
High-Speed Path Probing Method for Large-Scale Network


Abstract
1. Introduction
- The design and development of a large-scale network path probing tool. We used the tool to scan the worldwide network at 100 kpps in under an hour and found nearly 600,000 surviving addresses.
- An analysis of the main factors affecting the probing effect, which provides a basis for a reasonable parameter setting.
- An analysis of the effect of different probing packages on the probing effect.
2. Related Work
3. Approach to Design
3.1. Probing Packet Construction Approach Based on the Identification Field of the IP Packet and Identification Field of the ICMP Packet
3.2. Destination Address Sequence Generation Approach Based on the Inverse Binary Sequence
3.3. Bidirectional Path Probing Approach Based on the TTL Value Dynamic Update Strategy
- initTTL, initial TTL value, which means the TTL value of the initial probing for a certain destination.
- curTTL, current TTL value, which means the TTL value of the current probing for a certain destination.
- maxTTL, maximum TTL value, which means the maximum TTL value of the probing for a certain destination.
- rspTTL, response TTL value, which means the TTL value in the response packet.
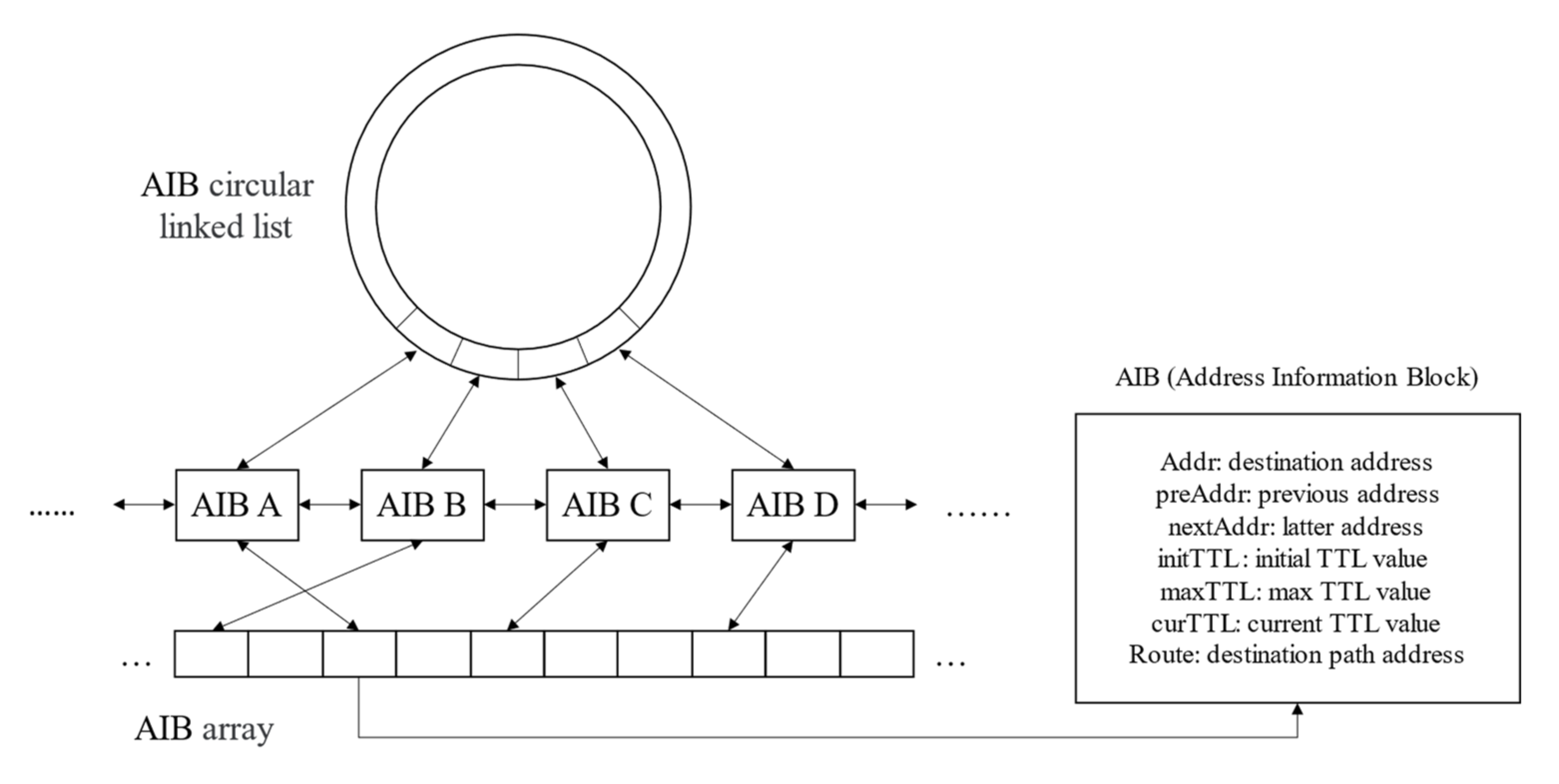
3.4. Design of Destination Storage Structure
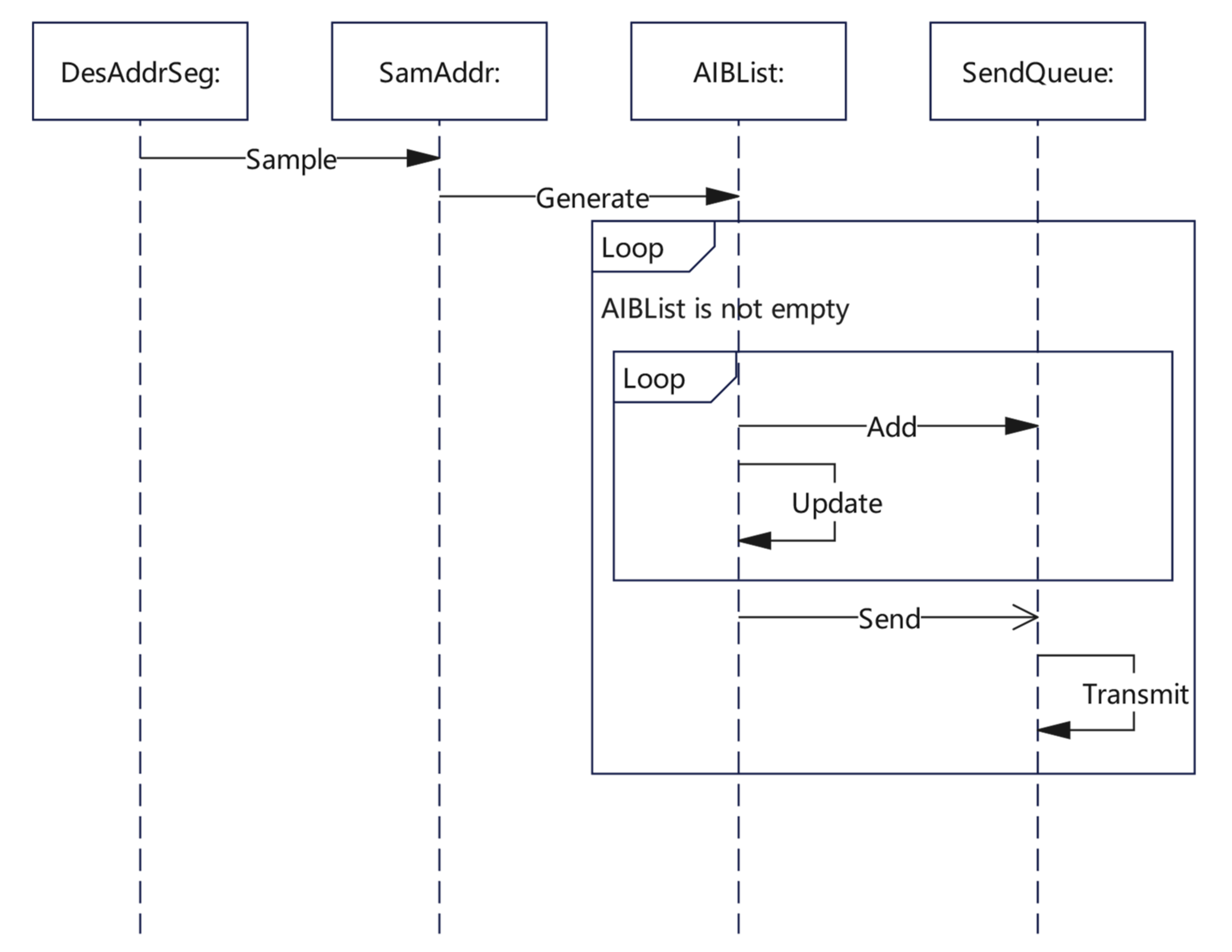
3.5. Algorithm Description
| Algorithm 1 Packet Sending Algorithm |
| Input: Destination address segment DesAddrSeg, Waiting time T. |
| Output: Part of the statistical information of the probing (the number of sending packages, the time of probing). |
| 1 Function SendThread(DesAddrSeg, T): |
| 2 SamAddr ← DesAddrSegs.Sample() |
| 3 AIBList ← new AIBList(SamAddr) |
| 4 SendQueue ← new SendQueue() |
| 5 SendCount ← 0 |
| 6 StartTime ← Time.Now() |
| 7 while not AIBList.empty() do |
| 8 for AIB in AIBList do |
| 9 packet ← GeneratePacket(AIB) |
| 10 SendQueue.Add(packet) |
| 11 AIB.Update() |
| 12 SendCount ← SendCount + 1 |
| 13 end for |
| 14 SendQueue.Transmit() |
| 15 Wait(T) |
| 16 end while |
| 17 EndTime ← Time.Now() |
| 18 ScanTime ← EndTime—StartTime |
| 19 return |
| 20 end Function |
| 21 |
| 22 Function Sample(this AddrSegs): |
| 23 for AddrSeg in AddrSegs: |
| 24 Addr ← random_address(AddrSeg) |
| 25 SamAddr.Add(Addr) |
| 26 end for |
| 27 return SamAddr |
| 28 end Function |
| 29 |
| 30 Function GeneratePacket(AIB): |
| 31 packet.IP.SrcAddr ← LocalIP |
| 32 packet.IP.DstAddr ← AIB.Addr |
| 33 packet.IP.Id ← AIB.curTTL |
| 34 packet.IP.TTL ← AIB.curTTL |
| 35 packet.ICMP.Id ← Hash(AIB.Addr) |
| 36 return packet |
| 37 end Function |
| 38 |
| 39 Function Update(this AIB): |
| 40 if AIB.curTTL == 1: |
| 41 AIB.curTTL ← AIB.initTTL + 1 |
| 42 else if AIB.curTTL == maxTTL: |
| 43 AIBList.Remove(AIB) |
| 44 else if AIB.curTTL ≤ AIB.initTTL: |
| 45 AIB.curTTL ← AIB.curTTL—1 |
| 46 else: |
| 47 AIB.curTTL ← AIB.curTTL + 1 |
| 48 end if |
| 49 return |
| 50 end Function |
| Algorithm 2 Packet Receiving Algorithm |
| Input: Timeout time T. |
| Output: Address information block array, part of the statistical information of the probing (the number of receiving packages, the number of discovered addresses). |
| 1 Function RecvThread(T): |
| 2 RecvQueue ← new RecvQueue() |
| 3 KeepListen() |
| 4 RecvCount ← 0 |
| 5 AddrSet ← new Set() |
| 6 while not RecvQueue.empty(T) do |
| 7 packet ← RecvQueue.pop() |
| 8 if not Check(packet) do |
| 9 continue |
| 10 end if |
| 11 Info ← packet.Resolve() |
| 12 AIBList.Update(Info) |
| 13 AddrSet.Add(Info.Addr) |
| 14 RecvCount ← RecvCount + 1 |
| 15 end while |
| 16 return |
| 17 end Function |
| 18 |
| 19 Function Check(packet): |
| 20 if not packet.IP.DstAddr == LocalAddr do |
| 21 return false |
| 22 else if not Hash(packet.IP.SrcAddr) == packet.ICMP.Id do |
| 23 return false |
| 24 else do |
| 25 return true |
| 26 end if |
| 27 end Function |
| 28 |
| 29 Function Resolve(this packet): |
| 30 Info.Addr ← packet.IP.SrcAddr |
| 31 Info.TTL ← packet.IP.Id |
| 32 Info.DstAddr ← packet.ICMP.Data.IP.DstAddr |
| 33 return Info |
| 34 end Function |
| 35 |
| 36 Function Update(this AIBList, Info): |
| 37 AIBList[Info.DstAddr].Route[Info.TTL] ← Info.Addr |
| 38 return |
| 39 end Function |
- , the maximum number of threads, set to 1000.
- , the average reply time considering the nonresponse case, set to 1 s.
- , the maximum network interface card (NIC) packet sending rate, determined by the hardware device, set to 10,000,000 packets per second.
- , bandwidth, determined by the network environment, set to 100 Mb per second.
- , the probe packet size, determined by the probe packet construction, set to 100 bits.
- , the processing interval time of the destination address, considered as a constant.
- , the average sending interval time of the probing source, considered as a constant.
- , the sending interval time of the probing source.
- , the ratio of probes with destination responses to the total number of probes.
- The case of anonymous routers was not considered, i.e., the destination address certainly responded to the probing packet as long as it satisfied the processing interval time requirement of the destination address.
- To maintain a high response ratio, the average sending interval time was greater than the processing interval time of the destination address i.e.,
4. Performance Evaluation
4.1. Tool Design and Implementation
4.2. Tool Validation and Analysis of Experimental Results
4.2.1. Coverage of the Test Network
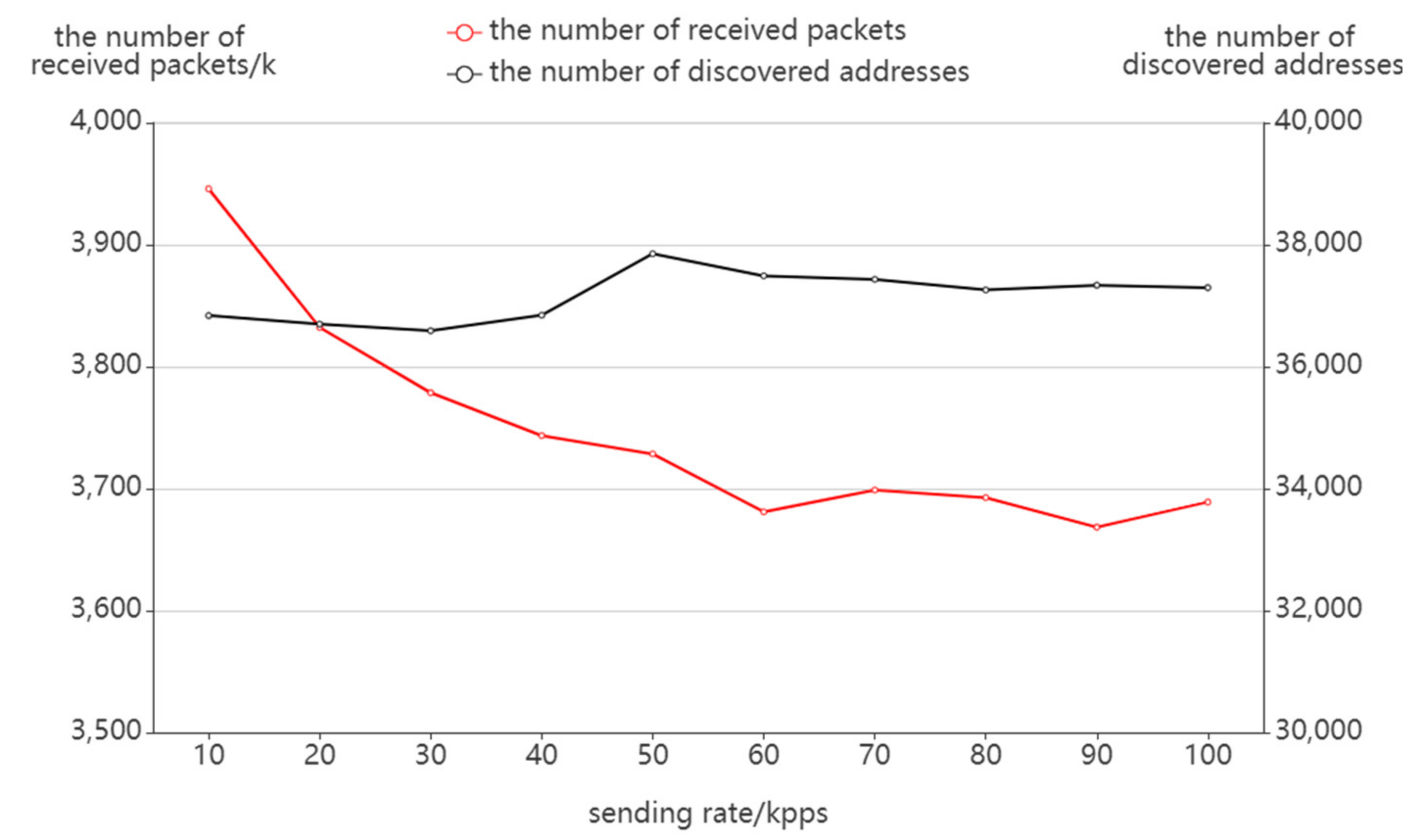
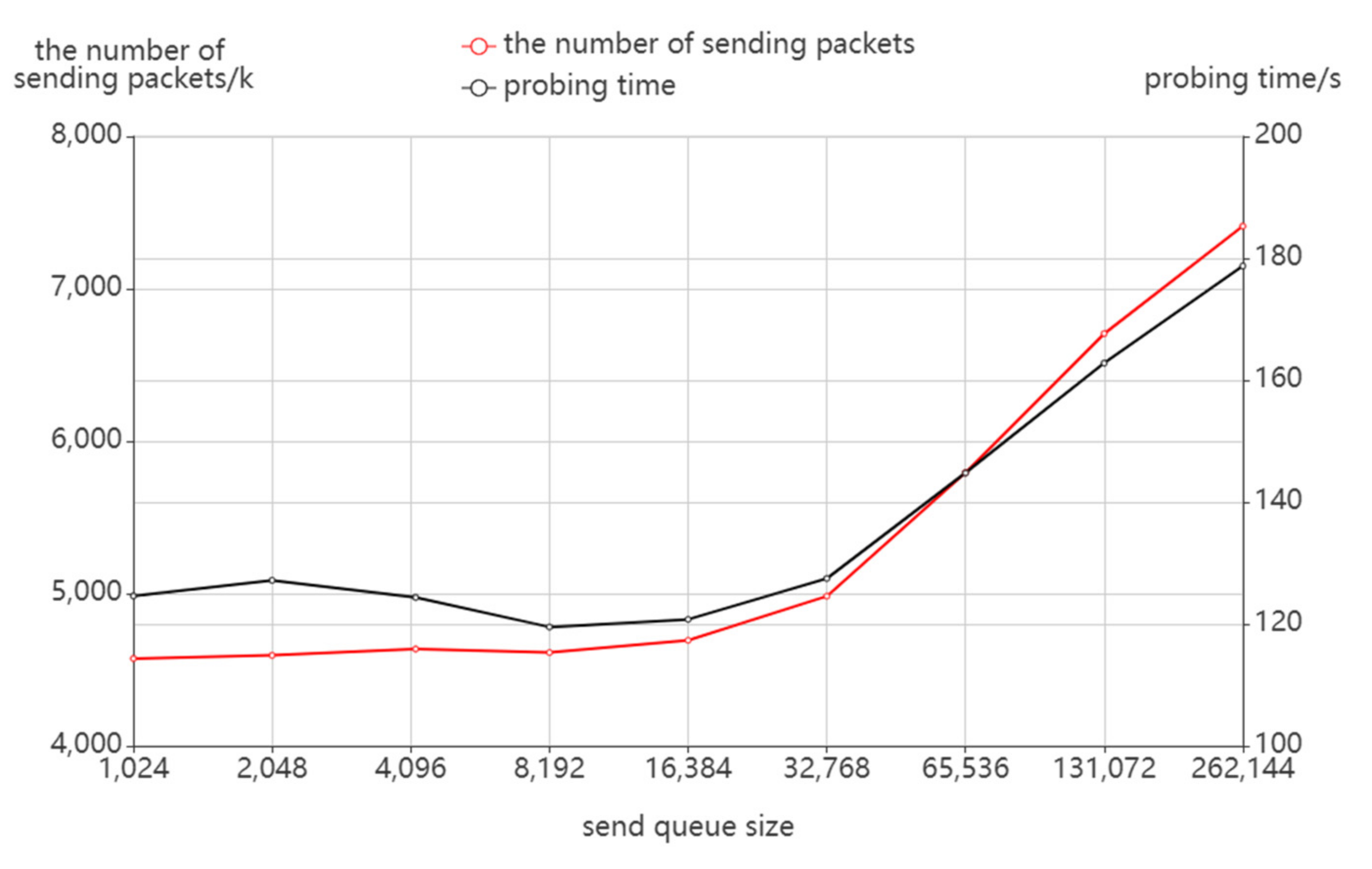
4.2.2. Possible Factors Affecting the Probing Effect
Sending Rate
maxTTL
Send Queue Size
4.2.3. Impact of Different Probing Packets on the Probing Effect
4.2.4. Comparison with Available Tools
4.2.5. Impact on the Network
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mao, G.; Anderson, B.D.O. Towards a better understanding of large-scale network models. IEEE/ACM Trans. Netw. 2011, 20, 408–421. [Google Scholar] [CrossRef]
- Richter, P.; Berger, A. Scanning the scanners: Sensing the internet from a massively distributed network telescope. In Proceedings of the Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 144–157. [Google Scholar]
- De Vaere, P.; Bühler, T.; Kühlewind, M.; Trammell, B. Three bits suffice: Explicit support for passive measurement of internet latency in quic and tcp. In Proceedings of the Internet Measurement Conference 2018, Boston, MA, USA, 31 October–2 November 2018; pp. 22–28. [Google Scholar]
- Fontugne, R.; Pelsser, C.; Aben, E.; Bush, R. Pinpointing delay and forwarding anomalies using large-scale traceroute measurements. In Proceedings of the 2017 Internet Measurement Conference, London, UK, 1–3 November 2017; pp. 15–28. [Google Scholar]
- Grailet, J.F.; Donnet, B. Travelling Without Moving: Discovering Neighborhood Adjacencies. In Proceedings of the Network Traffic Measurement and Analysis Conference, Online, 13–15 September 2021. [Google Scholar]
- Canbaz, M.A. Internet Topology Mining: From Big Data to Network Science. Ph.D. Thesis, University of Nevada, Reno, NV, USA, 2018. [Google Scholar]
- Wang, Z.; Li, Z.; Liu, G.; Chen, Y.; Wu, Q.; Cheng, G. Examination of WAN traffic characteristics in a large-scale data center network. In Proceedings of the 21st ACM Internet Measurement Conference, Online, 2–4 November 2021; pp. 1–14. [Google Scholar]
- Basat, R.B.; Einziger, G.; Gong, J.; Moraney, J.; Raz, D. q-MAX: A unified scheme for improving network measurement throughput. In Proceedings of the Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 322–336. [Google Scholar]
- Zolfaghari, H.; Mustafa, H.; Nurmi, J. Run-to-Completion versus Pipelined: The Case of 100 Gbps Packet Parsing. In Proceedings of the 2021 IEEE 22nd International Conference on High Performance Switching and Routing (HPSR), Paris, France, 7–10 June 2021; pp. 1–6. [Google Scholar]
- Gharaibeh, M.; Shah, A.; Huffaker, B.; Zhang, H.; Ensafi, R.; Papadopoulos, C. A look at router geolocation in public and commercial databases. In Proceedings of the 2017 Internet Measurement Conference, London, UK, 1–3 November 2017; pp. 463–469. [Google Scholar]
- Amjad, A.H.; Saleem, D.; Gulzar, M.A.; Shafiq, Z.; Zaffar, F. Trackersift: Untangling mixed tracking and functional web resources. In Proceedings of the 21st ACM Internet Measurement Conference, Online, 2–4 November 2021; pp. 569–576. [Google Scholar]
- Li, R.; Makhijani, K.; Dong, L. New ip: A data packet framework to evolve the internet. In Proceedings of the 2020 IEEE 21st International Conference on High Performance Switching and Routing (HPSR), Newark, NJ, USA, 11–14 May 2020; pp. 1–8. [Google Scholar]
- Ren, Y.; Liu, W.; Liu, A.; Wang, T.; Li, A. A privacy-protected intelligent crowdsourcing application of IoT based on the reinforcement learning. Future Gener. Comput. Syst. 2022, 127, 56–69. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, M.; Liu, X.; Xiong, N.; Liu, A.; Zhu, Y. Design and analysis of probing route to defense sink-hole attacks for Internet of Things security. IEEE Trans. Netw. Sci. Eng. 2018, 7, 356–372. [Google Scholar] [CrossRef]
- Giotsas, V.; Koch, T.; Fazzion, E.; Cunha, I.; Calder, M.; Madhyastha, H.V.; Katz-Bassett, E. Reduce, reuse, recycle: Repurposing existing measurements to identify stale traceroutes. In Proceedings of the ACM Internet Measurement Conference, Online, 27–29 October 2020; pp. 247–265. [Google Scholar]
- Wan, G.; Izhikevich, L.; Adrian, D.; Yoshioka, K.; Holz, R.; Rossow, C.; Durumeric, Z. On the origin of scanning: The impact of location on internet-wide scans. In Proceedings of the ACM Internet Measurement Conference, Online, 27–29 October 2020; pp. 662–679. [Google Scholar]
- Vermeulen, K.; Strowes, S.D.; Fourmaux, O.; Friedman, T. Multilevel MDA-lite Paris traceroute. In Proceedings of the Internet Measurement Conference 2018, Boston, MA, USA, 31 October–2 November 2018; pp. 29–42. [Google Scholar]
- Luckie, M. Scamper: A scalable and extensible packet prober for active measurement of the Internet. In Proceedings of the IMC ’10—10th ACM SIGCOMM Conference on Internet Measurement, Melbourne, Australia, 1–30 November 2010; pp. 239–245. [Google Scholar]
- Hyun, Y.; Claffy, C. Archipelago Measurement Infrastructure. 2021. Available online: http://www.caida.org/projects/ark/ (accessed on 20 April 2022).
- Durumeric, Z.; Wustrow, E.; Halderman, J.A. Zmap: Fast internet-wide scanning and its security applications. In Proceedings of the USENIX Security Symposium, Washington, DC, USA, 14–16 August 2013; pp. 605–620. [Google Scholar]
- Beverly, R. Yarrp’ing the Internet: Randomized high-speed active topology discovery. In Proceedings of the ACM SIGCOMM Internet Measurement Conference, Santa Monica, CA, USA, 14–16 November 2016; pp. 413–420. [Google Scholar]
- Huang, Y.; Rabinovich, M.; Al-Dalky, R. FlashRoute: Efficient Traceroute on a Massive Scale. In Proceedings of the ACM Internet Measurement Conference, Online, 27–29 October 2020; pp. 443–455. [Google Scholar]
- Donnet, B.; Raoult, P.; Friedman, T.; Crovella, M. Deployment of an algorithm for large-scale topology discovery. IEEE J. Sel. Areas Commun. 2006, 24, 2210–2220. [Google Scholar] [CrossRef]
- Tozal, M.E. Policy-preferred paths in AS-level Internet topology graphs. Theory Appl. Graphs 2018, 5, 3. [Google Scholar] [CrossRef]
- Ravaioli, R.; Urvoy-Keller, G.; Barakat, C. Characterizing ICMP rate limitation on routers. In Proceedings of the IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 6043–6049. [Google Scholar]
- University of Oregon RouteViews. 2022. Available online: http://www.routeviews.org/ (accessed on 20 April 2022).
- Partridge, C.; Allman, M. Ethical considerations in network measurement papers. Commun. ACM 2016, 59, 58–64. [Google Scholar] [CrossRef]
- Levchenko, K.; Dhamdhere, A.; Huffaker, B.; Claffy, K.; Allman, M.; Paxson, V. Packetlab: A universal measurement endpoint interface. In Proceedings of the 2017 Internet Measurement Conference, London, UK, 1–3 November 2017; pp. 254–260. [Google Scholar]
- Tusa, F.; Griffin, D.; Rio, M. Private Routing in the Internet. In Proceedings of the 2021 IEEE 22nd International Conference on High Performance Switching and Routing (HPSR), Paris, France, 7–10 June 2021; pp. 1–6. [Google Scholar]
- Spang, B.; Hannan, V.; Kunamalla, S.; Huang, T.Y.; McKeown, N.; Johari, R. Unbiased experiments in congested networks. In Proceedings of the 21st ACM Internet Measurement Conference, Online, 2–4 November 2021; pp. 80–95. [Google Scholar]
- Goßen, D.; Jonker, H.; Karsch, S. HLISA: Towards a more reliable measurement tool. In Proceedings of the 21st ACM Internet Measurement Conference, Online, 2–4 November 2021; pp. 380–389. [Google Scholar]
- Vermeulen, K.; Rohrer, J.P.; Beverly, R.; Friedman, T. Diamond-Miner: Comprehensive Discovery of the Internet’s Topology Diamonds. In Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI20), Santa Clara, CA, USA, 25–27 February 2020; pp. 479–493. [Google Scholar]
- Al Shinwan, M.; Abualigah, L.; Huy, T.D.; Shdefat, A.Y.; Altalhi, M.; Kim, C.; El-Sappagh, S.; Abd Elaziz, M.; Kwak, K.S. An efficient 5G data plan approach based on partially distributed mobility architecture. Sensors 2022, 22, 349. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | TTL Update Policy | |
|---|---|---|
| Remove destination address | ||
| Condition | TTL Update Policy | |
|---|---|---|
| TTL exceeded in transit | Destination address out of the stop set | Add the response address to the stop set |
| ICMP echo reply | Reset initTTL and curTTL | |
| , Reset initTTL and curTTL | ||
| Remove destination address | ||
| Packet | The Number of Sending Packages | The Number of Receiving Packages | Receiving and Sending Ratio | Probing Time (s) | DiscoveredAddresses |
|---|---|---|---|---|---|
| ICMP | 5,019,079 | 1,577,417 | 31.43% | 105.05 | 39,330 |
| UDP | 5,058,460 | 1,515,532 | 29.96% | 99.423 | 39,121 |
| TCP SYN | 5,393,412 | 1,009,524 | 18.72% | 102.188 | 38,310 |
| Approach | The Number of Sending Packages | The Number of Receiving Packages | Receiving and Sending Ratio | Probing Time (s) | DiscoveredAddresses |
|---|---|---|---|---|---|
| Yarrp | 8,735,440 | 1,930,020 | 22.09% | 249.04 | 37,990 |
| FlashRoute | 5,303,465 | 816,832 | 15.40% | 113 | 39,610 |
| Ours | 4,608,352 | 1,565,637 | 33.97% | 102.717 | 37,853 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Z.; Liu, J.; Yang, G.; Zhang, Y.; Hang, Z. High-Speed Path Probing Method for Large-Scale Network. Sensors 2022, 22, 5650. https://doi.org/10.3390/s22155650
Luo Z, Liu J, Yang G, Zhang Y, Hang Z. High-Speed Path Probing Method for Large-Scale Network. Sensors. 2022; 22(15):5650. https://doi.org/10.3390/s22155650
Chicago/Turabian StyleLuo, Zhihao, Jingju Liu, Guozheng Yang, Yongheng Zhang, and Zijun Hang. 2022. "High-Speed Path Probing Method for Large-Scale Network" Sensors 22, no. 15: 5650. https://doi.org/10.3390/s22155650
APA StyleLuo, Z., Liu, J., Yang, G., Zhang, Y., & Hang, Z. (2022). High-Speed Path Probing Method for Large-Scale Network. Sensors, 22(15), 5650. https://doi.org/10.3390/s22155650