
HHI-AttentionNet: An Enhanced Human-Human Interaction Recognition Method Based on a Lightweight Deep Learning Model with Attention Network from CSI

Abstract
:1. Introduction
- A lightweight DL model (HHI-AttentionNet) has been proposed to improve the recognition accuracy of HHIs;
- An AFSAM that combines the antenna attention module (AAM) and frame-subcarrier attention module (FSAM) is designed in the HHI-AttentionNet model to improve the representative capability of the proposed model for recognizing HHIs correctly;
- A comparative study of different methods for HHI recognition and comparison of their performance;
- The proposed method could be the best-suited sophisticated method for recognizing both HHIs and single human activity because of its high-level activity recognition ability with a limited number of parameters.
2. Related Work
2.1. RSSI-Based Methods
2.2. CSI-Based Methods
3. Dataset
4. Background of CSI
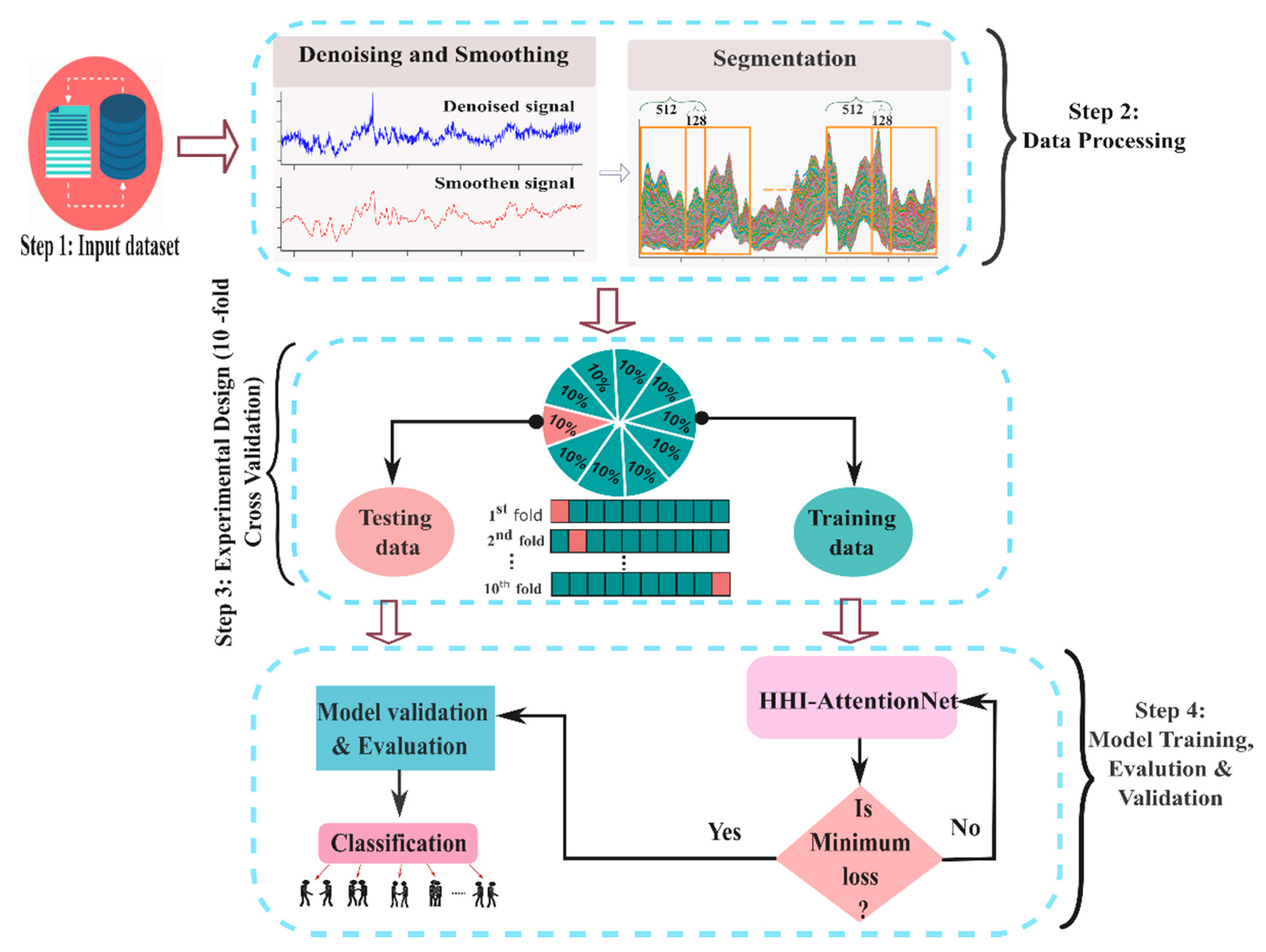
5. Proposed Methodology
5.1. Data Preprocessing
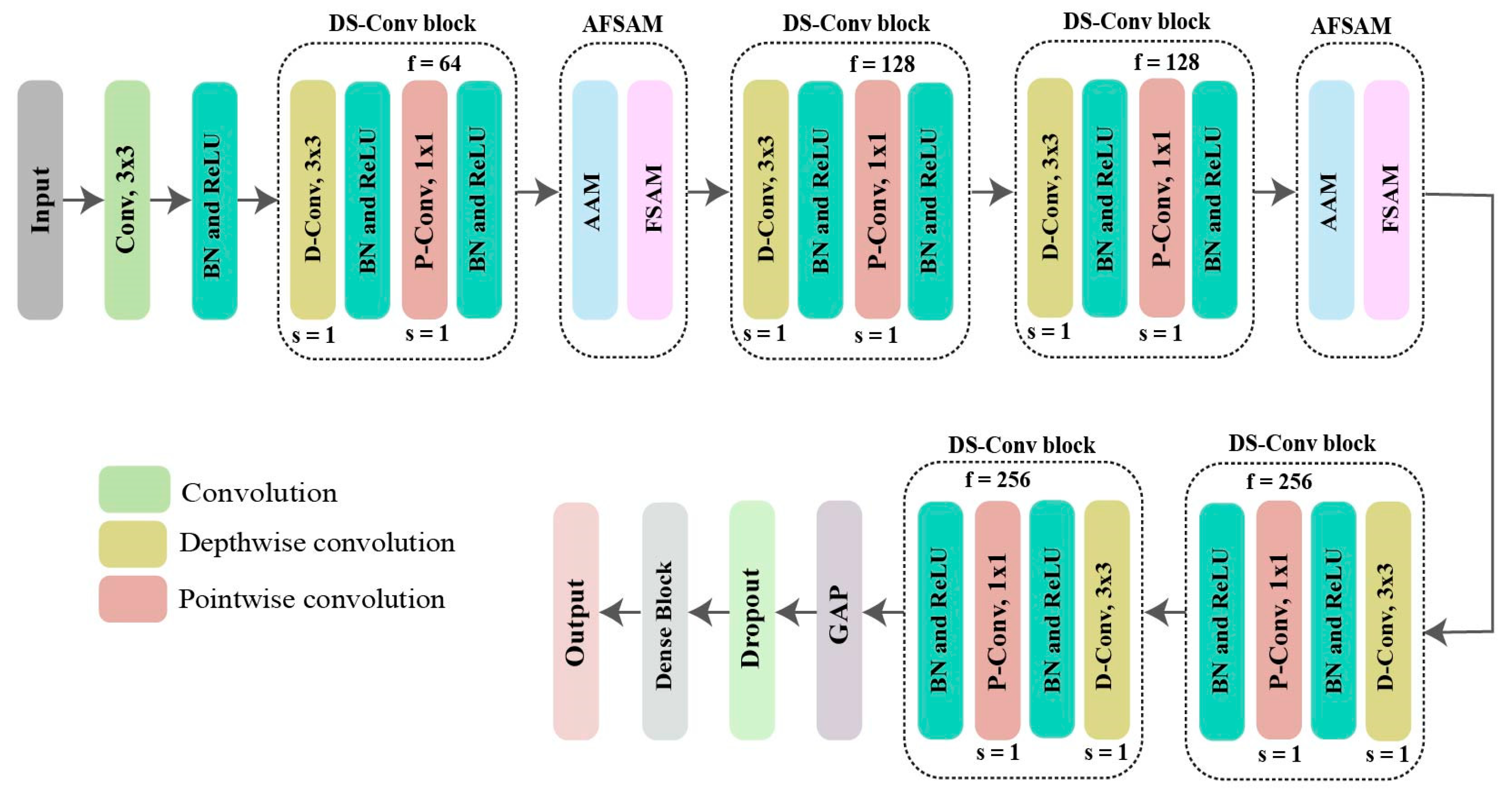
5.2. HHI-AttentionNet
5.2.1. Depthwise Separable Convolutional Block and Dense Block
5.2.2. Antenna-Frame-Subcarrier Attention Mechanism (AFSAM)
Antenna Attention Module (AAM)
| Algorithm 1: The Pseudocode for the Antenna Attention Module (AAM) |
| Input: The input feature map, F ϵ ℝ F × S × A |
| 1: Begin |
| 2: Fgap ← ∅ |
| 3: Fgap ←Globalaveragepooling (F) |
| 4: Fr←reshape(Fgap) //After reshape operation, the input feature map, Fr ϵ ℝ 1 × 1 × A |
| 5: Initialize the filter: filter1, filrer2,…, filtern |
| 6: antenna_feature ← ∅ |
| 7: for f FilterSize do |
| 8: i ← 0 |
| 9: temp ←∅ |
| 10: while i ≠ filtern |
| 11: convi ←Convolute(Fr, FilterSize, padding = ‘same’) |
| 12: append(temp, convi) |
| 13: i←i + 1 |
| 14: end while |
| 15: append (antenna_feature,temp) |
| 16: end for |
| 17: AAM ← Apply (antenna_feature, sigmoid) |
| 18: return (F⊗ AAM) |
| 19: end |
Frame-Subcarrier Attention Module
| Algorithm 2: The Pseudocode Frame-Subcarrier Attention Module (FSAM). |
| Input: The input feature map, F ϵ ℝ FAAM × SAAM × AAAM |
| Output: The frame-subcarrier attention features map |
| 1: Begin |
| 2: Favg ←AveragePooling (F) |
| 3: frame_sub_feature ← ∅ |
| 4: for f FilterSize do |
| 5: i ← 0 |
| 6: temp←∅ |
| 7: while i≠ filter |
| 8: convi ←Convolute(Favg, FilterSize, padding = ‘same’) |
| 9: append(temp, convi) |
| 10: i←i + 1 |
| 11: end while |
| 12: append (frame_sub_feature, temp) |
| 13: end for |
| 14: FSAM ←apply(frame_sub_feature, sigmoid) |
| 15: return (F⊗ FSAM) |
| 16: end |
5.3. Hyper-Parameters and Training
| Algorithm 3: Pseudocode of class Prediction and Training Loss Computation |
| Input: Number of activity classes L, Dataset {(x1, y1), (x2, y2), …, (xn, yn)}, feature extractor, |
| Output: Predicted class label , model loss J |
| 1: Randomly divide dataset into K disjoint equal-sized fold |
| 2: For m in 1: K do |
| loss, J = 0//Initialize loss |
| 3: For batch_size in training set do |
| 4: For class in classes {1… L} do |
| 5: (batch_size; model parameter) ϵ ℝ D (D is the dimension) |
| 6: αij = Softmax (eij) = |
| 7: . αij//Predicated label |
| 8: end for |
| 9: calculate cross-entropy, J (xi, yi) = |
| 10: loss = reduce_mean (J (xi, yi)) |
| 11: J = J //loss update |
| 12: end for |
| 13: end for |
5.4. Evaluation Metrics
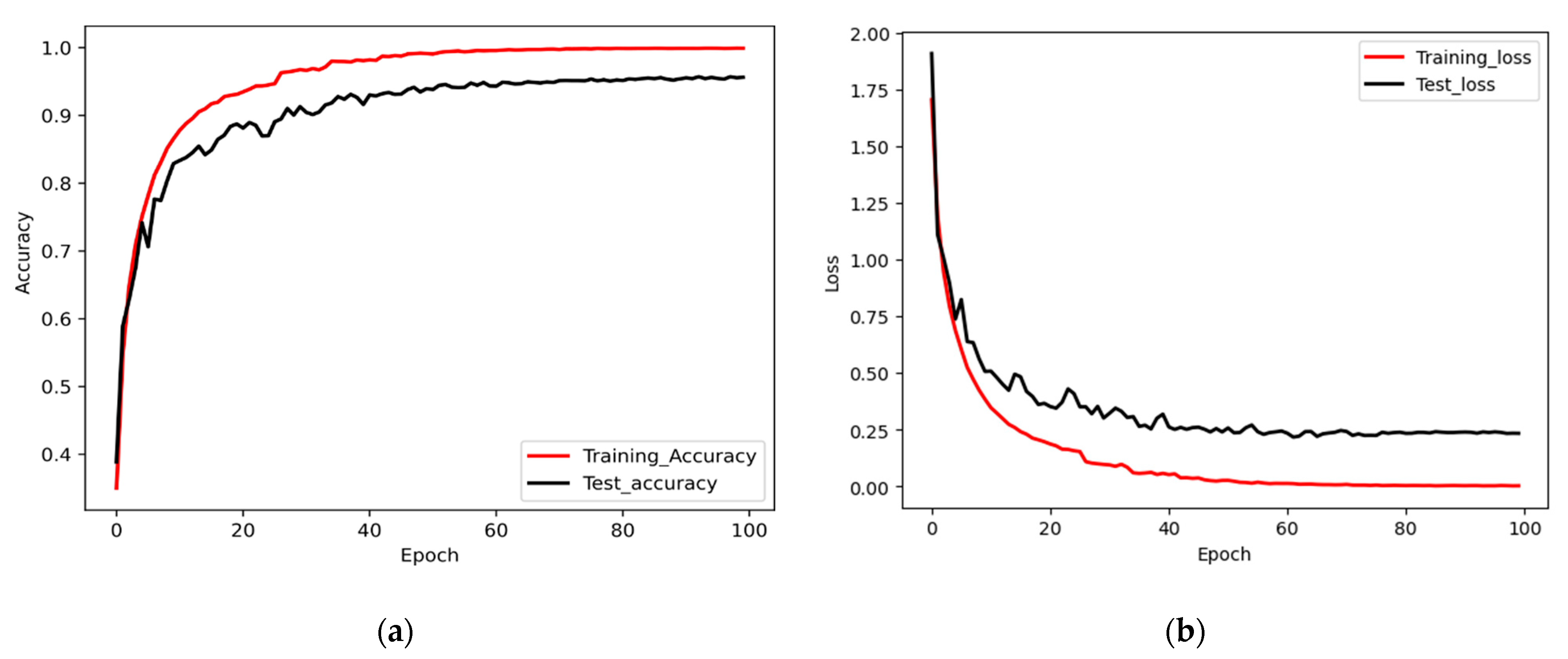
6. Result and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hsu, Y.L.; Yang, S.C.; Chang, H.C.; Lai, H.C. Human daily and sport activity recognition using a wearable inertial sensor network. IEEE Access 2018, 6, 31715–31728. [Google Scholar] [CrossRef]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2. [Google Scholar]
- Ahad, M.A.R. Activity recognition for health-care and related works. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018. [Google Scholar]
- Uddin, M.H.; Ara, J.M.K.; Rahman, M.H.; Yang, S.H. A Study of Real-Time Physical Activity Recognition from Motion Sensors via Smartphone Using Deep Neural Network. In Proceedings of the 2021 5th International Conference on Electrical Information and Communication Technology (EICT), Khulan, Bangladesh, 17–19 December 2021. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Münzner, S.; Schmidt, P.; Reiss, A.; Hanselmann, M.; Stiefelhagen, R.; Dürichen, R. CNN-based sensor fusion techniques for multimodal human activity recognition. In Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, Hawaii, 11–15 September 2017. [Google Scholar]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl.-Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Ma, Y.; Gang, Z.; Shuangquan, W. WiFi sensing with channel state information: A survey. ACM Comput. Surv. 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Youssef, M.; Mah, M.; Agrawala, A. Challenges: Device-free passive localization for wireless environments. In Proceedings of the 13th Annual ACM international Conference on Mobile Computing and Networking, New Orleans, LA, USA, 25–29 October 2007; pp. 222–229. [Google Scholar]
- Wilson, J.; Neal, P. See-through walls: Motion tracking using variance-based radio tomography networks. IEEE Trans. Mob. Comput. 2010, 10, 612–621. [Google Scholar] [CrossRef]
- Wilson, J.; Neal, P. Radio tomographic imaging with wireless networks. IEEE Trans. Mob. Comput. 2010, 9, 621–632. [Google Scholar] [CrossRef]
- Li, H.; He, X.; Chen, X.; Fang, Y.; Fang, Q. Wi-Motion: A robust human activity recognition using WiFi signals. IEEE Access 2019, 7, 153287–153299. [Google Scholar] [CrossRef]
- Yadav, S.K.; Sai, S.; Gundewar, A.; Rathore, H.; Tiwari, K.; Pandey, H.M.; Mathur, M. CSITime: Privacy-preserving human activity recognition using WiFi channel state information. Neural Netw. 2022, 146, 11–21. [Google Scholar] [CrossRef]
- Wang, G.; Zou, Y.; Zhou, Z.; Wu, K.; Ni, L.M. We Can Hear You with Wi-Fi! IEEE Trans. Mob. Comput. 2016, 15, 2907–2920. [Google Scholar] [CrossRef]
- Hao, Z.; Duan, Y.; Dang, X.; Liu, Y.; Zhang, D. Wi-SL: Contactless Fine-Grained Gesture Recognition Uses Channel State Information. Sensors 2020, 20, 4025. [Google Scholar] [CrossRef]
- Wang, F.; Feng, J.; Zhao, Y.; Zhang, X.; Zhang, S.; Han, J. Joint Activity Recognition and Indoor Localization with WiFi Fingerprints. IEEE Access 2019, 7, 80058–80068. [Google Scholar] [CrossRef]
- Duan, S.; Tianqing, Y.; Jie, H. WiDriver: Driver activity recognition system based on WiFi CSI. Int. J. Wireless Inf. Netw. 2018, 25, 146–156. [Google Scholar] [CrossRef]
- Guo, Z.; Xiao, F.; Sheng, B.; Fei, H.; Yu, S. WiReader: Adaptive Air Handwriting Recognition Based on Commercial WiFi Signal. IEEE Internet Things J. 2020, 7, 10483–10494. [Google Scholar] [CrossRef]
- Wang, F.; Panev, S.; Dai, Z.; Han, J.; Huang, D. Can WiFi estimate person pose? arXiv 2019, arXiv:1904.00277. [Google Scholar]
- Wang, Y.; Kaishun, W.; Lionel, M.N. Wifall: Device-free fall detection by wireless networks. IEEE Trans. Mob. Comput. 2016, 16, 581–594. [Google Scholar] [CrossRef]
- Thapa, K.; Md, Z.; Sung-Hyun, Y. Adapted Long Short-Term Memory (LSTM) for concurrent Human Activity Recognition. Comput. Mater. 2021, 69, 1653–1670. [Google Scholar] [CrossRef]
- Kim, S.C.; Tae, G.K.; Sung, H.K. Human activity recognition and prediction based on Wi-Fi channel state information and machine learning. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019. [Google Scholar]
- Alsaify, B.A.; Almazari, M.M.; Alazrai, R.; Alouneh, S.; Daoud, M.I. A CSI-Based Multi-Environment Human Activity Recognition Framework. Appl. Sci. 2022, 12, 930. [Google Scholar] [CrossRef]
- Sung-Hyun, Y.; Thapa, K.; Kabir, M.H.; Hee-Chan, L. Log-Viterbi algorithm applied on second-order hidden Markov model for human activity recognition. Int. J. Distrib. Sens. Netw. 2018, 14, 1550147718772541. [Google Scholar] [CrossRef]
- Kabir, M.H.; Hoque, M.R.; Thapa, K.; Yang, S.H. Two-layer hidden Markov model for human activity recognition in home environments. Int. J. Distrib. Sens. Netw. 2016, 12, 4560365. [Google Scholar] [CrossRef]
- Feng, C.; Arshad, S.; Zhou, S.; Cao, D.; Liu, Y. Wi-multi: A three-phase system for multiple human activity recognition with commercial wifi devices. IEEE Internet Things J. 2019, 6, 7293–7304. [Google Scholar] [CrossRef]
- Gu, T.; Wang, L.; Chen, H.; Tao, X.; Lu, J. Recognizing multiuser activities using wireless body sensor networks. IEEE Trans. Mob. Comput. 2011, 10, 1618–1631. [Google Scholar] [CrossRef]
- Alazrai, R.; Yaser, M.; George, C.S.L. Anatomical-plane-based representation for human-human interactions analysis. Pattern Recognit. 2015, 48, 2346–2363. [Google Scholar] [CrossRef]
- Hsieh, C.F.; Chen, Y.C.; Hsieh, C.Y.; Ku, M.L. Device-free indoor human activity recognition using Wi-Fi RSSI: Machine learning approaches. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taoyuan, Taiwan, 28–30 September 2020. [Google Scholar]
- Sigg, S.; Blanke, U.; Troster, G. The telepathic phone: Frictionless activity recognition from WiFi-RSSI. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 148–155. [Google Scholar]
- Chen, J.; Huang, X.; Jiang, H.; Miao, X. Low-cost and device-free human activity recognition based on hierarchical learning model. Sensors 2021, 21, 2359. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, X.; Gao, Q.; Ma, X.; Feng, X.; Wang, H. Device-free simultaneous wireless localization and activity recognition with wavelet feature. IEEE Trans. Veh. Technol. 2016, 66, 1659–1669. [Google Scholar] [CrossRef]
- Huang, H.; Lin, S. WiDet: Wi-Fi based device-free passive person detection with deep convolutional neural networks. Comput. Commun. 2020, 150, 357–366. [Google Scholar] [CrossRef]
- Gu, Y.; Ren, F.; Li, J. Paws: Passive human activity recognition based on wifi ambient signals. IEEE Internet Things J. 2015, 3, 796–805. [Google Scholar] [CrossRef]
- Yang, J. A framework for human activity recognition based on WiFi CSI signal enhancement. Int. J. Antennas Propag. 2021, 2021, 6654752. [Google Scholar] [CrossRef]
- Damodaran, N.; Schäfer, J. Device free human activity recognition using WiFi channel state information. In Proceedings of the 2019 IEEE Smart World, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Leicester, UK, 19–23 August 2019; pp. 1069–1074. [Google Scholar]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using WiFi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Device-Free Human Activity Recognition Using Commercial WiFi Devices. IEEE J. Sel. Areas Commun. 2017, 35, 1118–1131. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, Y.; Wang, Y.; Xu, K. WiAct: A passive WiFi-based human activity recognition system. IEEE Sens. J. 2019, 20, 296–305. [Google Scholar] [CrossRef]
- Muaaz, M.; Chelli, A.; Pätzold, M. Wi-Fi-based human activity recognition using convolutional neural network. In Innovative and Intelligent Technology-Based Services for Smart Environments–Smart Sensing and Artificial Intelligence; CRC Press: Boca Raton, FL, USA, 2021; pp. 61–67. [Google Scholar]
- Alazrai, R.; Hababeh, M.; Baha’A, A.; Ali, M.Z.; Daoud, M.I. An end-to-end deep learning framework for recognizing human-to-human interactions using Wi-Fi signals. IEEE Access 2020, 8, 197695–197710. [Google Scholar] [CrossRef]
- Kabir, M.H.; Rahman, M.H.; Shin, W. CSI-IANet: An Inception Attention Network for Human-Human Interaction Recognition Based on CSI Signal. IEEE Access 2021, 9, 166624–166638. [Google Scholar] [CrossRef]
- Alazrai, R.; Awad, A.; Baha’A, A.; Hababeh, M.; Daoud, M.I. A dataset for Wi-Fi-based human-to-human interaction recognition. Data Brief 2020, 31, 105668. [Google Scholar] [CrossRef] [PubMed]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool release: Gathering 802.11 n traces with channel state information. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B 1974, 36, 111–133. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Janocha, K.; Wojciech, M.C. On loss functions for deep neural networks in classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Islam, M.; Shafiqul, K.T.; Sung-Hyun, Y. Epileptic-Net: An Improved Epileptic Seizure Detection System Using Dense Convolutional Block with Attention Network from EEG. Sensors 2022, 22, 728. [Google Scholar] [CrossRef]
- Alazrai, R.; Awad, A.; Alsaify, B.A.; Daoud, M.I. A wi-fi-based approach for recognizing human-human interactions. In Proceedings of the 2021 12th International Conference on Information and Communication Systems (ICICS), Valencia, Spain, 24–26 May 2021. [Google Scholar]
- Yao, L.; Nie, F.; Sheng, Q.Z.; Gu, T.; Li, X.; Wang, S. Learning from less for better: Semi-supervised activity recognition via shared structure discovery. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interaction | Label | No. of Samples | Interaction | Label | No. of Samples |
|---|---|---|---|---|---|
| Approaching | I1 | 3359 | Pointing with the left hand | I8 | 4067 |
| Departing | I2 | 3115 | Pointing with the right hand | I9 | 4081 |
| Handshaking | I3 | 3606 | Punching with the left hand | I10 | 2497 |
| High five | I4 | 3643 | Punching with the right hand | I11 | 2500 |
| Hugging | I5 | 2480 | Pushing | I12 | 3610 |
| Kicking with the left leg | I6 | 2471 | Steady state | I13 | 22,792 |
| Kicking with the right leg | I7 | 2489 |
| Section | Layer Type | Output Shape | Parameters |
|---|---|---|---|
| Conv 2D | 256 × 15 × 32 | 1760 | |
| BN and ReLU | 256 × 15 × 32 | 128 | |
| DS-Conv block | 128 × 8 × 64 | 2816 | |
| AFSAM | 128 × 8 × 64 | 4145 | |
| DS-Conv block | 64 × 4 × 128 | 9728 | |
| DS-Conv block | 32 × 2 × 128 | 18,816 | |
| AFSAM | 32 × 2 × 128 | 16,433 | |
| DS-Conv block | 16 × 1 × 256 | 35,840 | |
| DS-Conv block | 8 × 1 × 256 | 70,400 | |
| Recognition | GAP | 1 × 256 | 0 |
| Dropout (0.20) | 1 × 256 | 0 | |
| Dense | 1 × 64 | 16,448 | |
| Softmax | 1 × 13 | 845 |
| Number of Class | Metrics (%) | Fold | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | |||
| 12 | Accuracy | 94.60 | 94.74 | 95.00 | 94.85 | 94.44 | 94.60 | 94.56 | 94.26 | 94.23 | 95.04 | 94.55 ± 0.25 |
| F1 Score | 94.56 | 94.70 | 94.95 | 94.75 | 94.42 | 94.56 | 94.52 | 94.15 | 94.20 | 94.81 | 94.50 ± 0.24 | |
| k-score | 0.945 | 0.947 | 0.948 | 0.946 | 0.944 | 0.945 | 0.945 | 0.941 | 0.942 | 0.948 | 0.945 ± 0.22 | |
| MCC | 0.944 | 0.946 | 0.948 | 0.945 | 0.943 | 0.944 | 0.954 | 0.941 | 0.941 | 0.947 | 0.945 ± 0.38 | |
| 13 | Accuracy | 95.44 | 95.58 | 95.23 | 95.51 | 95.23 | 95.77 | 95.53 | 95.67 | 95.18 | 95.60 | 95.47 ± 0.19 |
| F1 Score | 95.41 | 95.56 | 95.21 | 95.49 | 95.22 | 95.74 | 95.51 | 95.66 | 95.16 | 95.55 | 95.45 ± 0.19 | |
| k-score | 0.950 | 0.951 | 0.948 | 0.951 | 0.947 | 0.954 | 0.951 | 0.953 | 0.947 | 0.953 | 0.951 ± 0.20 | |
| MCC | 0.950 | 0.951 | 0.948 | 0.951 | 0.948 | 0.953 | 0.951 | 0.952 | 0.946 | 0.952 | 0.950 ± 0.20 | |
| Model | No. of Class | No. of Parameter | Time (s) | |||
|---|---|---|---|---|---|---|
| Trainable | Non-Trainable | Total | Training | Recognition | ||
| HHI-AttentionNet | 12 | 173,406 | 2944 | 176,350 | 1615 ± 1.9 | 0.000198 ± 0.000012 |
| 13 | 173,551 | 2944 | 176,495 | 3000 ± 1.4 | 0.000200 ± 0.000014 | |
| Study | Methodology and Year | Metrics (%) | Trainable Parameters | Recognition Time(s) | |||
|---|---|---|---|---|---|---|---|
| Accuracy | F1-Score | k-Score | MCC | ||||
| Alazrai et al. [50] | SVM (2021) | 69.79 | - | - | - | - | - |
| Alazrai et al. [41] | E2EDLF (2020) | 86.30 | 86.00 | 85.00 | - | 935,053 | 0.00022 ± 0.000018 |
| Kabir et al. [42] | CSI-IANet (2021) | 91.30 | 91.27 | 89.42 | - | 546,321 | 0.00036 ± 0.000025 |
| Proposed | HHI-AttentionNet | 95.47 | 95.45 | 95.05 | 95.06 | 176,495 | 0.000200 ± 0.000014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shafiqul, I.M.; Jannat, M.K.A.; Kim, J.-W.; Lee, S.-W.; Yang, S.-H. HHI-AttentionNet: An Enhanced Human-Human Interaction Recognition Method Based on a Lightweight Deep Learning Model with Attention Network from CSI. Sensors 2022, 22, 6018. https://doi.org/10.3390/s22166018
Shafiqul IM, Jannat MKA, Kim J-W, Lee S-W, Yang S-H. HHI-AttentionNet: An Enhanced Human-Human Interaction Recognition Method Based on a Lightweight Deep Learning Model with Attention Network from CSI. Sensors. 2022; 22(16):6018. https://doi.org/10.3390/s22166018
Chicago/Turabian StyleShafiqul, Islam Md, Mir Kanon Ara Jannat, Jin-Woo Kim, Soo-Wook Lee, and Sung-Hyun Yang. 2022. "HHI-AttentionNet: An Enhanced Human-Human Interaction Recognition Method Based on a Lightweight Deep Learning Model with Attention Network from CSI" Sensors 22, no. 16: 6018. https://doi.org/10.3390/s22166018
APA StyleShafiqul, I. M., Jannat, M. K. A., Kim, J.-W., Lee, S.-W., & Yang, S.-H. (2022). HHI-AttentionNet: An Enhanced Human-Human Interaction Recognition Method Based on a Lightweight Deep Learning Model with Attention Network from CSI. Sensors, 22(16), 6018. https://doi.org/10.3390/s22166018