


Model-Based 3D Contact Geometry Perception for Visual Tactile Sensor


Abstract
:1. Introduction
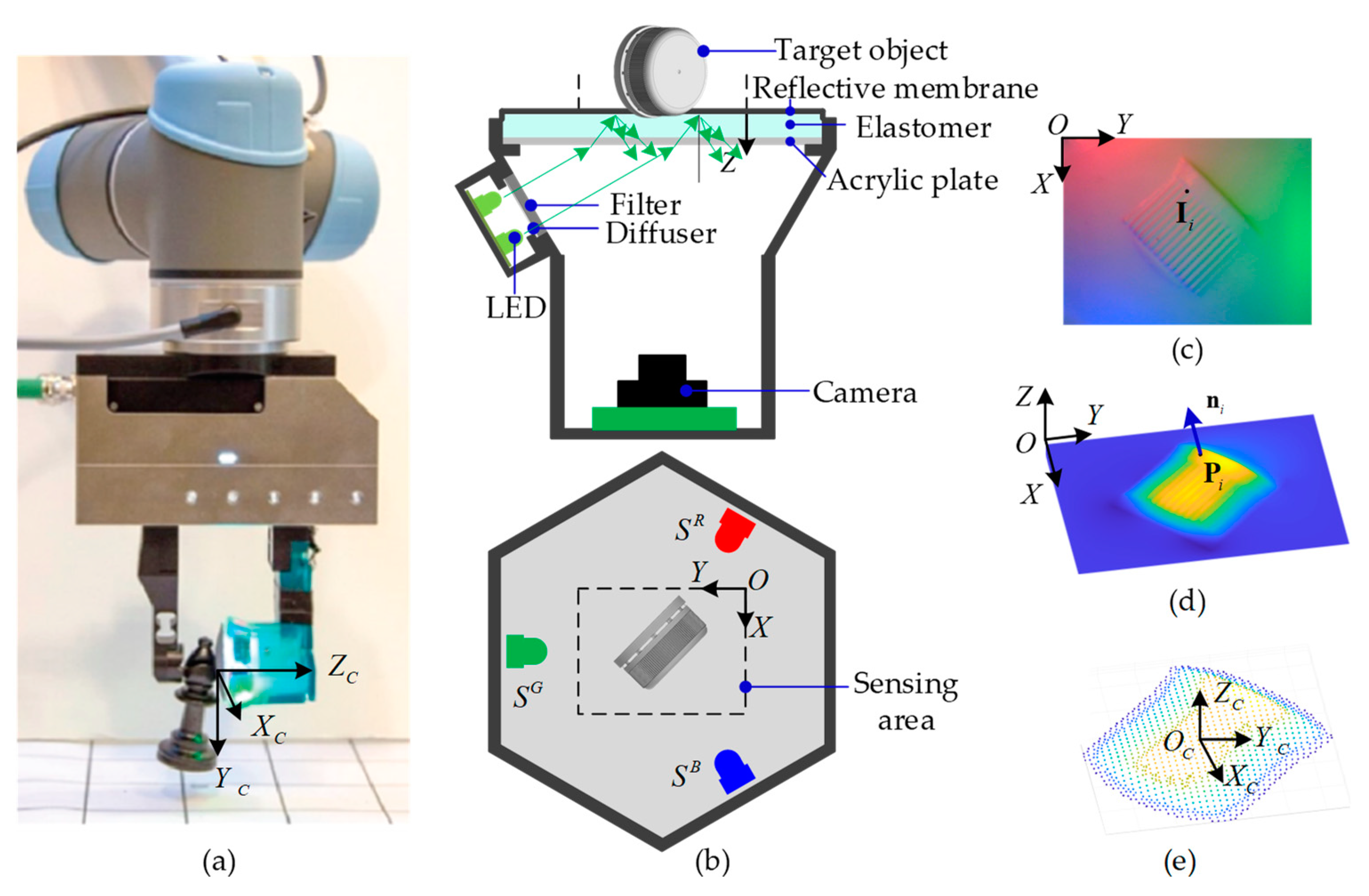
2. Three-Dimensional Geometry Perceptual Scheme
2.1. Formulation
- Subscript : pixel index;
- Superscript : color channels;
- : imaged intensity triple at the th pixel;
- : linear matrix involves the projected RGB illumination parameters at the th pixel;
- : normal direction of the contact surface at the th pixel;
- : reflective albedo of the membrane in the given color channel;
- : coordinates of the th pixel to be reconstructed, in terms of OXYZ system;
- : coordinates of an equivalent spot light source of the physical LED array in color, in terms of OXYZ system.
2.1.1. Offline Calibration of Illumination Conditions
2.1.2. Poisson-Solver Online Reconstruction
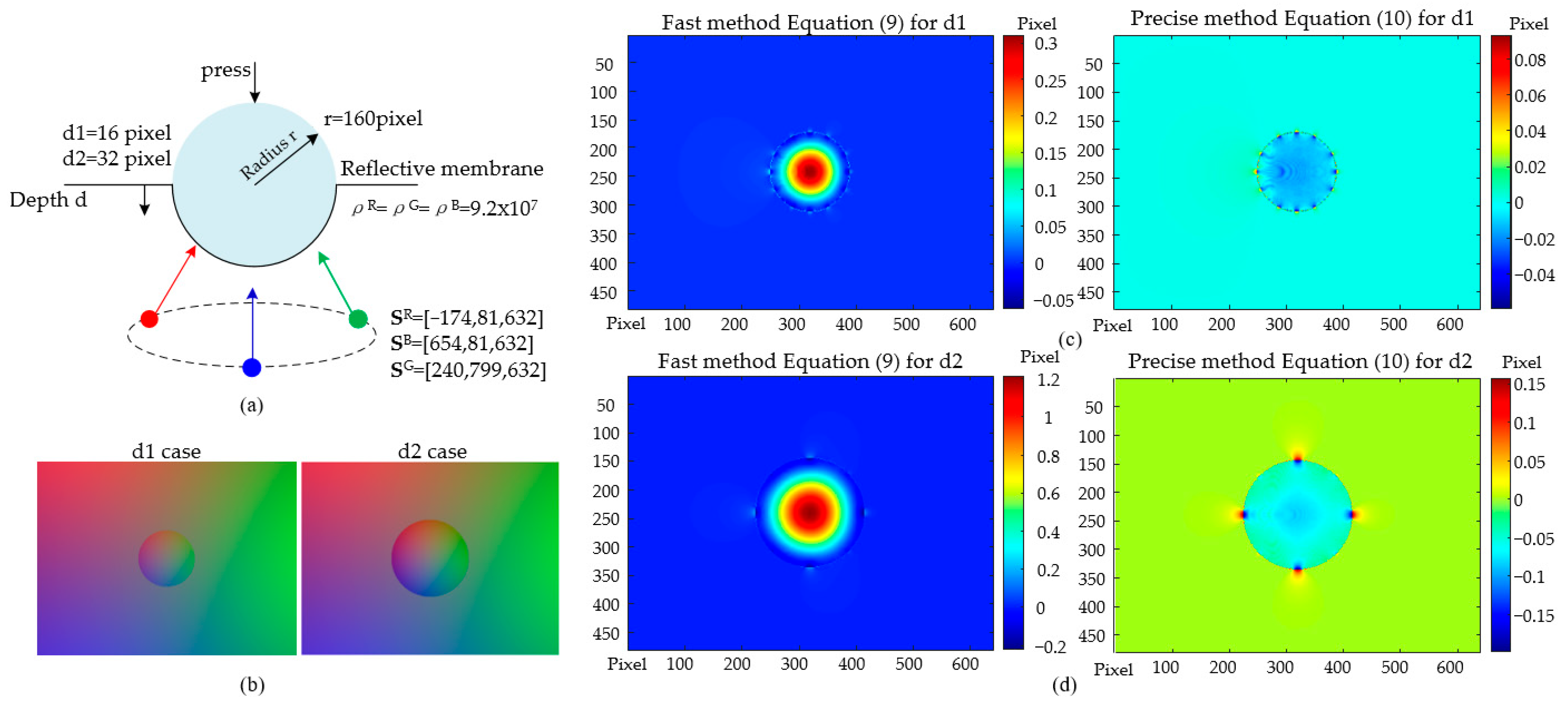
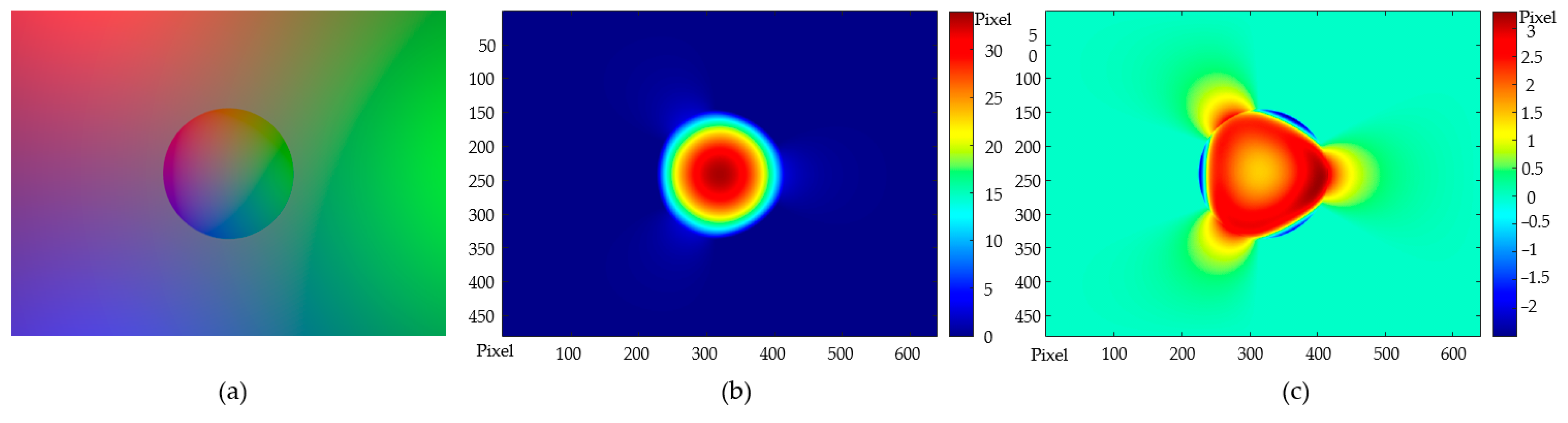
2.2. Error Analysis by Simulation
2.2.1. Error by the Zero-Piz Assumption
2.2.2. Overall Error Performance of the End-To-End Perceptual Method
3. Experimental Results and Discussion
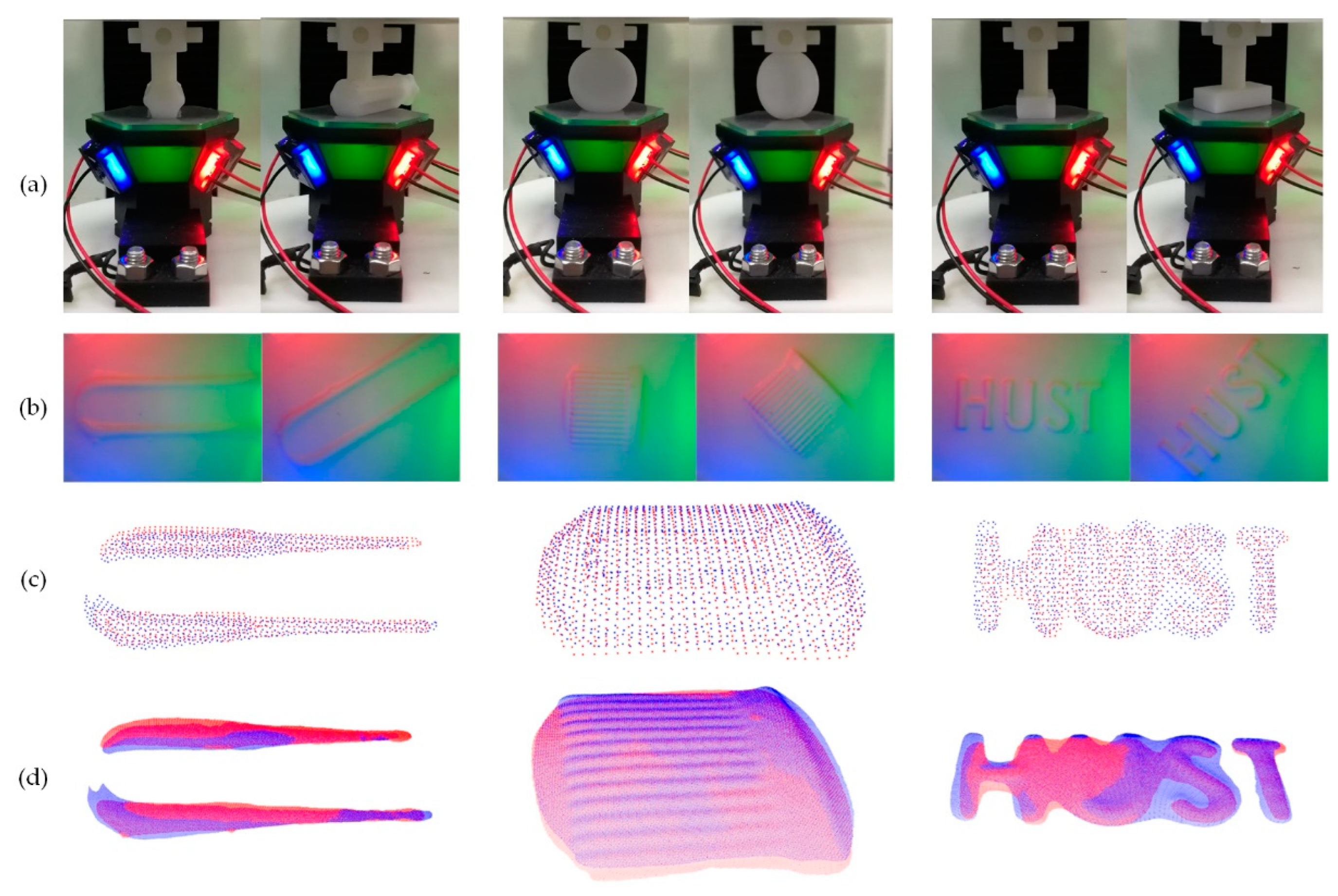
3.1. Contact Shape and Texture Perception Experiments
- Figure 7b gives an impression of a well-established lighting environment inside the VTS prototype, and of the high-contrast contact images captured depicting clearly the shape and texture. This implies the appropriateness of the components of VTS in fulfilling the hardware requisition for the 3D geometry detection. Shape and texture details, including a hole of 1.2 mm diameter on ➀, Philips-head screw with a slot of 1.4 mm width on ➁, protruding ribs of 0.5 mm thickness on ➂, and inter-slot gap of 0.3 mm between particles on ➃, are captured in detail.
- By a comparison between Figure 7c,d, and that between 7e,f, one could tell that the perceptual result by the proposed model-driven method is quite close to the that obtained by the traditional benchmark method, indicating the ability in an accurate 3D depth reconstruction of our method. The quantitative comparison in Table 2 shows that, for the given compression depth of 16~24 pixels, the reconstructed characterizing feature depth (step depth of ➀ and slot depths of ➁➂➃, by solving for the depth difference between the two blue + positions in Figure 7b) is 8.40~12.89 pixels, and the RMSE of the result by the proposed method within the contact area is in the range of 0.79~1.83 pixels, away from the result of the traditional benchmark. The results clearly indicate the capability of our method with a considerable reconstruction accuracy compared to the traditional look-up table method. However, the implementation process is much simpler, the proposed depth perceptual method is mathematically formulated with a robust depth perception precision, and it requires only one image for calibrating the sensor lighting condition, free of data-expensive calibration or learning procedures.
3.2. Pose Estimation for a Grasped Target
- In comparison with the known ground truth specified by the target design, the errors of the estimated overall relative orientation angles of cases I, II, and III, in a spatial view, were 0.6430°, 2.3461°, and 2.5936°, respectively. Additionally, the errors of translation displacement all fell within 1mm. The RMSEs of the registered point cloud against the reference one in all cases were quite restricted to a sub-millimeter level, indicating a perfect coincidence obtained by the registration process. We could tell from the errors in both orientation and translation together with the registration RMSE that the estimation of the pose of each target is fairly accurate.
- In each depth map, partial points near the edge of the contact area were removed in de-noise before building up the point cloud. That way, the number of almost-zero points was reduced in registration as far as possible for a reliability concern while trying to keep the shape reconstructed intact. For instance, the letters “HUST” in case III form a multi-connected domain in a mathematical sense. In handling this case, some points with an almost-zero depth value were treated as noise-contaminated and thus neglected in building up the point cloud, making the left portion of the letter “H” shortened a little bit.
- The time consumption for each registration round was about 6~8 s in our experiments, as the number of points in the cloud was relatively large at around 103. Some advanced procedures such as discrete sampling could be expected in our future work in order to speed up the registration.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shimonomura, K. Tactile image sensors employing camera: A review. Sensors 2019, 19, 3933. [Google Scholar] [CrossRef] [PubMed]
- Abad, A.C.; Ranasinghe, A. Visuotactile sensors with emphasis on GelSight sensor: A review. IEEE Sens. J. 2020, 20, 7628–7638. [Google Scholar] [CrossRef]
- Shah, U.H.; Muthusamy, R.; Gan, D.; Zweiri, Y.; Seneviratne, L. On the design and development of vision-based tactile sensors. J. Intell. Rob. Syst. Theor. Appl. 2021, 102, 82. [Google Scholar] [CrossRef]
- Li, R.; Adelson, E.H. Sensing and recognizing surface textures using a GelSight sensor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Fang, B.; Long, X.; Sun, F.; Liu, H.; Zhang, S.; Fang, C. Tactile-based fabric defect detection using convolutional neural network with attention mechanism. IEEE Trans. Instrum. Meas. 2022, 71, 501309. [Google Scholar] [CrossRef]
- Yuan, W.; Zhu, C.; Owens, A.; Srinivasan, M.A.; Adelson, E.H. Shape-independent hardness estimation using deep learning and a GelSight tactile sensor. In Proceedings of the 2017 International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Zhang, Y.; Kan, Z.; Tse, Y.A.; Yang, Y.; Wang, M.Y. FingerVision tactile sensor design and slip detection using convolutional LSTM network. arXiv 2018, arXiv:1810.02653. [Google Scholar]
- Bauza, M.; Bronars, A.; Rodriguez, A. Tac2Pose: Tactile object pose estimation from the first touch. arXiv 2022, arXiv:2204.11701. [Google Scholar]
- Johnson, M.K.; Adelson, E.H. Retrographic sensing for the measurement of surface texture and shape. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Yuan, W.; Dong, S.; Adelson, E.H. GelSight: High-resolution robot tactile sensors for estimating geometry and force. Sensors 2017, 17, 2762. [Google Scholar] [CrossRef] [PubMed]
- Taylor, I.; Dong, S.; Rodriguez, A. GelSlim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger. In Proceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Li, J.; Dong, S.; Adelson, E.H. End-to-end pixelwise surface normal estimation with convolutional neural networks and shape reconstruction using GelSight sensor. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018. [Google Scholar]
- Wang, S.; She, Y.; Romero, B.; Adelson, E.H. GelSight wedge: Measuring high-resolution 3d contact geometry with a compact robot finger. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Sodhi, P.; Kaess, M.; Mukadam, M.; Anderson, S. Patchgraph: In-hand tactile tracking with learned surface normals. In Proceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Lambeta, M.; Chou, P.W.; Tian, S.; Yang, B.; Maloon, B.; Most, V.R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; et al. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE Robot. Autom. Lett. 2020, 5, 3838–3845. [Google Scholar] [CrossRef]
- Yu, C.; Lindenroth, L.; Hu, J.; Back, J.; Abrahams, G.; Liu, H. A vision-based soft somatosensory system for distributed pressure and temperature sensing. IEEE Robot. Autom. Lett. 2020, 5, 3323–3329. [Google Scholar] [CrossRef]
- Lin, X.; Wiertlewski, M. Sensing the frictional state of a robotic skin via subtractive color mixing. IEEE Robot. Autom. Lett. 2019, 4, 2386–2392. [Google Scholar] [CrossRef]
- Du, Y.; Zhang, G.; Zhang, Y.; Wang, M.Y. High-resolution 3-dimensional contact deformation tracking for FingerVision sensor with dense random color pattern. IEEE Robot. Autom. Lett. 2021, 6, 2147–2154. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, X.; Zhou, Z.; Zeng, J.; Liu, H. An enhanced FingerVision for contact spatial surface sensing. IEEE Sens. J. 2021, 21, 16492–16502. [Google Scholar] [CrossRef]
- Sferrazza, C.; Wahlsten, A.; Trueeb, C.; D’Andrea, R. Ground truth force distribution for learning-based tactile sensing: A finite element approach. IEEE Access 2019, 7, 173438–173449. [Google Scholar] [CrossRef]
- Ambrus, R.; Guizilini, V.; Kuppuswamy, N.; Beasulieu, A.; Gaidon, A.; Alspach, A. Monocular depth estimation for soft visuotactile sensors. In Proceedings of the 2021 IEEE 4th International Conference on Soft Robotics (RoboSoft), New Haven, CT, USA, 12–16 April 2021. [Google Scholar]
- Do, W.K.; Kennedy, M., III. DenseTact: Optical tactile sensor for dense shape reconstruction. In Proceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Dong, S.; Yuan, W.; Adelson, E.H. Improved GelSight tactile sensor for measuring geometry and slip. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Fan, H.; Rao, Y.; Rigall, E.; Qi, L.; Wang, Z.; Dong, J. Near-field photometric stereo using a ring-light imaging device. Signal Process Image Commun. 2022, 102, 116605. [Google Scholar] [CrossRef]
- Wang, S.; Lambeta, M.; Chou, P.W.; Calandra, R. TACTO: A fast, flexible and open-source simulator for high-resolution vision-based tactile sensors. IEEE Robot. Autom. Lett. 2022, 7, 3930–3937. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Besl, P.J.; Mckay, H.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Material/Model/Property | Fabrication/Source |
|---|---|---|
| LED (red) | LR T64F-CBDB-1-1-20-R33-Z (wavelength = 625 nm) | ams-OSRAM AG |
| LED (green) | LT T64G-EAFB-29-N424-20-R33-Z (wavelength = 532 nm) | |
| LED (blue) | LB T64G-AACB-59-Z484-20-R33-Z (wavelength = 469 nm) | |
| Acrylic Plate | Polymethyl methacrylate | Laser cutting |
| Elastomer | Solaris A:Solaris B:Slacker = 1:1:1 | Cold mold |
| Reflective membrane | Aluminum spherules and protective silicone rubber | Manual coating |
| Camera | C310 USB web-camera (resolution = 480 × 640) | Logitech®, Switzerland |
| Filter | Transmittance = 25% | PHTODE®, China |
| Diffuser | LGT125J, a PET film (Transmittance = 66%, Haze = 95%) | Commercially available |
| Enclosure | Black resin | 3D-printed |
| Target | ➀ | ➁ | ➂ | ➃ |
|---|---|---|---|---|
| RMSE over the contact image | 0.26 | 1.28 | 1.12 | 1.24 |
| RMSE over the contact area | 0.79 | 1.83 | 1.73 | 1.17 |
| Maximum compression depth | 16 | 24 | 22 | 16 |
| Reconstructed characterizing feather depth | 8.40 | 12.89 | 9.12 | 8.68 |
| Cases | Item | Relative Orientation (°) | Translation (mm) | Registration RMSE (mm) | Time Consumption (s) |
|---|---|---|---|---|---|
| I. Tool Handle | Ground truth | (0, 0, −30) | (0, 0, 0) | 0.1540 | 6.305 |
| Estimated | (0.2423, −0.0494, −29.3991) | (0.1303, 0.532, −0.0128) | |||
| Overall Error | 0.6430° | (0.1303, 0.532, −0.0128) | |||
| II. Bottle Cap | Ground truth | (0, 0, −45) | (0, 0, 0) | 0.0619 | 8.206 |
| Estimated | (0.4354, −0.3108, −47.2867) | (−0.6321, 0.7604, 0.0158) | |||
| Overall Error | 2.3461° | (−0.6321, 0.7604, 0.0158) | |||
| III. “HUST” Stamp | Ground truth | (0, 0, −50) | (0, 0, 0) | 0.1827 | 8.024 |
| Estimated | (0.3396, 0.5836, −52.5028) | (−0.1980, 0.2841, 0.0339) | |||
| Overall Error | 2.5936° | (−0.1980, 0.2841, 0.0339) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, J.; Liu, Y.; Ma, H. Model-Based 3D Contact Geometry Perception for Visual Tactile Sensor. Sensors 2022, 22, 6470. https://doi.org/10.3390/s22176470
Ji J, Liu Y, Ma H. Model-Based 3D Contact Geometry Perception for Visual Tactile Sensor. Sensors. 2022; 22(17):6470. https://doi.org/10.3390/s22176470
Chicago/Turabian StyleJi, Jingjing, Yuting Liu, and Huan Ma. 2022. "Model-Based 3D Contact Geometry Perception for Visual Tactile Sensor" Sensors 22, no. 17: 6470. https://doi.org/10.3390/s22176470
APA StyleJi, J., Liu, Y., & Ma, H. (2022). Model-Based 3D Contact Geometry Perception for Visual Tactile Sensor. Sensors, 22(17), 6470. https://doi.org/10.3390/s22176470