
Selecting the Most Important Features for Predicting Mild Cognitive Impairment from Thai Verbal Fluency Assessments

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
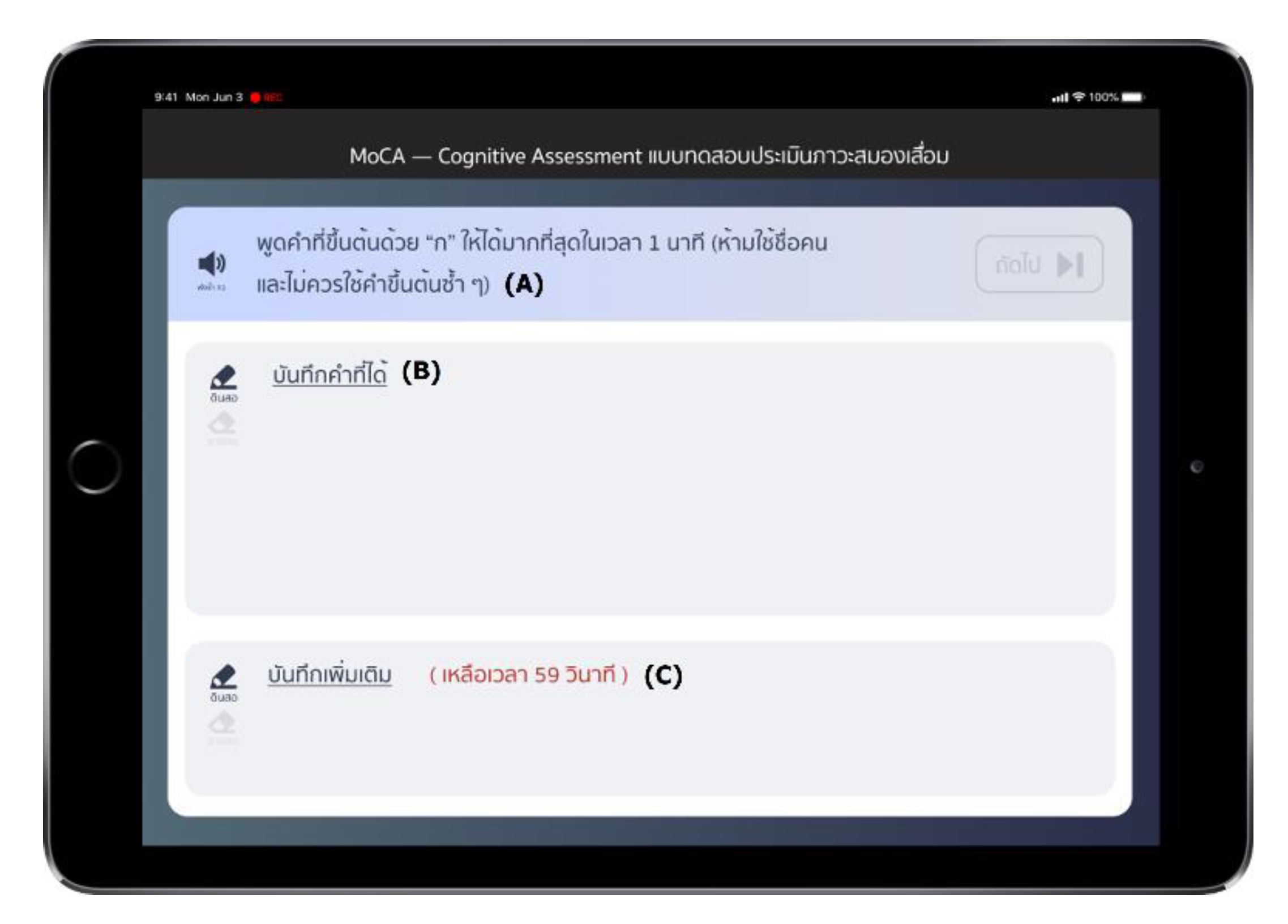
3.1. Data Collection
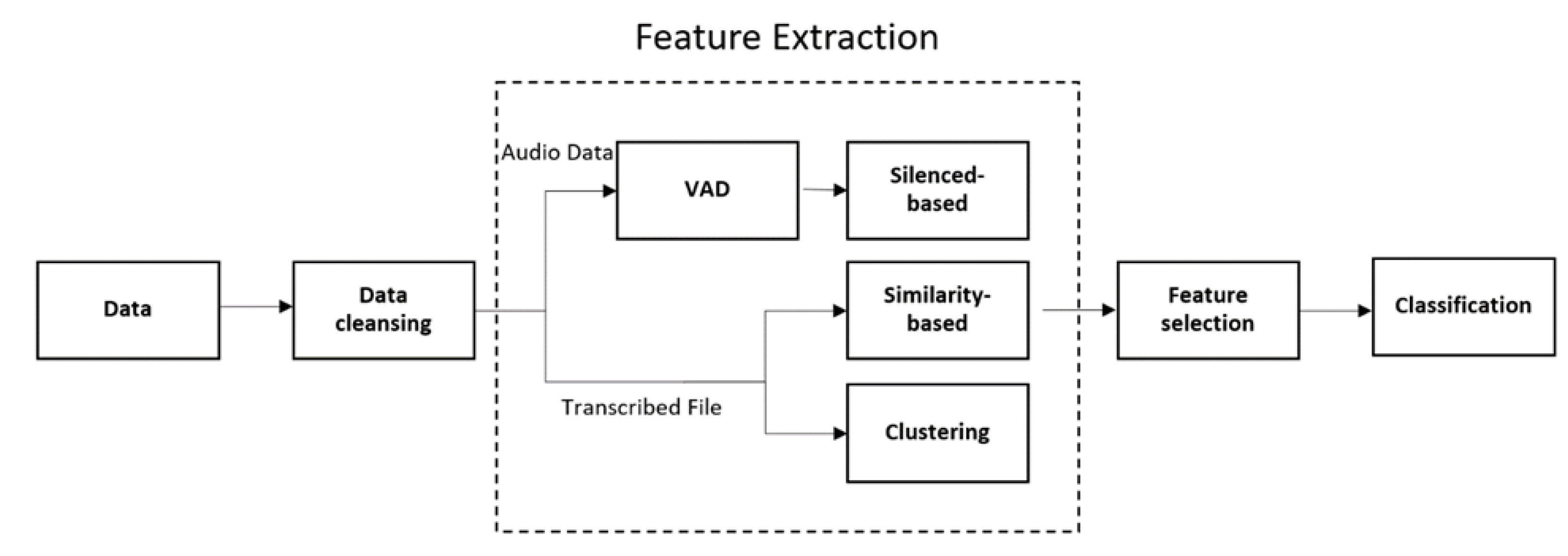
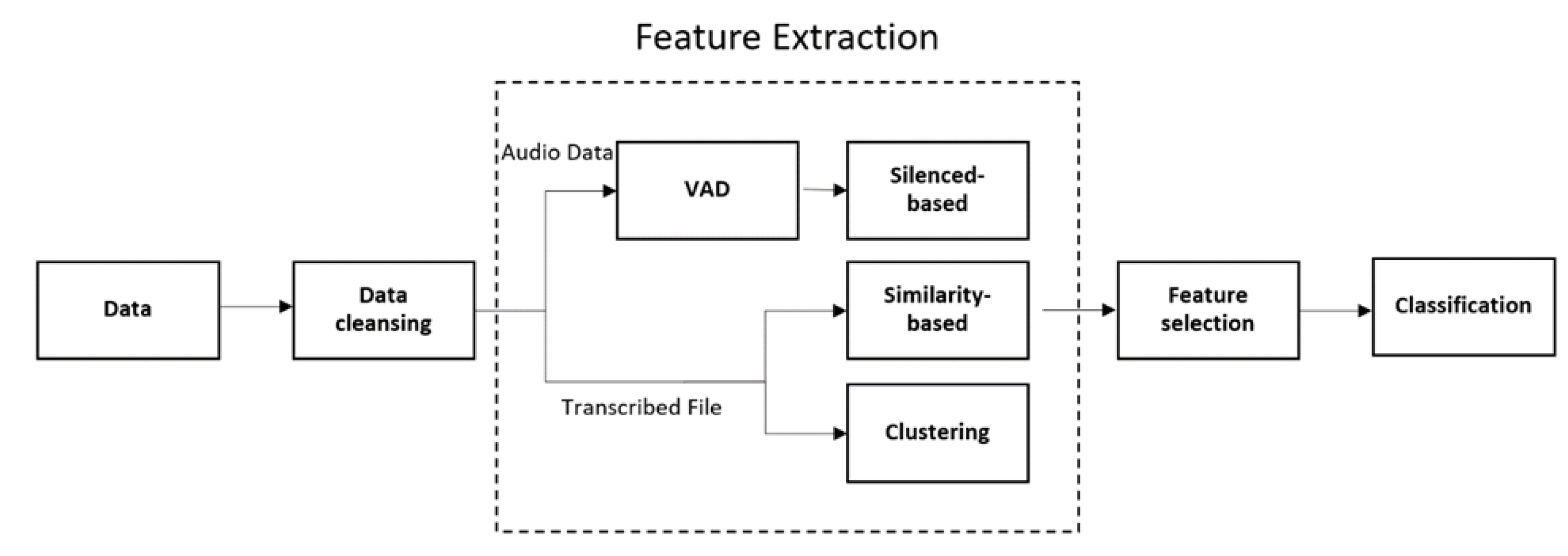
3.2. Feature Extraction
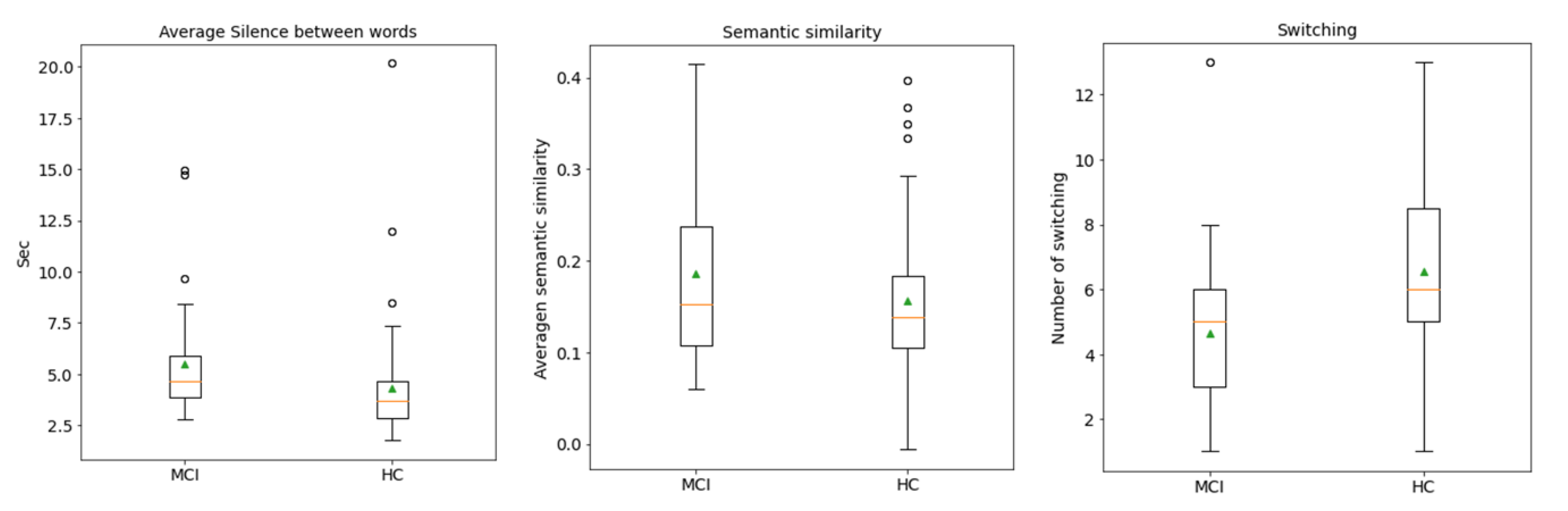
3.2.1. Silenced-Based Features
3.2.2. Similarity-Based Features
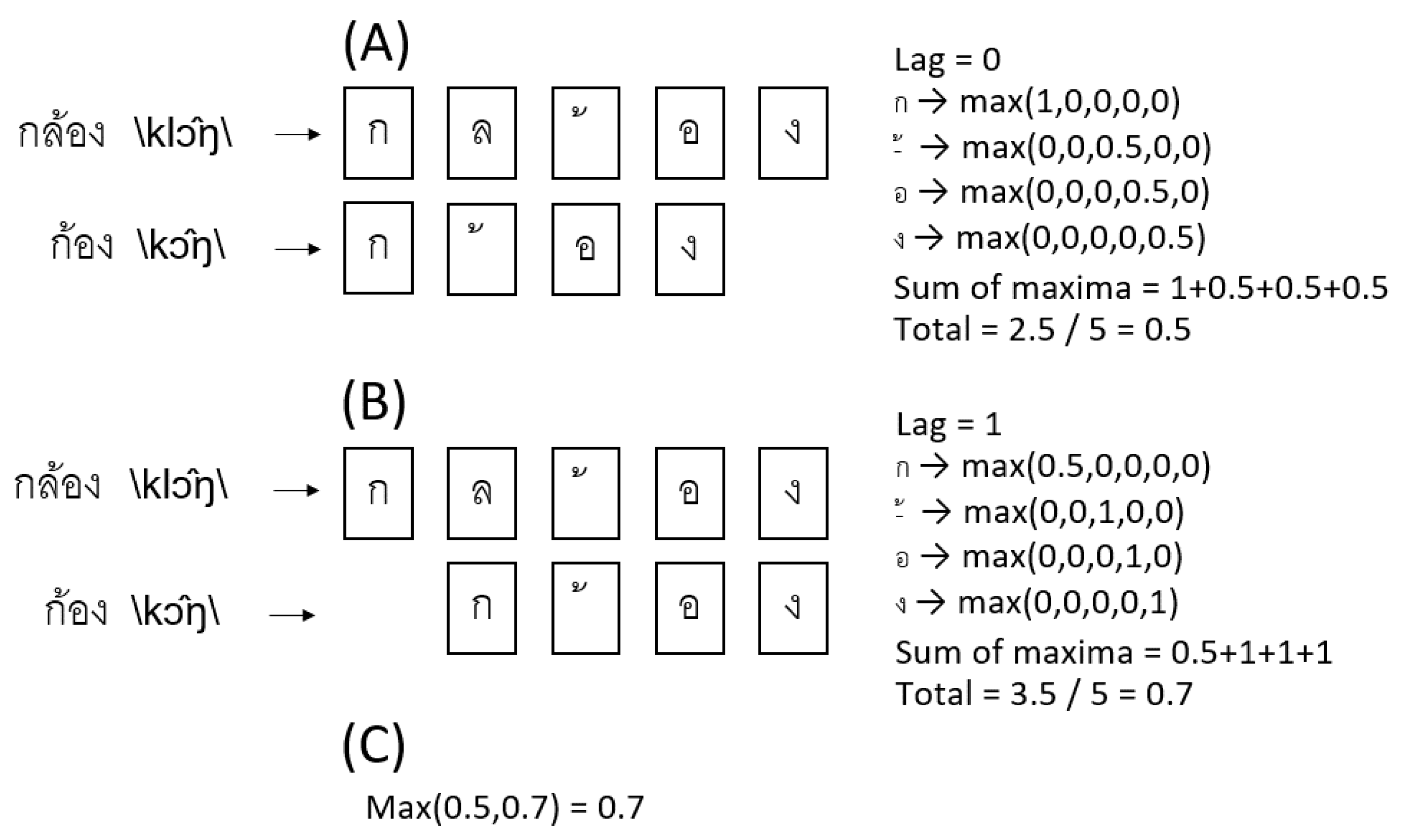
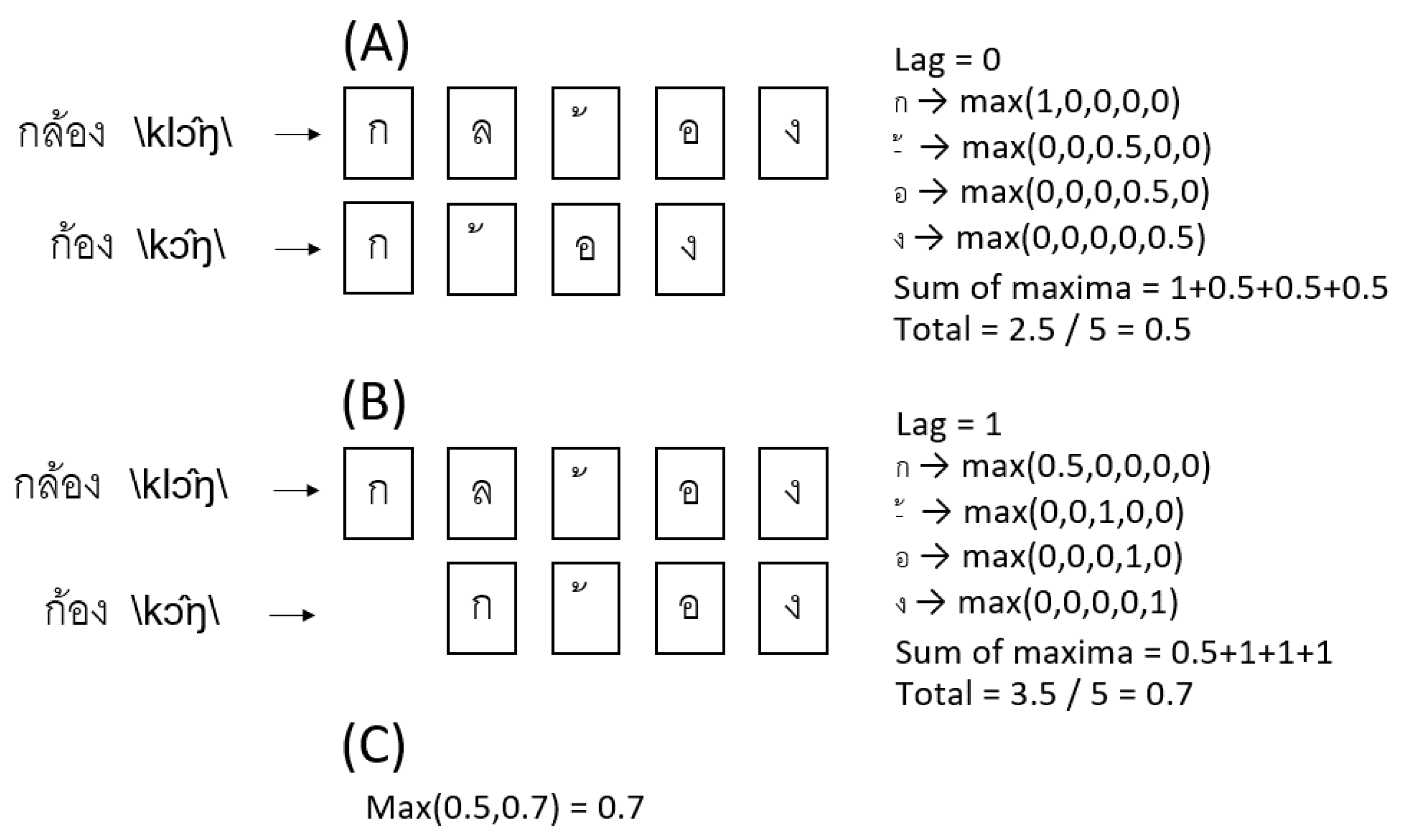
3.2.3. Orthographic Similarity in Thai
3.2.4. Phonemic Clustering for Thai PVF
3.2.5. Switching in Thai
3.3. Classification
3.4. Feature Selection
3.5. Evaluation
4. Results
4.1. Classification Results
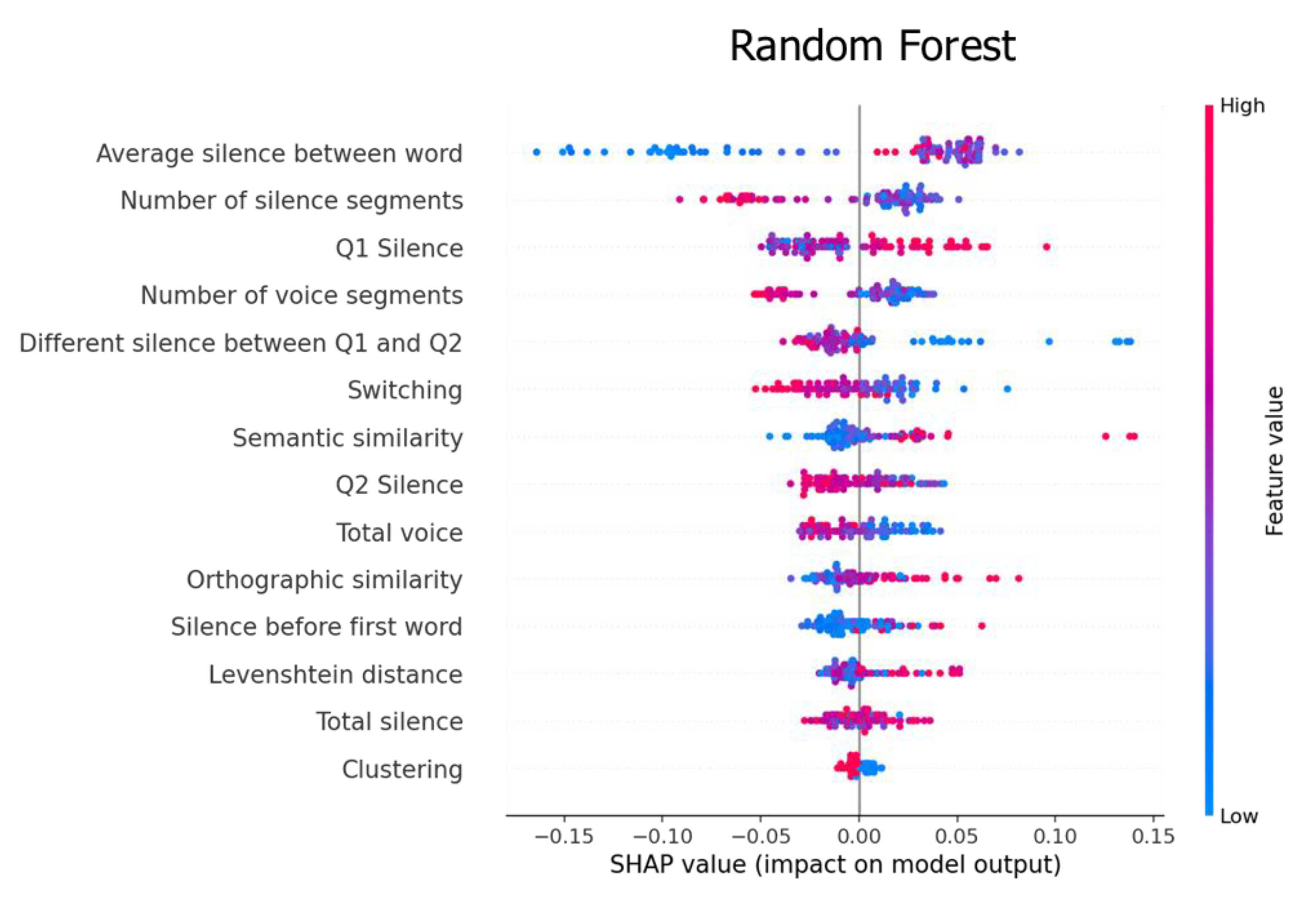
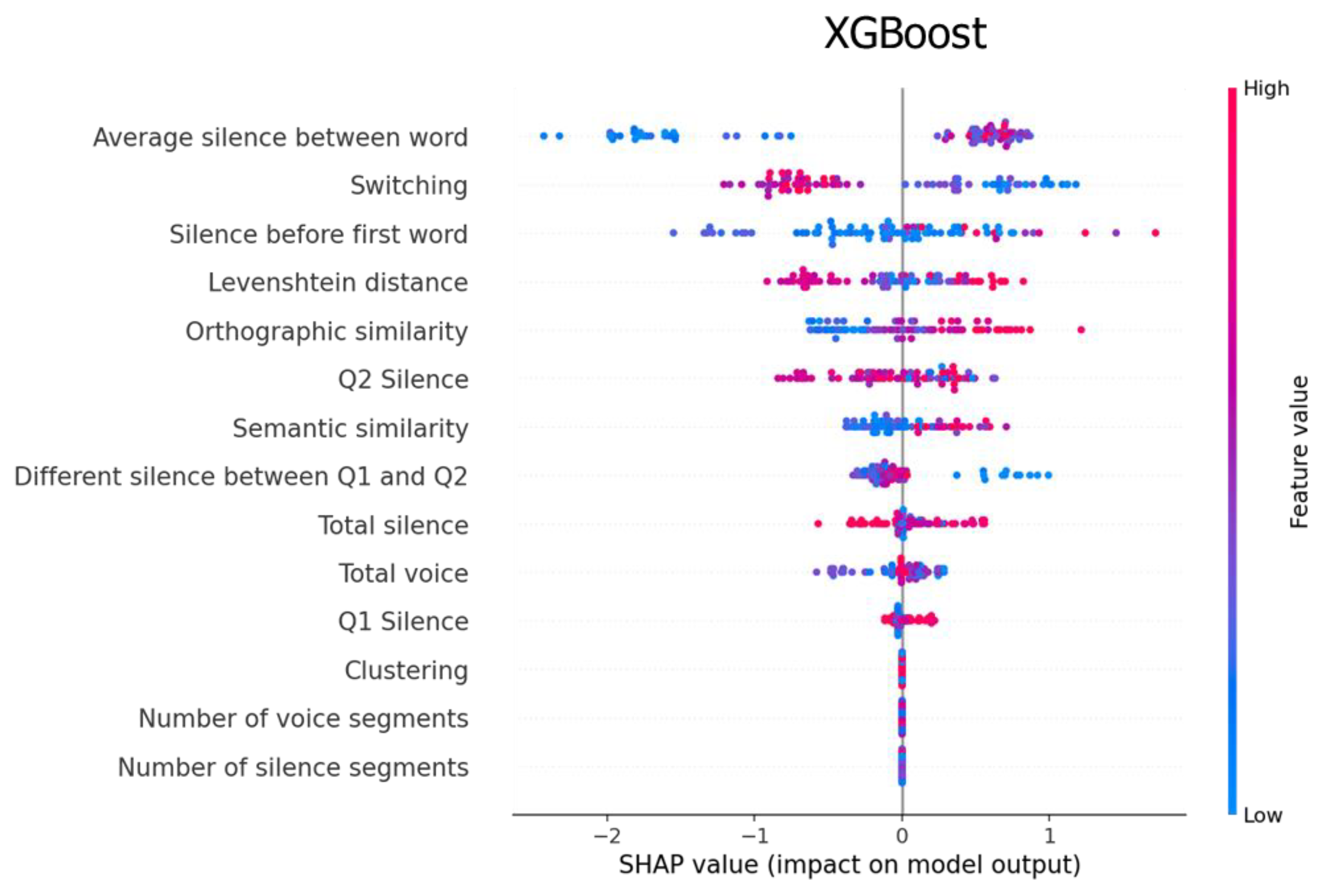
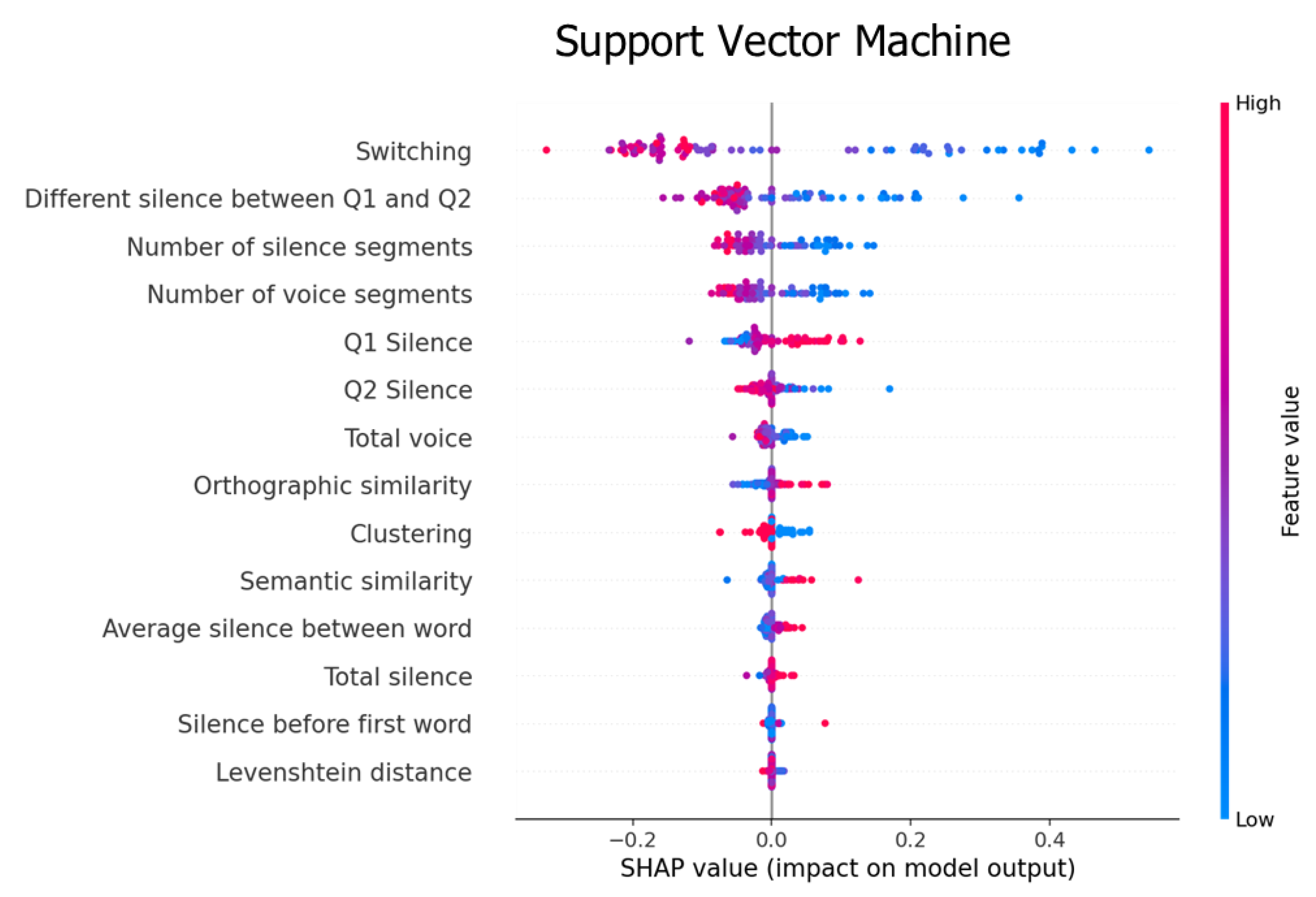
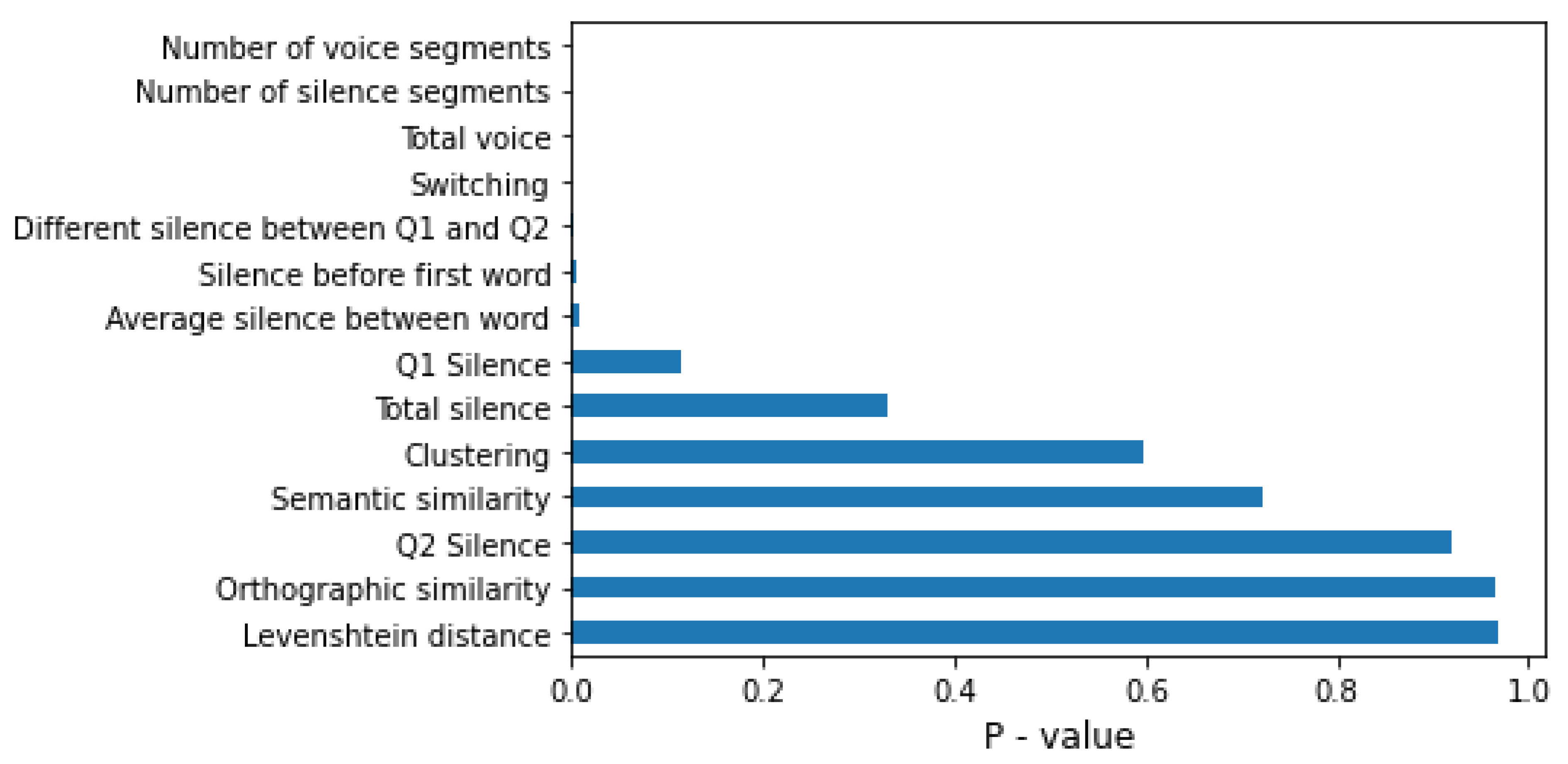
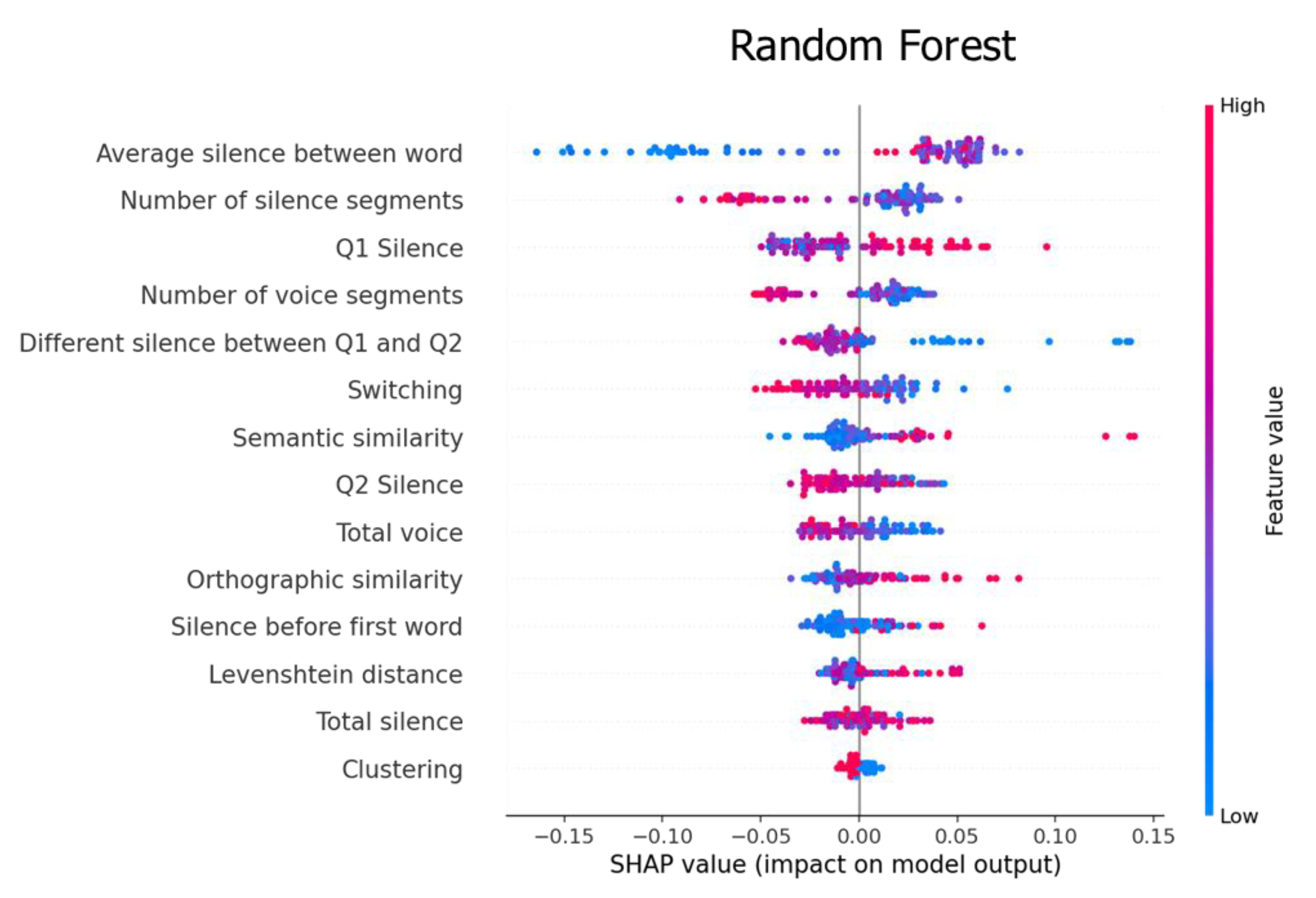
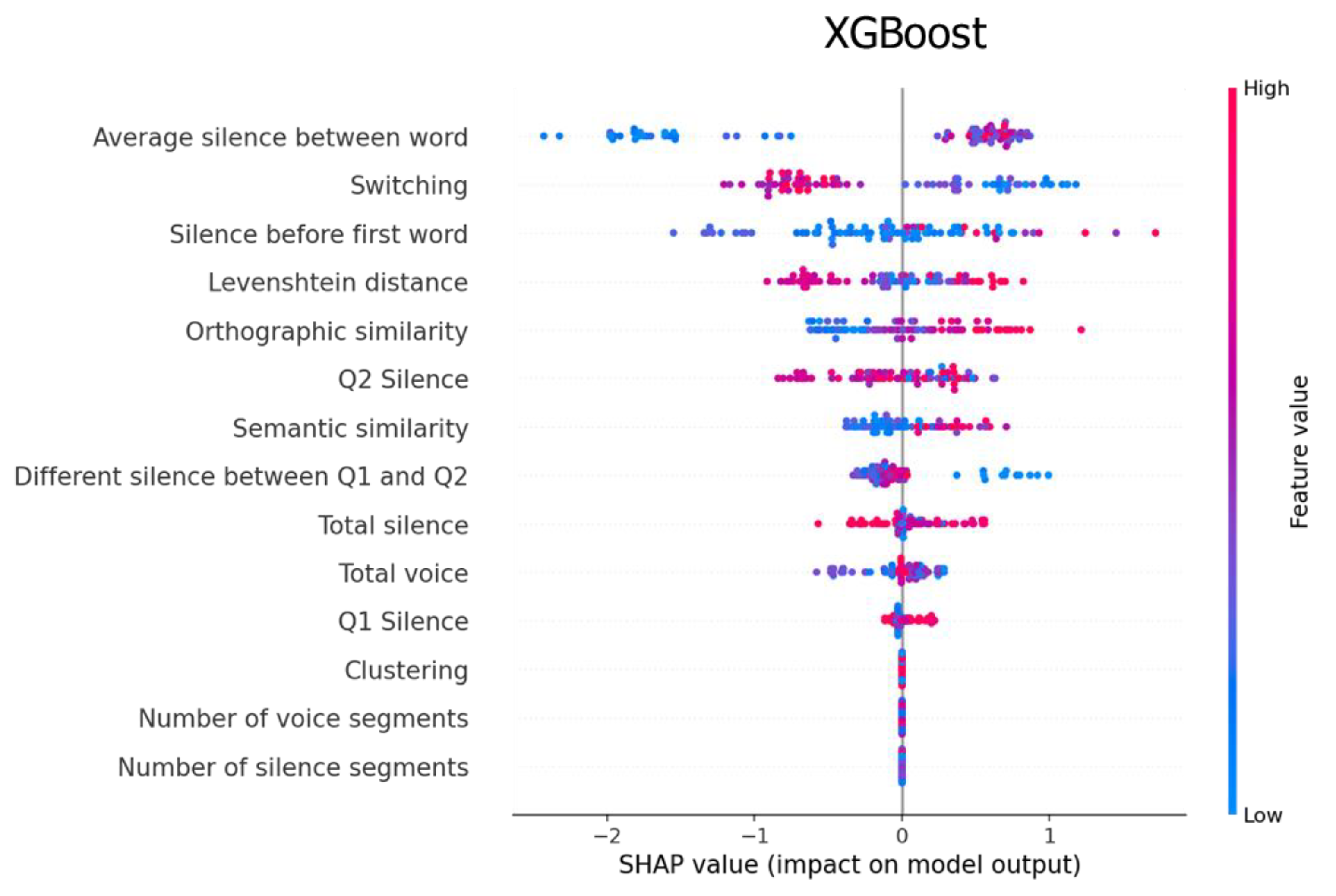
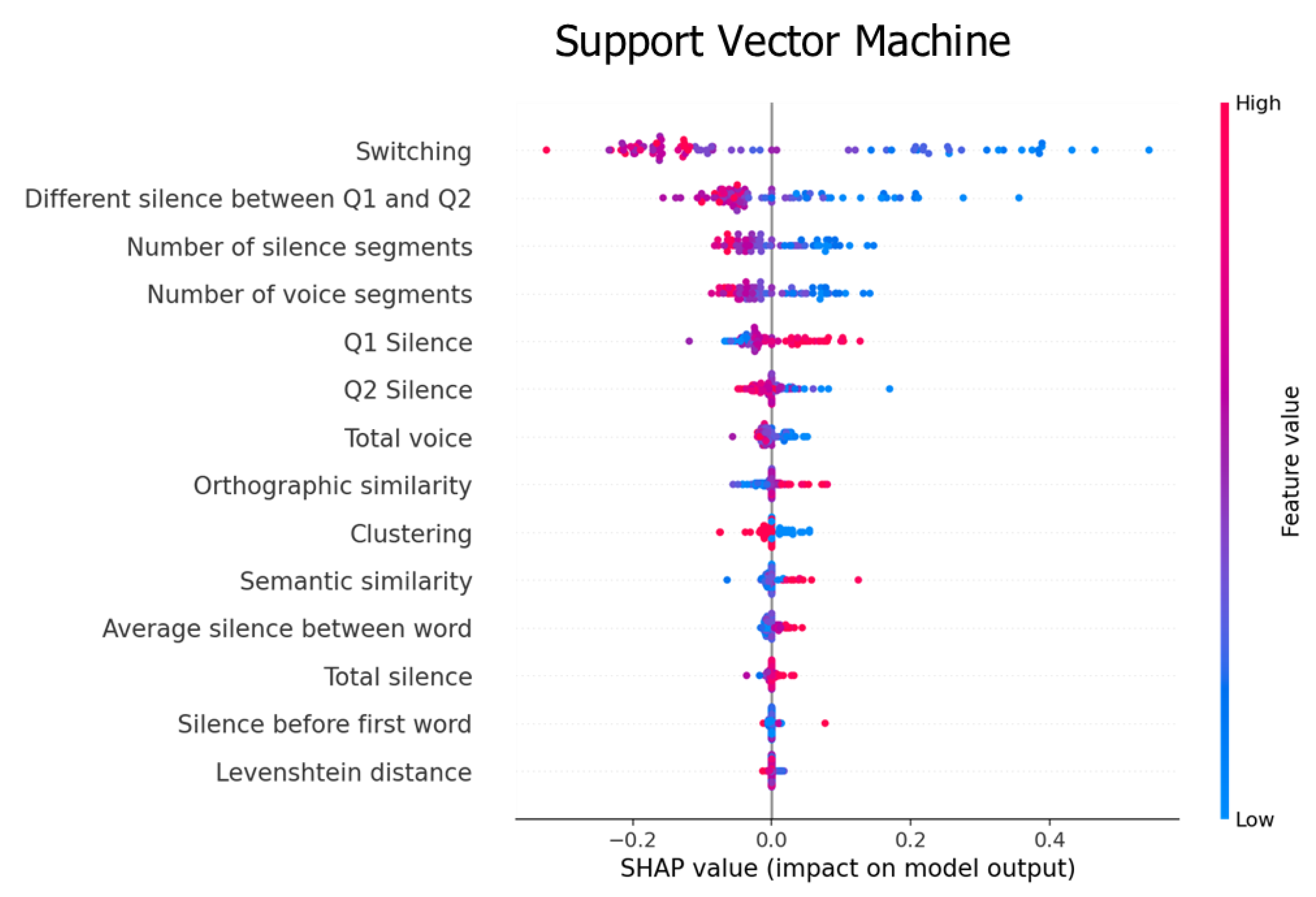
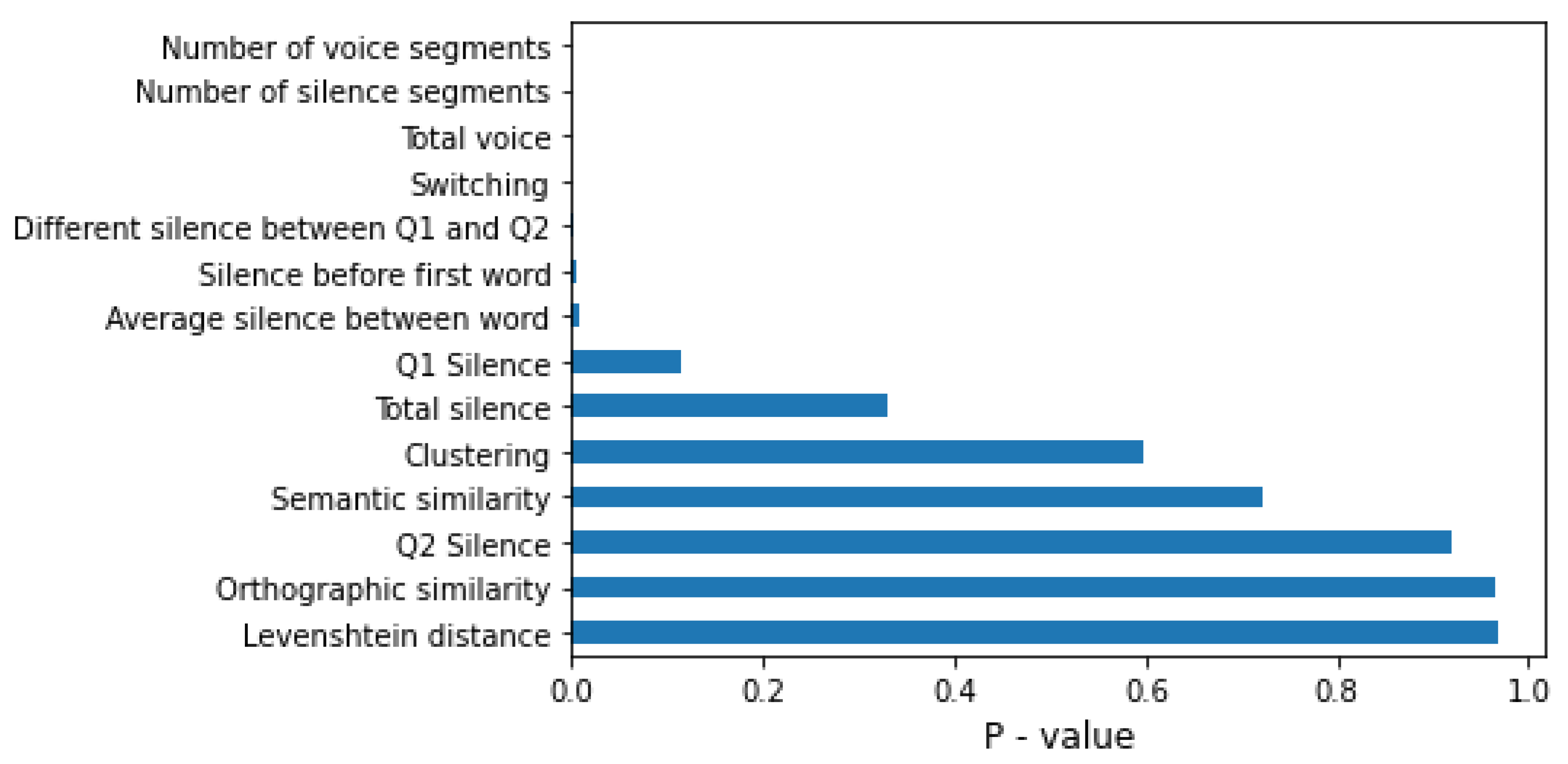
4.2. Feature Importance
5. Discussion
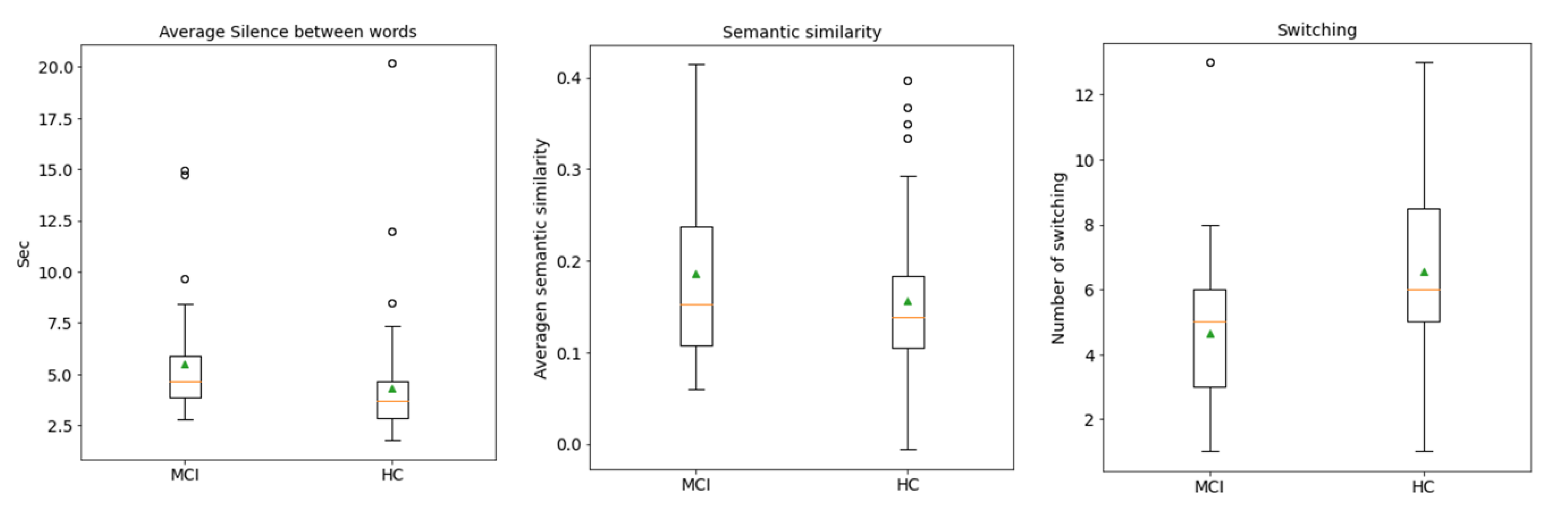
5.1. Feature Analysis
5.2. Classification Analysis
5.3. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
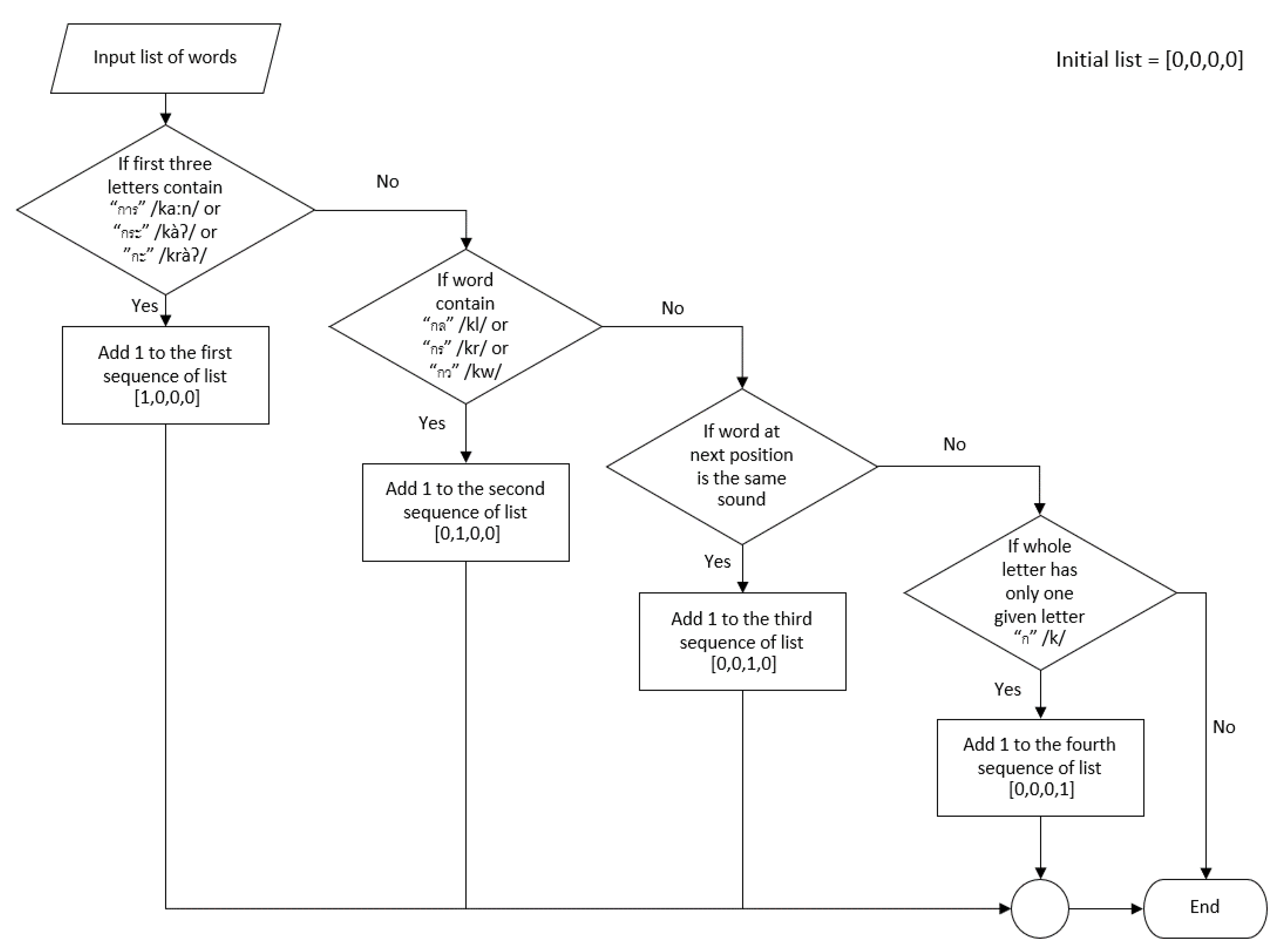
Appendix A. Phonemic Clustering for Thai PVF
Appendix A.1. Cluster 1: Words Starting with “การ” /kaːn/ or “กะ” /kàʔ/ or “กระ” /kràʔ/
Appendix A.2. Cluster 2: Consonant Blends
Appendix A.3. Cluster 3: Homonym
Appendix A.4. Cluster 4: Words with Only One Syllable and Others
 ” /àː/ to form the word “ไก่” /kàj/, which means “chicken” in English. Practically, the input word that did not match any conditions in our algorithm were classified into the fourth cluster after checking input words starting with the sound “ก” /k/.
” /àː/ to form the word “ไก่” /kàj/, which means “chicken” in English. Practically, the input word that did not match any conditions in our algorithm were classified into the fourth cluster after checking input words starting with the sound “ก” /k/.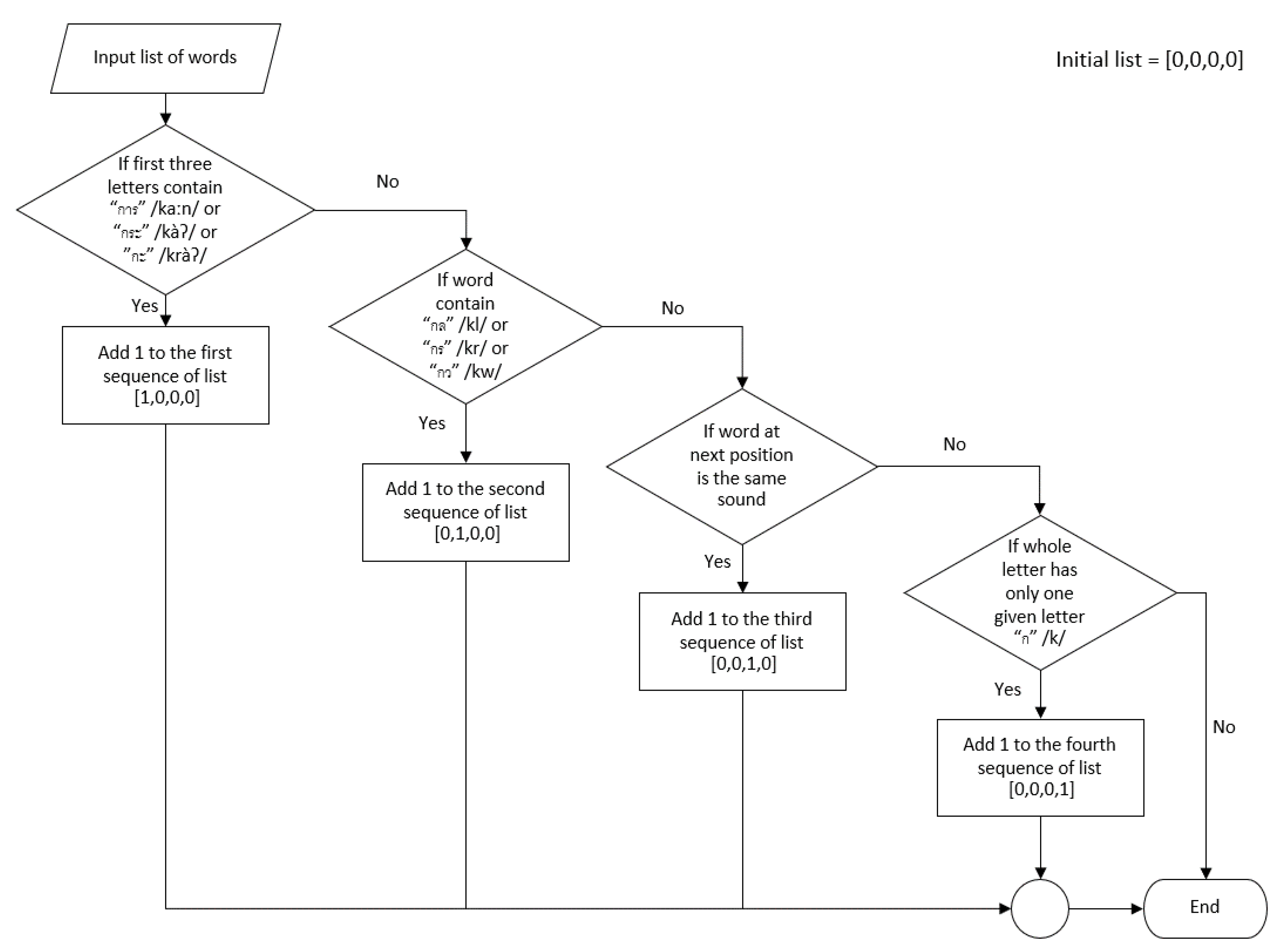
References
- Number of Population from Registration by Age Group Province and Region: 2011–2020. Available online: http://statbbi.nso.go.th/staticreport/page/sector/th/01.aspx (accessed on 17 August 2021).
- Deetong-on, T.; Puapornpong, P.; Pumipichet, S.; Benyakorn, S.; Kitporntheranunt, M.; Kongsomboon, K. Prevalence and risk factors of mild cognitive impairment in menopausal women at HRH Princess Maha Chakri Sirindhorn Medical Center. Thai J. Obstet. Gynaecol. 2013, 21, 110–116. [Google Scholar]
- Rattanawat, W.; Nakawiro, D.; Visajan, P. Prevalence of mild cognitive impairment (MCI) in pre-retirement period of hospital staff. J. Psychiatr. Assoc. Thail. 2018, 63, 55–64. [Google Scholar]
- Langa, K.M.; Levine, D.A. The diagnosis and management of mild cognitive impairment: A clinical review. JAMA 2014, 312, 2551–2561. [Google Scholar]
- Gauthier, S.; Reisberg, B.; Zaudig, M.; Petersen, R.C.; Ritchie, K.; Broich, K.; Belleville, S.; Brodaty, H.; Bennett, D.; Chertkow, H. Mild cognitive impairment. Lancet 2006, 367, 1262–1270. [Google Scholar]
- Nasreddine, Z.S.; Phillips, N.A.; Bédirian, V.; Charbonneau, S.; Whitehead, V.; Collin, I.; Cummings, J.L.; Chertkow, H. The Montreal Cognitive Assessment, MoCA: A brief screening tool for mild cognitive impairment. J. Am. Geriatr. Soc. 2005, 53, 695–699. [Google Scholar] [PubMed]
- Zhai, Y.; Chao, Q.; Li, H.; Wang, B.; Xu, R.; Wang, N.; Han, Y.; He, X.; Jia, X.; Wang, X. Application and Revision of montreal cognitive assessment in China’s military retirees with mild cognitive impairment. PLoS ONE 2016, 11, e0145547. [Google Scholar] [CrossRef] [Green Version]
- Fengler, S.; Kessler, J.; Timmermann, L.; Zapf, A.; Elben, S.; Wojtecki, L.; Tucha, O.; Kalbe, E. Screening for cognitive impairment in Parkinson’s disease: Improving the diagnostic utility of the MoCA through subtest weighting. PLoS ONE 2016, 11, e0159318. [Google Scholar] [CrossRef]
- Lee, M.T.; Chang, W.Y.; Jang, Y. Psychometric and diagnostic properties of the Taiwan version of the Quick Mild Cognitive Impairment screen. PLoS ONE 2018, 13, e0207851. [Google Scholar] [CrossRef]
- Kantithammakorn, P.; Punyabukkana, P.; Pratanwanich, P.N.; Hemrungrojn, S.; Chunharas, C.; Wanvarie, D. Using Automatic Speech Recognition to Assess Thai Speech Language Fluency in the Montreal Cognitive Assessment (MoCA). Sensors 2022, 22, 1583. [Google Scholar]
- Chi, Y.K.; Han, J.W.; Jeong, H.; Park, J.Y.; Kim, T.H.; Lee, J.J.; Lee, S.B.; Park, J.H.; Yoon, J.C.; Kim, J.L. Development of a screening algorithm for Alzheimer’s disease using categorical verbal fluency. PLoS ONE 2014, 9, e84111. [Google Scholar]
- Frankenberg, C.; Weiner, J.; Knebel, M.; Abulimiti, A.; Toro, P.; Herold, C.J.; Schultz, T.; Schröder, J. Verbal fluency in normal aging and cognitive decline: Results of a longitudinal study. Comput. Speech Lang. 2021, 68, 101195. [Google Scholar] [CrossRef]
- Amunts, J.; Camilleri, J.A.; Eickhoff, S.B.; Patil, K.R.; Heim, S.; von Polier, G.G.; Weis, S. Comprehensive verbal fluency features predict executive function performance. Sci. Rep. 2021, 11, 6926. [Google Scholar] [CrossRef]
- Woods, D.L.; Wyma, J.M.; Herron, T.J.; Yund, E.W. Computerized analysis of verbal fluency: Normative data and the effects of repeated testing, simulated malingering, and traumatic brain injury. PLoS ONE 2016, 11, e0166439. [Google Scholar] [CrossRef]
- Tóth, L.; Hoffmann, I.; Gosztolya, G.; Vincze, V.; Szatlóczki, G.; Bánréti, Z.; Pákáski, M.; Kálmán, J. A speech recognition-based solution for the automatic detection of mild cognitive impairment from spontaneous speech. Curr. Alzheimer Res. 2018, 15, 130–138. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.J.; Rich, J.B.; Troyer, A.K. Verbal fluency patterns in amnestic mild cognitive impairment are characteristic of Alzheimer’s type dementia. J. Int. Neuropsychol. Soc. 2006, 12, 570–574. [Google Scholar] [CrossRef]
- Dubois, B.; Slachevsky, A.; Litvan, I.; Pillon, B. The FAB: A frontal assessment battery at bedside. Neurology 2000, 55, 1621–1626. [Google Scholar] [CrossRef] [Green Version]
- Charernboon, T. Verbal fluency in the Thai elderly, elderly with mild cognitive impairment and elderly with dementia. J. Ment. Health Thail. 2018, 26, 91–102. [Google Scholar]
- Tingsabadh, M.K.; Abramson, A.S. Thai. J. Int. Phon. Assoc. 1993, 23, 24–28. [Google Scholar] [CrossRef]
- Hemrungrojn, S.; Tangwongchai, S.; Charoenboon, T. Use of the Montreal Cognitive Assessment Thai version (MoCA) to discriminate amnestic mild cognitive impairment from Alzheimer’s disease and healthy controls: Machine learning results. Running head: MoCA and amnestic mild cognitive impairment. Dement. Geriatr. Cogn. Disord. 2021; preprints. [Google Scholar]
- Troyer, A.K.; Moscovitch, M.; Winocur, G. Clustering and switching as two components of verbal fluency: Evidence from younger and older healthy adults. Neuropsychology 1997, 11, 138. [Google Scholar] [CrossRef] [PubMed]
- Ryan, J.O.; Pakhomov, S.; Marino, S.; Bernick, C.; Banks, S. Computerized analysis of a verbal fluency test. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 884–889. [Google Scholar]
- Mueller, K.D.; Koscik, R.L.; LaRue, A.; Clark, L.R.; Hermann, B.; Johnson, S.C.; Sager, M.A. Verbal fluency and early memory decline: Results from the Wisconsin registry for Alzheimer’s prevention. Arch. Clin. Neuropsychol. 2015, 30, 448–457. [Google Scholar] [CrossRef]
- Clark, D.; Wadley, V.; Kapur, P.; DeRamus, T.; Singletary, B.; Nicholas, A.; Blanton, P.; Lokken, K.; Deshpande, H.; Marson, D. Lexical factors and cerebral regions influencing verbal fluency performance in MCI. Neuropsychologia 2014, 54, 98–111. [Google Scholar] [CrossRef] [PubMed]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Siew, C.S. The orthographic similarity structure of English words: Insights from network science. Appl. Netw. Sci. 2018, 3, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harispe, S.; Ranwez, S.; Janaqi, S.; Montmain, J. Semantic similarity from natural language and ontology analysis. In Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2015; Volume 8, pp. 1–254. [Google Scholar]
- Lindsay, H.; Linz, N.; Tröger, J.; Alexandersson, J. Automatic data-driven approaches for evaluating the phonemic verbal fluency task with healthy adults. In Proceedings of the 3rd International Conference on Natural Language and Speech Processing, Trento, Italy, 12–13 September 2019; pp. 17–24. [Google Scholar]
- Lindsay, H.; Mueller, P.; Linz, N.; Zeghari, R.; Mina, M.M.; König, A.; Tröger, J. Dissociating semantic and phonemic search strategies in the phonemic verbal fluency task in early Dementia. In Proceedings of the Seventh Workshop on Computational Linguistics and Clinical Psychology: Improving Access, Online, 11 June 2021; pp. 32–44. [Google Scholar]
- Hoffmann, I.; Nemeth, D.; Dye, C.D.; Pákáski, M.; Irinyi, T.; Kálmán, J. Temporal parameters of spontaneous speech in Alzheimer’s disease. Int. J. Speech-Lang. Pathol 2010, 12, 29–34. [Google Scholar] [CrossRef] [PubMed]
- Tóth, L.; Gosztolya, G.; Vincze, V.; Hoffmann, I.; Szatlóczki, G.; Biró, E.; Zsura, F.; Pákáski, M.; Kálmán, J. Automatic detection of mild cognitive impairment from spontaneous speech using ASR. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6 September 2015. [Google Scholar]
- Campbell, E.L.; Mesía, R.Y.; Docío-Fernández, L.; García-Mateo, C. Paralinguistic and linguistic fluency features for Alzheimer’s disease detection. Comput. Speech Lang. 2021, 68, 101198. [Google Scholar] [CrossRef]
- Robert, J.; Webbie, M.; Larrosa, A.; Acacio, D.; McMellen, J. Pydub. 2018. Available online: http://pydub.com/ (accessed on 17 August 2021).
- Phatthiyaphaibun, W.; Chaovavanich, K.; Polpanumas, C.; Suriyawongkul, A.; Lowphansirikul, L.; Chormai, P. PyThaiNLP: Thai Natural Language Processing in Python. June 2016. Available online: https://github.com/PyThaiNLP/pythainlp (accessed on 17 August 2021).
- Troyer, A.K.; Moscovitch, M.; Winocur, G.; Alexander, M.P.; Stuss, D. Clustering and switching on verbal fluency: The effects of focal frontal-and temporal-lobe lesions. Neuropsychologia 1998, 36, 499–504. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. Chi2: Feature selection and discretization of numeric attributes. In Proceedings of the 7th IEEE International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 5–8 November 1995; pp. 388–391. [Google Scholar]
- Mandrekar, J.N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef] [Green Version]
- Hajian-Tilaki, K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Casp. J. Intern. Med. 2013, 4, 627. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCI (N = 41) | HC (N = 59) | |
|---|---|---|
| Male | 7 | 10 |
| Female | 34 | 49 |
| Word count (mean) | 3–15 (9.61) | 2–24 (10.10) |
| MoCA Score (mean) | 10–24 (21.59) | 25–29 (27) |
| Feature | Description |
|---|---|
| Silence-based features | |
| Total silence | Total length of silence during the test. |
| Total voiced | Total length of voiced during the test. |
| Number of silence segments | Total number of silence segments. |
| Number of voice segments | Total number of voice segments. |
| Average silence between word | Total silence divided by the number of silence segments. |
| Q1 Silence | Total silence in the first 30 s of the audio file. |
| Q2 Silence | Total silence in the last 30 s of the audio file. |
| Silence before first word | Silence length before the participant speaks the first word. |
| Different silence between Q1 and Q2 | Total silence in the first 30 s minus the last 30 s. |
| Similarity-based features | |
| Orthographic similarity | Average orthographic similarity value of all words. |
| Levenshtein distance | Average Levenshtein distance ratio of all words. |
| Semantic similarity | Average semantic similarity value of all words. |
| Cluster features | |
| Phonemic clustering | Group of words by phonemic categories. |
| Switching | Total number of the transition between clusters. |
| Cluster | Characteristic | Example with IPA |
|---|---|---|
| 1 | Word started with “การ” /kaːn/ or “กะ” /kàʔ/ or “กระ” /kràʔ/ | “การเรียน” /kaːn riːan/ “to learn”, “กระต่าย” /kràʔ tàːj/ “rabbit”, “กระโดด” /kràʔ dòːt/ “to jump” |
| 2 | Consonant blends | “กลวง” /kluːaŋ/ “hollow”, “กราบ” /kràːp/ “to pay respects”, “กวาด” /kwàːt/ “to sweep” |
| 3 | Homonym | “ก้าว” /kâːw/ “to step”, “เก้า” /kâːw/ “nine” |
| 4 | Word with only 1 syllable and others | “เกิด” /kə̀ət/ “born”, “แก่” /kɛ̀ɛ/ “old”, “เก็บ” /kèp/ “to store” |
| N | Acc. | F1-Score | Precision | Recall | Specificity | AUC |
|---|---|---|---|---|---|---|
| 1 | 0.584 ± 0.16 | 0.565 ± 0.18 | 0.497 ± 0.24 | 0.535 ± 0.24 | 0.627 ± 0.22 | 0.636 ± 0.20 |
| 2 | 0.584 ± 0.16 | 0.565 ± 0.18 | 0.497 ± 0.24 | 0.535 ± 0.24 | 0.627 ± 0.22 | 0.636 ± 0.20 |
| 3 | 0.584 ± 0.18 | 0.561 ± 0.19 | 0.504 ± 0.26 | 0.530 ± 0.27 | 0.623 ± 0.24 | 0.629 ± 0.21 |
| 4 | 0.574 ± 0.19 | 0.556 ± 0.19 | 0.473 ± 0.21 | 0.510 ± 0.28 | 0.623 ± 0.19 | 0.649 ± 0.20 |
| 5 | 0.534 ± 0.20 | 0.501 ± 0.22 | 0.415 ± 0.29 | 0.375 ± 0.28 | 0.643 ± 0.19 | 0.660 ± 0.23 |
| 6 | 0.594 ± 0.20 | 0.563 ± 0.22 | 0.440 ± 0.26 | 0.450 ± 0.29 | 0.697 ± 0.18 | 0.653 ± 0.22 |
| 7 | 0.590 ± 0.18 | 0.558 ± 0.20 | 0.448 ± 0.26 | 0.500 ± 0.32 | 0.642 ± 0.17 | 0.646 ± 0.22 |
| 8 | 0.640 ± 0.23 * | 0.616 ± 0.25 * | 0.506 ± 0.30 | 0.575 ± 0.37 * | 0.683 ± 0.17 | 0.667 ± 0.23 |
| 9 | 0.610 ± 0.20 | 0.579 ± 0.23 | 0.452 ± 0.28 | 0.550 ± 0.38 | 0.647 ± 0.15 | 0.650 ± 0.19 |
| 10 | 0.580 ± 0.19 | 0.552 ± 0.21 | 0.450 ± 0.28 | 0.455 ± 0.30 | 0.663 ± 0.15 | 0.671 ± 0.21 |
| 11 | 0.620 ± 0.21 | 0.600 ± 0.23 | 0.512 ± 0.30 * | 0.530 ± 0.33 | 0.683 ± 0.17 | 0.683 ± 0.24 * |
| 12 | 0.570 ± 0.18 | 0.545 ± 0.19 | 0.457 ± 0.24 | 0.455 ± 0.27 | 0.647 ± 0.15 | 0.642 ± 0.23 |
| 13 | 0.600 ± 0.17 | 0.565 ± 0.19 | 0.482 ± 0.27 | 0.430 ± 0.26 | 0.717 ± 0.15 * | 0.642 ± 0.25 |
| 14 | 0.580 ± 0.19 | 0.542 ± 0.22 | 0.435 ± 0.32 | 0.430 ± 0.32 | 0.683 ± 0.17 | 0.617 ± 0.22 |
| N | Acc. | F1-Score | Precision | Recall | Specificity | AUC |
|---|---|---|---|---|---|---|
| 1 | 0.570 ± 0.15 | 0.557 ± 0.15 | 0.494 ± 0.14 | 0.610 ± 0.23* | 0.543 ± 0.21 | 0.665 ± 0.23 |
| 2 | 0.570 ± 0.15 | 0.557 ± 0.15 | 0.494 ± 0.14 | 0.610 ± 0.23* | 0.543 ± 0.21 | 0.669 ± 0.23 |
| 3 | 0.580 ± 0.17 | 0.563 ± 0.17 | 0.490 ± 0.17 | 0.540 ± 0.27 | 0.613 ± 0.18 | 0.672 ± 0.25 |
| 4 | 0.610 ± 0.19 | 0.588 ± 0.20 | 0.515 ± 0.25 | 0.505 ± 0.28 | 0.683 ± 0.17 | 0.680 ± 0.23 |
| 5 | 0.610 ± 0.21 | 0.576 ± 0.22 | 0.523 ± 0.29 | 0.430 ± 0.28 | 0.733 ± 0.20 | 0.717 ± 0.21 |
| 6 | 0.650 ± 0.22 * | 0.626 ± 0.24 * | 0.567 ± 0.28 | 0.525 ± 0.31 | 0.733 ± 0.20 | 0.721 ± 0.21 |
| 7 | 0.650 ± 0.21 * | 0.624 ± 0.22 | 0.583 ± 0.28 * | 0.505 ± 0.28 | 0.750 ± 0.20 | 0.729 ± 0.20 |
| 8 | 0.590 ± 0.18 | 0.551 ± 0.18 | 0.539 ± 0.29 | 0.365 ± 0.20 | 0.750 ± 0.20 | 0.725 ± 0.21 |
| 9 | 0.530 ± 0.11 | 0.362 ± 0.09 | 0.200 ± 0.40 | 0.025 ± 0.08 | 0.883 ± 0.17 | 0.733 ± 0.20 * |
| 10 | 0.540 ± 0.11 | 0.366 ± 0.09 | 0.250 ± 0.43 | 0.025 ± 0.07 | 0.900 ± 0.17 | 0.733 ± 0.20 |
| 11 | 0.550 ± 0.07 | 0.356 ± 0.03 | 0.000 ± 0.00 | 0.000 ± 0.00 | 0.933 ± 0.11 | 0.733 ± 0.20 |
| 12 | 0.560 ± 0.07 | 0.358 ± 0.03 | 0.000 ± 0.00 | 0.000 ± 0.00 | 0.950 ± 0.11 * | 0.725 ± 0.21 |
| 13 | 0.560 ± 0.07 | 0.358 ± 0.03 | 0.000 ± 0.00 | 0.000 ± 0.00 | 0.950 ± 0.11 * | 0.725 ± 0.21 |
| 14 | 0.560 ± 0.07 | 0.358 ± 0.03 | 0.000 ± 0.00 | 0.000 ± 0.00 | 0.950 ± 0.11 * | 0.725 ± 0.21 |
| N | Acc. | F1-Score | Precision | Recall | Specificity | AUC |
|---|---|---|---|---|---|---|
| 1 | 0.620 ± 0.15 | 0.594 ± 0.17 | 0.521 ± 0.24 | 0.605 ± 0.28 * | 0.633 ± 0.22 | 0.640 ± 0.21 |
| 2 | 0.620 ± 0.15 | 0.594 ± 0.17 | 0.521 ± 0.24 | 0.605 ± 0.28 * | 0.633 ± 0.22 | 0.640 ± 0.21 |
| 3 | 0.590 ± 0.17 | 0.558 ± 0.19 | 0.475 ± 0.24 | 0.480 ± 0.27 | 0.663 ± 0.19 | 0.626 ± 0.17 |
| 4 | 0.560 ± 0.14 | 0.515 ± 0.15 | 0.438 ± 0.21 | 0.390 ± 0.23 | 0.680 ± 0.20 | 0.659 ± 0.13 |
| 5 | 0.550 ± 0.17 | 0.497 ± 0.20 | 0.343 ± 0.28 | 0.400 ± 0.34 | 0.647 ± 0.19 | 0.550 ± 0.23 |
| 6 | 0.570 ± 0.17 | 0.540 ± 0.19 | 0.447 ± 0.24 | 0.480 ± 0.27 | 0.630 ± 0.21 | 0.638 ± 0.19 |
| 7 | 0.560 ± 0.17 | 0.526 ± 0.19 | 0.433 ± 0.22 | 0.450 ± 0.29 | 0.630 ± 0.19 | 0.617 ± 0.17 |
| 8 | 0.590 ± 0.20 | 0.564 ± 0.21 | 0.489 ± 0.23 | 0.500 ± 0.30 | 0.650 ± 0.22 | 0.621 ± 0.21 |
| 9 | 0.570 ± 0.13 | 0.536 ± 0.16 | 0.420 ± 0.22 | 0.455 ± 0.28 | 0.647 ± 0.13 | 0.638 ± 0.18 |
| 10 | 0.580 ± 0.14 | 0.550 ± 0.16 | 0.437 ± 0.22 | 0.480 ± 0.27 | 0.647 ± 0.13 | 0.642 ± 0.17 |
| 11 | 0.630 ± 0.11 * | 0.603 ± 0.13 * | 0.522 ± 0.16 * | 0.530 ± 0.26 | 0.697 ± 0.09 | 0.642 ± 0.23 |
| 12 | 0.630 ± 0.18 * | 0.585 ± 0.22 | 0.522 ± 0.35 * | 0.455 ± 0.34 | 0.747 ± 0.15 * | 0.650 ± 0.25 |
| 13 | 0.620 ± 0.17 | 0.592 ± 0.17 | 0.512 ± 0.24 | 0.505 ± 0.25 | 0.697 ± 0.14 | 0.671 ± 0.18 * |
| 14 | 0.630 ± 0.13 * | 0.601 ± 0.16 | 0.513 ± 0.23 | 0.505 ± 0.25 | 0.713 ± 0.10 | 0.629 ± 0.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Metarugcheep, S.; Punyabukkana, P.; Wanvarie, D.; Hemrungrojn, S.; Chunharas, C.; Pratanwanich, P.N. Selecting the Most Important Features for Predicting Mild Cognitive Impairment from Thai Verbal Fluency Assessments. Sensors 2022, 22, 5813. https://doi.org/10.3390/s22155813
Metarugcheep S, Punyabukkana P, Wanvarie D, Hemrungrojn S, Chunharas C, Pratanwanich PN. Selecting the Most Important Features for Predicting Mild Cognitive Impairment from Thai Verbal Fluency Assessments. Sensors. 2022; 22(15):5813. https://doi.org/10.3390/s22155813
Chicago/Turabian StyleMetarugcheep, Suppat, Proadpran Punyabukkana, Dittaya Wanvarie, Solaphat Hemrungrojn, Chaipat Chunharas, and Ploy N. Pratanwanich. 2022. "Selecting the Most Important Features for Predicting Mild Cognitive Impairment from Thai Verbal Fluency Assessments" Sensors 22, no. 15: 5813. https://doi.org/10.3390/s22155813
APA StyleMetarugcheep, S., Punyabukkana, P., Wanvarie, D., Hemrungrojn, S., Chunharas, C., & Pratanwanich, P. N. (2022). Selecting the Most Important Features for Predicting Mild Cognitive Impairment from Thai Verbal Fluency Assessments. Sensors, 22(15), 5813. https://doi.org/10.3390/s22155813