
Predicting Activity Duration in Smart Sensing Environments Using Synthetic Data and Partial Least Squares Regression: The Case of Dementia Patients

 , ,
, ,  ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Related Works
2.1. Synthesizing Data for Sensor Based Activity Recognition
2.2. Challenges with Existing Approaches for Data Synthesis
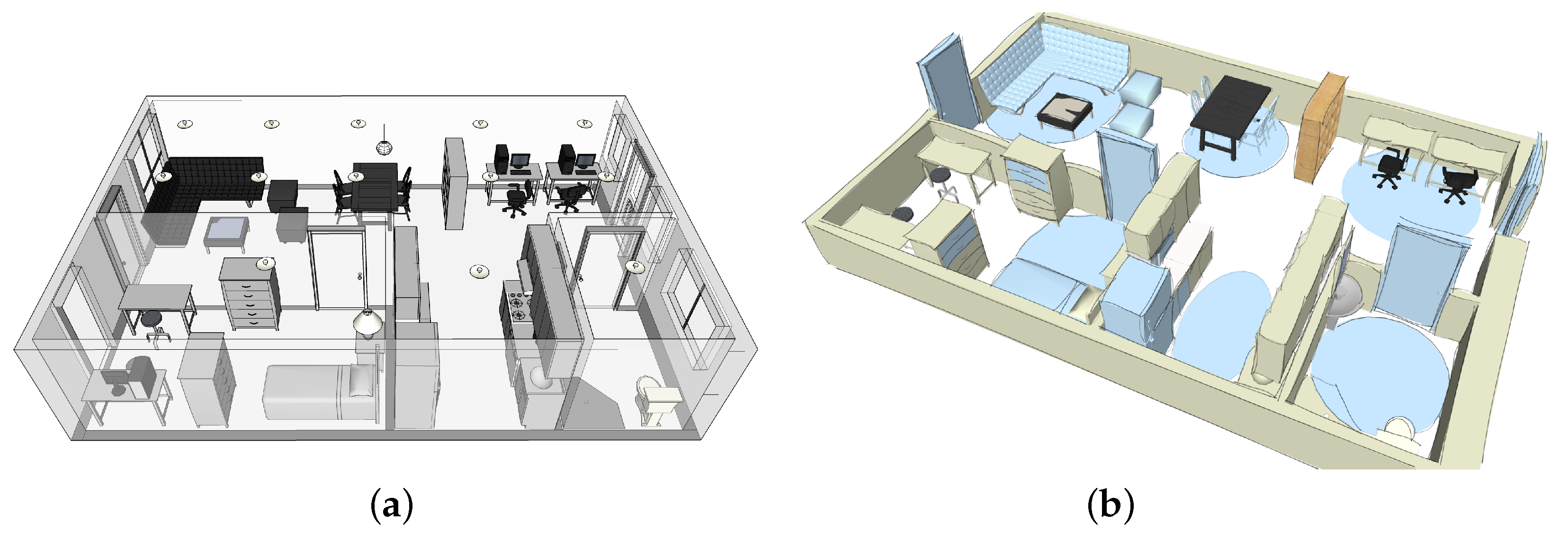
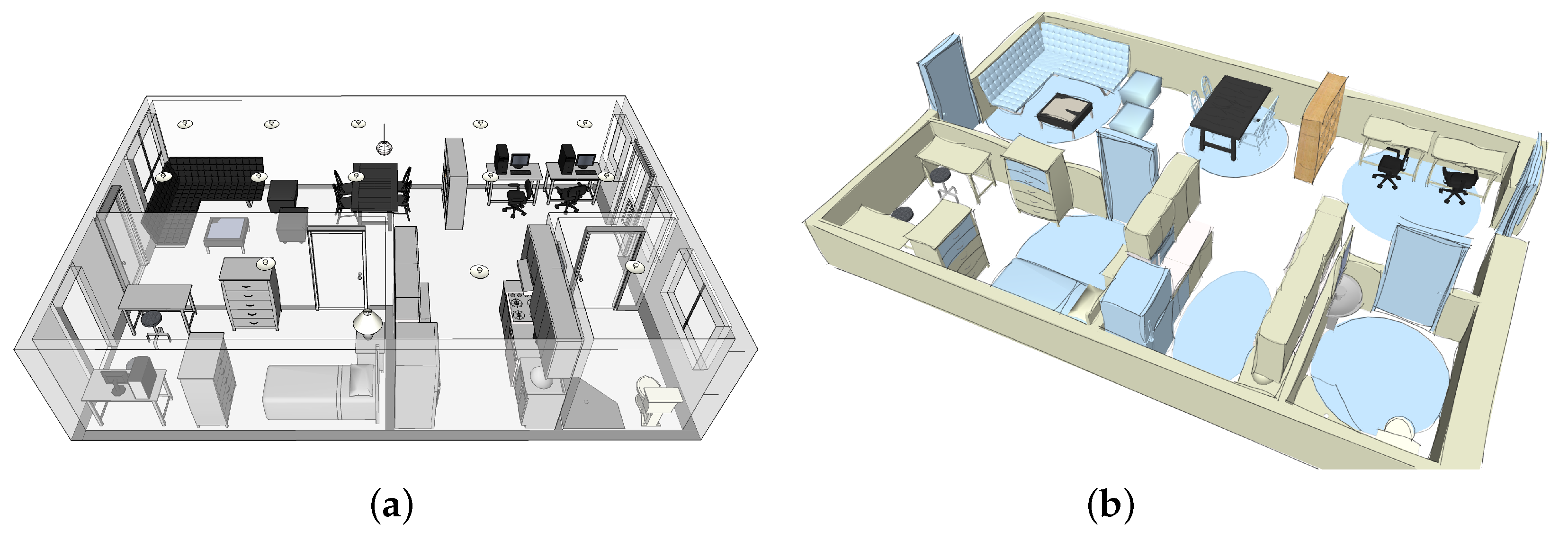
3. Materials and Methods
Assessment of Model and Data
4. Experiment Definition
- –
- Please carefully read the tasks to be carried out in each activity.
- –
- Please feel free to re-read the instructions of each activity if necessary.
- –
- Please press the Start/Stop switch when an activity is finished.
- –
- Please lock the door upon crossing through.
- –
- Please switch off each household appliance after use.
- ADL 1: Stay in bedYou can remain in bed as long as you wish. The maximum time is 2 min. After this, you have to get out of the bedroom, lock the door, and press the Start/Stop switch.
- ADL 2: Use restroomYou can use the hand-washing sink and/or toilet if you need. After this, please get out of the bathroom, lock the door, and press the Start/Stop switch.
- ADL 3: Make breakfastYou have to cook something for breakfast. Besides, you can select between milk and cereals or coffee. However, it is also possible to prepare both if you want. After this, move the bowl up on the dining table, sit down, and press the Start/Stop switch.
- ADL 4: Get out of homeYou can decide to leave the house from the courtyard door or from the front door. When you are in outdoors, please push the Start/Stop switch.
- ADL 5: Get cold drinkYou can take the drink from the refrigerator or serve plain water. After this, put the poured glass on the kitchen table and press the Start/Stop button.
- ADL 6: Stay in the officePlease proceed to the office and push the Start/Stop button.
- ADL 7: Get hot drinkYou can select between preparing coffee or tea. After this, put the poured cup on the kitchen table and push the Start/Stop button.
- ADL 8: Cook dinnerPlease make soup. Put the served bowl on the kitchen desk and push the Start/Stop button.
5. Results and Discussion
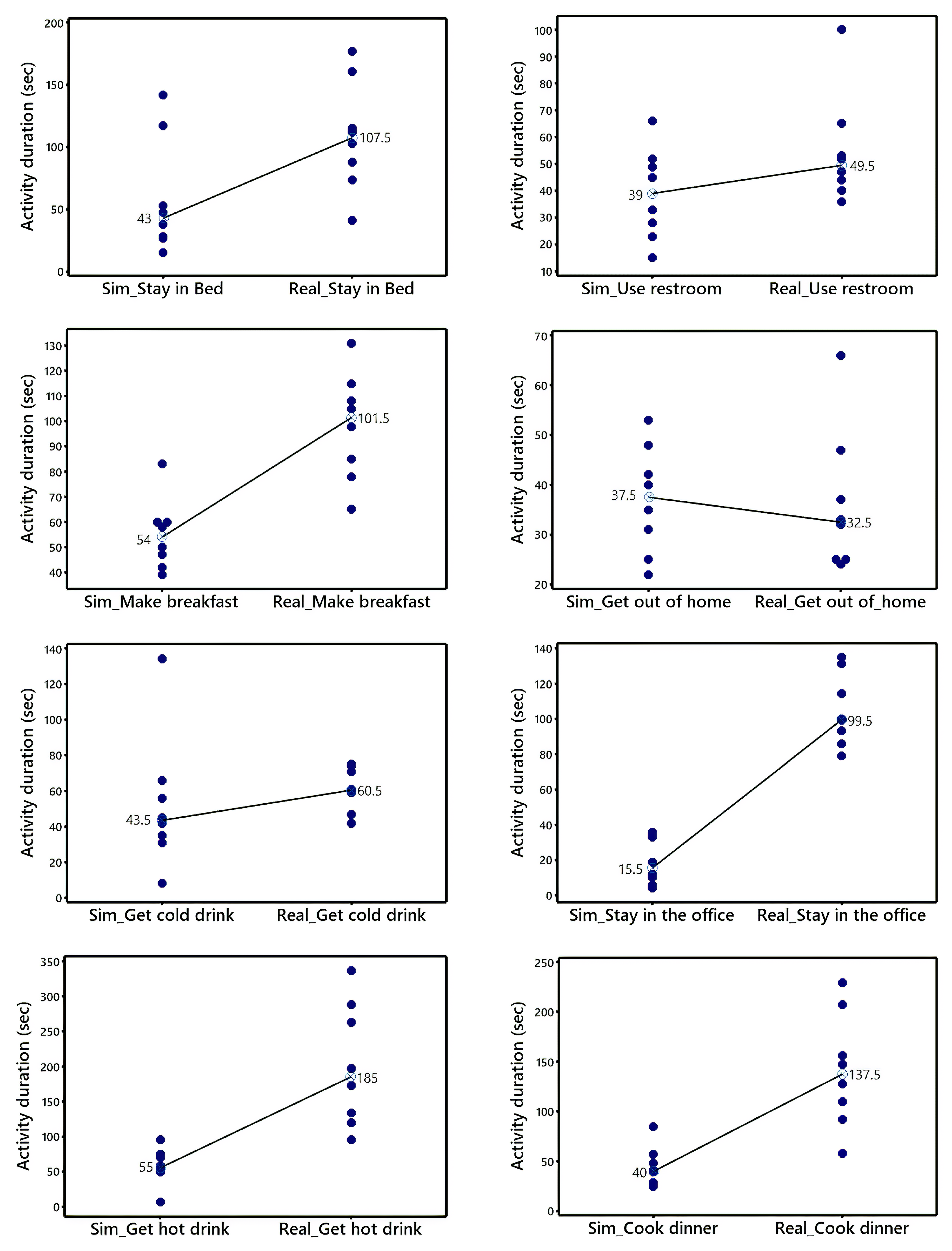
5.1. Contrasting Real and Synthetic Activity Duration
5.2. Transforming Synthetic Data to Predict Real Activity Duration
5.2.1. Use Restroom
5.2.2. Make Breakfast
5.2.3. Stay in the Office
5.2.4. Get Hot Drink
5.2.5. Cook Dinner
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADLs | Activities of Daily Living |
| AI | Artificial Intelligence |
| ANOVA | Analysis of Variance |
| AR | Activity Recognition |
| CNN | Convolutional Neural Network |
| DF | Degrees of Freedom |
| DTW | Dynamic Time Warping |
| DW | Durbin Watson |
| GANs | Generative Adversarial Networks |
| HINT | Halmstad Intelligent Home |
| HMM | Hidden Markov Model |
| ML | Machine Learning |
| MS | Mean Square |
| NEA | Number of Events per Activity |
| Number of Events per Activity for Get Hot Drink | |
| Number of Events per Activity for Make Breakfast | |
| Number of Events per Activity for Stay in the Office | |
| Number of Events per Pressure Sensor | |
| Number of Events per Sensor (Chair Pressure) | |
| NESA | Number of Events per Sensor per Activity |
| NIPALS | Nonlinear Iterative Partial Least Squares |
| OLSR | Ordinary Least Squares Regression (OLSR) |
| PCA | Principal Components Analysis |
| PCR | Principal Components Regression |
| PIR | Passive Infrared |
| PLS | Partial Least Squares |
| PLSR | Partial Least Squares Regression |
| PRESS | Prediction Residuals Sum of Squares |
| PwD | People with Dementia |
| SAD | Smoking Activity Dataset |
| Synthetic Activity Duration for Cook Dinner | |
| Synthetic Activity Duration for Get Hot Drink | |
| Synthetic Activity Duration for Make Breakfast | |
| Synthetic Activity Duration for Stay in the Office | |
| Synthetic Activity Duration for Use Restroom | |
| SHL | Sussex-Huawei Locomotion |
| SS | Squared Sum |
| UTI | Urinary Tract Infection |
| WHO | World Health Organization |
References
- World Health Organisation Dementia Key Facts. Available online: https://www.who.int/news-room/fact-sheets/detail/dementia (accessed on 28 April 2022).
- McConaghy, R.; Caltabiano, M.L. Caring for a person with dementia: Exploring relationships between perceived burden, depression, coping and well-being. Nurs. Health Sci. 2005, 7, 81–91. [Google Scholar] [CrossRef] [PubMed]
- Lorenz, K.; Freddolino, P.P.; Comas-Herrera, A.; Knapp, M.; Damant, J. Technology-based tools and services for people with dementia and carers: Mapping technology onto the dementia care pathway. Dementia 2019, 18, 725–741. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garcia-Constantino, M.; Orr, C.; Synnott, J.; Shewell, C.; Ennis, A.; Cleland, I.; Nugent, C.; Rafferty, J.; Morrison, G.; Larkham, L.; et al. Design and Implementation of a Smart Home in a Box to Monitor the Wellbeing of Residents with Dementia in Care Homes. Front. Digit. Health 2021, 3, 798889. [Google Scholar] [CrossRef] [PubMed]
- Ortíz-Barrios, M.A.; Garcia-Constantino, M.; Nugent, C.; Alfaro-Sarmiento, I. A Novel Integration of IF-DEMATEL and TOPSIS for the Classifier Selection Problem in Assistive Technology Adoption for People with Dementia. Int. J. Environ. Res. Public Health 2022, 19, 1133. [Google Scholar] [CrossRef]
- Ortíz-Barrios, M.A.; Lundström, J.; Synnott, J.; Järpe, E.; Sant’Anna, A. Complementing real datasets with simulated data: A regression-based approach. Multimed. Tools Appl. 2020, 79, 34301–34324. [Google Scholar] [CrossRef]
- Dahmen, J.; Cook, D. SynSys: A synthetic data generation system for healthcare applications. Sensors 2019, 19, 1181. [Google Scholar] [CrossRef] [Green Version]
- HekmatiAthar, S.; Goins, H.; Raymond, S.; Byfield, G.; Anwar, M. Data-driven forecasting of agitation for persons with dementia: A deep learning-based approach. SN Comput. Sci. 2021, 2, 326. [Google Scholar] [CrossRef]
- Urwyler, P.; Stucki, R.; Rampa, L.; Müri, R.; Mosimann, U.P.; Nef, T. Cognitive impairment categorized in community-dwelling older adults with and without dementia using in-home sensors that recognise activities of daily living. Sci. Rep. 2017, 7, 42084. [Google Scholar] [CrossRef] [Green Version]
- Damla, A.; Wang, Y.; Bouchachia, A. Detection of dementia-related abnormal behaviour using recursive auto-encoders. Sensors 2021, 21, 260. [Google Scholar] [CrossRef]
- Enshaeifar, S.; Zoha, A.; Skillman, S.; Markides, A.; Acton, S.T.; Elsaleh, T.; Kenny, M.; Rostill, H.; Nilforooshan, R.; Barnaghi, P. Machine learning methods for detecting urinary tract infection and analysing daily living activities in people with dementia. PLoS ONE 2019, 14, e0209909. [Google Scholar] [CrossRef] [Green Version]
- Virone, G.; Lefebvre, B.; Noury, N.; Demongeot, J. Modeling and computer simulation of physiological rhythms and behaviors at home for data fusion programs in a telecare system. In Proceedings of the 5th International Workshop on Enterprise Networking and Computing in Healthcare Industry, Santa Monica, CA, USA, 7 June 2003; pp. 111–117. [Google Scholar]
- Helal, A.; Mendez-Vazquez, A.; Hossain, S. Specification and synthesis of sensory datasets in pervasive spaces. In Proceedings of the 2009 IEEE Symposium on Computers and Communications, Sousse, Tunisia, 5–8 July 2009; pp. 920–925. [Google Scholar]
- Alharbi, F.; Ouarbya, L.; Ward, J.A. Synthetic sensor data for human activity recognition. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–9. [Google Scholar]
- Lee, J.W.; Cho, S.; Liu, S.; Cho, K.; Helal, S. Persim 3d: Context-driven simulation and modeling of human activities in smart spaces. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1243–1256. [Google Scholar] [CrossRef]
- Kamara-Esteban, O.; Azkune, G.; Pijoan, A.; Borges, C.E.; Alonso-Vicario, A.; López-de-Ipiña, D. MASSHA: An agent-based approach for human activity simulation in intelligent environments. Pervasive Mob. Comput. 2017, 40, 279–300. [Google Scholar] [CrossRef]
- Alshammari, N.; Alshammari, T.; Sedky, M.; Champion, J.; Bauer, C. Openshs: Open smart home simulator. Sensors 2017, 17, 1003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Damien, B.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A survey of human activity recognition in smart homes based on IoT sensors algorithms: Taxonomies, challenges, and opportunities with deep learning. Sensors 2021, 21, 6037. [Google Scholar] [CrossRef]
- Wang, K.F.; Gou, C.; Zheng, N.N.; Rehg, J.M.; Wang, F.-Y. Parallel vision for perception and understanding of complex scenes: Methods, framework and perspectives. Artif. Intell. Rev. 2017, 48, 299–329. [Google Scholar] [CrossRef]
- Reeves, D.R.; Taylor, S.J. Selection of training data for neural networks by a genetic algorithm. In Proceedings of the International Conference on Parallel Problem Solving from Nature 1998, Amsterdam, The Netherlands, 27–30 September 1998; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Kleijnen, J.P.C. Verification and validation of simulation models. Eur. J. Oper. Res. 1995, 82, 145–162. [Google Scholar] [CrossRef] [Green Version]
- Wold, H. Estimation of principal components and related models by iterative least squares. In Multivariate Analysis; Academic Press: Cambridge, MA, USA, 1966; pp. 391–420. [Google Scholar]
- Otto, M.; Wegscheider, W. Selectivity in multicomponent analysis. Anal. Chim. Acta 1986, 180, 445–456. [Google Scholar] [CrossRef]
- Pirouz, D.M. An Overview of Partial Least Squares. In ERN: Other Econometrics: Econometric & Statistical Methods (Topic); SSRN: Rochester, NY, USA, 2006. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Ruhe, A.; Wold, H.; Dunn, W.J., III. The Collinearity Problem in Linear Regression. The Partial Least Squares (PLS) Approach to Generalized Inverses. SIAM J. Sci. Stat. Comput. 1984, 5, 735–743. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Albano, C.; Dunn, W.J., III; Edlund, U.; Esbensen, K.; Geladi, P.; Hellberg, S.; Johansson, E.; Lindeberg, W.; Sjöström, M. Multivarite Data Analysis in Chemistry. In Chemometrics: Mathematics and Statistics; Kowalski, B., Ed.; D. Riedel Publishing Company: Dordrecht, The Netherlands, 1984; Volume 17. [Google Scholar]
- Wold, S.; Albano, C.; Dunn, W.J., III; Esbensen, K.; Hellberg, S.; Johansson, E.; Sjöström, M.; Martens, H.; Rosswurm, J. Food Research and Data Analysis; Martens, W., Rosswurm, H., Eds.; Applied Science Publishers: London, UK, 1984. [Google Scholar]
- Geladi, P.; Kowalski, B. Partial least-squares regression—A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Camarrone, F.; van Hulle, M.M. Fast Multiway Partial Least Squares Regression. IEEE Trans. Biomed. Eng. 2019, 66, 433. [Google Scholar] [CrossRef]
- Henseler, J. On the convergence of the partial least squares path modeling algorithm. Comput. Stat. 2010, 25, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.B.; You, X.G.; You, S.J.; Tao, D.C.; Chen, C.L.P.; Cheung, Y.M. Variance constrained partial least squares. Chemom. Intell. Lab. Syst. 2015, 145, 60–71. [Google Scholar] [CrossRef]
- Mou, Y.; Zhou, L.; You, X.G.; Lu, Y.L.; Chen, W.Z.; Zhao, X. Multiview Partial Least Squares. Chemom. Intell. Lab. Syst. 2017, 160, 13–21. [Google Scholar] [CrossRef]
- Singer, M.; Krivobokova, T.; Munk, A.; Groot, B. Partial least squares for dependent data. Biometrika 2016, 103, 351–362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Helland, I.S.; Saebo, S.; Almoy, T.; Rimal, R. Model and estimators for partial least squares regression. J. Chemom. 2018, 32, e3044. [Google Scholar] [CrossRef]
- Butler, N.A.; Denham, M.C. The peculiar shrinkage properties of partial least squares regression. J. R. Stat. Soc. B 2000, 62, 585–593. [Google Scholar] [CrossRef]
- Hinkle, J.; Raynes, W. Partial least squares and compositional data: Problems and alternatives. Chemom. Intell. Lab. Syst. 1995, 30, 159–172. [Google Scholar] [CrossRef]
- Rönkkö, M.; McIntosh, C.N.; Antonakis, J.; Edwards, J.R. Partial least squares path modeling: Time for some serious second thoughts. J. Oper. Manag. 2016, 47–48, 9–27. [Google Scholar] [CrossRef] [Green Version]
- Chui, K.T.; Lytras, M.D.; Vasant, P. Combined Generative Adversarial Network and Fuzzy C-Means Clustering for Multi-Class Voice Disorder Detection with an Imbalanced Dataset. Appl. Sci. 2020, 10, 4571. [Google Scholar] [CrossRef]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How Generative Adversarial Networks and Their Variants Work: An Overview. ACM Comput. Surv. 2019, 52, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Alqahtani, H.; Kavakli, M.; Kumar, G. Applications of Generative Adversarial Networks (GANs): An Updated Review. Arch. Comput. Methods Eng. 2021, 28, 525–552. [Google Scholar] [CrossRef]
- Hui, J. GAN—Why It Is So Hard to Train Generative Adversarial Networks! Medium. 2018. Available online: https://jonathan-hui.medium.com/gan-why-it-is-so-hard-to-train-generative-advisory-networks-819a86b3750b (accessed on 1 July 2022).
- Luo, F.-L. Machine Learning for Future Wireless Communications; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Zeng, X.-Q.; Li, G.-Z. Incremental partial least squares analysis of big streaming data. Pattern Recognit. 2014, 47, 3726–3735. [Google Scholar] [CrossRef] [Green Version]
- Kearns, M.J. The Computational Complexity of Machine Learning; MIT Press: Cambridge, MA, USA, 1990. [Google Scholar] [CrossRef]
- Tang, Z.; Luo, L.; Xie, B.; Zhu, Y.; Zhao, R.; Bi, L.; Lu, C. Automatic sparse connectivity learning for neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q. Weight-Quantized SqueezeNet for Resource-Constrained Robot Vacuums for Indoor Obstacle Classification. Artif. Intell. 2022, 3, 180–193. [Google Scholar] [CrossRef]
- Chen, C.; Cao, X.; Tian, L. Partial least squares regression performs well in MRI-based individualized estimations. Front. Neurosci. 2019, 13, 1282. [Google Scholar] [CrossRef] [Green Version]
- Hansen, P.M.; Schjoerring, J.K. Reflectance measurement of canopy biomass and nitrogen status in wheat crops using normalized difference vegetation indices and partial least squares regression. Remote Sens. Environ. 2003, 86, 542–553. [Google Scholar] [CrossRef]
- Hao, C.; Chen, D. Software/Hardware Co-design for Multi-modal Multi-task Learning in Autonomous Systems. In Proceedings of the IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021. [Google Scholar] [CrossRef]
- Zheng, J.; Lu, C.; Hao, C.; Chen, D.; Guo, D. Improving the Generalization Ability of Deep Neural Networks for Cross-Domain Visual Recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 13, 607–620. [Google Scholar] [CrossRef]
- Allen, D.M. The Relationship Between Variable Selection and Data Agumentation and a Method for Prediction. Technometrics 1974, 16, 125–127. [Google Scholar] [CrossRef]
- Martínez, J.L.; Saulo, H.; Barrios Escobar, H.; Leão, J. A new model selection criterion for partial least squares regression. Chemom. Intell. Lab. Syst. 2017, 169, 64–78. [Google Scholar] [CrossRef]
- Liu, H.; Weiss, R.E.; Jennrich, R.I.; Wenger, N.S. PRESS model selection in repeated measures data. Comput. Stat. Data Anal. 1999, 30, 169–184. [Google Scholar] [CrossRef]
- Pratt, J.W.; Gibbons, J.D. Concepts of Nonparametric Theory; Springer: New York, NY, USA, 1981. [Google Scholar] [CrossRef]
- Kolassa, J.D. Edgeworth approximations for rank sum test statistics. Stat. Probab. Lett. 1995, 24, 169–171. [Google Scholar] [CrossRef]
- Cox, D.R.; Hinkley, D.V. Theoretical Statistics; Chapman & Hall: New York, NY, USA, 1974. [Google Scholar] [CrossRef]
- Larsen, R.J.; Marx, M.L. An Introduction to Mathematical Statistics and Its Applications, 6th ed.; Pearson: Boston, MA, USA, 2018. [Google Scholar] [CrossRef]
- Lundström, J.; Morais, W.O.D.; Menezes, M.; Gabrielli, C.; Bentes, J.; Sant’Anna, A.; Synnott, J.; Nugent, C. Halmstad intelligent home-capabilities and opportunities. In Proceedings of the International Conference on IoT Technologies for HealthCare, Budapest, Hungary, 18–19 October 2016; Springer: Cham, Switzerland, 2016; pp. 9–15. [Google Scholar] [CrossRef]
- Hamad, R.A.; Järpe, E.; Lundström, J. Stability analysis of the t-SNE algorithm for human activity pattern data. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1839–1845. [Google Scholar]
- Synnott, J.; Nugent, C.; Jeffers, P. Simulation of smart home activity datasets. Sensors 2015, 15, 14162–14179. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. CSUR 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Katz, S. Assessing self-maintenance: Activities of daily living, mobility, and instrumental activities of daily living. J. Am. Geriatr. Soc. 1983, 31, 721–727. [Google Scholar] [CrossRef] [PubMed]
- Park, B.; Min, H.; Bang, G.; Ko, I. The User Activity Reasoning Model in a Virtual Living Space Simulator. Int. J. Softw. Eng. Appl. 2015, 9, 53–62. [Google Scholar] [CrossRef]
- Synnott, J.; Chen, L.; Nugent, C.D.; Moore, G. The creation of simulated activity datasets using a graphical intelligent environment simulation tool. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 4143–4146. [Google Scholar]
- Ariani, A.; Redmond, S.J.; Chang, D.; Lovell, N.H. Simulation of a smart home environment. In Proceedings of the 2013 3rd International Conference on Instrumentation, Communications, Information Technology and Biomedical Engineering (ICICI-BME), Bandung, Indonesia, 7–8 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 27–32. [Google Scholar]
- McGlinn, K.; O’Neill, E.; Gibney, A.; O’Sullivan, D.; Lewis, D. SimCon: A Tool to Support Rapid Evaluation of Smart Building Application Design using Context Simulation and Virtual Reality. J. Univers. Comput. Sci. 2010, 16, 1992–2018. [Google Scholar]
- Fortino, G.; Guzzo, A.; Ianni, M.; Leotta, F.; Mecella, M. Predicting activities of daily living via temporal point processes: Approaches and experimental results. Comput. Electr. Eng. 2021, 96, 107567. [Google Scholar] [CrossRef]
- Saleh, M.; Abbas, M.; Le Jeannes, R.B. FallAllD: An open dataset of human falls and activities of daily living for classical and deep learning applications. IEEE Sens. J. 2020, 21, 1849–1858. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| ADL | p-Value | 95% CI for the Difference (sec) | Conclusion |
|---|---|---|---|
| Stay in bed | 0.093 | [−5; 100] | Statistically similar |
| Use restroom | 0.050 | [−34; −1] | Statistically different |
| Make breakfast | 0.012 | [−66; −22] | Statistically different |
| Get out of home | 0.889 | [−12; 16] | Statistically similar |
| Get cold drink | 0.161 | [−36; 7] | Statistically similar |
| Stay in the office | 0.012 | [−104; 64] | Statistically different |
| Get hot drink | 0.018 | [−236; −62] | Statistically different |
| Cook dinner | 0.012 | [−159; −44] | Statistically different |
| Source | DF | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|
| Regression | 3 | 98.32% | 123.55 | 41.18 | 100.79 | 0.000 |
| 1 | 3.61% | 4.54 | 4.54 | 11.11 | 0.021 | |
| 1 | 2.46% | 3.09 | 3.09 | 7.50 | 0.040 | |
| 1 | 9.47% | 11.90 | 11.90 | 29.12 | 0.003 | |
| Error | 5 | 1.62% | 2.043 | 0.4087 | ||
| Total | 8 | 100% | 125.60 |
| S | Adj | PRESS | (Pred) | |
|---|---|---|---|---|
| 0.639 | 98.37% | 97.40% | 4.51 | 96.41% |
| Source | DF | SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Regression | 3 | 777.21 | 99.07% | 777.72 | 259.24 | 178.08 | 0.000 |
| 1 | 739.72 | 94.23% | 37.46 | 37.46 | 25.73 | 0.004 | |
| 1 | 18.33 | 2.33% | 37.96 | 37.96 | 26.08 | 0.004 | |
| 1 | 19.66 | 2.50% | 19.66 | 19.66 | 13.51 | 0.014 | |
| Error | 5 | 7.27 | 0.93% | 7.27 | 1.45 | ||
| Total | 8 | 785.00 | 100% |
| S | Adj | PRESS | (Pred) | |
|---|---|---|---|---|
| 1.206 | 99.07% | 98.52% | 20.04 | 97.45% |
| Source | DF | SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Regression | 2 | 801.53 | 95.76% | 801.53 | 400.76 | 67.80 | 0.000 |
| 1 | 702.81 | 83.97% | 333.92 | 333.91 | 56.49 | 0.000 | |
| 1 | 98.72 | 11.79% | 98.72 | 98.72 | 16.70 | 0.006 | |
| Error | 6 | 35.47 | 4.24% | 35.47 | 35.47 | 1.45 | 1.45 |
| Total | 8 | 837.00 | 100% |
| S | Adj | PRESS | (Pred) | |
|---|---|---|---|---|
| 2.431 | 95.76% | 94.35% | 64.83 | 92.25% |
| Source | DF | SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Regression | 3 | 1570.99 | 97.82% | 1570.99 | 523.66 | 74.80 | 0.000 |
| 1 | 1287.84 | 80.19% | 184.11 | 184.11 | 26.30 | 0.004 | |
| 1 | 13.23 | 0.82% | 174.71 | 174.71 | 24.95 | 0.004 | |
| 1 | 269.92 | 16.81% | 269.92 | 269.92 | 38.55 | 0.002 | |
| Error | 5 | 35.01 | 2.18% | 35.01 | 7.001 | ||
| Total | 8 | 1606.00 | 100% |
| S | Adj | PRESS | (Pred) | |
|---|---|---|---|---|
| 2.645 | 97.82% | 96.51% | 77.27 | 95.19% |
| Source | DF | SS | Contribution | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|---|---|
| Regression | 3 | 188.24 | 98.59% | 188.24 | 62.74 | 116.28 | 0.000 |
| 1 | 163.16 | 85.45% | 19.02 | 19.02 | 35.25 | 0.002 | |
| 1 | 14.502 | 7.60% | 24.28 | 24.28 | 45.00 | 0.001 | |
| 1 | 10.57 | 5.54% | 10.57 | 10.57 | 19.59 | 0.007 | |
| Error | 5 | 2.698 | 1.41% | 2.69 | 0.53 | ||
| Total | 8 | 190.93 | 100% |
| S | Adj | PRESS | (Pred) | |
|---|---|---|---|---|
| 0.734 | 98.59% | 97.74% | 13.15 | 93.11% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortiz-Barrios, M.; Järpe, E.; García-Constantino, M.; Cleland, I.; Nugent, C.; Arias-Fonseca, S.; Jaramillo-Rueda, N. Predicting Activity Duration in Smart Sensing Environments Using Synthetic Data and Partial Least Squares Regression: The Case of Dementia Patients. Sensors 2022, 22, 5410. https://doi.org/10.3390/s22145410
Ortiz-Barrios M, Järpe E, García-Constantino M, Cleland I, Nugent C, Arias-Fonseca S, Jaramillo-Rueda N. Predicting Activity Duration in Smart Sensing Environments Using Synthetic Data and Partial Least Squares Regression: The Case of Dementia Patients. Sensors. 2022; 22(14):5410. https://doi.org/10.3390/s22145410
Chicago/Turabian StyleOrtiz-Barrios, Miguel, Eric Järpe, Matías García-Constantino, Ian Cleland, Chris Nugent, Sebastián Arias-Fonseca, and Natalia Jaramillo-Rueda. 2022. "Predicting Activity Duration in Smart Sensing Environments Using Synthetic Data and Partial Least Squares Regression: The Case of Dementia Patients" Sensors 22, no. 14: 5410. https://doi.org/10.3390/s22145410
APA StyleOrtiz-Barrios, M., Järpe, E., García-Constantino, M., Cleland, I., Nugent, C., Arias-Fonseca, S., & Jaramillo-Rueda, N. (2022). Predicting Activity Duration in Smart Sensing Environments Using Synthetic Data and Partial Least Squares Regression: The Case of Dementia Patients. Sensors, 22(14), 5410. https://doi.org/10.3390/s22145410