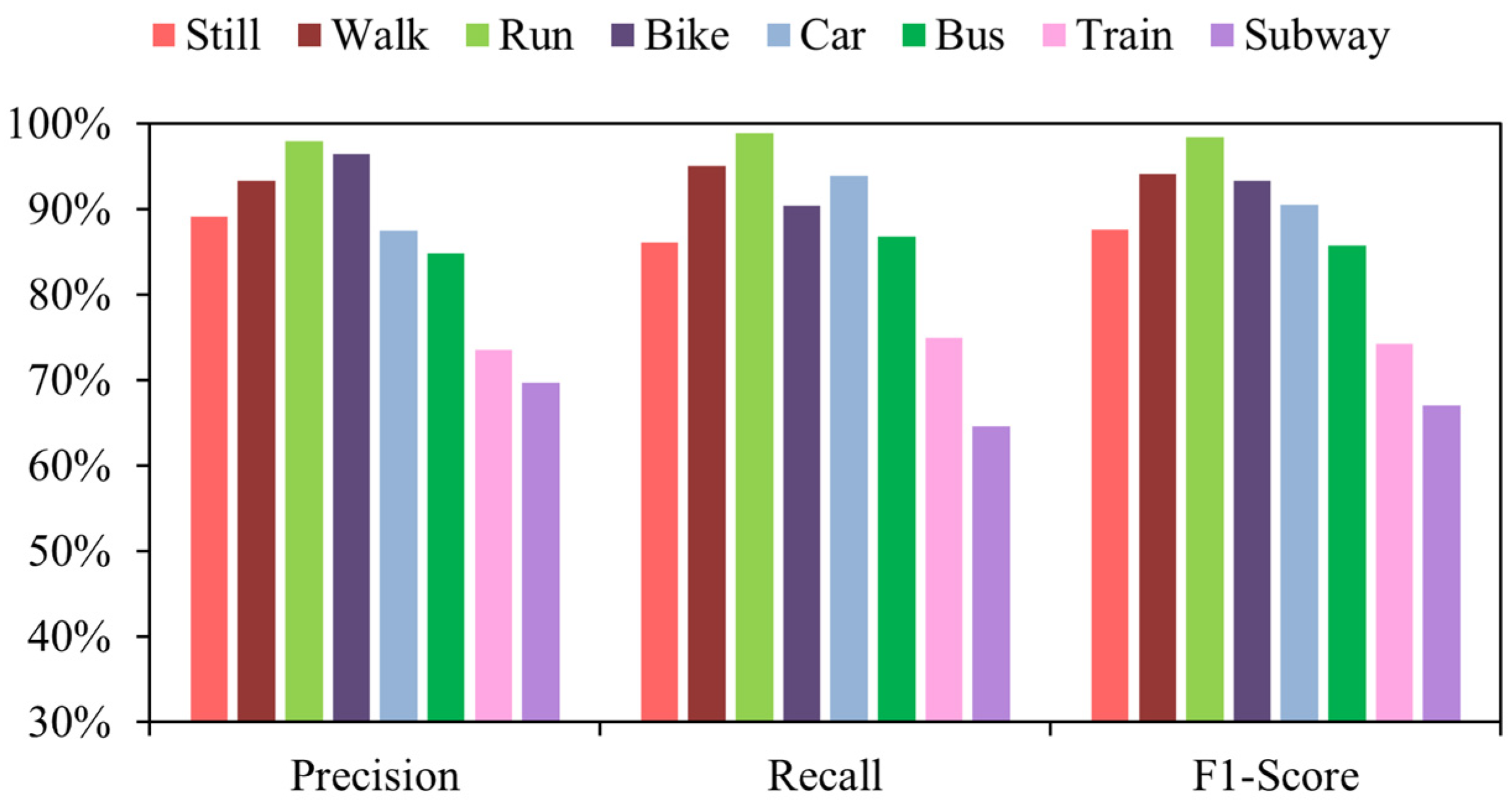
- Our proposed T2Trans was significantly superior to other baselines. The F1 score of the model on the SHL dataset is 86.42% and on the HTC dataset is 88.37%. The accuracy of the algorithms based on DT, RF, XGBOOST, MLP, LR + MLP, Bi-LSTM, and CNN + LSTM are all above 70%. Nevertheless, these baselines do not distinguish well between train and subway modes with high precision. T2Trans not only uses the time convolution layer to construct the entire network, but also includes convolution and pooling operations, and the construction of remaining cells in the complete connection layer not only speeds up the training and prediction process but also improves the overall performance of transportation mode detection. As illustrated in Table 4, classical machine learning algorithms can accurately recognize most transportation modes, i.e., still, walk, run, bike, car, and bus. However, the accuracy for train and subway is lower. Instead, a reasonable representation of all eight modes of transportation was obtained using T2Trans and better accuracy was achieved in all the above baselines.
4.7. Hyperparameter Fine-Tuning
4.8. Impact of Different Sensor Components
4.9. Calculation Complexity
4.10. The Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Engelbrecht, J.; Booysen, M.J.; van Rooyen, G.J.; Bruwer, F.J. Survey of smartphone-based sensing in vehicles for intelligent transportation system applications. IET Intell. Transp. Syst. 2015, 9, 924–935. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing detailed human context in the wild from smartphones and smartwatches. IEEE Pervas. Comput. 2017, 16, 62–74. [Google Scholar]
- Anagnostopoulou, E.; Urbančič, J.; Bothos, E.; Magoutas, B.; Bradesko, L.; Schrammel, J.; Mentzas, G. From mobility patterns to behavioural change: Leveraging travel behaviour and personality profiles to nudge for sustainable transportation. J. Intell. Inf. Syst. 2020, 54, 157–178. [Google Scholar]
- Lorintiu, O.; Vassilev, A. Transportation mode recognition based on smartphone embedded sensors for carbon footprint estimation. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1976–1981. [Google Scholar]
- Feng, T.; Timmermans, H.J. Transportation mode recognition using GPS and accelerometer data. Transp. Res. Part C Emerg. Technol. 2013, 37, 118–130. [Google Scholar] [CrossRef]
- Han, M.; Bang, J.H.; Nugent, C.; McClean, S.; Lee, S. A lightweight hierarchical activity recognition framework using smartphone sensors. Sensors 2014, 14, 16181–16195. [Google Scholar] [CrossRef]
- Gjoreski, H.; Ciliberto, M.; Wang, L.; Morales, F.J.O.; Mekki, S.; Valentin, S.; Roggen, D. The university of sussex-huawei locomotion and transportation dataset for multimodal analytics with mobile devices. IEEE Access 2018, 6, 42592–42604. [Google Scholar]
- Yu, M.C.; Yu, T.; Wang, S.C.; Lin, C.J.; Chang, E.Y. Big data small footprint: The design of a low-power classifier for detecting transportation modes. Proc. VLDB Endow. 2014, 7, 1429–1440. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Almannaa, M.H.; Elhenawy, M.; Rakha, H.A.; House, L. Smartphone transportation mode recognition using a hierarchical machine learning classifier and pooled features from time and frequency domains. IEEE Trans. Intell. Transp. Syst. 2018, 20, 244–252. [Google Scholar]
- Randhawa, P.; Shanthagiri, V.; Kumar, A.; Yadav, V. Human activity detection using machine learning methods from wearable sensors. Sens. Rev. 2020, 40, 591–603. [Google Scholar]
- Badawi, A.A.; Al-Kabbany, A.; Shaban, H. Multimodal human activity recognition from wearable inertial sensors using machine learning. In Proceedings of the 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Sarawak, Malaysia, 3–6 December 2018; pp. 402–407. [Google Scholar]
- Hemminki, S.; Nurmi, P.; Tarkoma, S. Accelerometer-based transportation mode detection on smartphones. In Proceedings of the 11th ACM Conference on Embedded Networked Sensor Systems, Roma, Italy, 11–15 November 2013; pp. 1–14. [Google Scholar]
- Jahangiri, A.; Rakha, H.A. Applying machine learning techniques to transportation mode recognition using mobile phone sensor data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2406–2417. [Google Scholar]
- Stenneth, L.; Wolfson, O.; Yu, P.S.; Xu, B. Transportation mode detection using mobile phones and GIS information. In Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 1–4 November 2011; pp. 54–63. [Google Scholar]
- Roy, A.; Fuller, D.; Nelson, T. Assessing the role of geographic context in transportation mode detection from GPS data. J. Transp. Geogr. 2022, 100, 103330. [Google Scholar] [CrossRef]
- Chandrasiri, G.; Kumarasinghe, K.; Nandalal, H.K. Application of GPS/GIS Based Travel Mode Detection Method for Energy Efficient Transportation Sector. In Proceedings of the 2018 International Conference on Sustainable Built Environment (ICSBE), Singapore, 7 August 2019; pp. 11–21. [Google Scholar]
- Vu, T.H.; Dung, L.; Wang, J.C. Transportation mode detection on mobile devices using recurrent nets. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 392–396. [Google Scholar]
- Dabiri, S.; Heaslip, K. Inferring transportation modes from GPS trajectories using a convolutional neural network. Transp. Res. Part C Emerg. Technol. 2018, 86, 360–371. [Google Scholar] [CrossRef]
- Liu, H.B.; Lee, I. End-to-end trajectory transportation mode classification using Bi-LSTM recurrent neural network. In Proceedings of the 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–5. [Google Scholar]
- Drosouli, I.; Voulodimos, A.S.; Miaoulis, G. Transportation mode detection using machine learning techniques on mobile phone sensor data. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, New York, NY, USA, 30 June 2020; pp. 1–8. [Google Scholar]
- Majeed, U.; Hassan, S.S.; Hong, C.S. Vanilla Split Learning for Transportation Mode Detection using Diverse Smartphone Sensors. In Proceedings of the KIISE Korea Computer Congress, Jeju, Korea, 23–25 June 2021; pp. 867–869. [Google Scholar]
- Wang, C.; Luo, H.; Zhao, F. Combining Residual and LSTM Recurrent Networks for Transportation Mode Detection Using Multimodal Sensors Integrated in Smartphones. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5473–5485. [Google Scholar] [CrossRef]
- Liang, X.Y.; Wang, G.L. A convolutional neural network for transportation mode detection based on smartphone platform. In Proceedings of the 2017 IEEE 14th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Orlando, FL, USA, 22–25 October 2017; pp. 338–342. [Google Scholar]
- Wang, L.; Gjoreski, H.; Ciliberto, M.; Mekki, S.; Valentin, S.; Roggen, D. Benchmarking the SHL recognition challenge with classical and deep-learning pipelines. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1626–1635. [Google Scholar]
- Bastani, F.; Huang, Y.; Xie, X.; Powell, J.W. A greener transportation mode: Flexible routes discovery from GPS trajectory data. In Proceedings of the 19th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems, Chicago, IL, USA, 1–4 November 2011. [Google Scholar]
- Ito, C.; Shuzo, M.; Maeda, E. CNN for human activity recognition on small datasets of acceleration and gyro sensors using transfer learning. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 724–729. [Google Scholar]
- Friedrich, B.; Cauchi, B.; Hein, A.; Fudickar, S. Transportation mode classification from smartphone sensors via a long-short-term-memory network. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 709–713. [Google Scholar]
- Qin, Y.J.; Luo, H.Y.; Zhao, F.; Wang, C.X.; Wang, J.Q.; Zhang, Y.X. Toward transportation mode recognition using deep convolutional and long short-term memory recurrent neural networks. IEEE Access 2019, 7, 142353–142367. [Google Scholar] [CrossRef]
- Chen, Z.H.; Zhang, L.; Jiang, C.Y.; Cao, Z.G.; Cui, W. WiFi CSI based passive human activity recognition using attention based BLSTM. IEEE Trans. Mob. Comput. 2018, 18, 2714–2724. [Google Scholar] [CrossRef]
- Bai, S.J.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. Available online: https://arxiv.org/abs/1803.01271 (accessed on 1 September 2022).
- Sesti, N.; Garau-Luis, J.J.; Crawley, E.; Cameron, B. Integrating LSTMS and GNNS for covid-19 forecasting. arXiv 2021, arXiv:2108.10052. Available online: https://arxiv.org/abs/2108.10052 (accessed on 1 September 2022).
- Cao, Y.D.; Ding, Y.F.; Jia, M.P.; Tian, R.S. A novel temporal convolutional network with residual self-attention mechanism for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lawrence, S.; Giles, C.L. Overfitting and neural networks: Conjugate gradient and backpropagation. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27–27 July 2000; pp. 114–119. [Google Scholar]
- Saranya, C.; Manikandan, G. A study on normalization techniques for privacy preserving data mining. Int. J. Eng. Technol. 2013, 5, 2701–2704. [Google Scholar]
- Olanow, C.W.; Koller, W.C. An algorithm (decision tree) for the management of Parkinson’s disease: Treatment guidelines. American Academy of Neurology. Neurology 1998, 50, S1–S57. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Pour, N.M.; Oja, T. Prediction power of logistic regression (LR) and Multi-Layer perceptron (MLP) models in exploring driving forces of urban expansion to be sustainable in estonia. Sustainability 2022, 14, 160. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, C.; Luo, H. Transportation recognition with the Sussex-Huawei Locomotion challenge. In Proceedings of the Adjunct Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 798–802. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–13. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Architecture |
|---|---|
| DT | min_leaf_size = 1000 |
| RF | TreeBagger: NumTrees = 20, minleafsize = 1000 |
| XGBOOST | n_estimators = 900, max_depth = 7, min_child_weight = 1 |
| CNN | C(32)-C(32)-C(64) |
| MLP | FC(128)-FC(256)-FC(512)-FC(1024)-Softmax |
| Bi-LSTM | LSTM(128)-LSTM(128)-FC-Softmax |
| CNN + LSTM | EACH ELEMENT[C(64)-C(128)]-C(32)-LSTM(128)-DNN(128)-DNN(256)-DNN(512)-DNN(1024)-Softmax |
| Name | Detail |
|---|---|
| CPU | Intel(R) Xeon(R) CPU @ 2.30 GHz |
| Memory | 16GB |
| GPU | Tesla P100-PCIE-16GB |
| Operating System | Ubuntu 18.04.5 LTS |
| Python Environment | 3.7.13 |
| Development Framework | Keras |
| DT | RF | XGBOOST | CNN | MLP | CNN + LSTM | T2Trans | |
|---|---|---|---|---|---|---|---|
| Still | 72.87% | 74.75% | 75.60% | 90.97% | 75.45% | 82.14% | 89.18% |
| Walk | 76.01% | 86.77% | 89.98% | 95.97% | 87.43% | 92.82% | 93.31% |
| Run | 87.58% | 97.68% | 99.34% | 98.02% | 96.30% | 98.50% | 98.02% |
| Bike | 72.32% | 83.56% | 85.10% | 95.05% | 67.37% | 93.81% | 96.49% |
| Car | 68.93% | 65.42% | 72.76% | 85.81% | 65.49% | 79.67% | 87.53% |
| Bus | 60.30% | 57.73% | 61.11% | 77.27% | 62.17% | 68.83% | 84.81% |
| Train | 66.57% | 59.78% | 64.46% | 62.21% | 56.64% | 68.78% | 73.54% |
| Subway | 61.97% | 54.51% | 52.63% | 63.16% | 62.24% | 60.49% | 69.70% |
| DT | RF | XGBOOST | CNN | MLP | CNN + LSTM | T2Trans | |
|---|---|---|---|---|---|---|---|
| Still | 76.74% | 93.22% | 81.91% | 91.76% | 82.47% | 86.31% | 90.74% |
| Walk | 54.12% | 68.04% | 79.41% | 89.66% | 62.54% | 81.03% | 91.79% |
| Run | 77.98% | 94.83% | 93.62% | 97.34% | 86.22% | 94.76% | 97.35% |
| Bike | 52.06% | 75.42% | 79.74% | 90.79% | 65.54% | 83.89% | 95.61% |
| Car | 66.23% | 74.50% | 69.36% | 84.85% | 80.94% | 82.99% | 91.13% |
| Bus | 36.07% | 84.48% | 74.71% | 62.50% | 73.01% | 71.22% | 85.81% |
| Train | 58.38% | 78.53% | 74.50% | 69.44% | 69.88% | 76.60% | 84.94% |
| Subway | 50.42% | 75.22% | 68.36% | 71.88% | 64.35% | 78.99% | 76.65% |
| SHL DATASET | HTC DATASET | |||
|---|---|---|---|---|
| Training | Test | Training | Test | |
| Still | 97.62% | 86.16% | 95.87% | 92.99% |
| Walk | 98.72% | 95.03% | 97.59% | 92.48% |
| Run | 99.93% | 98.86% | 99.56% | 97.87% |
| Bike | 99.26% | 90.42% | 98.60% | 92.79% |
| Car | 99.48% | 93.90% | 97.73% | 91.72% |
| Bus | 99.53% | 86.80% | 84.67% | 70.74% |
| Train | 95.10% | 75.00% | 91.99% | 78.01% |
| Subway | 83.65% | 64.65% | 98.50% | 85.53% |
| RF | XGBOOST | CNN | MLP | LR + MLP | Bi-LSTM | CNN + LSTM | T2Trans | |
|---|---|---|---|---|---|---|---|---|
| Still | 75.95% | 85.40% | 81.46% | 84.74% | 86.18% | 72.45% | 80.16% | 86.16% |
| Walk | 89.96% | 84.65% | 96.34% | 60.15% | 79.70% | 93.62% | 94.76% | 95.03% |
| Run | 89.56% | 89.43% | 98.29% | 87.77% | 85.64% | 98.91% | 98.29% | 98.86% |
| Bike | 83.63% | 64.90% | 94.31% | 57.38% | 80.33% | 91.40% | 88.92% | 90.42% |
| Car | 58.18% | 90.09% | 90.38% | 83.31% | 76.33% | 76.82% | 81.92% | 93.90% |
| Bus | 60.59% | 38.28% | 76.83% | 59.57% | 48.93% | 60.67% | 69.21% | 86.80% |
| Train | 58.60% | 69.95% | 66.59% | 80.85% | 60.99% | 52.49% | 54.20% | 75.00% |
| Subway | 63.37% | 68.83% | 65.26% | 46.84% | 65.53% | 55.34% | 57.10% | 64.65% |
| RF | XGBOOST | CNN | MLP | LR + MLP | Bi-LSTM | CNN + LSTM | T2Trans | |
|---|---|---|---|---|---|---|---|---|
| Still | 93.90% | 89.14% | 89.69% | 87.22% | 84.33% | 84.94% | 89.07% | 92.99% |
| Walk | 68.27% | 75.44% | 91.23% | 67.42% | 75.69% | 78.47% | 86.72% | 92.48% |
| Run | 94.74% | 92.05% | 97.87% | 92.55% | 92.55% | 88.88% | 94.15% | 97.87% |
| Bike | 73.02% | 69.77% | 89.84% | 67.21% | 82.95% | 82.13% | 87.87% | 92.79% |
| Car | 75.04% | 81.56% | 88.23% | 81.50% | 78.00% | 75.31% | 83.83% | 91.72% |
| Bus | 92.59% | 52.68% | 70.74% | 62.23% | 42.02% | 62.50% | 58.51% | 70.74% |
| Train | 78.88% | 73.99% | 76.95% | 77.31% | 47.16% | 67.01% | 75.18% | 78.01% |
| Subway | 73.50% | 71.88% | 78.42% | 61.05% | 67.37% | 56.78% | 71.05% | 85.53% |
| Algorithm | Platform Type | Training Time | Parameter Size |
|---|---|---|---|
| DT | GPU | 90 s | - |
| RF | GPU | 90 s | - |
| XGBOOST | GPU | 6653.52 s | - |
| MLP | GPU | 140.44 s | 1,338,248 |
| CNN | GPU | 1200 s | 70,348 |
| CNN + LSTM | GPU | 64,080 s | 125,568 |
| T2Trans | GPU | 786.09 s | 796,880 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Jiang, Y. Transportation Mode Detection Using Temporal Convolutional Networks Based on Sensors Integrated into Smartphones. Sensors 2022, 22, 6712. https://doi.org/10.3390/s22176712
Wang P, Jiang Y. Transportation Mode Detection Using Temporal Convolutional Networks Based on Sensors Integrated into Smartphones. Sensors. 2022; 22(17):6712. https://doi.org/10.3390/s22176712
Chicago/Turabian StyleWang, Pu, and Yongguo Jiang. 2022. "Transportation Mode Detection Using Temporal Convolutional Networks Based on Sensors Integrated into Smartphones" Sensors 22, no. 17: 6712. https://doi.org/10.3390/s22176712
APA StyleWang, P., & Jiang, Y. (2022). Transportation Mode Detection Using Temporal Convolutional Networks Based on Sensors Integrated into Smartphones. Sensors, 22(17), 6712. https://doi.org/10.3390/s22176712