
SGSNet: A Lightweight Depth Completion Network Based on Secondary Guidance and Spatial Fusion


Abstract
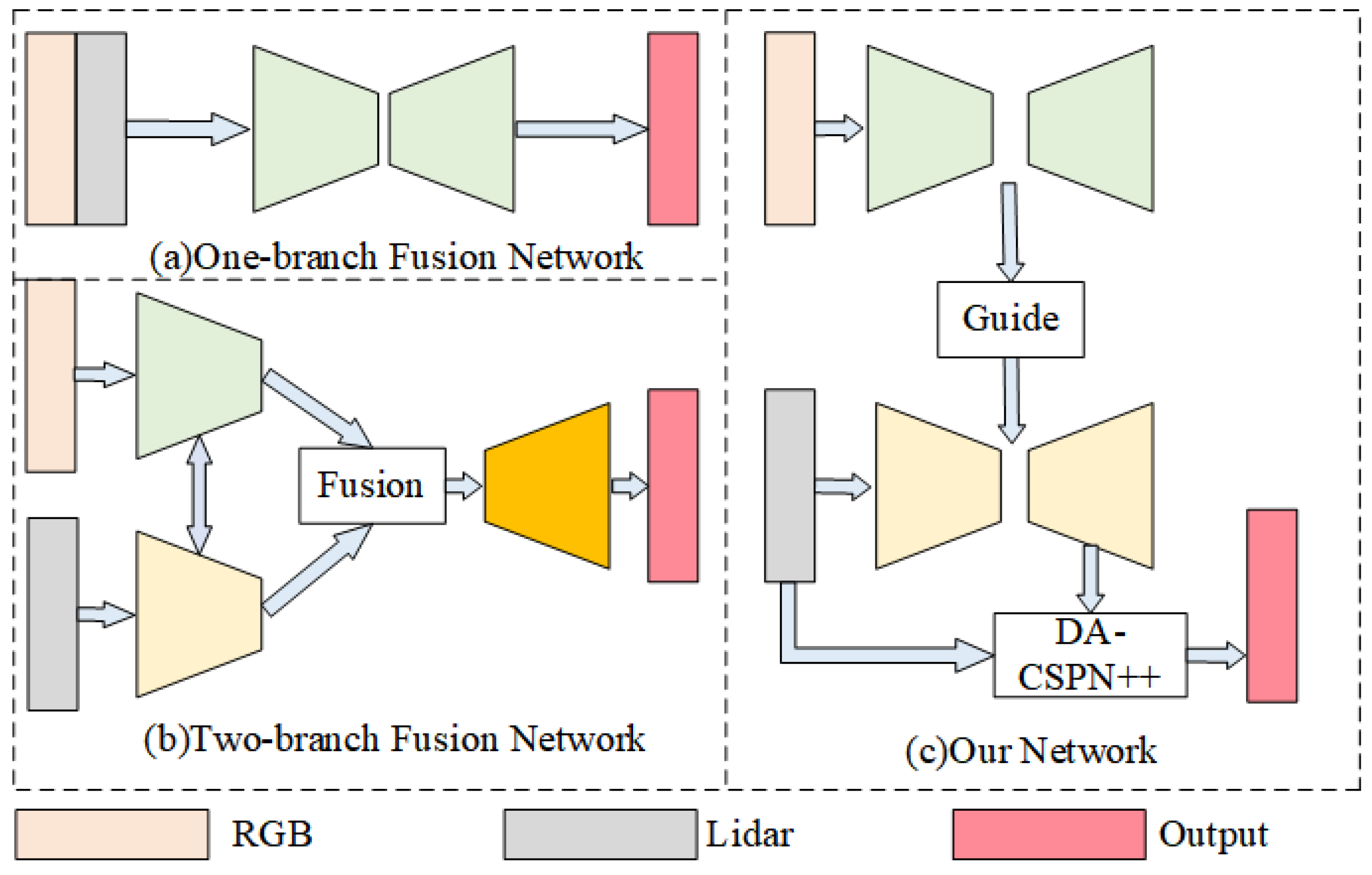
:1. Introduction
- An image feature extraction method, which contains a spatial feature extraction as well as a scale feature extraction, is used. Compared with the traditional image pyramid module, this module focuses more on mining richer multiscale information in the same domain.
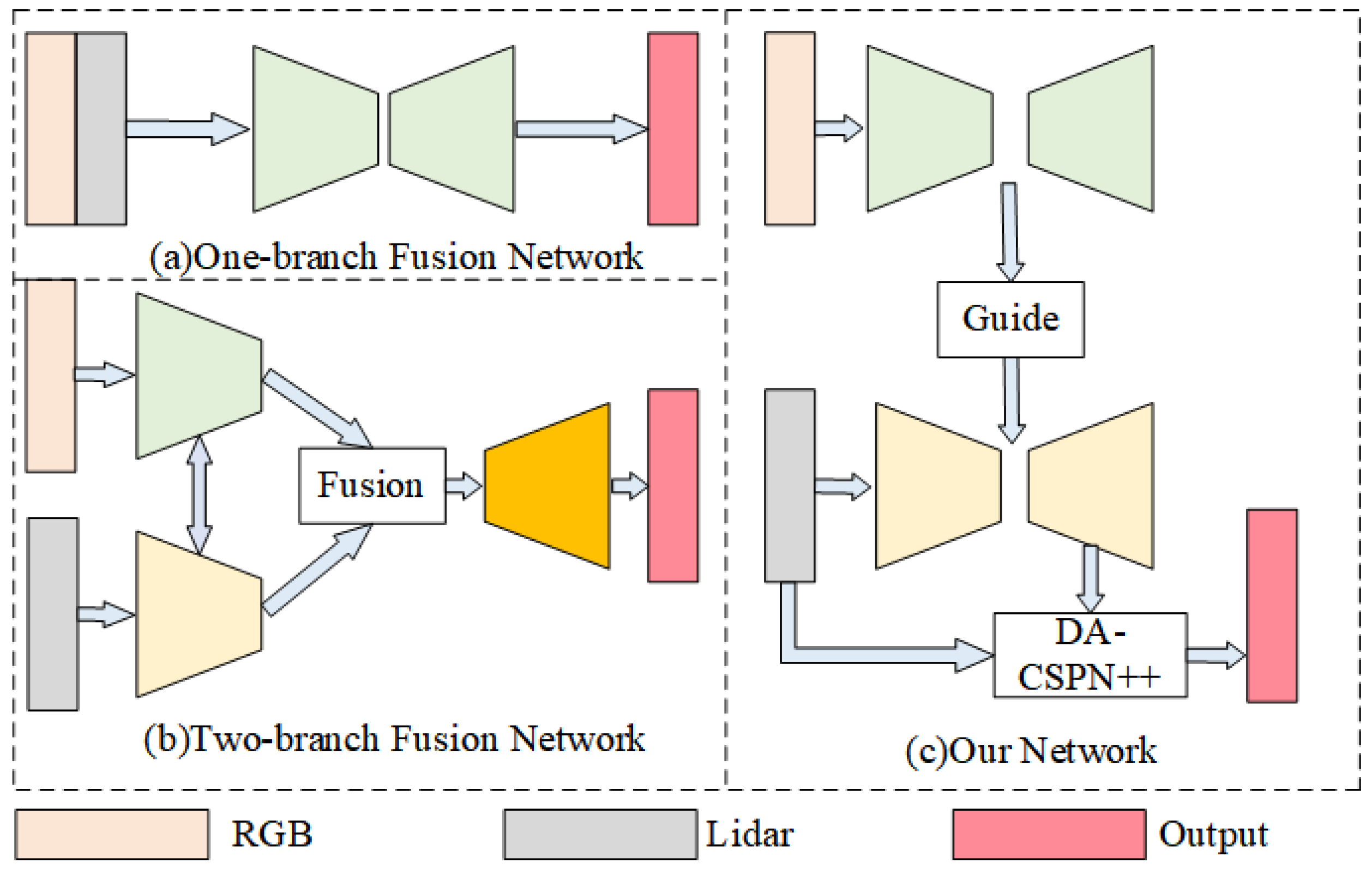
- A secondary guidance module is used to guide the guidance features to the LiDAR features and the input DA-CSPN++ network. It is 10 times faster than that in the baseline GuideNet, allowing the overall network to meet the demand for real-time data preprocessing.
2. Materials and Methods
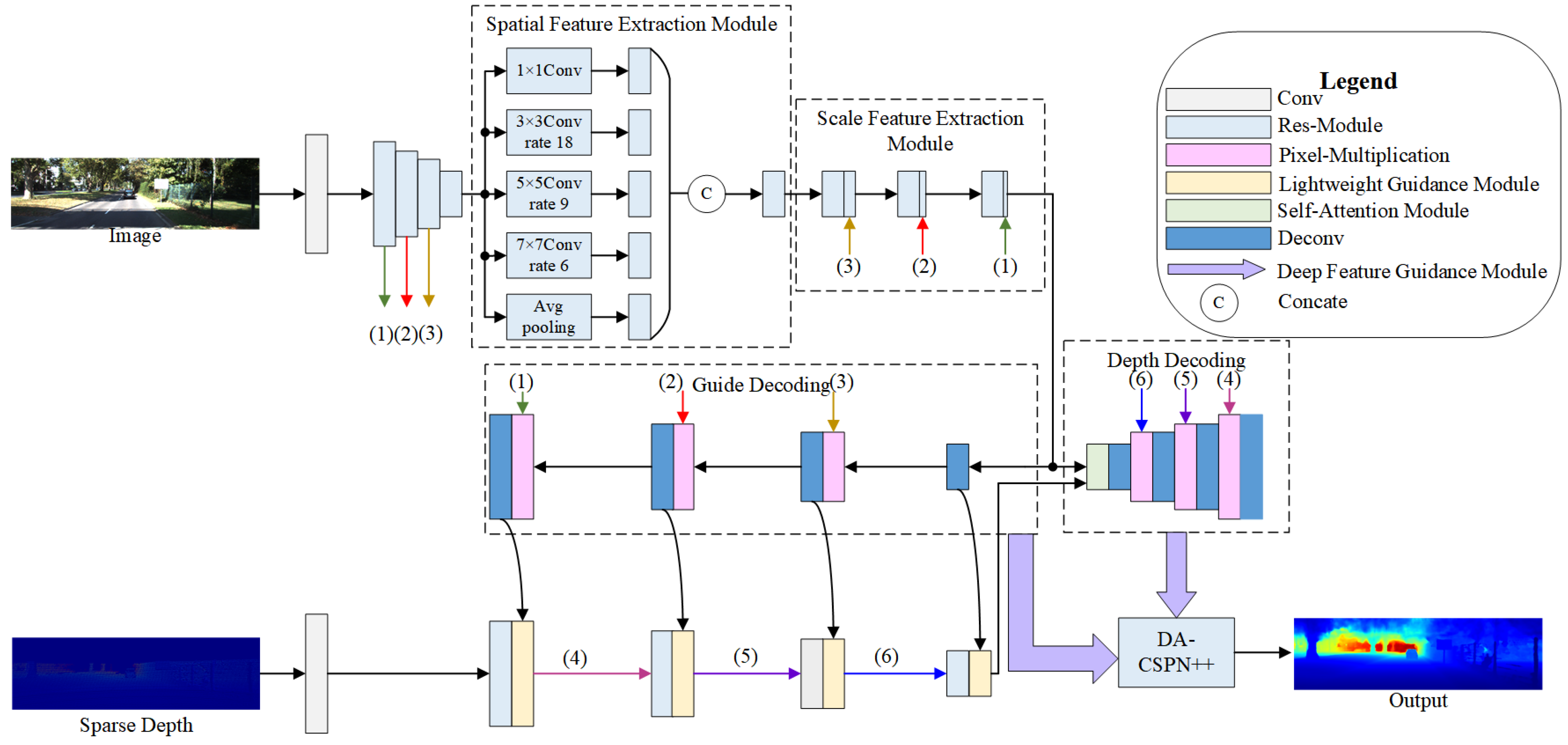
2.1. Image Feature Extraction Module
2.1.1. Spatial Feature Extraction
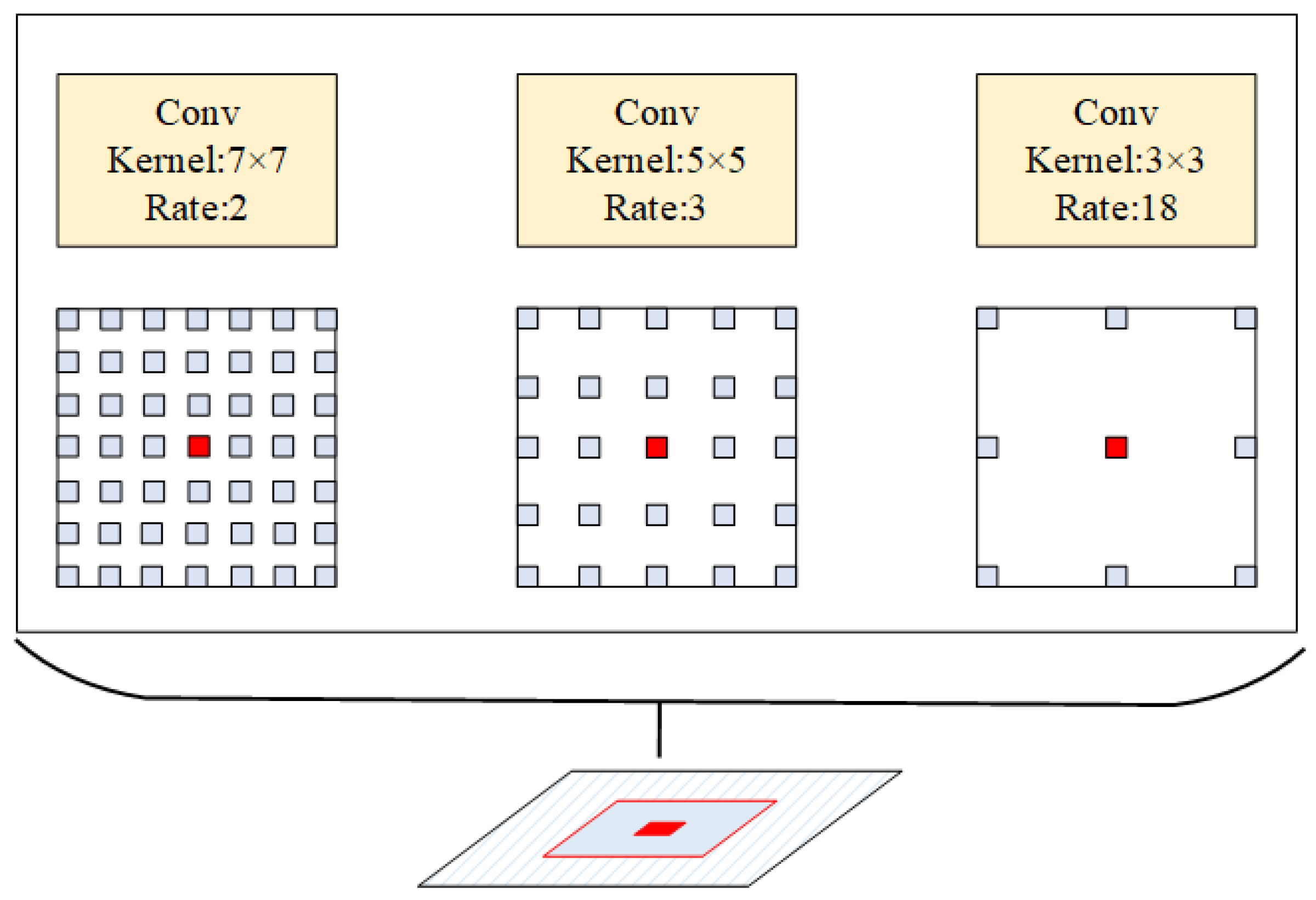
2.1.2. Scale Feature Extraction
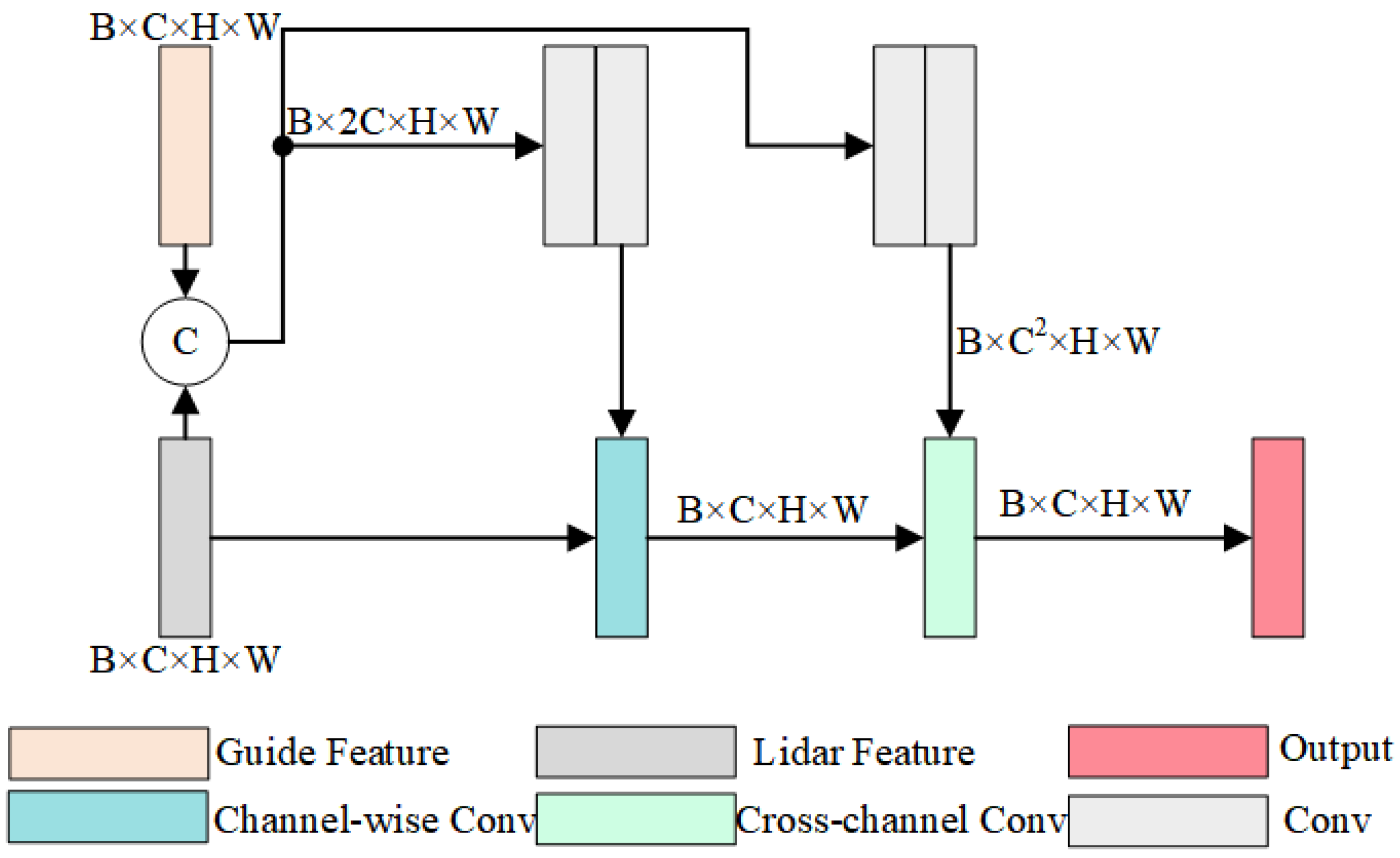
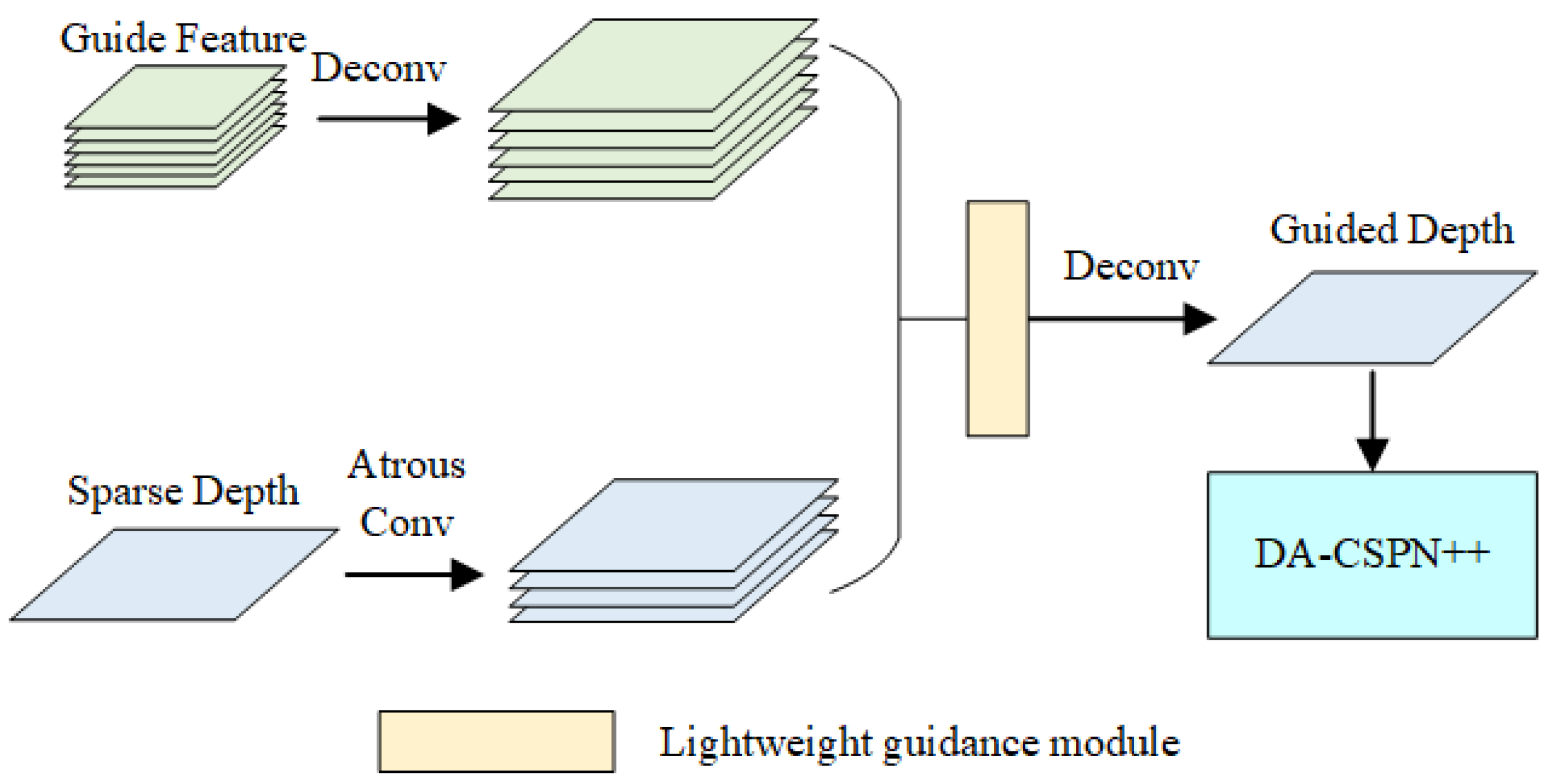
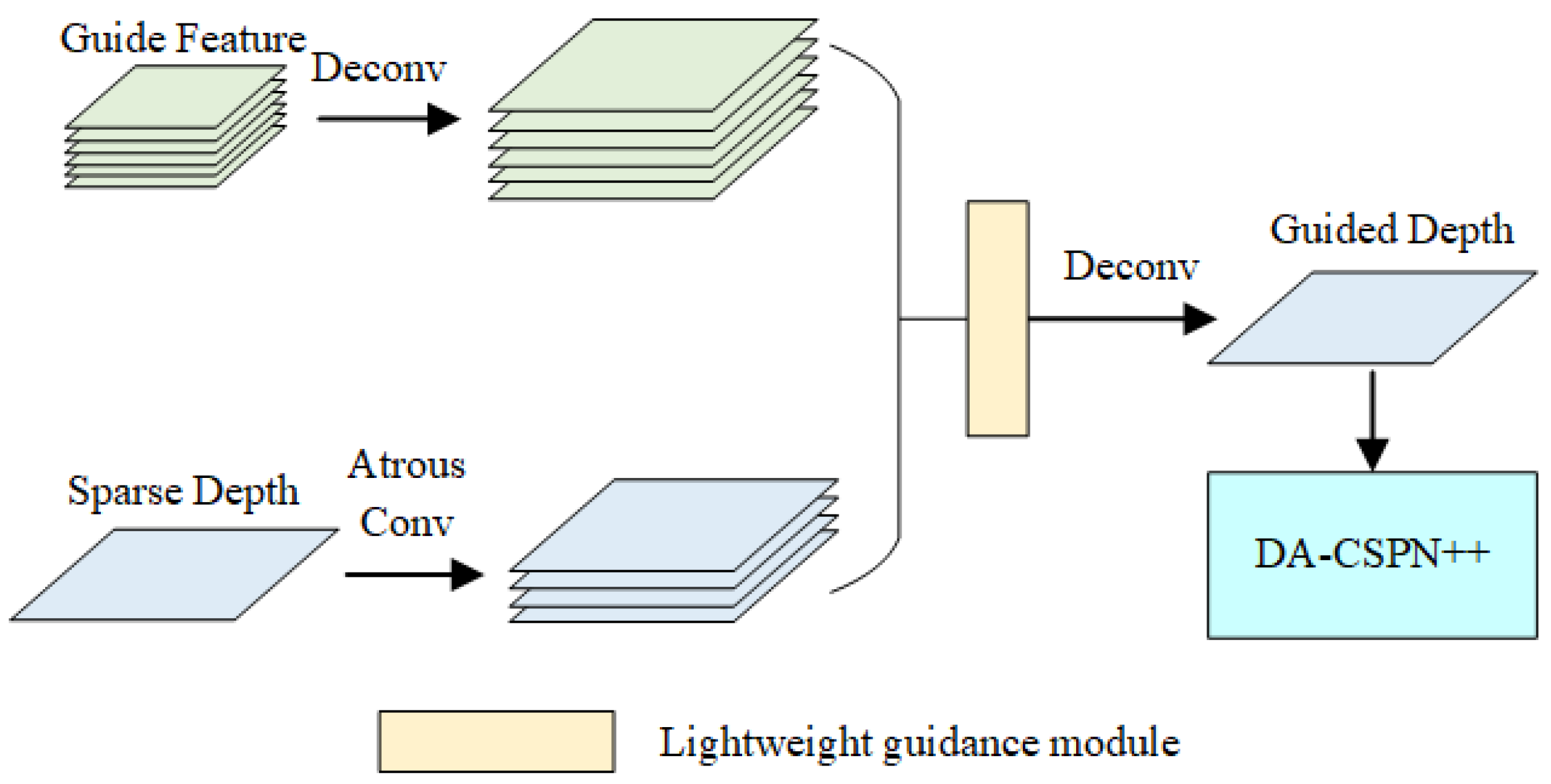
2.2. Lightweight Guidance Module
2.3. Depth Information Completion Module
2.4. The Training Loss
3. Results
3.1. Experimental Setup
3.1.1. Dataset and Evaluation Metrics
3.1.2. Experimental Environment
3.2. Ablation Studies
3.2.1. The Efficiency of the Image Feature Extraction Module
3.2.2. The Efficiency of the Secondary Guidance Module
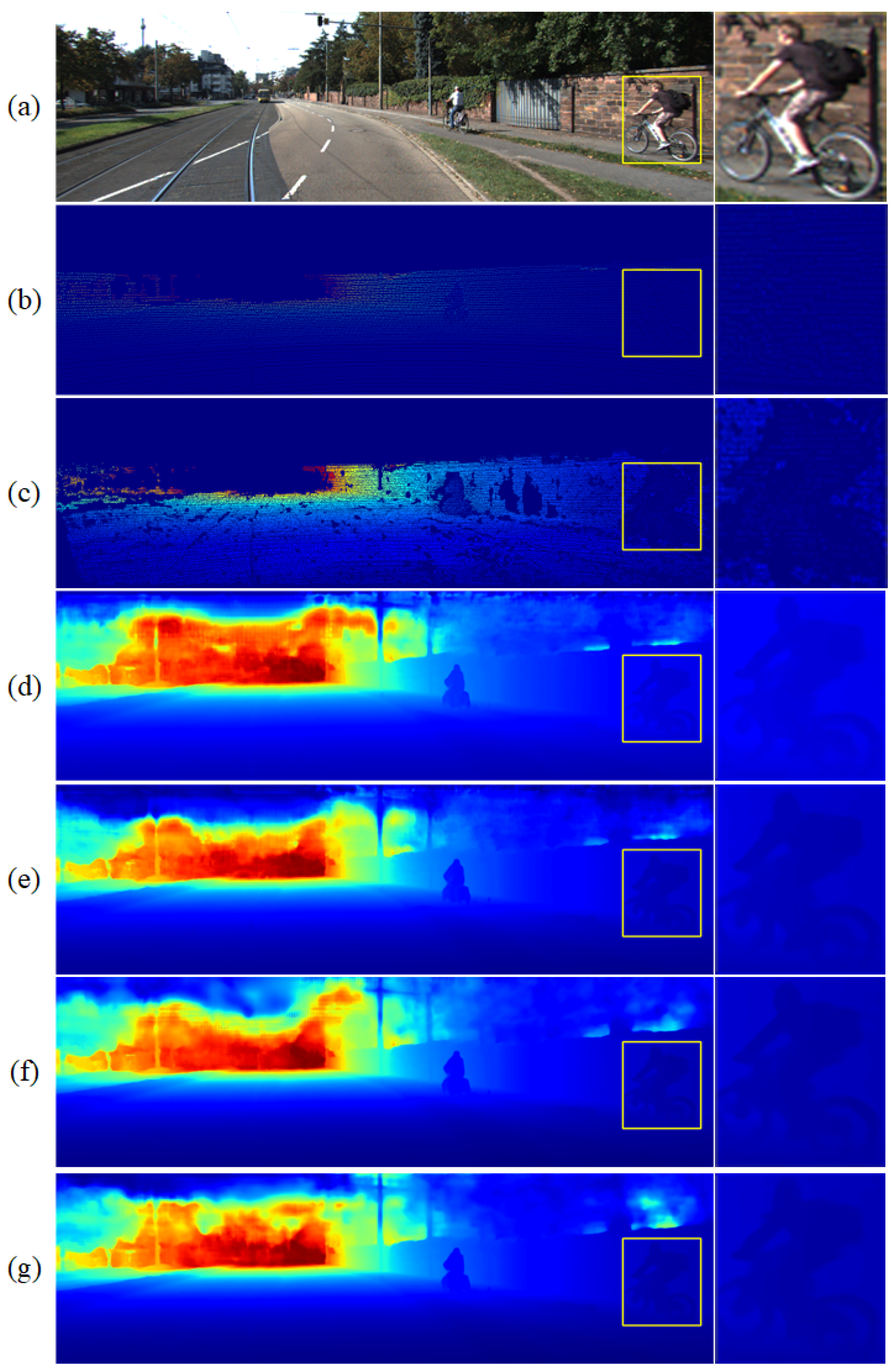
3.3. Comparison with State-Of-The-Art
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dey, A.; Jarvis, G.; Sandor, C.; Reitmayr, G. Tablet versus phone: Depth perception in handheld augmented reality. In Proceedings of the 2012 IEEE international symposium on mixed and augmented reality (ISMAR), Altanta, GA, USA, 5–8 November 2012; pp. 187–196. [Google Scholar]
- Song, X.; Dai, Y.; Zhou, D.; Liu, L.; Li, W.; Li, H.; Yang, R. Channel attention based iterative residual learning for depth map super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5631–5640. [Google Scholar]
- Armbrüster, C.; Wolter, M.; Kuhlen, T.; Spijkers, W.; Fimm, B. Depth perception in virtual reality: Distance estimations in peri-and extrapersonal space. Cyberpsychol. Behav. 2008, 11, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Huang, S.; Xiong, R.; Wu, J. A framework for multi-session RGBD SLAM in low dynamic workspace environment. CAAI Trans. Intell. Technol. 2016, 1, 90–103. [Google Scholar] [CrossRef]
- Park, J.; Joo, K.; Hu, Z.; Liu, C.-K.; Kweon, I.S. Non-local spatial propagation network for depth completion. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 120–136. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Yan, Y.; Sebe, N.; Yang, J. Pattern-affinitive propagation across depth, surface normal and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4106–4115. [Google Scholar]
- Ma, F.; Cavalheiro, G.V.; Karaman, S. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3288–3295. [Google Scholar]
- Ma, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4796–4803. [Google Scholar]
- Hu, M.; Wang, S.; Li, B.; Ning, S.; Fan, L.; Gong, X. Penet: Towards precise and efficient image guided depth completion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13656–13662. [Google Scholar]
- Chen, Y.; Yang, B.; Liang, M.; Urtasun, R. Learning joint 2d-3d representations for depth completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10023–10032. [Google Scholar]
- Gu, J.; Xiang, Z.; Ye, Y.; Wang, L. DenseLiDAR: A real-time pseudo dense depth guided depth completion network. IEEE Robot. Autom. Lett. 2021, 6, 1808–1815. [Google Scholar] [CrossRef]
- Qiu, J.; Cui, Z.; Zhang, Y.; Zhang, X.; Liu, S.; Zeng, B.; Pollefeys, M. Deeplidar: Deep surface normal guided depth prediction for outdoor scene from sparse lidar data and single color image. arXiv 2019, arXiv:1812.00488. [Google Scholar]
- Liu, L.; Song, X.; Lyu, X.; Diao, J.; Wang, M.; Liu, Y.; Zhang, L. FCFR-Net: Feature Fusion based Coarse-to-Fine Residual Learning for Depth Completion. AAAI Conf. Artif. Intell. 2021, 35, 2136–2144. [Google Scholar]
- Zhao, S.; Gong, M.; Fu, H.; Tao, D. Adaptive context-aware multi-modal network for depth completion. IEEE Trans. Image Process. 2021, 30, 5264–5276. [Google Scholar] [CrossRef] [PubMed]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant cnns. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 11–20. [Google Scholar]
- Hua, J.; Gong, X. A normalized convolutional neural network for guided sparse depth upsampling. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 2283–2290. [Google Scholar]
- Eldesokey, A.; Felsberg, M.; Khan, F.S. Propagating confidences through cnns for sparse data regression. arXiv 2018, arXiv:1805.11913. [Google Scholar]
- Huang, Z.; Fan, J.; Cheng, S.; Yi, S.; Wang, X.; Li, H. Hms-net: Hierarchical multi-scale sparsity-invariant network for sparse depth completion. IEEE Trans. Image Process. 2019, 29, 3429–3441. [Google Scholar] [CrossRef] [PubMed]
- Eldesokey, A.; Felsberg, M.; Holmquist, K.; Persson, M. Uncertainty-aware cnns for depth completion: Uncertainty from beginning to end. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12014–12023. [Google Scholar]
- Van Gansbeke, W.; Neven, D.; De Brabandere, B.; Van Gool, L. Sparse and noisy lidar completion with rgb guidance and uncertainty. In Proceedings of the 2019 16th international conference on machine vision applications (MVA), Tokyo, Japan, 27–31 May 2019; pp. 1–6. [Google Scholar]
- Tang, J.; Tian, F.P.; Feng, W.; Li, J.; Tan, P. Learning guided convolutional network for depth completion. IEEE Trans. Image Process. 2020, 30, 1116–1129. [Google Scholar] [CrossRef] [PubMed]
- Yan, Z.; Wang, K.; Li, X.; Zhang, Z.; Xu, B.; Li, J.; Yang, J. RigNet: Repetitive image guided network for depth completion. arXiv 2021, arXiv:2107.13802. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27, 2366–2374. [Google Scholar]
- Li, A.; Yuan, Z.; Ling, Y.; Chi, W.; Zhang, C. A multi-scale guided cascade hourglass network for depth completion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2020; pp. 32–40. [Google Scholar]
- Xu, Y.; Zhu, X.; Shi, J.; Zhang, G.; Bao, H.; Li, H. Depth completion from sparse lidar data with depth-normal constraints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2811–2820. [Google Scholar]
- Jaritz, M.; De Charette, R.; Wirbel, E.; Perrotton, X.; Nashashibi, F. Sparse and dense data with cnns: Depth completion and semantic segmentation. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 52–60. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Liu, S.; De Mello, S.; Gu, J.; Zhong, G.; Yang, M.H.; Kautz, J. Learning affinity via spatial propagation networks. Adv. Neural Inf. Process. Syst. 2017, 30, 1519–1529. [Google Scholar]
- Cheng, X.; Wang, P.; Yang, R. Depth estimation via affinity learned with convolutional spatial propagation network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–119. [Google Scholar]
- Cheng, X.; Wang, P.; Guan, C.; Yang, R. Cspn++: Learning context and resource aware convolutional spatial propagation networks for depth completion. AAAI Conf. Artif. Intell. 2020, 34, 10615–10622. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Qiao, S.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. Vip-deeplab: Learning visual perception with depth-aware video panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3997–4008. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Xu, Z.; Yin, H.; Yao, J. Deformable spatial propagation networks for depth completion. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 913–917. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | SPFE Module 1 | SCFE Module 2 | LG Module 3 | DIC Module 4 | DA- CSPN++ | RMSE | MAE | iRMSE | iMAE | Runtime |
|---|---|---|---|---|---|---|---|---|---|---|
| B | 778.63 | 223.37 | 2.35 | 0.98 | 0.140 | |||||
| B1 | ✓ | 769.25 | 220.12 | 2.34 | 0.98 | 0.143 | ||||
| B2 | ✓ | ✓ | 767.04 | 219.57 | 2.34 | 0.98 | 0.145 | |||
| C | ✓ | ✓ | ✓ | 766.89 | 218.56 | 2.31 | 0.97 | 0.014 | ||
| C+D1 | ✓ | ✓ | ✓ | 1 | 753.20 | 210.23 | 2.21 | 0.93 | 0.018 | |
| C+D2 | ✓ | ✓ | ✓ | 1, 2 | 751.32 | 209.37 | 2.17 | 0.92 | 0.018 | |
| C+D4 | ✓ | ✓ | ✓ | 1, 2, 4 | 749.93 | 209.82 | 2.18 | 0.92 | 0.019 | |
| C+E1 | ✓ | ✓ | ✓ | ✓ | 1 | 746.93 | 209.30 | 2.18 | 0.91 | 0.019 |
| C+E2 | ✓ | ✓ | ✓ | ✓ | 1, 2 | 745.77 | 208.85 | 2.16 | 0.91 | 0.020 |
| C+E4 | ✓ | ✓ | ✓ | ✓ | 1, 2, 4 | 744.04 | 206.30 | 2.16 | 0.90 | 0.020 |
| Method | Dynamic Convolution | Guidance Module | Our Module |
|---|---|---|---|
| Memory (GB) | 42.73 | 0.332 | 0.035 |
| Times | 1155 | 9 | 1 |
| Models | RMSE (mm) | MAE (mm) | iRMSE (1/km) | iMAE (1/km) | Runtime (s) |
|---|---|---|---|---|---|
| PwP [25] | 777.05 | 235.17 | 2.42 | 1.13 | 0.100 |
| DSPN [36] | 766.74 | 220.36 | 2.47 | 1.03 | 0.340 |
| DeepLiDAR [12] | 758.38 | 226.50 | 2.56 | 1.15 | 0.051 |
| UberATG [10] | 752.88 | 221.19 | 2.34 | 1.14 | 0.090 |
| CSPN++ [30] | 743.69 | 209.28 | 2.07 | 0.90 | 0.200 |
| NLSPN [5] | 741.68 | 199.59 | 1.99 | 0.84 | 0.127 |
| GuideNet [21] | 736.24 | 218.83 | 2.25 | 0.99 | 0.140 |
| FCFR-Net [13] | 735.81 | 217.15 | 2.20 | 0.98 | 0.130 |
| ACMNet [14] | 732.99 | 206.80 | 2.08 | 0.90 | 0.330 |
| PENet [9] | 730.08 | 210.55 | 2.17 | 0.94 | 0.032 |
| RigNet [22] | 712.66 | 203.25 | 2.08 | 0.90 | 0.240 |
| SGSNet (Ours) | 723.67 | 209.54 | 2.11 | 0.92 | 0.020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Lv, X.; Liu, C.; Jiao, H. SGSNet: A Lightweight Depth Completion Network Based on Secondary Guidance and Spatial Fusion. Sensors 2022, 22, 6414. https://doi.org/10.3390/s22176414
Chen B, Lv X, Liu C, Jiao H. SGSNet: A Lightweight Depth Completion Network Based on Secondary Guidance and Spatial Fusion. Sensors. 2022; 22(17):6414. https://doi.org/10.3390/s22176414
Chicago/Turabian StyleChen, Baifan, Xiaotian Lv, Chongliang Liu, and Hao Jiao. 2022. "SGSNet: A Lightweight Depth Completion Network Based on Secondary Guidance and Spatial Fusion" Sensors 22, no. 17: 6414. https://doi.org/10.3390/s22176414
APA StyleChen, B., Lv, X., Liu, C., & Jiao, H. (2022). SGSNet: A Lightweight Depth Completion Network Based on Secondary Guidance and Spatial Fusion. Sensors, 22(17), 6414. https://doi.org/10.3390/s22176414