
Infrared and Visible Image Fusion Method Using Salience Detection and Convolutional Neural Network

Abstract
:1. Introduction
- 1.
- This paper divides the image information into change information and redundant information and introduces global contrast-based image significance detection (LC) for change information. In the image pre-processing process, significance detection is performed on the infrared images while suppressing the redundant information in the images.
- 2.
- Based on the principle of saliency detection, the loss function of infrared images is redesigned to better guide the training of the network and selectively extract effective features.
2. Related Works
2.1. Traditional Fusion-Based Methods
2.2. Deep Learning-Based Fusion Methods
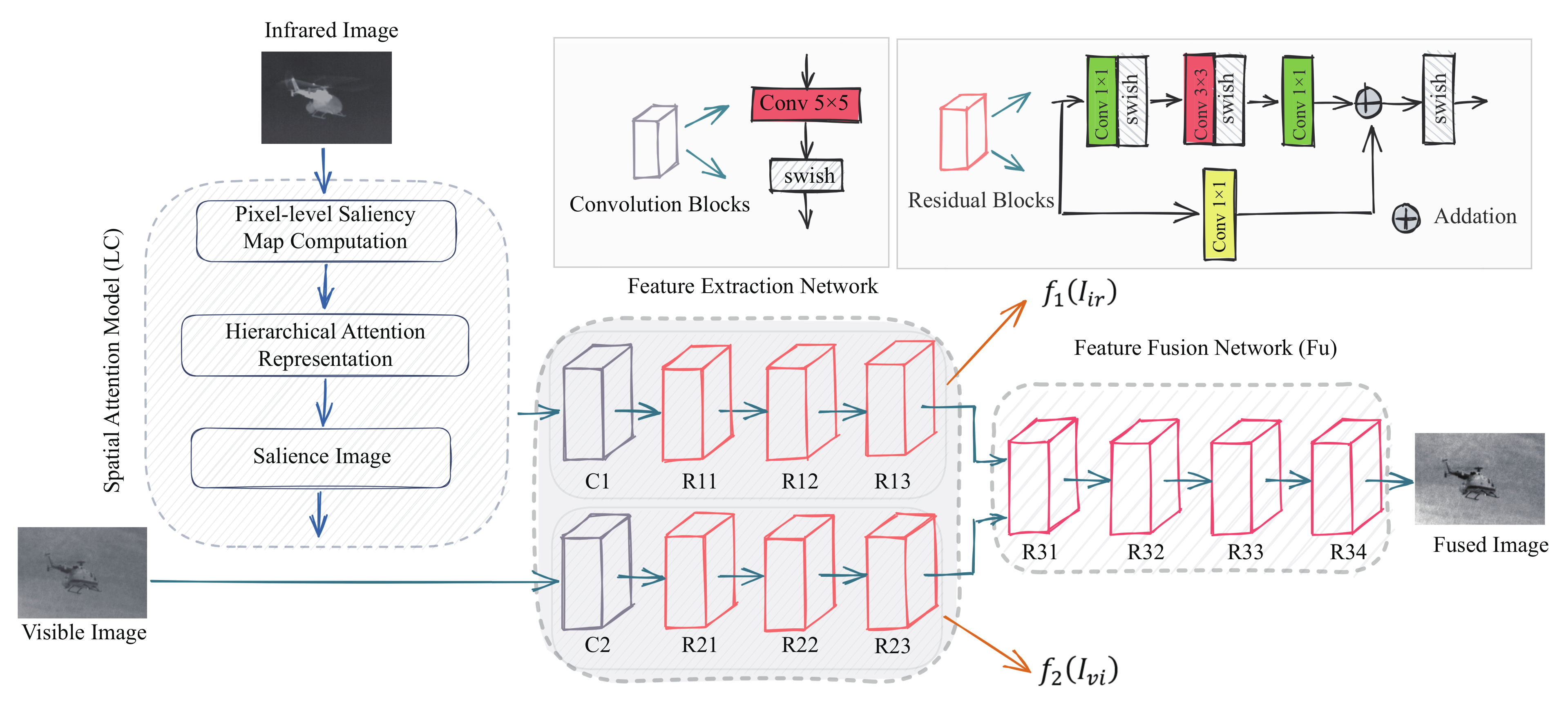
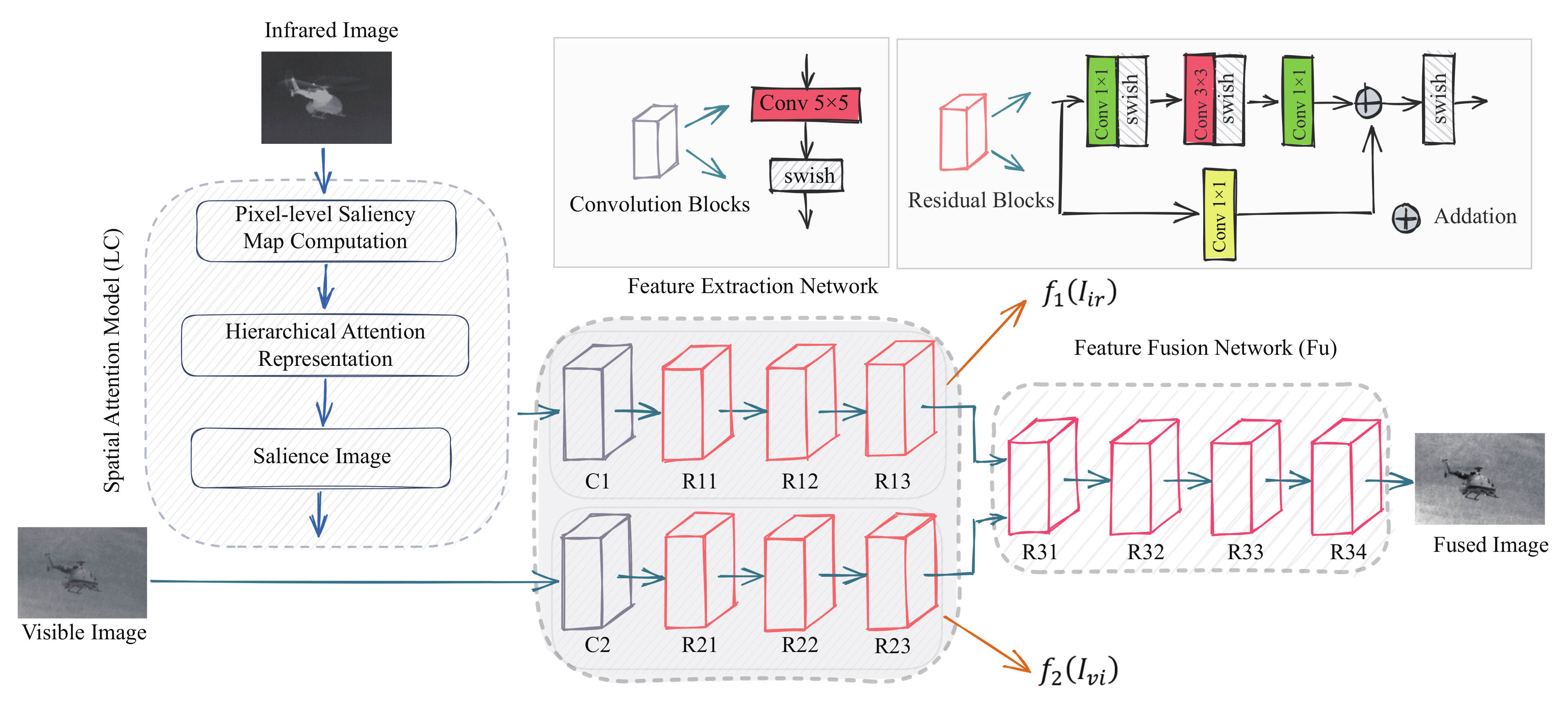
3. Proposed Method
3.1. Problem Formulation
3.2. Network Architecture
3.3. Loss Function
4. Experimental Results and Analysis
4.1. Experimental Results
4.1.1. Implementation Parameters
4.1.2. Evaluation Indicators
4.2. Comparative with State-of-the-Arts
4.2.1. Qualitative Evaluation
4.2.2. Quantitative Evaluation
4.3. Generalization Experiment
4.3.1. Qualitative Evaluation
4.3.2. Quantitative Evaluation
5. Discussion
5.1. Significance Testing
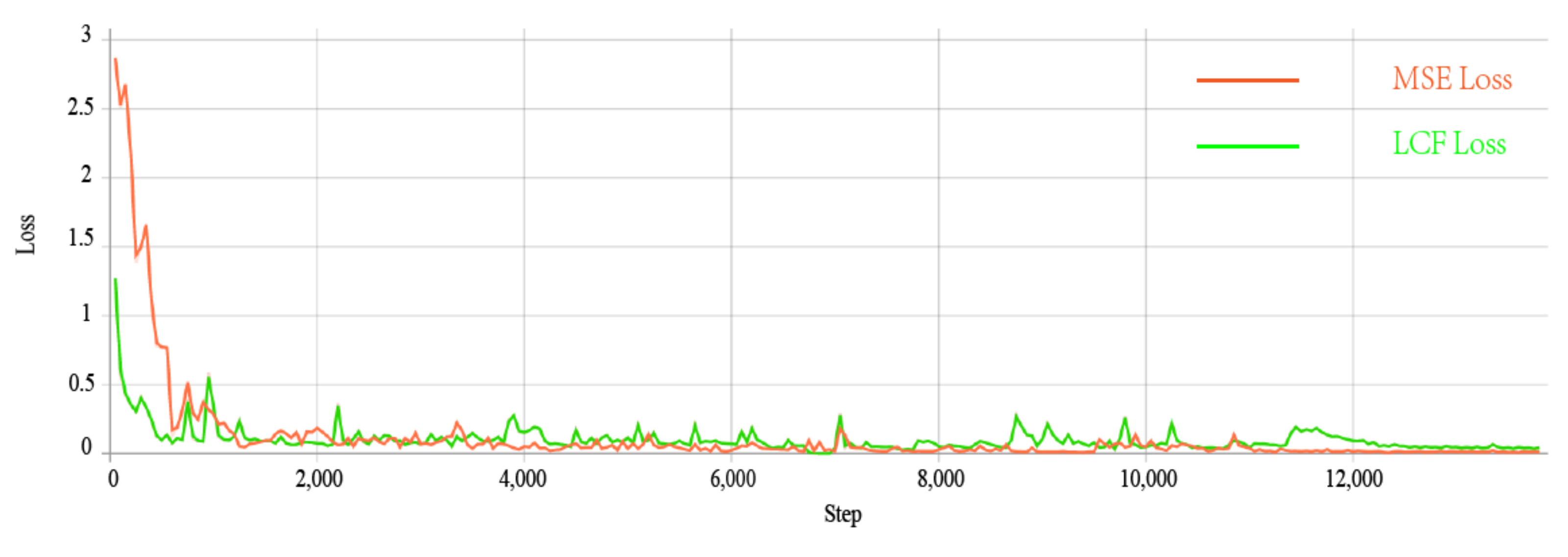
5.2. Loss Function
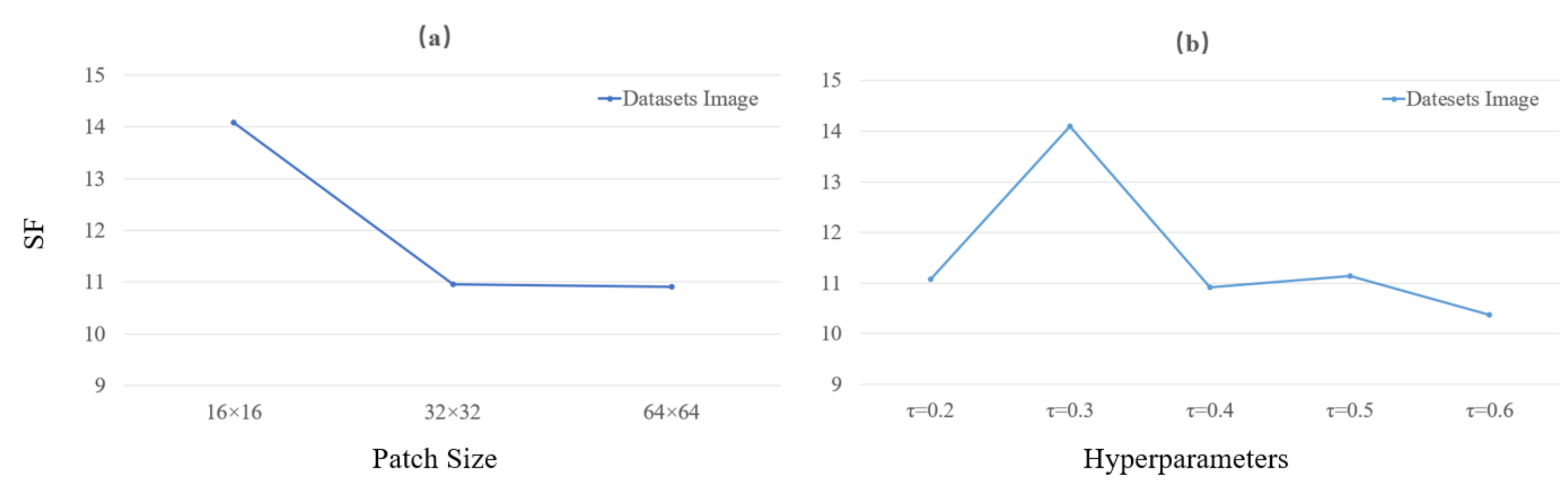
5.3. Different Parameters
5.4. Add Noise
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LCF | Image Significance Detection Fusion |
| PCA | Principal Component Analysis |
| ICA | Independent Component Analysis |
| NMF | Non-negative Matrix Factorization |
| GAN | Generative Adversarial Network |
| CSF | Classification Saliency-Based Fusion |
| VIF | Visible Image Fusion |
| GTF | Gradient Transfer Fusion |
| STD | Salient Target Detection |
| LP | Laplacian Pyramid |
| MSVD | Multi-Resolution Singular Value Decomposition |
References
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Y. Infrared and visible image fusion via gradientlet filter. Comput. Vis. Image Underst. 2020, 2, 197–198. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H. GANMcC: A Generative Adversarial Network with Multiclassification Constraints for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2021, 99, 1–4. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An Infrared and Visible Image Fusion Network Based on Salient Target Detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Duan, C. Infrared and visible image fusion using multi-scale edge-preserving decomposition and multiple saliency features. Opt.-Int. J. Light Electron Opt. 2021, 228, 165775. [Google Scholar] [CrossRef]
- Xiao, W.; Zhang, Y.; Wang, H. Heterogeneous Knowledge Distillation for Simultaneous Infrared-Visible Image Fusion and Super-Resolution. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Yang, Y.; Kong, X.; Huang, S.; Wan, W. Infrared and Visible Image Fusion Based on Multiscale Network with Dual-channel Information Cross Fusion Block. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–7. [Google Scholar]
- Li, Q.; Lu, L.; Li, Z.; Wu, W.; Liu, Z.; Jeon, G.; Yang, X. Coupled GAN with Relativistic Discriminators for Infrared and Visible Images Fusion. IEEE Sens. J. 2021, 21, 7458–7467. [Google Scholar] [CrossRef]
- Zhou, W.; Wu, W.; Zhou, H. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar]
- Xu, D.; Wang, Y.; Zhang, X.; Zhang, N.; Yu, S. Infrared and Visible Image Fusion Using a Deep Unsupervised Framework With Perceptual Loss. IEEE Access 2020, 8, 206445–206458. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, X.; Zhang, Y.; Xu, M.; Gu, S.; Duan, Y. Deep Coupled Feedback Network for Joint Exposure Fusion and Image Super-Resolution. IEEE Trans. Image Process. 2021, 30, 3098–3112. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Yu, W. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An Unsupervised Framework for Infrared and Visible Image Fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Zhang, D.; Hou, J.; Wu, W. A generative adversarial network with dual discriminators for infrared and visible image fusion based on saliency detection. Math. Probl. Eng. 2021. [Google Scholar] [CrossRef]
- Zhai, Y.; Shah, M. Visual attention detection in video sequences using spatiotemporal cues. In Proceedings of the 14th ACM International Conference on Multimedia, Santa Barbara, CA, USA, 23–27 October 2006; pp. 23–27. [Google Scholar]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Burt, P.J.; Adelson, E.H. The laplacian pyramid as a compact image code. Read. Comput. Vis. 1983, 31, 671–679. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Naidu, V.P.S. Image Fusion Technique using Multi-resolution Singular Value Decomposition. Def. Sci. J. 2011, 61, 479–484. [Google Scholar] [CrossRef] [Green Version]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Chen, G. Image quality measures for predicting automatic target recognition performance. In Proceedings of the In 2008 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.A. StyleFuse: An unsupervised network based on style loss function for infrared and visible image fusion. Signal Process. Image Commun. 2022, 106, 116722. [Google Scholar] [CrossRef]
- Li, J.; Huo, H.; Li, C.; Wang, R.; Feng, Q. AttentionFGAN: Infrared and visible image fusion using attention-based generative adversarial networks. IEEE Trans. Multimed. 2021, 23, 1383–1396. [Google Scholar] [CrossRef]
- Raza, A.; Liu, J.; Liu, Y.; Liu, J.; Li, Z.; Chen, X.; Huo, H.; Fang, T. IR-MSDNet: Infrared and visible image fusion based on infrared features and multiscale dense network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3426–3437. [Google Scholar] [CrossRef]
- A Toet. TNO Image Fusion Dataset. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029 (accessed on 10 June 2022).
- The Source Code of Proposed Method Is. Available online: https://github.com/Wangdayday7/Infrared-and-Visible-Image-Fusion.git (accessed on 10 June 2022).
- Chen, G.; Wang, S.; Shang, K.; Chen, Y. Infrared and visible image fusion based on rolling guided filter and ResNet101. In Proceedings of the 2021 International Conference on Electronic Information Engineering and Computer Science (EIECS), Changchun, China, 23–26 September 2021; pp. 248–251. [Google Scholar]
- Zhang, X.; Ye, P.; Qiao, D. Object fusion tracking based on visible and infrared images using fully convolutional siamese networks. In Proceedings of the 2019 22th International Conference on Information Fusion, Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wu, Y. UNFusion: A unified multi-scale densely connected network for infrared and visible image fusion. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3360–3374. [Google Scholar] [CrossRef]
- Wang, F.; Wu, D.; Gao, G. Color constancy via multi-Scale region-weighed network guided by semantics. Front. Neurorobot. 2022, 16, 841426. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR | SSIM | SF | MI |
|---|---|---|---|---|
| LP | 17.53 ± 1.82 | 0.65 ± 0.08 | 10.43 ± 2.73 | 1.75 ± 0.02 |
| GTF | 16.63 ± 4.25 | 0.86 ± 0.17 | 9.03 ± 0.43 | 1.48 ± 0.10 |
| MSVD | 13.14 ± 0.63 | 0.56 ± 0.08 | 10.72 ± 2.38 | 0.87 ± 0.10 |
| Nestfuse | 17.24 ± 5.29 | 0.78 ± 0.05 | 12.67 ± 3.61 | 3.18 ± 0.47 |
| VIF | 14.40 ± 5.75 | 0.72 ± 0.09 | 11.08 ± 6.86 | 1.68 ± 0.76 |
| STD | 22.43 ± 9.42 | 0.82 ± 0.06 | 12.53 ± 3.09 | 3.25 ± 1.33 |
| LCF | 18.98 ± 7.07 | 0.84 ± 0.05 | 14.07 ± 4.66 | 4.51 ± 1.61 |
| Methods | PSNR | SSIM | SF | MI |
|---|---|---|---|---|
| LP | 7.61 ± 0.54 | 0.34 ± 0.11 | 11.62 ± 7.91 | 1.23 ± 0.71 |
| GTF | 7.63 ± 0.03 | 0.55 ± 0.07 | 9.67 ± 2.18 | 1.31 ± 0.71 |
| MSVD | 12.17 ± 3.97 | 0.58 ± 0.14 | 14.16 ± 4.36 | 0.79 ± 0.12 |
| Nestfuse | 15.86 ± 3.53 | 0.69 ± 0.11 | 13.44 ± 3.15 | 1.64 ± 0.57 |
| VIF | 9.57 ± 2.87 | 0.54 ± 0.01 | 7.88 ± 1.37 | 1.56 ± 0.87 |
| STD | 13.96 ± 1.43 | 0.72 ± 0.06 | 16.54 ± 3.59 | 2.84 ± 1.16 |
| LCF | 15.38 ± 0.04 | 0.84 ± 0.03 | 15.43 ± 4.71 | 5.77 ± 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, F.; Wu, D.; Gao, G. Infrared and Visible Image Fusion Method Using Salience Detection and Convolutional Neural Network. Sensors 2022, 22, 5430. https://doi.org/10.3390/s22145430
Wang Z, Wang F, Wu D, Gao G. Infrared and Visible Image Fusion Method Using Salience Detection and Convolutional Neural Network. Sensors. 2022; 22(14):5430. https://doi.org/10.3390/s22145430
Chicago/Turabian StyleWang, Zetian, Fei Wang, Dan Wu, and Guowang Gao. 2022. "Infrared and Visible Image Fusion Method Using Salience Detection and Convolutional Neural Network" Sensors 22, no. 14: 5430. https://doi.org/10.3390/s22145430
APA StyleWang, Z., Wang, F., Wu, D., & Gao, G. (2022). Infrared and Visible Image Fusion Method Using Salience Detection and Convolutional Neural Network. Sensors, 22(14), 5430. https://doi.org/10.3390/s22145430