

Anisotropic SpiralNet for 3D Shape Completion and Denoising


Abstract
:1. Introduction
2. Related Work
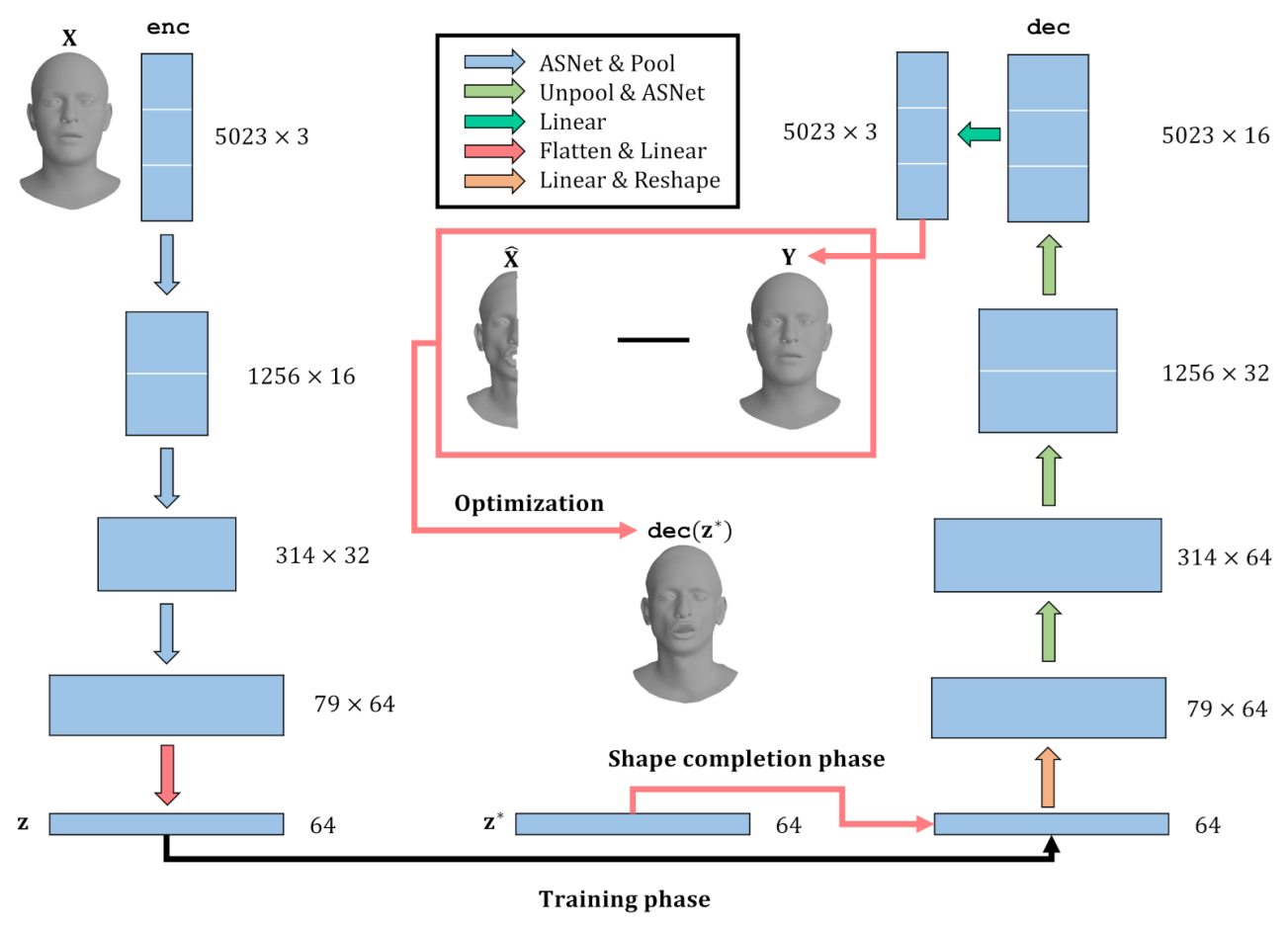
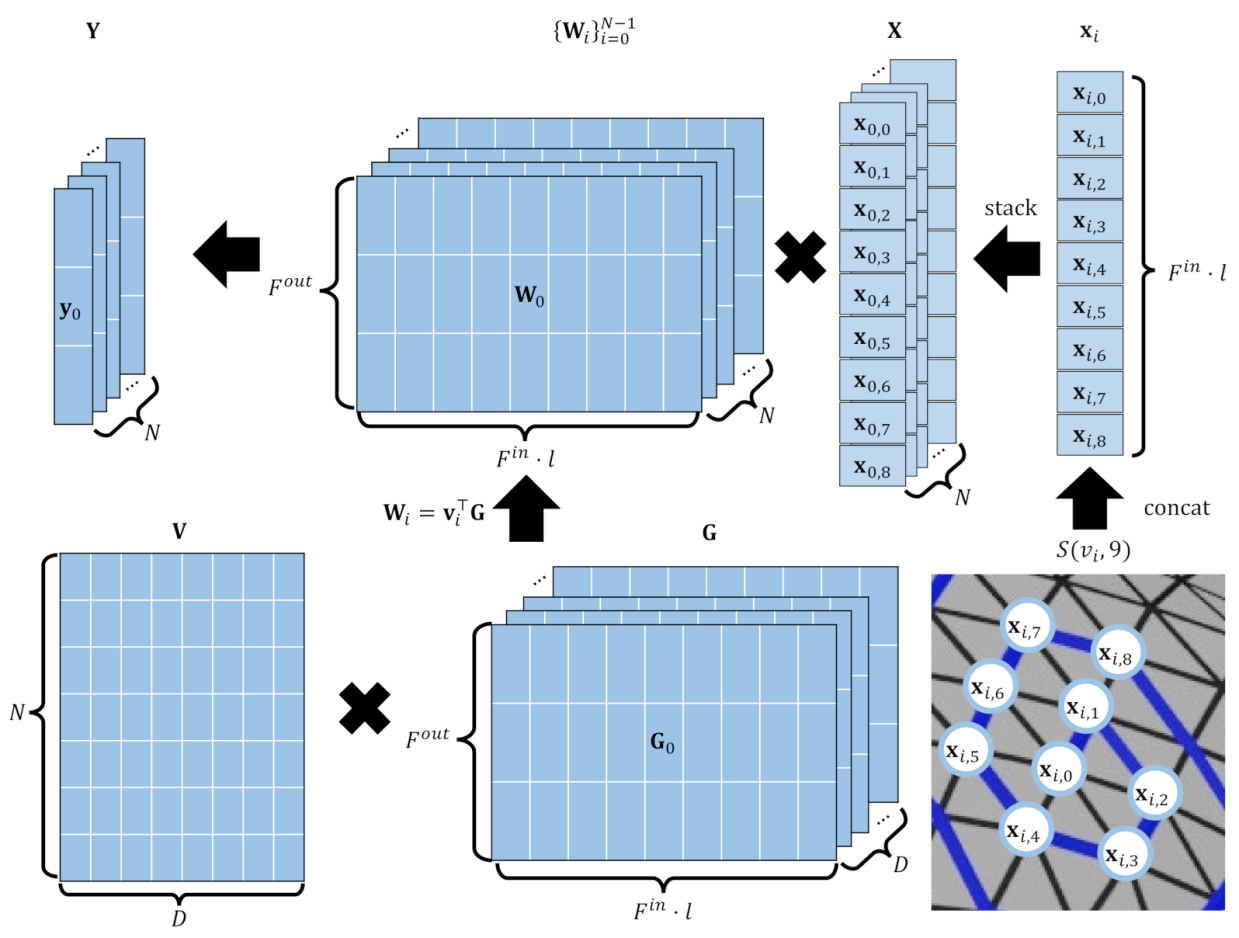
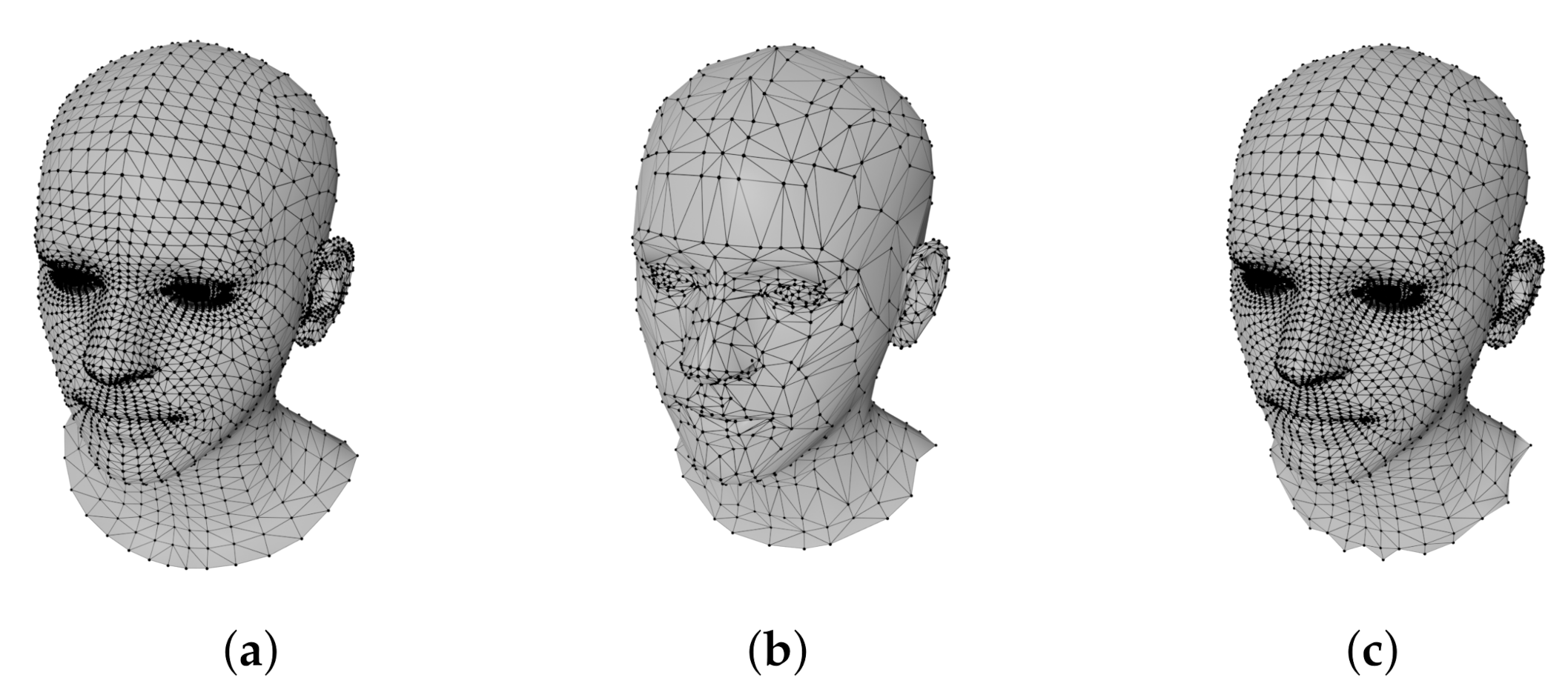
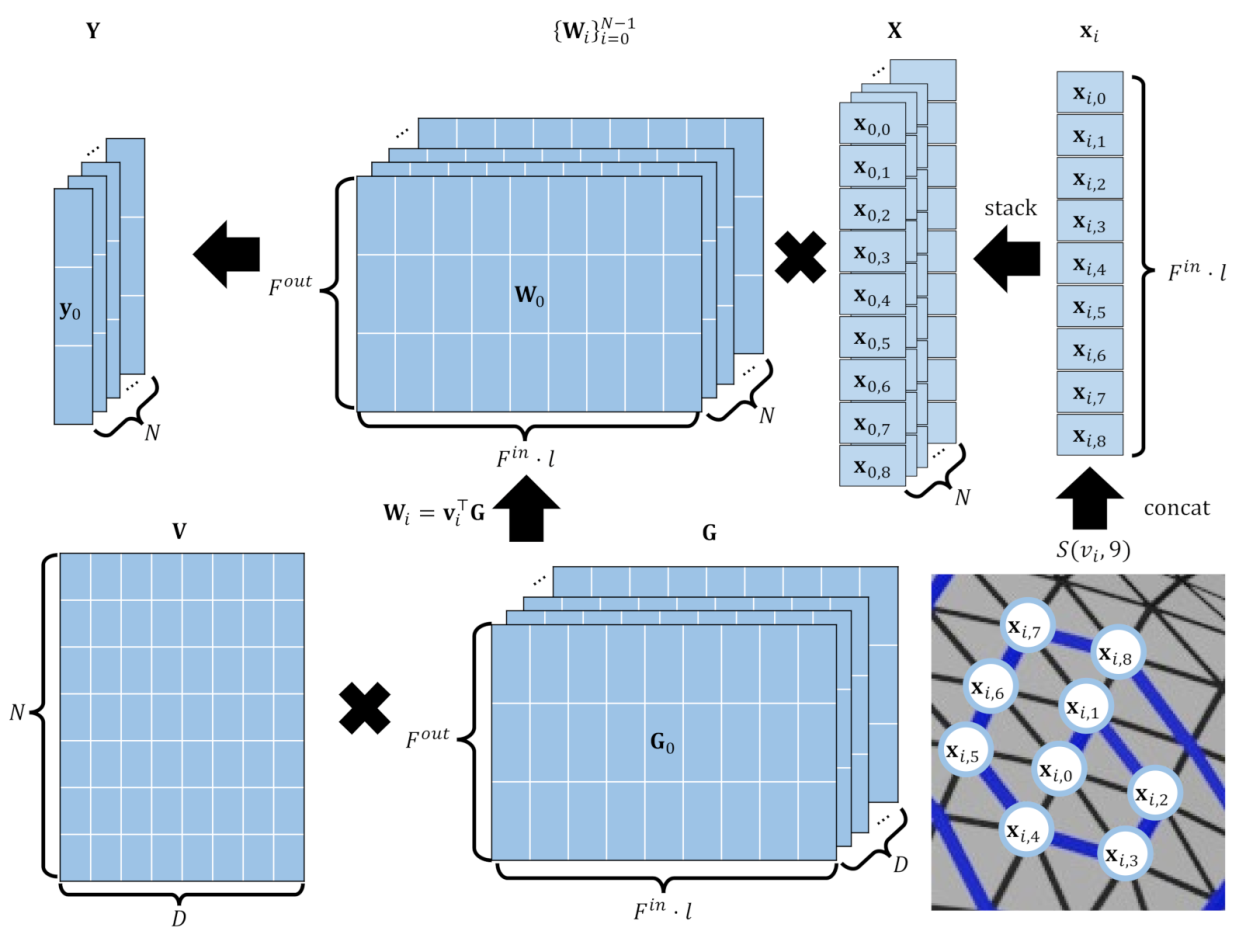
3. Method
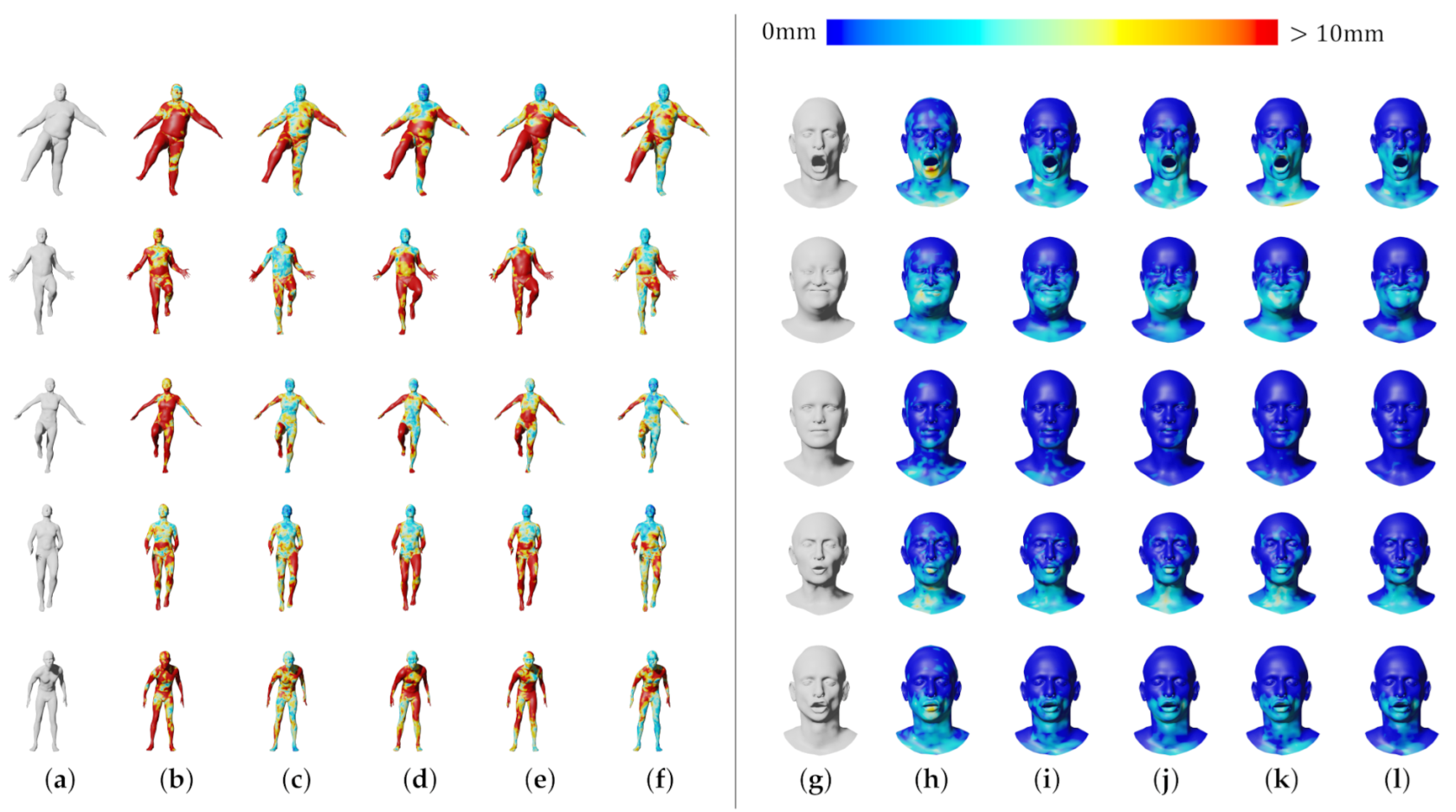
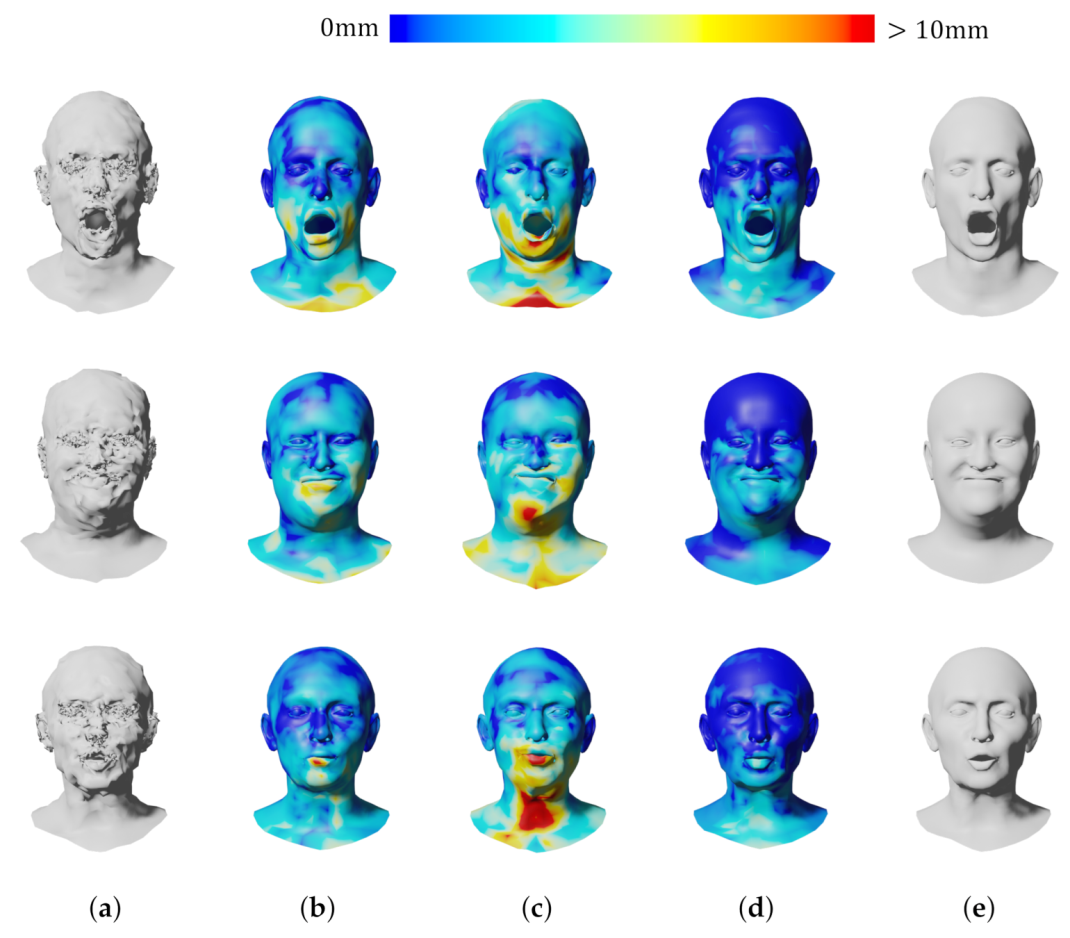
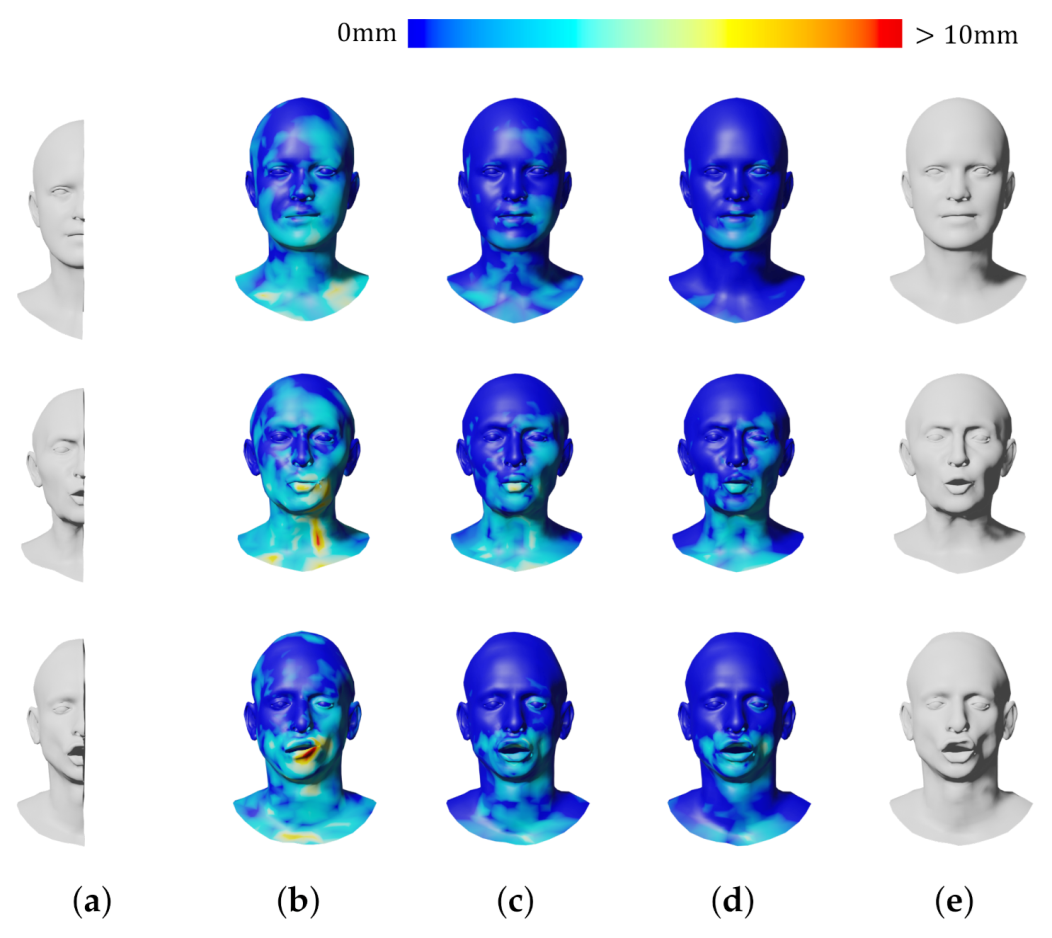
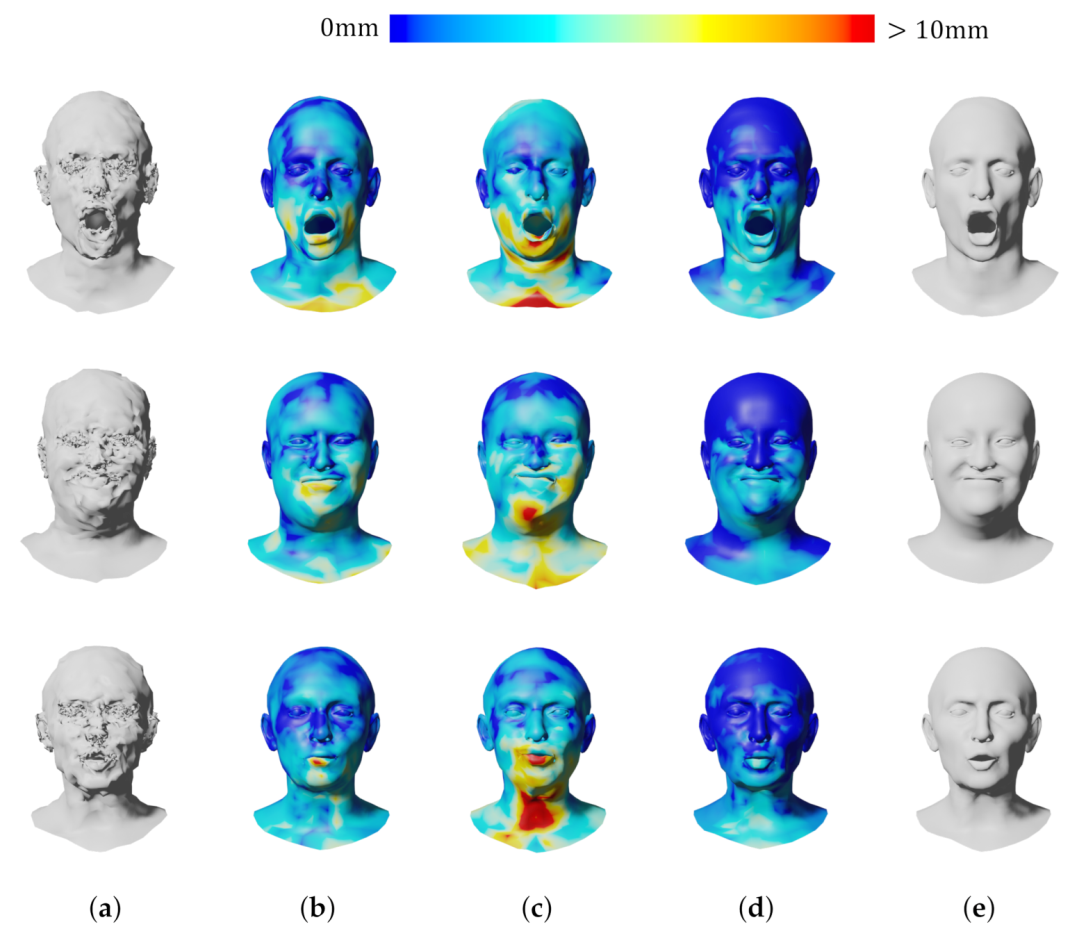
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | Three-dimensional |
| CNN | Convolutional neural network |
| CoMA | Convolutional mesh autoencoder |
| PCA | Principal component analysis |
| GCN | Graph convolutional network |
| LSTM | Long short-term memory |
| MLP | Multi-layer perceptron |
| MRI | Magnetic Resonance Imaging |
| CT | Computed Tomography |
References
- Li, Y.; Guo, W.; Shen, J.; Wu, Z.; Zhang, Q. Motion-Induced Phase Error Compensation Using Three-Stream Neural Networks. Appl. Sci. 2022, 12, 8114. [Google Scholar] [CrossRef]
- Di Filippo, A.; Villecco, F.; Cappetti, N.; Barba, S. A Methodological Proposal for the Comparison of 3D Photogrammetric Models. In Proceedings of the Design Tools and Methods in Industrial Engineering II, Rome, Italy, 9–10 September 2021; Rizzi, C., Campana, F., Bici, M., Gherardini, F., Ingrassia, T., Cicconi, P., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 930–937. [Google Scholar]
- Jayathilakage, R.; Rajeev, P.; Sanjayan, J. Rheometry for Concrete 3D Printing: A Review and an Experimental Comparison. Buildings 2022, 12, 1190. [Google Scholar] [CrossRef]
- The CGAL Project. CGAL User and Reference Manual, 5.4th ed.; CGAL Editorial Board: Valbonne, France, 2022. [Google Scholar]
- Botsch, M.; Steinberg, S.; Bischoff, S.; Kobbelt, L. OpenMesh—A Generic and Efficient Polygon Mesh Data Structure. 2002. Available online: https://www.graphics.rwth-aachen.de/software/openmesh/ (accessed on 8 December 2020).
- Fleishman, S.; Drori, I.; Cohen-Or, D. Bilateral mesh denoising. In ACM SIGGRAPH 2003 Papers; Association for Computing Machinery: New York, NY, USA, 2003; pp. 950–953. [Google Scholar]
- Lee, K.W.; Wang, W.P. Feature-preserving mesh denoising via bilateral normal filtering. In Proceedings of the Ninth International Conference on Computer Aided Design and Computer Graphics (CAD-CG’05), Hong Kong, China, 7–10 December 2005; p. 6. [Google Scholar]
- Hou, Q.; Bai, L.; Wang, Y. Mesh smoothing via adaptive bilateral filtering. In Proceedings of the International Conference on Computational Science, Atlanta, GA, USA, 22–25 May 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 273–280. [Google Scholar]
- Ranjan, A.; Bolkart, T.; Sanyal, S.; Black, M.J. Generating 3D faces using Convolutional Mesh Autoencoders. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 725–741. [Google Scholar]
- Lim, I.; Dielen, A.; Campen, M.; Kobbelt, L. A simple approach to intrinsic correspondence learning on unstructured 3D meshes. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bouritsas, G.; Bokhnyak, S.; Ploumpis, S.; Bronstein, M.; Zafeiriou, S. Neural 3D morphable models: Spiral convolutional networks for 3D shape representation learning and generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7213–7222. [Google Scholar]
- Gong, S.; Chen, L.; Bronstein, M.; Zafeiriou, S. Spiralnet++: A fast and highly efficient mesh convolution operator. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Verma, N.; Boyer, E.; Verbeek, J. Feastnet: Feature-steered graph convolutions for 3D shape analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2598–2606. [Google Scholar]
- Gao, Z.; Yan, J.; Zhai, G.; Zhang, J.; Yang, Y.; Yang, X. Learning Local Neighboring Structure for Robust 3D Shape Representation. Proc. Aaai Conf. Artif. Intell. 2021, 35, 1397–1405. [Google Scholar]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. Acm Trans. Graph. 2013, 32, 1–13. [Google Scholar] [CrossRef]
- Zhao, W.; Gao, S.; Lin, H. A robust hole-filling algorithm for triangular mesh. Vis. Comput. 2007, 23, 987–997. [Google Scholar] [CrossRef]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–13 August 1999; pp. 187–194. [Google Scholar]
- Anguelov, D.; Srinivasan, P.; Koller, D.; Thrun, S.; Rodgers, J.; Davis, J. Scape: Shape completion and animation of people. In ACM SIGGRAPH 2005 Papers; Association for Computing Machinery: New York, NY, USA, 2005; pp. 408–416. [Google Scholar]
- Li, T.; Bolkart, T.; Black, M.J.; Li, H.; Romero, J. Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph. 2017, 36, 194:1–194:17. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Azhar, I.; Sharif, M.; Raza, M.; Khan, M.A.; Yong, H.S. A Decision Support System for Face Sketch Synthesis Using Deep Learning and Artificial Intelligence. Sensors 2021, 21, 8178. [Google Scholar] [CrossRef] [PubMed]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning representations and generative models for 3D point clouds. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 945–953. [Google Scholar]
- Wei, L.; Huang, Q.; Ceylan, D.; Vouga, E.; Li, H. Dense human body correspondences using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1544–1553. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph CNN for learning on point clouds. Acm Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Choi, H.; Moon, G.; Lee, K.M. Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 769–787. [Google Scholar]
- Apicella, A.; Isgrò, F.; Pollastro, A.; Prevete, R. Dynamic filters in graph convolutional neural networks. arXiv 2021, arXiv:2105.10377. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Garland, M.; Heckbert, P.S. Surface simplification using quadric error metrics. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 3–8 August 1997; pp. 209–216. [Google Scholar]
- Litany, O.; Bronstein, A.; Bronstein, M.; Makadia, A. Deformable shape completion with graph convolutional autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1886–1895. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Dutilleux, P. An implementation of the “algorithme à trous” to compute the wavelet transform. In Wavelets; Springer: Berlin/Heidelberg, Germany, 1990; pp. 298–304. [Google Scholar]
- Liang-Chieh, C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gao, Z.; Yan, J.; Zhai, G.; Yang, X. Learning Spectral Dictionary for Local Representation of Mesh. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 19–27 August 2021; pp. 685–692. [Google Scholar] [CrossRef]
- Bogo, F.; Romero, J.; Pons-Moll, G.; Black, M.J. Dynamic FAUST: Registering Human Bodies in Motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mei, S.; Liu, M.; Kudreyko, A.; Cattani, P.; Baikov, D.; Villecco, F. Bendlet Transform Based Adaptive Denoising Method for Microsection Images. Entropy 2022, 24, 869. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CoMA / SpiralNet++ (Encoder) | Ours (Encoder) | ||||
|---|---|---|---|---|---|
| Layer | Input | Output | Layer | Input | Output |
| CoMA/SpiralNet | ASNet | ||||
| Pool | Pool | ||||
| CoMA/SpiralNet | ASNet | ||||
| Pool | Pool | ||||
| CoMA/SpiralNet | ASNet | ||||
| Pool | Pool | ||||
| Flatten | Flatten | ||||
| Linear | * | Linear | * | ||
| CoMA / SpiralNet++ (Decoder) | Ours (Decoder) | ||||
| Layer | Input | Output | Layer | Input | Output |
| Linear | Linear | ||||
| Reshape | Reshape | ||||
| Pool | Pool | ||||
| CoMA/SpiralNet | ASNet | ||||
| Pool | Pool | ||||
| CoMA/SpiralNet | ASNet | ||||
| Pool | Pool | ||||
| CoMA/SpiralNet | ASNet | ||||
| CoMA/SpiralNet | Linear | ||||
| Network | Dataset | |||||
|---|---|---|---|---|---|---|
| DFAUST | CoMA | |||||
| Error | Params | Frame/sec | Error | Params | Frame/sec | |
| CoMA | 12.416 | 1390K | 0.6661 | 1031K | ||
| SpiralNet++ | 7.510 | 1418K | 0.4236 | 1059K | ||
| LSAConv 1 | 10.493 | 2540K | 0.4203 | 1723K | ||
| SDConv 1 | 10.488 | 564K | 0.4525 | 443K | ||
| Ours | 6.151 | 2147K | 0.3551 | 1750K | ||
| Network | Actor ID | Mean | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0137 | 3272 | 0024 | 0138 | 3274 | 3275 | 0128 | 3276 | 3277 | 3278 | 3279 | 0223 | ||
| CoMA | 1.073 | 1.179 | 1.057 | 1.107 | 1.161 | 0.890 | 1.306 | 1.059 | 0.999 | 0.926 | 1.040 | 0.873 | 1.071 |
| SpiralNet++ | 0.489 | 0.568 | 0.592 | 0.675 | 0.699 | 0.460 | 0.760 | 0.594 | 0.558 | 0.516 | 0.611 | 0.473 | 0.603 |
| Ours | 0.447 | 0.574 | 0.495 | 0.593 | 0.625 | 0.389 | 0.759 | 0.533 | 0.474 | 0.437 | 0.530 | 0.419 | 0.541 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.U.; Roh, J.; Im, H.; Kim, J. Anisotropic SpiralNet for 3D Shape Completion and Denoising. Sensors 2022, 22, 6457. https://doi.org/10.3390/s22176457
Kim SU, Roh J, Im H, Kim J. Anisotropic SpiralNet for 3D Shape Completion and Denoising. Sensors. 2022; 22(17):6457. https://doi.org/10.3390/s22176457
Chicago/Turabian StyleKim, Seong Uk, Jihyun Roh, Hyeonseung Im, and Jongmin Kim. 2022. "Anisotropic SpiralNet for 3D Shape Completion and Denoising" Sensors 22, no. 17: 6457. https://doi.org/10.3390/s22176457
APA StyleKim, S. U., Roh, J., Im, H., & Kim, J. (2022). Anisotropic SpiralNet for 3D Shape Completion and Denoising. Sensors, 22(17), 6457. https://doi.org/10.3390/s22176457