
A Smart Visual Sensing Concept Involving Deep Learning for a Robust Optical Character Recognition under Hard Real-World Conditions



Abstract
:1. Introduction
2. Related Works
2.1. Text Detection
- (A)
- Detecting text on scanned images of printed documents that contain no handwriting.
- (B)
- Detecting text on scanned images of printed documents that contain handwriting.
- (C)
- Detecting text on images of natural scenes or on images of printed documents that have been captured by a camera (e.g., smartphone camera).
- (a)
- Text elements are normally separated, and have no other text elements in their background, but traditional object detection can have multiple objects within one anchor—for example, a person walking in front of a car.
- (b)
- Text can be rotated to the left or to the right, or it can have a curved path. Based on these properties, the text detection models must be extended to support a greater variety of cases (for example, one could take and extend an efficient and accurate existing text detector (e.g., EAST) [10]).
2.2. Text Recognition
2.2.1. Traditional/Classical Machine-Learning-Based Methods for Text Recognition
2.2.2. Deep-Learning-Based Methods for Text Recognition
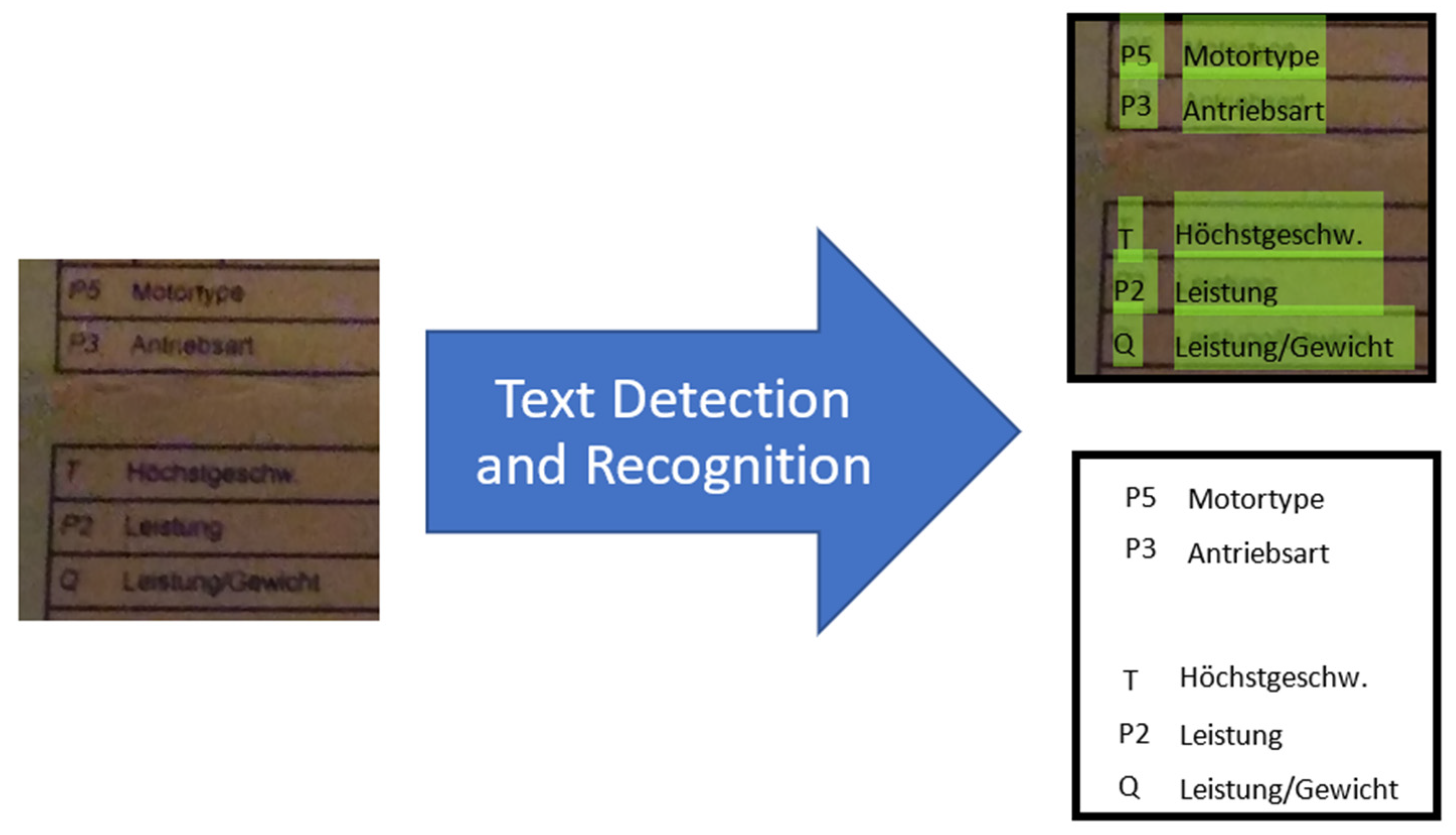
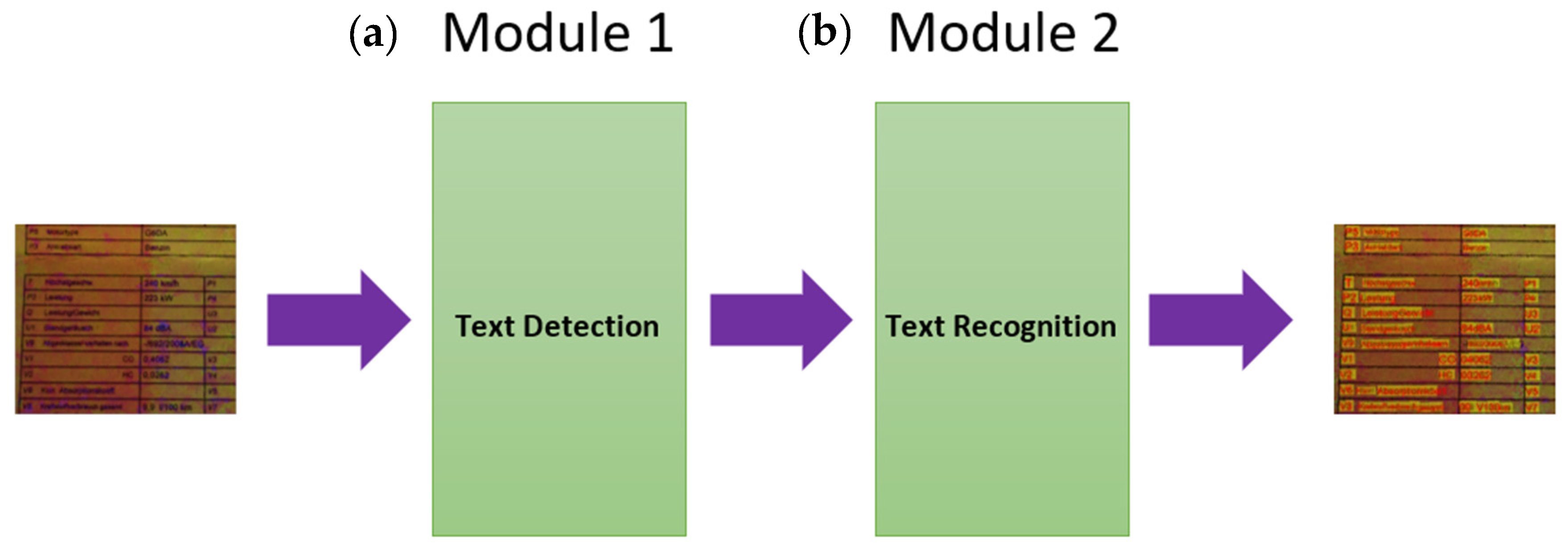
3. Our New Method/Model for “Text Detection” and “Text Recognition”
- Blur problems, e.g., focus blur, Gaussian blur, or motion blur;
- Noise problems, e.g., salt noise or pepper noise, depending on the image sensor’s sensitivity;
- Contrast problems, e.g., shadows, spotlight, and contrast adjustment.
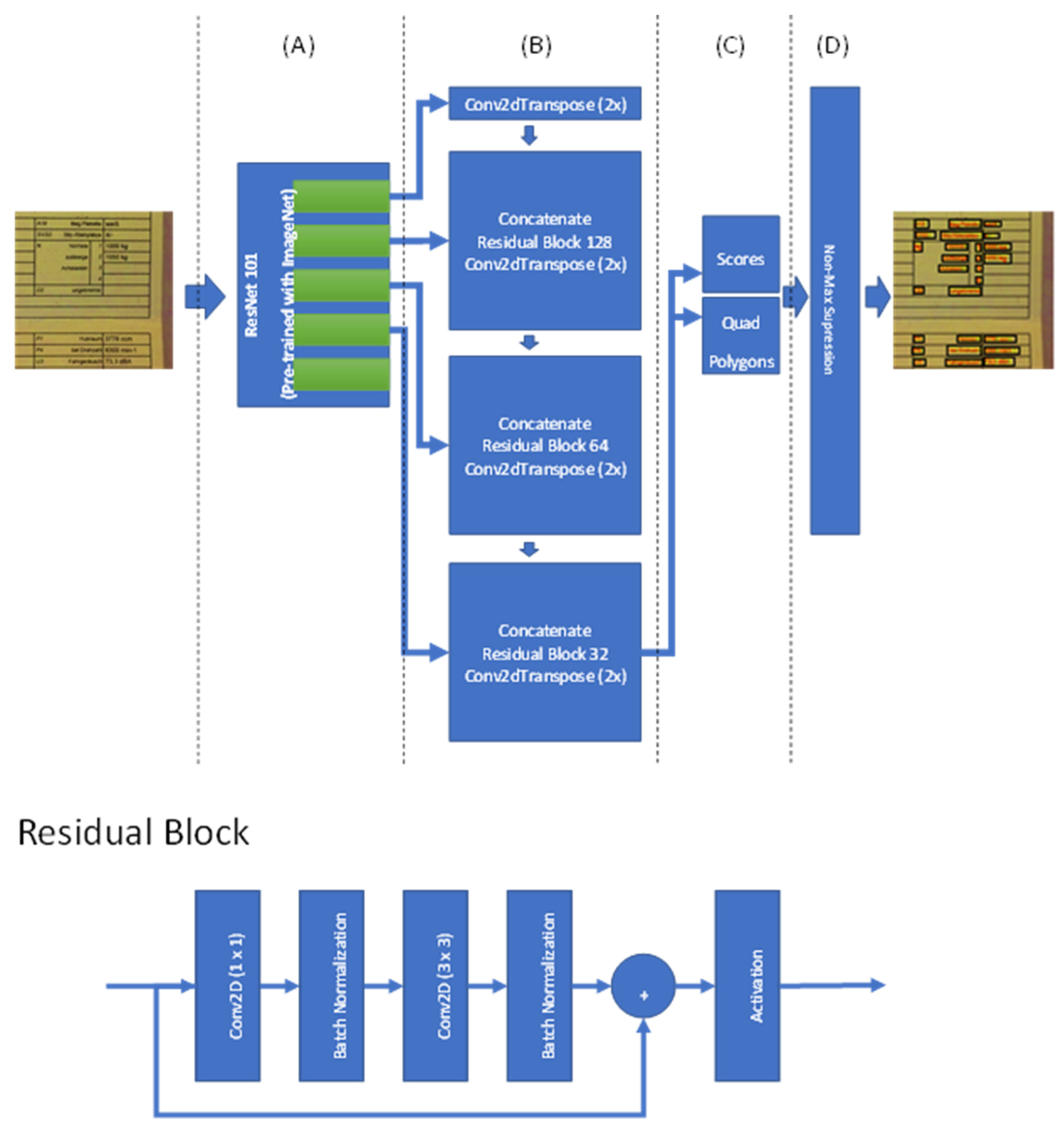
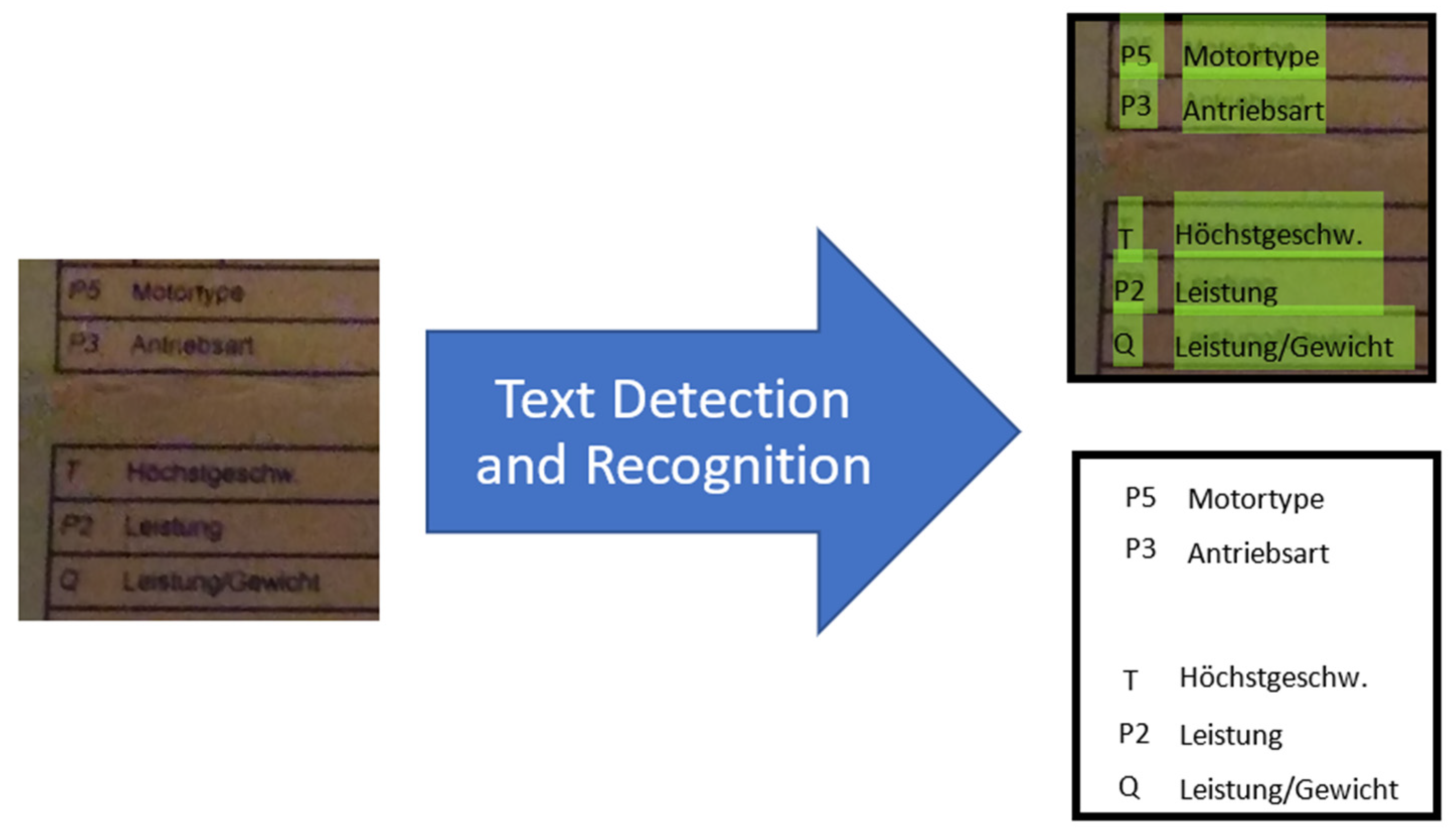
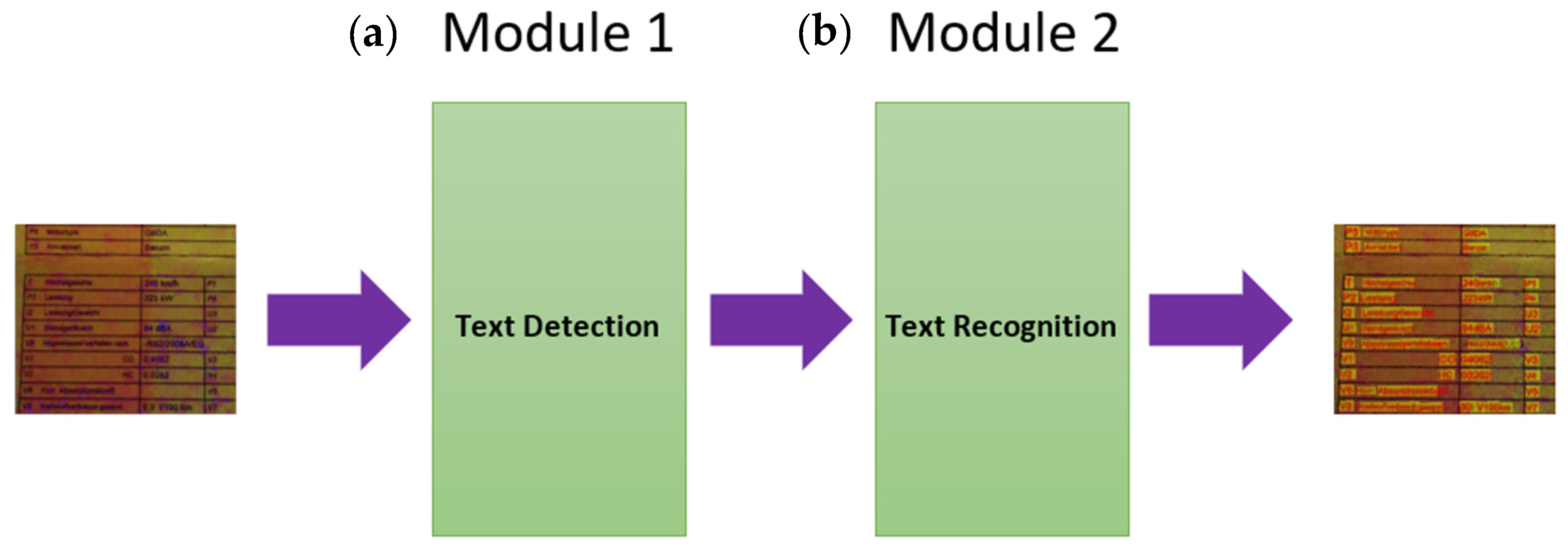
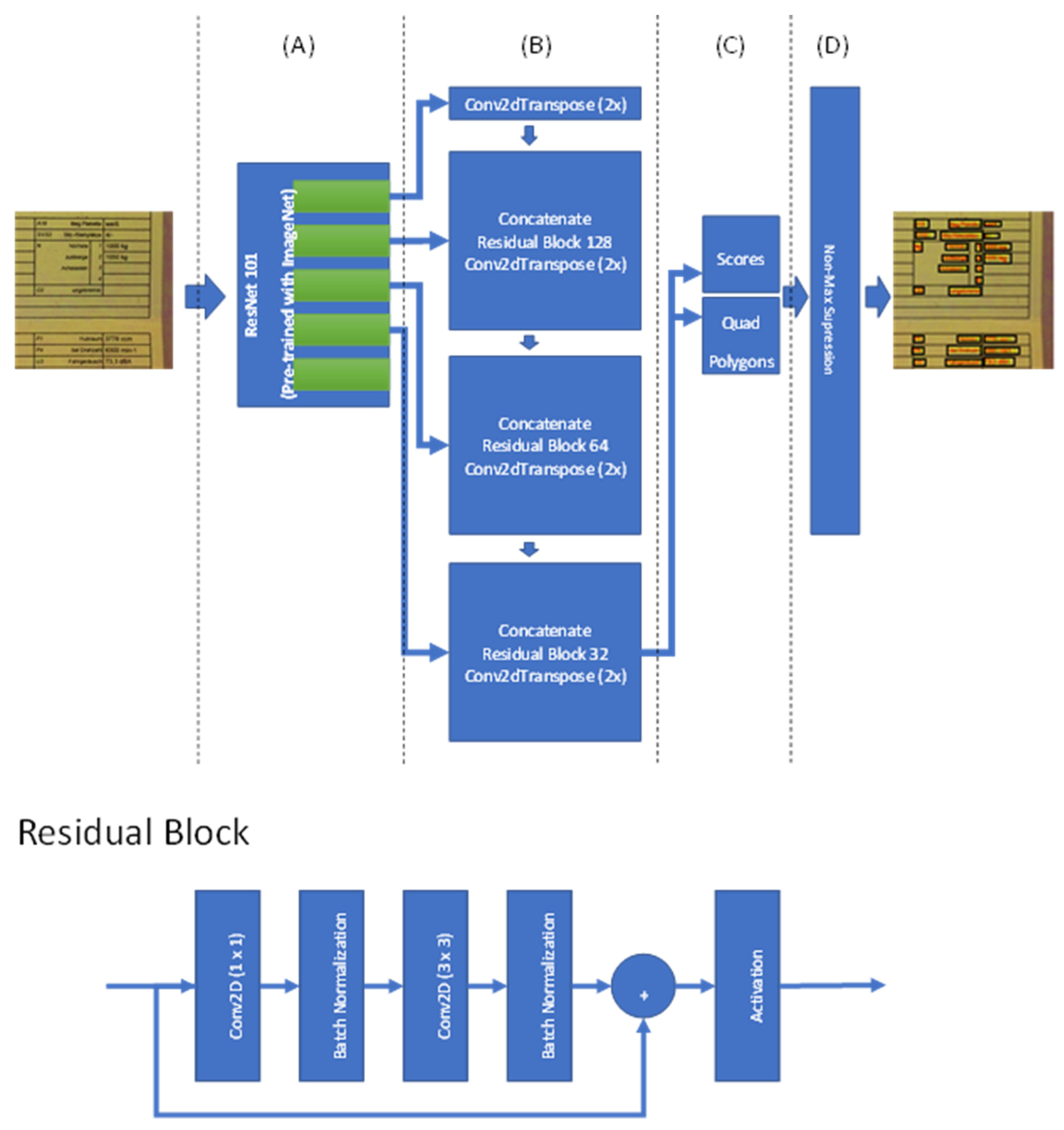
3.1. Text Detection
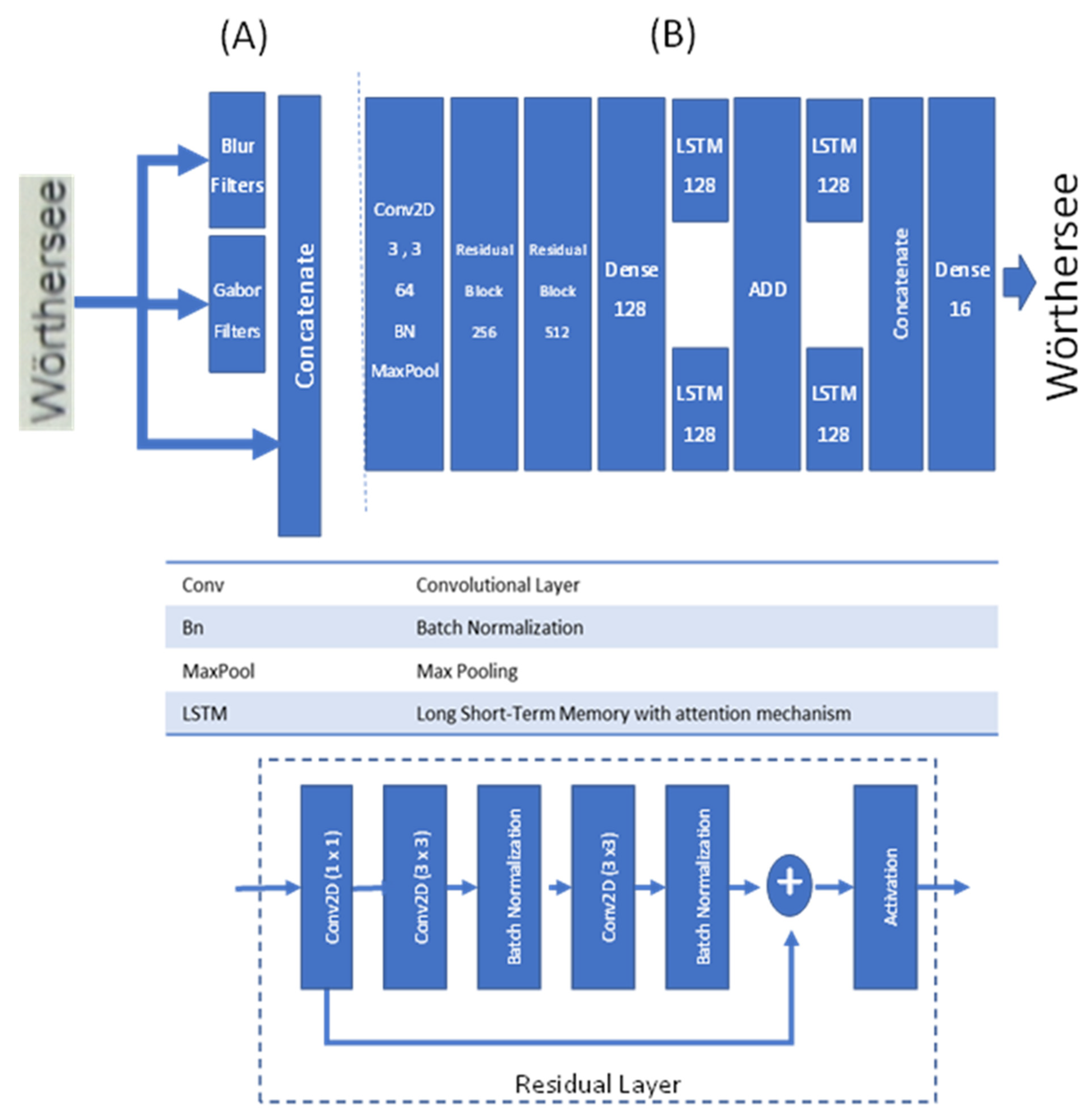
3.2. Text Recognition
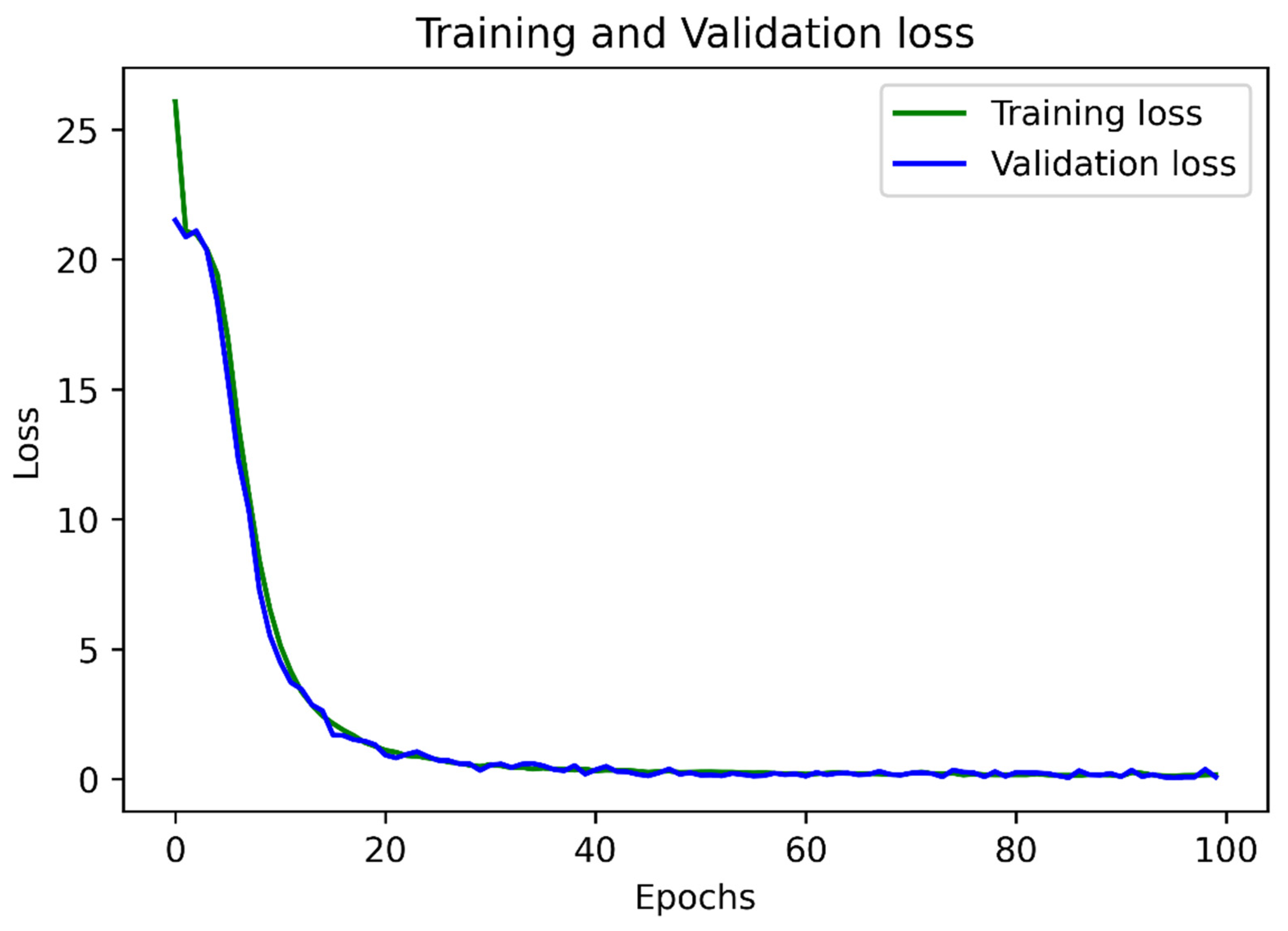
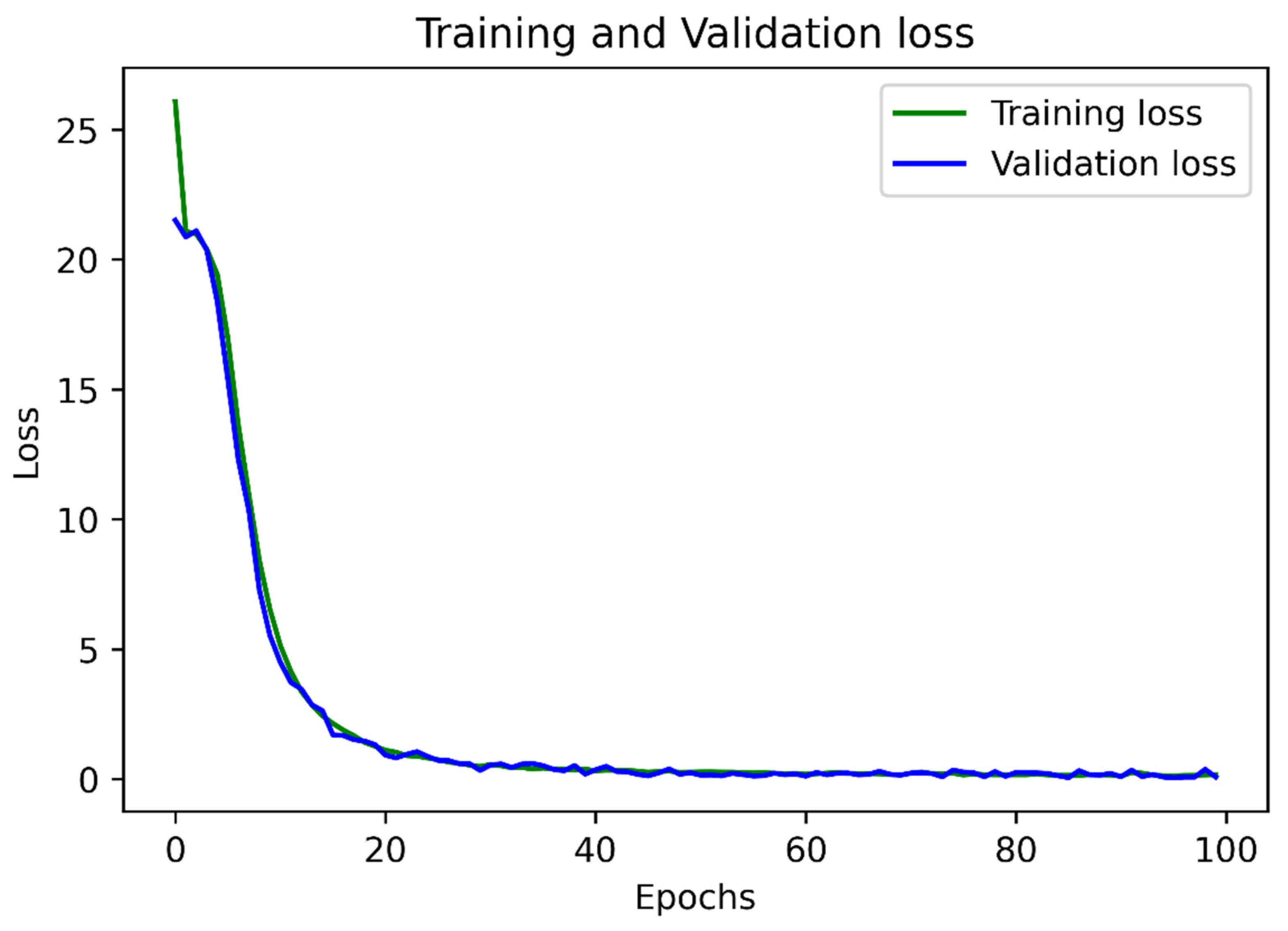
4. Models’ Training and Comprehensive Testing (for Both “Text Detection” and “Text Recognition”), Results Obtained, and Discussion of the Results Obtained
- (a)
- ICDAR 2013 dataset: This dataset contains 229 training images and 233 testing images with word-level annotation.
- (b)
- ICDAR 2015 dataset: This dataset contains 229 training images and 233 testing images with word-level annotation.
- (c)
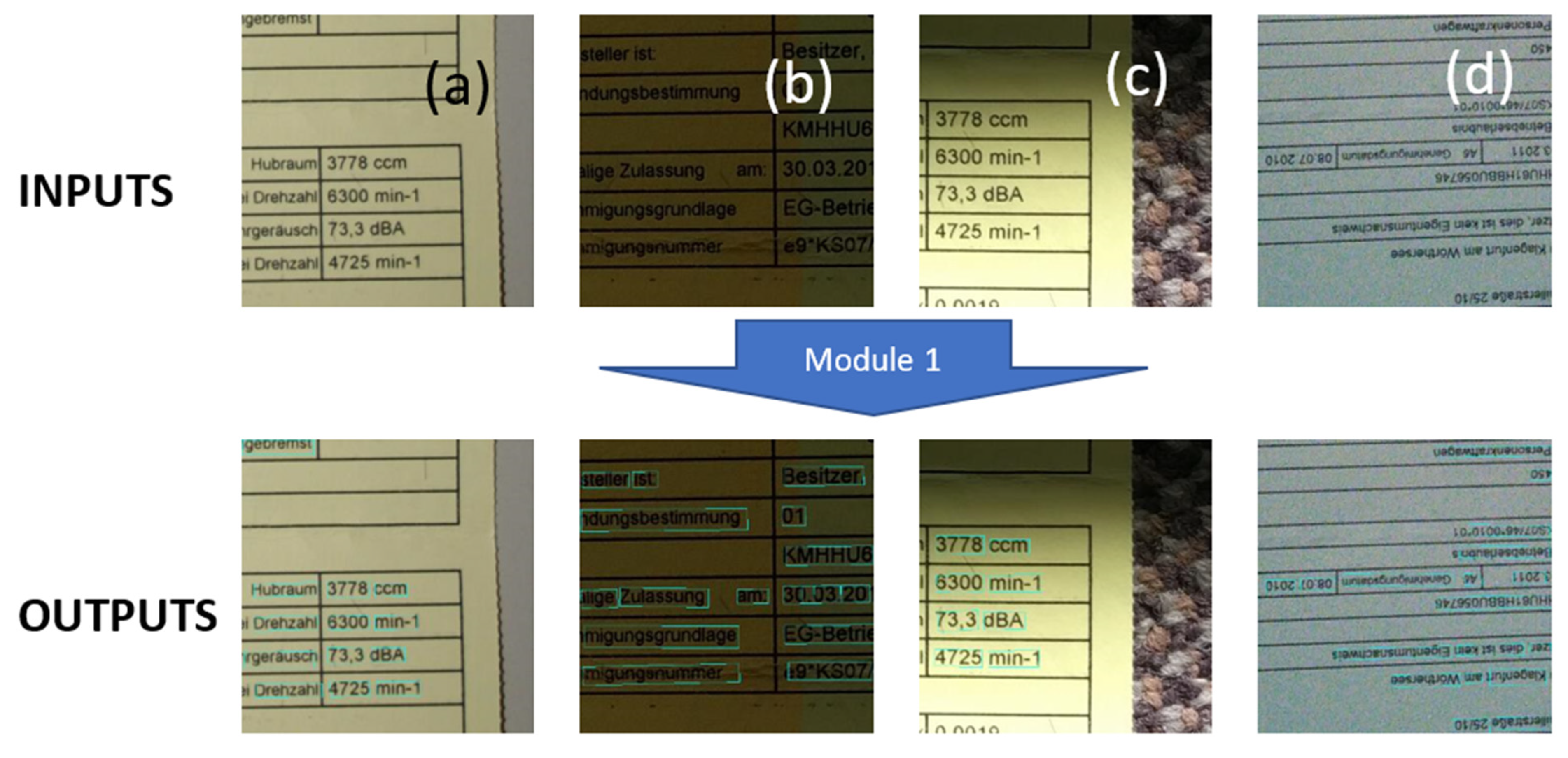
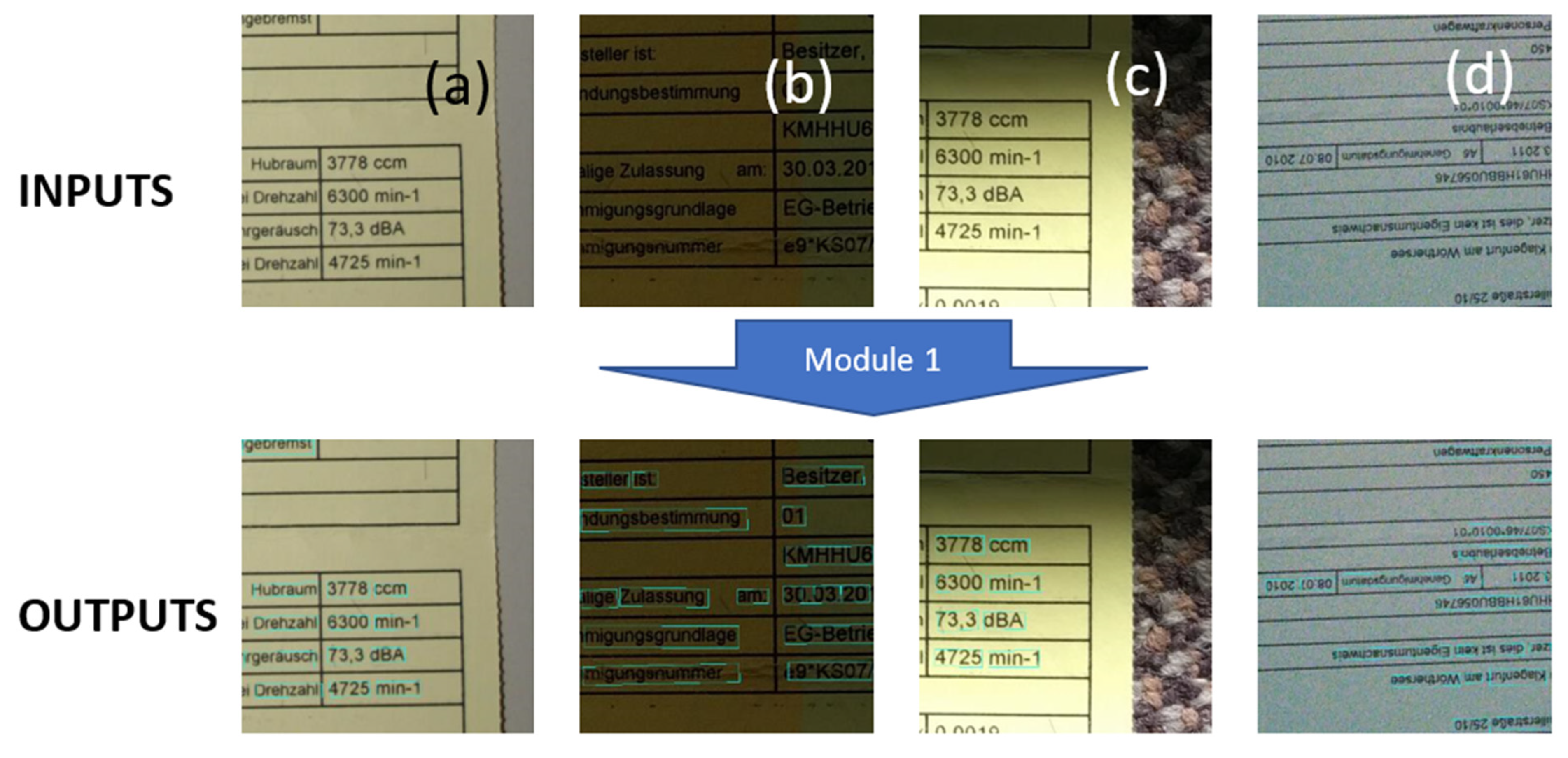
- Our own dataset: The samples in this dataset were gathered by our team. It has 456 images, 270 of which are used for training. These images are unique, as they capture and present different kinds of real-world distortions that can take place in document images taken using smartphone cameras. Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10 show illustrative parts of our own dataset.
- (a)
- MJSynth dataset: This dataset contains 9 million images covering 90,000 English words [50].
- (b)
- Generated German dataset: This dataset contains 20 million images covering 165,000 German words. The images were created using an author’s written module in Python and the dictionary used is taken from aspell.net, which contains many open-source dictionaries for spell checking. The generated data are synthetic, based on words from the dictionary and generated by our Python module (see Figure 13).
- (c)
- Our own dataset: The samples of this dataset were gathered by our team. It has 4560 word images. These images are unlike those of the other datasets, as they contain real-world distorted images, some of them strongly distorted; these are not synthetic data. Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10 show illustrative parts of our own dataset.
4.1. Performance Results of Module 1 for Text Detection
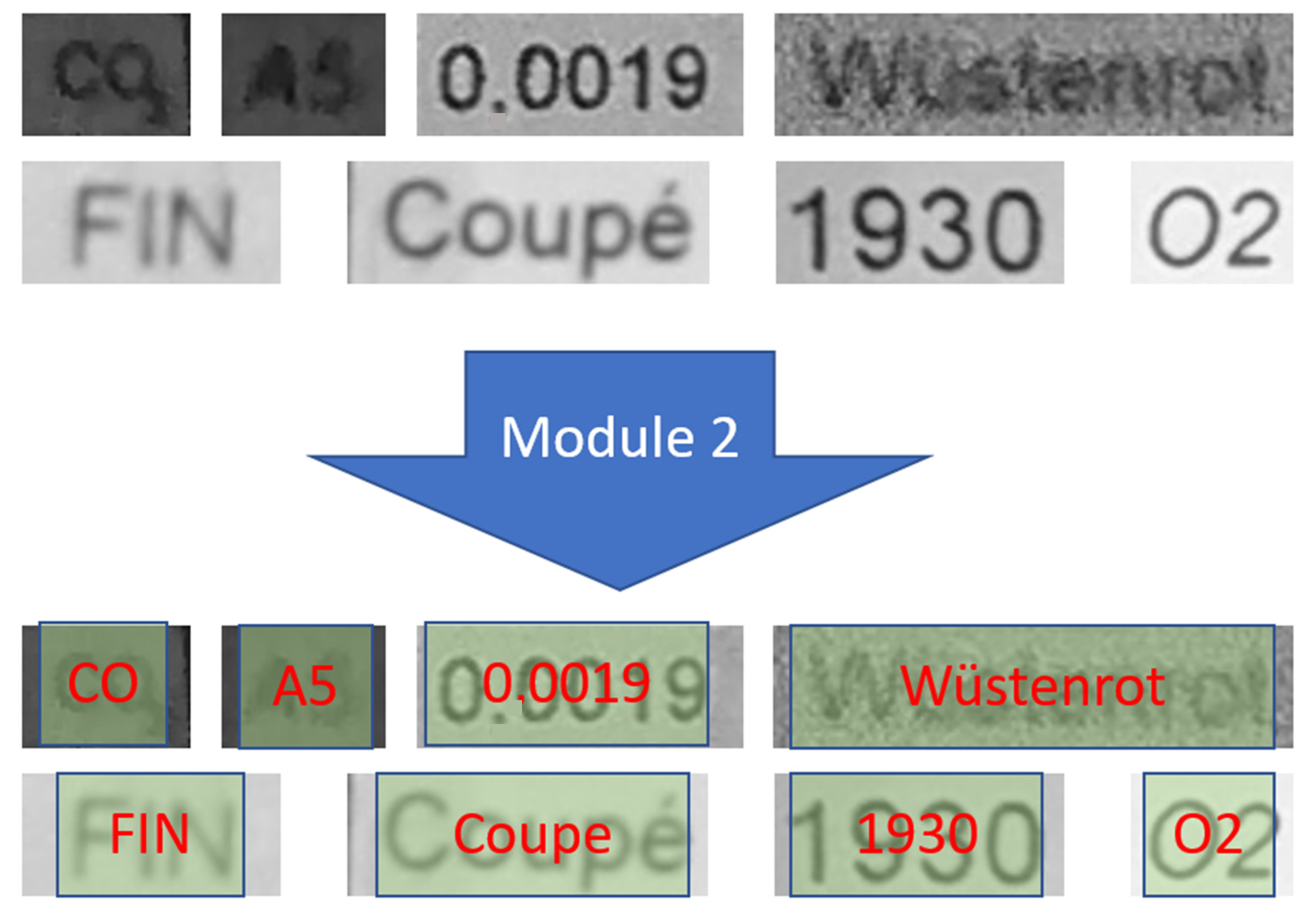
4.2. Performance Results of Module 2 for Text Recognition
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Joshi, G.D.; Garg, S.; Sivaswamy, J. A generalised framework for script identification. Int. J. Doc. Anal. Recognit. 2007, 10, 55–68. [Google Scholar] [CrossRef]
- Wang, X.; Ding, X.; Liu, H.; Liu, C. A new document authentication method by embedding deformation characters. Electron. Imaging 2006, 6067, 132–140. [Google Scholar]
- Berkner, K.; Likforman-Sulem, L. Special issue on document recognition and retrieval 2009. Int. J. Doc. Anal. Recognit. 2010, 13, 77–78. [Google Scholar] [CrossRef]
- Chung, Y.; Chi, S.; Bae, K.S.; Kim, K.; Jang, D.; Kim, K.; Choi, Y. Extraction of Character Areas from Digital Camera Based Color Document Images and OCR System. In Optical Information Systems III; SPIE Optics: San Diego, CA, USA, 2005; Volume 5908. [Google Scholar]
- Sharma, P.; Sharma, S. Image Processing Based Degraded Camera Captured Document Enhancement for Improved OCR Accuracy; IEEE: Noida, India, 2016. [Google Scholar]
- Visvanathan, A.; Chattopadhyay, T.; Bhattacharya, U. Enhancement of Camera Captured Text Images with Specular Reflection; IEEE: Jodhpur, India, 2013. [Google Scholar]
- Tian, D.; Hao, Y.; Ha, M.; Tian, X.; Ha, Y. Algorithm of Contrast Enhancement for Visual Document Images with Underexposure; SPIE: Beijing, China, 2007; Volume 6625. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Fan, M.; Huang, R.; Feng, W.; Sun, J. Image Blur Classification and Blur Usefulness Assessment; IEEE: Hong Kong, China, 2017. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on CVPR, Honolulu, HI, USA, 10 July 2017. [Google Scholar]
- Li, H.; Wang, W. Reinterpreting CTC training as iterative fitting. Pattern Recognit. 2020, 105, 107392. [Google Scholar] [CrossRef]
- Kuang, X.; Sui, X.; Liu, Y.; Chen, Q.; Gu, G. Single infrared image enhancement using a deep convolutional neural network. Neurocomputing 2019, 332, 119–128. [Google Scholar] [CrossRef]
- Lefkimmiatis, S. Non-local Color Image Denoising with Convolutional Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Bangalore, India, 8–10 December 2017; pp. 5882–5891. [Google Scholar]
- Cruz, C.; Foi, A.; Katkovnik, V.; Egiazarian, K. Nonlocality-Reinforced Convolutional Neural Networks for Image Denoising. IEEE Signal Process. Lett. 2018, 25, 1216–1220. [Google Scholar] [CrossRef]
- Sun, J.; Kim, S.W.; Lee, S.W.; Ko, S. A novel contrast enhancement forensics based on convolutional neural networks. Signal Process.-Image Commun. 2018, 63, 49–160. [Google Scholar] [CrossRef]
- Leal, H.K.; Yang, X. Removing the Blur in Images Using Deep Convolutional Neural Network; Young Scientist: Glendale, CA, USA, 2018; pp. 51–59. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. Arxiv Comput. Vis. Pattern Recognit. 2017, 257–265. [Google Scholar]
- Raisi, Z.; Naiel, M.; Fieguth, P.; Wardell, S.; Zelek, J. Text detection and recognition in the wild: A review. ACM Comput. Surv. 2020, 54, 1–35. [Google Scholar]
- Kim, K.I.; Jung, K.; Kim, J.H. Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1631–1639. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Hanif, S.M.; Prevost, L. Text Detection and Localization in Complex Scene Images Using Constrained Adaboost Algorithm. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Catalunya, Spain, 26–29 July 2009. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic Data for Text Localisation in Natural Images. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Oxford, UK, 22 April 2016; pp. 2315–2324. [Google Scholar]
- Jeon, M.; Jeong, Y. Compact and accurate scene text detector. Appl. Sci. 2020, 10, 2096. [Google Scholar] [CrossRef]
- Kobchaisawat, T.; Chalidabhongse, T.; Satoh, S. Scene text detection with polygon offsetting and border augmentation. Electronics 2020, 9, 117. [Google Scholar] [CrossRef]
- Liao, M.; Shi, B.; Bai, X. TextBoxes++: A Single-Shot Oriented Scene Text Detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Belongie, S. Word Spotting in the Wild. In Proceedings of the European Conference on Computer Vision, Berlin, Germany, 24 October 2010; pp. 591–604. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Risnumawan, A.; Shivakumara, P.; Chan, C.S.; Tan, C.L. A robust arbitrary text detection system for natural scene images. Expert Syst. Wit Appl. 2014, 41, 8027–8048. [Google Scholar]
- Iwamura, M.; Morimoto, N.; Tainaka, K.; Bazazian, D.; Gomez, L.; Karatzas, D. ICDAR2017 Robust Reading Challenge on Omnidirectional Video. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1448–1453. [Google Scholar]
- Liu, W.; Chen, C.; Wong, K.Y.K.; Su, Z.; Han, J. STAR-Net: A spatial attention residue network for scene text recognition. BMVC 2016, 2, 7. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comp. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor noparametric regression. Amer. Stat. 1992, 46, 175–185. [Google Scholar]
- Ye, Q.; Doermann, D. Text detection and recognition in imagery: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef]
- Neumann, L.; Matas, J. Real-Time Scene Text Localization and Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Almaz’an, J.; Gordo, A.; Forn’es, A.; Valveny, E. Word spotting and recognition with embedded attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2552–2566. [Google Scholar] [CrossRef]
- Simponyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, T.; Wu, D.; Coates, A.; Ng, A. End-to-End Text Recognition with Convolutional Neural Network. In Proceedings of the International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 3304–3308. [Google Scholar]
- Bissacco, A.; Cummins, M.; Netzer, Y.; Neven, H. PhotoOCR: Reading Text in Uncontrolled Conditions. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 785–792. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comp. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Borisyuk, F.; Albert, G.; Viswanath, S. Rosetta: Large Scale System for Text Detection and Recognition in Images. In Proceedings of the 4th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 19 July 2018. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef]
- Baek, J.; Kim, G.; Lee, J.; Park, S.; Han, D.; Yun, S.; Oh, S.J.; Lee, H. What is Wrong with Scene Text Recognition Model Comparisons? Dataset and Model Analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 3 April 2019. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-net and its variants for medical image segmentation: A review of theory and applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Maini, R.; Aggarwal, H. A Comprehensive Review of Image Enhancement Techniques. arXiv 2010, arXiv:1003.4053. [Google Scholar]
- Yang, C.; Hsieh, C. High Accuracy Text Detection Using ResNet as Feature Extractor. In Proceedings of the IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 3–6 October 2019. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Kingma, D.; Adam, J.B. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition. Int. J. Comput. Vis. 2014, 116, 1–20. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Belongie, S. Detecting Oriented Text in Natural Images by Linking Segments. In Proceedings of the IEEE Conference Computing Visual Pattern Recognition, Honolulu, HL, USA, 21–26 July 2017. [Google Scholar]
- Deng, D.; Liu, H.; Li, X.; Cai, D. Pixellink: Detecting Scene Text via Instance Segmentation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, Riverside, CA, USA, 27 April 2018. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Textsnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. In Proceedings of the European Conference Computer Vision, Munich, Germany, 9 October 2018. [Google Scholar]
- Tang, J.; Yang, Z.; Wang, Y.; Zheng, Q.; Xu, Y.; Bai, X. SegLink++: Detecting dense and arbitrary-shaped scene text by instance-aware component grouping. Pattern Recognit. 2019, 96, 106954. [Google Scholar] [CrossRef]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation. In Proceedings of the IEEE Conference Computer Vision Pattern Recognition, Salt Lake City, UT, USA, 25 February 2018. [Google Scholar]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. TextField: Learning a deep direction field for irregular scene text detection. IEEE Trans. Image Process. 2019, 28, 5566–5579. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection with Progressive Scale Expansion Network. In Proceedings of the IEEE Conference Computer Vision Pattern Recognition, Long Beach, CA, USA, 1 June 2019. [Google Scholar]
- Yang, P.; Yang, G.; Gong, X.; Wu, P.; Han, X.; Wu, J.; Chen, C. Instance Segmentation Network with Self-Distillation for Scene Text Detection. IEEE Access 2020, 8, 45825–45836. [Google Scholar] [CrossRef]
- Shi, B.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Robust Scene Text Recognition with Automatic Rectification. In Proceedings of the CVPR, Las Vegas, NV, USA, 19 April 2016. [Google Scholar]










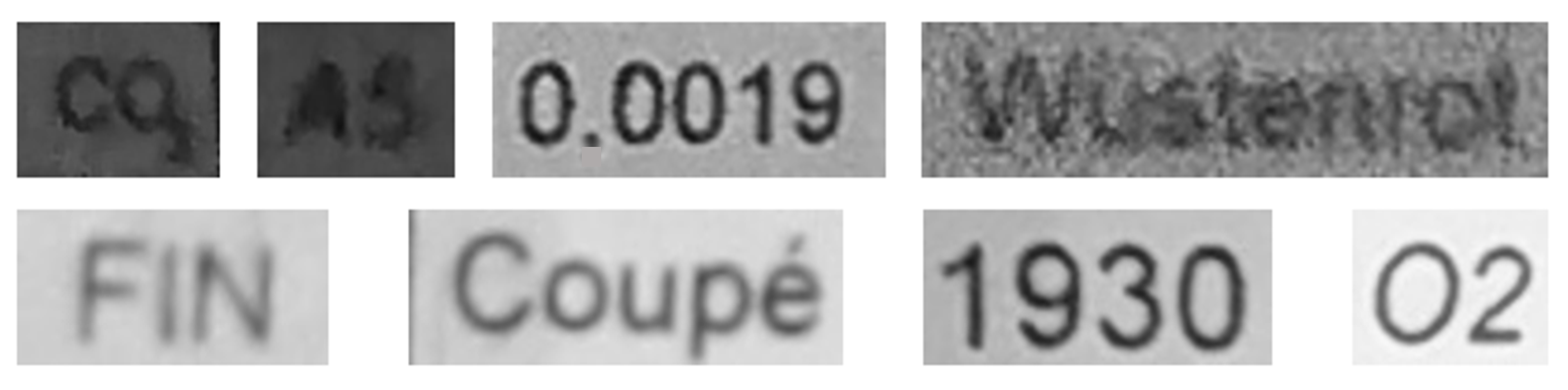


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Recall | Precision | FPS (Frames per Second) |
|---|---|---|---|
| SegLink [51] | 76.8 | 73.1 | - |
| EAST [10] | 70.8 | 79.2 | 13.2 |
| PixelLink [52] | 81.7 | 80.7 | 7.3 |
| TextSnake [53] | 85.3 | 81.5 | 1.1 |
| SegLink++ [54] | 80.4 | 82.5 | 7.1 |
| CLRS [55] | 70.7 | 90.1 | 1.1 |
| TextField [56] | 83.9 | 83.1 | 1.8 |
| PSENet [57] | 84.5 | 85.9 | 1.6 |
| DB-ResNet-50 [58] | 87.3 | 81.7 | 26 |
| Our model (First Module) | 96.8 | 95.4 | 4 |
| Image Quality vs. Precision and Recall | Very Good | Good | Middle | Bad | Very Bad |
|---|---|---|---|---|---|
| Precision | 100% | 100% | 98.9% | 98.3% | 90.1% |
| Recall | 100% | 100% | 99.1% | 98.3% | 89.8% |
| Method | WRA | CRA |
|---|---|---|
| CRNN [41] | 85.2 | 73.1 |
| RARE [59] | 84.81 | 79.2 |
| ROSETTA [40] | 86.1 | 80.7 |
| STAR-Net [58] | 86.6 | 81.5 |
| CLOVA [44] | 88.2 | 82.5 |
| ASTER [43] | 86.9 | 90.1 |
| Our model | 98.21 | 97.51 |
| Image Quality vs. WRA and WCA Performance | Very Good | Good | Middle | Bad | Very Bad |
|---|---|---|---|---|---|
| WRA | 98.32 | 98.29 | 91.81 | 92.43 | 81.53 |
| WCA | 99.51 | 98.69 | 95.06 | 92.13 | 84.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohsenzadegan, K.; Tavakkoli, V.; Kyamakya, K. A Smart Visual Sensing Concept Involving Deep Learning for a Robust Optical Character Recognition under Hard Real-World Conditions. Sensors 2022, 22, 6025. https://doi.org/10.3390/s22166025
Mohsenzadegan K, Tavakkoli V, Kyamakya K. A Smart Visual Sensing Concept Involving Deep Learning for a Robust Optical Character Recognition under Hard Real-World Conditions. Sensors. 2022; 22(16):6025. https://doi.org/10.3390/s22166025
Chicago/Turabian StyleMohsenzadegan, Kabeh, Vahid Tavakkoli, and Kyandoghere Kyamakya. 2022. "A Smart Visual Sensing Concept Involving Deep Learning for a Robust Optical Character Recognition under Hard Real-World Conditions" Sensors 22, no. 16: 6025. https://doi.org/10.3390/s22166025
APA StyleMohsenzadegan, K., Tavakkoli, V., & Kyamakya, K. (2022). A Smart Visual Sensing Concept Involving Deep Learning for a Robust Optical Character Recognition under Hard Real-World Conditions. Sensors, 22(16), 6025. https://doi.org/10.3390/s22166025