
Making Group Decisions within the Framework of a Probabilistic Hesitant Fuzzy Linear Regression Model


 ,
,  ,
,
Abstract
:1. Introduction
2. Preliminaries
3. Probabilistic Hesitant Fuzzy Linear Regression Model
4. Decision-Making Algorithms
4.1. Algorithm for PHFLRM
- Step 1.
- Let be a connected IPOP variable decision matrix provided by the DMs, where are PHFEs.
- Step 2.
- For two finite PHFEs and , there are two opposite principles for normalization. The first one is normalization, in which we remove some elements of and which have more elements than the other ones. The second one is normalization, in which we add some elements to and , which have fewer elements than the other one. In this study, we use the principle of normalization to make all PHFEs equal in the matrix H. Let be the normalized matrix, where are PHFEs.
- Step 3.
- Using Definition 3, probabilistic information is completed for the PHFES in the decision matrix . Let be a decision matrix after completing probabilistic information in the matrix , where are PHFEs.
- Step 4.
- Again, normalize the matrix by using the following equationLet be a normalized decision matrix where are PHFEs.
- Step 5.
- By using the normalized decision matrix , the PHFLRM is obtained. We further estimate the parameters of PHFLRM employing LPM.
- Step 6.
- Rank the alternatives using residual values obtained from the score values of and i.e.,, where are predicted values which are calculated by using Definitions 3 and 4.
- Step 7.
- Finally, the alternatives are ranked according to the values of . The alternative with the least residual is identified as the best choice.
4.2. The TOPSIS Algorithm
- Step 1.
- Take the decision matrices and same as mentioned in Step 1, 2, and 3 of Section 4.1.
- Step 2.
- Normalize the decision matrix with the help of the following formula.Let be the normalized decision matrix, where are PHFEs.
- Step 3.
- The weighted normalized decision matrix is calculated by multiplaying the normalized decision matrix with its associated weights, i.e., , where is a PHFE.
- Step 4.
- Determine the positive ideal solution and negative ideal solution aswhere and represent the set of benefit and cost criteria, respectively.
- Step 5.
- Calculate the Euclidean distances of D and D of each alternative A from the positive ideal solution A and negative ideal solution A, respectively, by using Definition 6.
- Step 6.
- Calculate the relative closeness of each alternative to the ideal solution as
- Step 7.
- The alternatives are ranked according to relative closeness values in the descending order.
5. Application Example
- Step 1.
- Step 2 & 3.
- We obtain the matrix , which can be shown in Table 2, by making all PHFES equal using normalization and making the sum of all probabilities equal to one for all PHFES in the decision matrix H and , respectively.
- Step 4 & 5.
- We will estimate the parameters from the normalized decision matrix using LP after normalizing the matrix , as follows:
- Step 6 & 7.
- By using PHFLRM, we will find the estimated PHFEs of all possible alternatives. To save time, we will just compute the estimated PHFE against the alternative using the Definition 3 and 4, as follows:
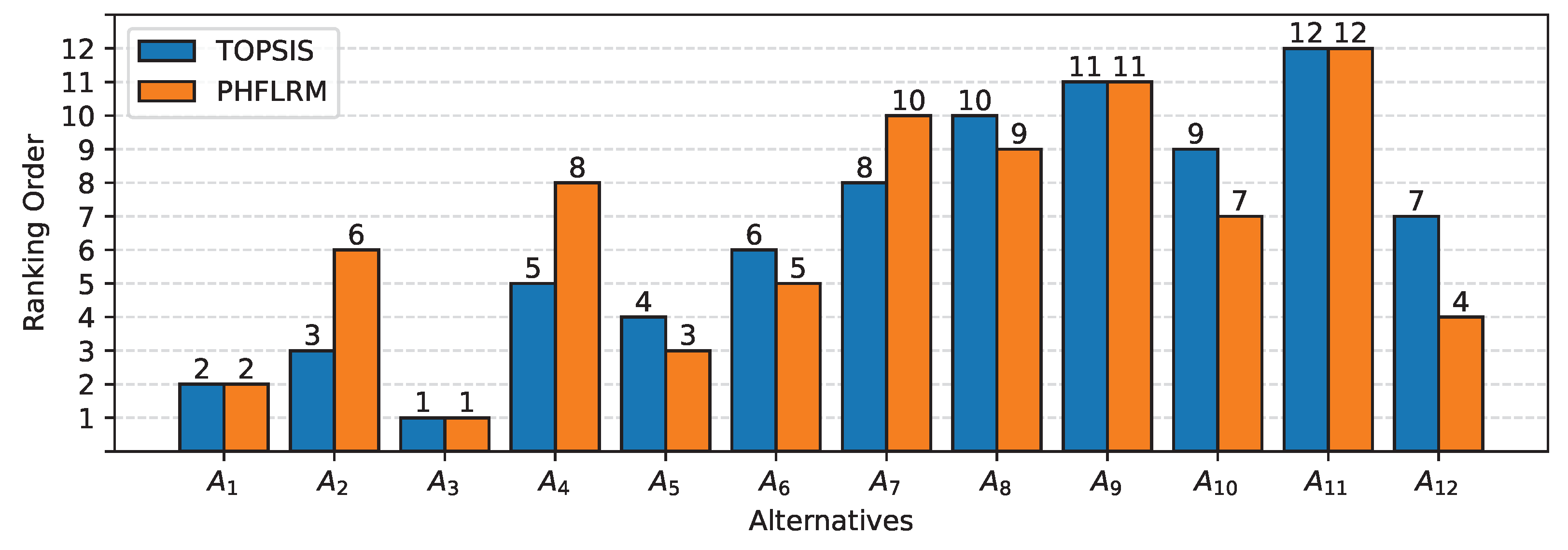
A Comparative Study of the PHFLRM and the TOPSIS
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MCDM | Multi-Criteria Decision-Making; |
| HFS | Hesitant Fuzzy Set; |
| PHFS | Probabilistic Hesitant Fuzzy Set; |
| FLRM | Fuzzy Linear Regression Model; |
| PHFE | Probabilistic Hesitant Fuzzy Elements; |
| IPOP | Input–Output; |
| LPM | Linear Programming Model; |
| PHFLRM | Probabilistic Hesitant Fuzzy Linear Regression Model; |
| TOPSIS | Technique For Order Preference by Similarity to Ideal Solution. |
References
- Asai, H.; Tanaka, S.; Uegima, K. Linear regression analysis with fuzzy model. IEEE Trans. Syst. Man Cybern 1982, 12, 903–907. [Google Scholar]
- Tanaka, H. Fuzzy data analysis by possibilistic linear models. Fuzzy Sets Syst. 1987, 24, 363–375. [Google Scholar] [CrossRef]
- Celmiņš, A. Least squares model fitting to fuzzy vector data. Fuzzy Sets Syst. 1987, 22, 245–269. [Google Scholar] [CrossRef]
- Diamond, P. Fuzzy least squares. Inf. Sci. 1988, 46, 141–157. [Google Scholar] [CrossRef]
- Peters, G. Fuzzy linear regression with fuzzy intervals. Fuzzy Sets Syst. 1994, 63, 45–55. [Google Scholar] [CrossRef]
- Wang, H.F.; Tsaur, R.C. Bicriteria variable selection in a fuzzy regression equation. Comput. Math. Appl. 2000, 40, 877–883. [Google Scholar] [CrossRef]
- Hong, D.H.; Song, J.K.; Do, H.Y. Fuzzy least-squares linear regression analysis using shape preserving operations. Inf. Sci. 2001, 138, 185–193. [Google Scholar] [CrossRef]
- Tanaka, H.; Lee, H. Fuzzy linear regression combining central tendency and possibilistic properties. In Proceedings of the 6th International Fuzzy Systems Conference, Barcelona, Spain, 5 July 2009; Volume 1. pp. 63–68. [Google Scholar]
- Modarres, M.; Nasrabadi, E.; Nasrabadi, M.M. Fuzzy linear regression analysis from the point of view risk. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2004, 12, 635–649. [Google Scholar] [CrossRef]
- Parvathi, R.; Malathi, C.; Akram, M.; Atanassov, K.T. Intuitionistic fuzzy linear regression analysis. Fuzzy Optim. Decis. Mak. 2013, 12, 215–229. [Google Scholar] [CrossRef]
- Sultan, A.; Sałabun, W.; Faizi, S.; Ismail, M. Hesitant Fuzzy linear regression model for decision making. Symmetry 2021, 13, 1846. [Google Scholar] [CrossRef]
- Bardossy, A. Note on fuzzy regression. Fuzzy Sets Syst. 1990, 37, 65–75. [Google Scholar] [CrossRef]
- Zadeh, L.A. Information and control. Fuzzy Sets 1965, 8, 338–353. [Google Scholar]
- Sahu, R.; Dash, S.R.; Das, S. Career selection of students using hybridized distance measure based on picture fuzzy set and rough set theory. Decis. Mak. Appl. Manag. Eng. 2021, 4, 104–126. [Google Scholar] [CrossRef]
- Gorcun, O.F.; Senthil, S.; Küçükönder, H. Evaluation of tanker vehicle selection using a novel hybrid fuzzy MCDM technique. Decis. Mak. Appl. Manag. Eng. 2021, 4, 140–162. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Zhu, B.; Xu, Z. Probability-hesitant fuzzy sets and the representation of preference relations. Technol. Econ. Dev. Econ. 2018, 24, 1029–1040. [Google Scholar] [CrossRef]
- Atanasov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Z.; Zhang, S.; Garg, H. Novel correlation coefficient between hesitant fuzzy sets with application to medical diagnosis. Expert Syst. Appl. 2021, 183, 115393. [Google Scholar] [CrossRef]
- Zeng, W.; Xi, Y.; Yin, Q.; Guo, P. Weighted dual hesitant fuzzy set and its application in group decision making. Neurocomputing 2021, 458, 714–726. [Google Scholar] [CrossRef]
- Yan, Y.; Wu, X.; Wu, Z. Bridge safety monitoring and evaluation based on hesitant fuzzy set. Alex. Eng. J. 2022, 61, 1183–1200. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, Z.; He, Y. Operations and integrations of probabilistic hesitant fuzzy information in decision making. Inf. Fusion 2017, 38, 1–11. [Google Scholar] [CrossRef]
- Gao, J.; Xu, Z.; Liao, H. A dynamic reference point method for emergency response under hesitant probabilistic fuzzy environment. Int. J. Fuzzy Syst. 2017, 19, 1261–1278. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.Q. An extended QUALIFLEX method under probability hesitant fuzzy environment for selecting green suppliers. Int. J. Fuzzy Syst. 2017, 19, 1866–1879. [Google Scholar] [CrossRef]
- Wu, Z.; Jin, B.; Xu, J. Local feedback strategy for consensus building with probability-hesitant fuzzy preference relations. Appl. Soft Comput. 2018, 67, 691–705. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; Agricultural Economics Review; Mcgraw Hill: New York, NY, USA, 1980; Volume 70. [Google Scholar]
- Rezaei, J. Best-worst multi-criteria decision-making method. Omega 2015, 53, 49–57. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Zavadskas, E.K.; Olfat, L.; Turskis, Z. Multi-criteria inventory classification using a new method of evaluation based on distance from average solution (EDAS). Informatica 2015, 26, 435–451. [Google Scholar] [CrossRef]
- Palczewski, K.; Sałabun, W. The fuzzy TOPSIS applications in the last decade. Procedia Comput. Sci. 2019, 159, 2294–2303. [Google Scholar] [CrossRef]
- Pamucar, D.; Žižović, M.; Biswas, S.; Božanić, D. A new logarithm methodology of additive weights (LMAW) for multi-criteria decision-making: Application in logistics. Facta Univ. Ser. Mech. Eng. 2021, 19, 361–380. [Google Scholar] [CrossRef]
- Pamucar, D.; Ecer, F. Prioritizing the weights of the evaluation criteria under fuzziness: The fuzzy full consistency method–FUCOM-F. Facta Univ. Ser. Mech. Eng. 2020, 18, 419–437. [Google Scholar] [CrossRef]
- Faizi, S.; Sałabun, W.; Ullah, S.; Rashid, T.; Więckowski, J. A new method to support decision-making in an uncertain environment based on normalized interval-valued triangular fuzzy numbers and comet technique. Symmetry 2020, 12, 516. [Google Scholar] [CrossRef] [Green Version]
- Faizi, S.; Rashid, T.; Sałabun, W.; Zafar, S.; Wątróbski, J. Decision making with uncertainty using hesitant fuzzy sets. Int. J. Fuzzy Syst. 2018, 20, 93–103. [Google Scholar] [CrossRef] [Green Version]
- Stanujkić, D.; Karabašević, D. An extension of the WASPAS method for decision-making problems with intuitionistic fuzzy numbers: A case of website evaluation. Oper. Res. Eng. Sci. Theory Appl. 2018, 1, 29–39. [Google Scholar] [CrossRef]
- Dezert, J.; Tchamova, A.; Han, D.; Tacnet, J.M. The SPOTIS rank reversal free method for multi-criteria decision-making support. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8. [Google Scholar]
- Shekhovtsov, A.; Kizielewicz, B.; Sałabun, W. New rank-reversal free approach to handle interval data in mcda problems. In Proceedings of the International Conference on Computational Science, Krakow, Poland, 16–18 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 458–472. [Google Scholar]
- Božanić, D.; Milić, A.; Tešić, D.; Salabun, W.; Pamučar, D. D numbers–FUCOM–fuzzy RAFSI model for selecting the group of construction machines for enabling mobility. Facta Univ. Ser. Mech. Eng. 2021, 19, 447–471. [Google Scholar] [CrossRef]
- Đalić, I.; Ateljević, J.; Stević, Ž.; Terzić, S. An integrated swot–fuzzy piprecia model for analysis of competitiveness in order to improve logistics performances. Facta Univ. Ser. Mech. Eng. 2020, 18, 439–451. [Google Scholar] [CrossRef]
- Li, Z.; Wei, G. Pythagorean fuzzy heronian mean operators in multiple attribute decision making and their application to supplier selection. Int. J. Knowl.-Based Intell. Eng. Syst. 2019, 23, 77–91. [Google Scholar] [CrossRef]
- Ashraf, A.; Ullah, K.; Hussain, A.; Bari, M. Interval-Valued Picture Fuzzy Maclaurin Symmetric Mean Operator with application in Multiple Attribute Decision-Making. Rep. Mech. Eng. 2022, 3, 301–317. [Google Scholar] [CrossRef]
- Wei, G.; Lu, M.; Gao, H. Picture fuzzy heronian mean aggregation operators in multiple attribute decision making. Int. J. Knowl.-Based Intell. Eng. Syst. 2018, 22, 167–175. [Google Scholar] [CrossRef]
- Karsak, E.E.; Sener, Z.; Dursun, M. Robot selection using a fuzzy regression-based decision-making approach. Int. J. Prod. Res. 2012, 50, 6826–6834. [Google Scholar] [CrossRef]
- Kim, K.J.; Moskowitz, H.; Koksalan, M. Fuzzy versus statistical linear regression. Eur. J. Oper. Res. 1996, 92, 417–434. [Google Scholar] [CrossRef]
- Chowdhury, A.K.; Debsarkar, A.; Chakrabarty, S. Novel methods for assessing urban air quality: Combined air and noise pollution approach. J. Atmos. Pollut. 2015, 3, 1–8. [Google Scholar]
- Sałabun, W.; Urbaniak, K. A new coefficient of rankings similarity in decision-making problems. In Proceedings of the International Conference on Computational Science, Amsterdam, The Netherlands, 3–5 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 632–645. [Google Scholar]


{kind=link}
{kind=link}
| 2 | ||||
| 6 | ||||
| 1 | ||||
| 8 | ||||
| 3 | ||||
| 5 | ||||
| 10 | ||||
| 9 | ||||
| 11 | ||||
| 7 | ||||
| 12 | ||||
| 4 |
| 2 | ||||
| 3 | ||||
| 1 | ||||
| 5 | ||||
| 4 | ||||
| 6 | ||||
| 8 | ||||
| 10 | ||||
| 11 | ||||
| 9 | ||||
| 12 | ||||
| 7 |
| 2 | 2 | 0 | |
| 3 | 6 | 9 | |
| 1 | 1 | 0 | |
| 5 | 8 | 9 | |
| 4 | 3 | 1 | |
| 6 | 5 | 1 | |
| 8 | 10 | 4 | |
| 10 | 9 | 1 | |
| 11 | 11 | 0 | |
| 9 | 7 | 4 | |
| 12 | 12 | 0 | |
| 7 | 4 | 9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultan, A.; Sałabun, W.; Faizi, S.; Ismail, M.; Shekhovtsov, A. Making Group Decisions within the Framework of a Probabilistic Hesitant Fuzzy Linear Regression Model. Sensors 2022, 22, 5736. https://doi.org/10.3390/s22155736
Sultan A, Sałabun W, Faizi S, Ismail M, Shekhovtsov A. Making Group Decisions within the Framework of a Probabilistic Hesitant Fuzzy Linear Regression Model. Sensors. 2022; 22(15):5736. https://doi.org/10.3390/s22155736
Chicago/Turabian StyleSultan, Ayesha, Wojciech Sałabun, Shahzad Faizi, Muhammad Ismail, and Andrii Shekhovtsov. 2022. "Making Group Decisions within the Framework of a Probabilistic Hesitant Fuzzy Linear Regression Model" Sensors 22, no. 15: 5736. https://doi.org/10.3390/s22155736
APA StyleSultan, A., Sałabun, W., Faizi, S., Ismail, M., & Shekhovtsov, A. (2022). Making Group Decisions within the Framework of a Probabilistic Hesitant Fuzzy Linear Regression Model. Sensors, 22(15), 5736. https://doi.org/10.3390/s22155736