
Deep Learning-Based Subtask Segmentation of Timed Up-and-Go Test Using RGB-D Cameras



Abstract
:1. Introduction
- We propose a novel DL-based subtask segmentation of the TUG test using an RGB-D camera (Azure Kinect). In the proposed method, a dilated temporal convolutional network (TCN) is used to improve the accuracy and processing time of subtask segmentation compared to the existing Bi-LSTM.
- We investigated several inputs to the dilated TCN model to determine the input(s) that is (are) better than the others in the TUG subtask segmentation. We showed that the input from the pelvis alone had the best accuracy among many inputs. This single feature point and the optimized dilated TCN architecture also reduce the processing time in the inference phase.
- We evaluated the proposed method using the newly collected TUG data for three subject groups: (1) healthy young people, (2) older adults, and (3) stroke patients. The test results showed significantly better accuracy and robustness than existing rule-based and artificial neural network (ANN)-based subtask segmentation methods.
2. Related Work
3. Methods
3.1. Data Acquisition System and Participants
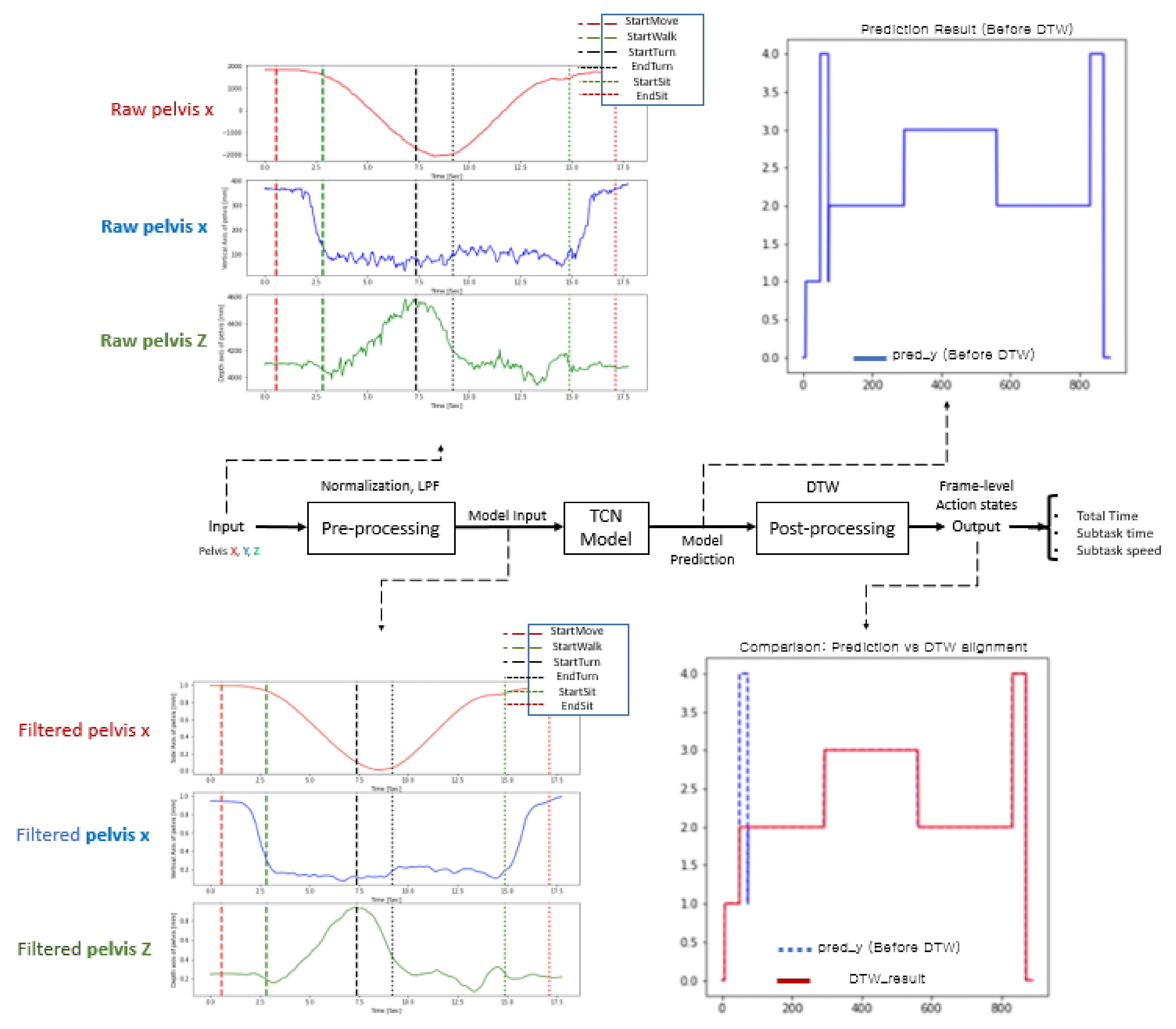
3.2. Proposed Method Overview
3.2.1. Labeling Process
3.2.2. Preprocessing
3.2.3. DL-Based TUG Subtask Segmentation Algorithm
3.2.4. Postprocessing
4. Experiments and Results
4.1. Metrics
4.2. Input Comparison Study
4.3. Optimization of Deep Learning Model
4.4. Comparison with Rule-Based Method
4.4.1. TUG Event Detection
4.4.2. TUG Subtask Segmentation
4.5. Comparison with ANN-Based Method
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Purpose (Method) | Population | System (Sensor) | Inputs | Reason of Input Location |
|---|---|---|---|---|---|
| Hsieh et al. [23] | subtask segmentation (rule-based) | 5 healthy people (25.6 ± 1.36 years old), 5 patients with severe knee osteoarthritis (67.4 ± 2.15 years old) | 3 wearable sensors (3D-Acc/Gyro) | waist, R/L thigh | To acquire body acceleration and angular velocity while focusing on detecting changes of subtasks. (trunk bending, rotating, etc.) |
| Nguyen et al. [28] | subtask segmentation (rule-based) | 16 healthy older adults (9 females; 68.7 ± 9.3 years, 7 males, 67.3 ± 5.8 years) | motion capture suit (17 IMU) (3D-Acc/Gyro), 3D-Magn | each body segment | To capture full-body 3D movement |
| Nguyen et al. [45] | subtask segmentation (rule-based) | 12 older adults diagnosed with early PD (4 females; 67.8 ± 10.4 years; 8 males, 66.6 ± 3.6 years) | motion capture suit (17 IMU) (3D-Acc/Gyro), 3D-Magn | each body segment | To capture full-body 3D movement |
| Lohmann et al. [35] | subtask segmentation (rule-based) | 5 older adults who suffered from age-related medical conditions, 4 healthy young | 2 Kinect for Xbox 360 | shoulder center (vel, acc), distance between R/L shoulder | To detect TUG events while focusing on detecting changes of subtasks |
| Kampel et al. [37] (SkeletonTUG) | subtask segmentation (rule-based) | 11 older adults (89.3 ± 3.6 years) | 1 Kinect v2 | spine shoulder, distance between R/L shoulder | To detect TUG events while focusing on detecting changes of subtasks |
| Kampel et al. [37] (Detph TUG) | subtask segmentation (rule-based) | 11 older adults (89.3 ± 3.6 years) | 1 Kinect v2 | Center of Mass | To acquire moving history data, COM is calculated using silhouette extraction method |
| Salarian et al. [3] | subtask segmentation (rule-based) | 12 older adults in early stages of PD (60.4 ± 8.5 years), 12 age-matched control subjects (60.2 ± 8.2 years) | 7 IMUs | forearms, shanks, thighs, trunk | To detect and analyze each subtask. For example, sensor attached to forearm used to detect walking |
| Hsieh et al. [4] | subtask segmentation (ANN-based) | 26 patients with severe knee osteoarthritis (69.15 ± 6.71 years) | 6 wearable sensors (3D-Acc/Gyro), 2 RGB cameras | chest, lower back, R/L thigh, R/L shank | To acquire body movement from various parts |
| Li et al. [18] | subtask segmentation (ANN-based) | 24 PD patients (56.79± 9.48 years) | 1 RGB camera | neck, R/L shoulder, R/L hip, R/L knee, R/L ankle | In total, 9 body keypoints were used to represent the human poses |
| Savoie et al. [22] | subtask segmentation (ANN-based) | 30 healthy young (26.1 ± 9.4 years) | 1 Kinect V2, 1 RGB camera | center of shoulder, height between the center of feet and nose, right and left hip | To detect TUG events while focusing on detecting changes of the subtasks, e.g., center of shoulder for ‘began to stand’ |
| Ortega-Bastidas et al. [25] | fall risk prediction | 25 healthy young (25–33 years), 12 older adults (59–93 years) | IMU sensor RGB video (GoPro hero 7 for answer) | back (acceleration, angles, and angular velocities) | To detect all gait, biomechanical elements of the pelvis, and other spatial and temporal kinematics factor |
| Jian et al. [42] | fall risk prediction | 40 subjects (most tests were conducted on healthy subjects; few subjects were with high fall risk) | 1 RGB camera, 1 RGBD camera | full joints (3D spatial) | To compute gait characteristics such as gait speed, step length, etc. Fall risk has been predicted based on gait characteristics using ML-method |
| Wang et al. [17] | abnormal gait classification | 404 subjects (subjects are selected to fulfill the requirement of diversity) | 1 RGB camera | vertical location sequence of R/L shoulder | Considering the visibility and stability of joint detection |
References
- Podsiadlo, D.; Richardson, S. The Timed “Up & Go”: A Test of Basic Functional Mobility for Frail Elderly Persons. J. Am. Geriatr. Soc. 1991, 39, 142–148. [Google Scholar] [CrossRef]
- Sprint, G.; Cook, D.J.; Weeks, D.L. Toward Automating Clinical Assessments: A Survey of the Timed Up and Go. IEEE Rev. Biomed. Eng. 2015, 8, 64–77. [Google Scholar] [CrossRef]
- Salarian, A.; Horak, F.B.; Zampieri, C.; Carlson-Kuhta, P.; Nutt, J.G.; Aminian, K. iTUG, a Sensitive and Reliable Measure of Mobility. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 303–310. [Google Scholar] [CrossRef]
- Hsieh, C.-Y.; Huang, H.Y.; Liu, K.C.; Chen, K.H.; Hsu, S.J.; Chan, C.T. Subtask Segmentation of Timed up and Go Test for Mobility Assessment of Perioperative Total Knee Arthroplasty. Sensors 2020, 20, 6302. [Google Scholar] [CrossRef]
- Timmermans, C.; Roerdink, M.; van Ooijen, M.W.; Meskers, C.G.; Janssen, T.W.; Beek, P.J. Walking Adaptability Therapy After Stroke: Study Protocol for a Randomized Controlled Trial. Trials 2016, 17, 425. [Google Scholar] [CrossRef]
- Sebastião, E.; Sandroff, B.M.; Learmonth, Y.C.; Motl, R.W. Validity of the Timed up and Go Test as a Measure of Functional Mobility in Persons with Multiple Sclerosis. Arch. Phys. Med. Rehabil. 2016, 97, 1072–1077. [Google Scholar] [CrossRef]
- Gautschi, O.P.; Corniola, M.V.; Joswig, H.; Smoll, N.R.; Chau, I.; Jucker, D.; Stienen, M.N. The Timed up and Go Test for Lumbar Degenerative Disc Disease. J. Clin. Neurosci. 2015, 22, 1943–1948. [Google Scholar] [CrossRef]
- Clemens, S.M.; Gailey, R.S.; Bennett, C.L.; Pasquina, P.F.; Kirk-Sanchez, N.J.; Gaunaurd, I.A. The Component Timed-Up-and-Go Test: The Utility and Psychometric Properties of Using a Mobile Application to Determine Prosthetic Mobility in People with Lower Limb Amputations. Clin. Rehabil. 2018, 32, 388–397. [Google Scholar] [CrossRef]
- Marques, A.; Cruz, J.; Quina, S.; Regêncio, M.; Jácome, C. Reliability, Agreement and Minimal Detectable Change of the Timed up & Go and the 10-Meter Walk Tests in Older Patients with COPD. COPD J. Chronic Obstr. Pulm. Dis. 2016, 13, 279–287. [Google Scholar] [CrossRef]
- Greene, B.R.; Kenny, R.A. Assessment of Cognitive Decline through Quantitative Analysis of the Timed up and Go Test. IEEE Trans. Biomed. Eng. 2012, 59, 988–995. [Google Scholar] [CrossRef]
- Wall, J.C.; Bell, C.; Campbell, S.; Davis, J. The Timed Get-Up-and-Go Test Revisited: Measurement of the Component Tasks. J. Rehabil. Res. Dev. 2000, 37, 109–113. [Google Scholar]
- Shumway-Cook, A.; Brauer, S.; Woollacott, M. Predicting the Probability for Falls in Community-Dwelling Older Adults Using the Timed Up & Go Test. Phys. Ther. 2000, 80, 896–903. [Google Scholar]
- Vernon, S.; Paterson, K.; Bower, K.; McGinley, J.; Miller, K.; Pua, Y.H.; Clark, R.A. Quantifying Individual Components of the Timed up and Go Using the Kinect in People Living with Stroke. Neurorehabilit. Neural Repair 2015, 29, 48–53. [Google Scholar] [CrossRef]
- Aschneider, F.B.; Valencia, L.S.V.; Bastos-Filho, T.F.; Marques-Ciarelli, P.; Frizera-Neto, A. Automation and segmentation of timed up and go test with single redundant IMU. J. Mech. Eng. Biomech. 2019, 4, 45–51. [Google Scholar] [CrossRef]
- Ponciano, V.; Pires, I.M.; Ribeiro, F.R.; Marques, G.; Garcia, N.M.; Pombo, N.; Spinsante, S.; Zdravevski, E. Is the Timed-Up and Go Test Feasible in Mobile Devices? A Systematic Review. Electronics 2020, 9, 528. [Google Scholar] [CrossRef]
- Ansai, J.H.; De Andrade, L.P.; Nakagawa, T.H.; Rebelatto, J.R. Performances on the Timed up and Go Test and Subtasks Between Fallers and Non-fallers in Older Adults with Cognitive Impairment. Arq. Neuropsiquiatr. 2018, 76, 381–386. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, Q.; Tang, Y.; Wang, Q.; Ding, J.; Wang, X.; Shi, C.-J.R. SAIL: A Deep-Learning-Based System for Automatic Gait Assessment from TUG Videos. IEEE Trans. Hum.-Mach. Syst. 2021, 52, 110–122. [Google Scholar] [CrossRef]
- Li, T.; Chen, J.; Hu, C.; Ma, Y.; Wu, Z.; Wan, W.; Huang, Y.; Jia, F.; Gong, C.; Wan, S.; et al. Automatic Timed up-and-Go Sub-task Segmentation for Parkinson’s Disease Patients Using Video-Based Activity Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 2189–2199. [Google Scholar] [CrossRef]
- Landi, F.; Abbatecola, A.M.; Provinciali, M.; Corsonello, A.; Bustacchini, S.; Manigrasso, L.; Cherubini, A.; Bernabei, R.; Lattanzio, F. Moving Against Frailty: Does Physical Activity Matter? Biogerontology 2010, 11, 537–545. [Google Scholar] [CrossRef]
- Peterson, M.J.; Giuliani, C.; Morey, M.C.; Pieper, C.F.; Evenson, K.R.; Mercer, V.; Cohen, H.J.; Visser, M.; Brach, J.S.; Kritchevsky, S.B.; et al. Physical Activity as a Preventative Factor for Frailty: The Health, Aging, and Body Composition Study. J. Gerontol. Ser. A Biol. Sci. Med. Sci. 2009, 64, 61–68. [Google Scholar] [CrossRef]
- Rubenstein, L.Z.; Josephson, K.R.; Trueblood, P.R.; Loy, S.; Harker, J.O.; Pietruszka, F.M.; Robbins, A.S. Effects of a Group Exercise Program on Strength, Mobility, and Falls Among Fall-Prone Elderly Men. J. Gerontol. Ser. A Biol. Sci. Med. Sci. 2000, 55, M317–M321. [Google Scholar] [CrossRef]
- Savoie, P.; Cameron, J.A.D.; Kaye, M.E.; Scheme, E.J. Automation of the Timed-up-and-Go Test Using a Conventional Video Camera. IEEE J. Biomed. Health Inform. 2021, 24, 1196–1205. [Google Scholar] [CrossRef]
- Hsieh, C.-Y.; Huang, H.-Y.; Liu, K.-C.; Chen, K.-H.; Hsu, S.J.; Chan, C.-T. Automatic Subtask Segmentation Approach of the Timed up and Go Test for Mobility Assessment System Using Wearable Sensors. In Proceedings of the 2019 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Chicago, IL, USA, 19–22 May 2019. [Google Scholar] [CrossRef]
- Hassani, A.; Kubicki, A.; Brost, V.; Yang, F. Preliminary Study on the Design of a Low-Cost Movement Analysis System Reliability Measurement of Timed up and Go Test. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014. [Google Scholar]
- Bergquist, R.; Nerz, C.; Taraldsen, K.; Mellone, S.; Ihlen, E.A.F.; Vereijken, B.; Helbostad, J.L.; Becker, C.; Mikolaizak, A.S. Predicting Advanced Balance Ability and Mobility with an Instrumented Timed up and Go Test. Sensors 2020, 20, 4987. [Google Scholar] [CrossRef]
- Ortega-Bastidas, P.; Aqueveque, P.; Gómez, B.; Saavedra, F.; Cano-de-la-Cuerda, R. Use of a Single Wireless IMU for the Segmentation and Automatic Analysis of Activities Performed in the 3-m Timed up & Go Test. Sensors 2019, 19, 1647. [Google Scholar] [CrossRef]
- Hellmers, S.; Izadpanah, B.; Dasenbrock, L.; Diekmann, R.; Bauer, J.M.; Hein, A.; Fudickar, S. Towards an Automated Unsupervised Mobility Assessment for Older People Based on Inertial TUG Measurements. Sensors 2018, 18, 3310. [Google Scholar] [CrossRef]
- Nguyen, H.P.; Ayachi, F.; Lavigne-Pelletier, C.; Blamoutier, M.; Rahimi, F.; Boissy, P.; Jog, M.; Duval, C. Auto Detection and Segmentation of Physical Activities During a Timed-Up-and-Go (TUG) Task in Healthy Older Adults Using Multiple Inertial Sensors. J. Neuroeng. Rehabil. 2015, 12, 36. [Google Scholar] [CrossRef]
- Reinfelder, S.; Hauer, R.; Barth, J.; Klucken, J.; Eskofier, B.M. Timed Up-and-Go Phase Segmentation in Parkinson’s Disease Patients Using Unobtrusive Inertial Sensors. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Alin-Ionut, P.; Mihai, Z.; Sminchisescu, C. Deep Multitask Architecture for Integrated 2d and 3-d Human Sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Pfister, A.; West, A.M.; Bronner, S.; Noah, J.A. Comparative Abilities of Microsoft Kinect and Vicon 3D Motion Capture for Gait Analysis. J. Med. Eng. Technol. 2014, 38, 274–280. [Google Scholar] [CrossRef]
- Müller, B.; Ilg, W.; Giese, M.A.; Ludolph, N. Validation of Enhanced Kinect Sensor Based Motion Capturing for Gait Assessment. PLoS ONE 2017, 12, e0175813. [Google Scholar] [CrossRef]
- Geerse, D.J.; Coolen, B.H.; Roerdink, M. Kinematic Validation of a Multi-Kinect v2 Instrumented 10-Meter Walkway for Quantitative Gait Assessments. PLoS ONE 2015, 10, e0139913. [Google Scholar] [CrossRef]
- Lohmann, O.; Luhmann, T.; Hein, A. Skeleton Timed up and go. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine, Philadelphia, PA, USA, 4–7 October 2012. [Google Scholar] [CrossRef]
- Van Kersbergen, J.; Otte, K.; de Vries, N.M.; Bloem, B.R.; Röhling, H.M.; Mansow-Model, S.; van der Kolk, N.M.; Overeem, S.; Zinger, S.; van Gilst, M.M. Camera-Based Objective Measures of Parkinson’s Disease Gait Features. BMC Res. Notes 2021, 14, 329. [Google Scholar] [CrossRef]
- Kampel, M.; Doppelbauer, S.; Planinc, R. Automated Timed Up & Go Test for Functional Decline Assessment of Older Adults. In Proceedings of the 12th EAI International Conference on Pervasive Computing Technologies for Healthcare, New York, NY, USA, 21–24 May 2018; pp. 208–216. [Google Scholar] [CrossRef]
- Beyea, J.; McGibbon, C.A.; Sexton, A.; Noble, J.; O’Connell, C. Convergent Validity of a Wearable Sensor System for Measuring Sub-task Performance During the Timed up-and-Go Test. Sensors 2017, 17, 934. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Bai, S.; Zico Kolter, J.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Nguyen, H.; Lebel, K.; Boissy, P.; Bogard, S.; Goubault, E.; Duval, C. Auto Detection and Segmentation of Daily Living Activities During a Timed Up and Go Task in People with Parkinson’s Disease Using Multiple Inertial Sensors. J. Neuroeng. Rehabil. 2017, 14, 26. [Google Scholar] [CrossRef]
- Jian, M.A. Predicting TUG Score from Gait Characteristics with Video Analysis and Machine Learning. bioRxiv 2020. [Google Scholar] [CrossRef]
- Nguyen, M.D.; Mun, K.R.; Jung, D.; Han, J.; Park, M.; Kim, J.; Kim, J. IMU-Based Spectrogram Approach with Deep Convolutional Neural Networks for Gait Classification. In Proceedings of the IEEE International Conference on Consumer Electronics (ICCE); IEEE Publications, Las Vegas, NV, USA, 4–6 January 2020. [Google Scholar] [CrossRef]
- Galán-Mercant, A.; Cuesta-Vargas, A.I. Clinical Frailty Syndrome Assessment Using Inertial Sensors Embedded in Smartphones. Physiol. Meas. 2015, 36, 1929–1942. [Google Scholar] [CrossRef]
- Ayena, J.C.; Chioukh, L.; Otis, M.J.; Deslandes, D. Risk of Falling in a Timed up and Go Test Using An UWB Radar and an Instrumented Insole. Sensors 2021, 21, 722. [Google Scholar] [CrossRef]










| TUG Events | Label | Criteria |
|---|---|---|
| StartMove | 0 | When body is tilted 45 degrees to get up from the chair |
| StartWalk | 1 | After getting up from the chair, when the first step is off the ground |
| StartTurn | 2 | When subject rotates the body to turn at the TUG marker |
| EndTurn | 3 | After turning at the TUG marker, when the body looks back at the chair |
| StartSit | 4 | When body stands against the chair after turning body to sit on the chair |
| EndSit | 5 | When body is titled 45 degrees to lean on the chair |
| Input | Healthy Young | Older Adults | Stroke Patients | ||
|---|---|---|---|---|---|
| Joint | No. | Acc. [%] | Acc. [%] | Acc. [%] | |
| Results | pelvis | input 1 | 95.46 | 94.53 | 93.58 |
| spine chest | input 2 | 94.29 | 94.25 | 92.83 | |
| head | input 3 | 94.1 | 93.86 | 90.86 | |
| hand (left/right) | input 4 | 92.24 | 91.32 | 79.46 | |
| ankle(left/right) | input 5 | 89.89 | 86.53 | 80.58 | |
| pelvis, head | input 6 | 94.4 | 94.22 | 91.59 | |
| pelvis, spine chest | input 7 | 94.46 | 94.045 | 92.29 | |
| pelvis, ankle | input 8 | 93.42 | 93.81 | 87.56 | |
| pelvis, hand | input 9 | 93.46 | 93.68 | 87.07 | |
| pelvis, head, spine chest | input 10 | 93.78 | 93.44 | 91.72 | |
| pelvis, head, ankle | input 11 | 93.59 | 93.93 | 90.89 | |
| pelvis, hand, ankle | input 12 | 93.15 | 93.84 | 91.944 | |
| pelvis, head, hand | input 13 | 93.3 | 93.63 | 91.31 | |
| head, hand, ankle | input 14 | 93.25 | 93.39 | 91.72 | |
| pelvis, head spine chest, hand, ankle | input 15 | 93.62 | 93.95 | 92.4 | |
| Title 1 | Kernel Size (Window Size = 8) | Window Size (Kernel Size = 3) | |||||
|---|---|---|---|---|---|---|---|
| 3 | 5 | 7 | 4 | 8 | 16 | 32 | |
| Accuracy | 94.53 | 93.21 | 92.73 | 92.8 | 94.53 | 92.11 | 87.26 |
| # of parameters | 41,879 | 112,537 | 218,521 | 40,921 | 41,879 | 43,801 | 47,641 |
| Number of Temporal Blocks. Number of Conv. Layers | |||
|---|---|---|---|
| 1.1 | 1.2 | 1.3 | |
| Acc [%] | 92.3 | 93.53 | 92.54 |
| 2.1 | 2.2 | 2.3 | |
| Acc [%] | 93.94 | 90.42 | 92.03 |
| 3.1 | 3.2 | 3.3 | |
| Acc [%] | 92.34 | 94.53 | 93.44 |
| 4.1 | 4.2 | 4.3 | |
| Acc [%] | 92.75 | 92.31 | 91.86 |
| Method | MAE, STD, Precision, Recall, and F1 Score of TUG Phases | |||||||
|---|---|---|---|---|---|---|---|---|
| Metric | Total TUG Time | Sit-to-Stand | Walk | Turn #1 | Walk | Turn #2 | Stand-to-Sit | |
| Skeleton TUG [37] | MAE | 0.227 | 1.024 | 0.903 | 1.061 | 1.224 | 2.182 | 1.570 |
| Prec. | 0.997 | 0.647 | 0.961 | 0.793 | 0.831 | 0.832 | 0.593 | |
| Recall | 0.990 | 0.928 | 0.906 | 0.871 | 0.983 | 0.759 | 0.952 | |
| F1 score | 0.994 | 0.753 | 0.933 | 0.830 | 0.900 | 0.793 | 0.731 | |
| Proposed method | MAE | 0.221 | 0.138 | 0.134 | 0.182 | 0.196 | - | 0.181 |
| STD | 0.237 | 0.228 | 0.109 | 0.136 | 0.148 | - | 0.145 | |
| Prec. | 0.986 | 0.955 | 0.947 | 0.967 | 0.913 | - | 0.884 | |
| Recall | 0.990 | 0.973 | 0.966 | 0.96 | 0.932 | - | 0.818 | |
| F1 score | 0.988 | 0.964 | 0.957 | 0.963 | 0.923 | - | 0.849 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, Y.; Bae, Y.; Cha, B.; Ryu, J. Deep Learning-Based Subtask Segmentation of Timed Up-and-Go Test Using RGB-D Cameras. Sensors 2022, 22, 6323. https://doi.org/10.3390/s22176323
Choi Y, Bae Y, Cha B, Ryu J. Deep Learning-Based Subtask Segmentation of Timed Up-and-Go Test Using RGB-D Cameras. Sensors. 2022; 22(17):6323. https://doi.org/10.3390/s22176323
Chicago/Turabian StyleChoi, Yoonjeong, Yoosung Bae, Baekdong Cha, and Jeha Ryu. 2022. "Deep Learning-Based Subtask Segmentation of Timed Up-and-Go Test Using RGB-D Cameras" Sensors 22, no. 17: 6323. https://doi.org/10.3390/s22176323
APA StyleChoi, Y., Bae, Y., Cha, B., & Ryu, J. (2022). Deep Learning-Based Subtask Segmentation of Timed Up-and-Go Test Using RGB-D Cameras. Sensors, 22(17), 6323. https://doi.org/10.3390/s22176323