
A Fast Point Cloud Recognition Algorithm Based on Keypoint Pair Feature

Abstract
:1. Introduction
- On the basis of PPF, a keypoint extraction algorithm based on grid ISS sampling combined with curvature-adaptive sampling and angle-adaptive judgment is proposed. The algorithm has higher efficiency compared to the original PPF.
- Several sets of experiments are compared between K-PPF, PPF and other algorithms in public datasets, and the results prove the superiority and robustness of the K-PPF algorithm.
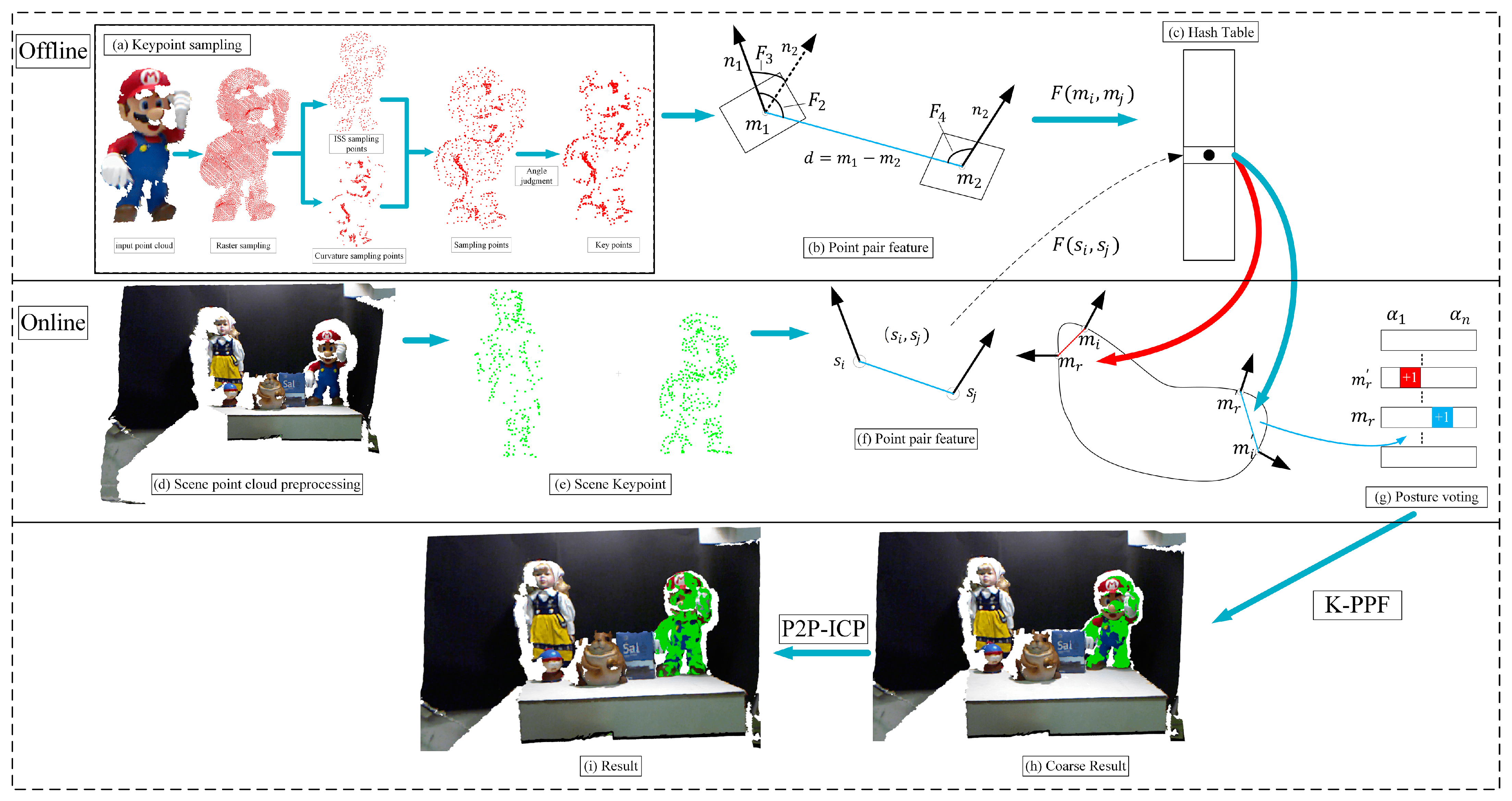
2. The Proposed Method
2.1. Offline Stage
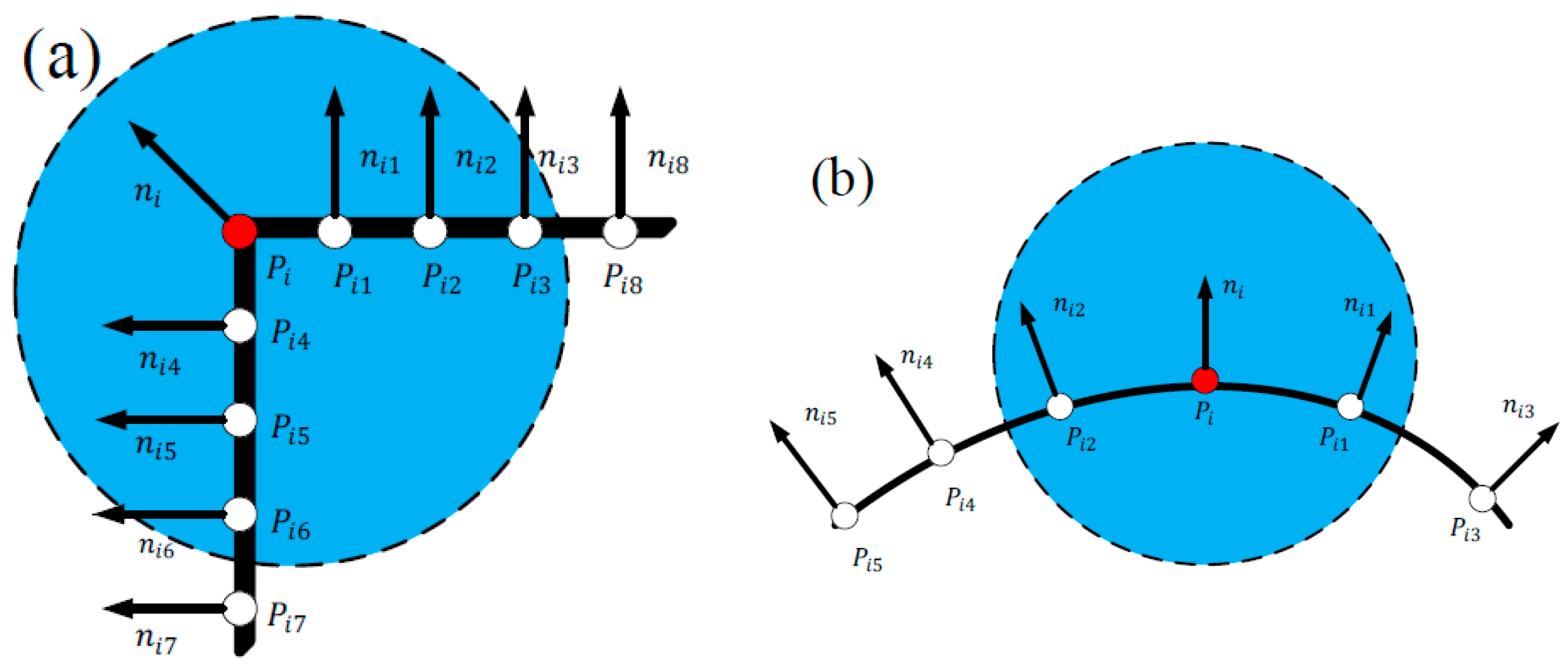
2.1.1. Curvature Sampling Point
2.1.2. ISS Sampling
2.1.3. Angle-Adaptive Judgment
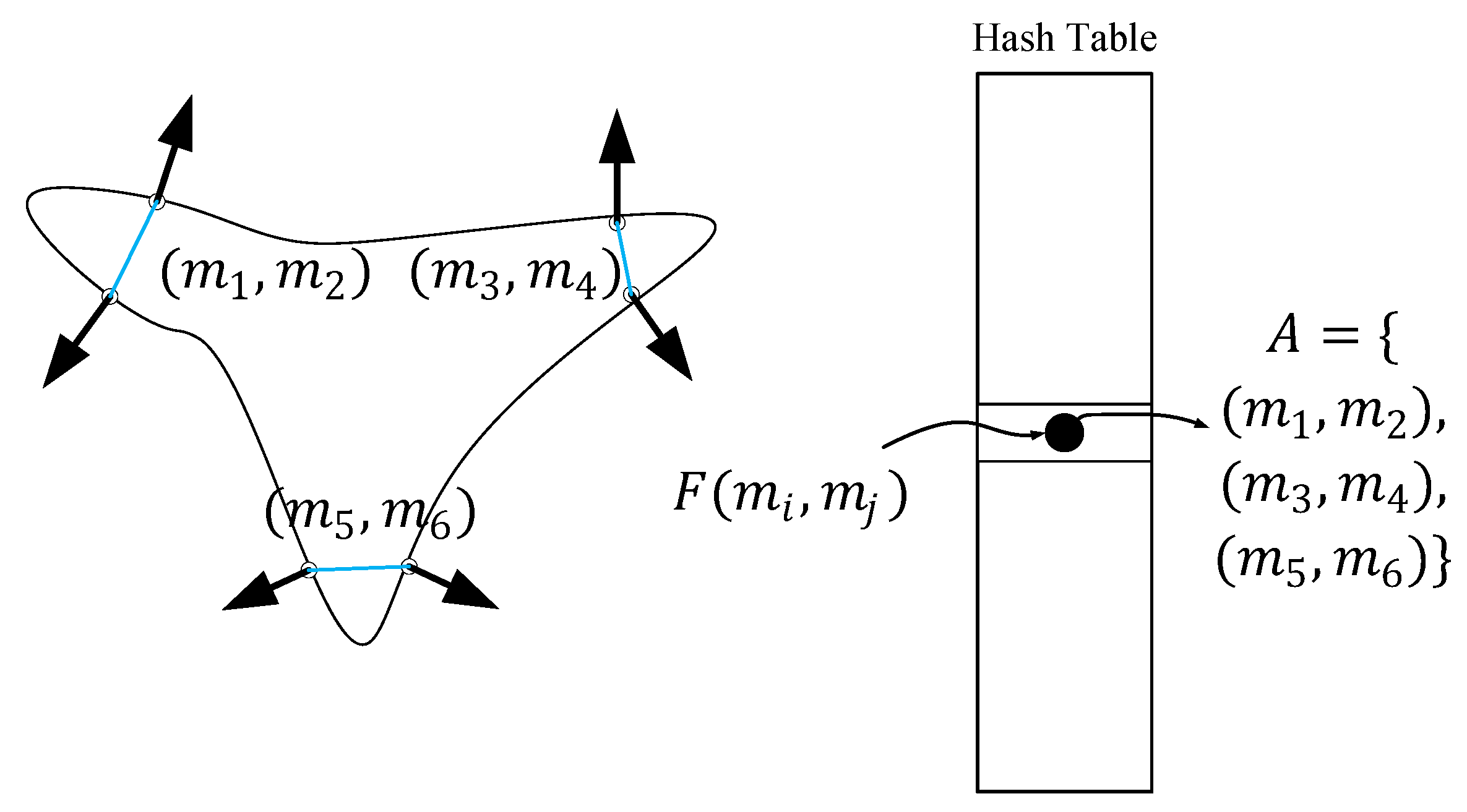
2.1.4. Point Pair Feature
2.1.5. Global Feature Description
2.2. Online Stage
2.2.1. Voting Strategy
2.2.2. Pose Clustering
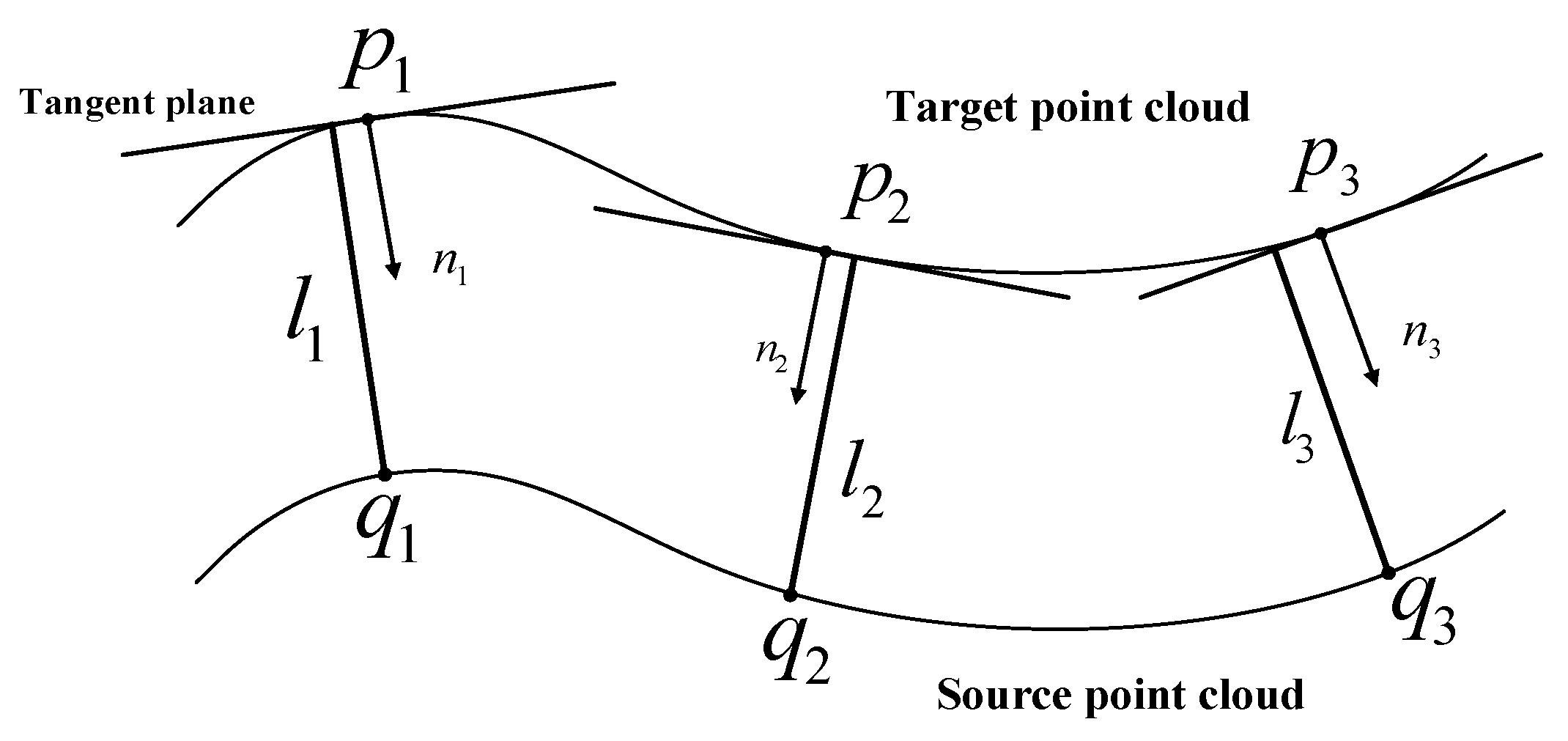
3. Fine Registration
Point-to-Plane ICP
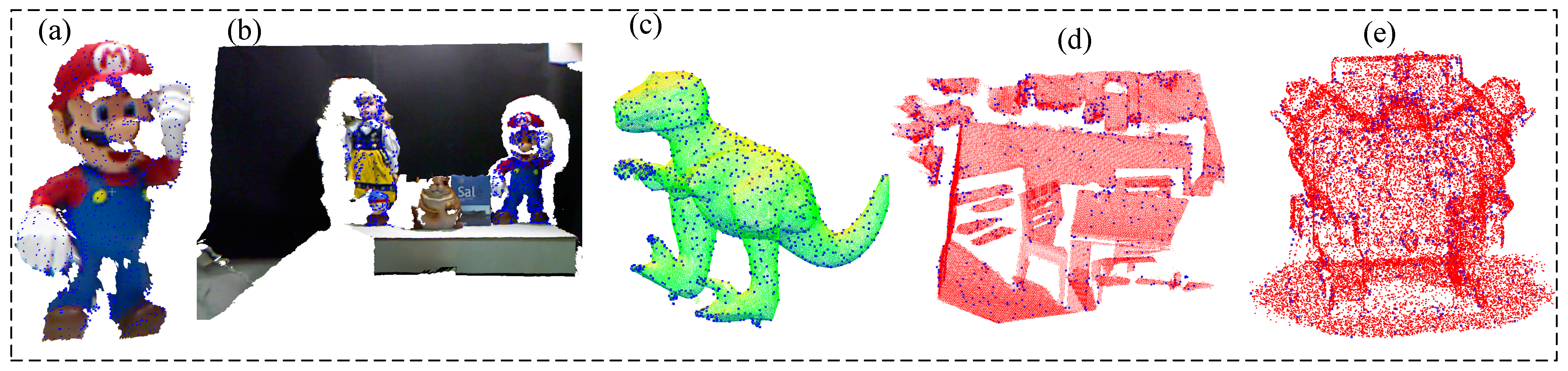
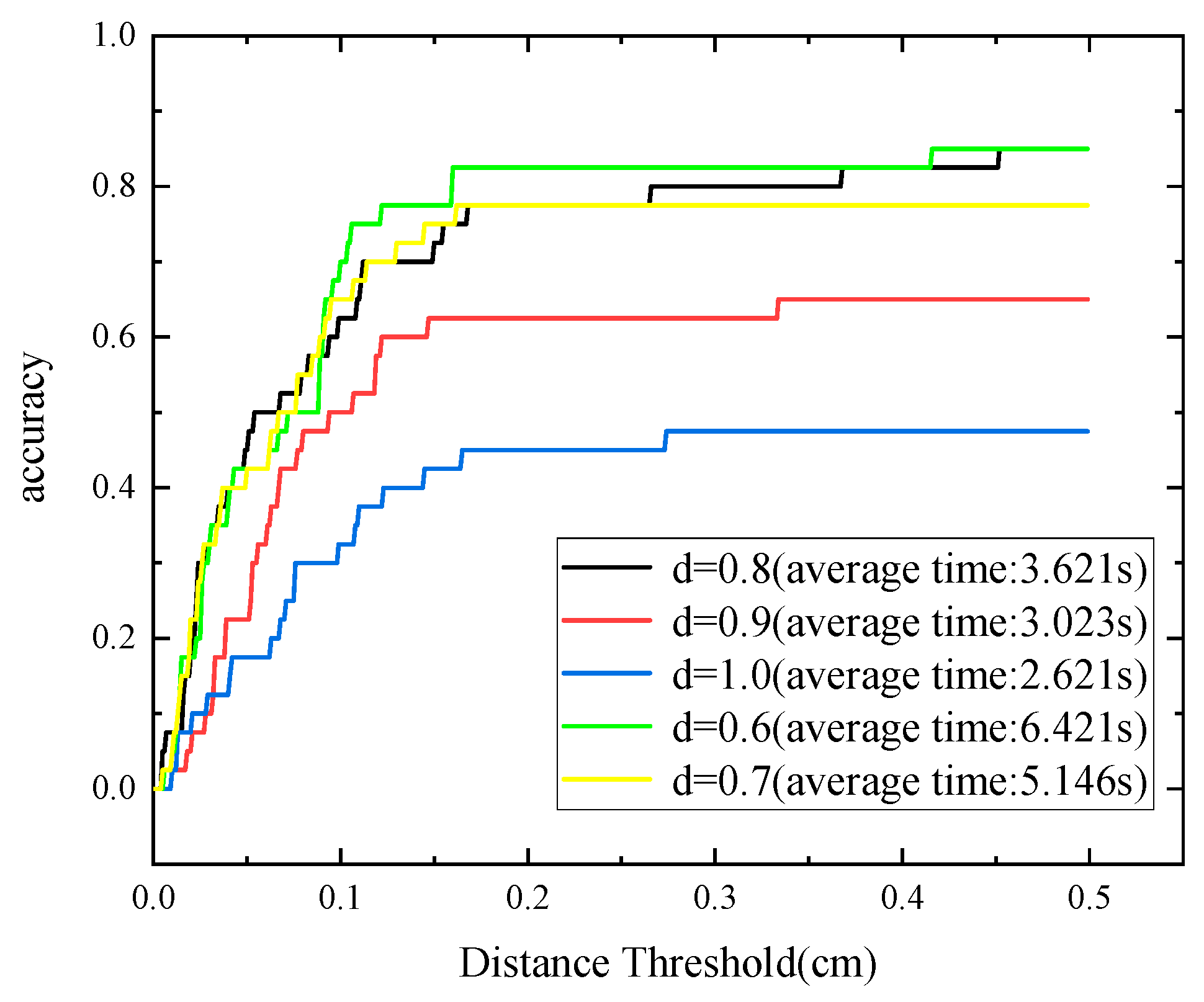
4. Performance Evaluation Experiments
4.1. Datesets
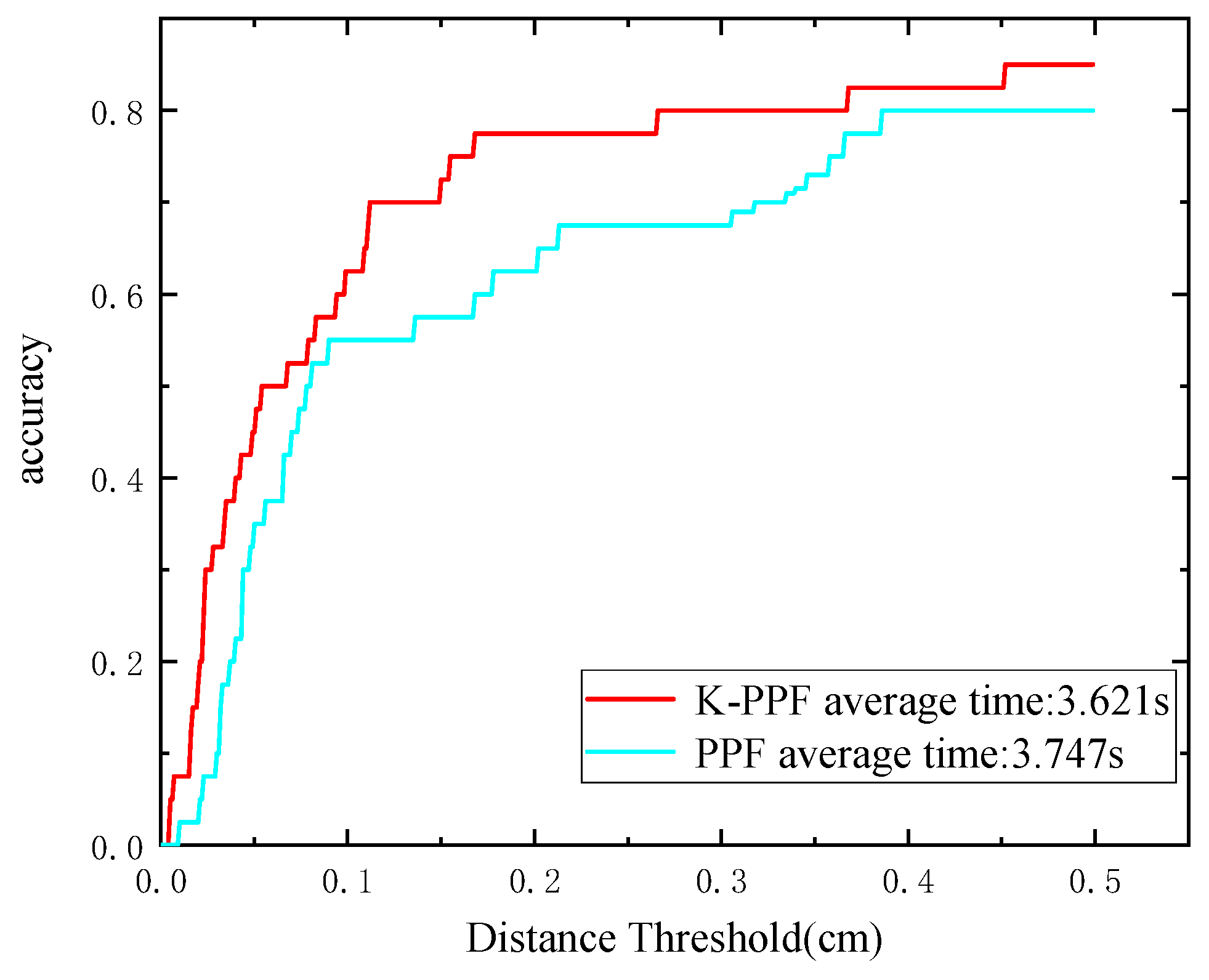
4.2. Comparison with Original PPF Algorithm
4.2.1. UWA Dataset (Complex Scene)
4.2.2. Overlap Rate Calculation
4.2.3. Redkitchen Dataset (Rich Corners)
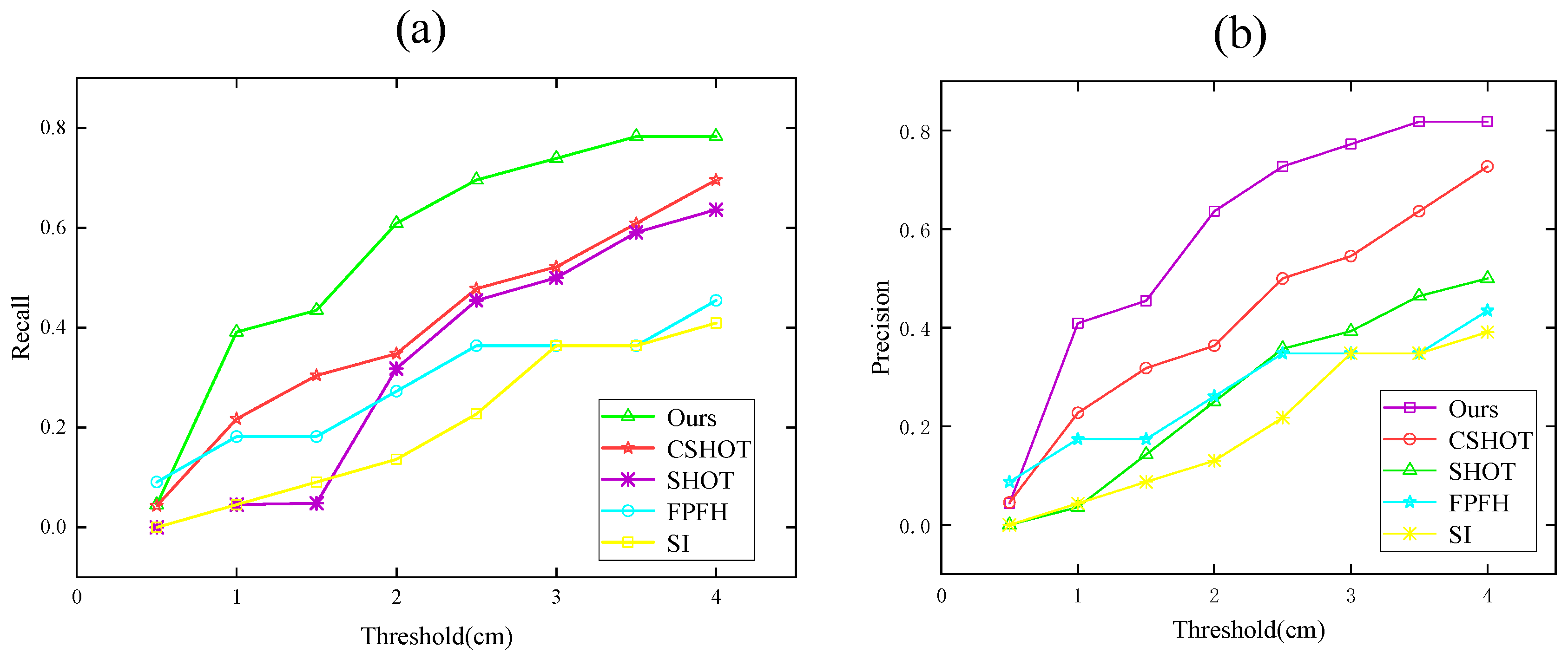
4.3. Compare with Other Algorithms
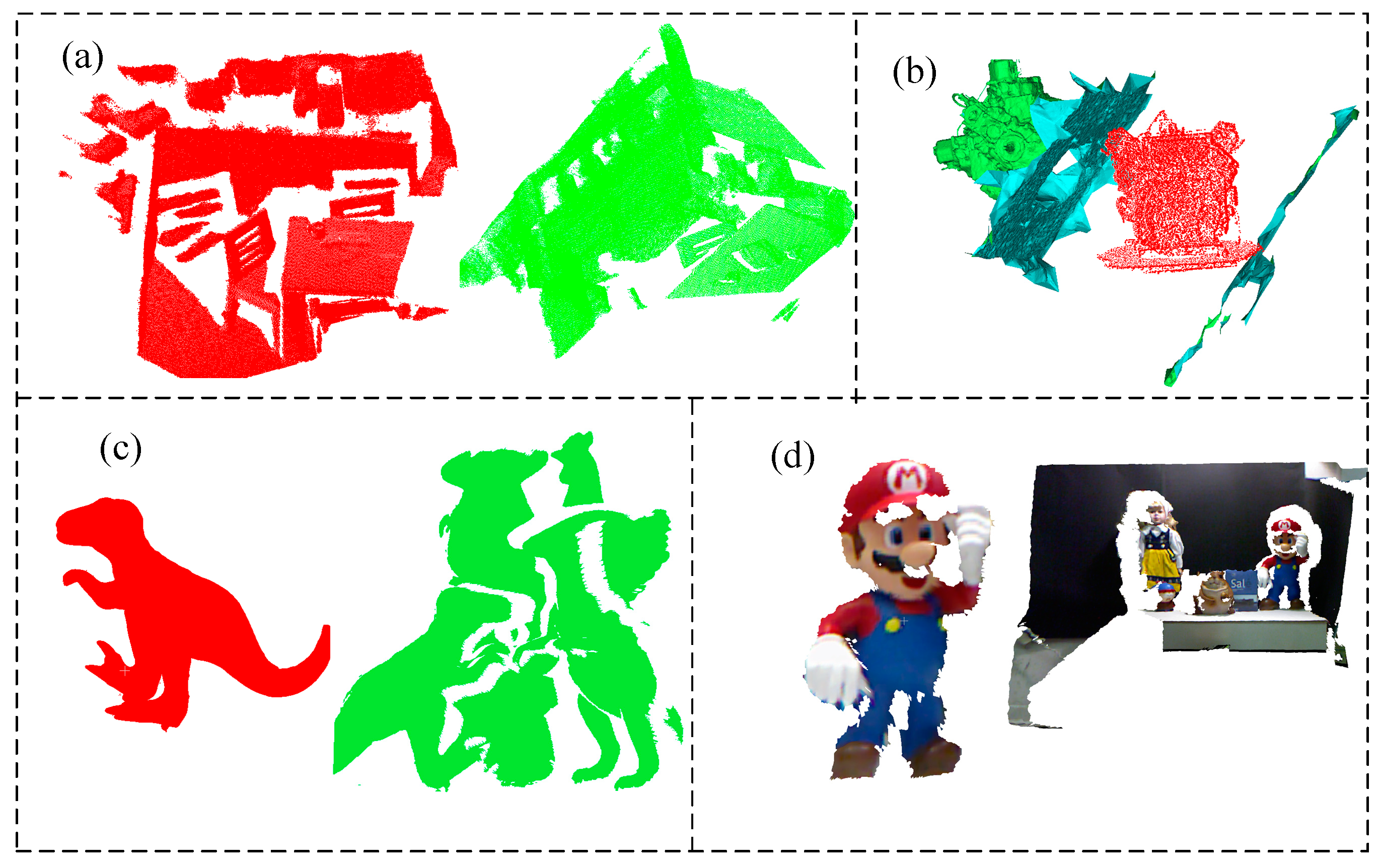
4.4. Point Cloud Recognition Experiment
4.5. Real Dataset Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 1611, 586–606. [Google Scholar] [CrossRef] [Green Version]
- Low, K.L. Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration; University of North Carolina: Chapel Hill, NC, USA, 2004; Volume 4, pp. 1–3. [Google Scholar]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-ICP. Robot. Sci. Syst. 2009, 2, 435. [Google Scholar]
- Koide, K.; Yokozuka, M.; Oishi, S.; Banno, A. Voxelized gicp for fast and accurate 3d point cloud registration. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 11054–11059. [Google Scholar]
- Li, R.Z.; Yang, M.; Tian, Y.; Liu, Y.Y.; Zhang, H.H. Point Cloud Registration Algorithm Based on the ISS Feature Points Combined with Improved ICP Algorithm. Laser Optoelectron. Prog. 2017, 54, 111503. [Google Scholar]
- Shi, X.; Peng, J.; Li, J.; Yan, P.; Gong, H. The Iterative Closest Point Registration Algorithm Based on the Normal Distribution Transformation. Procedia Comput. Sci. 2019, 147, 181–190. [Google Scholar] [CrossRef]
- Bai, X.; Luo, Z.; Zhou, L.; Chen, H.; Li, L.; Hu, Z. PointDSC: Robust Point Cloud Registration using Deep Spatial Consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 19–25 June 2021; pp. 15854–15864. [Google Scholar]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique Signatures of Histograms for Surface and Texture Description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D Registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Johnson, A.E.; Hebert, M. Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Hashimoto, K. Curve set feature-based robust and fast pose estimation algorithm. Sensors 2017, 17, 1782. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Da, F.; Tao, H. An Automatic Registration Algorithm for Point Cloud Based on Feature Extraction. Chin. J. Lasers 2015, 42, 0308002. [Google Scholar] [CrossRef]
- Liu, J.; Bai, D. 3D Point Cloud Registration Algorithm Based on Feature Matching. Acta Opt. Sin. 2018, 38, 1215005. [Google Scholar]
- Fengguang, X.; Biao, D.; Wang, H.; Min, P.; Liqun, K.; Xie, H. A local feature descriptor based on rotational volume for pairwise registration of point clouds. IEEE Access 2020, 8, 100120–100134. [Google Scholar] [CrossRef]
- Lu, J.; Shao, H.; Wang, W.; Fan, Z.; Xia, G. Point Cloud Registration Method Based on Keypoint Extraction with Small Overlap. Trans. Beijing Inst. Technol. 2020, 40, 409–415. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Chang, S.; Ahn, C.; Lee, M.; Oh, S. Graph-matching-based correspondence search for nonrigid point cloud registration. Comput. Vis. Image Underst. 2020, 192, 102899. [Google Scholar] [CrossRef]
- Li, J.; Qian, F.; Chen, X. Point Cloud Registrati-on Algorithm Based on Overlapping Region Extraction. J. Phys. Conf. Ser. 2020, 1634, 012012. [Google Scholar] [CrossRef]
- Xiao, Z.; Gao, J.; Wu, D.; Zhang, L.; Chen, X. A fast 3D object recognition algorithm using plane-constrained point pair features. Multimed. Tools Appl. 2020, 79, 29305–29325. [Google Scholar] [CrossRef]
- Li, D.; Wang, H.; Liu, N.; Wang, X.; Xu, J. 3D object recognition and pose estimation from point cloud using stably observed point pair feature. IEEE Access 2020, 8, 44335–44345. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Rajkumar, N.; Konolige, K. Going Further with Point Pair Features. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 834–848. [Google Scholar]
- Wang, G.; Yang, L.; Liu, Y. An Improved 6D Pose Estimation Method Based on Point Pair Feature. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 455–460. [Google Scholar]
- Yue, X.; Liu, Z.; Zhu, J.; Gao, X.; Yang, B.; Tian, Y. Coarse-fine point cloud registration based on local point-pair features and the iterative closest point algorithm. Appl. Intell. 2022, 1–15. [Google Scholar] [CrossRef]
- Liu, D.; Arai, S.; Miao, J.; Kinugawa, J.; Wang, Z.; Kosuge, K. Point pair feature-based pose estimation with multiple edge appearance models (PPF-MEAM) for robotic bin picking. Sensors 2018, 18, 2719. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Liu, Y.; Ding, F.; Zhuang, Z. Recognition and Grasping of Disorderly Stacked Wood Planks Using a Local Image Patch and Point Pair Feature Method. Sensors 2020, 20, 6235. [Google Scholar] [CrossRef]
- Bobkov, D.; Chen, S.; Jian, R.; Iqbal, M.Z.; Steinbach, E. Noise-resistant deep learning for object classification in three-dimensional point clouds using a point pair descriptor. IEEE Robot. Autom. Lett. 2018, 3, 865–872. [Google Scholar] [CrossRef] [Green Version]
- Cui, X.; Yu, M.; Wu, L.; Wu, S. A 6D Pose Estimation for Robotic Bin-Picking Using Point-Pair Features with Curvature (Cur-PPF). Sensors 2022, 22, 1805. [Google Scholar] [CrossRef]
- Zhao, H.; Tang, M.; Ding, H. HoPPF: A Novel Local Surface Descriptor for 3D Object Recognition. Pattern Recognit. 2020, 103, 107272. [Google Scholar] [CrossRef]
- Pauly, M.; Gross, M.; Kobbelt, L.P. Efficient simplification of point-sampled surfaces. In Proceedings of the Conference on Visualization, IEEE Visualization, Boston, MA, USA, 27 October–1 November 2002; pp. 163–170. [Google Scholar]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3D object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar]
- Hodaň, T.; Matas, J.; Obdržálek, Š. On evaluation of 6D object pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 606–661. [Google Scholar]
- Yang, J.; Zhang, Q.; Xiao, Y.; Cao, Z. TOLDI: An Effective and Robust Approach for 3D Local Shape Description. Pattern Recognit. 2017, 65, 175–187. [Google Scholar] [CrossRef]
- Tombari, F.; Salti, S.; Stefano, L.D. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 356–369. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. Performance Evaluation of 3D Keypoint Detectors. Int. J. Comput. Vis. 2012, 102, 198–220. [Google Scholar] [CrossRef]
- Shotton, J.; Glocker, B.; Zach, C.; Izadi, S.; Criminisi, A.; Fitzgibbon, A. Scene coordinate regression forests for camera relocalization in RGB-D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2930–2937. [Google Scholar]
- Mian, A.S.; Bennamoun, M.; Owens, R. Three-dimensional model-based object recognition and segmentation in cluttered scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1584–1601. [Google Scholar] [CrossRef] [Green Version]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A con-volutional neural network for 6D object pose estimation in cluttered scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Akizuki, S.; Hashimoto, M. High-speed and reliable object recognition using distinctive 3-D vector-pairs in a range image. In Proceedings of the 2012 International Symposium on Optomechatronic Technologies, Paris, France, 29–31 October 2012; pp. 1–6. [Google Scholar]
- Guo, J.T. Research on Target Recognition and Pose Estimation Method Based on Point Cloud. Master’s Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PN | PR | Overlap Rate/% | Time/s |
|---|---|---|---|---|
| PPF | 98 | 0 | 95.314 | 5.24 |
| K-PPF | 71 | 27 | 96.1419 | 3.71 |
| Data | Average Overlap Rate/% | Average Occlusion Rate/% |
|---|---|---|
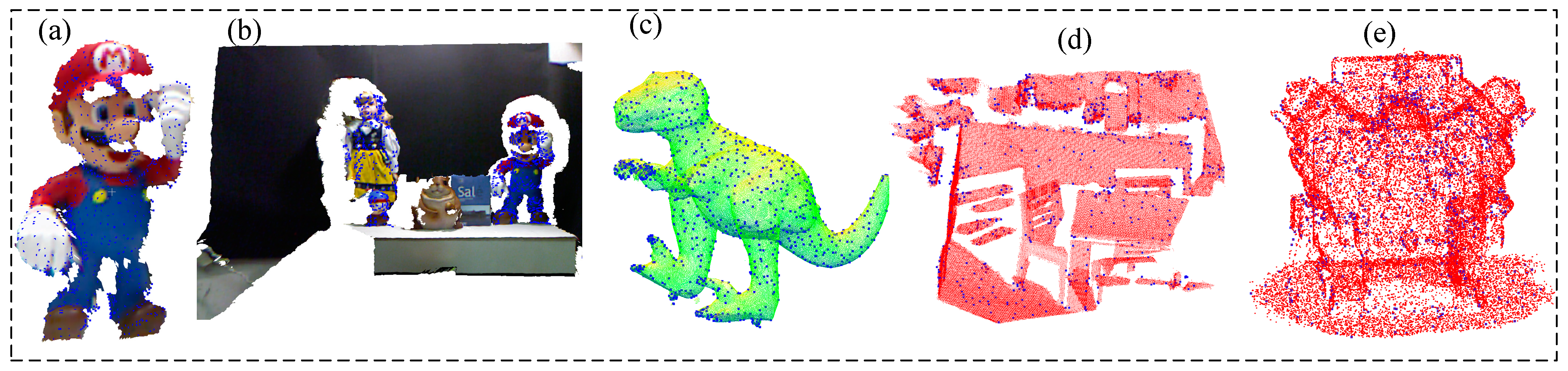
| (a) | 93.2966 | 22.01925 |
| (b) | 92.2091 | 27.9866 |
| (c) | 91.5807 | 28.6893 |
| (d) | 90.7508 | 32.4563 |
| (e) | 96.214 | 15.671 |
| Method | PN | Overlap Rate/% | Time/s |
|---|---|---|---|
| PPF | 190 | 97.02 | 1.791 |
| K-PPF | 167 | 98.733 | 1.194 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, Z.; Shen, X.; Gao, Q.; Sun, H.; Tang, X.; Cai, Q. A Fast Point Cloud Recognition Algorithm Based on Keypoint Pair Feature. Sensors 2022, 22, 6289. https://doi.org/10.3390/s22166289
Ge Z, Shen X, Gao Q, Sun H, Tang X, Cai Q. A Fast Point Cloud Recognition Algorithm Based on Keypoint Pair Feature. Sensors. 2022; 22(16):6289. https://doi.org/10.3390/s22166289
Chicago/Turabian StyleGe, Zhexue, Xiaolei Shen, Quanqin Gao, Haiyang Sun, Xiaoan Tang, and Qingyu Cai. 2022. "A Fast Point Cloud Recognition Algorithm Based on Keypoint Pair Feature" Sensors 22, no. 16: 6289. https://doi.org/10.3390/s22166289
APA StyleGe, Z., Shen, X., Gao, Q., Sun, H., Tang, X., & Cai, Q. (2022). A Fast Point Cloud Recognition Algorithm Based on Keypoint Pair Feature. Sensors, 22(16), 6289. https://doi.org/10.3390/s22166289