
Model-Based Reinforcement Learning with Automated Planning for Network Management

 ,
,  , and
, and
Abstract
:1. Introduction
2. Methodology
3. Background: RL and AP in Network Management
3.1. Reinforcement Learning in Network Management
3.2. Automated Planning
3.3. Model-Based Reinforcement Learning
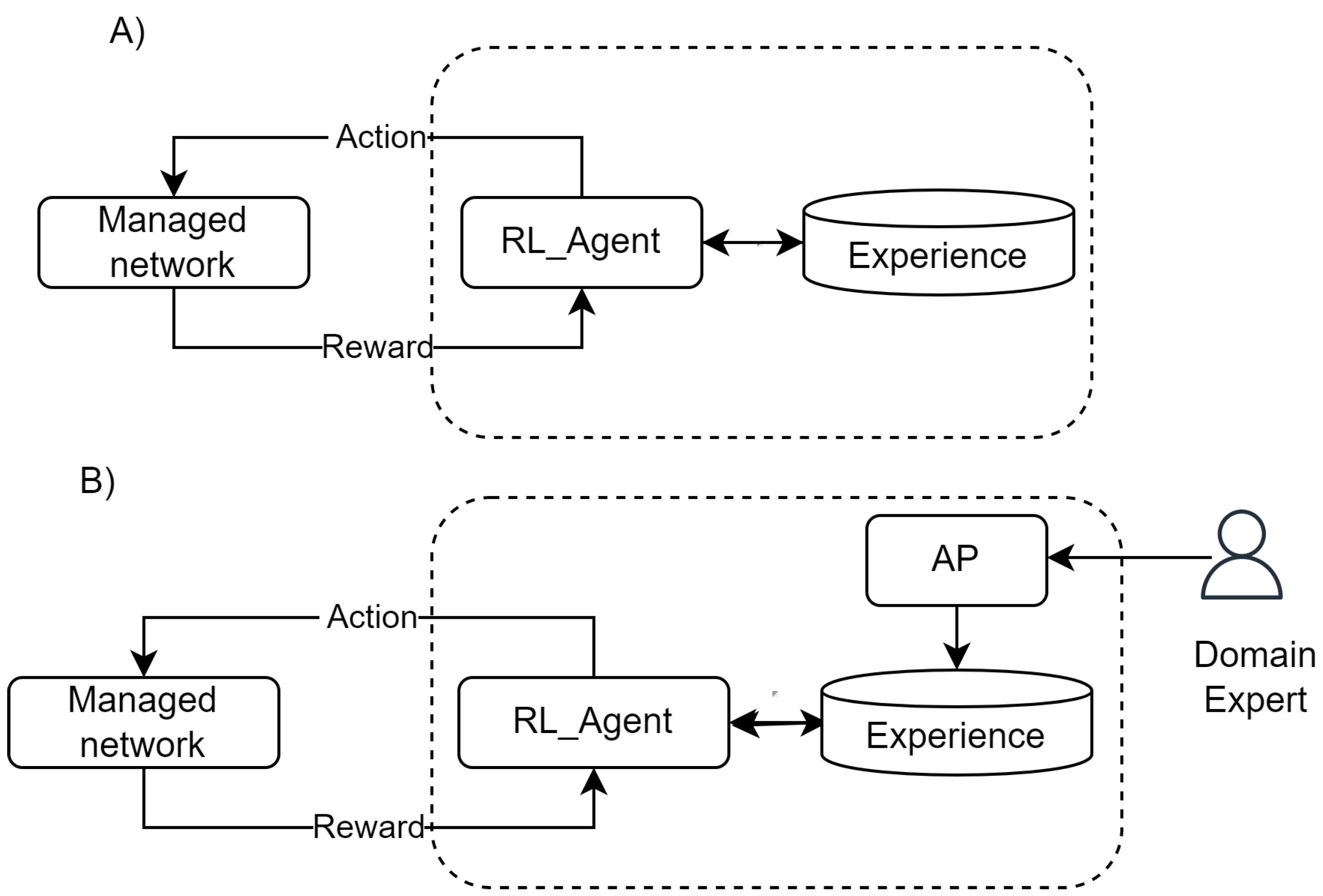
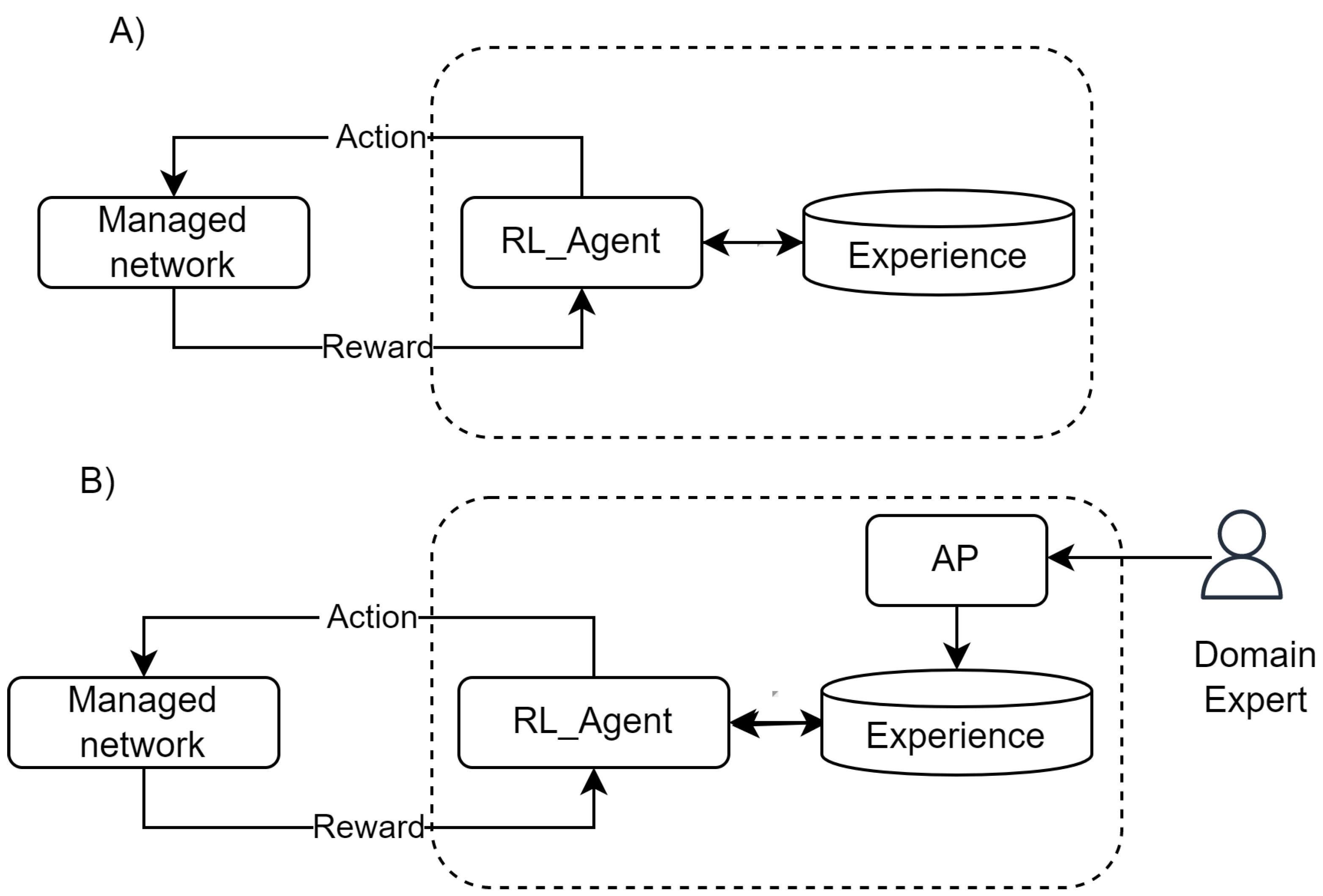
4. Integrating Automated Planning and Reinforcement Learning for Network Management
4.1. Combination Strategies
4.2. MBRL in the Network Management of Functional Areas
Faults Management
4.3. Configuration Management
4.4. Accounting
4.5. Performance
4.6. Security
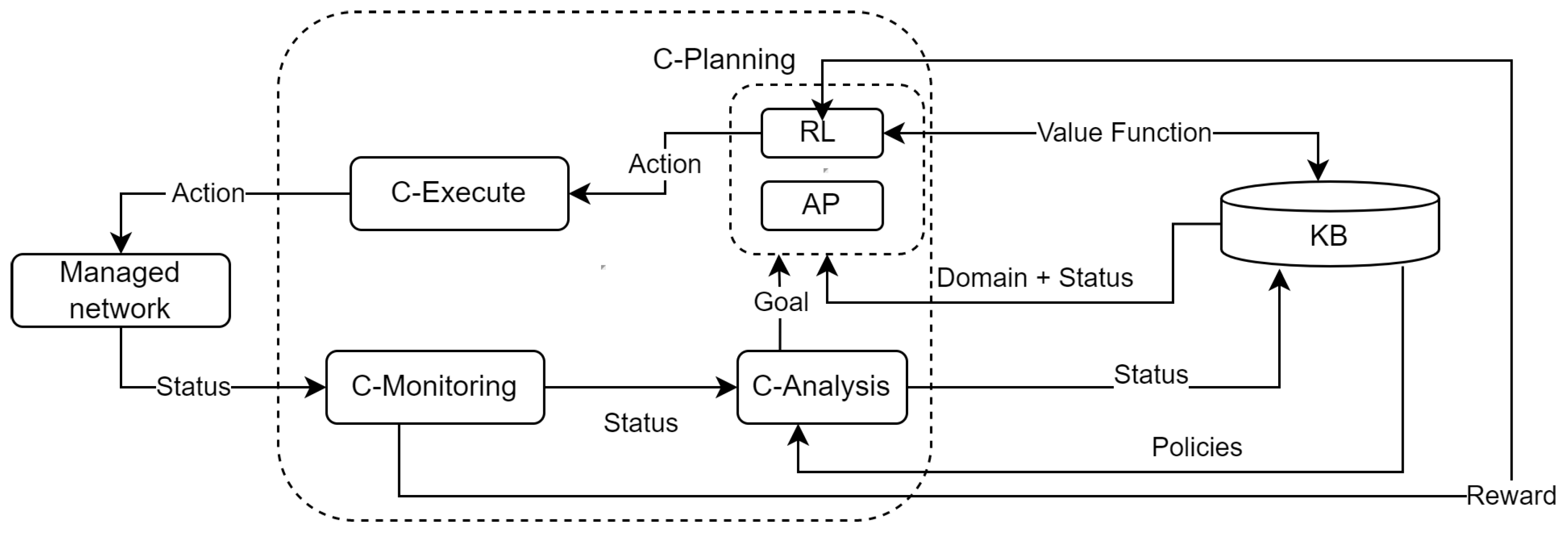
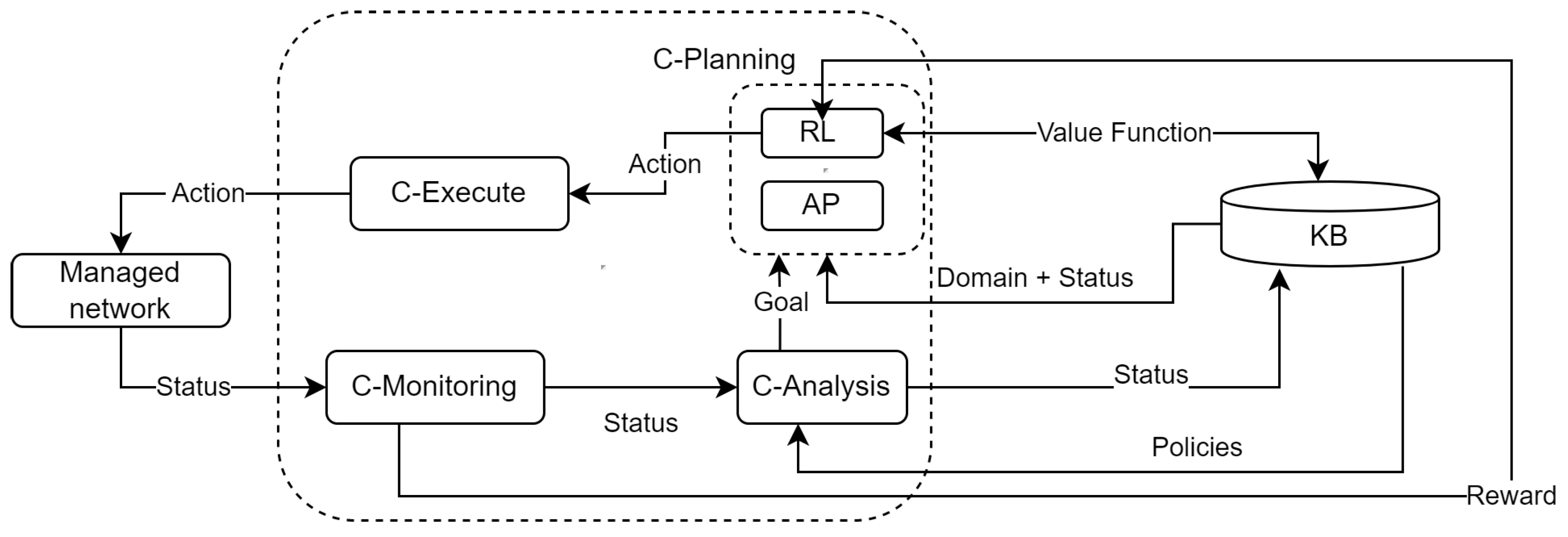
5. An Architecture for Cognitive Management Based on AP and RL
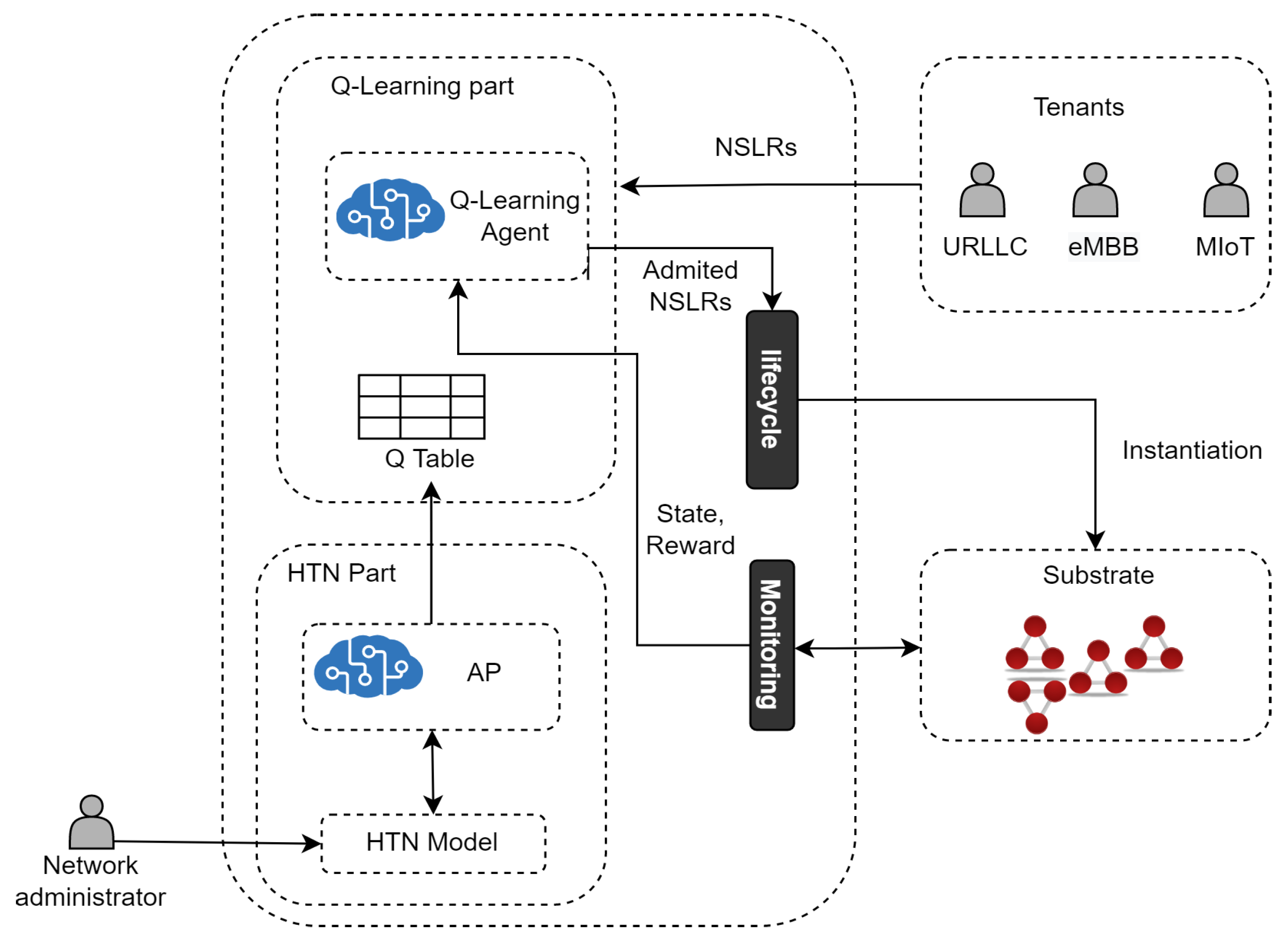
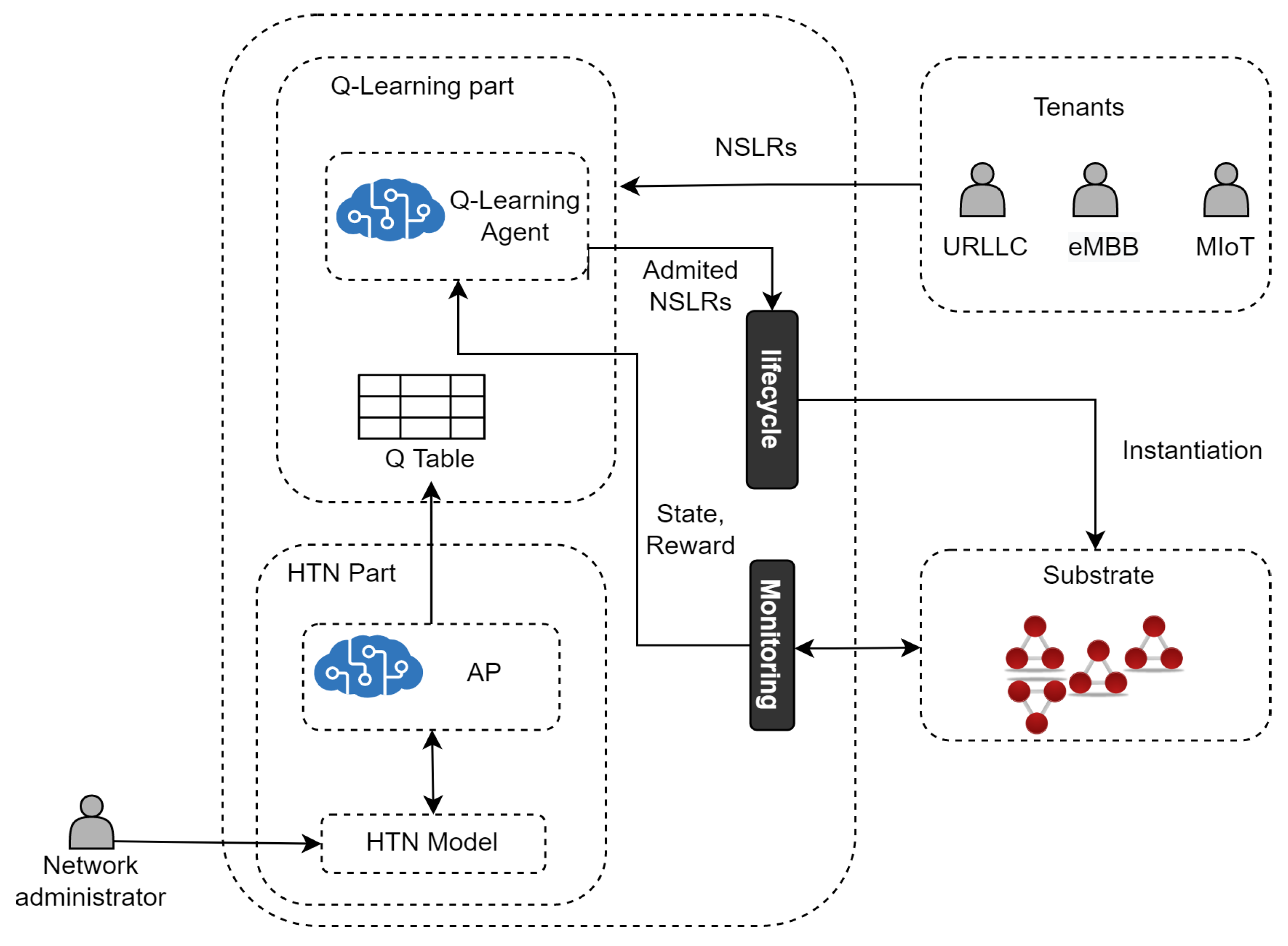
6. Case Study: Admission Control for Network Slicing Based on AP and RL
6.1. Network Slicing Admission Control with 1P2L
- The Q-learning agent first receives NSLRs and makes decisions (i.e., execute actions) on their admission.
- The Admitted NSLRs are instantiated in the substrate network by the Lifecycle Module.
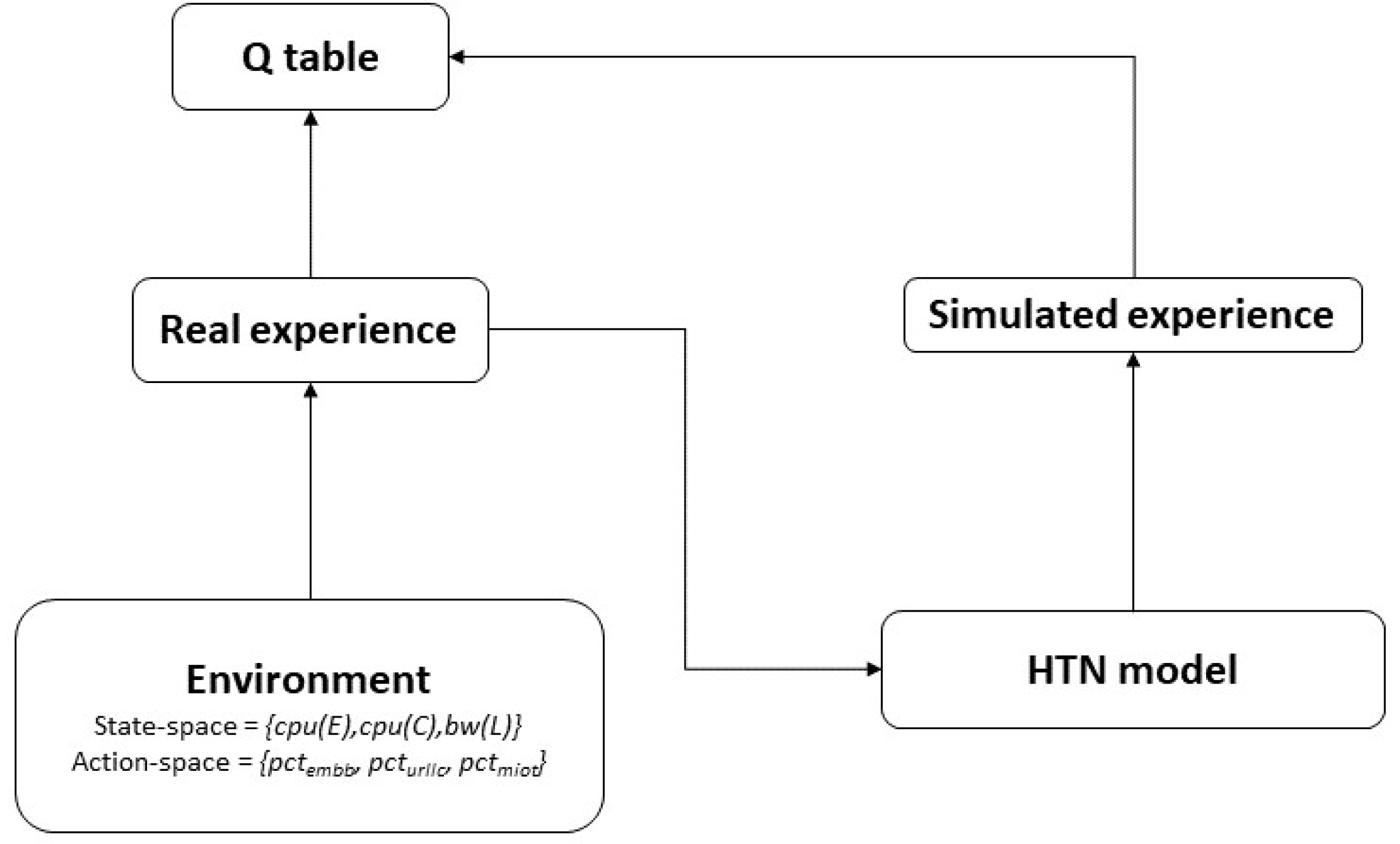
- The Q-learning agent receives a reward and an updated state from the Monitoring Module. A state is defined by the tuple (where and are the available processing capacity in the set of edge (E) and core nodes (C), respectively, and is the available bandwidth in the set of links (L)) and represents the available resources in the substrate network after the Q-learning agent executes an action. Each action is represented by , where , , and are the percentages to admit for each type of service.
- The Q-learning agent chooses to execute the action a that returns the maximum accumulated reward (i.e., the Q-value with the highest profit) while optimizing resource utilization. The reward is a profit function calculated by subtracting the amount of money earned from selling the NSL, minus the operational cost caused by using processing and bandwidth resources for running the NSL in the Substrate Network. The quality of the action is determined based on the maximization of monetary profit generated by taking that action.
- The Q-learning agent goes to the next state and stores each action’s Q-value (profit) in the Q-table.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| task: optimize_edge_20 (edge,central,bw) precond: capacity (edge,20) subtasks: assign_capacity (edge,50), assign_capacity (central,100), assign_capacity (bw,50) |
| task: optimize_edge_40 (edge,central,bw) precond: capacity (edge,40) subtasks: assign_capacity (edge,75), assign_capacity (central,100), assign_capacity (bw,50) |
| task: optimize_central_20 (edge,central,bw) precond: capacity (edge,40) capacity (central,20) subtasks: assign_capacity (edge,75), assign_capacity (central,100), assign_capacity (bw,50) |
| task: optimize_edge_60 (edge,central,bw) precond: capacity (edge,40) subtasks: optimize_central_20 (edge, central, bw) |
6.1.1. Convergence
6.1.2. 1P2L vs. Deep Reinforcement Learning
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xu, X.; Jia, Y.; Xu, Y.; Xu, Z.; Chai, S.; Lai, C.S. A multi-agent reinforcement learning-based data-driven method for home energy management. IEEE Trans. Smart Grid 2020, 11, 3201–3211. [Google Scholar] [CrossRef] [Green Version]
- Jiang, C.; Zhu, X. Reinforcement learning based capacity management in multi-layer satellite networks. IEEE Trans. Wirel. Commun. 2020, 19, 4685–4699. [Google Scholar] [CrossRef]
- Al-Tam, F.; Correia, N.; Rodriguez, J. Learn to Schedule (LEASCH): A Deep reinforcement learning approach for radio resource scheduling in the 5G MAC layer. IEEE Access 2020, 8, 108088–108101. [Google Scholar] [CrossRef]
- Casas-Velasco, D.M.; Rendon, O.M.C.; da Fonseca, N.L.S. Intelligent Routing Based on Reinforcement Learning for Software-Defined Networking. IEEE Trans. Netw. Serv. Manag. 2021, 18, 870–881. [Google Scholar] [CrossRef]
- Jumnal, A.; Kumar, S.D. Optimal VM Placement Approach Using Fuzzy Reinforcement Learning for Cloud Data Centers. In Proceedings of the 3rd IEEE International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 29–35. [Google Scholar]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Wang, J.; Liu, Y. Research on Generating Adversarial Examples in Applications. J. Phys. Conf. Ser. 2021, 1757, 012045. [Google Scholar] [CrossRef]
- Mohakud, R.; Dash, R. Survey on hyperparameter optimization using nature-inspired algorithm of deep convolution neural network. In Intelligent and Cloud Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 737–744. [Google Scholar]
- Jia, S.; Lin, P.; Li, Z.; Zhang, J.; Liu, S. Visualizing surrogate decision trees of convolutional neural networks. J. Vis. 2020, 23, 141–156. [Google Scholar] [CrossRef]
- Moysen, J.; Giupponi, L. From 4G to 5G: Self-organized network management meets machine learning. Comput. Commun. 2018, 129, 248–268. [Google Scholar] [CrossRef] [Green Version]
- Papadimitriou, C.H.; Tsitsiklis, J.N. The complexity of Markov decision processes. Math. Oper. Res. 1987, 12, 441–450. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Lyu, D.; Liu, B.; Gustafson, S. PEORL: Integrating Symbolic Planning and Hierarchical Reinforcement Learning for Robust Decision-making. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI’18), Stockholm, Sweden, 13–19 July 2018; AAAI Press: Palo Alto, CA, USA, 2018; pp. 4860–4866. [Google Scholar]
- Moerland, T.M.; Broekens, J.; Jonker, C.M. Model-based reinforcement learning: A survey. arXiv 2020, arXiv:2006.16712. [Google Scholar]
- Sutton, R.S. Dyna, an integrated architecture for learning, planning, and reacting. ACM Sigart Bull. 1991, 2, 160–163. [Google Scholar] [CrossRef] [Green Version]
- Rybkin, O.; Zhu, C.; Nagabandi, A.; Daniilidis, K.; Mordatch, I.; Levine, S. Model-Based Reinforcement Learning via Latent-Space Collocation. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 9190–9201. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef] [PubMed]
- Ayoub, A.; Jia, Z.; Szepesvari, C.; Wang, M.; Yang, L. Model-based reinforcement learning with value-targeted regression. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 463–474. [Google Scholar]
- Leonetti, M.; Iocchi, L.; Stone, P. A synthesis of automated planning and reinforcement learning for efficient, robust decision-making. Artif. Intell. 2016, 241, 103–130. [Google Scholar] [CrossRef] [Green Version]
- Dong, S.; Xia, Y.; Peng, T. Network abnormal traffic detection model based on semi-supervised deep reinforcement learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Todorov, D.; Valchanov, H.; Aleksieva, V. Load balancing model based on machine learning and segment routing in SDN. In Proceedings of the 2020 IEEE International Conference Automatics and Informatics (ICAI), Varna, Bulgaria, 1–3 October 2020; pp. 1–4. [Google Scholar]
- Albert, R.; Barabási, A.L. Topology of evolving networks: Local events and universality. Phys. Rev. Lett. 2000, 85, 5234. [Google Scholar] [CrossRef] [Green Version]
- Xiang, H.; Peng, M.; Sun, Y.; Yan, S. Mode selection and resource allocation in sliced fog radio access networks: A reinforcement learning approach. IEEE Trans. Veh. Technol. 2020, 69, 4271–4284. [Google Scholar] [CrossRef] [Green Version]
- Faraci, G.; Grasso, C.; Schembra, G. Design of a 5G network slice extension with MEC UAVs managed with reinforcement learning. IEEE J. Sel. Areas Commun. 2020, 38, 2356–2371. [Google Scholar] [CrossRef]
- Nie, L.; Wang, H.; Jiang, X.; Guo, Y.; Li, S. Traffic Measurement Optimization Based on Reinforcement Learning in Large-Scale ITS-Oriented Backbone Networks. IEEE Access 2020, 8, 36988–36996. [Google Scholar] [CrossRef]
- Strehl, A.L.; Li, L.; Wiewiora, E.; Langford, J.; Littman, M.L. PAC model-free reinforcement learning. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 881–888. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Ghallab, M.; Nau, D.S.; Traverso, P. Automated Planning—Theory and Practice; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Rodriguez-Vivas, A.; Caicedo, O.M.; Ordoñez, A.; Nobre, J.C.; Granville, L.Z. NORA: An Approach for Transforming Network Management Policies into Automated Planning Problems. Sensors 2021, 21, 1790. [Google Scholar] [CrossRef]
- Gironza-Ceron, M.A.; Villota-Jacome, W.F.; Ordonez, A.; Estrada-Solano, F.; Rendon, O.M.C. SDN management based on Hierarchical Task Network and Network Functions Virtualization. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 1360–1365. [Google Scholar]
- Gopalan, N.; Littman, M.; MacGlashan, J.; Squire, S.; Tellex, S.; Winder, J.; Wong, L. Planning with abstract Markov decision processes. In Proceedings of the International Conference on Automated Planning and Scheduling, Pittsburgh, PA, USA, 18–23 June 2017; Volume 27. [Google Scholar]
- Lu, X.; Zhang, N.; Tian, C.; Yu, B.; Duan, Z. A Knowledge-Based Temporal Planning Approach for Urban Traffic Control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1907–1918. [Google Scholar] [CrossRef]
- Nejati, N.; Langley, P.; Konik, T. Learning hierarchical task networks by observation. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 665–672. [Google Scholar]
- Erol, K.; Hendler, J.A.; Nau, D.S. UMCP: A Sound and Complete Procedure for Hierarchical Task-network Planning. In Proceedings of the AIPS, Chicago, IL, USA, 13–15 June 1994; Volume 94, pp. 249–254. [Google Scholar]
- Georgievski, I.; Aiello, M. An overview of hierarchical task network planning. arXiv 2014, arXiv:1403.7426. [Google Scholar]
- Villota, W.; Gironza, M.; Ordonez, A.; Rendon, O.M.C. On the Feasibility of Using Hierarchical Task Networks and Network Functions Virtualization for Managing Software-Defined Networks. IEEE Access 2018, 6, 38026–38040. [Google Scholar] [CrossRef]
- Wurster, M.; Breitenbücher, U.; Falkenthal, M.; Krieger, C.; Leymann, F.; Saatkamp, K.; Soldani, J. The essential deployment metamodel: A systematic review of deployment automation technologies. SICS Softw. Intensive-Cyber-Phys. Syst. 2020, 35, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, A.; Yousef, A.H.; Medhat, W. DevSecOps: A Security Model for Infrastructure as Code Over the Cloud. In Proceedings of the 2nd IEEE International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022; pp. 284–288. [Google Scholar]
- Janner, M.; Fu, J.; Zhang, M.; Levine, S. When to trust your model: Model-based policy optimization. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Hayamizu, Y.; Amiri, S.; Chandan, K.; Takadama, K.; Zhang, S. Guiding Robot Exploration in Reinforcement Learning via Automated Planning. In Proceedings of the International Conference on Automated Planning and Scheduling, Guangzhou, China, 7–12 June 2021; Volume 31, pp. 625–633. [Google Scholar]
- Illanes, L.; Yan, X.; Icarte, R.T.; McIlraith, S.A. Symbolic plans as high-level instructions for reinforcement learning. In Proceedings of the International Conference on Automated Planning and Scheduling, Nancy, France, 14–19 June 2020; Volume 30, pp. 540–550. [Google Scholar]
- Moridi, E.; Haghparast, M.; Hosseinzadeh, M.; Jassbi, S.J. Fault management frameworks in wireless sensor networks: A survey. Comput. Commun. 2020, 155, 205–226. [Google Scholar] [CrossRef]
- Chen, X.; Proietti, R.; Liu, C.Y.; Yoo, S.B. Towards Self-Driving Optical Networking with Reinforcement Learning and Knowledge Transferring. In Proceedings of the 2020 IEEE International Conference on Optical Network Design and Modeling (ONDM), Barcelona, Spain, 18–21 May 2020; pp. 1–3. [Google Scholar]
- Mismar, F.B.; Evans, B.L. Deep Q-Learning for Self-Organizing Networks Fault Management and Radio Performance Improvement. In Proceedings of the 52nd IEEE Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; pp. 1457–1461. [Google Scholar]
- Li, R.; Zhao, Z.; Sun, Q.; Chih-Lin, I.; Yang, C.; Chen, X.; Zhao, M.; Zhang, H. Deep reinforcement learning for resource management in network slicing. IEEE Access 2018, 6, 74429–74441. [Google Scholar] [CrossRef]
- Sciancalepore, V.; Costa-Perez, X.; Banchs, A. RL-NSB: Reinforcement Learning-Based 5G Network Slice Broker. IEEE/ACM Trans. Netw. 2019, 27, 1543–1557. [Google Scholar] [CrossRef] [Green Version]
- Dandachi, G.; De Domenico, A.; Hoang, D.T.; Niyato, D. An Artificial Intelligence Framework for Slice Deployment and Orchestration in 5G Networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 858–871. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, L.; Li, Z.; Jiang, C. SDCoR: Software defined cognitive routing for Internet of vehicles. IEEE Internet Things J. 2018, 5, 3513–3520. [Google Scholar] [CrossRef]
- Bouzid, S.; Serrestou, Y.; Raoof, K.; Omri, M. Efficient Routing Protocol for Wireless Sensor Network based on Reinforcement Learning. In Proceedings of the 5th IEEE International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 2–5 September 2020; pp. 1–5. [Google Scholar]
- Kim, S.; Yoon, S.; Lim, H. Deep Reinforcement Learning-Based Traffic Sampling for Multiple Traffic Analyzers on Software-Defined Networks. IEEE Access 2021, 9, 47815–47827. [Google Scholar] [CrossRef]
- Wang, C.; Batth, R.S.; Zhang, P.; Aujla, G.S.; Duan, Y.; Ren, L. VNE solution for network differentiated QoS and security requirements: From the perspective of deep reinforcement learning. Computing 2021, 103, 1061–1083. [Google Scholar] [CrossRef]
- Patra, S.; Velazquez, A.; Kang, M.; Nau, D. Using online planning and acting to recover from cyberattacks on software-defined networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 15377–15384. [Google Scholar]
- Speicher, P.; Steinmetz, M.; Hoffmann, J.; Backes, M.; Künnemann, R. Towards automated network mitigation analysis. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 1971–1978. [Google Scholar]
- Ayoubi, S.; Limam, N.; Salahuddin, M.A.; Shahriar, N.; Boutaba, R.; Estrada-Solano, F.; Caicedo, O.M. Machine learning for cognitive network management. IEEE Commun. Mag. 2018, 56, 158–165. [Google Scholar] [CrossRef]
- Sanchez-Navarro, I.; Salva-Garcia, P.; Wang, Q.; Calero, J.M.A. New Immersive Interface for Zero-Touch Management in 5G Networks. In Proceedings of the 3rd IEEE 5G World Forum (5GWF), Bangalore, India, 10–12 September 2020; pp. 145–150. [Google Scholar] [CrossRef]
- de Sousa, N.F.S.; Perez, D.A.L.; Rothenberg, C.E.; Gomes, P.H. End-to-End Service Monitoring for Zero-Touch Networks. J. ICT Stand. 2021, 9, 91–112. [Google Scholar] [CrossRef]
- Castillo, E.F.; Rendon, O.M.C.; Ordonez, A.; Granville, L.Z. IPro: An approach for intelligent SDN monitoring. Comput. Netw. 2020, 170, 107108. [Google Scholar] [CrossRef]
- ETSI. Zero Touch Network and Service Management (ZSM); Reference Architecture, Standard ETSI GS ZSM; ETSI: Sophia Antipolis, France, 2020. [Google Scholar]
- Li, W.; Chai, Y.; Khan, F.; Jan, S.R.U.; Verma, S.; Menon, V.G.; Li, X. A comprehensive survey on machine learning-based big data analytics for IoT-enabled smart healthcare system. Mob. Netw. Appl. 2021, 26, 234–252. [Google Scholar] [CrossRef]
- Bari, M.F.; Chowdhury, S.R.; Ahmed, R.; Boutaba, R.; Duarte, O.C.M.B. Orchestrating Virtualized Network Functions. IEEE Trans. Netw. Serv. Manag. 2016, 13, 725–739. [Google Scholar] [CrossRef]
- Villota Jácome, W.F.; Caicedo Rendon, O.M.; da Fonseca, N.L.S. Admission Control for 5G Network Slicing based on (Deep) Reinforcement Learning. IEEE Syst. J. 2021. [Google Scholar] [CrossRef]
- Partalas, I.; Vrakas, D.; Vlahavas, I. Reinforcement learning and automated planning: A survey. In Artificial Intelligence for Advanced Problem Solving Techniques; IGI Global: Hershey, PA, USA, 2008; pp. 148–165. [Google Scholar]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef] [Green Version]
- Song, H.; Luan, D.; Ding, W.; Wang, M.Y.; Chen, Q. Learning to predict vehicle trajectories with model-based planning. In Proceedings of the Conference on Robot Learning (PMLR), London, UK, 8–11 November 2022; pp. 1035–1045. [Google Scholar]
- Li, J.; Pan, Z. Network traffic classification based on deep learning. KSII Trans. Internet Inf. Syst. (TIIS) 2020, 14, 4246–4267. [Google Scholar]
- Susilo, B.; Sari, R.F. Intrusion Detection in Software Defined Network Using Deep Learning Approach. In Proceedings of the 11th IEEE Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021; pp. 0807–0812. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ordonez, A.; Caicedo, O.M.; Villota, W.; Rodriguez-Vivas, A.; da Fonseca, N.L.S. Model-Based Reinforcement Learning with Automated Planning for Network Management. Sensors 2022, 22, 6301. https://doi.org/10.3390/s22166301
Ordonez A, Caicedo OM, Villota W, Rodriguez-Vivas A, da Fonseca NLS. Model-Based Reinforcement Learning with Automated Planning for Network Management. Sensors. 2022; 22(16):6301. https://doi.org/10.3390/s22166301
Chicago/Turabian StyleOrdonez, Armando, Oscar Mauricio Caicedo, William Villota, Angela Rodriguez-Vivas, and Nelson L. S. da Fonseca. 2022. "Model-Based Reinforcement Learning with Automated Planning for Network Management" Sensors 22, no. 16: 6301. https://doi.org/10.3390/s22166301
APA StyleOrdonez, A., Caicedo, O. M., Villota, W., Rodriguez-Vivas, A., & da Fonseca, N. L. S. (2022). Model-Based Reinforcement Learning with Automated Planning for Network Management. Sensors, 22(16), 6301. https://doi.org/10.3390/s22166301