
Comparison of Deep Learning and Deterministic Algorithms for Control Modeling



Abstract
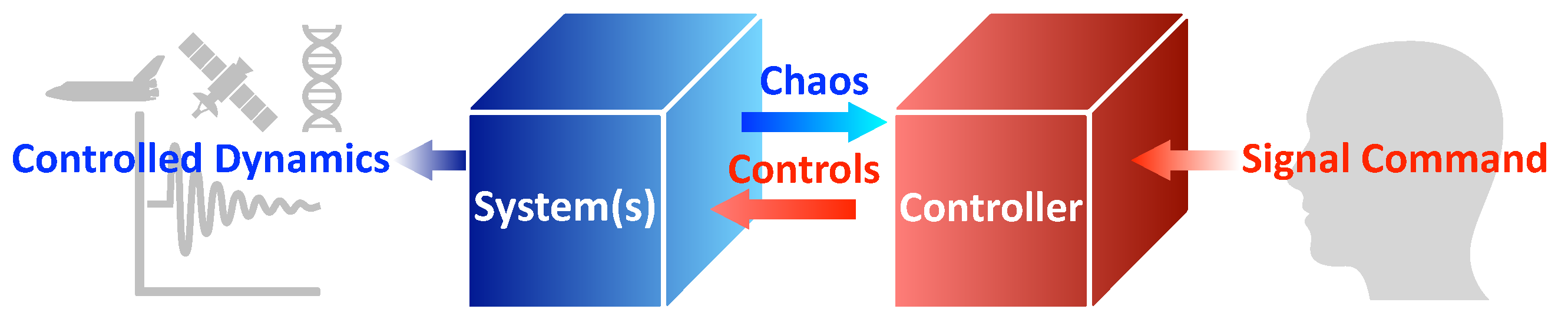
:1. Introduction
1.1. Physics-Informed Machine Learning
1.2. Deterministic Algorithms
2. Problem Formulation
3. Methodology and Materials
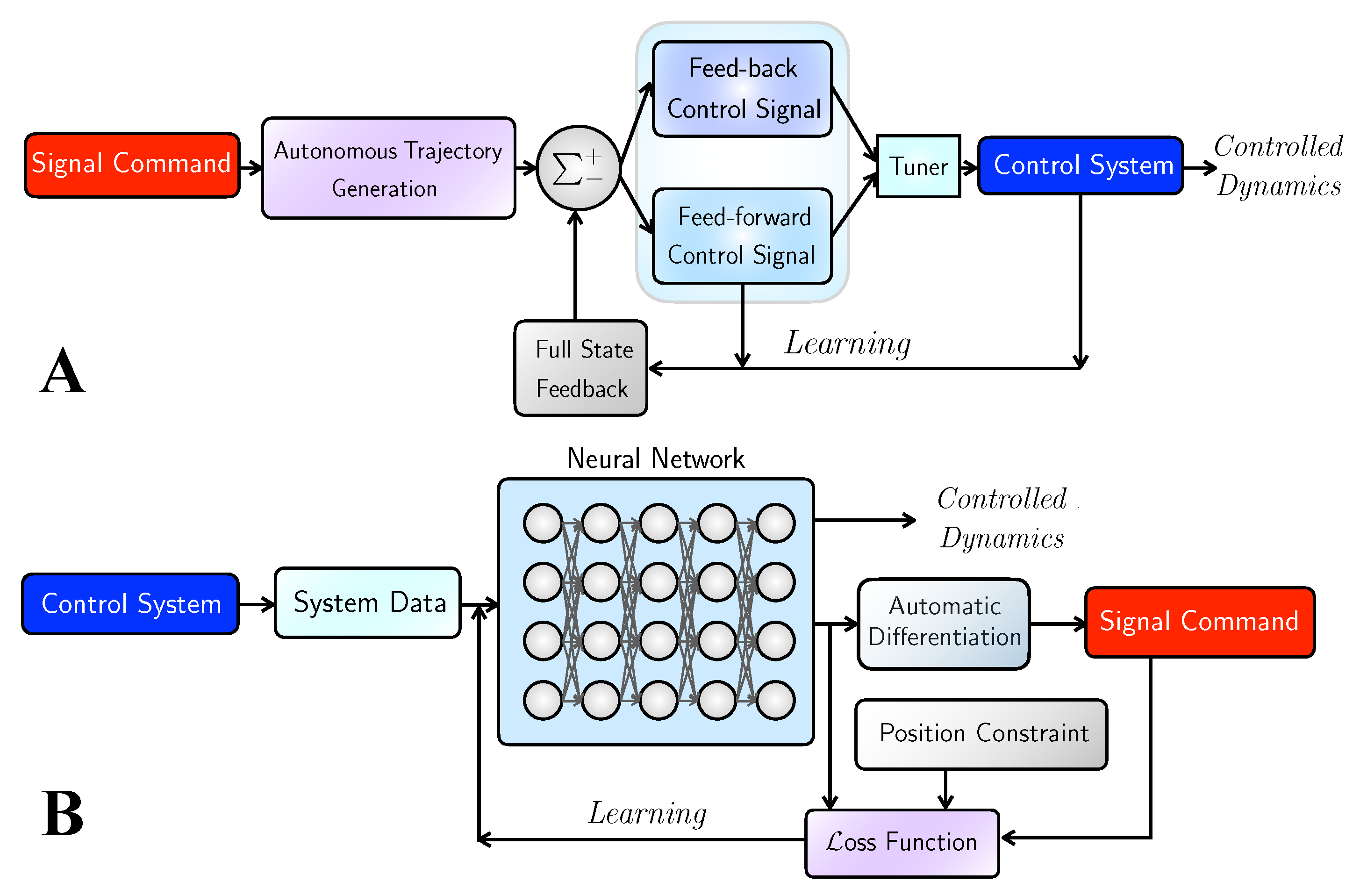
3.1. Physics-Informed Deep Operator Control
3.1.1. Deep Learning
3.1.2. Physics-Informed Control
3.2. Deterministic Control Algorithms
3.2.1. Linearized Feedback Control
3.2.2. Nonlinear Feed-Forward Control
3.2.3. Combined Control
3.3. Comparison and Estimation
4. Results and Discussion
4.1. Benchmark Analysis
4.2. Trajectory Amplitude
4.3. Nonlinear Effects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Routh, E.J. A Treatise on the Stability of a Given State of Motion, Particularly Steady Motion: Particularly Steady Motion; Macmillan and Co.: Cambridge, UK, 1877. [Google Scholar]
- Maxwell, J.C. On Governors. Proc. R. Soc. Lond. 1868, 100, 270–283. [Google Scholar] [CrossRef] [Green Version]
- Cartwright, J.; Eguíluz, V.; Hernández-García, E.; Piro, O. Dynamics of Elastic Excitable Media. Int. J. Bif. Chaos 1999, 9, 2197–2202. [Google Scholar] [CrossRef] [Green Version]
- FitzHugh, R. Impulses and Physiological States in Theoretical Models of Nerve Membrane. Bio. J 1961, 1, 445–466. Available online: https://www.cell.com/biophysj/pdf/S0006-3495(61)86902-6.pdf (accessed on 14 August 2022).
- Nagumo, J.; Arimoto, S.; Yoshizawa, S. An Active Pulse Transmission Line Simulating Nerve Axon. Proc. IRE Inst. Elec. Electr. Eng. 1962, 50, 2061–2070. Available online: https://ieeexplore.ieee.org/document/4066548 (accessed on 14 August 2022). [CrossRef]
- Lighthill, J. Artificial Intelligence: A General Survey. In J. Art. Int. A General Survey Artificial Intelligence: A Paper Symposium; Science Research Council: New York, NY, USA, 1972; Available online: http://www.chilton-computing.org.uk/inf/literature/reports/lighthill_report/p001.htm (accessed on 14 August 2022).
- Towell, G.G.; Shavlik, J.W. Knowledge-based artificial neural networks. Artif. Intell. 1994, 70, 119–165. [Google Scholar] [CrossRef]
- Towell, G.G.; Shavlik, J.W.; Noordewier, M.O. Refinement of Approximate Domain Theories by Knowledge-Based Neural Networks. AAAI-90 Proc. 1990, 2, 861–866. Available online: https://www.aaai.org/Papers/AAAI/1990/AAAI90-129.pdf (accessed on 14 August 2022).
- Towell, G.G.; Shavlik, J.W. Extracting refined rules from knowledge-based neural networks. Mach. Learn. 1993, 13, 71–101. [Google Scholar] [CrossRef] [Green Version]
- Fu, L. Introduction to knowledge-based neural networks. Knowl.-Based Syst. 1995, 8, 299–300. [Google Scholar] [CrossRef]
- Nechepurenko, L.; Voss, V.; Gritsenko, V. Comparing Knowledge-Based Reinforcement Learning to Neural Networks in a Strategy Game. In Hybrid Artificial Intelligent Systems. HAIS 2020; Lecture Notes in Computer Science; de la Cal, E.A., Villar Flecha, J.R., Quintián, H., Corchado, E., Eds.; Springer: Cham, Switerzland, 2020; Volume 12344. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L. Physics-Informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Raissi, M.; Yazdani, A.; Karniadakis, G.E. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 2020, 367, 1026–1030. [Google Scholar] [CrossRef]
- Zhai, H.; Zhou, Q.; Hu, G. Predicting micro-bubble dynamics with semi-physics-informed deep learning. AIP Adv. 2022, 12, 035153. [Google Scholar] [CrossRef]
- Zhai, H.; Sands, T. Controlling Chaos in Van Der Pol Dynamics Using Signal-Encoded Deep Learning. Mathematics 2022, 10, 453. [Google Scholar] [CrossRef]
- Cooper, M.; Heidlauf, P.; Sands, T. Controlling Chaos—Forced van der Pol Equation. Mathematics 2017, 5, 70. [Google Scholar] [CrossRef] [Green Version]
- Efheij, H.; Albagul, A. Comparison of PID and Artificial Neural Network Controller in on line of Real Time Industrial Temperature Process Control System. In Proceedings of the 2021 IEEE 1st International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering MI-STA, Tripoli, Libya, 25–27 May 2021; pp. 110–115. [Google Scholar] [CrossRef]
- Lee, Y.-S.; Jang, D.-W. Optimization of Neural Network Based Self-Tuning PID Controllers for Second Order Mechanical Systems. Appl. Sci. 2021, 11, 8002. [Google Scholar] [CrossRef]
- Scott, G.M.; Shavlik, J.W.; Ray, W.H. Refining PID Controllers Using Neural Networks. Neural Comput. 1992, 4, 746–757. [Google Scholar] [CrossRef]
- Hagan, M.T.; Demuth, H.B. Neural networks for control. In Proceedings of the 1999 American Control Conference (Cat. No. 99CH36251), San Diego, CA, USA, 2–4 June 1999; Volume 3, pp. 1642–1656. [Google Scholar] [CrossRef]
- Nguyen, D.H.; Widrow, B. Neural networks for self-learning control systems. IEEE Control. Syst. Mag. 1990, 10, 18–23. [Google Scholar] [CrossRef]
- Antsaklis, P.J. Neural Networks in Control Systems; Guest Editor’s Introduction. IEEE Control. Syst. Mag. 1990, 10, 3–5. [Google Scholar]
- van der Pol, B. On “Relaxation Oscillations”. I. Philos. Mag. 1926, 2, 978–992. [Google Scholar] [CrossRef]
- van der Pol, B.; van der Mark, J. Frequency Demultiplication. Nature 1927, 120, 363–364. [Google Scholar] [CrossRef]
- Duke University. The van der Pol System. Available online: https://services.math.duke.edu/education/ccp/materials/diffeq/vander/vand1.html (accessed on 14 August 2022).
- Partially Modified from “Phase portrait of Van-Der-Pol oscillator in TikZ”. Available online: https://latexdraw.com/phase-portrait-of-van-der-pol-oscillator/ (accessed on 14 August 2022).
- Schult, D. Math 329—Numerical Analysis Webpage. Available online: http://math.colgate.edu/math329/exampleode.py (accessed on 14 August 2022).
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019. [Google Scholar] [CrossRef]
- Ahmed, H.; Ríos, H.; Salgado, I. Chapter 13—Robust Synchronization of Master Slave Chaotic Systems: A Continuous Sliding-Mode Control Approach with Experimental Study. Recent Adv. Chaotic Syst. Synchron. 2019, 261–275. [Google Scholar] [CrossRef]
- Hu, K.; Chung, K.-W. On the stability analysis of a pair of van der Pol oscillators with delayed self-connection, position and velocity couplings. AIP Adv. 2013, 3, 112118. [Google Scholar] [CrossRef] [Green Version]
- Elfouly, M.A.; Sohaly, M.A. Van der Pol model in two-delay differential equation representation. Sci. Rep. 2022, 12, 2925. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 3 | 5 | 7 | 9 | |
|---|---|---|---|---|---|
| 329.82 | 618.97 | 713.30 | 261.37 | 480.77 | |
| 5.70 | 6.01 | 5.26 | 6.21 | 5.66 | |
| 6.68 | 7.23 | 5.99 | 6.07 | 6.87 | |
| 8.35 | 6.63 | 7.62 | 6.46 | 6.06 |
| 1 | 3 | 5 | 7 | 9 | 10 | |
|---|---|---|---|---|---|---|
| 713.30 | 257.64 | 305.91 | 225.15 | 197.76 | 199.52 | |
| 5.26 | 10.33 | 7.77 | 6.45 | 5.38 | 5.12 | |
| 5.99 | 5.61 | 6.84 | 6.02 | 5.52 | 5.30 | |
| 7.62 | 5.94 | 5.12 | 5.83 | 5.26 | 5.42 |
| 𝓕𝓕 | 𝓕𝓑 | 𝓒 | ||
|---|---|---|---|---|
| 39.4999 | 1.0000 | 0.8000 | 0.6826 | |
| 93.3585 | 1.0000 | 1.0905 | 0.9065 | |
| 93.6090 | 1.0000 | 0.7861 | 0.6903 | |
| 40.4602 | 1.0000 | 0.9396 | 0.9613 | |
| 79.3355 | 1.0000 | 1.1337 | 0.9340 | |
| 135.6084 | 1.0000 | 1.1388 | 1.4487 | |
| 51.5006 | 1.0000 | 0.9444 | 1.7391 | |
| 38.6258 | 1.0000 | 1.3359 | 1.5176 | |
| 34.2228 | 1.0000 | 1.0326 | 1.1063 | |
| 42.8036 | 1.0000 | 1.0494 | 1.0228 | |
| 47.5353 | 1.0000 | 0.9779 | 0.9446 |
| 𝓒 | 𝓕𝓕 | 𝓕𝓑 | ||
|---|---|---|---|---|
| 2.1379 | 1.7199 | 2.0618 | 0.2225 | |
| 0.3645 | 0.4124 | 0.4473 | 0.2102 | |
| 0.3884 | 0.4245 | 0.6694 | 0.2128 | |
| 0.4168 | 0.4260 | 0.7288 | 0.3387 | |
| 0.4232 | 0.4264 | 0.7408 | 0.2788 | |
| 0.3884 | 0.4245 | 0.6694 | 0.2056 | |
| 0.8889 | 0.4306 | 0.6327 | 0.6590 | |
| 0.8819 | 0.4353 | 0.6387 | 0.6074 | |
| 0.8782 | 0.4425 | 0.6432 | 0.6345 | |
| 0.8757 | 0.4443 | 0.6466 | 0.7101 | |
| 0.8748 | 0.4847 | 0.6481 | 0.6690 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, H.; Sands, T. Comparison of Deep Learning and Deterministic Algorithms for Control Modeling. Sensors 2022, 22, 6362. https://doi.org/10.3390/s22176362
Zhai H, Sands T. Comparison of Deep Learning and Deterministic Algorithms for Control Modeling. Sensors. 2022; 22(17):6362. https://doi.org/10.3390/s22176362
Chicago/Turabian StyleZhai, Hanfeng, and Timothy Sands. 2022. "Comparison of Deep Learning and Deterministic Algorithms for Control Modeling" Sensors 22, no. 17: 6362. https://doi.org/10.3390/s22176362
APA StyleZhai, H., & Sands, T. (2022). Comparison of Deep Learning and Deterministic Algorithms for Control Modeling. Sensors, 22(17), 6362. https://doi.org/10.3390/s22176362