
Workshop Safety Helmet Wearing Detection Model Based on SCM-YOLO


Abstract
:1. Introduction
2. YOLOv4-Tiny Object Detection Algorithm Model
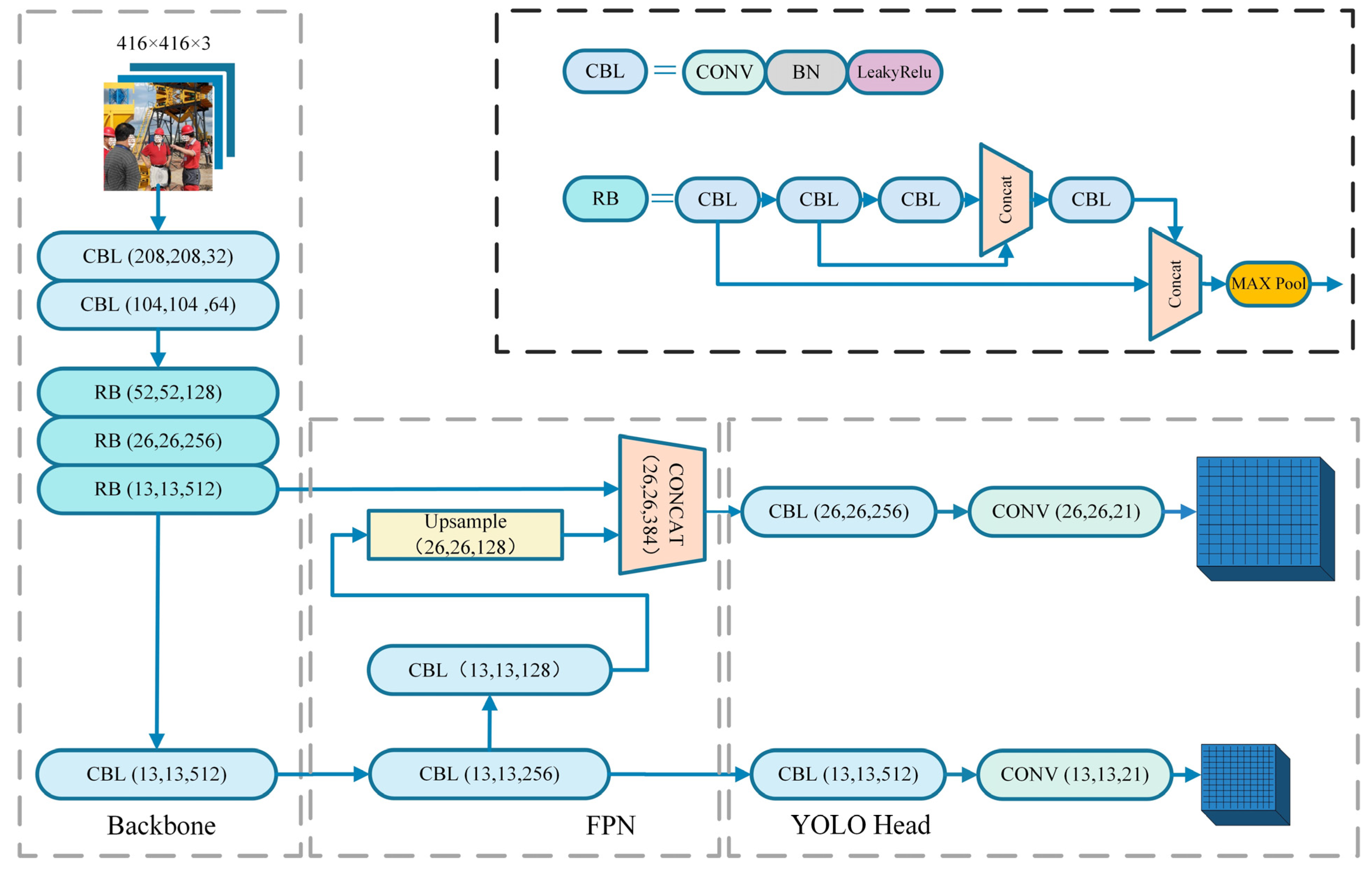
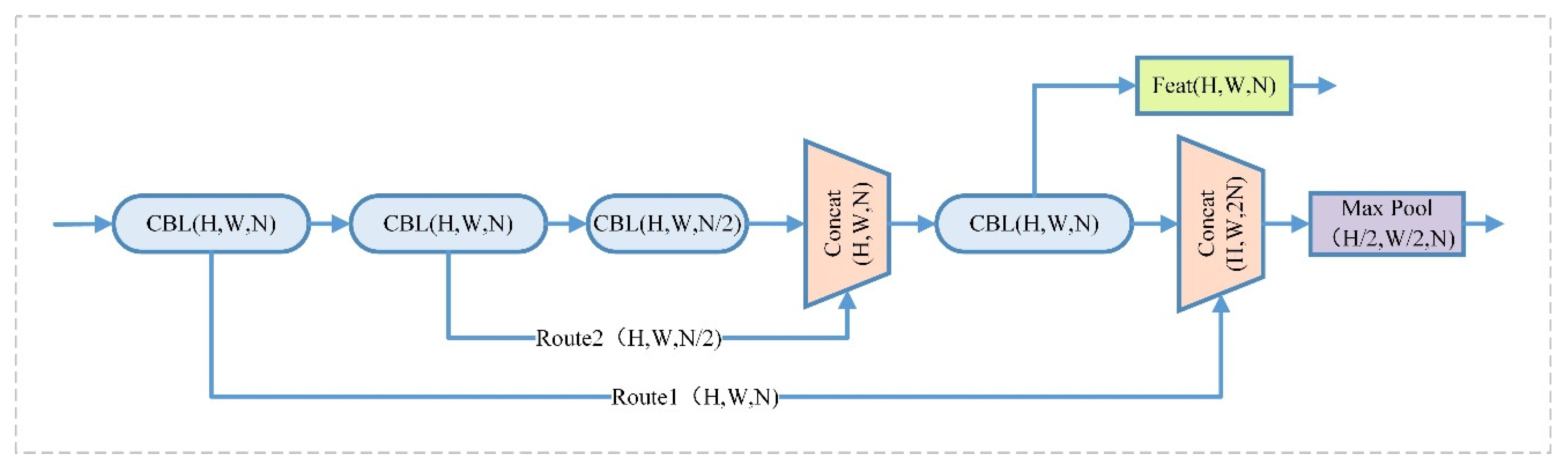
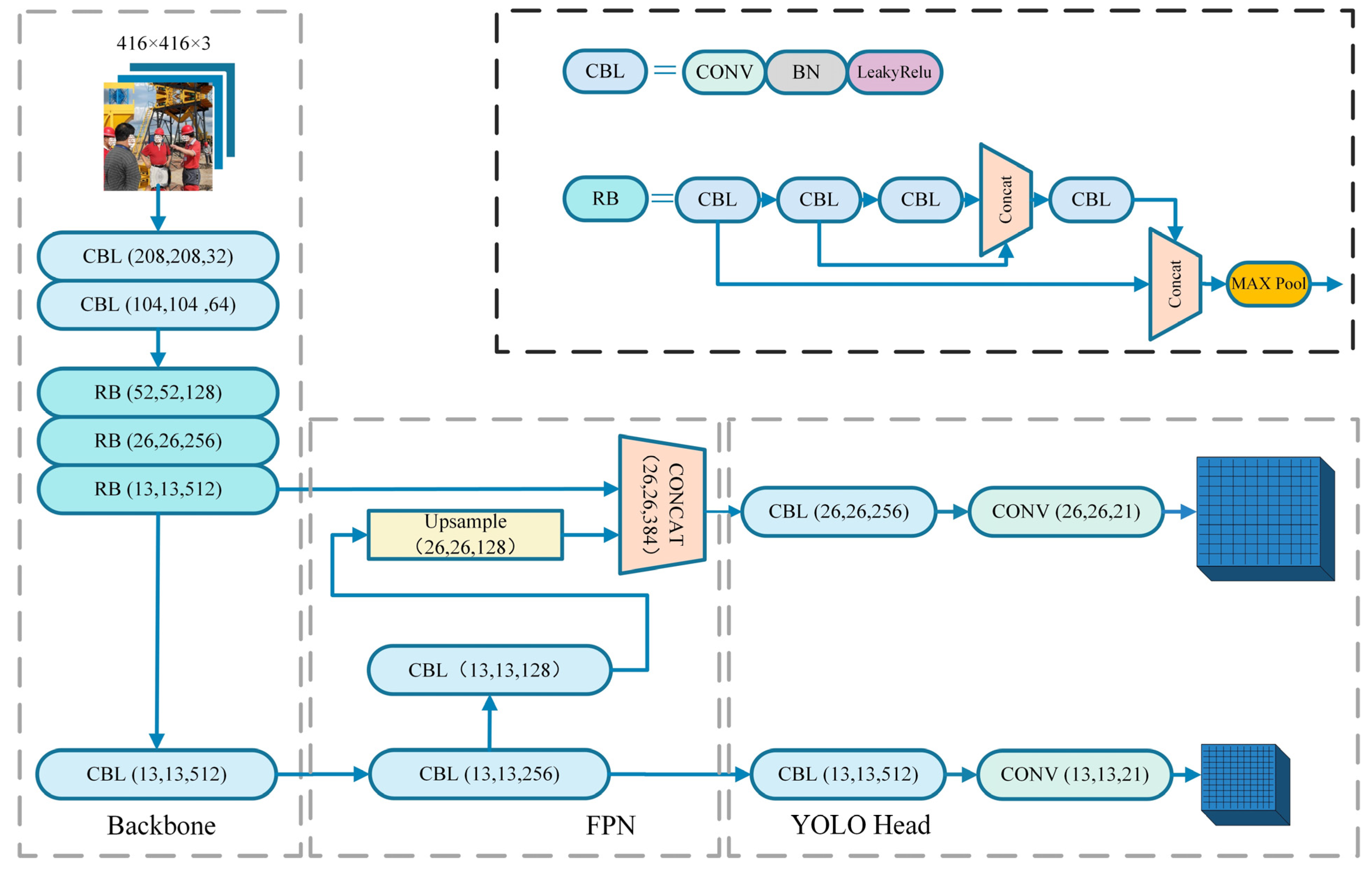
2.1. YOLOv4-Tiny Model Structure
2.2. Problems of YOLOv4-Tiny Algorithm
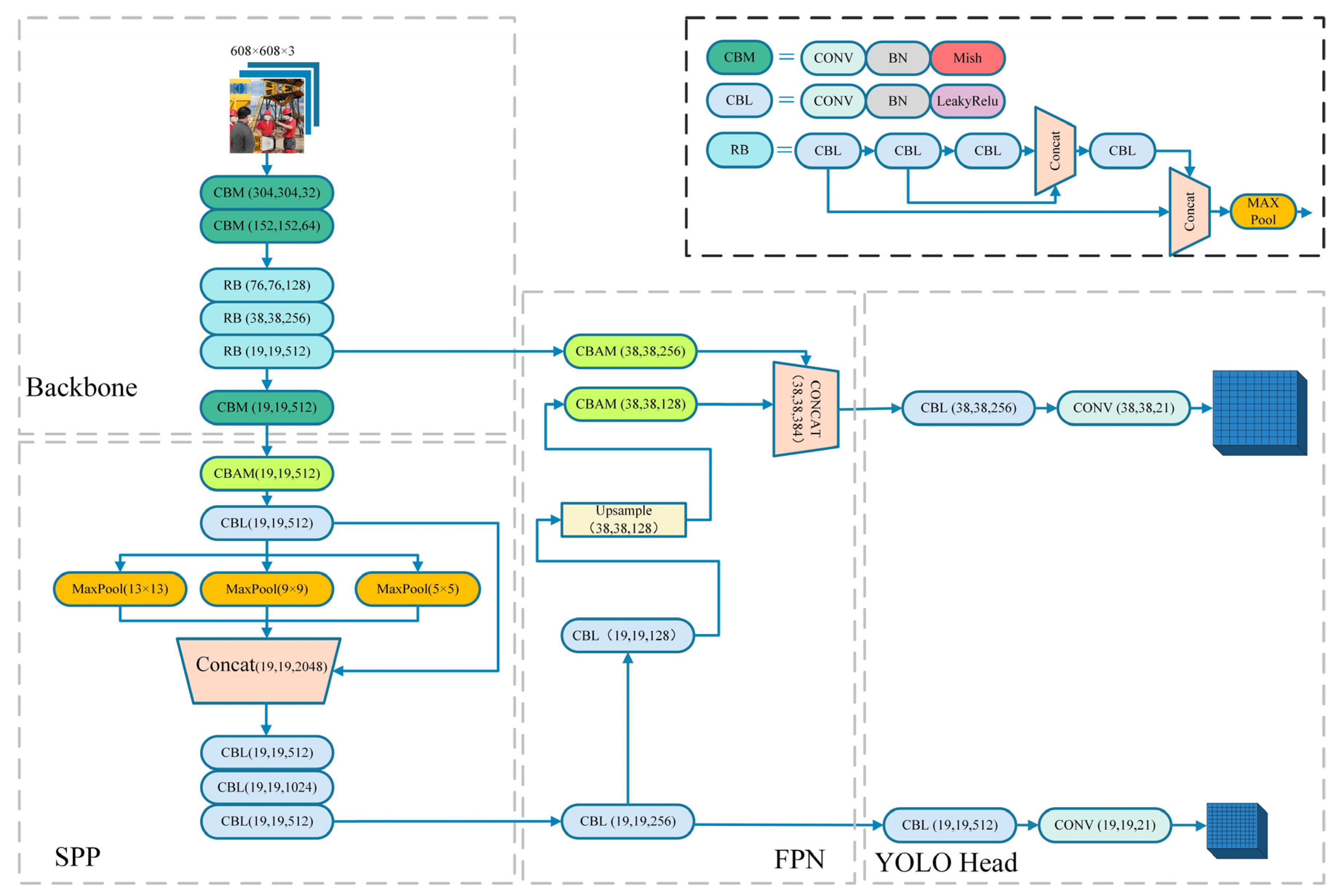
3. SCM-YOLO Detection Model Based on Improved YOLOv4-Tiny
3.1. SCM-YOLO Model Structure
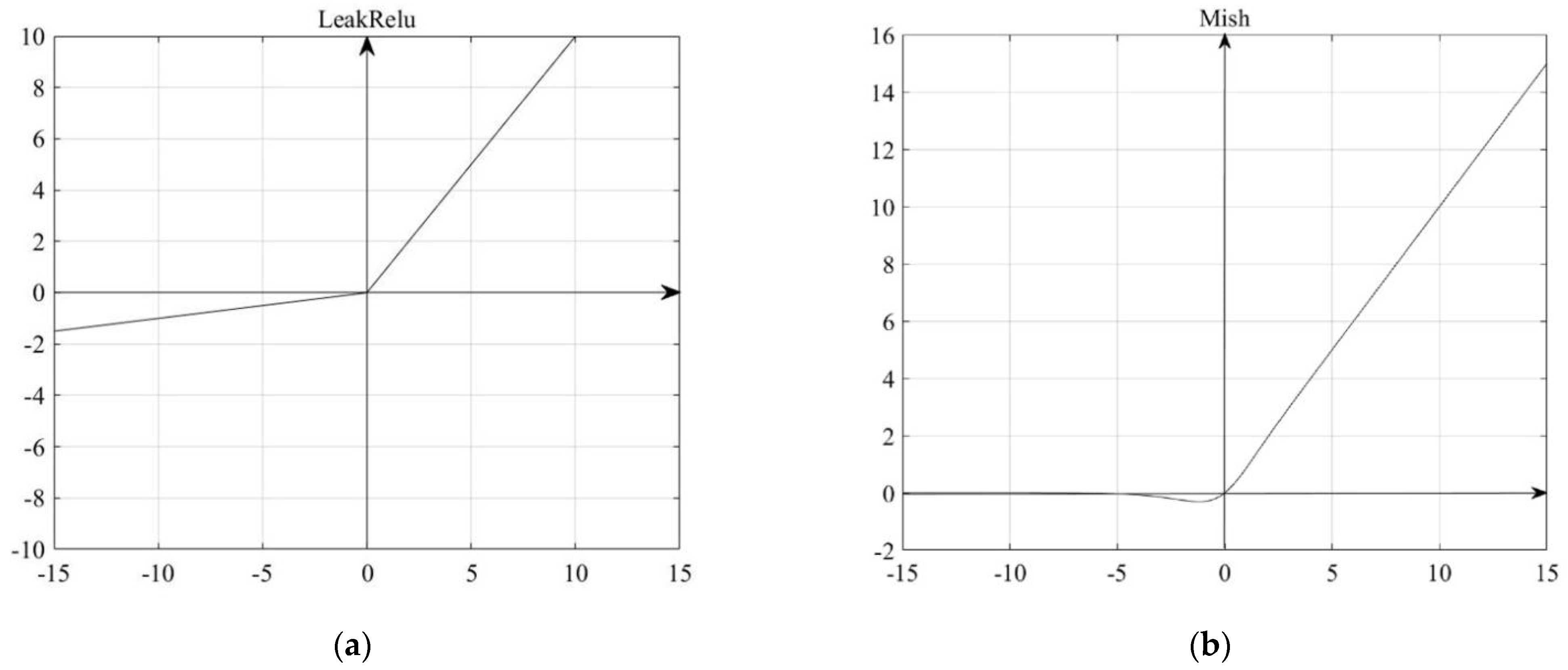
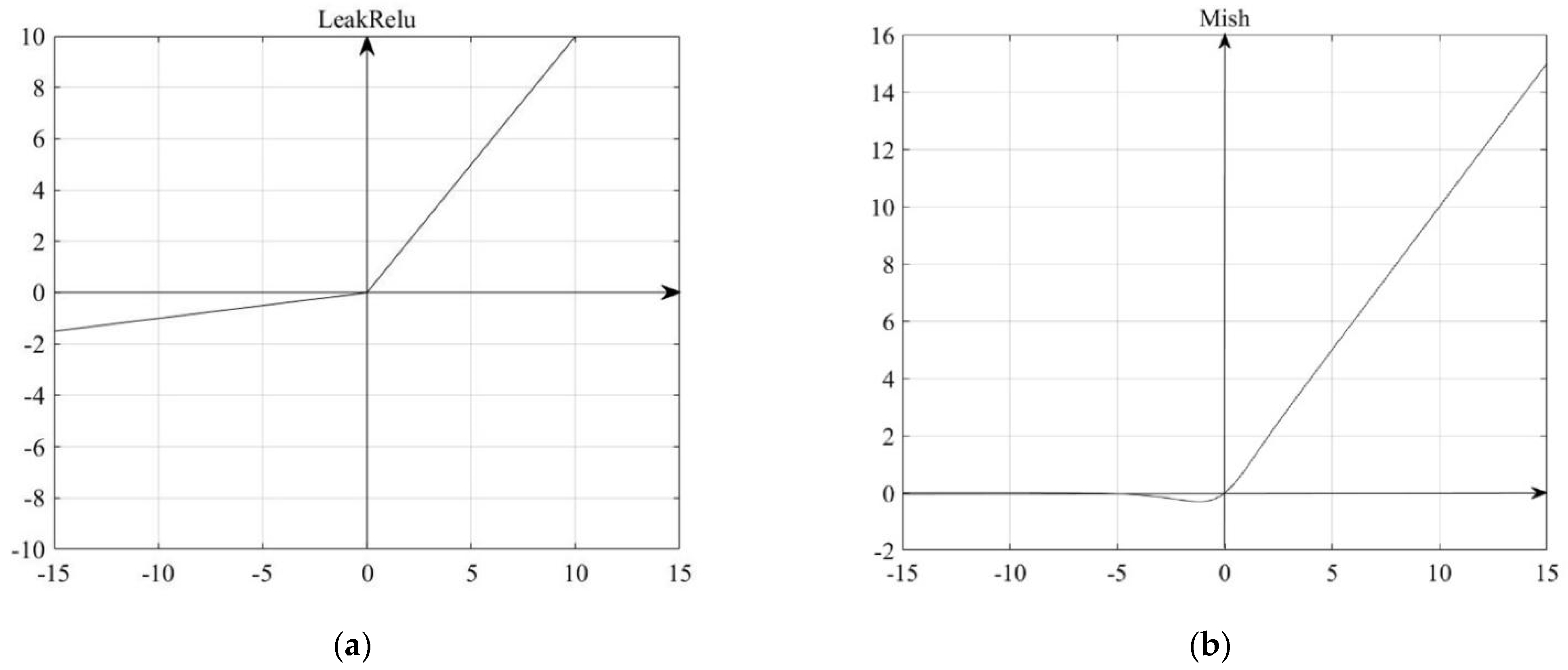
3.2. Improvement of Backbone Network Activation Function
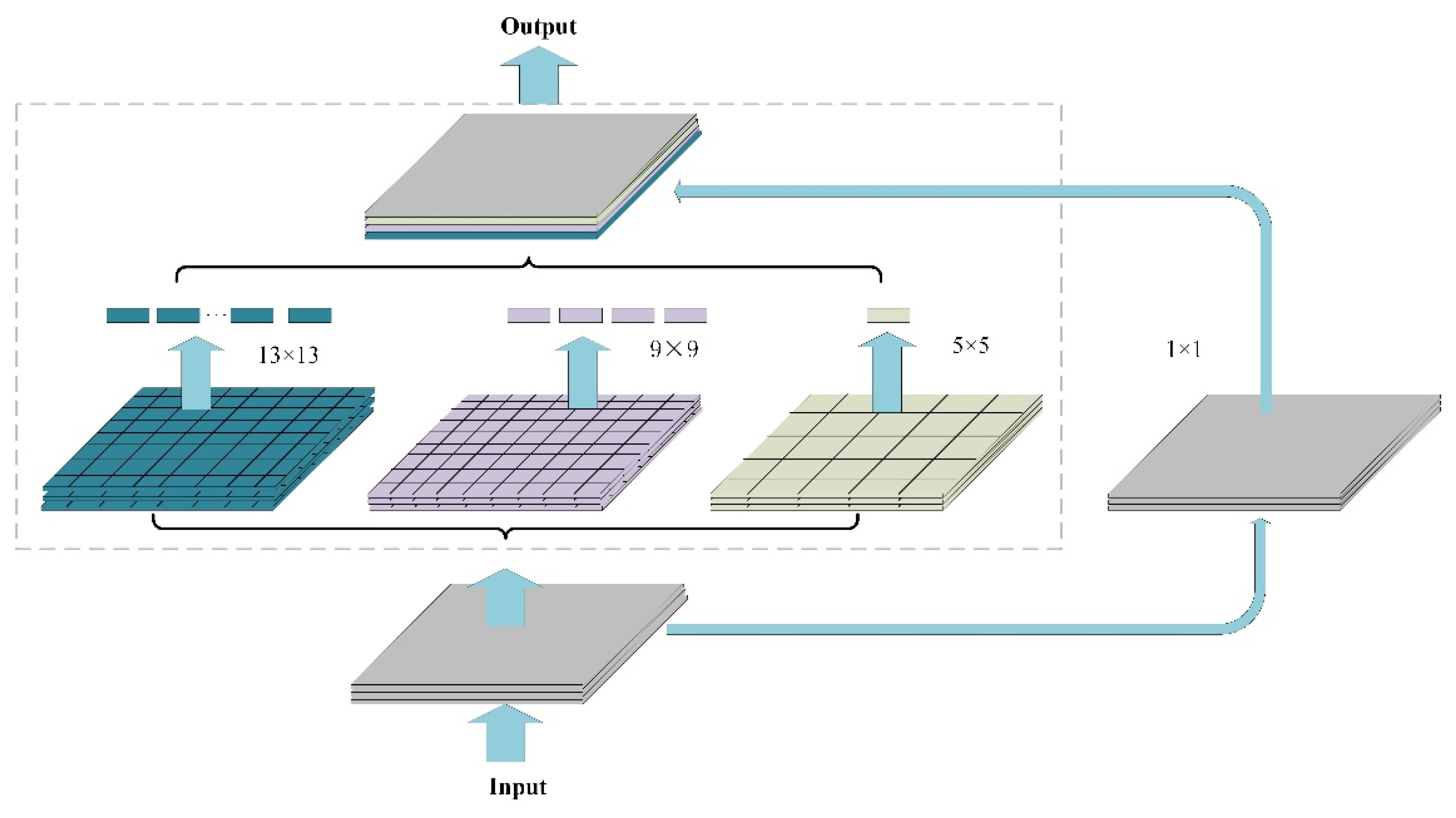
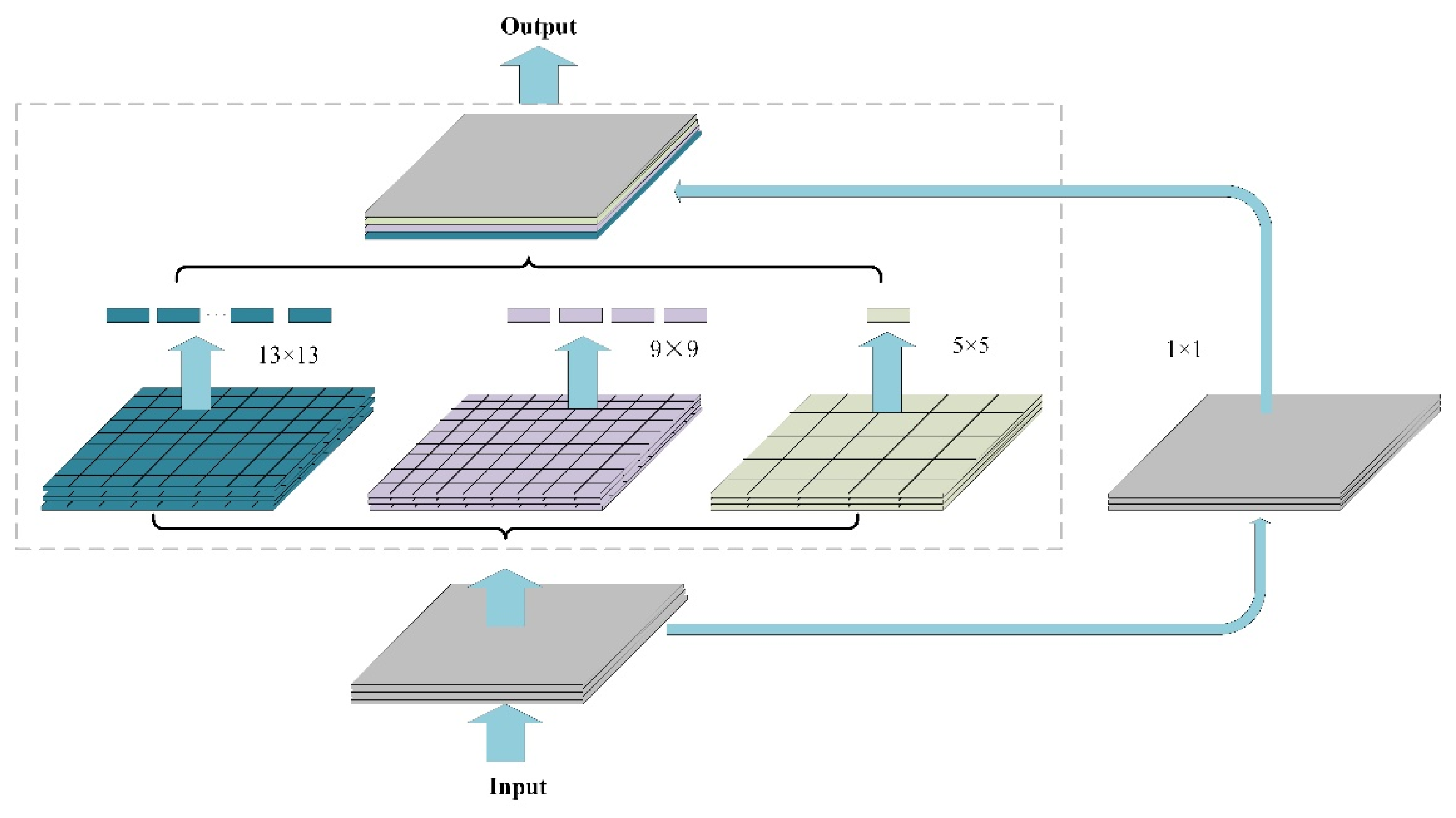
3.3. SPP-Spatial Pyramid Pooling Structure
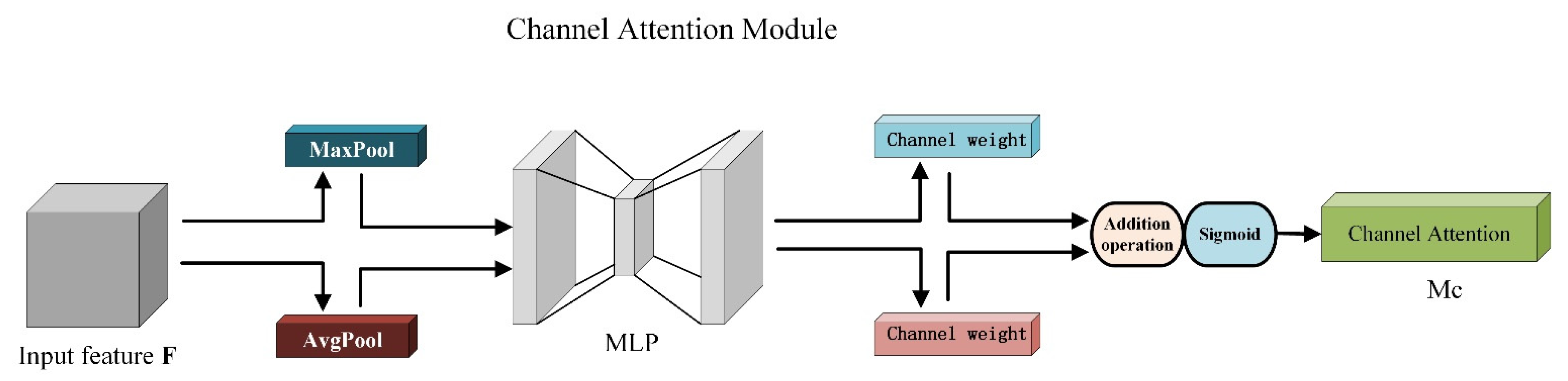
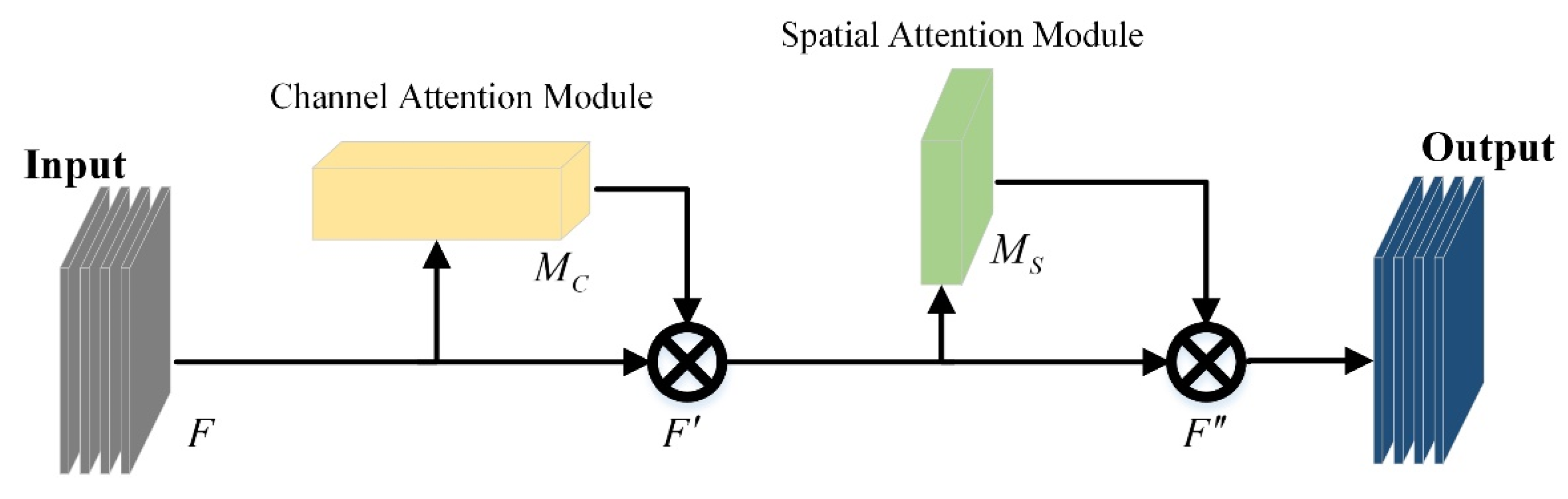
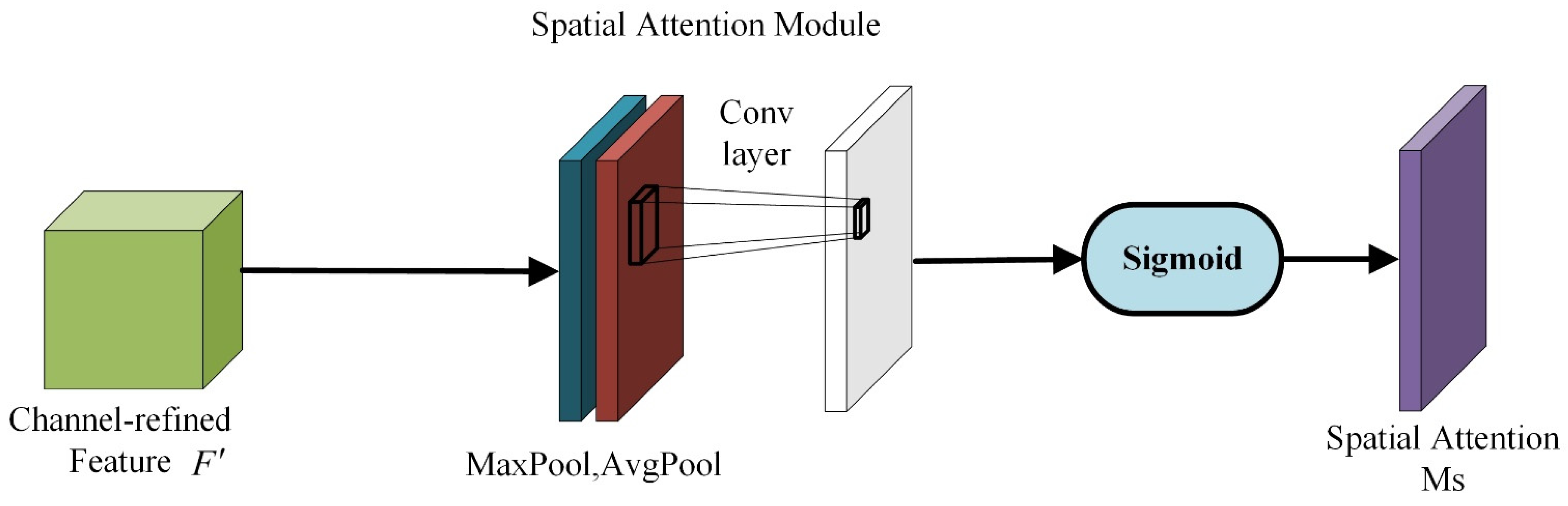
3.4. CBAM-Convolutional Block Attention Module
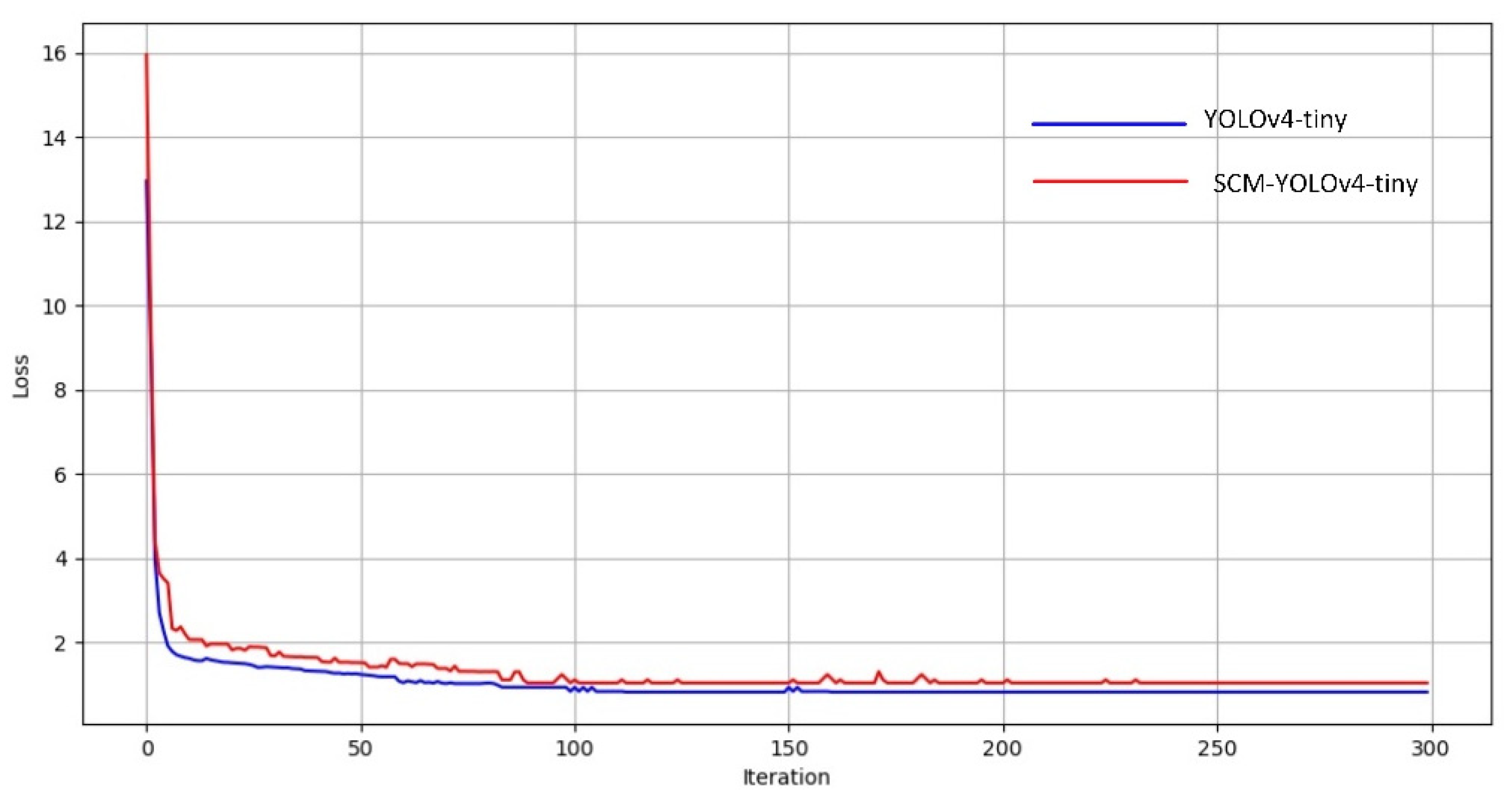
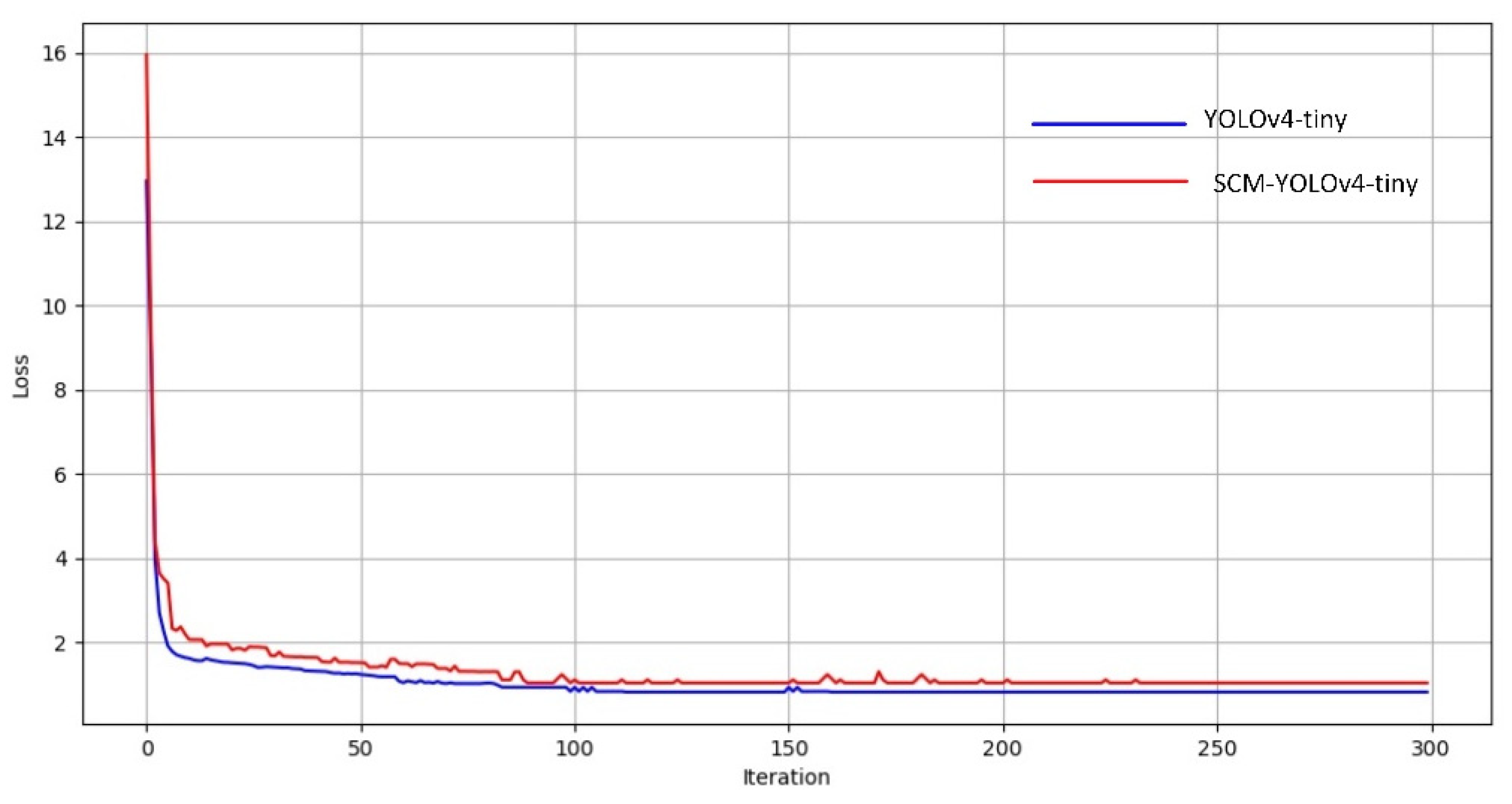
3.5. Improvement of Model Training Process
3.5.1. Label Smoothing Regularization
3.5.2. Mosaic Data Enhancement
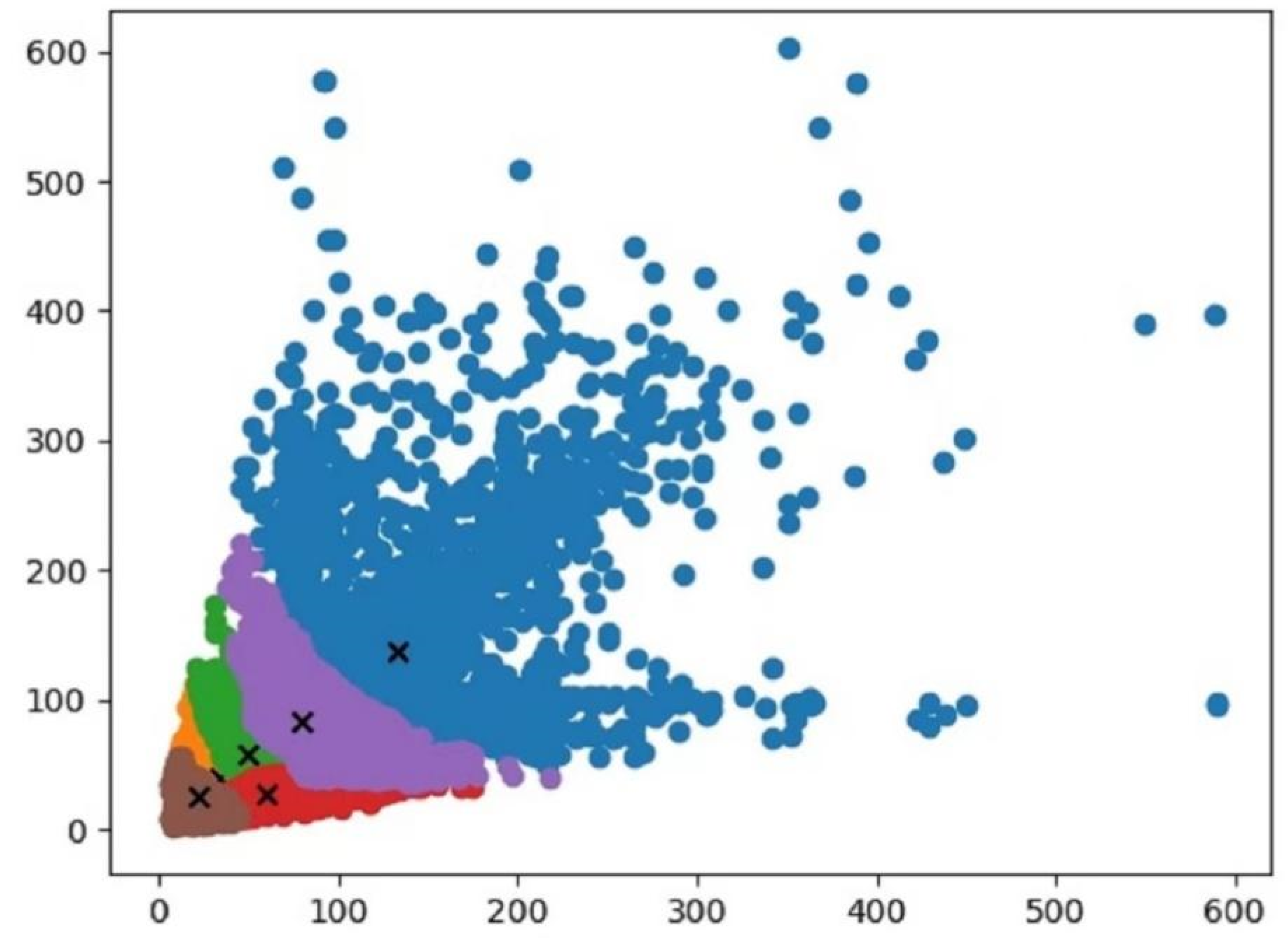
3.5.3. K-Means++ Clustering Algorithm
- (1)
- Randomly select a point from the set of input data points as the initial cluster center.
- (2)
- For each point x in the dataset, calculate its distance D(x) from the nearest cluster center.
- (3)
- Select the second cluster center according to the principle that the larger the point distance D(x) is, the greater the probability of being selected as the cluster center.
- (4)
- Repeat (2) and (3) until the k cluster centers are selected.
- (5)
- Use the above initial cluster centers to perform the standard K-Means algorithm.
4. Experimental Results and Discussion
4.1. Experimental Environment Configuration and Training Parameter Settings
4.2. Dataset
4.3. Comparative Experiment and Analysis of Results
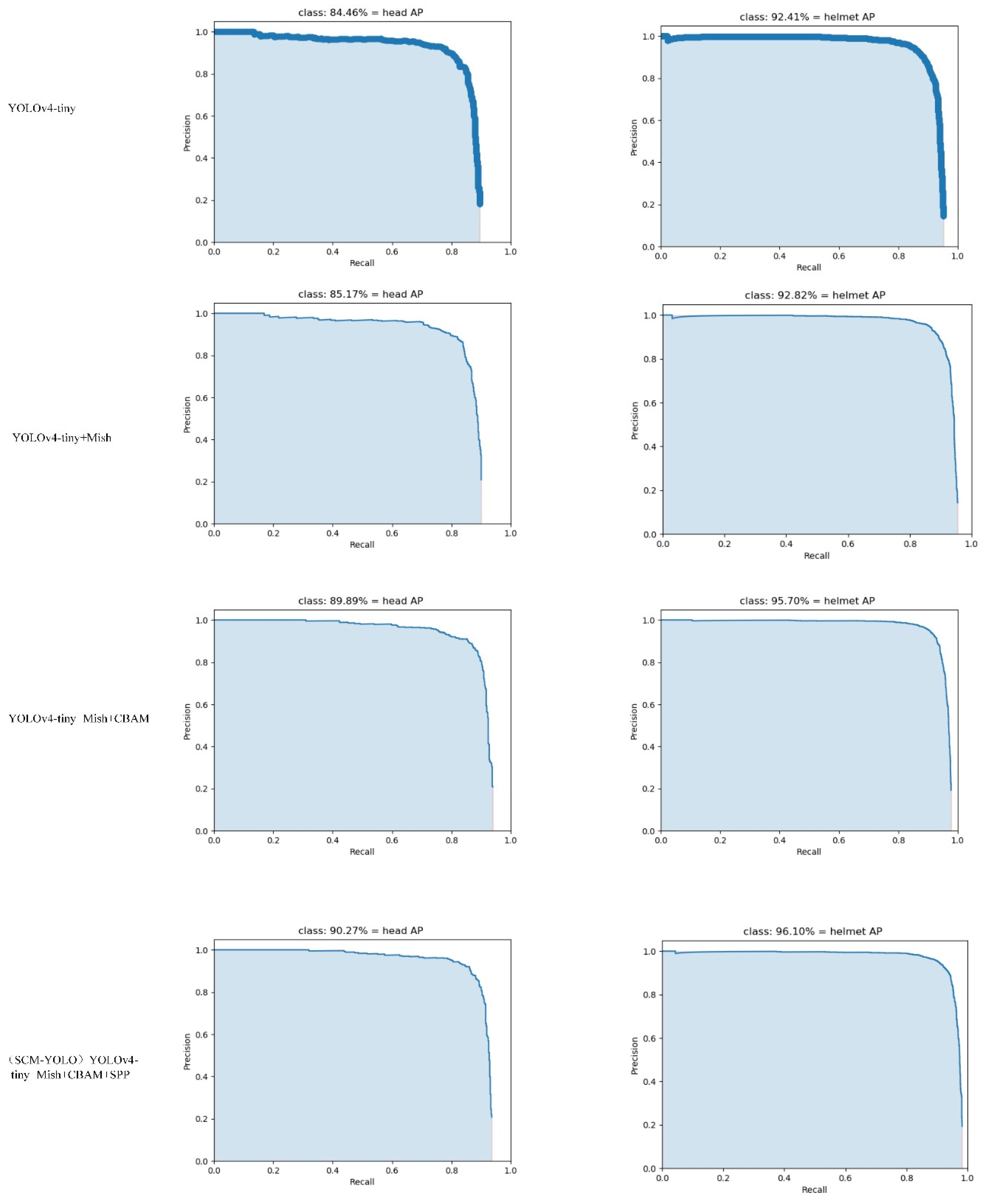
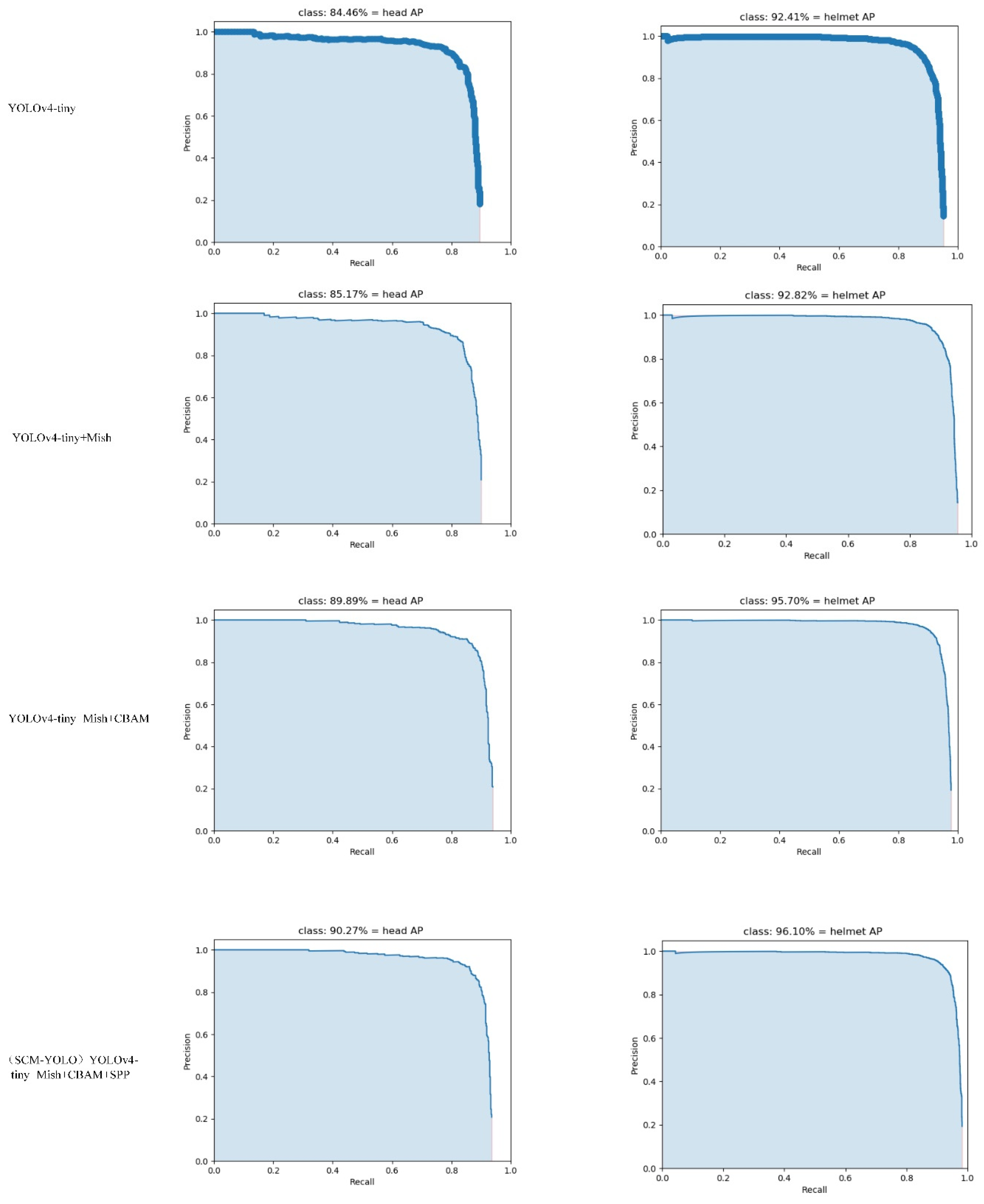
4.4. Ablation Experiment and Analysis of Results
4.5. CBAM Visualization Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep reinforcement learning in computer vision: A comprehensive survey. Artif. Intell. Rev. 2021, 55, 2733–2819. [Google Scholar] [CrossRef]
- Campero-Jurado, I.; Márquez-Sánchez, S.; Quintanar-Gómez, J.; Rodríguez, S.; Corchado, J.M. Smart helmet 5.0 for industrial internet of things using artificial intelligence. Sensors 2020, 20, 6241. [Google Scholar] [CrossRef] [PubMed]
- Otgonbold, M.-E.; Gochoo, M.; Alnajjar, F.; Ali, L.; Tan, T.-H.; Hsieh, J.-W.; Chen, P.-Y. SHEL5K: An extended dataset and benchmarking for safety helmet detection. Sensors 2022, 22, 2315. [Google Scholar] [CrossRef] [PubMed]
- Yue, S.; Zhang, Q.; Shao, D.; Fan, Y.; Bai, J. Safety helmet wearing status detection based on improved boosted random ferns. Multimed. Tools Appl. 2022, 81, 16783–16796. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Shi, L.; Li, N.; Zhuang, L.; Xu, S. Automatic detection of safety helmet wearing based on head region location. IET Image Process. 2021, 15, 2441–2453. [Google Scholar] [CrossRef]
- Fan, Z.; Peng, C.; Dai, L.; Cao, F.; Qi, J.; Hua, W. A deep learning-based ensemble method for helmet-wearing detection. PeerJ Comput. Sci. 2020, 6, e311. [Google Scholar] [CrossRef]
- Cheng, R.; He, X.; Zheng, Z.; Wang, Z. Multi-scale safety helmet detection based on SAS-YOLOv3-tiny. Appl. Sci. 2021, 11, 3652. [Google Scholar] [CrossRef]
- Nan, Y.; Jian-Hua, Q.; Zhen, W.; Hong-Chang, W. Safety Helmet Detection Dynamic Model Based on the Critical Area Attention Mechanism. In Proceedings of the 2022 7th Asia Conference on Power and Electrical Engineering (ACPEE), Hangzhou, China, 15–17 April 2022; pp. 1296–1303. [Google Scholar]
- Min-xin, Z.; Fang-Zhou, Z.; Sheng-Rong, G. Helmet wearing detection method based on new feature fusion. Comput. Eng. Des. 2021, 42, 3181–3187. [Google Scholar]
- Ti-gang, X.; Le-Cai, C.; Ke-Yuan, T. Improved YOLOv3 Helmet Wearing Detection Method. J. Comput. Eng. Appl. Eng. 2021, 57, 216–223. [Google Scholar]
- Ben-yang, D.; Xiao-chun, L.; Miao, Y. Safety helmet detection method based on YOLO v4. In Proceedings of the 2020 16th International Conference on Computational Intelligence and Security (CIS), Guangxi, China, 27–30 November 2020; pp. 155–158. [Google Scholar]
- Zeng, L.; Duan, X.; Pan, Y.; Deng, M. Research on the algorithm of helmet-wearing detection based on the optimized yolov4. Vis. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Gao, S.; Ruan, Y.; Wang, Y.; Xu, W.; Zheng, M. Safety Helmet Detection based on YOLOV4-M. In Proceedings of the 2022 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 24–26 June 2022; pp. 179–181. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, pre print. arXiv:2004.10934 2020. [Google Scholar]
- Lin, Y.; Cai, R.; Lin, P.; Cheng, S. A detection approach for bundled log ends using K-median clustering and improved YOLOv4-Tiny network. Comput. Electron. Agric. 2022, 194, 106700. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. European conference on computer vision. In SSD: Single Shot Multibox Detector; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Zhang, F.; Wang, X. Object tracking in siamese network with attention mechanism and Mish function. Acad. J. Comput. Inf. Sci. 2021, 4, 75–81. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Zhou, Z.-H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Cui, H.; Pan, H.; Zhang, K. SCU-Net++: A Nested U-Net Based on Sharpening Filter and Channel Attention Mechanism. Wirel. Commun. Mob. Comput. 2022, 2022, 2848365. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Lasloum, T.; Alhichri, H.; Bazi, Y.; Alajlan, N. SSDAN: Multi-source semi-supervised domain adaptation network for remote sensing scene classification. Remote Sens. 2021, 13, 3861. [Google Scholar] [CrossRef]
- Ainam, J.-P.; Qin, K.; Liu, G.; Luo, G. Sparse label smoothing regularization for person re-identification. IEEE Access 2019, 7, 27899–27910. [Google Scholar] [CrossRef]
- Wu, J.; Shi, L.; Yang, L.; Niu, X.; Li, Y.; Cui, X.; Tsai, S.-B.; Zhang, Y. User Value Identification Based on Improved RFM Model and-Means++ Algorithm for Complex Data Analysis. Wirel. Commun. Mob. Comput. 2021, 2021, 9982484. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | FPS/s−1 | AP/% | mAP/% | |
|---|---|---|---|---|
| Head | Helmet | |||
| YOLOv3 | 8.5 | 92.3% | 92.7% | 92.5% |
| YOLOv4 | 8.1 | 95.1% | 97.5% | 96.3% |
| YOLOv3-tiny | 19.4 | 76.2% | 83.6% | 79.9% |
| YOLOv4-tiny | 24.1 | 84.4% | 92.4% | 88.4% |
| YOLOv5 | 8.4 | 96.1% | 97.3% | 96.7% |
| SCM-YOLO | 22.9 | 90.2% | 96.1% | 93.1% |
| Model | AP/% | mAP/% | |
|---|---|---|---|
| Head | Helmet | ||
| YOLOv4-tiny | 84.46% | 92.41% | 88.43% |
| YOLOv4-tiny+Mish | 85.17% | 92.82% | 88.99% |
| YOLOv4-tiny+Mish+CBAM | 89.89% | 95.70% | 92.79% |
| (SCM-YOLO) YOLOv4-tiny+Mish+CBAM+SPP | 90.27% | 96.10% | 93.19% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, B.; Sun, C.-F.; Fang, S.-Q.; Zhao, Y.-H.; Su, S. Workshop Safety Helmet Wearing Detection Model Based on SCM-YOLO. Sensors 2022, 22, 6702. https://doi.org/10.3390/s22176702
Zhang B, Sun C-F, Fang S-Q, Zhao Y-H, Su S. Workshop Safety Helmet Wearing Detection Model Based on SCM-YOLO. Sensors. 2022; 22(17):6702. https://doi.org/10.3390/s22176702
Chicago/Turabian StyleZhang, Bin, Chuan-Feng Sun, Shu-Qi Fang, Ye-Hai Zhao, and Song Su. 2022. "Workshop Safety Helmet Wearing Detection Model Based on SCM-YOLO" Sensors 22, no. 17: 6702. https://doi.org/10.3390/s22176702
APA StyleZhang, B., Sun, C.-F., Fang, S.-Q., Zhao, Y.-H., & Su, S. (2022). Workshop Safety Helmet Wearing Detection Model Based on SCM-YOLO. Sensors, 22(17), 6702. https://doi.org/10.3390/s22176702