
RPDNet: Automatic Fabric Defect Detection Based on a Convolutional Neural Network and Repeated Pattern Analysis


Abstract
:1. Introduction
2. Related Works
2.1. Periodic Pattern Analysis
2.2. Automatic Defect Detection
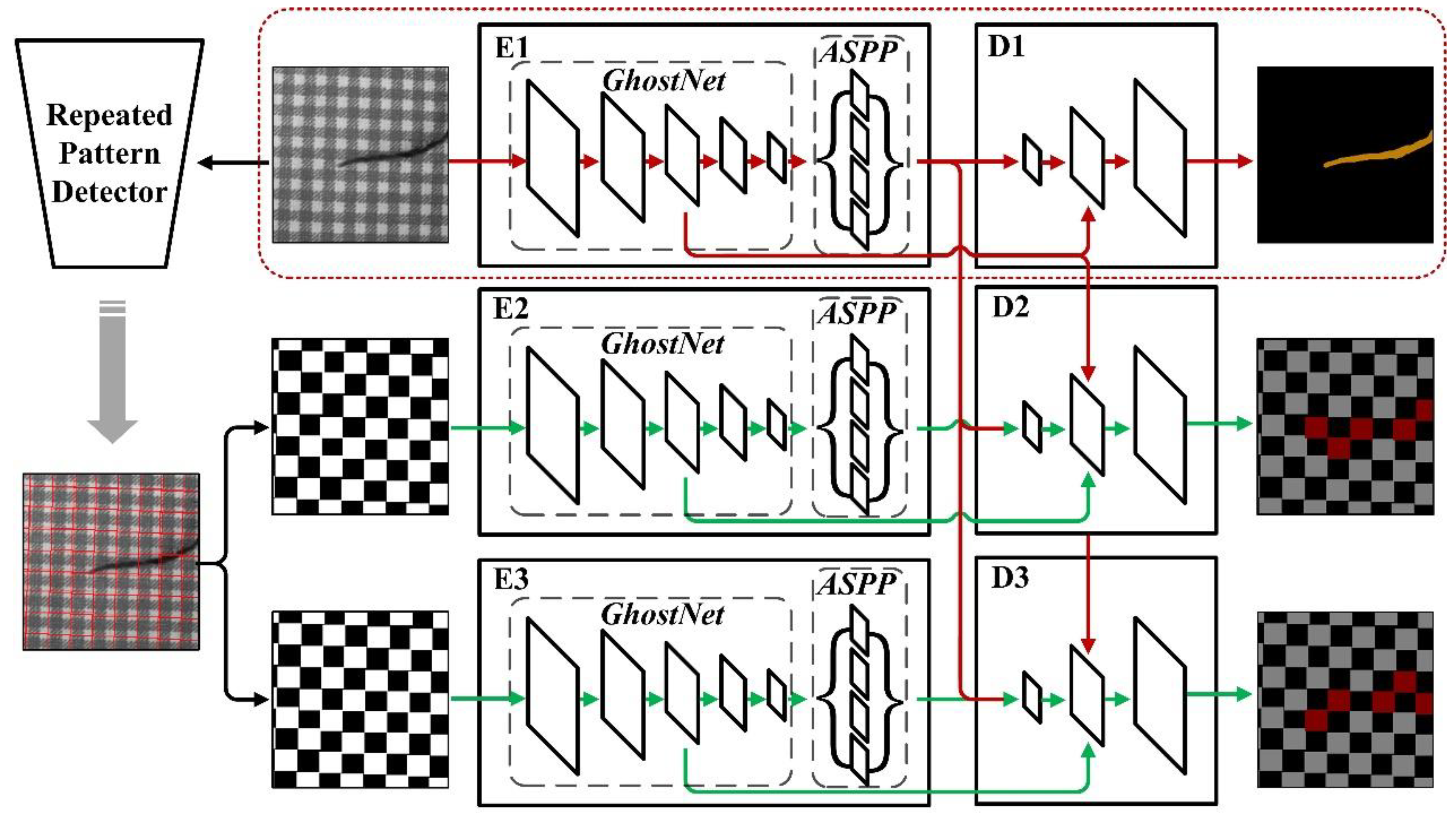
3. Methodology
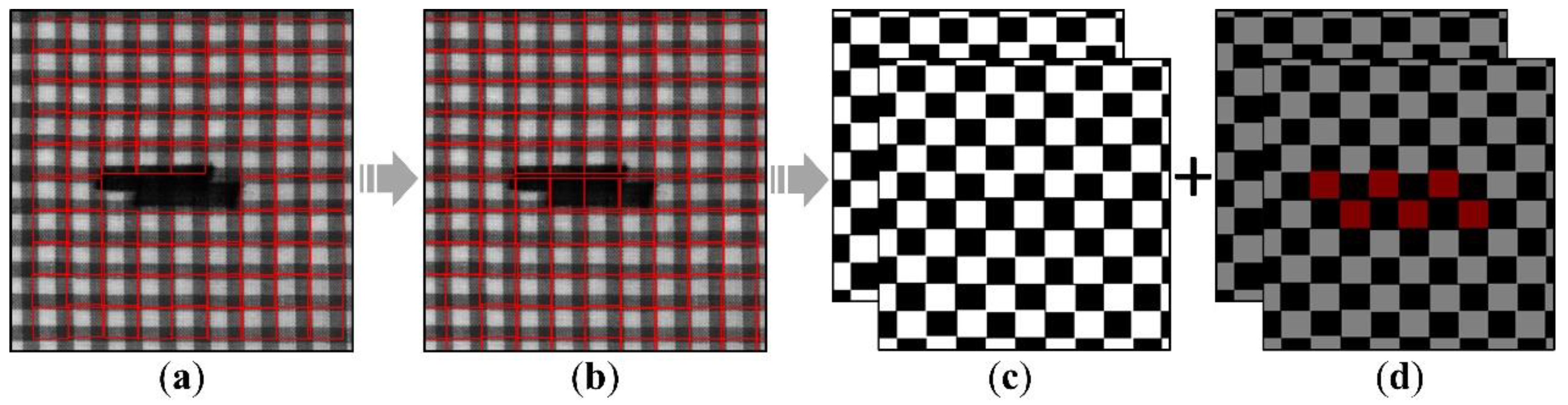
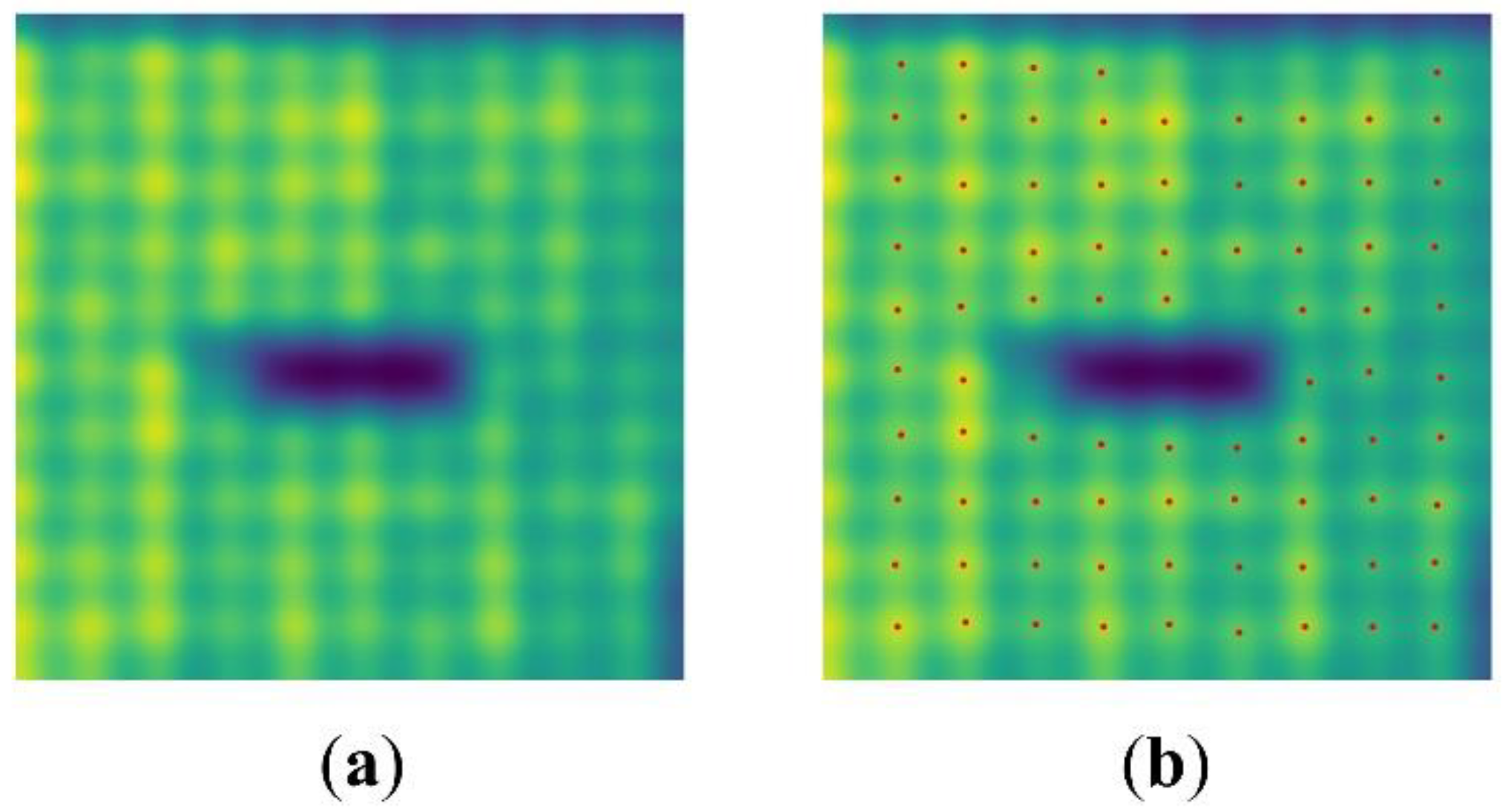
3.1. Repeated Pattern Analysis Stage
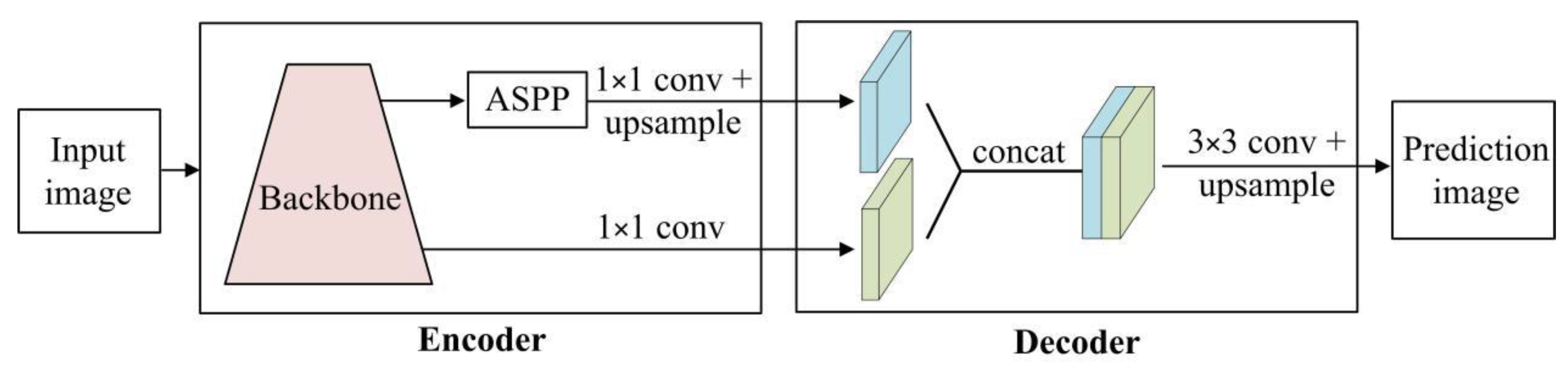
3.2. Semantic Segmentation Stage
3.3. Training Procedure
4. Experiments and Discussion
4.1. Performance Evaluation
4.2. Ablation Studies
4.3. Model Extension
4.4. Experiments on Repeated-Pattern-Free Images
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Srinivasan, K.; Dastoor, P.H.; Radhakrishnaiah, P.; Jayaraman, S. FDAS: A knowledge-based framework for analysis of defects in woven textile structures. J. Text. Inst. Proc. Abstr. 1990, 83, 431–448. [Google Scholar] [CrossRef]
- Ngan, H.; Pang, G.; Yung, N. Review article: Automated fabric defect detection—A review. Image Vis. Comput. 2011, 29, 442–458. [Google Scholar] [CrossRef]
- Hanbay, K.; Talu, M.F.; Özgüven, Ö.F. Fabric defect detection systems and methods—A systematic literature review. Optik 2016, 127, 11960–11973. [Google Scholar] [CrossRef]
- Xie, X. A Review of Recent Advances in Surface Defect Detection using Texture analysis Techniques. Electron. Lett. Comput. Vis. Image Anal. 2008, 7, 1–22. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Xie, H.; Wu, Z. A Robust Fabric Defect Detection Method Based on Improved RefineDet. Sensors 2020, 20, 4260. [Google Scholar] [CrossRef]
- Yang, H.; Chen, Y.; Song, K.; Yin, Z. Multiscale Feature-Clustering-Based Fully Convolutional Autoencoder for Fast Accurate Visual Inspection of Texture Surface Defects. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1450–1467. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, X.; Fang, F. Automatic fabric defect detection using cascaded mixed feature pyramid with guided localization. Sensors 2020, 20, 871. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Zheng, L.; Yin, L.; Chen, J.; Lu, J. Unsupervised Learning with Generative Adversarial Network for Automatic Tire Defect Detection from X-ray Images. Sensors 2021, 21, 6773. [Google Scholar] [CrossRef]
- Ngan, H.; Pang, G.; Yung, N. Motif-based defect detection for patterned fabric. Pattern Recogn. 2008, 41, 1878–1894. [Google Scholar] [CrossRef]
- Jing, J.F.; Ma, H.; Zhang, H.H. Automatic fabric defect detection using a deep convolutional neural network. Color. Technol. 2019, 135, 213–223. [Google Scholar] [CrossRef]
- Jia, L.; Chen, C.; Liang, J.; Hou, Z. Fabric defect inspection based on lattice segmentation and Gabor filtering. Neurocomputing 2017, 238, 84–102. [Google Scholar] [CrossRef]
- Jia, L.; Zhang, J.; Chen, S.; Hou, Z. Fabric defect inspection based on lattice segmentation and lattice templates. J. Frankl. Inst. 2018, 355, 7764–7798. [Google Scholar] [CrossRef]
- Liang, J.A.; Chen, C.B.; Sx, A.; Ju, S.C. Fabric defect inspection based on lattice segmentation and template statistics. Inf. Sci. 2020, 512, 964–984. [Google Scholar]
- Lettry, L.; Perdoch, M.; Vanhoey, K.; Gool, L.V. Repeated Pattern Detection Using CNN Activations. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 27–29 March 2017; pp. 47–55. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zucker, S.W.; Terzopoulos, D. Finding structure in co-occurrence matrices for texture analysis. Comput. Graph. Image Process. 1980, 12, 286–308. [Google Scholar] [CrossRef]
- Unser, M. Sum and Difference Histograms for Texture Classification. IEEE Trans. Pattern Anal. 1986, 8, 118. [Google Scholar] [CrossRef]
- Liu, Y.; Collins, R.T.; Tsin, Y. A Computational Model for Periodic Pattern Perception Based on Frieze and Wallpaper Groups. IEEE Trans. Pattern Anal. 2004, 26, 354–371. [Google Scholar]
- Nasri, A.; Benslimane, R.; Ouaazizi, A.E. A Genetic Based Algorithm for Automatic Motif Detection of Periodic Patterns. In Proceedings of the IEEE Tenth International Conference on Signal-Image Technology & Internet-Based Systems, Marrakech, Morocco, 23–27 November 2014; pp. 112–118. [Google Scholar]
- Xiang, Z.; Zhou, D.; Qian, M.; Ma, M.; Hu, X. Repeat pattern segmentation of print fabric based on adaptive template matching. J. Eng. Fibers Fabr. 2020, 15, 155892502097328. [Google Scholar] [CrossRef]
- Mallik-Goswami, B.; Datta, A.K. Detecting defects in fabric with laser-based morphological image processing. Text. Res. J. 2000, 70, 758–762. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, T.Y. Automated surface inspection for statistical textures. Image Vis. Comput. 2003, 2, 307–323. [Google Scholar] [CrossRef]
- Cohen, F.S.; Fan, Z. Automated inspection of textile fabrics using textural models. IEEE Trans. Pattern Anal. 1991, 13, 803–808. [Google Scholar] [CrossRef]
- Zuo, H.; Wang, Y.; Yang, X.; Xin, W. Fabric Defect Detection Based on Texture Enhancement. In Proceedings of the 5th International Congress on Image and Signal Processing, Chongqing, China, 16–18 October 2012; pp. 876–880. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ren, R.; Hung, T.; Tan, K.C. A Generic Deep-Learning-Based Approach for Automated Surface Inspection. IEEE Trans. Cybern. 2018, 43, 929–940. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, D.; Lee, D.J. Automatic fabric defect detection with a wide-and-compact network. Neurocomputing 2019, 329, 329–338. [Google Scholar] [CrossRef]
- Jing, J.; Wang, Z.; Rätsch, M.; Zhang, H. Mobile-Unet: An efficient convolutional neural network for fabric defect detection. Text. Res. J. 2022, 92, 30–42. [Google Scholar] [CrossRef]
- Hu, G.; Huang, J.; Wang, Q.; Li, J.; Xu, Z.; Huang, X. Unsupervised fabric defect detection based on a deep convolutional generative adversarial network. Text. Res. J. 2020, 90, 247–270. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic Fabric Defect Detection with a Multi-Scale Convolutional Denoising Autoencoder Network Model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef]
- Hu, X.; Fu, M.; Zhu, Z.; Xiang, Z.; Qian, M.; Wang, J. Unsupervised defect detection algorithm for printed fabrics using content-based image retrieval techniques. Text. Res. J. 2021, 91, 2551–2566. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Sifre, L. Rigid-Motion Scattering for Image Classifification. Ph.D. Thesis, Ecole Polytechnique, CMAP, Paris, France, 2014. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1314–1324. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. 2018, 42, 318–327. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; Devito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In COMPSTAT′2010, Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; Springer: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Tsang, C.S.; Ngan, H.Y.; Pang, G.K. Fabric inspection based on the Elo rating method. Pattern Recogn. 2016, 51, 378–394. [Google Scholar] [CrossRef]
- Workgroup on Texture Analysis of DFG’s. TILDA Textile Texture Database. Available online: https://lmb.informatik.uni-freiburg.de/resources/datasets/tilda.en.html (accessed on 10 July 2022).
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Automatic pixel-level crack segmentation in images using fully convolutional neural network based on residual blocks and pixel local weights. Eng. Appl. Artif. Intell. 2021, 104, 104391. [Google Scholar] [CrossRef]
- Pratt, L.; Govender, D.; Klein, R. Defect detection and quantification in electroluminescence images of solar PV modules using U-net semantic segmentation. Renew. Energy 2021, 178, 1211–1222. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
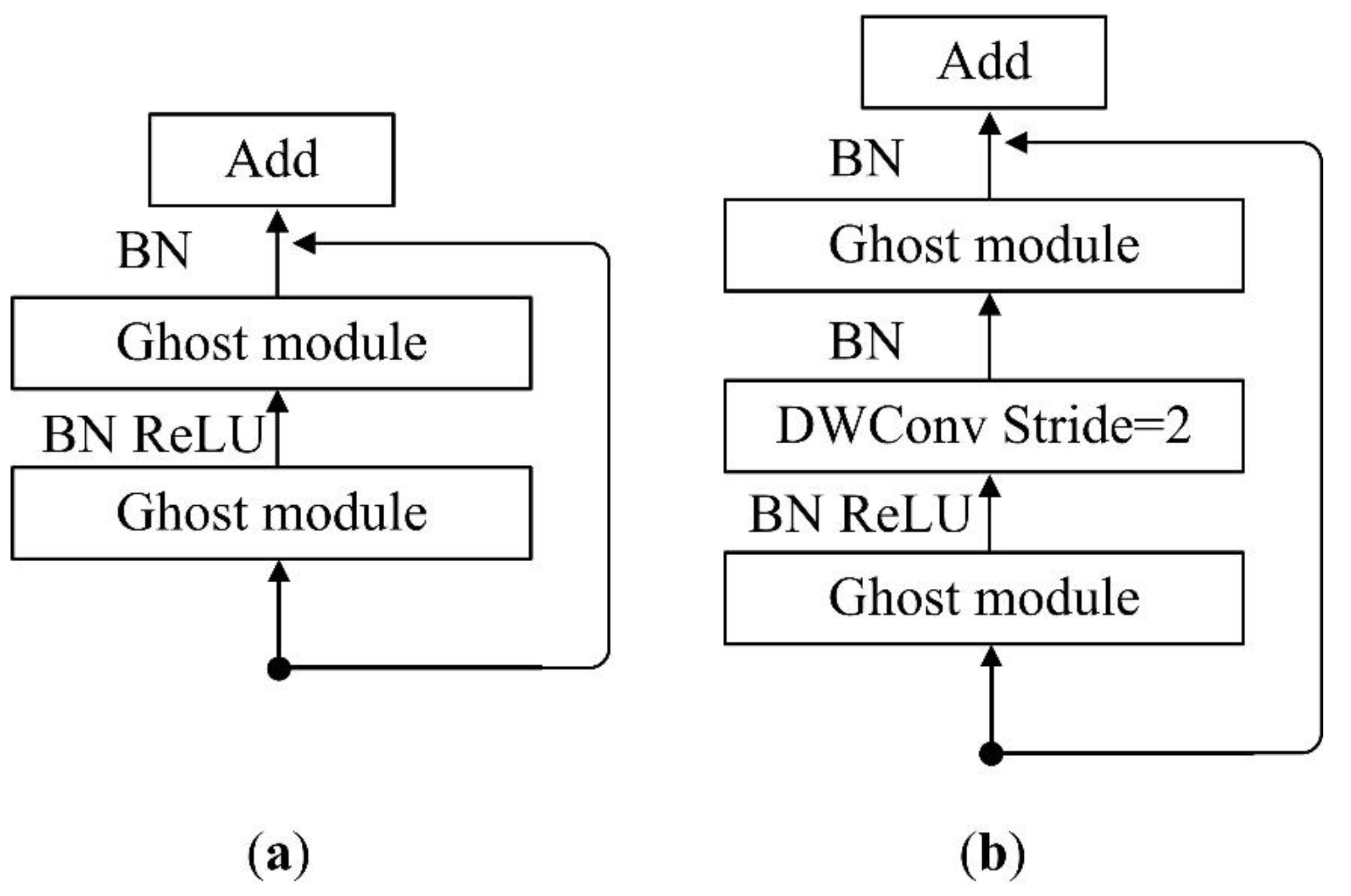{kind=link}
{kind=link}
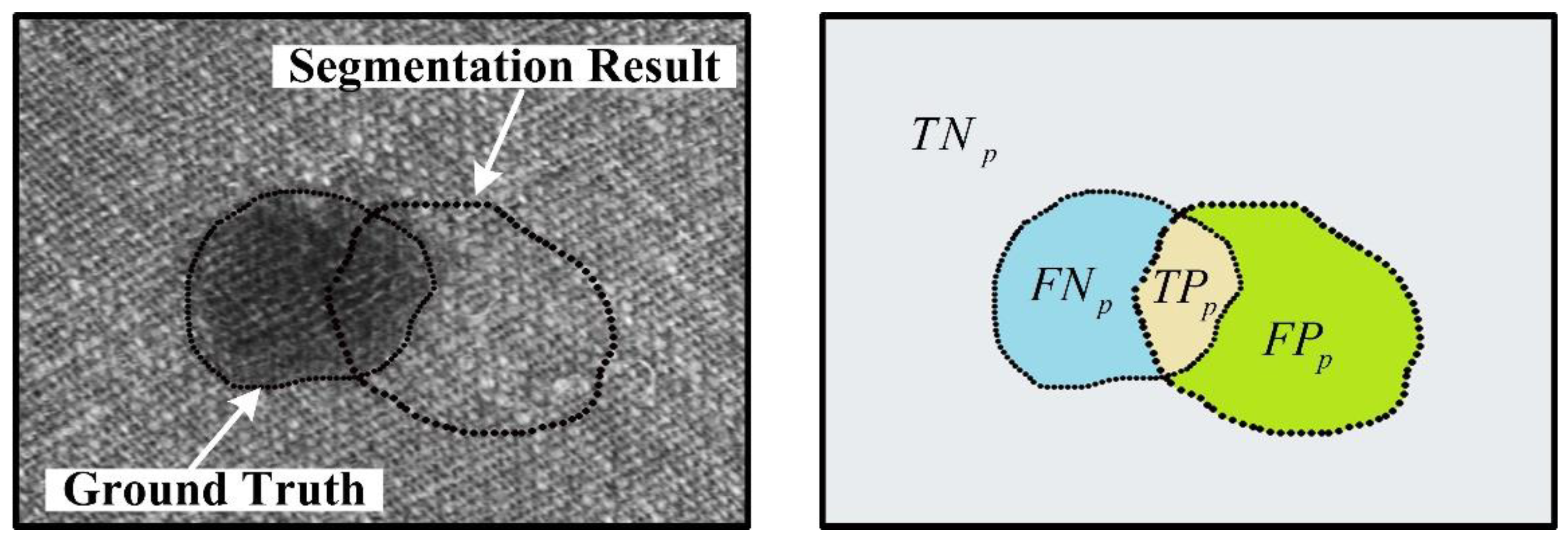{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Kernel Size | #Mid | #Out | SE | Stride |
|---|---|---|---|---|---|---|
| 256 × 256 × 3 | Conv2d | 3 × 3 | - | 16 | - | 2 |
| 128 × 128 × 16 | G-bneck | 3 × 3 | 16 | 16 | - | 1 |
| 128 × 128 × 16 | G-bneck | 3 × 3 | 48 | 24 | - | 2 |
| 64 × 64 × 24 | G-bneck | 3 × 3 | 72 | 24 | - | 1 |
| 64 × 64 × 24 | G-bneck | 5 × 5 | 72 | 40 | True | 2 |
| 32 × 32 × 40 | G-bneck | 5 × 5 | 120 | 40 | True | 1 |
| 32 × 32 × 40 | G-bneck | 3 × 3 | 240 | 80 | - | 2 |
| 16 × 16 × 80 | G-bneck | 3 × 3 | 200 | 80 | - | 1 |
| 16 × 16 × 80 | G-bneck | 3 × 3 | 184 | 80 | - | 1 |
| 16 × 16 × 80 | G-bneck | 3 × 3 | 184 | 80 | - | 1 |
| 16 × 16 × 80 | G-bneck | 3 × 3 | 480 | 112 | True | 1 |
| 16 × 16 × 112 | G-bneck | 3 × 3 | 672 | 112 | True | 1 |
| 16 × 16 × 112 | G-bneck | 5 × 5 | 672 | 160 | True | 2 |
| 8 × 8 × 160 | G-bneck | 5 × 5 | 960 | 160 | - | 1 |
| 8 × 8 × 160 | G-bneck | 5 × 5 | 960 | 160 | True | 1 |
| 8 × 8 × 160 | G-bneck | 5 × 5 | 960 | 160 | - | 1 |
| 8 × 8 × 160 | G-bneck | 5 × 5 | 960 | 160 | True | 1 |
| Dataset | Class | Number | Color |
|---|---|---|---|
| Fabric Images | Hole | 100 | Red |
| Thick bar | 100 | Green | |
| Thin bar | 100 | Yellow | |
| Broken end | 100 | Orange | |
| Knot | 100 | Purple | |
| Netting multiple | 100 | Cyan | |
| Non-defective | 100 | Black | |
| TILDA | Hole | 240 | Red |
| Color spot | 240 | Green | |
| Thread error | 240 | Yellow | |
| Foreign body | 240 | Orange | |
| Non-defective | 240 | Black |
| Dataset | Metric | FCN | UNet | Mobile-Unet | LSTS | RPDNet |
|---|---|---|---|---|---|---|
| FI | IoU | 0.645 | 0.687 | 0.727 | 0.650 | 0.766 |
| Recall | 0.771 | 0.800 | 0.792 | 0.811 | 0.833 | |
| Precision | 0.798 | 0.822 | 0.898 | 0.766 | 0.905 | |
| F1-Measure | 0.784 | 0.809 | 0.842 | 0.788 | 0.867 | |
| TILDA | IoU | 0.719 | 0.687 | 0.752 | 0.831 | |
| Recall | 0.831 | 0.784 | 0.833 | 0.886 | ||
| Precision | 0.842 | 0.849 | 0.886 | 0.930 | ||
| F1-Measure | 0.836 | 0.815 | 0.859 | 0.907 |
| Method | IoU | Recall | Precision | F1-Measure |
|---|---|---|---|---|
| RPDNet w/o E2-D2 and E3-D3 | 0.767 | 0.850 | 0.887 | 0.868 |
| RPDNet w blank input labels | 0.801 | 0.866 | 0.914 | 0.890 |
| RPDNet | 0.831 | 0.886 | 0.930 | 0.907 |
| Method | IoU | Recall | Precision | F1-Measure |
|---|---|---|---|---|
| UNet | 0.687 | 0.784 | 0.849 | 0.815 |
| RPDNet-UNet | 0.730 (6.2%) | 0.813 (3.7%) | 0.877 (3.4%) | 0.844 (3.6%) |
| MobileNetv2 and DeeplabV3+ | 0.759 | 0.819 | 0.911 | 0.863 |
| RPDNet-MobileNetv2 and DeeplabV3+ | 0.820 (8.0%) | 0.869 (6.1%) | 0.935 (2.6%) | 0.901 (4.4%) |
| GhostNet and DeeplabV3+ | 0.767 | 0.850 | 0.887 | 0.868 |
| RPDNet-GhostNet and DeeplabV3+ | 0.831 (8.3%) | 0.886 (4.2%) | 0.930 (4.9%) | 0.907 (4.5%) |
| Method | IoU | Recall | Precision | F1-Measure |
|---|---|---|---|---|
| RPDNet w/o E2-D2 and E3-D3 | 0.754 | 0.825 | 0.897 | 0.860 |
| RPDNet w blank input labels | 0.774 | 0.833 | 0.916 | 0.872 |
| RPDNet | 0.772 | 0.848 | 0.895 | 0.871 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Xiang, Z. RPDNet: Automatic Fabric Defect Detection Based on a Convolutional Neural Network and Repeated Pattern Analysis. Sensors 2022, 22, 6226. https://doi.org/10.3390/s22166226
Huang Y, Xiang Z. RPDNet: Automatic Fabric Defect Detection Based on a Convolutional Neural Network and Repeated Pattern Analysis. Sensors. 2022; 22(16):6226. https://doi.org/10.3390/s22166226
Chicago/Turabian StyleHuang, Yubo, and Zhong Xiang. 2022. "RPDNet: Automatic Fabric Defect Detection Based on a Convolutional Neural Network and Repeated Pattern Analysis" Sensors 22, no. 16: 6226. https://doi.org/10.3390/s22166226
APA StyleHuang, Y., & Xiang, Z. (2022). RPDNet: Automatic Fabric Defect Detection Based on a Convolutional Neural Network and Repeated Pattern Analysis. Sensors, 22(16), 6226. https://doi.org/10.3390/s22166226