
Efficient Multi-Scale Stereo-Matching Network Using Adaptive Cost Volume Filtering


Abstract
:1. Introduction
- We propose an efficient multi-scale stereo-matching network, MSFFNet, that connects multi-scale SFF modules in parallel and effectively generates a cost volume using the proposed interlaced cost concatenation method.
- We propose an adaptive cost-volume-filtering loss that adaptively filters the estimated cost volume using a ground truth disparity map and an accurate teacher network for direct supervision of the estimated cost volume.
2. Related Works
2.1. Efficient Stereo-Matching Networks
2.2. Cost Volume Filtering
3. Proposed Method
3.1. Feature Extractor
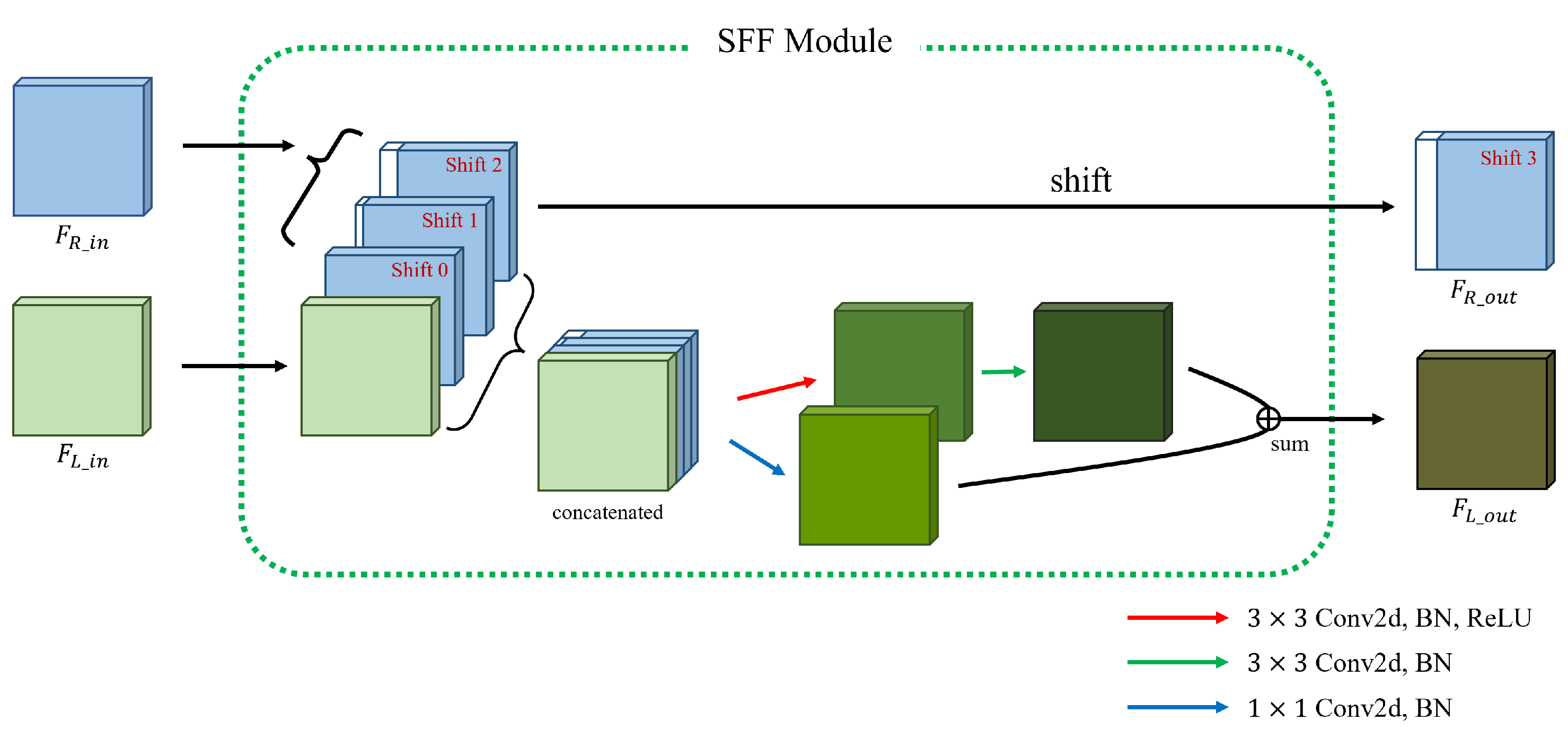
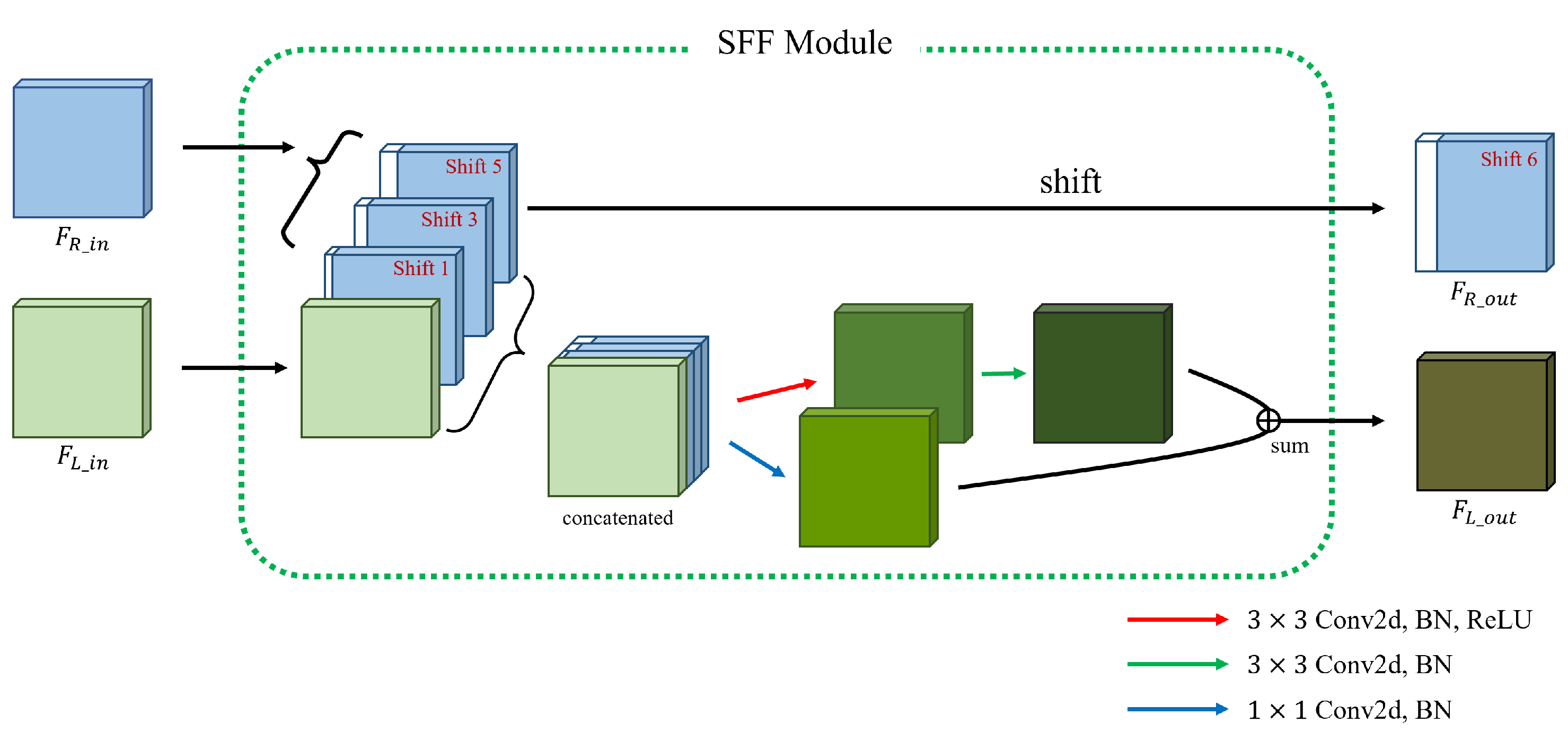
3.2. Cost Aggregation
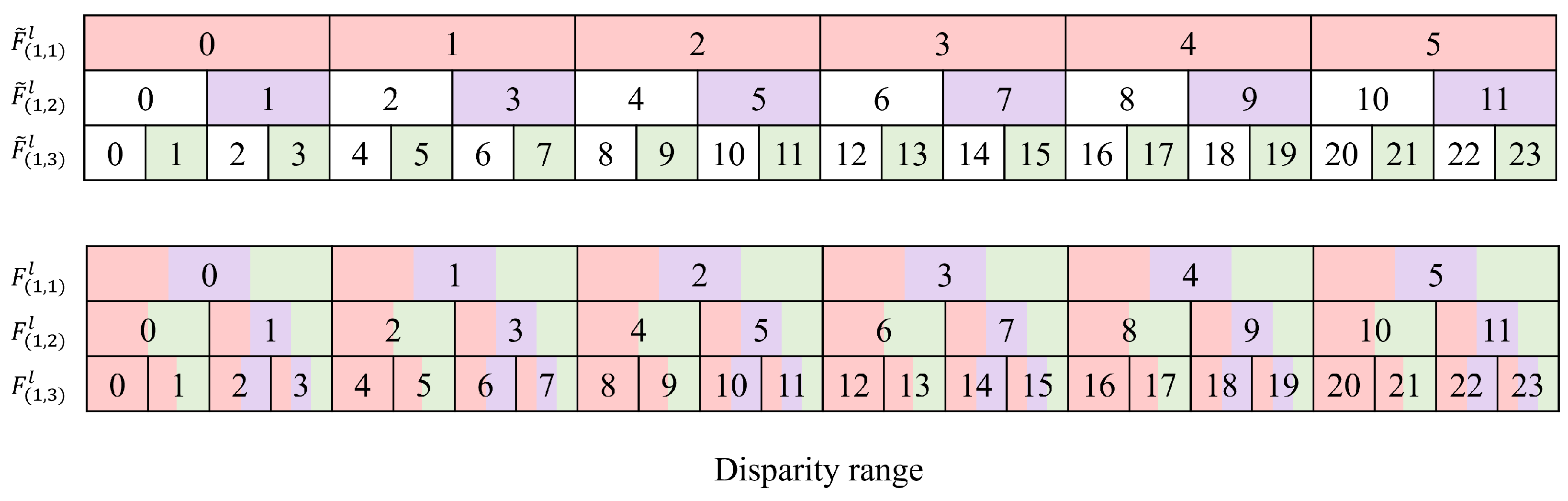
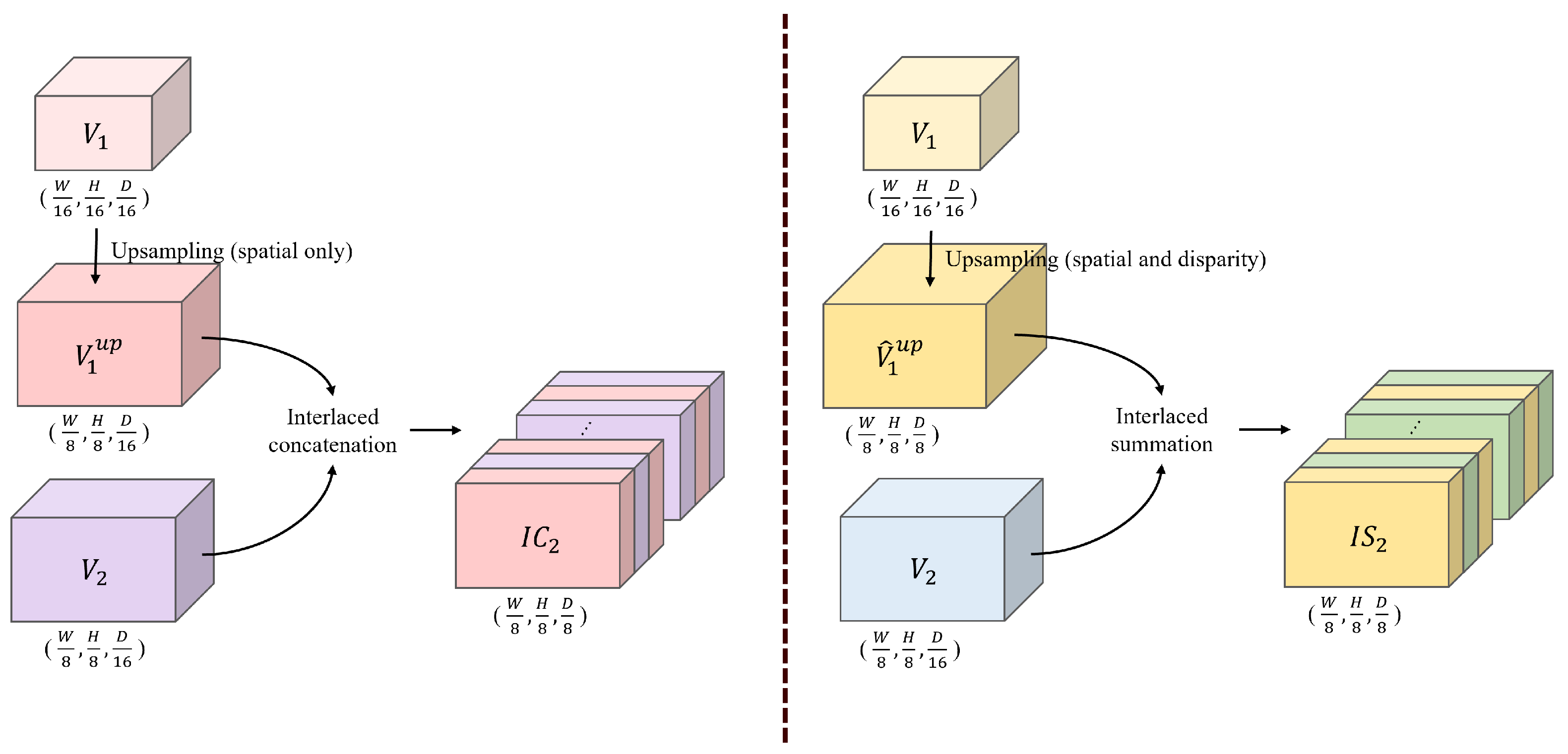
3.3. Interlaced Cost Volume
3.4. Disparity Regression and Refinement
3.5. Loss Function
3.5.1. Disparity Regression Loss
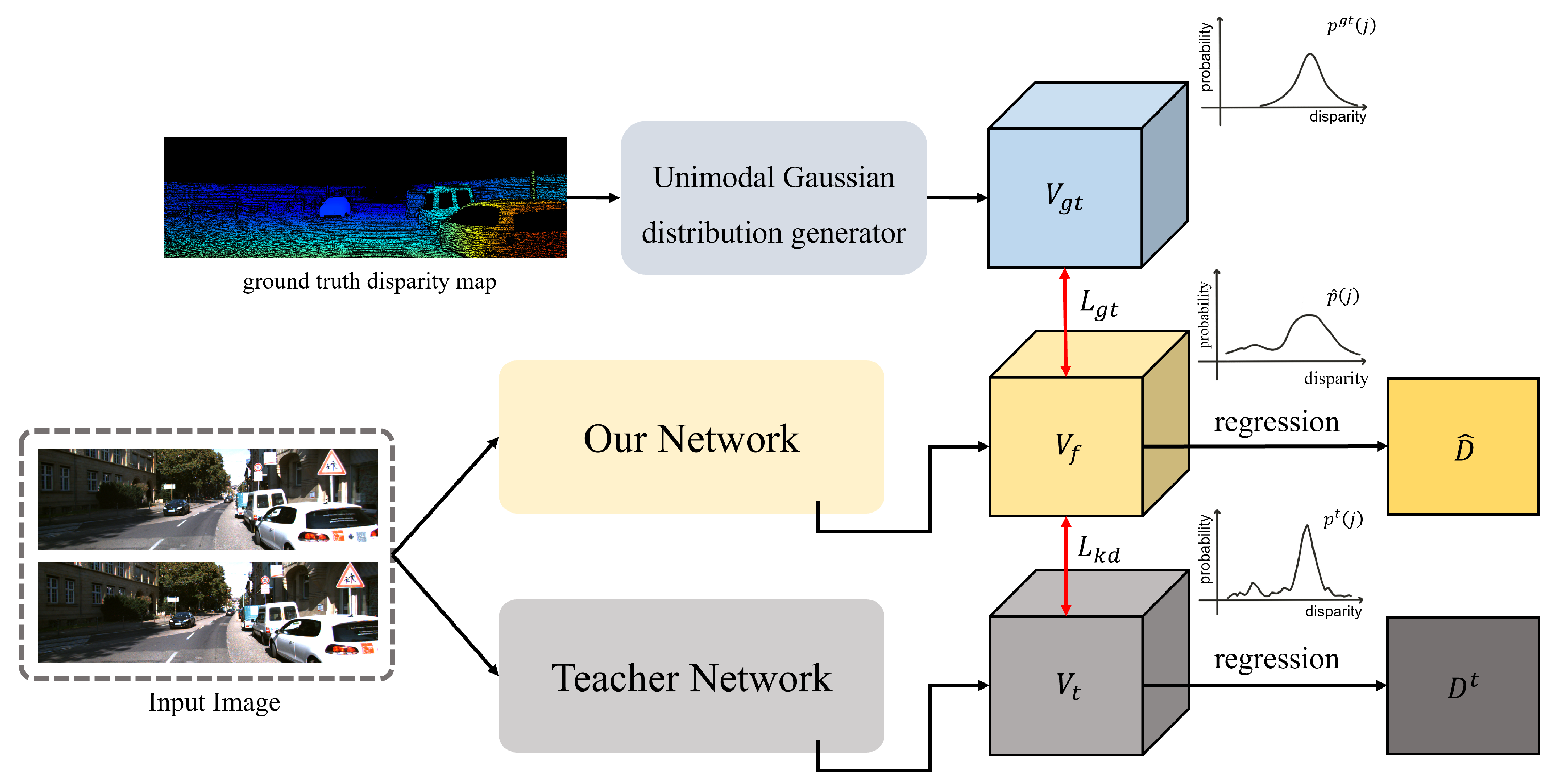
3.5.2. Adaptive Cost-Volume-Filtering Loss
Cost Volume Filtering Using Ground Truth Disparity
Cost Volume Filtering Using Knowledge Distillation
3.5.3. Total Loss Function
4. Experiments and Results
4.1. Datasets and Evaluation Metrics
- Scene Flow [10]: A large-scale synthetic dataset with dense ground truth disparity maps. It contains 35,454 training image pairs and 4370 test image pairs to train the network directly. The end point error (EPE), which is the average disparity error in pixels of the estimated disparity map, was used as an evaluation metric.
- KITTI: KITTI 2015 [25] and KITTI 2012 [29] are real-world datasets with outdoor views captured from a driving car. KITTI 2015 contains 200 training stereo image pairs with sparse ground truth disparity maps and 200 image pairs for testing. KITTI 2012 contains 194 training image pairs with sparse ground truth disparity maps and 195 testing image pairs. The 3-Pixel-Error (3PE), the percentage of pixels with a disparity error larger than three pixels, was used as an evaluation metric.
4.2. Implementation Details
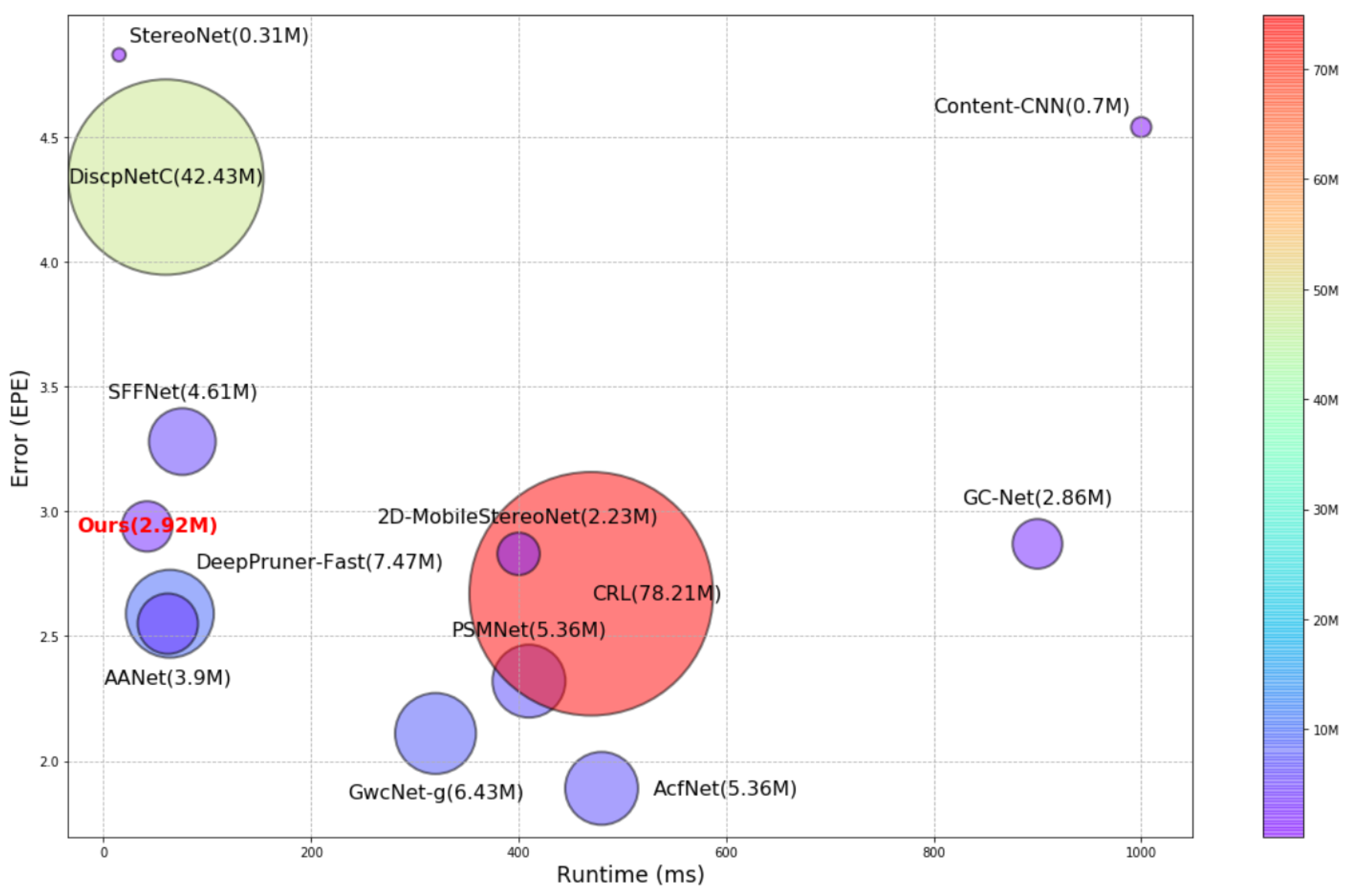
4.3. Comparative Result
4.3.1. Scene Flow Dataset
4.3.2. KITTI-2015 Dataset
4.4. Ablation Study
4.4.1. Effect of Interlaced Cost Concatenation
4.4.2. Effect of Adaptive Cost-Volume-Filtering Loss
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| SFF module | Sequential Feature Fusion module |
| SFFNet | Sequential Feature Fusion Network |
| MSFF module | Multi-scale Sequential Feature Fusion module |
| MSFFNet | Multi-scale Sequential Feature Fusion Network |
| ACVF | Adaptive Cost Volume Filtering |
| EPE | End Point Error |
| 3PE | 3-Pixel Error |
| FLOPs | FLoating point Operations Per Second |
References
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Huang, J.; Tang, S.; Liu, Q.; Tong, M. Stereo matching algorithm for autonomous positioning of underground mine robots. In Proceedings of the International Conference on Robots & Intelligent System, Changsha, China, 26–27 May 2018; pp. 40–43. [Google Scholar]
- Zenati, N.; Zerhouni, N. Dense stereo matching with application to augmented reality. In Proceedings of the IEEE International Conference on Signal Processing and Communications, Dubai, United Arab Emirates, 24–27 November 2007; pp. 1503–1506. [Google Scholar]
- El Jamiy, F.; Marsh, R. Distance estimation in virtual reality and augmented reality: A survey. In Proceedings of the IEEE International Conference on Electro Information Technology, Brookings, SD, USA, 20–22 May 2019; pp. 063–068. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Wong, A.; Mundhra, M.; Soatto, S. Stereopagnosia: Fooling stereo networks with adversarial perturbations. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2879–2888. [Google Scholar]
- Kwon, H.; Kim, Y. BlindNet backdoor: Attack on deep neural network using blind watermark. Multimed. Tools Appl. 2022, 81, 6217–6234. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo-matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Khamis, S.; Fanello, S.; Rhemann, C.; Kowdle, A.; Valentin, J.; Izadi, S. Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 573–590. [Google Scholar]
- Wang, Y.; Lai, Z.; Huang, G.; Wang, B.H.; Van Der Maaten, L.; Campbell, M.; Weinberger, K.Q. Anytime stereo image depth estimation on mobile devices. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5893–5900. [Google Scholar]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3273–3282. [Google Scholar]
- Xu, H.; Zhang, J. Aanet: Adaptive aggregation network for efficient stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1959–1968. [Google Scholar]
- Jeong, J.; Jeon, S.; Heo, Y.S. An Efficient stereo-matching network Using Sequential Feature Fusion. Electronics 2021, 10, 1045. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Bai, X.; Yu, S.; Yu, K.; Li, Z.; Yang, K. Adaptive unimodal cost volume filtering for deep stereo matching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12926–12934. [Google Scholar]
- Garg, D.; Wang, Y.; Hariharan, B.; Campbell, M.; Weinberger, K.Q.; Chao, W.L. Wasserstein distances for stereo disparity estimation. Adv. Neural Inf. Process. Syst. 2020, 33, 22517–22529. [Google Scholar]
- Yuan, L.; Tay, F.E.; Li, G.; Wang, T.; Feng, J. Revisiting Knowledge Distillation via Label Smoothing Regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3903–3911. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhou, H.; Song, L.; Chen, J.; Zhou, Y.; Wang, G.; Yuan, J.; Zhang, Q. Rethinking soft labels for knowledge distillation: A bias-variance tradeoff perspective. arXiv 2021, arXiv:2102.00650. [Google Scholar]
- Zhao, B.; Cui, Q.; Song, R.; Qiu, Y.; Liang, J. Decoupled Knowledge Distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; 2022; pp. 11953–11962. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Duggal, S.; Wang, S.; Ma, W.C.; Hu, R.; Urtasun, R. Deeppruner: Learning efficient stereo matching via differentiable patchmatch. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4384–4393. [Google Scholar]
- Pang, J.; Sun, W.; Ren, J.S.; Yang, C.; Yan, Q. Cascade Residual Learning: A Two-Stage Convolutional Neural Network for Stereo Matching. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 887–895. [Google Scholar]
- Shamsafar, F.; Woerz, S.; Rahim, R.; Zell, A. MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2417–2426. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Shen, Z.; Dai, Y.; Rao, Z. Msmd-net: Deep stereo matching with multi-scale and multi-dimension cost volume. arXiv 2020, arXiv:2006.12797. [Google Scholar]
- Gao, Q.; Zhou, Y.; Li, G.; Tong, T. Compact StereoNet: Stereo Disparity Estimation via Knowledge Distillation and Compact Feature Extractor. IEEE Access 2020, 8, 192141–192154. [Google Scholar] [CrossRef]
- Mao, Y.; Liu, Z.; Li, W.; Dai, Y.; Wang, Q.; Kim, Y.T.; Lee, H.S. UASNet: Uncertainty Adaptive Sampling Network for Deep Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6311–6319. [Google Scholar]
- Liang, Z.; Feng, Y.; Guo, Y.; Liu, H.; Chen, W.; Qiao, L.; Zhou, L.; Zhang, J. Learning for disparity estimation through feature constancy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2811–2820. [Google Scholar]
- Yang, G.; Zhao, H.; Shi, J.; Deng, Z.; Jia, J. Segstereo: Exploiting semantic information for disparity estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 636–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. Ga-net: Guided aggregation net for end-to-end stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 185–194. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Cost Volume | Architecture | Cost Volume Filtering | Dataset |
|---|---|---|---|---|
| MC-CNN [8] | 4D | Single scale | X | KITTI |
| DispNetC [10] | 3D | Single scale | X | Scene Flow, KITTI |
| PSMNet [12] | 4D | Single scale | X | Scene Flow, KITTI |
| AnyNet [14] | 4D | Multi scale | X | Scene Flow, KITTI |
| Sequential | ||||
| AANet [16] | 4D | Multi scale | X | Scene Flow, KITTI |
| Parallel | ||||
| Msmd-net [30] | 4D | Multi scale | X | Scene Flow, KITTI |
| Parallel | ||||
| CompactStereoNet [31] | 4D | Multi scale | X | Scene Flow, KITTI |
| Sequential | ||||
| UASNet [32] | 4D | Multi scale | X | Scene Flow, KITTI |
| Sequential | ||||
| SFFNet [17] | 3D | Single scale | X | Scene Flow, KITTI |
| AcfNet [18] | 4D | Single scale | O | Scene Flow, KITTI |
| CDN [19] | 4D | Single scale | O | Scene Flow, KITTI |
| 2D-MobileStereoNet [28] | 4D | Single scale | X | Scene Flow, KITTI |
| 3D Conv. Models | 2D Conv. Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSMNet [12] | StereoNet [13] | Gwc-Net [15] | DeepPruner-Fast [26] | AANet [16] | AcfNet [18] | DispNet-C [10] | CRL [27] | SFFNet [17] | 2D-MobileStereoNet [28] | Ours |
| 1.09 | 1.10 | 0.79 | 0.97 | 0.87 | 0.92 | 1.68 | 1.32 | 1.04 | 1.14 | 1.01 |
| Method | Network | Runtime | Noc (%) | All (%) | Params | FLOPs | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| bg | fg | All | bg | fg | All | |||||
| 3D conv. method | Content-CNN [9] | 1000 ms | 3.32 | 7.44 | 4.00 | 3.73 | 8.58 | 4.54 | 0.70 M | 978.19 G |
| MC-CNN [8] | 67,000 ms | 2.48 | 7.64 | 3.33 | 2.89 | 8.88 | 3.89 | 0.15 M | 526.28 G | |
| GC-Net [11] | 900 ms | 2.02 | 3.12 | 2.45 | 2.21 | 6.16 | 2.87 | 2.86 M | 2510.96 G | |
| PSMNet [12] | 410 ms | 1.71 | 4.31 | 2.14 | 1.86 | 4.62 | 2.32 | 5.36 M | 761.57 G | |
| StereoNet [13] | 15 ms | - | - | - | 4.30 | 7.45 | 4.83 | 0.31 M | - | |
| GwcNet-g [15] | 320 ms | 1.61 | 3.49 | 1.92 | 1.74 | 3.93 | 2.11 | 6.43 M | - | |
| GANet-15 [39] | 1500 ms | 1.40 | 3.37 | 1.73 | 1.55 | 3.82 | 1.93 | - | - | |
| DeepPruner-Best [26] | 182 ms | 1.71 | 3.18 | 1.95 | 1.87 | 3.56 | 2.15 | 7.39 M | 383.49 G | |
| DeepPruner-Fast [26] | 64 ms | 2.13 | 3.43 | 2.35 | 2.32 | 3.91 | 2.59 | 7.47 M | 153.77 G | |
| AANet [16] | 62 ms | 1.80 | 4.93 | 2.32 | 1.99 | 5.39 | 2.55 | 3.9 M | - | |
| AcfNet [18] | 480 ms | 1.36 | 3.49 | 1.72 | 1.51 | 3.80 | 1.89 | 5.36 M | - | |
| 2D conv. method | DispNetC [10] | 60 ms | 4.11 | 3.72 | 4.05 | 4.32 | 4.41 | 4.34 | 42.43 M | 93.46 G |
| CRL [27] | 470 ms | 2.32 | 3.68 | 2.38 | 2.48 | 3.59 | 2.67 | 78.21 M | 185.85 G | |
| SFFNet [17] | 76 ms | 2.50 | 5.44 | 2.99 | 2.69 | 6.23 | 3.28 | 4.61 M | 208.21 G | |
| 2D-MobileStereoNet [28] | 400 ms | 2.29 | 3.81 | 2.54 | 2.49 | 4.53 | 2.83 | 2.23 M | 125.58 G | |
| Ours | 42 ms | 2.35 | 4.58 | 2.72 | 2.53 | 4. 99 | 2.94 | 2.92 M | 97.96 G | |
| Network Architecture | Adaptive Cost Volume Filtering | EPE | ||
|---|---|---|---|---|
| Concatenation | Summation | |||
| ✓ | 1.174 | |||
| ✓ | 1.098 | |||
| ✓ | ✓ | 1.04 | ||
| ✓ | ✓ | 1.043 | ||
| ✓ | ✓ | ✓ | 1.011 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, S.; Heo, Y.S. Efficient Multi-Scale Stereo-Matching Network Using Adaptive Cost Volume Filtering. Sensors 2022, 22, 5500. https://doi.org/10.3390/s22155500
Jeon S, Heo YS. Efficient Multi-Scale Stereo-Matching Network Using Adaptive Cost Volume Filtering. Sensors. 2022; 22(15):5500. https://doi.org/10.3390/s22155500
Chicago/Turabian StyleJeon, Suyeon, and Yong Seok Heo. 2022. "Efficient Multi-Scale Stereo-Matching Network Using Adaptive Cost Volume Filtering" Sensors 22, no. 15: 5500. https://doi.org/10.3390/s22155500
APA StyleJeon, S., & Heo, Y. S. (2022). Efficient Multi-Scale Stereo-Matching Network Using Adaptive Cost Volume Filtering. Sensors, 22(15), 5500. https://doi.org/10.3390/s22155500