
Frequency, Time, Representation and Modeling Aspects for Major Speech and Audio Processing Applications


Abstract
:1. Introduction
2. Related Work
2.1. Speech Emotion Recognition
2.2. Speaker Recognition
2.3. Speech Recognition
2.4. Audio Event Recognition
3. Materials and Methods
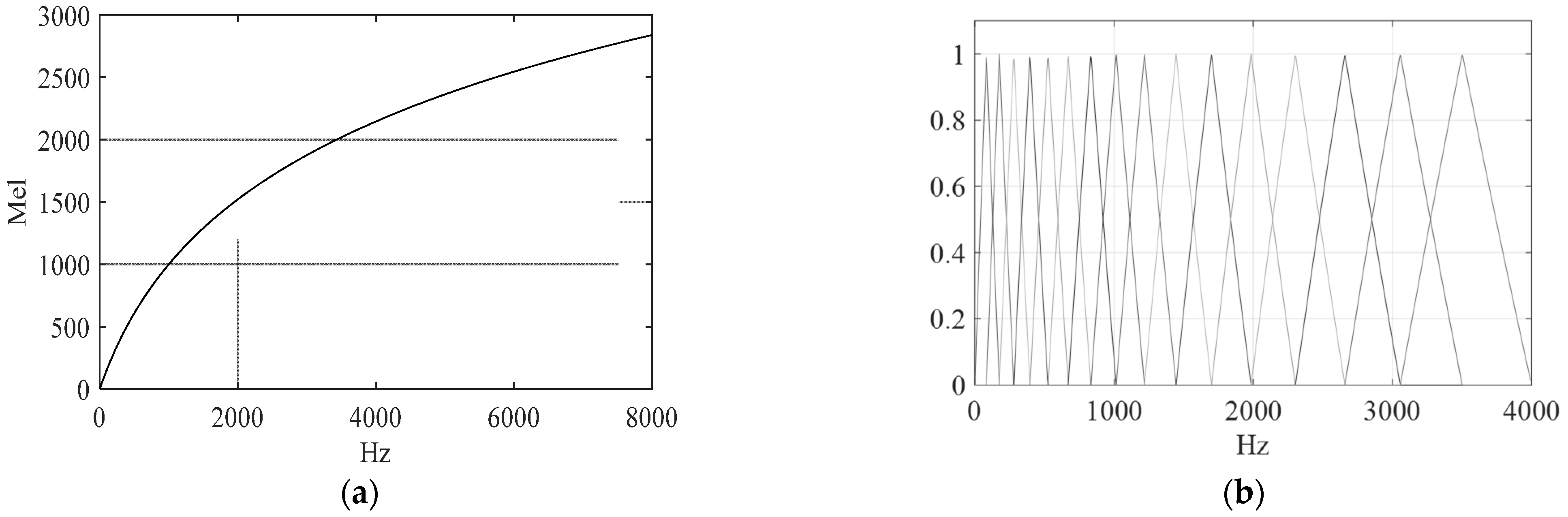
3.1. Theoretical Background on Speech, Audio Signals, and Perception
3.2. Selection of Methods
3.3. Spectrograms
3.4. Vocal Tract-Based Features—Filter Banks and Cepstral Coefficients
3.5. Quantization
3.6. Convolutional Neural Networks
4. Experimental Settings and Datasets
4.1. Software and Hardware
4.2. Databases
4.2.1. Speech Emotion Database
4.2.2. Speaker Recognition Database
4.2.3. Speech Recognition Database
4.2.4. Audio Events Database
4.3. Networks and Training
5. Results
5.1. Time and Segmentation
5.1.1. Emotion Recognition
5.1.2. Speaker Recognition
5.1.3. Speech Recognition
5.1.4. Audio Event Recognition
5.2. Frequency Ranges
5.2.1. Emotion Recognition
5.2.2. Speaker Recognition
5.2.3. Speech Recognition
5.2.4. Audio Event Recognition
5.3. Vocal Tract-Based Features: Filter Banks and Cepstral Coefficients
5.3.1. Emotion Recognition
5.3.2. Speaker Recognition
5.3.3. Speech Recognition
5.3.4. Audio Event Recognition
5.4. Quantization
5.4.1. Emotion Recognition
5.4.2. Speaker Recognition
5.4.3. Speech Recognition
5.4.4. Audio Event Recognition
5.5. Modeling Considerations
5.5.1. Emotion Recognition
5.5.2. Speaker Recognition
5.5.3. Speech Recognition
5.5.4. Audio Event Recognition
6. Discussion
- The best results were observed for a frequency range of 0 to 8 kHz, in line with expectations; however, using only a 4 kHz range caused only a small drop in the accuracy, i.e., by approx. 1%. On the other hand, the importance of low frequencies, i.e., less than 300 Hz, was more obvious, where more than a 6.5% decrease could be observed.
- In the case of time–frequency resolution, 20 ms-long windows provided the best results, whereas shorter shifts between adjacent frames were preferred. This resulted in more training data that were, on the other hand, more redundant. The recognition accuracy naturally grew with the length of analyzed speech intervals; however, the increase became saturated over the 1 s interval.
- The quantization was not relevant to the accuracy; i.e., all the tested settings provided rather similar results, e.g., in the worst case (8 bit linear) the decrease in recognition rate was only 1.3%, but using only half of the original precision.
- The representation of speech using MFBs (60) brought a 3.8% improvement compared to basic spectrograms while saving FV size. Thus, MFBs in combination with CNNs present more suitable FVs than spectrograms.
- Quite similar results were observed across CNNs of different complexities, i.e., 2, 3, and 4-layer CNNs with approx. 170 k, 145 k, and 310 k of free parameters varied at most by 5.2%, with CNN 2 being the best scorer. This suggests that even a CNN having 2 convolutional layers with approx. 150 k parameters fits such an application, while providing competitive results. This is in line with the findings in [7] showing that the deployment of complex pre-trained networks was of limited benefits.
- The best performance was observed in the 0–8 kHz frequency band, which provides valuable extra information for the speaker recognition task. If, for any reason, only a 4 kHz range is available, then more than a 3% drop in the accuracy can be anticipated. Lower frequencies (under 300 Hz) proved to be important as they could increase the accuracy by more than 2.8%.
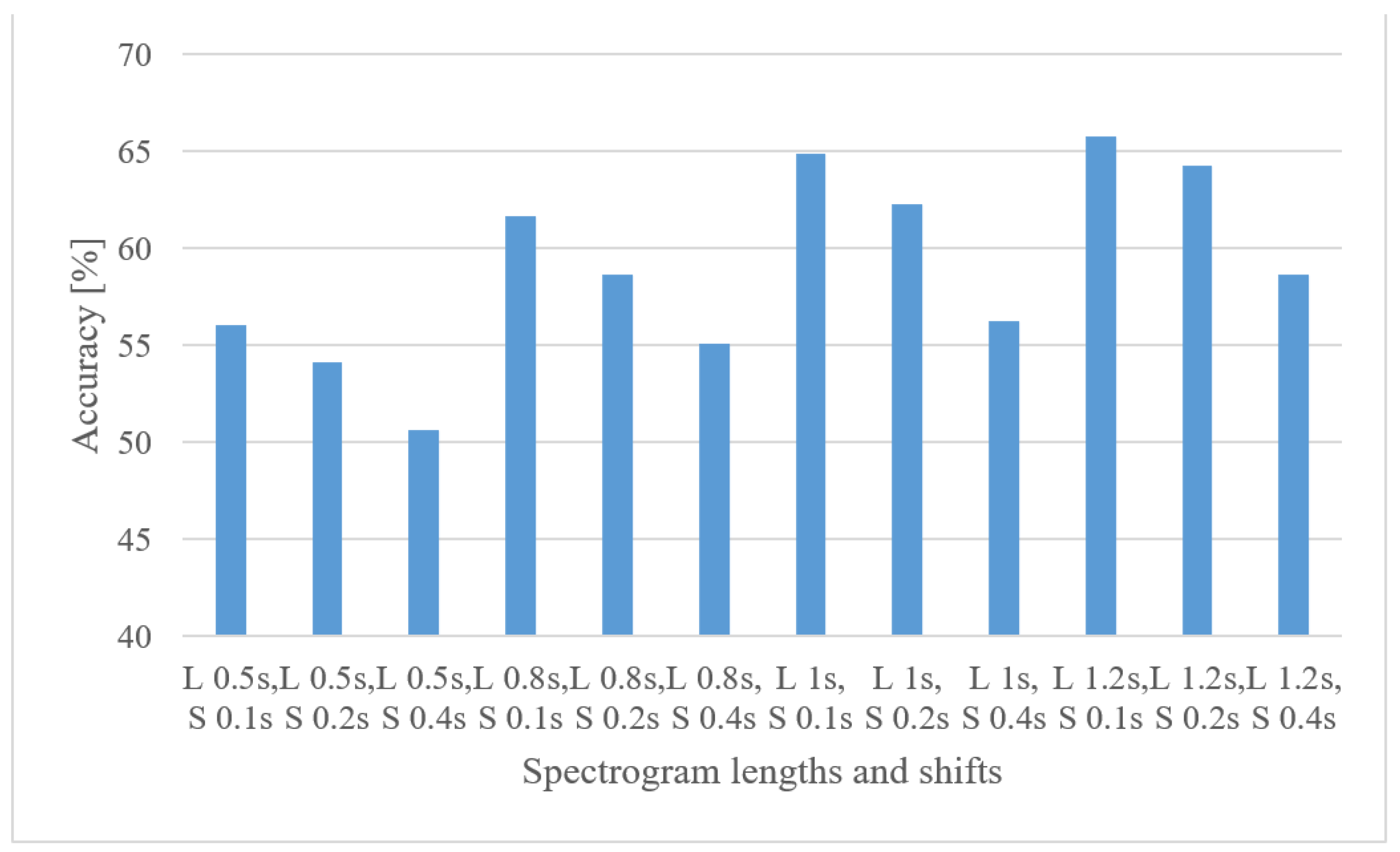
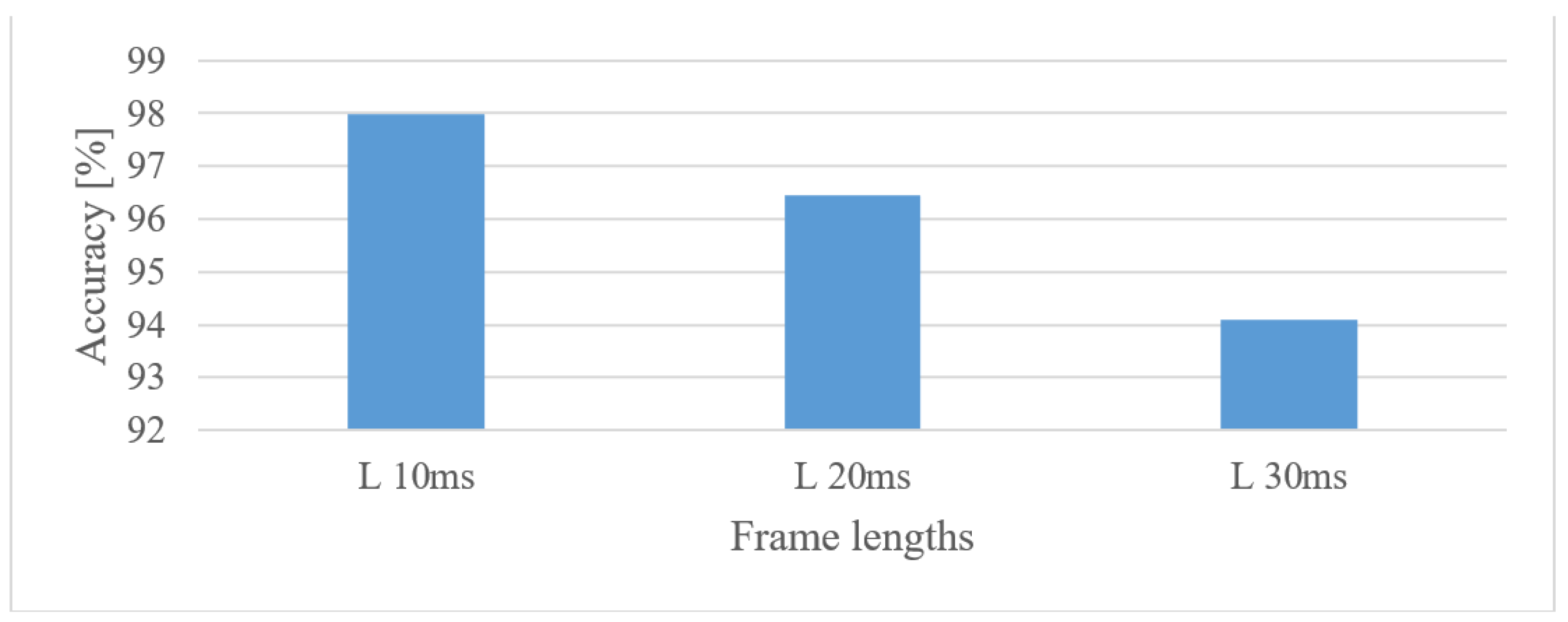
- When speech frames are regarded, 10 ms-long windows recorded the best scores. This may suggest that the time structure (resolution) was more emphasized. However, this may be partly attributed to the existence of more data as there were more frames. Using shorter windows (10 ms) than the common 20 ms ones increased the accuracy by more than 1.5%. Furthermore, increasing the analyzed speech intervals steadily improved the recognition accuracy up to a duration of 3 s. After this the accuracy saturated and longer intervals, e.g., 4 or 5 s, increased FV sizes and delays more than the accuracy.
- The tested quantization schemes (ranging from 16 to 8 bits) had no significant effect on the accuracy, and the recorded variations can be more attributed to the stochastic nature of the training process, i.e., there was only a 0.2% difference in the accuracy when comparing the best (12 bit linear) and the worst (8 bit linear) cases.
- The vocal tract features represented by MFB and MFCC did not improve the results obtained by spectrograms. In fact, more than a 5.4% decrease in the accuracy was observed in the best settings. Spectrograms preserve some information about excitation signals, e.g., fundamental frequency, and that may be valuable for speaker recognition as well. On the other hand, vocal tract features, especially MFCCs, reduced the FV size.
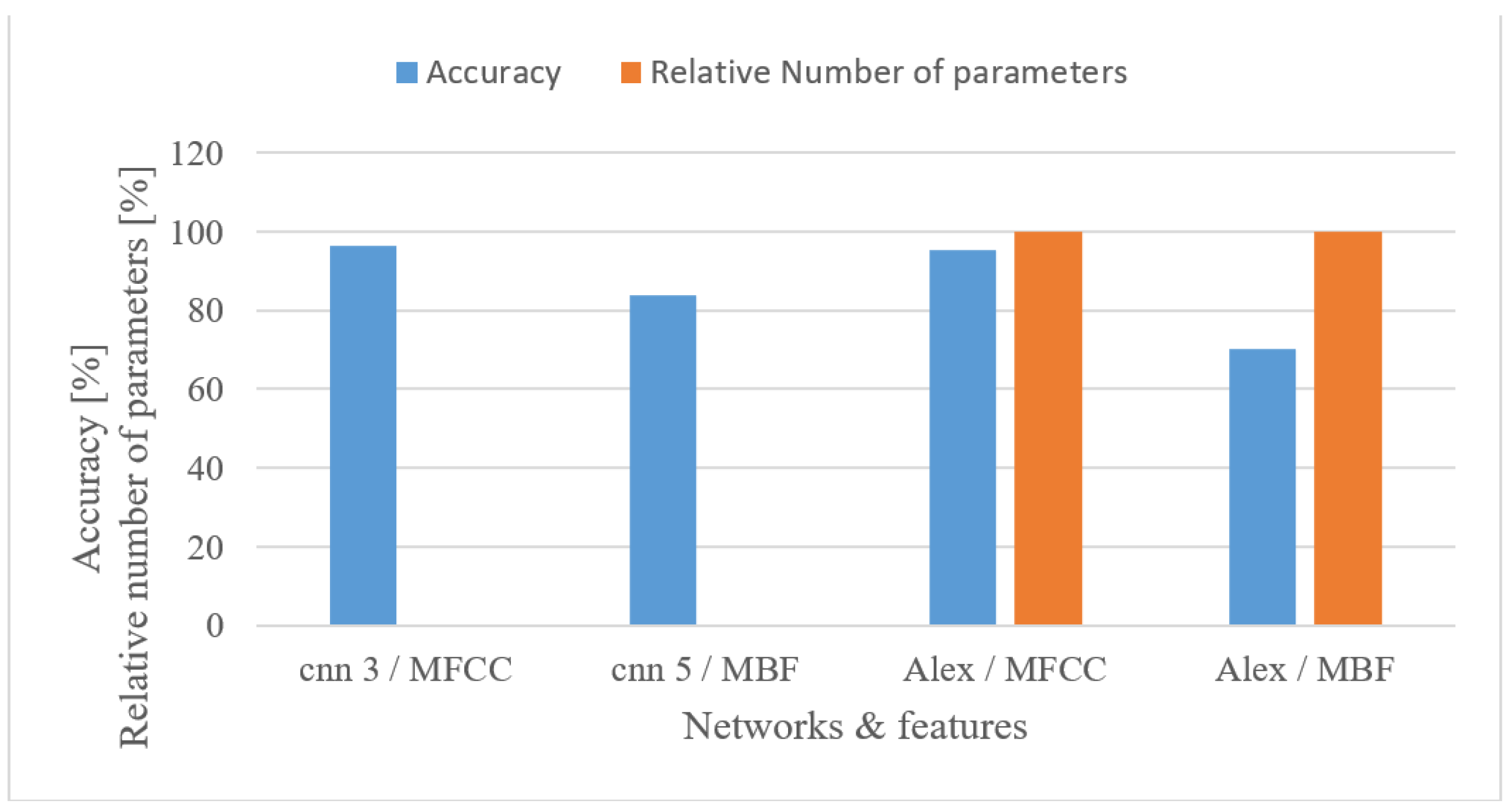
- The effect of complexity was tested using 2 custom but still optimized CNNs (CNN3, CNN5) and the Alexnet for MFB and MFCC features. In both cases, the custom networks slightly outperformed the Alexnet (Figure 21), while using only a fraction of free parameters, i.e., 0.098% (3-layer CNN) and 0.065% (5-layer CNN). This suggests that even low-complexity networks having 3 to 5 layers and approx. 60 k parameters can achieve outstanding results.
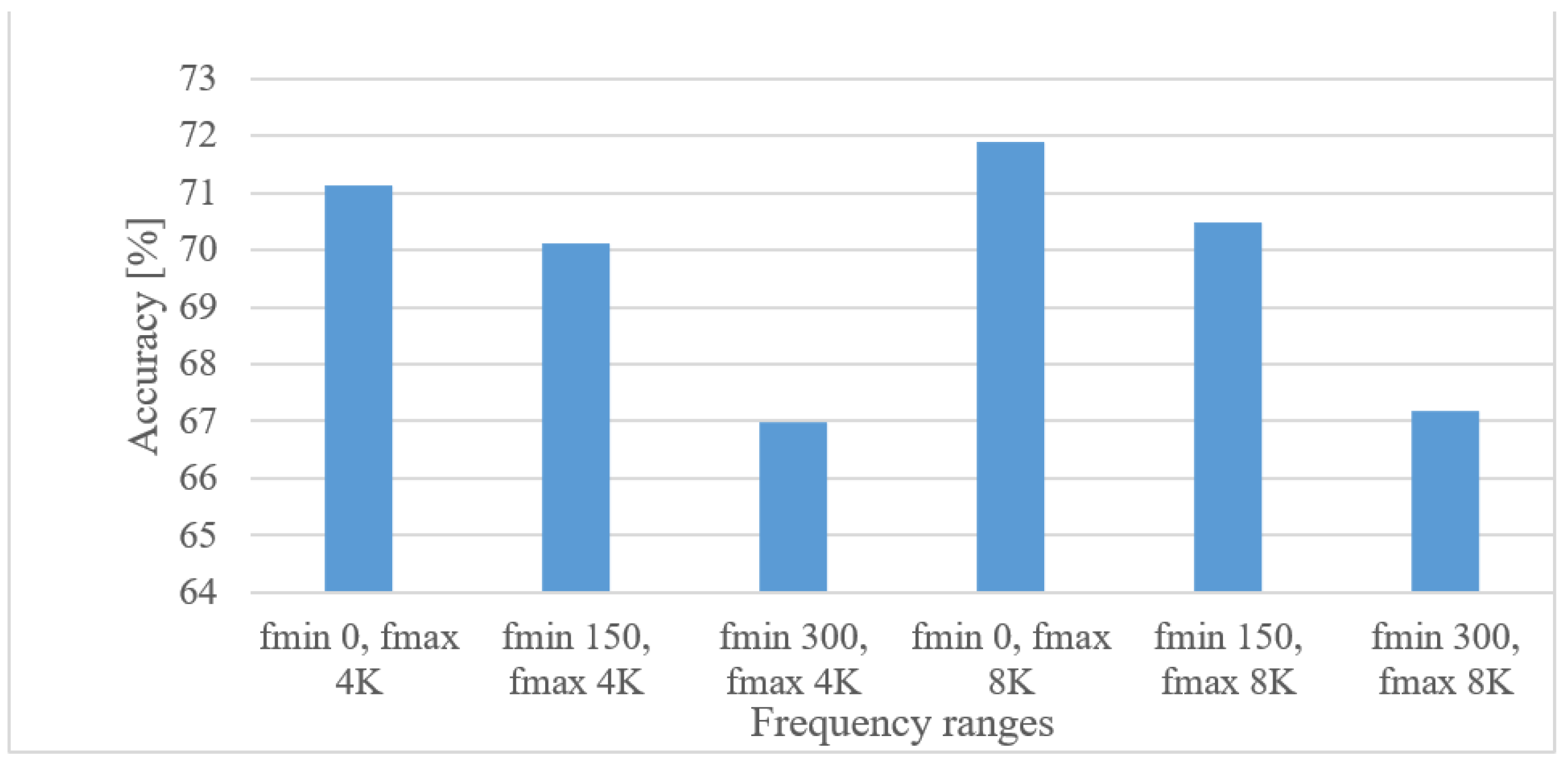
- The best performance was provided by a frequency range of 0 to 4 kHz for both magnitude-based and log spectrograms. This is not surprising as such a band is a standard for speech recognition. The 8 kHz band caused a decrease in the accuracy for all tested cases, and moreover, it somehow disrupted the otherwise homogeneous positive effect of low frequencies, especially in the case of log spectrograms. This may indicate that outside this common range there is mostly non-lexical information and noise that is even emphasized by a log function.
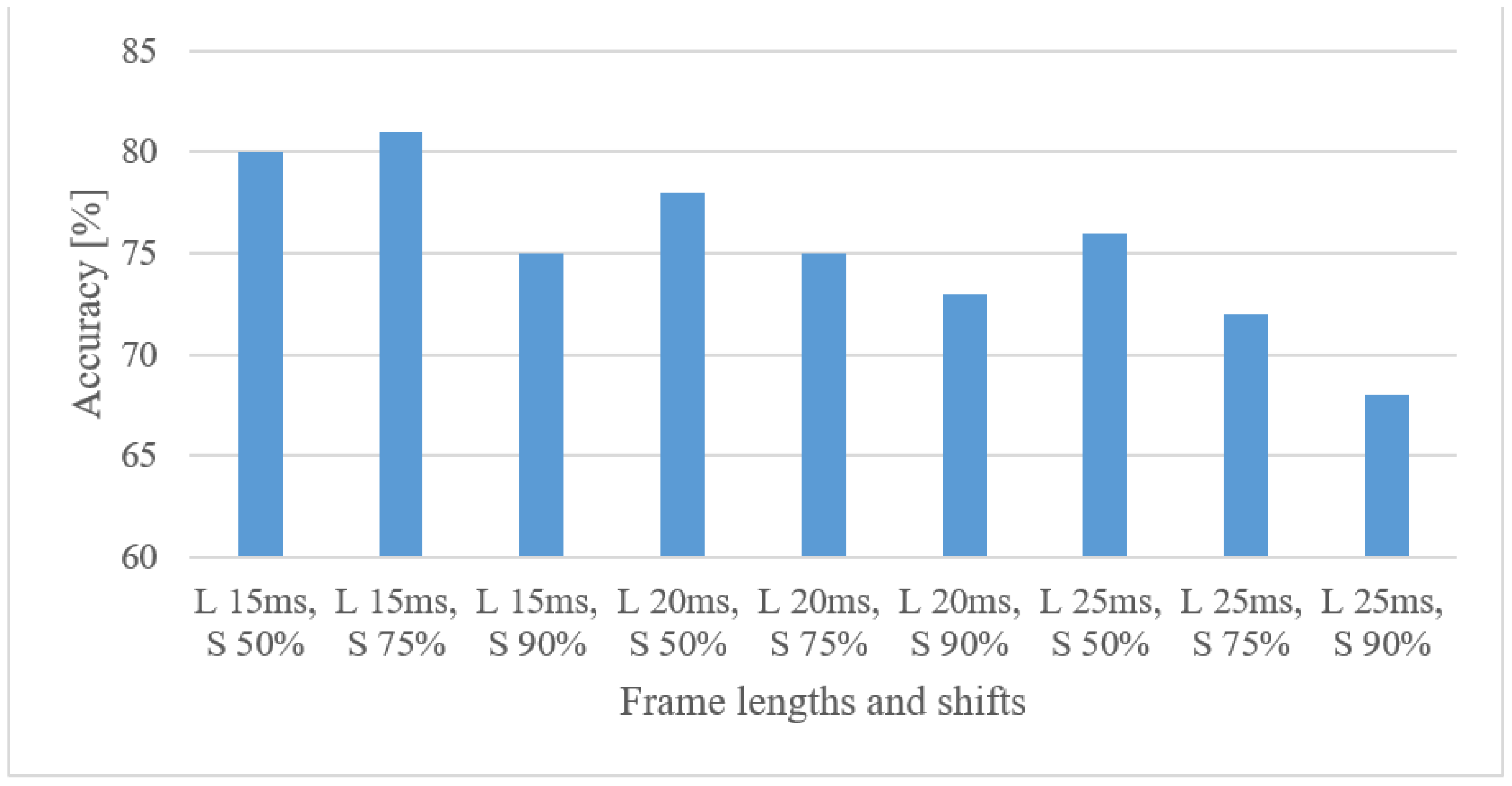
- When a time–frequency resolution is regarded (Figure 7), 15 ms-long windows provided the best results, as well as the shorter shifts between adjacent frames. Both parameters resulted in more training data, which were, however, more redundant. Furthermore, shorter windows prioritized time resolution over frequency, which seemed to be beneficial in combination with CNNs.
- Quantization was tested both for spectrograms and MFBs. Here, the adverse effect of low bit representation, i.e., 8 bit linear, was the most apparent of all applications. Using an 8 bit linear quantization led to 7.6% (spectrogram) and 12% (MFB) degradations in the recognition rate. However, the less severe quantization schemes (12 bit and 8 bit μ-law) performed much better. This indicates that the lexical information encoded in speech signals is more sensitive to the degradation caused by quantization.
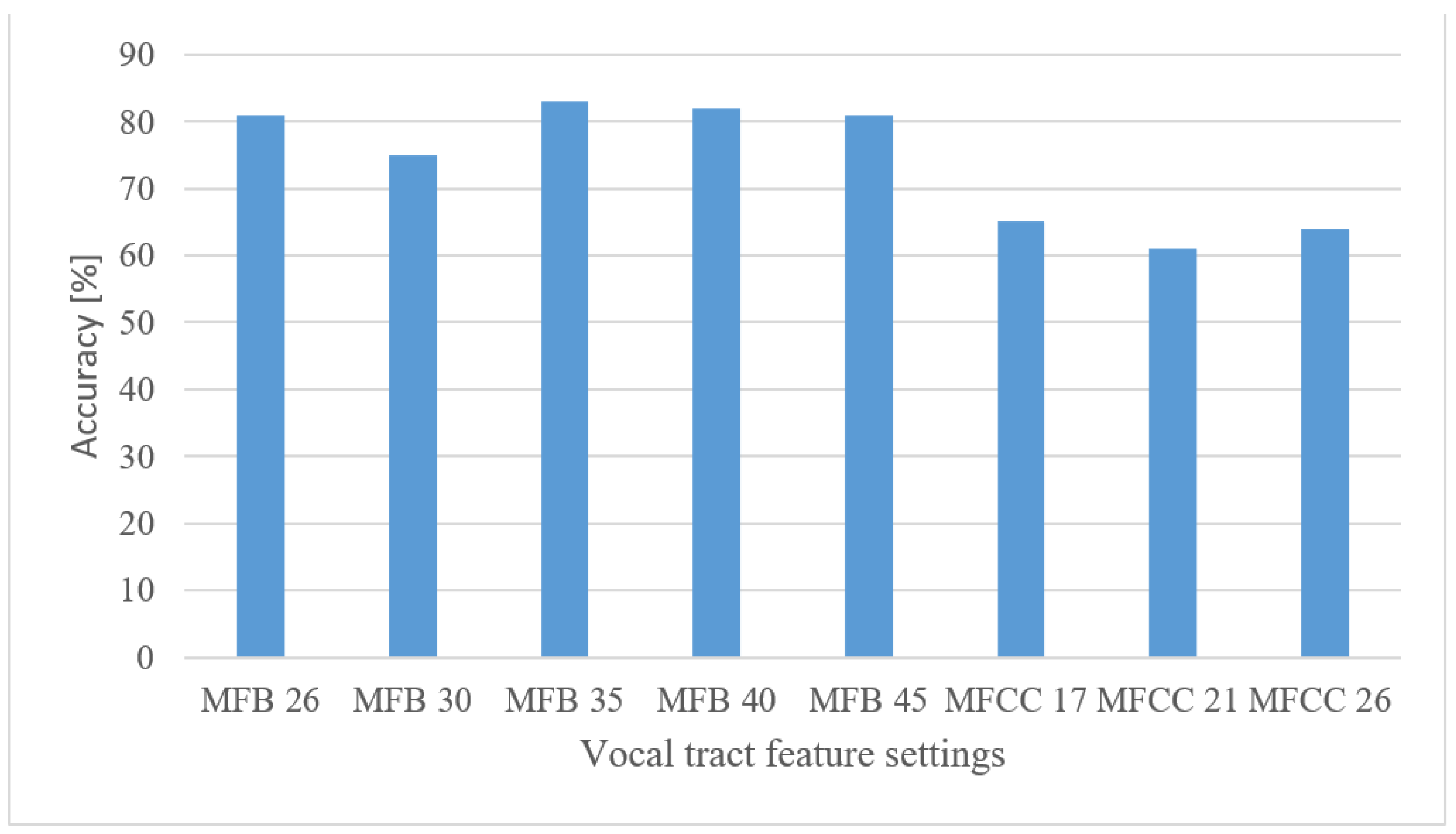
- Properly set MFBs, i.e., having 35–45 banks, provided almost similar results compared to basic spectrograms, while using shorter FVs. However, the more compressed MFCCs features failed in combination with CNNs as they scored approx. 23% worse than spectrograms.
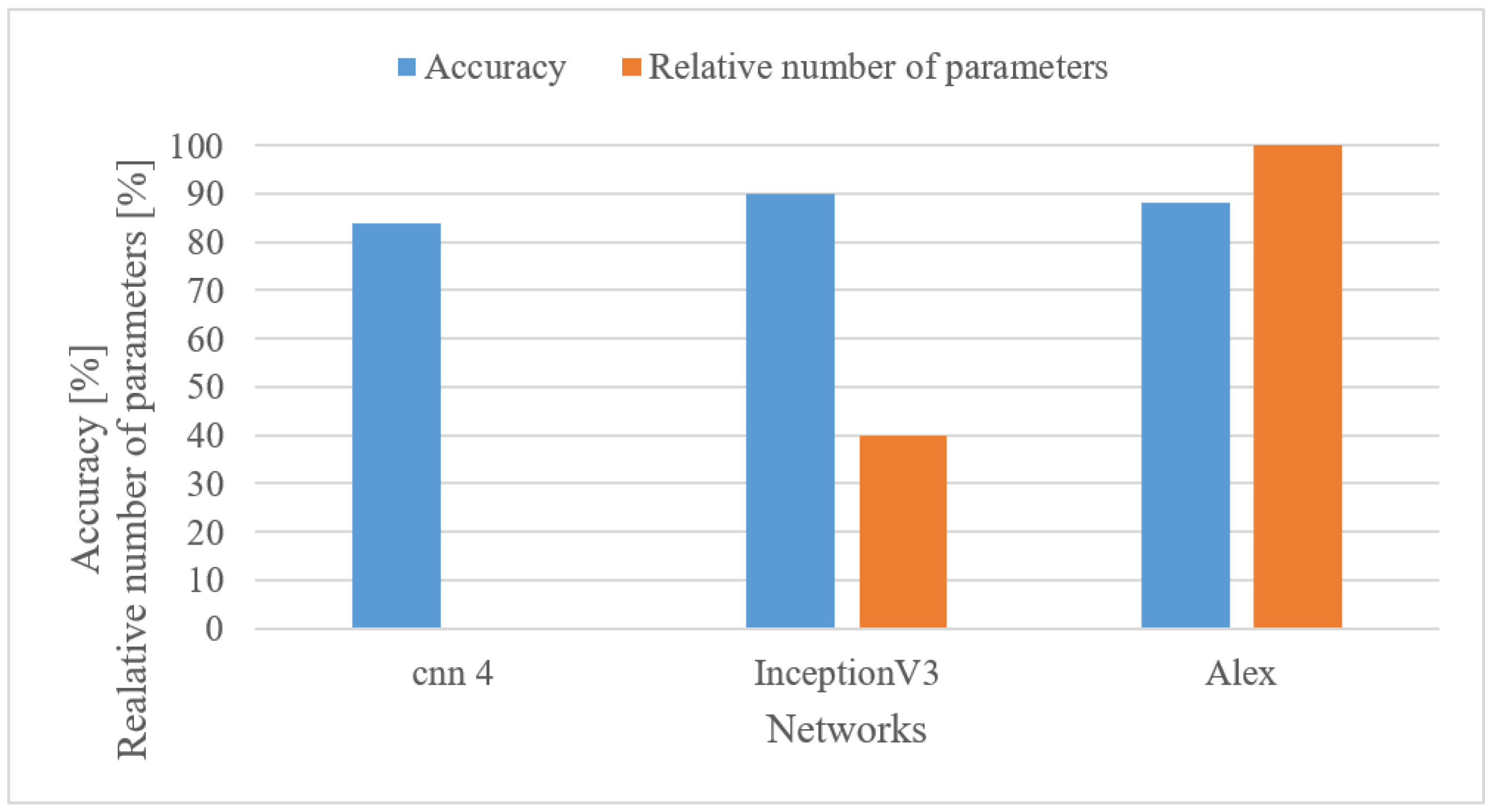
- The more complex and pre-trained networks (Alexnet and Inception V3) achieved better results than the custom-designed 4-layer CNN having only approx. 55 k parameters. There was a 7.1% increase in accuracy; however, the custom network used only 0.22% of free parameters of the Inception V3 network. Nevertheless, this gives designers an option of making a trade-off between accuracy and complexity.
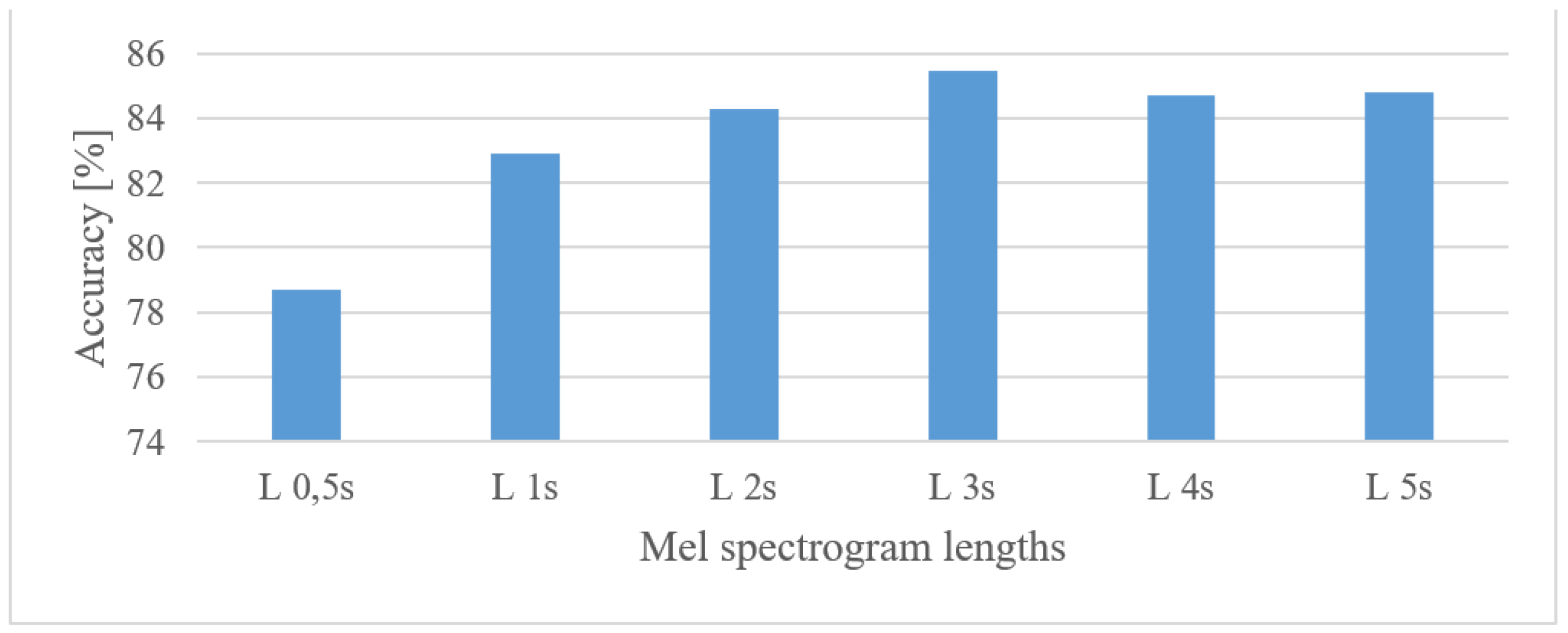
- By averaging the results over lower and upper frequency limits separately, the reasonable band was approx. 100 Hz–17.5 kHz. This means that many events in the environment have significant information located also in higher frequencies. If only limited band, e.g., up to 4 kHz is assumed, one can expect approx. a 12% decrease in the accuracy.
- In the frame length test (Figure 8) the results showed a high degree of insensitivity to the tested sizes (20–50 ms). In spite of an outlier, there seems to be a trend of preferring shorter windows, e.g., 20 ms ones similar to speech processing applications. When the lengths of analyzed time intervals are considered, the best results were observed in the range from 0.75 to 1 s.
- Quantization tests (Figure 19) provided rather unexpected results. No matter how weird these may look, they can still have explanations other than just the “random nature” of the training. We suspect that the following phenomenon may have taken place here. First, the quantization may have suppressed or normalized some noise (background) that deteriorated the recognition process. This is because high-frequency components (e.g., over 8 kHz) usually tend to rapidly vanish for common signals, meaning that such components are most of the time rather noisy, and by introducing coarser quantization, such noise can be partly suppressed or normalized. Next, the quantization noise may have masked portions of signals that were confusing in the classification stage for most similar classes, or the quantization may have reduced variability for some classes of signals, i.e., introducing some sort of normalization, etc. However, a more credible explanation of this phenomenon requires a different and thorough investigation. Here, only the benefits of coarser quantization were measured and presented.
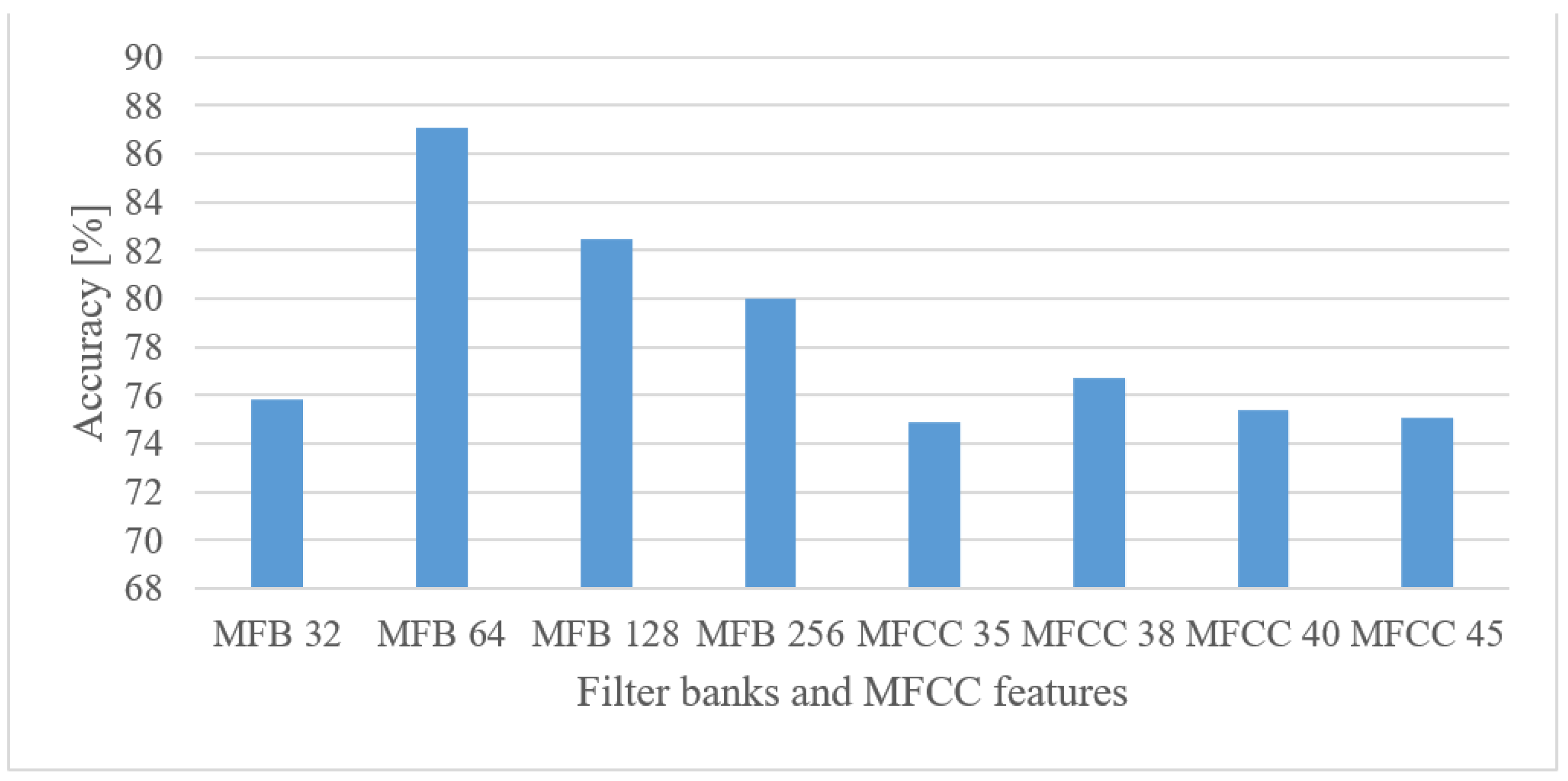
- MFBs (64) proved to be beneficial for AER as they slightly outperformed the basic representation by spectrograms, while reducing the FV size. On the other hand, the more compact features of MFCC failed, as they caused approx. a 12% decrease in the accuracy.
- The pre-trained complex models scored better than the custom small-size networks by 7.3% when the best cases were compared. However, when relative complexity is considered, the custom-designed network had only 0.19% of VGG19 parameters. Such a comparison urges a designer to make a proper trade-off between complexity and computational load and accuracy.
- Even though CNNs are a very complex classification method with outstanding results in image/speech processing, we cannot reject the fact that the findings here can be partly affected by their limitations (structure, training algorithm, numerical precisions, etc.).
- Some settings especially related to the model complexity are class size-dependent, i.e., the complexity may differ based on the number of classes these systems are to recognize. This may substantially vary for applications such as speech recognition (30 words were tested), speaker recognition (251 speakers), and audio events (8 events).
- Even though some datasets also contained noise (real environment), this may still be slightly different from a particular deployment scenario.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic speech recognition: A survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Greenberg, C.S.; Mason, L.P.; Sadjadi, S.O.; Reynolds, D.A. Two decades of speaker recognition evaluation at the national institute of standards and technology. Comput. Speech Lang. 2020, 60, 101032. [Google Scholar] [CrossRef]
- Cen, L.; Wu, F.; Yu, Z.L.; Hu, F. A Real-Time Speech Emotion Recognition System and its Application in Online Learning. In Emotions, Technology, Design, and Learning, 1st ed.; Tettegah, S.Y., Gartmeier, M., Eds.; Academic Press: San Diego, IL, USA, 2016; pp. 27–46. [Google Scholar] [CrossRef]
- Politis, A.; Mesaros, A.; Adavanne, S.; Heittola, T.; Virtanen, T. Overview and evaluation of sound event localization and detection in DCASE 2019. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 684–698. [Google Scholar] [CrossRef]
- Rabiner, L.; Juan, B.H. Fundamentals of Speech Recognition; PTR Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Bosch, E.; Oehl, M.; Jeon, M.; Alvarez, I.; Healey, J.; Ju, W.; Jallais, C. Emotional GaRage: A workshop on in-car emotion recognition and regulation. In Proceedings of the Adjunct 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI ‘18). Association for Computing Machinery, Toronto, Canada, 23–25 September 2018; pp. 44–49. [Google Scholar] [CrossRef] [Green Version]
- Badshah, A.; Ahmad, J.; Rahim, N.; Baik, S. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the International Conference on Platform Technology and Service, Busan, Korea, 13–15 February 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Badshah, A.M.; Rahim, N.; Ullah, N.; Ahmad, J.; Muhammad, K.; Lee, M.Y.; Kwon, S.; Baik, S.W. Deep features-based speech emotion recognition for smart affective services. Multimed. Tools Appl. 2019, 78, 5571–5589. [Google Scholar] [CrossRef]
- Zheng, L.; Li, Q.; Ban, H.; Liu, S. Speech emotion recognition based on convolution neural network combined with random forest. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 4143–4147. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Z.; Jin, J.S.; Han, X.; Li, C. Speech emotion recognition with heterogeneous feature unification of deep neural network. Sensors 2019, 19, 2730. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mansour, A.; Chenchah, F.; Lachiri, Z. Emotional speaker recognition in real life conditions using multiple descriptors and i-vector speaker modeling technique. Multimed. Tools Appl. 2019, 78, 6441–6458. [Google Scholar] [CrossRef]
- Kumar, P.; Jain, S.; Raman, B.; Roy, P.P.; Iwamura, M. End-to-end Triplet Loss based Emotion Embedding System for Speech Emotion Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8766–8773. [Google Scholar] [CrossRef]
- Kacur, J.; Puterka, B.; Pavlovicova, J.; Oravec, M. On the Speech Properties and Feature Extraction Methods in Speech Emotion Recognition. Sensors 2021, 21, 1888. [Google Scholar] [CrossRef] [PubMed]
- Abbaschian, B.J.; Sierra-Sosa, D.; Elmaghraby, A. Deep Learning Techniques for Speech Emotion Recognition, from Databases to Models. Sensors 2021, 21, 1249. [Google Scholar] [CrossRef] [PubMed]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814, 2021. [Google Scholar] [CrossRef]
- Pal, M.; Kumar, M.; Peri, R.; Park, T.J.; Hyun Kim, S.; Lord, C.; Bishop, S.; Narayanan, S. Speaker diarization using latent space clustering in generative adversarial network. In Proceedings of the 2020 International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 6504–6508. [Google Scholar]
- Kelly, F.; Forth, O.; Kent, S.; Gerlach, L.; Alexander, A. Deep neural network based forensic automatic speaker recognition in VOCALISE using x-vectors. In Proceedings of the Audio Engineering Society Conference: 2019 AES International Conference on Audio Forensics, Audio Engineering Society, Porto, Portugal, 18–20 June 2019. [Google Scholar]
- Georgescu, A.L.; Cucu, H. GMM-UBM modeling for speaker recognition on a Romanian large speech corpora. In Proceedings of the 2018 International Conference on Communications (COMM), Bucharest, Romania, 14–16 June 2018; pp. 547–551. [Google Scholar]
- Xing, Y.; Tan, P.; Wang, X. Speaker verification normalization sequence kernel based on Gaussian mixture model super-vector and Bhattacharyya distance. J. Low Freq. Noise Vib. Act. Control. 2021, 40, 60–71. [Google Scholar] [CrossRef] [Green Version]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Zhao, Y.; Zhou, T.; Chen, Z.; Wu, J. Improving deep CNN networks with long temporal context for text-independent speaker verification. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 6834–6838. [Google Scholar]
- Bai, Z.; Zhang, X.L. Speaker Recognition Based on Deep Learning: An Overview. Neural Netw. 2021, 140, 65–99. [Google Scholar] [CrossRef]
- Yadav, S.; Rai, A. Frequency and temporal convolutional attention for text-independent speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6794–6798. [Google Scholar]
- Wang, Z.; Yao, K.; Li, X.; Fang, S. Multi-resolution multi-head attention in deep speaker embedding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6464–6468. [Google Scholar]
- Hong, Q.B.; Wu, C.; Wang, H.; Huang, C. Statistics pooling time delay neural network based on x-vector for speaker verification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6849–6853. [Google Scholar]
- Taher, K.I.; Abdulazeez, A.M. Deep learning convolutional neural network for speech recognition: A review. Int. J. Sci. Bus. 2021, 5, 1–14. [Google Scholar]
- Tang, Y.; Wang, J.; Qu, X.; Xiao, J. Contrastive learning for improving end-to-end speaker verification. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–7. [Google Scholar]
- Valizada, A.; Akhundova, N.; Rustamov, S. Development of Speech Recognition Systems in Emergency Call Centers. Symmetry 2021, 13, 634. [Google Scholar] [CrossRef]
- Zhou, W.; Michel, W.; Irie, K.; Kitza, M.; Schluter, R.; Ney, H. The RWTH ASR System for TED-LIUM Release 2: Improving Hybrid HMM with SpecAugment. In Proceedings of the ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 7839–7843. [Google Scholar]
- Zeineldeen, M.; Xu, J.; Luscher, C.; Michel, W.; Gerstenberger, A.; Schluter, R.; Ney, H. Conformer-based Hybrid ASR System for Switchboard Dataset. In Proceedings of the ICASSP, Singapore, 23–27 May 2022; pp. 7437–7441. [Google Scholar]
- Chiu, C.-C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar] [CrossRef] [Green Version]
- Li, J. Recent advances in end-to-end automatic speech recognition. APSIPA Trans. Signal Inf. Process. 2022, 11, e8. [Google Scholar] [CrossRef]
- Smit, P.; Virpioja, S.; Kurimo, M. Advances in subword-based HMM-DNN speech recognition across languages. Comput. Speech Lang. 2021, 66, 101158. [Google Scholar] [CrossRef]
- Renda, W.; Zhang, C.H. Comparative Analysis of Firearm Discharge Recorded by Gunshot Detection Technology and Calls for Service in Louisville, Kentucky. ISPRS Int. J. Geo-Inf. 2019, 8, 275. [Google Scholar] [CrossRef] [Green Version]
- Larsen, H.L.; Pertoldi, C.; Madsen, N.; Randi, E.; Stronen, A.V.; Root-Gutteridge, H.; Pagh, S. Bioacoustic Detection of Wolves: Identifying Subspecies and Individuals by Howls. Animals 2022, 12, 631. [Google Scholar] [CrossRef]
- Bello, J.P.; Silva, C.; Nov, O.; DuBois, R.L.; Arora, A.; Salamon, J.; Mydlarz, C.; Doraiswamy, H. SONYC: A System for the Monitoring, Analysis and Mitigation of Urban Noise Pollution. Commun. ACM 2019, 62, 68–77. [Google Scholar] [CrossRef]
- Grzeszick, R.; Plinge, A.; Fink, G. Bag-of-Features Methods for Acoustic Event Detection and Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1242–1252. [Google Scholar] [CrossRef]
- Abdoli, S.; Cardinal, P.; Koerich, A.L. End-to-End Environmental Sound Classification using a 1D Convolutional Neural Network. Expert Syst. Appl. 2019, 136, 252–263. [Google Scholar] [CrossRef] [Green Version]
- Guzhov, A.; Raue, F.; Hees, J.; Dengel, A. ESResNet: Environmental Sound Classification Based on Visual Domain Models. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4933–4940. [Google Scholar]
- Shin, S.; Kim, J.; Yu, Y.; Lee, S.; Lee, K. Self-Supervised Transfer Learning from Natural Images for Sound Classification. Appl. Sci. 2021, 11, 3043. [Google Scholar] [CrossRef]
- Gerhard, D. Audio Signal Classification: History and Current Techniques; Technical Report TR-CS 2003-07; Department of Computer Science, University of Regina: Regina, SK, Canada, 2003; ISSN 0828-3494. [Google Scholar]
- Shah, V.H.; Chandra, M. Speech Recognition Using Spectrogram-Based Visual Features. In Advances in Machine Learning and Computational Intelligence. Algorithms for Intelligent Systems; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- Arias-Vergara, T.; Klumpp, P.; Vasquez-Correa, J.C.; Nöth, E.; Orozco-Arroyave, J.R.; Schuster, M. Multi-channel spectrograms for speech processing applications using deep learning methods. Pattern Anal. Appl. 2021, 24, 423–431. [Google Scholar] [CrossRef]
- Dua, S.; Kumar, S.S.; Albagory, Y.; Ramalingam, R.; Dumka, A.; Singh, R.; Rashid, M.; Gehlot, A.; Alshamrani, S.S.; AlGhamdi, A.S. Developing a Speech Recognition System for Recognizing Tonal Speech Signals Using a Convolutional Neural Network. Appl. Sci. 2022, 12, 6223. [Google Scholar] [CrossRef]
- Han, K.J.; Pan, J.; Tadala, V.K.N.; Ma, T.; Povey, D. Multistream CNN for Robust Acoustic Modeling. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6873–6877. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A Convolutional Neural Network Cascade for Face Detection. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90, ISSN 0001-0782. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar] [CrossRef]
- Tensorflow. Available online: https://www.tensorflow.org/resources/learn-ml?gclid=EAIaIQobChMI8Iqc57bp-AIV1LLVCh38vgc9EAAYASAAEgIMnvD_BwE (accessed on 7 July 2022).
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.; Weiss, B. A database of German emotional speech. INTERSPEECH. A Database of German Emotional Speech. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Panayotov, A.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brisbane, Queensland, 19–24 April 2015. [Google Scholar] [CrossRef]
- Google’s Speech Commands Dataset. Available online: https://pyroomacoustics.readthedocs.io/en/pypi-release/pyroomacoustics.datasets.google_speech_commands.html (accessed on 7 July 2022).
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shifts [%] | Length 500 ms | Length 750 ms | Length 1000 ms | Length 1500 ms | Average [%] |
|---|---|---|---|---|---|
| Shift 100% | 70.74 | 72.08 | 71.83 | 61.66 | 69.07 |
| Shift 75% | 70.12 | 69.27 | 74.3 | 70 | 70.92 |
| Shift 50% | 72.71 | 75 | 74.35 | 73.25 | 73.82 |
| Shift 25% | 72.9 | 74.09 | 73.92 | 72.24 | 73.28 |
| Average | 71.61 | 72.61 | 73.6 | 69.2875 | - |
| Fmax 4 kHz | Fmax 8 kHz | Fmax 12.5 kHz | Fmax 17.5 kHz | Fmax 22.05 kHz | Average [%] | |
|---|---|---|---|---|---|---|
| Fmin 0 Hz | 75.72 | 79.61 | 81.22 | 79.61 | 81.55 | 79.5 |
| Fmin 100 Hz | 75.08 | 85.37 | 84.78 | 85.11 | 85.76 | 83.2 |
| Fmin 200 Hz | 75.72 | 82.52 | 71.52 | 80.25 | 81.87 | 78.34 |
| Fmin 300 Hz | 74.75 | 72.49 | 78.64 | 83.81 | 79.54 | 77.84 |
| Average | 75.91 | 79.99 | 79.04 | 82.2 | 82.18 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kacur, J.; Puterka, B.; Pavlovicova, J.; Oravec, M. Frequency, Time, Representation and Modeling Aspects for Major Speech and Audio Processing Applications. Sensors 2022, 22, 6304. https://doi.org/10.3390/s22166304
Kacur J, Puterka B, Pavlovicova J, Oravec M. Frequency, Time, Representation and Modeling Aspects for Major Speech and Audio Processing Applications. Sensors. 2022; 22(16):6304. https://doi.org/10.3390/s22166304
Chicago/Turabian StyleKacur, Juraj, Boris Puterka, Jarmila Pavlovicova, and Milos Oravec. 2022. "Frequency, Time, Representation and Modeling Aspects for Major Speech and Audio Processing Applications" Sensors 22, no. 16: 6304. https://doi.org/10.3390/s22166304
APA StyleKacur, J., Puterka, B., Pavlovicova, J., & Oravec, M. (2022). Frequency, Time, Representation and Modeling Aspects for Major Speech and Audio Processing Applications. Sensors, 22(16), 6304. https://doi.org/10.3390/s22166304