With the rapid development of the world economy, people’s living standards are improving day by day; At the same time, the rapid development of the internet enables more and more consumers to choose convenient online shopping. According to the statistics of the China Post Bureau, the business volume of express service enterprises in China has reached 108.30 billion, up 29.9% year on year, and business revenue has reached 1033.23 billion yuan, up 17.5% year on year. In 2021, because of the increase of express business, this has put existing logistics systems to a huge test. At present, the sorting of express delivery is mainly by a courier sheet that can be divided into automatic sorting, semi-automatic sorting and manual sorting. Automatic sorting is by use of infrared bar code detection based on radio frequency identification (rfid) technology for delivery information [
1]. This method is costly, difficult to popularize, and mainly used in large-scale logistics express sorting centers [
2]. Semi-automatic sorting involves a semi-automatic sorting machine based on machine vision for sorting. The staff put the courier sheet upward and then put it on a conveyor belt. A camera above the conveyor belt acquires pictures of the courier sheet, and then the central processor identifies the barcode information to generate an electrical signal and control the conveyor belt to send the express to different areas. Manual sorting done directly by a labor force, which is inefficient. With the continuous development of smart logistics and the limitations of cost, most small logistics sorting centers now adopt a semi-automatic sorting method. However, due to the limitations of the sorting environment and equipment, barcodes cannot normally be recognized in the identification process, which requires manual intervention to increase sorting efficiency.
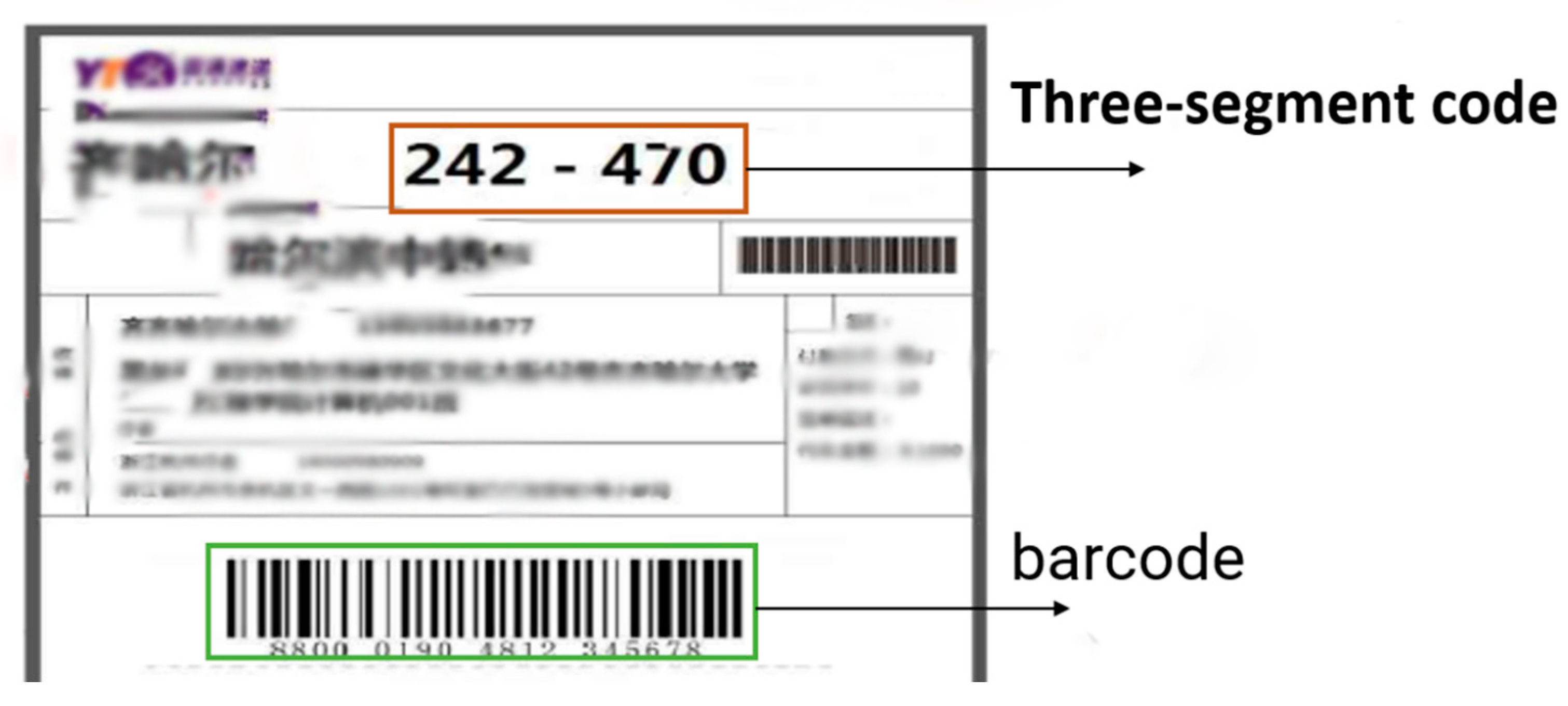
The courier sheet mainly contains a one-dimensional barcode, three segments of express code and the user’s personal information. The one-dimensional bar code is economical, time-dependent and has abundant logistics information. When this semi-automatic sorting method scans the one-dimensional bar code for sorting, the bar code can be disturbed obscured by stains and distortion after layer-by-layer sorting, which seriously affects express sorting. The light in the warehouse, creases and other factors affect detection of the barcode. An express three-segment code is composed of characters with larger fonts, and each segment represents different information, including cities, outlets and salesmen. However, the three-segment code is also easily affected by the characteristics of its surface, resulting in low accuracy in detecting the three-segment code area. Therefore, in the process of express sorting, the positioning of target information is key to sorting an determines its efficiency. Existing sorting methods based on single information on the courier sheet can be divided into two categories. One is a method based on traditional digital image processing. For example, Huang et al. [
3] used Halcon visual recognition technology to extract single three-segment code information from the courier sheet with good accuracy but high cost. Weihao et al. [
4] used a Hough transform to detect regions containing barcodes. Katona M [
5] used algorithms based on morphological operations to detect barcodes, and an improved version [
6] used Euclidean distance maps to match barcode candidates. However, such methods are subject to environmental factors and depend on digital image processing, so it is difficult to detect barcodes accurately and efficiently in complex environments. Another method is based on deeper learning [
7]. With the continuous development of convolutional neural networks in object detection, these have been widely used in sorting. Zamberletti A et al. [
8] first used a deep neural network for barcode detection, but it was not very effective in practice because it was developed using experimental images. Kolekar A and Ren Y [
9,
10] used the deeper learning detector of SSD for barcode detection, and achieved good performance under a complex background. Li J et al. [
11] used the Faster R-CNN network for barcode detection and achieved better detection results with higher accuracy and strong robustness. Z. Pan [
12] used a YOLO algorithm for detection of packages when dealing with the problem of express stacking. R. Shashidhar [
13] used a YOLOv3 model and OCR to detect and recognize license plates and achieved good results. Methods based on traditional digital processing are easily affected by environmental factors when detecting the target area, which leads to inaccurate detected areas and may cause recognition errors. The use of deeper learning methods to detect the target area has advantages. In image recognition, a convolutional neural network is used to learn various features of the target, which is more robust in target detection. In this regard, considering the complexity of the express sorting environment, we decided to use a deeper learning method to detect the target information. At the same time, we considered that it would be too simple to select only certain information as the sorting information in the real-time sorting process, and the robustness would be poor. In a complex logistics environment, false detection will occur, which will affect sorting efficiency. Therefore, we chose the multi-information method t better guarantee the accuracy of identification.
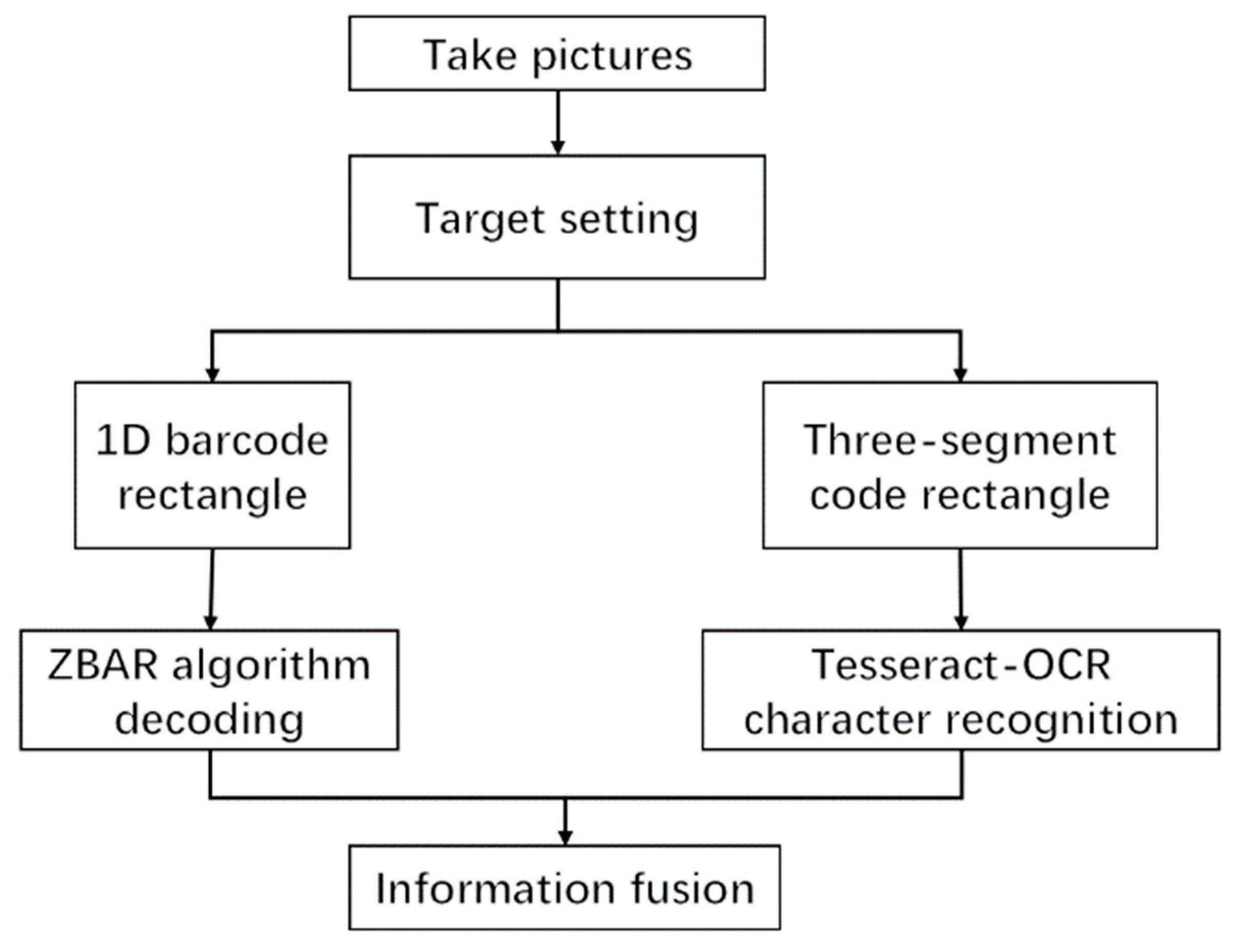
In summary, we propose a deeper learning-based multi-information fusion method for courier sheet recognition. The method is mainly divided into two stages, one being the positioning of the one-dimensional barcode and the three-segment code on the courier sheet, and the other the decoding of the barcode and the recognition of the three-segment code. As shown in
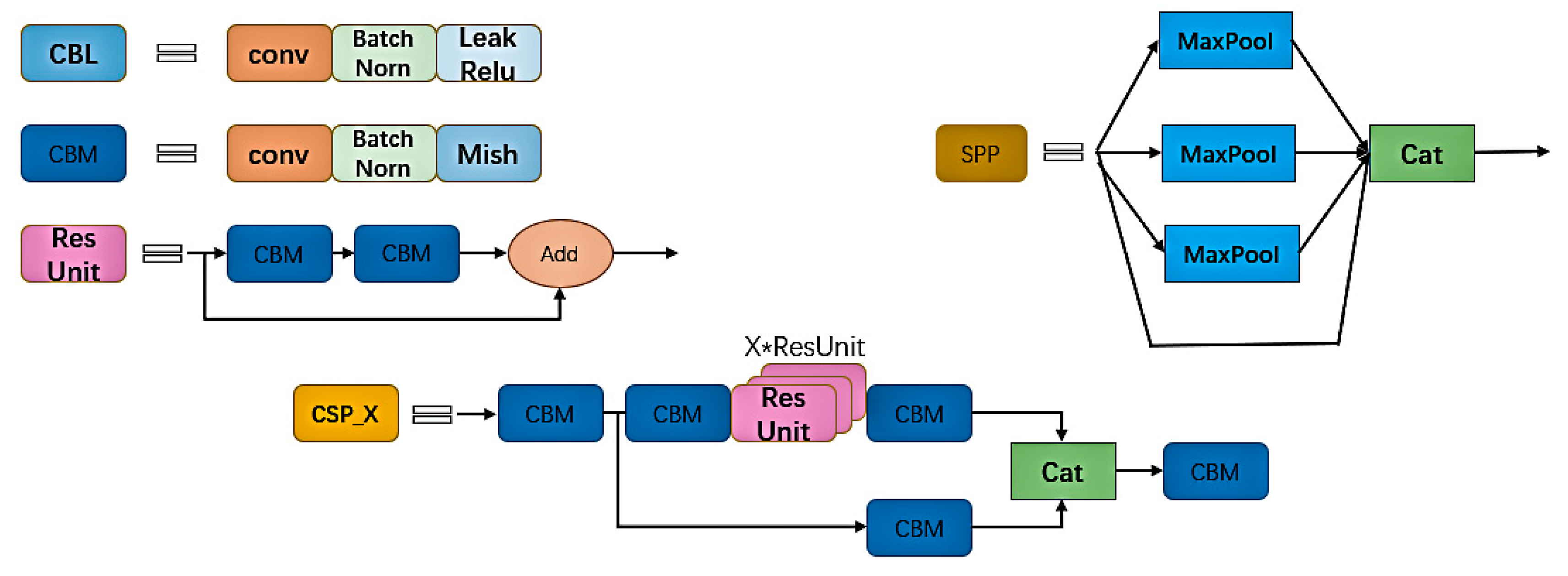
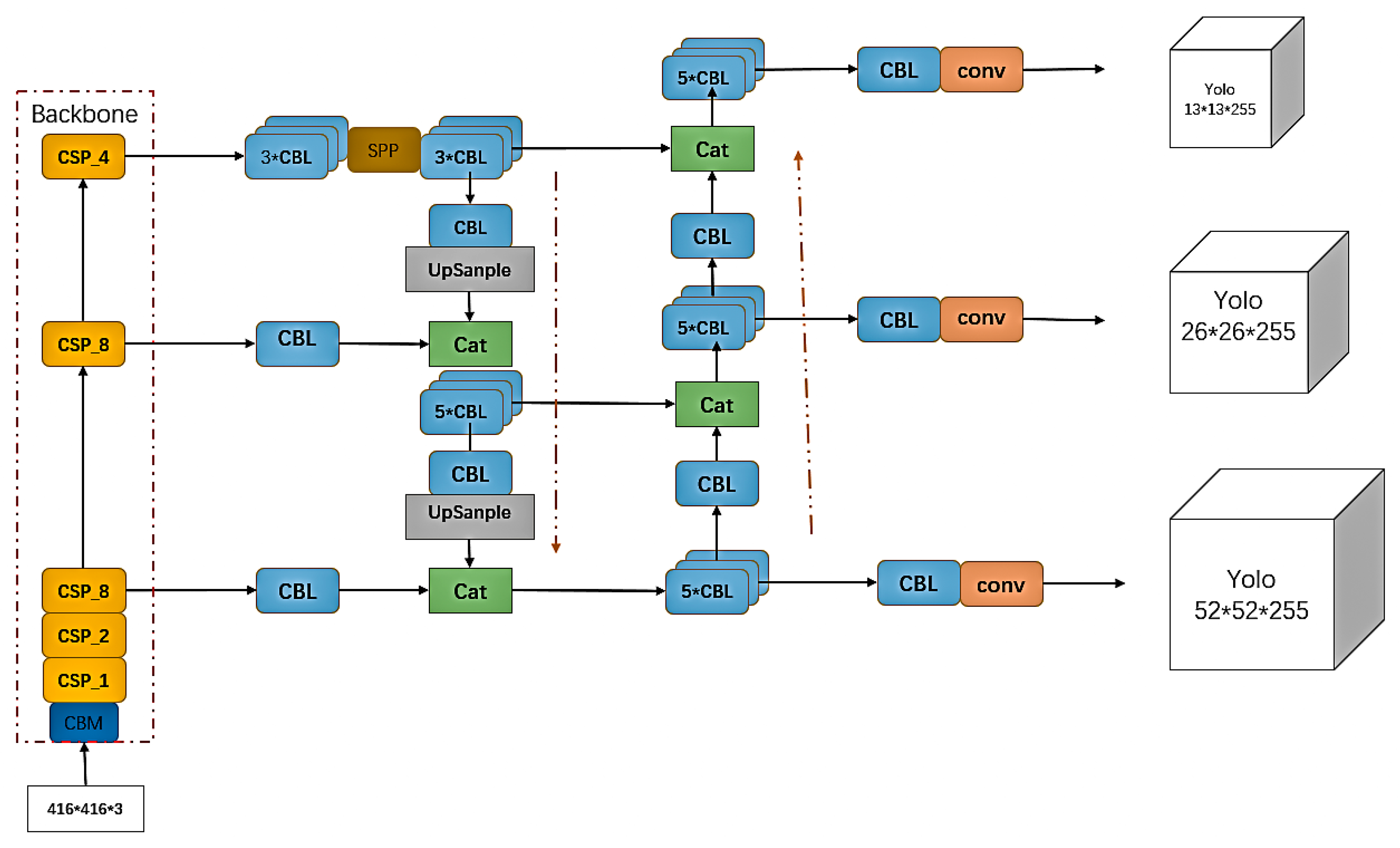
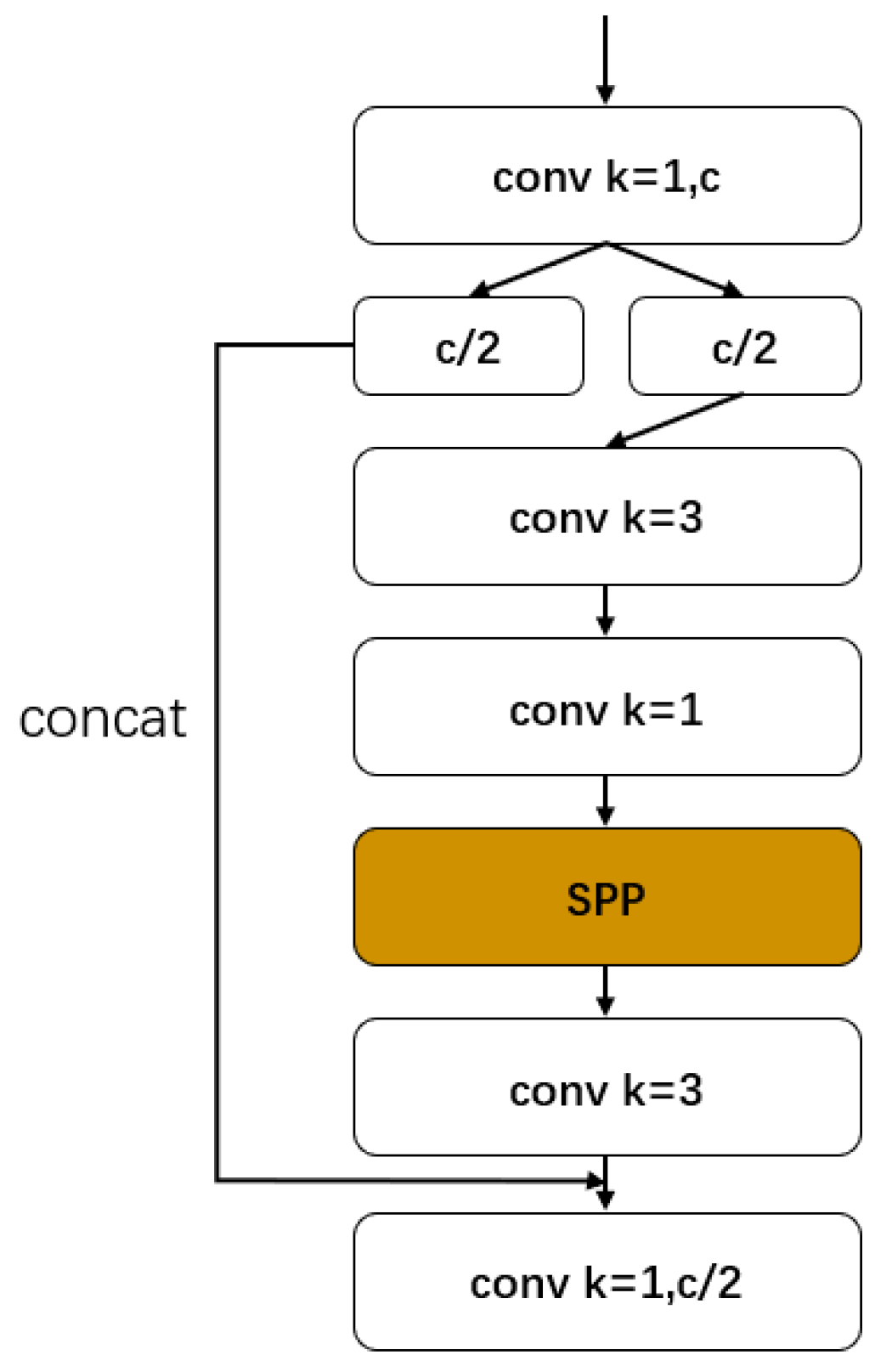
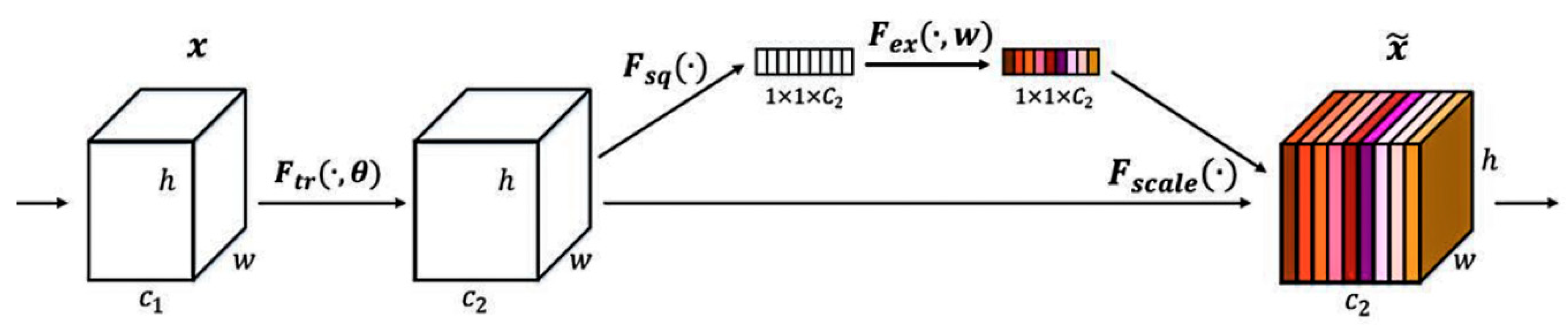
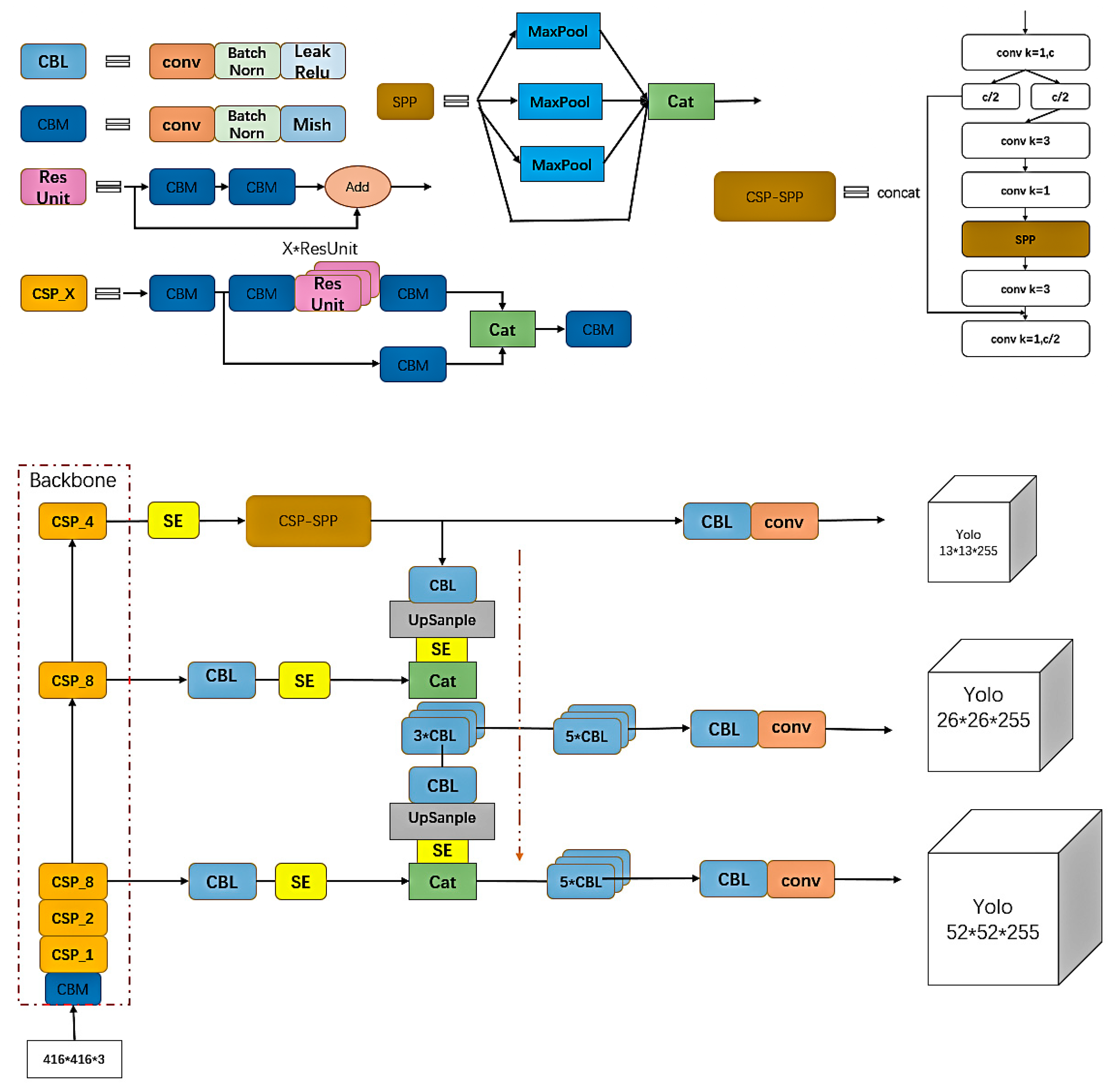
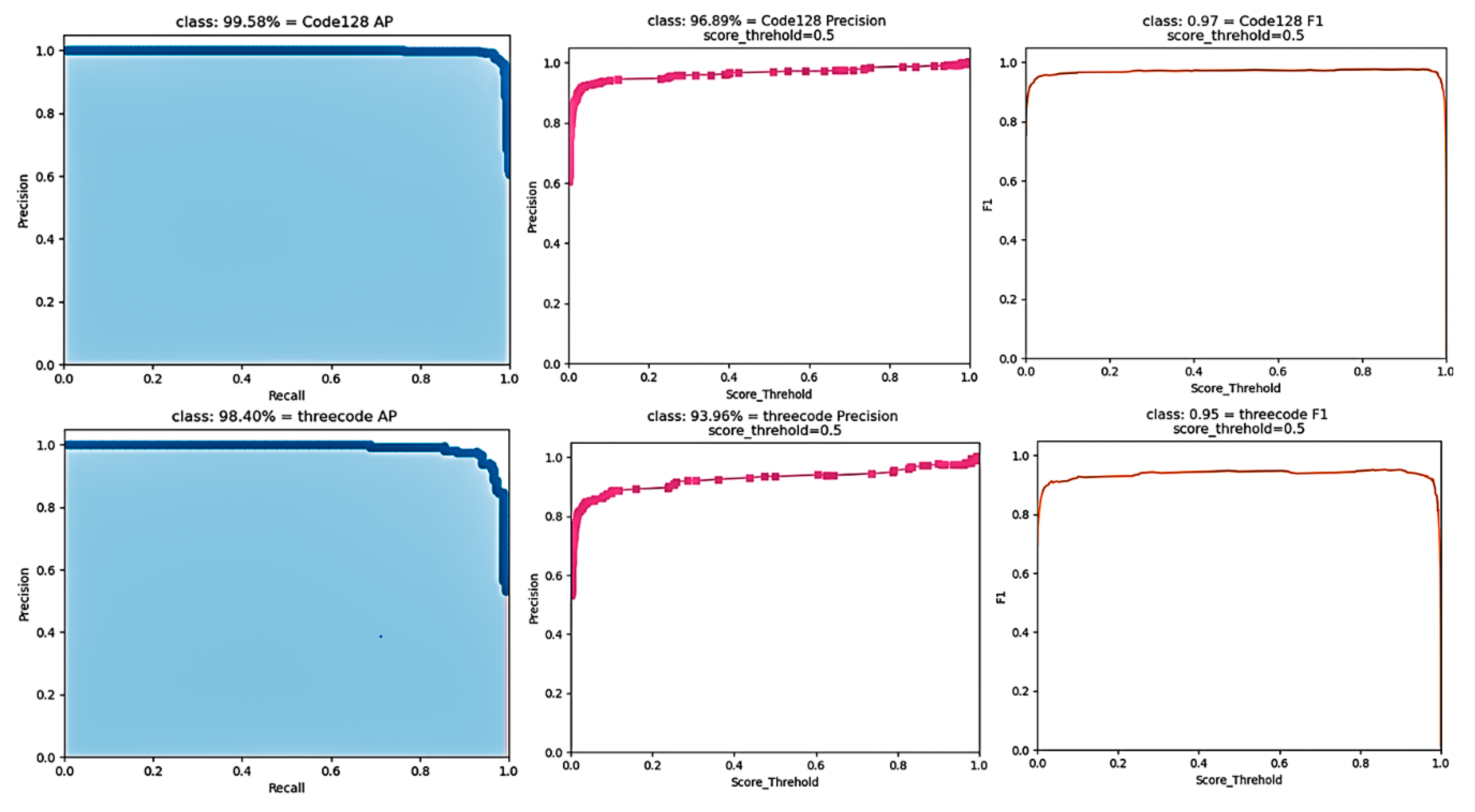
Figure 1, the images are first input into the target detection network for positioning of the two kinds of information. In enable accurate detection in complex environments, we redesigned the key positioning network, which was optimized based on YOLOv4, and ensured the speed and accuracy of the optimized network. The network includes the backbone feature extraction network of YOLOv4, the spatial pooling layer after adding the cross-stage module, the attention module SE, and the use of FPN structure. As a backbone feature extraction network, CSPDarKet53 can ensure accuracy and greatly reduce the number of parameters. A spatial pooling layer with inter-phase modules was used instead of the original spatial pooling layer, which helped to ensure the accuracy and reduce the number of parameters. The attention module SE was added to enhance features that improved the accuracy of detection. Replacing the original structure with an FPN structure effectively reduces the network complexity and parameter number, and the optimized positioning network is much better than the YOLOv4 network. The next step is the recognition of target information. First, the rectangular boxes containing barcode information and three-segment code information are captured, and the pictures containing barcode information are decoded and output by the ZBAR algorithm. The characters of the three-segment code information box are recognized by Tesseract-OCR text recognition. The string information of the two is written into the text so that the express sorting information can be accurately obtained from the database. Our main contributions are as follows.
The rest of this article is as follows.
Section 2 describes the target detection network used by the method.
Section 3 mainly describes the recognition method of target information. In
Section 4, experiments are described to verify the reliability of the detection model and the recognition algorithm, and the whole method is evaluated to verify the feasibility of the proposed method.
Section 5 provides the conclusion.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}