Brain Decoding of Multiple Subjects for Estimating Visual Information Based on a Probabilistic Generative Model


Abstract
:1. Introduction
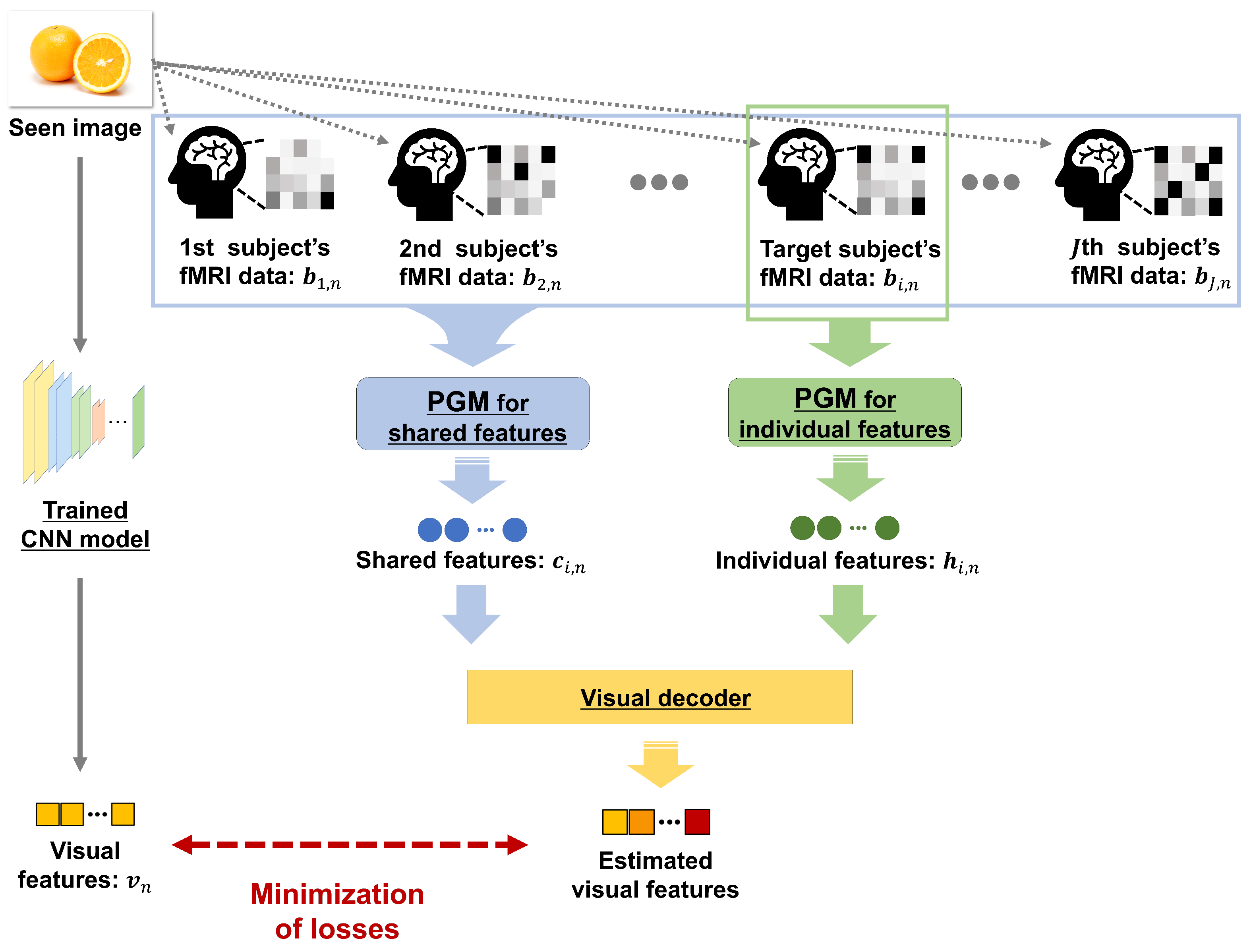
2. Estimation of Visual Features of Seen Image Using Shared and Individual Features
2.1. Training Phase: Construction of PGM and Visual Decoder
2.1.1. Step 1: Construction of PGM
| Algorithm 1: PGM for shared features . |
|
2.1.2. Step 2: Construction of Visual Decoder
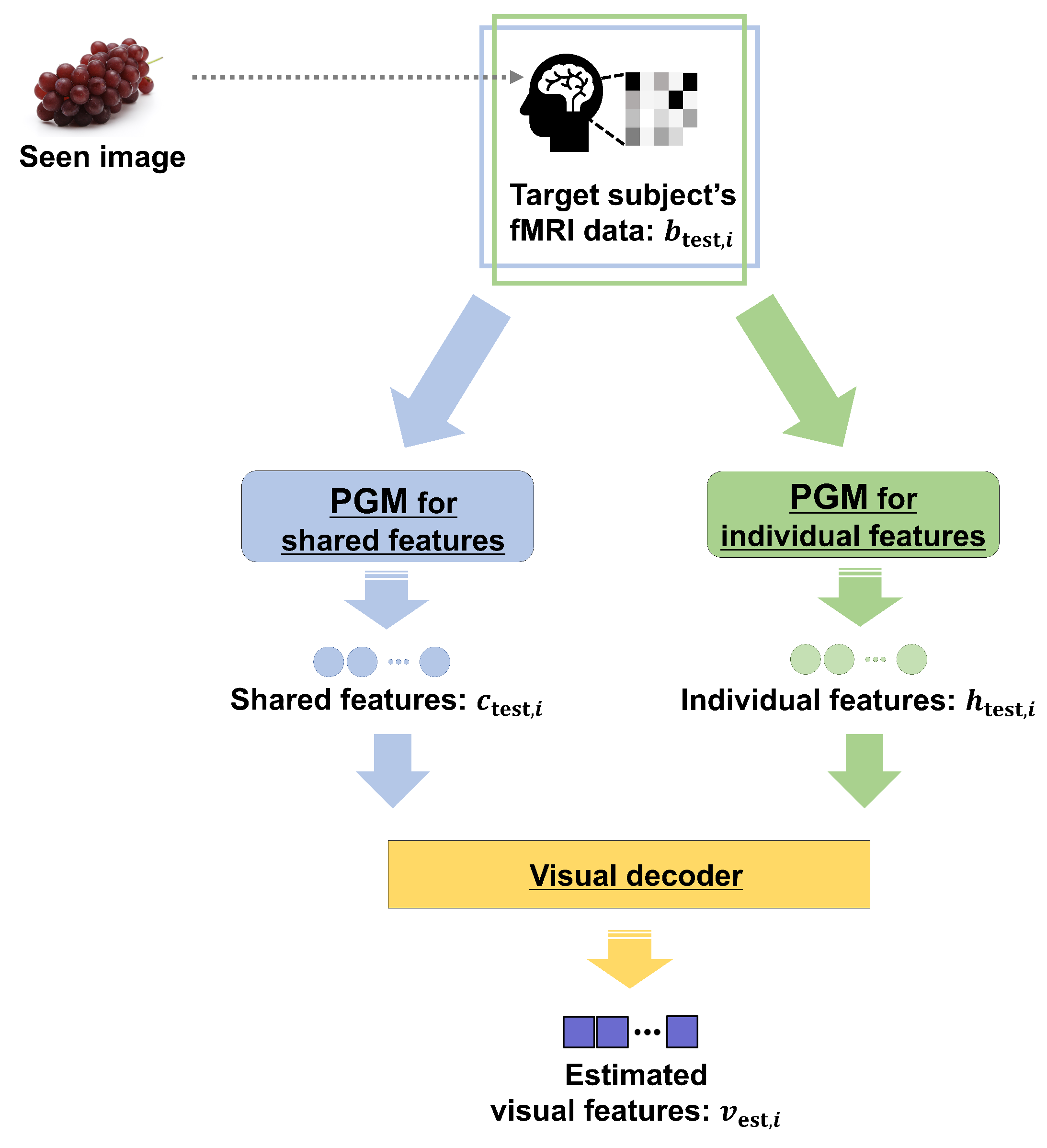
2.2. Test Phase: Estimation of Visual Features of Seen Image
2.2.1. Step 1: Extraction of Shared and Individual Features
2.2.2. Step 2: Estimation of Visual Features
3. Experimental Results
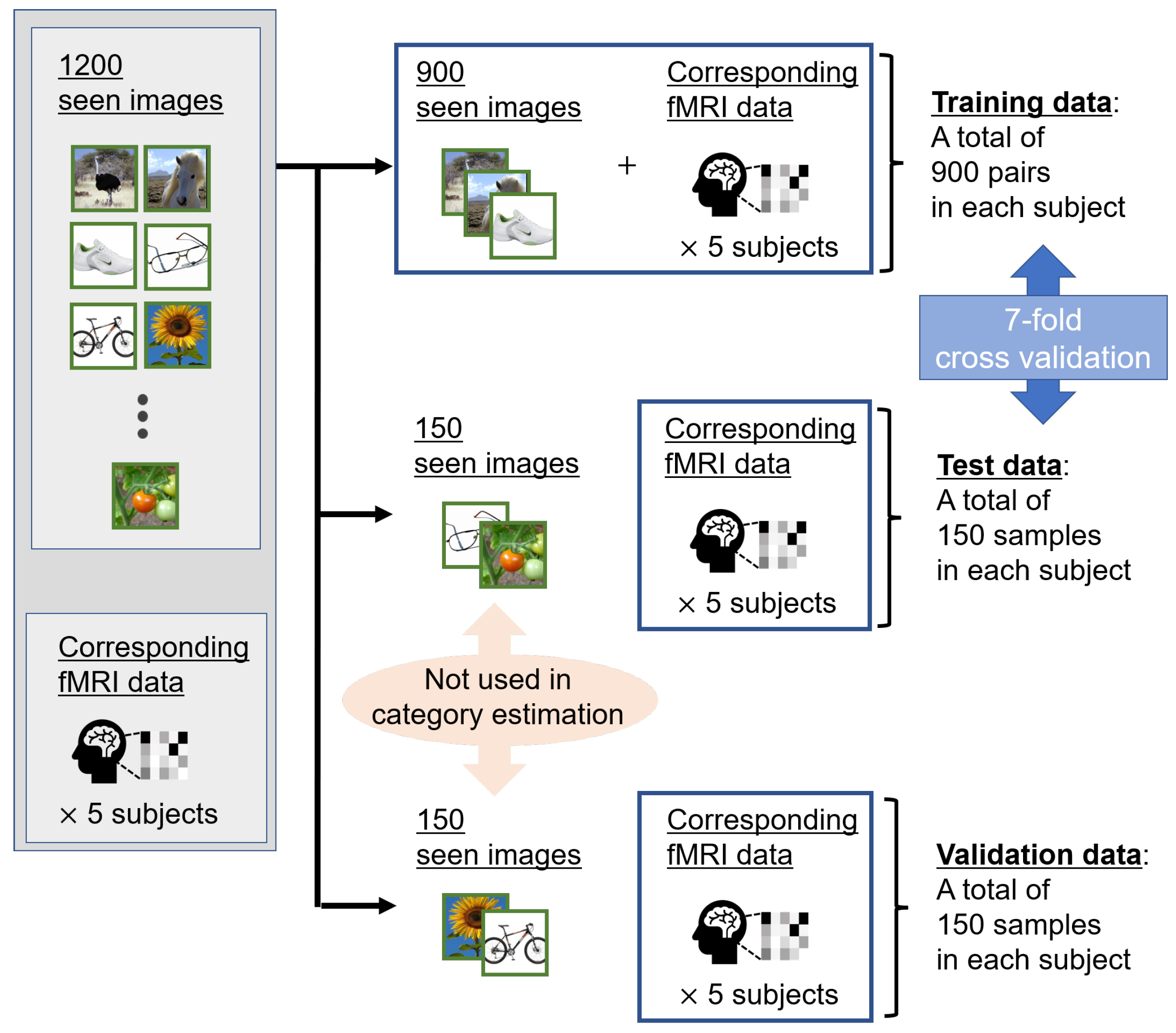
3.1. Dataset
3.2. Experimental Conditions
3.3. Comparison Methods
- Multi-subject probabilistic generative model (MSPGM):
- Multi-view Bayesian generative model for multi-subject fMRI Data (MVBGM-MS):
- Single-subject probabilistic generative model (SSPGM):
- Sparse linear regression (SLR):
- Canonical correlation analysis (CCA):
- Bayesian CCA (BCCA):
- Deep CCA (Deep CCA):The Deep CCA [50] method is also an extension of CCA that adopts deep learning. Similarly to CCA, visual features and fMRI data are converted into features belonging to the latent space, and accuracy is evaluated in the space. We searched for in the number of dimensions in the latent space.
3.4. Results and Discussion
3.4.1. Estimation Performance Evaluation
3.4.2. Qualitative Evaluation
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section 2.1.1: Construction of PGM | |
|---|---|
| fMRI data corresponding to nth image in ith subject | |
| fMRI data in ith subject () | |
| Shared features corresponding to nth image | |
| Shared features () | |
| Projection matrix that transforms fMRI data in ith subject into shared features | |
| I | Identity matrix |
| Covariance matrix of shared features | |
| Mean of fMRI data in ith subject | |
| Variance of fMRI data in ith subject | |
| Concatenated fMRI data corresponding to nth image for total J subjects | |
| Concatenated mean for total J subjects | |
| Concatenated projection matrix for total J subjects | |
| Error term of shared features | |
| Joint covariance | |
| Expected value of expectation maximization (EM) algorithm | |
| Variance of EM algorithm | |
| Expected value in maximization step of EM algorithm | |
| Updated projection matrix that transforms fMRI data in ith subject | |
| Updated variance of fMRI data in ith subject | |
| Updated covariance matrix of shared features | |
| Estimated shared features corresponding to nth image in ith subject | |
| J | Number of subjects |
| N | Number of seen images |
| n | Index of seen images () |
| i | Index of subjects () |
| Dimensions of shared features | |
| Dimensions of fMRI data in ith subject | |
| Sum of dimensions for total J subjects | |
| Updated PGM parameters (, , ) | |
| PGM parameters before update () | |
| Individual features corresponding to nth image in ith subject | |
| Individual features in ith subject () | |
| Projection matrix that transforms fMRI data in ith subject into individual features | |
| Variance of fMRI data in ith subject | |
| Covariance matrix of individual features | |
| Joint covariance in ith subject | |
| Error term of individual features in ith subject | |
| Dimensions of individual features | |
| Section 2.1.2: Construction of visual decoder | |
| Visual features of nth image | |
| Visual features () | |
| Estimated shared features in ith subject () | |
| Projection matrix that transforms shared features into visual features in ith subject | |
| Projection matrix that transforms individual features into visual features in ith subject | |
| Regularization parameter corresponding to shared features in ith subject | |
| Regularization parameter corresponding to individual features in ith subject | |
| Dimensions of visual features | |
| Section 2.2.1: Extraction of shared and individual features | |
| fMRI data in ith subject | |
| Shared features in ith subject | |
| Individual features in ith subject | |
| Section 2.2.2: Estimation of visual features | |
| Estimated visual features by visual decoder in ith subject | |
References
- Ponce, C.R.; Xiao, W.; Schade, P.F.; Hartmann, T.S.; Kreiman, G.; Livingstone, M.S. Evolving images for visual neurons using a deep generative network reveals coding principles and neuronal preferences. Cell 2019, 177, 999–1009. [Google Scholar] [CrossRef] [PubMed]
- Fazli, S.; Mehnert, J.; Steinbrink, J.; Curio, G.; Villringer, A.; Müller, K.R.; Blankertz, B. Enhanced performance by a hybrid NIRS–EEG brain computer interface. Neuroimage 2012, 59, 519–529. [Google Scholar] [CrossRef] [PubMed]
- Müller, K.R.; Tangermann, M.; Dornhege, G.; Krauledat, M.; Curio, G.; Blankertz, B. Machine learning for real-time single-trial EEG-analysis: From brain–computer interfacing to mental state monitoring. J. Neurosci. Methods 2008, 167, 82–90. [Google Scholar] [CrossRef]
- Engel, S.A.; Rumelhart, D.E.; Wandell, B.A.; Lee, A.T.; Glover, G.H.; Chichilnisky, E.J.; Shadlen, M.N. fMRI of human visual cortex. Nature 1994, 369, 525. [Google Scholar] [CrossRef] [PubMed]
- Engel, S.A.; Glover, G.H.; Wandell, B.A. Retinotopic organization in human visual cortex and the spatial precision of functional MRI. Cereb. Cortex 1997, 7, 181–192. [Google Scholar] [CrossRef] [PubMed]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef]
- Shen, G.; Dwivedi, K.; Majima, K.; Horikawa, T.; Kamitani, Y. End-to-end deep image reconstruction from human brain activity. Front. Comput. Neurosci. 2019, 13, 21. [Google Scholar] [CrossRef]
- Han, K.; Wen, H.; Shi, J.; Lu, K.H.; Zhang, Y.; Fu, D.; Liu, Z. Variational autoencoder: An unsupervised model for encoding and decoding fMRI activity in visual cortex. NeuroImage 2019, 198, 125–136. [Google Scholar] [CrossRef]
- Baillet, S. Magnetoencephalography for brain electrophysiology and imaging. Nat. Neurosci. 2017, 20, 327–339. [Google Scholar] [CrossRef] [PubMed]
- Zarief, C.N.; Hussein, W. Decoding the human brain activity and predicting the visual stimuli from magnetoencephalography (meg) recordings. In Proceedings of the 2019 International Conference on Intelligent Medicine and Image Processing, Bali, Indonesia, 19–22 April 2019; pp. 35–42. [Google Scholar]
- Liljeström, M.; Hulten, A.; Parkkonen, L.; Salmelin, R. Comparing MEG and fMRI views to naming actions and objects. Hum. Brain Mapp. 2009, 30, 1845–1856. [Google Scholar] [CrossRef] [PubMed]
- Taylor, M.; Donner, E.; Pang, E. fMRI and MEG in the study of typical and atypical cognitive development. Neurophysiol. Clin./Clin. Neurophysiol. 2012, 42, 19–25. [Google Scholar]
- Zheng, W.L.; Santana, R.; Lu, B.L. Comparison of classification methods for EEG-based emotion recognition. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering, Toronto, ON, Canada, 7–12 June 2015; pp. 1184–1187. [Google Scholar]
- Zheng, W.L.; Zhu, J.Y.; Lu, B.L. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2017, 10, 417–429. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Anitha, J. Brain signal based human emotion analysis by circular back propagation and Deep Kohonen Neural Networks. Comput. Electr. Eng. 2018, 68, 170–180. [Google Scholar] [CrossRef]
- Matsuo, E.; Kobayashi, I.; Nishimoto, S.; Nishida, S.; Asoh, H. Describing semantic representations of brain activity evoked by visual stimuli. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 576–583. [Google Scholar]
- Takada, S.; Togo, R.; Ogawa, T.; Haseyama, M. Generation of viewed image captions from human brain activity via unsupervised text latent space. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2521–2525. [Google Scholar]
- Shen, G.; Horikawa, T.; Majima, K.; Kamitani, Y. Deep image reconstruction from human brain activity. PLoS Comput. Biol. 2019, 15, e1006633. [Google Scholar] [CrossRef]
- Beliy, R.; Gaziv, G.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI. In Proceedings of the Advances in Neural Information Processing Systems 32, Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Ren, Z.; Li, J.; Xue, X.; Li, X.; Yang, F.; Jiao, Z.; Gao, X. Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning. NeuroImage 2021, 228, 117602. [Google Scholar]
- Nicolelis, M.A. Actions from thoughts. Nature 2001, 409, 403–407. [Google Scholar] [CrossRef]
- Lebedev, M.A.; Nicolelis, M.A. Brain-machine interfaces: Past, present and future. Trends Neurosci. 2006, 29, 536–546. [Google Scholar] [CrossRef]
- Patil, P.G.; Turner, D.A. The development of brain-machine interface neuroprosthetic devices. Neurotherapeutics 2008, 5, 137–146. [Google Scholar] [CrossRef]
- Cox, D.D.; Savoy, R.L. Functional magnetic resonance imaging (fMRI) ‘brain reading’: Detecting and classifying distributed patterns of fMRI activity in human visual cortex. Neuroimage 2003, 19, 261–270. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Daugman, J.G. Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. JOSA A 1985, 2, 1160–1169. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Nonaka, S.; Majima, K.; Aoki, S.C.; Kamitani, Y. Brain Hierarchy Score: Which Deep Neural Networks Are Hierarchically Brain-Like? IScience 2020, 24, 103013. [Google Scholar] [CrossRef] [PubMed]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Brain decoding of viewed image categories via semi-supervised multi-view Bayesian generative model. IEEE Trans. Signal Process. 2020, 68, 5769–5781. [Google Scholar] [CrossRef]
- Chen, P.H.C.; Chen, J.; Yeshurun, Y.; Hasson, U.; Haxby, J.; Ramadge, P.J. A reduced-dimension fMRI shared response model. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 460–468. [Google Scholar]
- Higashi, T.; Maeda, K.; Ogawa, T.; Haseyama, M. Estimation of viewed images using individual and shared brain responses. In Proceedings of the IEEE 9th Global Conference on Consumer Electronics, Kobe, Japan, 13–16 October 2020; pp. 716–717. [Google Scholar]
- Higashi, T.; Maeda, K.; Ogawa, T.; Haseyama, M. Estimation of Visual Features of Viewed Image From Individual and Shared Brain Information Based on FMRI Data Using Probabilistic Generative Model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 1335–1339. [Google Scholar]
- Papadimitriou, A.; Passalis, N.; Tefas, A. Visual representation decoding from human brain activity using machine learning: A baseline study. Pattern Recognit. Lett. 2019, 128, 38–44. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar]
- Kourtzi, Z.; Kanwisher, N. Cortical regions involved in perceiving object shape. J. Neurosci. 2000, 20, 3310–3318. [Google Scholar] [CrossRef]
- Kanwisher, N.; McDermott, J.; Chun, M.M. The fusiform face area: A module in human extrastriate cortex specialized for face perception. J. Neurosci. 1997, 17, 4302–4311. [Google Scholar] [CrossRef]
- Epstein, R.; Kanwisher, N. A cortical representation of the local visual environment. Nature 1998, 392, 598–601. [Google Scholar] [CrossRef]
- Sereno, M.I.; Dale, A.; Reppas, J.; Kwong, K.; Belliveau, J.; Brady, T.; Rosen, B.; Tootell, R. Borders of multiple visual areas in humans revealed by functional magnetic resonance imaging. Science 1995, 268, 889–893. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Multi-View bayesian generative model for multi-Subject fMRI data on brain decoding of viewed image categories. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 1215–1219. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Hotelling, H. Relations between two sets of variates. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 162–190. [Google Scholar]
- Fujiwara, Y.; Miyawaki, Y.; Kamitani, Y. Modular encoding and decoding models derived from Bayesian canonical correlation analysis. Neural Comput. 2013, 25, 979–1005. [Google Scholar] [CrossRef]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International Conference on Machine Learning, Miami, FL, USA, 4–7 December 2013; pp. 1247–1255. [Google Scholar]
- Ek, C.H.; Torr, P.H.; Lawrence, N.D. Gaussian process latent variable models for human pose estimation. In Proceedings of the International Workshop on Machine Learning for Multi-modal Interaction, Brno, Czech Republic, 28–30 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 132–143. [Google Scholar]



| Subject1 | Subject2 | Subject3 | Subject4 | Subject5 | Average | |
|---|---|---|---|---|---|---|
| Proposed Method (PM) | 0.756 | |||||
| MSPGM | 0.744 | 0.801 | 0.857 | 0.850 | 0.771 | 0.805 |
| MVBGM-MS [46] | 0.764 | 0.832 | 0.814 | 0.756 | 0.792 | |
| SSPGM | 0.696 | 0.802 | 0.859 | 0.851 | 0.763 | 0.794 |
| SLR [8] | 0.772 | 0.734 | 0.817 | 0.809 | 0.711 | 0.769 |
| CCA [48] | 0.706 | 0.723 | 0.796 | 0.782 | 0.705 | 0.742 |
| BCCA [49] | 0.661 | 0.762 | 0.835 | 0.824 | 0.740 | 0.764 |
| Deep CCA [50] | 0.622 | 0.697 | 0.792 | 0.755 | 0.685 | 0.710 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Higashi, T.; Maeda, K.; Ogawa, T.; Haseyama, M. Brain Decoding of Multiple Subjects for Estimating Visual Information Based on a Probabilistic Generative Model. Sensors 2022, 22, 6148. https://doi.org/10.3390/s22166148
Higashi T, Maeda K, Ogawa T, Haseyama M. Brain Decoding of Multiple Subjects for Estimating Visual Information Based on a Probabilistic Generative Model. Sensors. 2022; 22(16):6148. https://doi.org/10.3390/s22166148
Chicago/Turabian StyleHigashi, Takaaki, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2022. "Brain Decoding of Multiple Subjects for Estimating Visual Information Based on a Probabilistic Generative Model" Sensors 22, no. 16: 6148. https://doi.org/10.3390/s22166148
APA StyleHigashi, T., Maeda, K., Ogawa, T., & Haseyama, M. (2022). Brain Decoding of Multiple Subjects for Estimating Visual Information Based on a Probabilistic Generative Model. Sensors, 22(16), 6148. https://doi.org/10.3390/s22166148