
A Lightweight Subgraph-Based Deep Learning Approach for Fall Recognition


Abstract
:1. Introduction
- (1)
- Based on the skeleton data, we propose an end-to-end lightweight subgraph-based deep learning method that achieves better recognition accuracy while ensuring a lower number of parameters.
- (2)
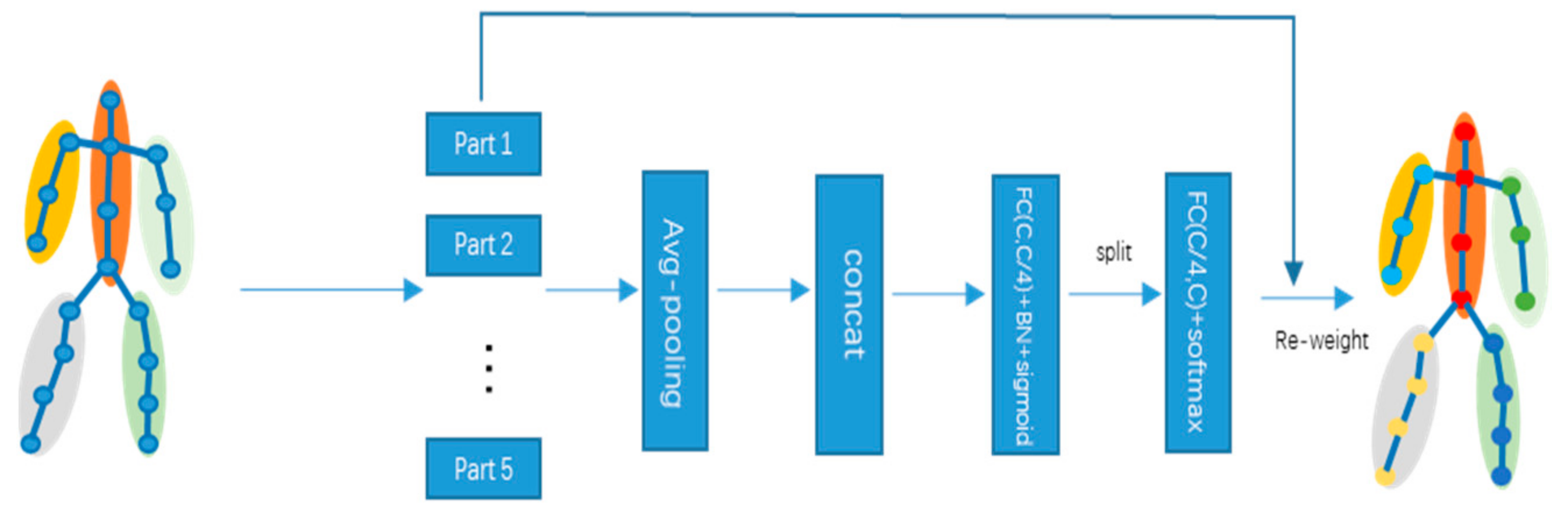
- A sub-graph division model is introduced, and a subgraph-based attention module is embedded to achieve better feature representation capability for fall behavior.
- (3)
- A multi-scale temporal convolution module is introduced in our model to enhance temporal feature representation.
- (4)
- A total of six categories of falls and behaviors similar to falls are collected in the NTU [5] dataset, and skeleton extraction was performed using OpenPose on two publicly available fall behavior datasets, i.e., UR Fall Detection Dataset [6] and UP-Fall detection dataset [7]. The model is validated in these three datasets.
2. Related Work
2.1. Skeleton-Based Action Recognition
2.2. Subgraph-Based Methods
2.3. Fall Recognition
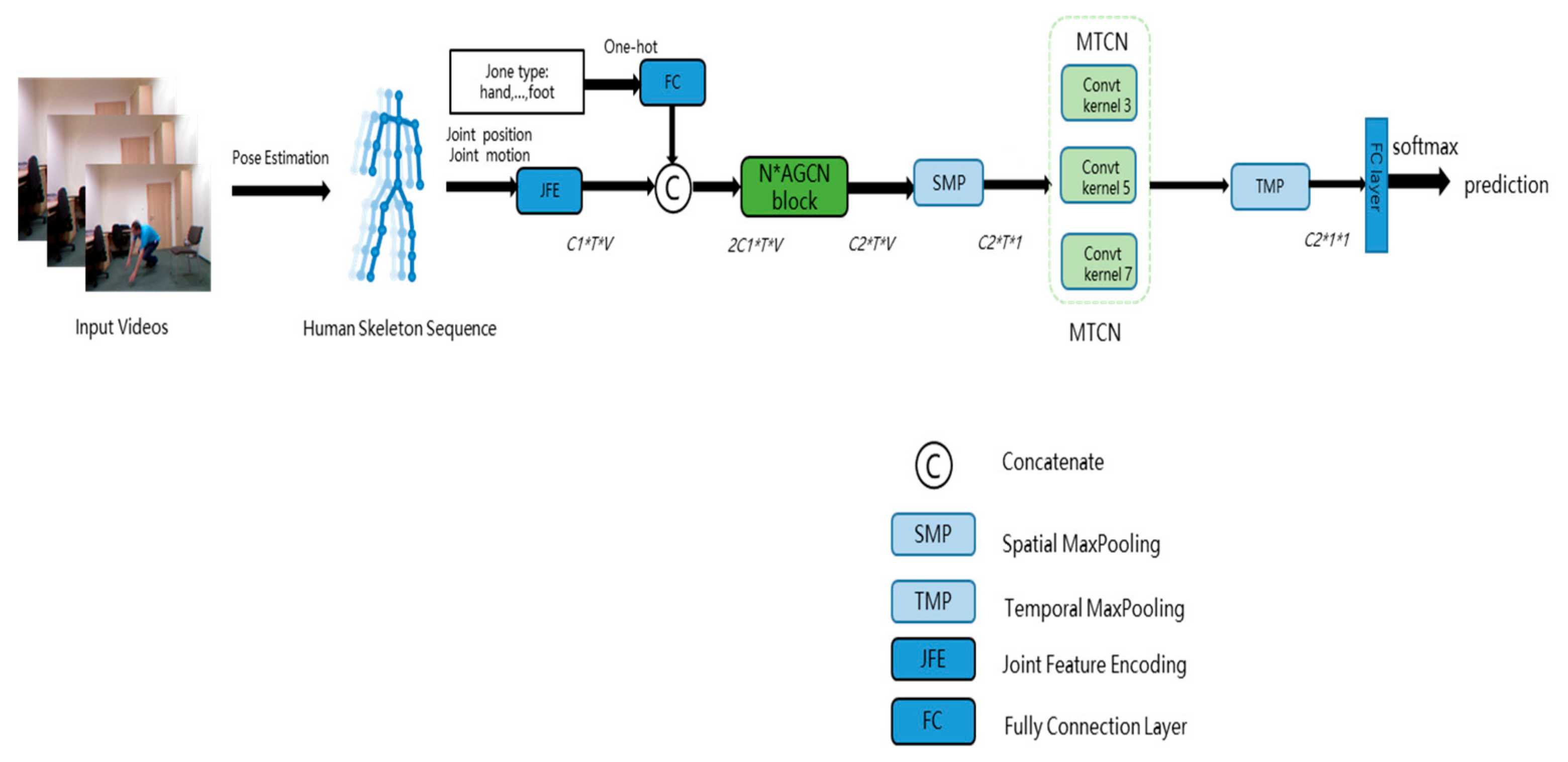
3. Method
3.1. Feature Encoding
3.2. Adaptive Graph Convolution Networks
3.3. Multi-Scale Temporal Convolution Network (MTCN)
4. Experiments
4.1. Datasets and Evaluation Measures
4.2. Implementation Details
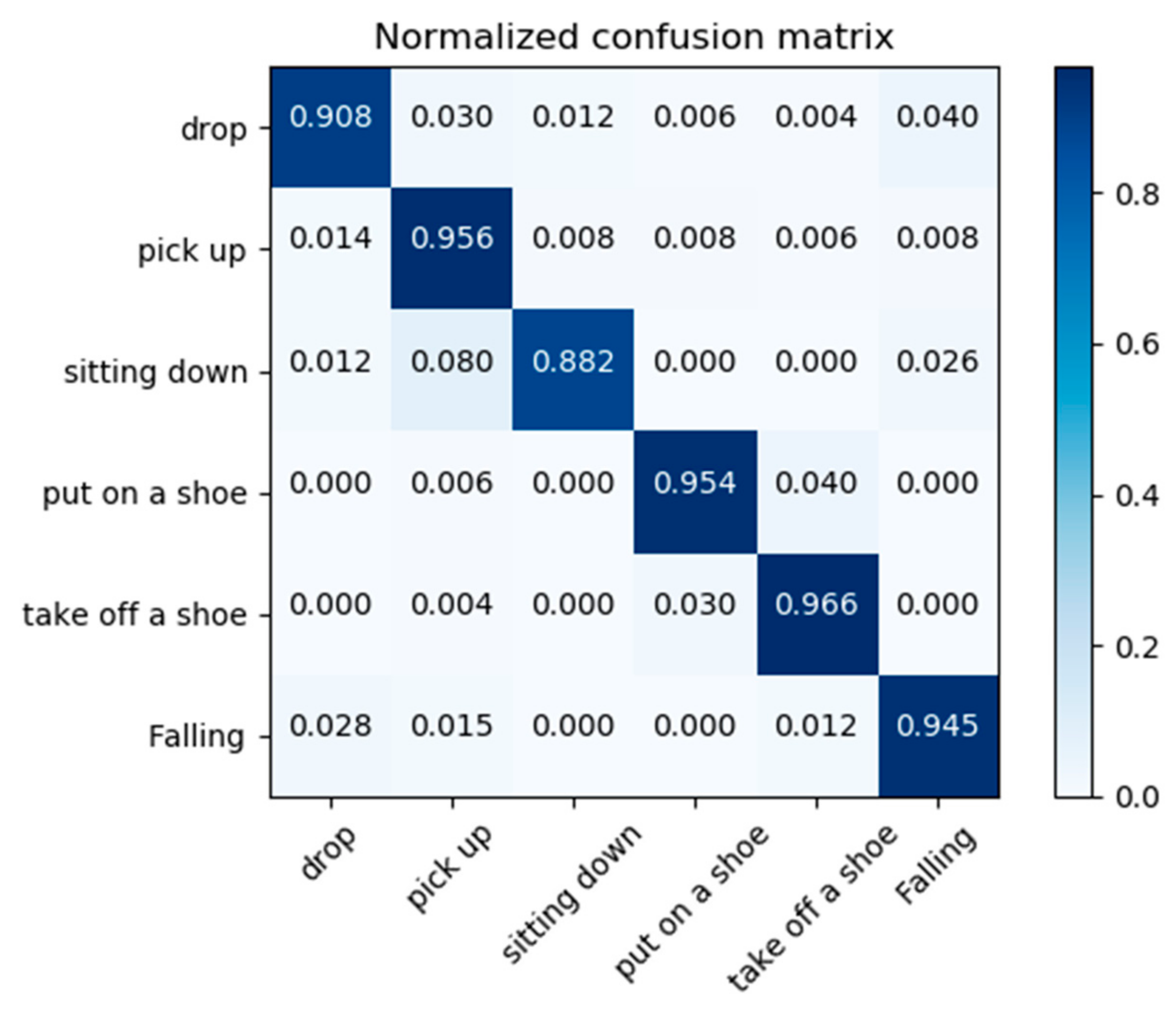
4.3. Results’ Comparison
4.4. Ablation Study
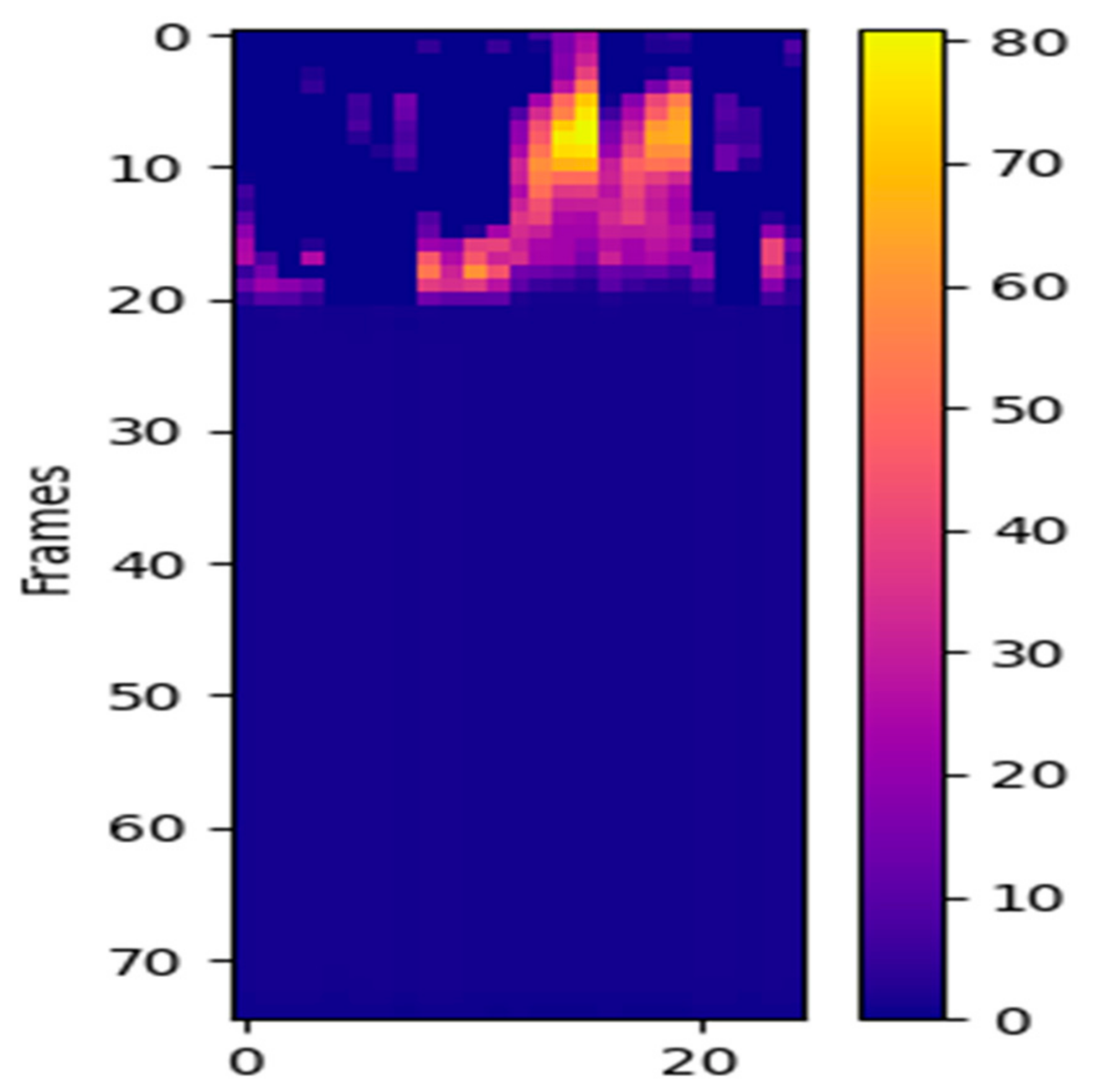
4.5. Visualization
4.6. Time and Memory Cost Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Christiansen, T.L.; Lipsitz, S.; Scanlan, M.; Yu, S.P.; Lindros, M.E.; Leung, W.Y.; Adelman, J.; Bates, D.W.; Dykes, P.C. Patient activation related to fall prevention: A multisite study. Jt. Comm. J. Qual. Patient Saf. 2020, 46, 129–135. [Google Scholar] [CrossRef] [PubMed]
- World Population Ageing 2020 Highlights-the United Nations. Available online: https://www.un.org/development/desa/pd/sites/www.un.org.development.desa.pd/files/undesa_pd-2020_world_population_ageing_highlights.pdf (accessed on 29 October 2021).
- Alam, E.; Sufian, A.; Dutta, P.; Leo, M. Vision-based human fall detection systems using deep learning: A review. Comput. Biol. Med. 2022, 146, 105626. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 July 2016; pp. 1010–1019. [Google Scholar]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-fall detection dataset: A multimodal approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Ali, H.; Van der Smagt, P. Two-stream RNN/CNN for action recognition in 3D videos. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4260–4267. [Google Scholar]
- Li, W.; Wen, L.; Chang, M.C.; Nam Lim, S.; Lyu, S. Adaptive RNN tree for large-scale human action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1444–1452. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar]
- Lev, G.; Sadeh, G.; Klein, B.; Wolf, L. Rnn fisher vectors for action recognition and image annotation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 833–850. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055. [Google Scholar]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 499–508. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 14–19 June 2020; pp. 183–192. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, virtual, 14–19 June 2020; pp. 143–152. [Google Scholar]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 14–19 June 2020; pp. 1112–1121. [Google Scholar]
- Thakkar, K.; Narayanan, P.J. Part-based graph convolutional network for action recognition. arXiv 2018, arXiv:1809.04983. [Google Scholar]
- Huang, L.; Huang, Y.; Ouyang, W.; Wang, L. Part-level graph convolutional network for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11045–11052. [Google Scholar]
- Mubashir, M.; Shao, L.; Seed, L. A survey on fall detection: Principles and approaches. Neurocomputing 2013, 100, 144–152. [Google Scholar] [CrossRef]
- Rathi, N.; Kakani, M.; El-Sharkawy, M.; Rizkalla, M. Wearable low power pre-fall detection system with IoT and bluetooth capabilities. In Proceedings of the 2017 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 27–30 June 2017; pp. 241–244. [Google Scholar]
- Hossain, F.; Ali, M.L.; Islam, M.Z.; Mustafa, H. A direction-sensitive fall detection system using single 3D accelerometer and learning classifier. In Proceedings of the 2016 International Conference on Medical Engineering, Health Informatics and Technology (MediTec), Dhaka, Bangladesh, 17–18 December 2016; pp. 1–6. [Google Scholar]
- Wu, F.; Zhao, H.; Zhao, Y.; Zhong, H. Development of a wearable-sensor-based fall detection system. Int. J. Telemed. Appl. 2015, 2015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bourke, A.K.; Lyons, G.M. A threshold-based fall-detection algorithm using a bi-axial gyroscope sensor. Med. Eng. Phys. 2008, 30, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Schwickert, L.; Becker, C.; Lindemann, U.; Maréchal, C.; Bourke, A.; Chiari, L.; Klenk, J. Fall detection with body-worn sensors. Z. Für Gerontol. Und Geriatr. 2013, 46, 706–719. [Google Scholar] [CrossRef] [PubMed]
- Yazar, A.; Çetin, A.E. Ambient assisted smart home design using vibration and PIR sensors. In Proceedings of the 2013 21st Signal Processing and Communications Applications Conference (SIU), Haspolat, Turkey, 24–26 April 2013; pp. 1–4. [Google Scholar]
- Arshad, A.; Khan, S.; Alam, A.Z.; Kadir, K.A.; Tasnim, R.; Ismail, A.F. A capacitive proximity sensing for human motion detection. In Proceedings of the 2017 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Torino, Italy, 22–25 May 2017; pp. 1–5. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7912–7921. [Google Scholar]
- Yun, Y.; Gu, I.Y.H. Human fall detection via shape analysis on Riemannian manifolds with applications to elderly care. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3280–3284. [Google Scholar]
- Harrou, F.; Zerrouki, N.; Sun, Y.; Houacine, A. Vision-based fall detection system for improving safety of elderly people. IEEE Instrum. Meas. Mag. 2017, 20, 49–55. [Google Scholar] [CrossRef] [Green Version]
- Bhandari, S.; Babar, N.; Gupta, P.; Shah, N.; Pujari, S. A novel approach for fall detection in home environment. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Las Vegas, NV, USA, 24–27 October 2017; pp. 1–5. [Google Scholar]
- Núñez-Marcos, A.; Azkune, G. Arganda-Carreras I. Vision-based fall detection with convolutional neural networks. Wirel. Commun. Mob. Comput. 2017, 2017. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Gao, C.; Wang, L.; Zhao, Y.; Song, T.; Li, Q. Spatio-temporal fall event detection in complex scenes using attention guided LSTM. Pattern Recognit. Lett. 2020, 130, 242–249. [Google Scholar] [CrossRef]
- Espinosa, R.; Ponce, H.; Gutiérrez, S.; Martínez-Villaseñor, L.; Brieva, J.; Moya-Albor, E. A vision-based approach for fall detection using multiple cameras and convolutional neural networks: A case study using the UP-Fall detection dataset. Comput. Biol. Med. 2019, 115, 103520. [Google Scholar] [CrossRef] [PubMed]
- Espinosa, R.; Ponce, H.; Gutiérrez, S.; Martínez-Villaseñor, L.; Brieva, J.; Moya-Albor, E. Application of convolutional neural networks for fall detection using multiple cameras. In Challenges and Trends in Multimodal Fall Detection for Healthcare; Springer: Cham, Switzerland, 2020; pp. 97–120. [Google Scholar]
- Ramirez, H.; Velastin, S.A.; Meza, I.; Fabregas, E.; Makris, D.; Farias, G. Fall detection and activity recognition using human skeleton features. IEEE Access 2021, 9, 33532–33542. [Google Scholar] [CrossRef]
- Inturi, A.R.; Manikandan, V.M.; Garrapally, V. A Novel Vision-Based Fall Detection Scheme Using Keypoints of Human Skeleton with Long Short-Term Memory Network. Arab. J. Sci. Eng. 2022, 1–13. [Google Scholar] [CrossRef]


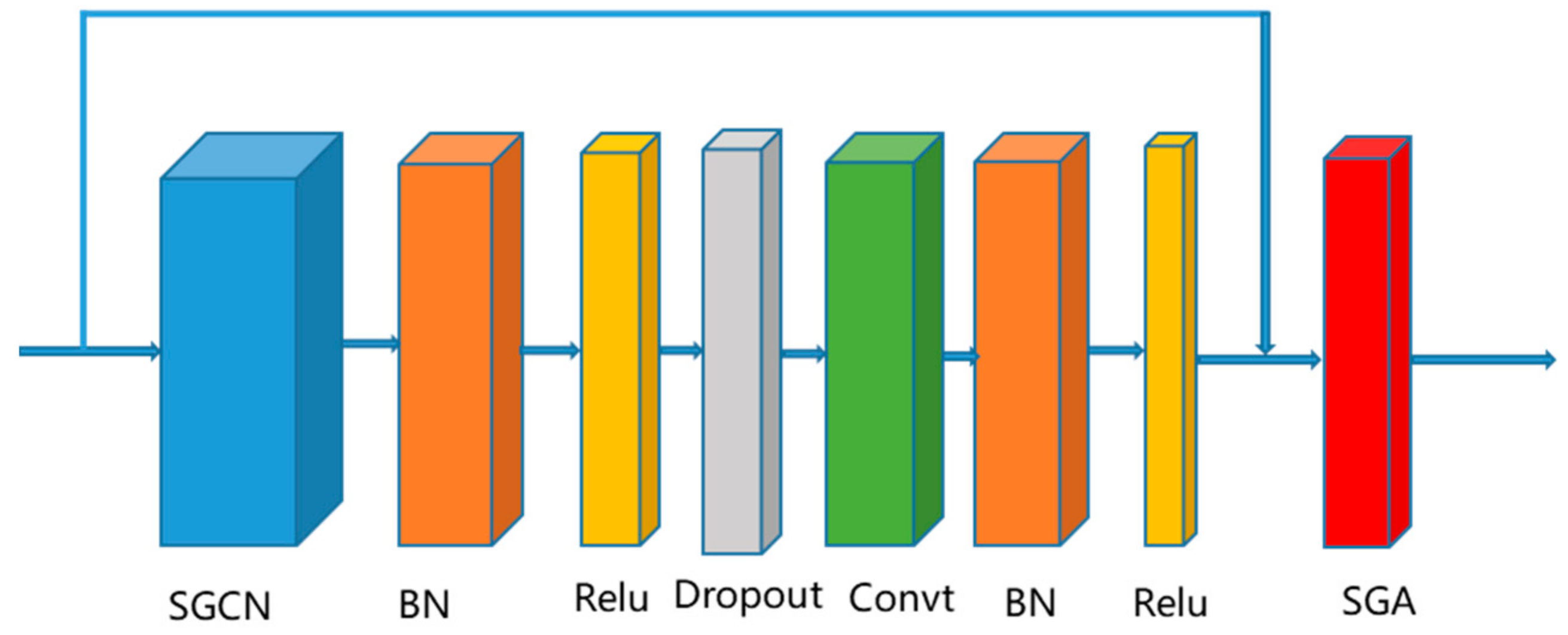



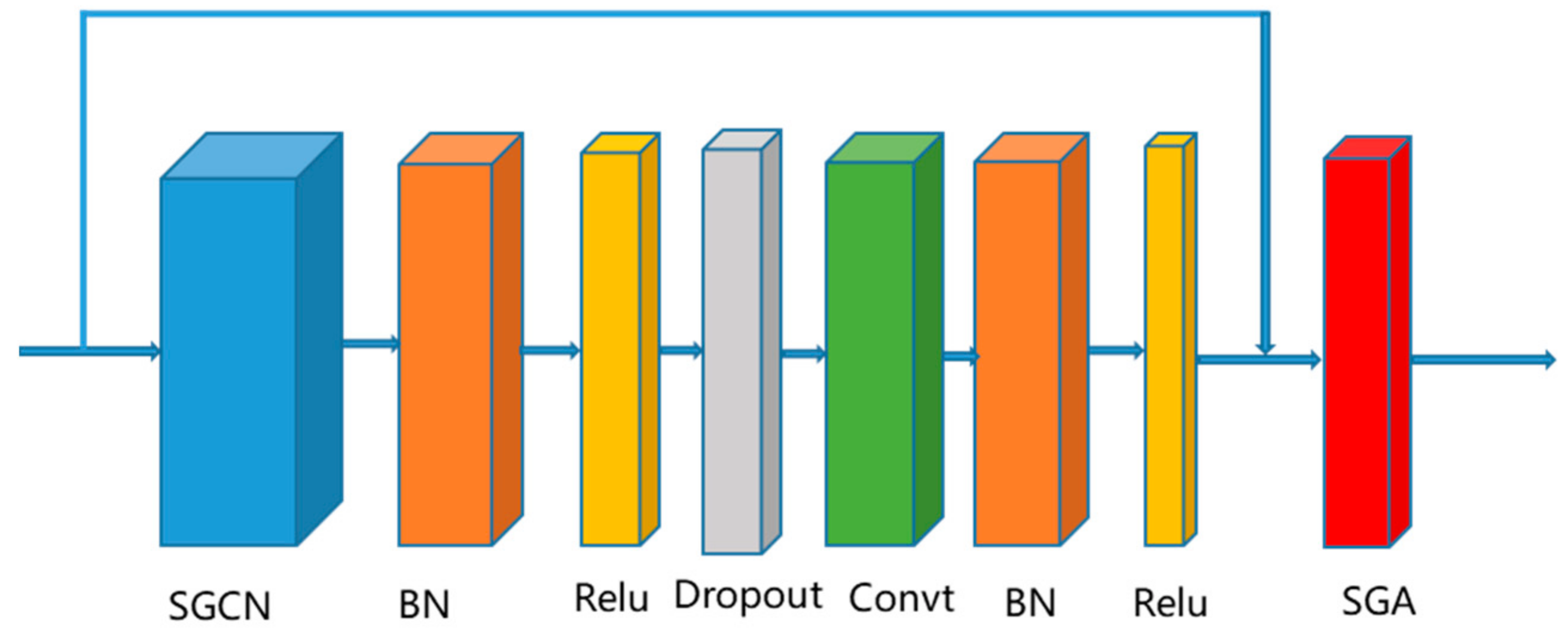
{kind=link}
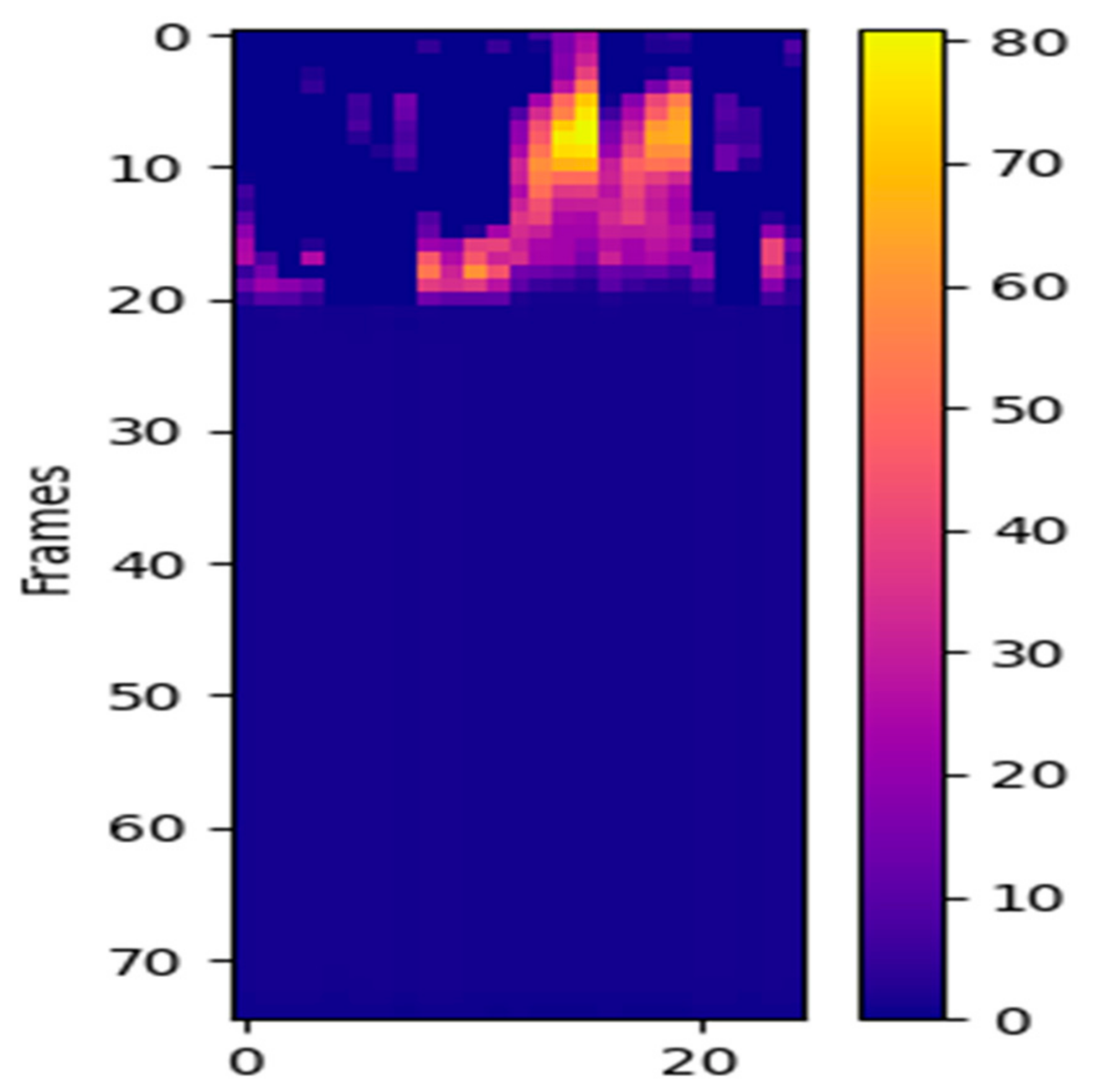
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Sensitivity | Specificity | Accuracy |
|---|---|---|---|
| AR-FD [30] | 98.0 | 89.4 | 94.0 |
| MEWMA-FD [31] | 100 | 94.9 | 96.6 |
| Shi-Tomasi-FD [32] | 96.7 | - | 95.7 |
| CNN-FD [33] | 100 | 92.0 | 95.0 |
| CNN-LSTM-FD [34] | 91.4 | - | - |
| Proposed method | 98.5 | 96.0 | 97.0 |
| Method | Sensitivity | Specificity | Accuracy |
|---|---|---|---|
| CNN + cam1 [35] | 97.72 | 81.58 | 95.24 |
| CNN + cam2 [35] | 95.57 | 79.67 | 94.78 |
| RF [7] | 14.48 | 92.9 | 32.33 |
| SVM [7] | 14.30 | 92.97 | 34.40 |
| MLP [7] | 10.59 | 92.21 | 27.08 |
| KNN [7] | 15.54 | 93.09 | 34.03 |
| CNN [7] | 71.3 | 99.5 | 95.1 |
| CNN [36] | 99.5 | 83.08 | 95.64 |
| RF + SVM + MLP + KNN [37] | 96.80 | 99.11 | 98.59 |
| CNN + LSTM [38] | 94.37 | 98.96 | 98.59 |
| Proposed method | 95.43 | 99.12 | 98.85 |
| Sensitivity | Specificity | Accuracy | |
|---|---|---|---|
| Result | 97.5 | 89.6 | 94.5 |
| Setting | NTU | |
|---|---|---|
| X-Sub | X-View | |
| Sub-Graph Division | 90.3 | 92.8 |
| Sub-Graph Attention | 90.2 | 92.5 |
| Sub-Graph Division + Sub-Graph Attention | 92.3 | 96.1 |
| Kernel Size | X-Sub | ||
|---|---|---|---|
| 3 | 5 | 7 | |
| 85.7 | |||
| 87.5 | |||
| √ | √ | 87.6 | |
| √ | 87.2 | ||
| √ | √ | 88.9 | |
| √ | √ | 88.4 | |
| √ | √ | 88.7 | |
| √ | √ | √ | 89.8 |
| Dataset | Training Time (h) | Speed (fp/s) |
|---|---|---|
| collected NTU dataset | 2 | 31 |
| URFD | 4.5 | 32 |
| UP-Fall | 7.5 | 30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Zhang, L.; Shang, H. A Lightweight Subgraph-Based Deep Learning Approach for Fall Recognition. Sensors 2022, 22, 5482. https://doi.org/10.3390/s22155482
Zhao Z, Zhang L, Shang H. A Lightweight Subgraph-Based Deep Learning Approach for Fall Recognition. Sensors. 2022; 22(15):5482. https://doi.org/10.3390/s22155482
Chicago/Turabian StyleZhao, Zhenxiao, Lei Zhang, and Huiliang Shang. 2022. "A Lightweight Subgraph-Based Deep Learning Approach for Fall Recognition" Sensors 22, no. 15: 5482. https://doi.org/10.3390/s22155482
APA StyleZhao, Z., Zhang, L., & Shang, H. (2022). A Lightweight Subgraph-Based Deep Learning Approach for Fall Recognition. Sensors, 22(15), 5482. https://doi.org/10.3390/s22155482