
Deep Lossless Compression Algorithm Based on Arithmetic Coding for Power Data



Abstract
:1. Introduction
- We propose a deep lossless compression algorithm for minute level power data to compress household power data of a smart grid;
- We analyze the learning effect of networks on power data. The performance evaluation experiments of compression ratio and entropy show that deep learning will improve the coding efficiency.
2. Related Work
3. Background
3.1. Bi-LSTM
3.2. Transformer
4. Proposed Method
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PMU | Phasor Measurement Unit |
| MSE | Mean Square Error |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| Bi-LSTM | Bi-directional Long Short-Term Memory |
| CR | Compression Ratio |
| CPU | Central Processing Unit |
| PCA | Principal Component Analysis |
| DBEA | Differential Binary Encoding Algorithm |
References
- González, I.; Calderón, A.J.; Portalo, J.M. Innovative Multi-Layered Architecture for Heterogeneous Automation and Monitoring Systems: Application Case of a Photovoltaic Smart Microgrid. Sustainability 2021, 13, 2234. [Google Scholar] [CrossRef]
- Song, F.; Qin, Z.; Xue, L.; Zhang, J.; Lin, X.; Shen, X. Privacy-preserving keyword similarity search over encrypted spatial data in cloud computing. Internet Things J. 2021, 9, 6184–6198. [Google Scholar] [CrossRef]
- Song, F.; Qin, Z.; Liu, D.; Zhang, J.; Lin, X.; Shen, X. Privacy-preserving task matching with threshold similarity search via vehicular crowdsourcing. Trans. Veh. Technol. 2021, 70, 7161–7175. [Google Scholar] [CrossRef]
- Plenz, M.; Dong, C.; Grumm, F.; Meyer, M.F.; Schumann, M.; McCulloch, M.; Jia, H.; Schulz, D. Framework Integrating Lossy Compression and Perturbation for the Case of Smart Meter Privacy. Electronics 2020, 9, 465. [Google Scholar] [CrossRef] [Green Version]
- Tightiz, L.; Yang, H. A Comprehensive Review on IoT Protocols’ Features in Smart Grid Communication. Energies 2020, 13, 2762. [Google Scholar] [CrossRef]
- Huang, X.; Hu, T.; Ye, C.; Xu, G.; Wang, X.; Chen, L. Electric Load Data Compression and Classification Based on Deep Stacked Auto-Encoders. Energies 2019, 12, 653. [Google Scholar] [CrossRef] [Green Version]
- Unterweger, A.; Engel, D. Resumable load data compression in smart grids. IEEE Trans. Smart Grid 2014, 6, 919–929. [Google Scholar] [CrossRef]
- Tong, X.; Kang, C.; Xia, Q. Smart metering load data compression based on load feature identification. Trans. Smart Grid 2016, 7, 2414–2422. [Google Scholar] [CrossRef]
- Sarkar, S.J.; Kundu, P.K.; Sarkar, G. Performance Analysis of Resumable Load Data Compression Algorithm (RLDA) for Power System Operational Data. In Proceedings of the Calcutta Conference (CALCON), Kolkata, India, 2–3 December 2017; pp. 16–20. [Google Scholar]
- Wang, Y.; Chen, Q.; Kang, C. Sparse and redundant representation-based smart meter data compression and pattern extraction. Trans. Power Systems 2016, 32, 2142–2151. [Google Scholar] [CrossRef]
- Wang, L.; Chen, Z.; Yin, F. A novel hierarchical decomposition vector quantization method for high-order LPC parameters. Trans. Audio Speech Lang. Process. 2014, 23, 212–221. [Google Scholar] [CrossRef]
- Watson, A.B. DCT quantization matrices visually optimized for individual images. Hum. Vision Vis. Process. Digit. Disp. IV SPIE 1993, 1913, 202–216. [Google Scholar]
- Ning, J.; Wang, J.; Gao, W.; Liu, C. A wavelet-based data compression technique for smart grid. Trans. Smart Grid 2010, 2, 212–218. [Google Scholar] [CrossRef]
- Das, S.; Rao, P.S.N. Principal Component Analysis Based Compression Scheme for Power System Steady State Operational Data. In Proceedings of the International Conference on Innovative Smart Grid Technologies, ISGT2011-India, Kollam, India, 1–3 December 2011; pp. 98–100. [Google Scholar]
- Mehra, R.; Bhatt, N.; Kazi, F.; Singh, N.M. Analysis of PCA based compression and denoising of smart grid data under normal and fault conditions. In Proceedings of the International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2013; pp. 1–6. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Witten, I.H.; Neal, R.M.; Cleary, J.G. Arithmetic coding for data compression. Commun. ACM 1987, 30, 520–540. [Google Scholar] [CrossRef]
- Ringwelski, M.; Renner, C.; Reinhardt, A.; Weigel, A.; Turau, V. The Hitchhiker’s guide to choosing the compression algorithm for your smart meter data. In Proceedings of the International Energy Conference and Exhibition (ENERGYCON), Florence, Italy, 2–9 September 2012; pp. 935–940. [Google Scholar]
- Das, S.; Rao, P.S.N. Arithmetic coding based lossless compression schemes for power system steady state operational data. Int. J. Electr. Power Energy Syst. 2012, 43, 47–53. [Google Scholar] [CrossRef]
- Sarkar, S.J.; Sarkar, N.K.; Banerjee, A. A novel Huffman coding based approach to reduce the size of large data array. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; pp. 1–5. [Google Scholar]
- Sarkar, S.J.; Kar, K.; Das, I. Basic arithmetic coding based approach for compressing generation scheduling data array. In Proceedings of the Calcutta Conference (CALCON), Kolkata, India, 2–3 December 2017; pp. 21–25. [Google Scholar]
- Khan, J.; Bhuiyan, S.M.A.; Murphy, G.; Arline, M. Embedded-zerotree-wavelet-based data denoising and compression for smart grid. Trans. Ind. Appl. 2015, 51, 4190–4200. [Google Scholar] [CrossRef]
- Khan, J.; Bhuiyan, S.; Murphy, G.; Murphy, G. Data denoising and compression for smart grid communication. IEEE Trans. Signal Inf. Process. Over Netw. 2016, 2, 200–214. [Google Scholar] [CrossRef]
- Ji, X.; Zhang, F.; Cheng, L.; Liang, C.; He, H. A wavelet-based universal data compression method for different types of signals in power systems. In Proceedings of the Power & Energy Society General Meeting (PESGM), Chicago, IL, USA, 16–20 July 2017; pp. 1–5. [Google Scholar]
- Cheng, L.; Ji, X.; Zhang, F.; Huang, H.; Gao, S. Wavelet-based data compression for wide-area measurement data of oscillations. J. Mod. Power Syst. Clean Energy 2018, 6, 1128–1140. [Google Scholar] [CrossRef] [Green Version]
- Prathibha, E.; Manjunatha, A.; Basavaraj, S. Dual tree complex wavelet transform based approach for power quality monitoring and data compression. In Proceedings of the 2016 Biennial International Conference on Power and Energy Systems: Towards Sustainable Energy (PESTSE), Bengaluru, India, 21–23 January 2016; pp. 1–5. [Google Scholar]
- Ruiz, M.; Simani, S.; Inga, E.; Jaramillo, M. A novel algorithm for high compression rates focalized on electrical power quality signals. Heliyon 2021, 7, e06475. [Google Scholar] [CrossRef] [PubMed]
- Gontijo, L.F.C.; André, N.O.; Nascimento, F.A.O. Segmentation and Entropy Coding Analysis of a Data Compression System for Power Quality Disturbances. In Proceedings of the 2020 Workshop on Communication Networks and Power Systems (WCNPS), Brasilia, Brazil, 12–13 November 2020; pp. 1–6. [Google Scholar]
- Wang, W.; Chen, C.; Yao, W.; Sun, K.; Qiu, W.; Liu, L. Synchrophasor Data Compression Under Disturbance Conditions via Cross-Entropy-Based Singular Value Decomposition. Trans. Ind. Inform. 2020, 17, 2716–2726. [Google Scholar] [CrossRef]
- Karthika, S.; Rathika, P. An Efficient Data Compression Algorithm for Smart Distribution Systems using Singular Value Decomposition. In Proceedings of the International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Tamilnadu, India, 11–13 April 2019; pp. 1–7. [Google Scholar]
- Sarkar, S.J.; Kundu, P.K.; Sarkar, G. DBEA: A novel approach of repetitive data array compression for power system application. In Proceedings of the International Conference for Convergence in Technology (I2CT), Kolkata, India, 7–9 April 2017; pp. 16–20. [Google Scholar]
- Sarkar, S.J.; Kundu, P.K.; Sarkar, G. Development of lossless compression algorithms for power system operational data. IET Gener. Transm. Distrib. 2018, 12, 4045–4052. [Google Scholar] [CrossRef]
- Sarkar, S.J.; Kundu, P.K.; Sarkar, G. Comparison of Different Differential Coding based Algorithms Developed for Compressing Power System Operational Data. In Proceedings of the Region 10 Symposium (TENSYMP), Kolkata, India, 14–16 July 2017; pp. 16–20. [Google Scholar]
- Abuadbba, A.; Khalil, I.; Yu, X. Gaussian approximation-based lossless compression of smart meter readings. Trans. Smart Grid 2017, 9, 5047–5056. [Google Scholar] [CrossRef]
- Tripathi, S.; De, S. An efficient data characterization and reduction scheme for smart metering infrastructure. Trans. Ind. Inform. 2018, 14, 4300–4308. [Google Scholar] [CrossRef]
- Goyal, M.; Tatwawadi, K.; Chandak, S.; Ochoa, I. DeepZip: Lossless Data Compression Using Recurrent Neural Networks. In Proceedings of the Data Compression Conference (DCC), Madrid, Spain, 26–29 March 2019. [Google Scholar]
- Liu, Q.; Xu, Y.; Li, Z. DecMac: A Deep Context Model for High Efficiency Arithmetic Coding. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 438–443. [Google Scholar]
- Wang, R.; Bai, Y.; Chu, Y.S.; Wang, Z.; Wang, Y.; Sun, M.; Li, J.; Zang, T.; Wang, Y. DeepDNA: A hybrid convolutional and recurrent neural network for compressing human mitochondrial genomes. In Proceedings of the International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 270–274. [Google Scholar]
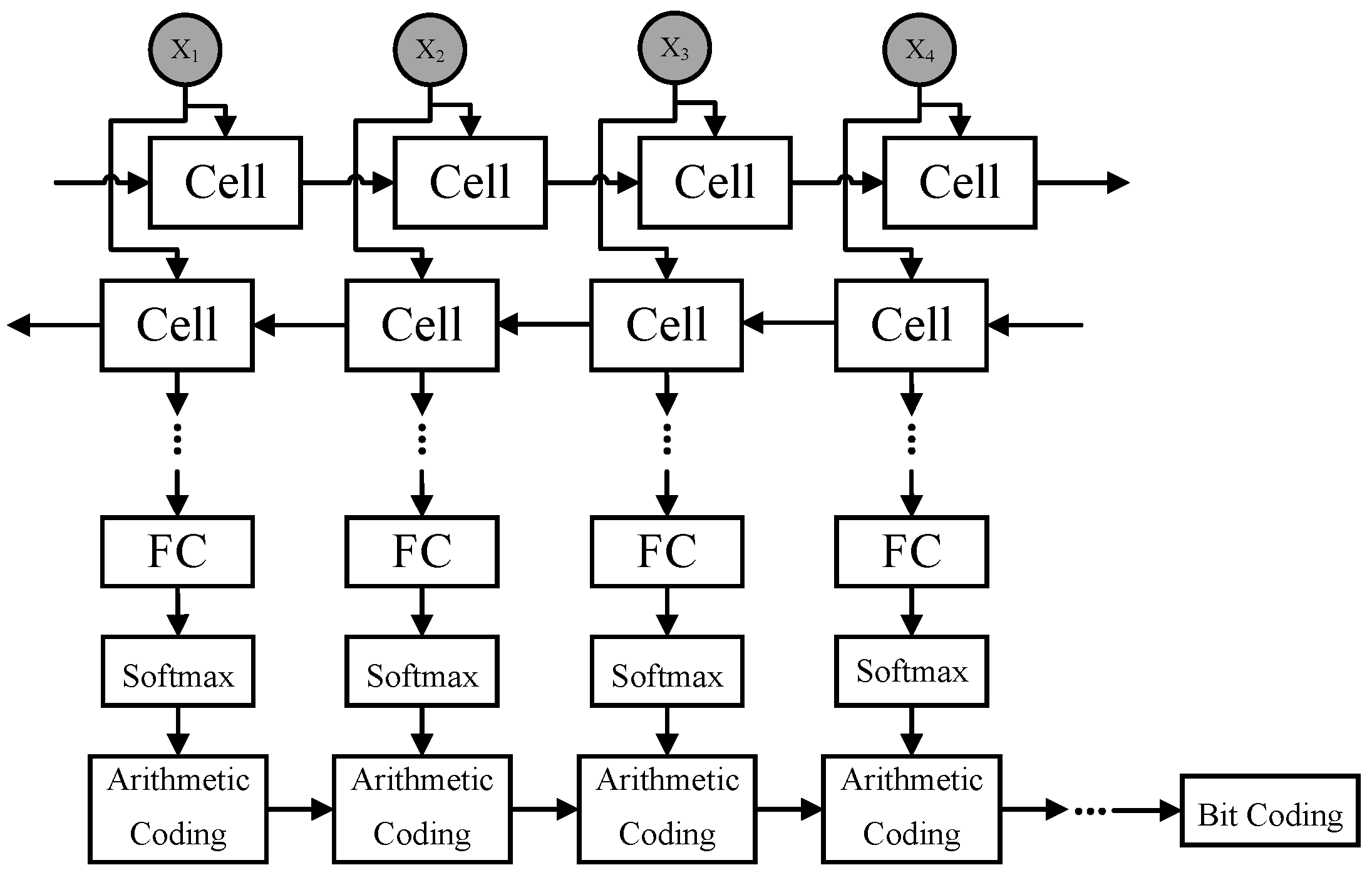
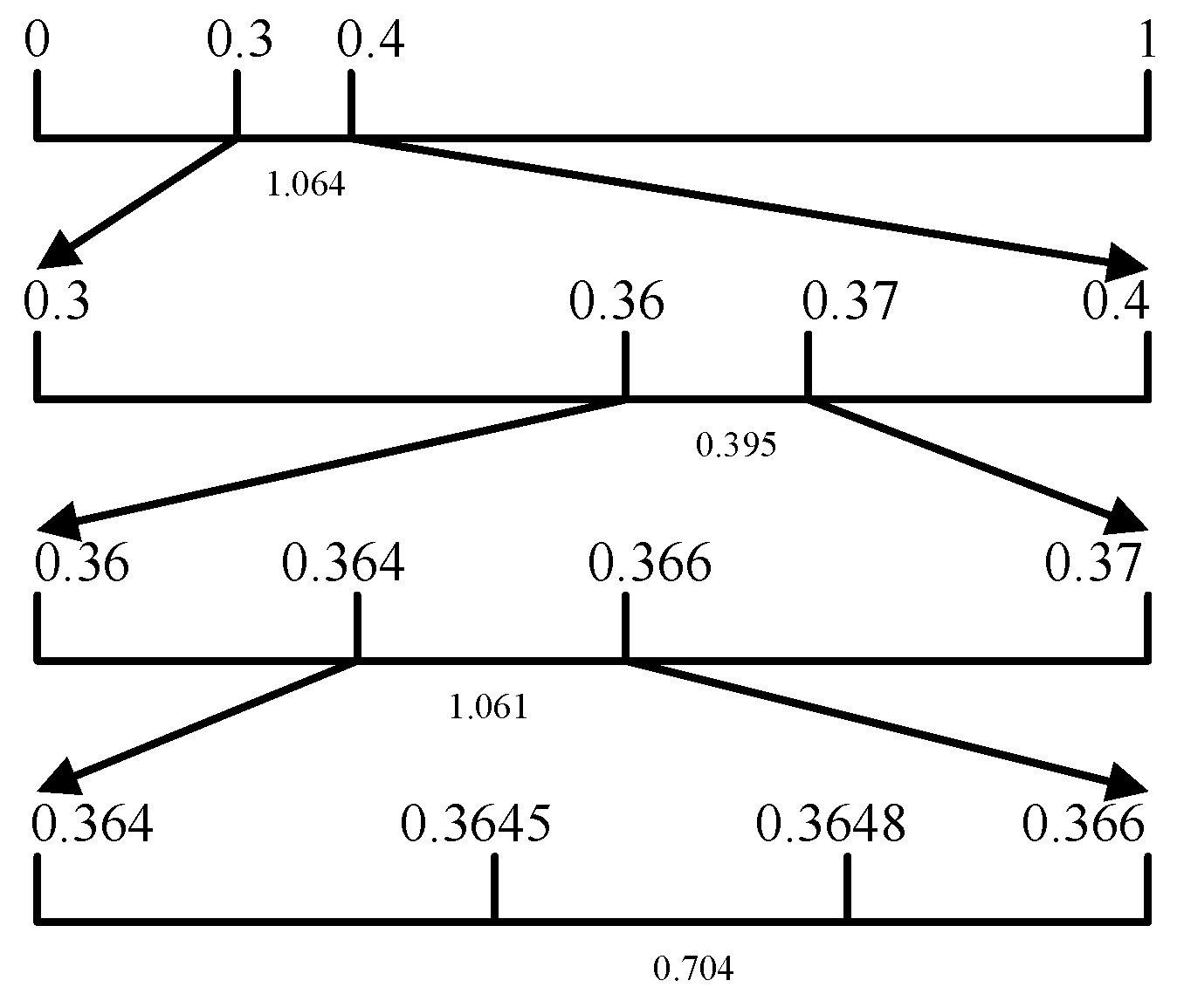
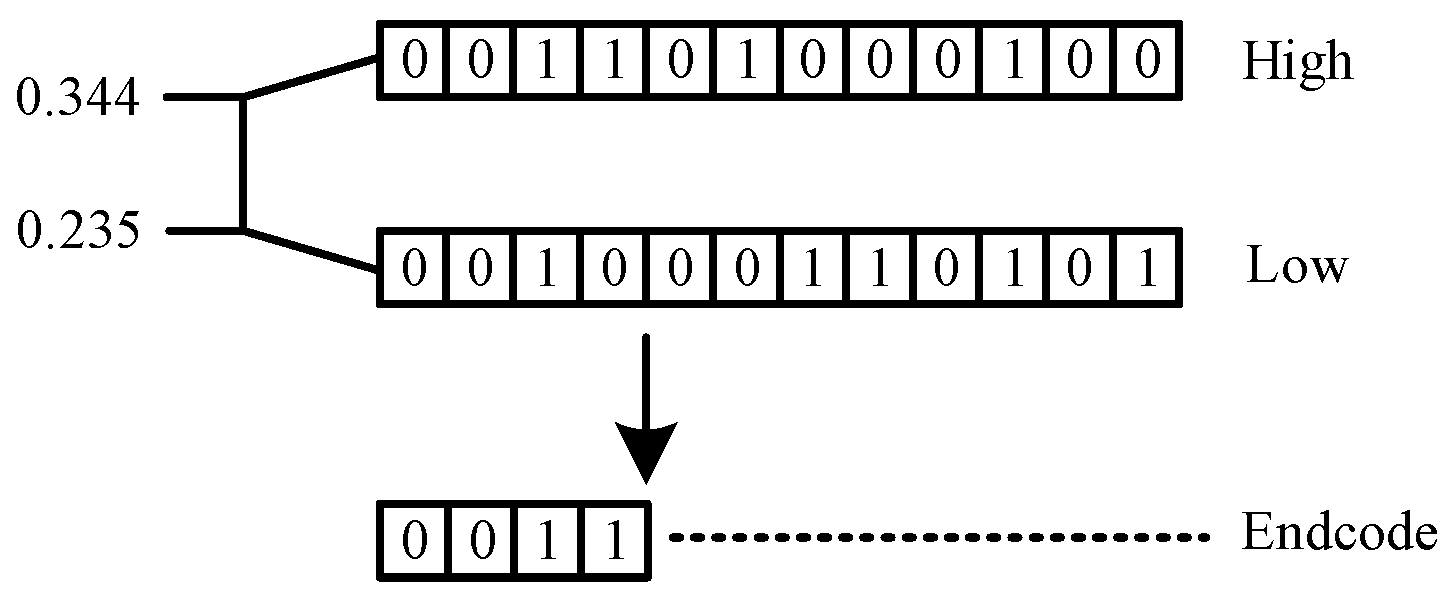


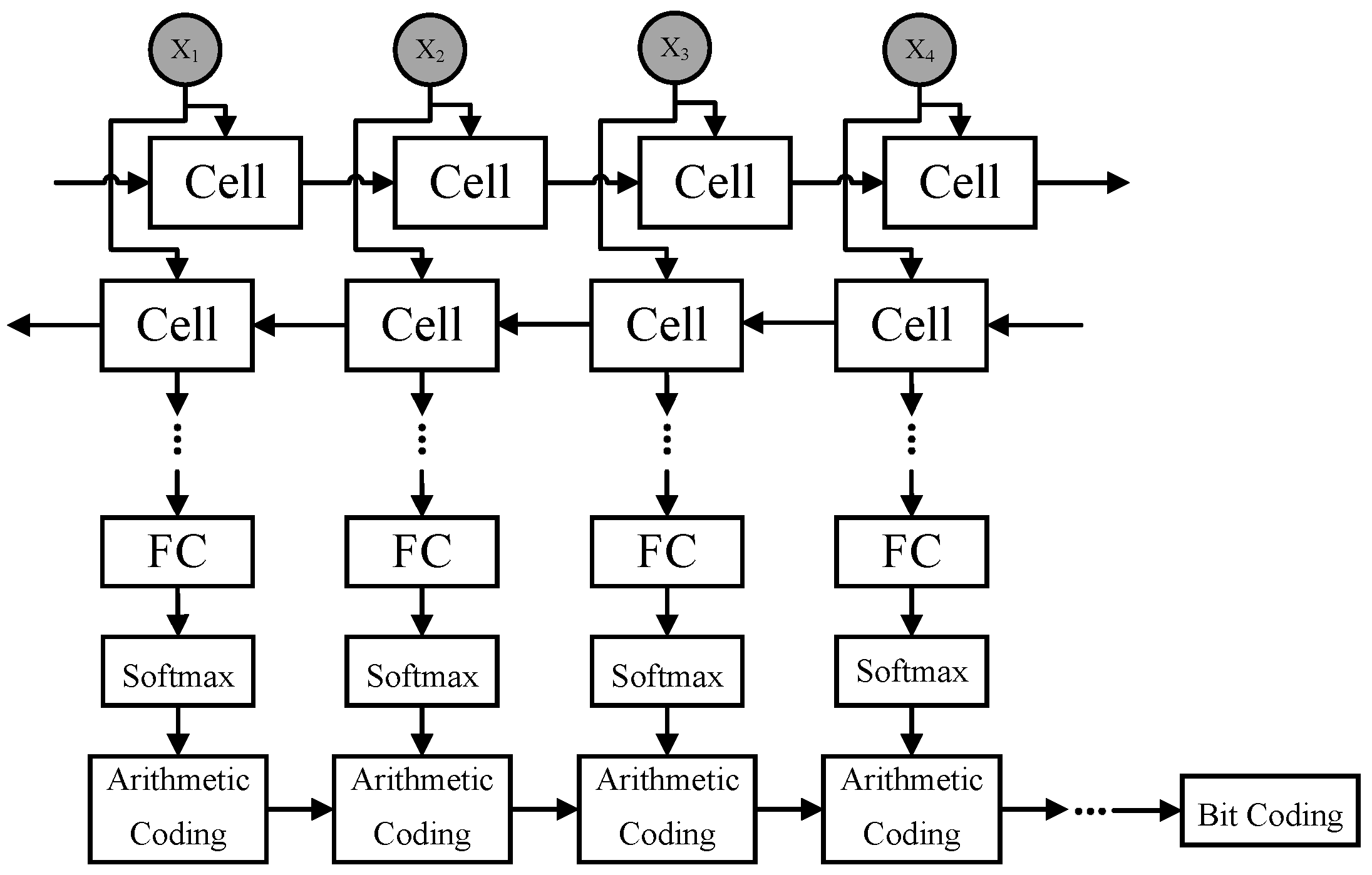{kind=link}
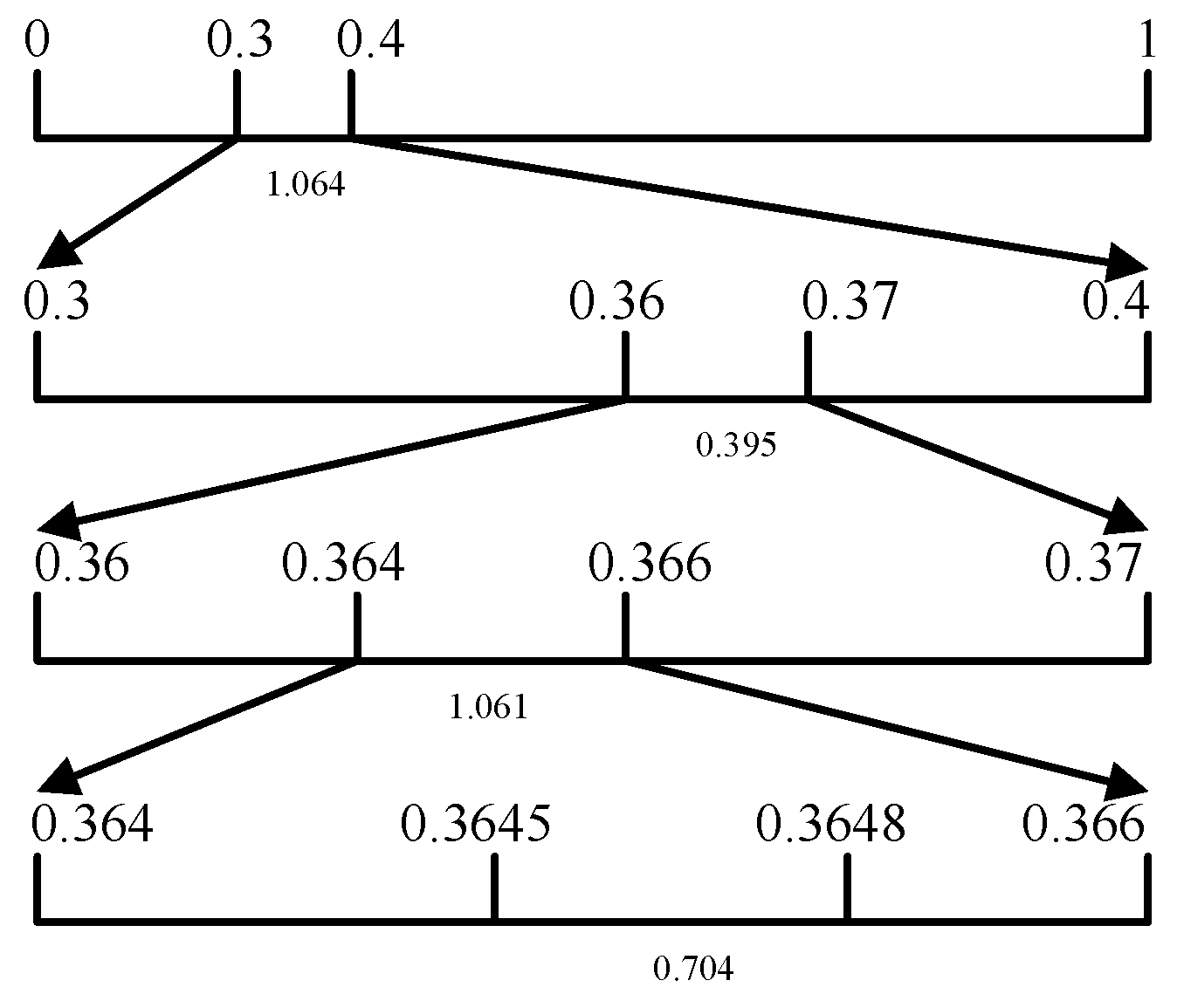{kind=link}
{kind=link}
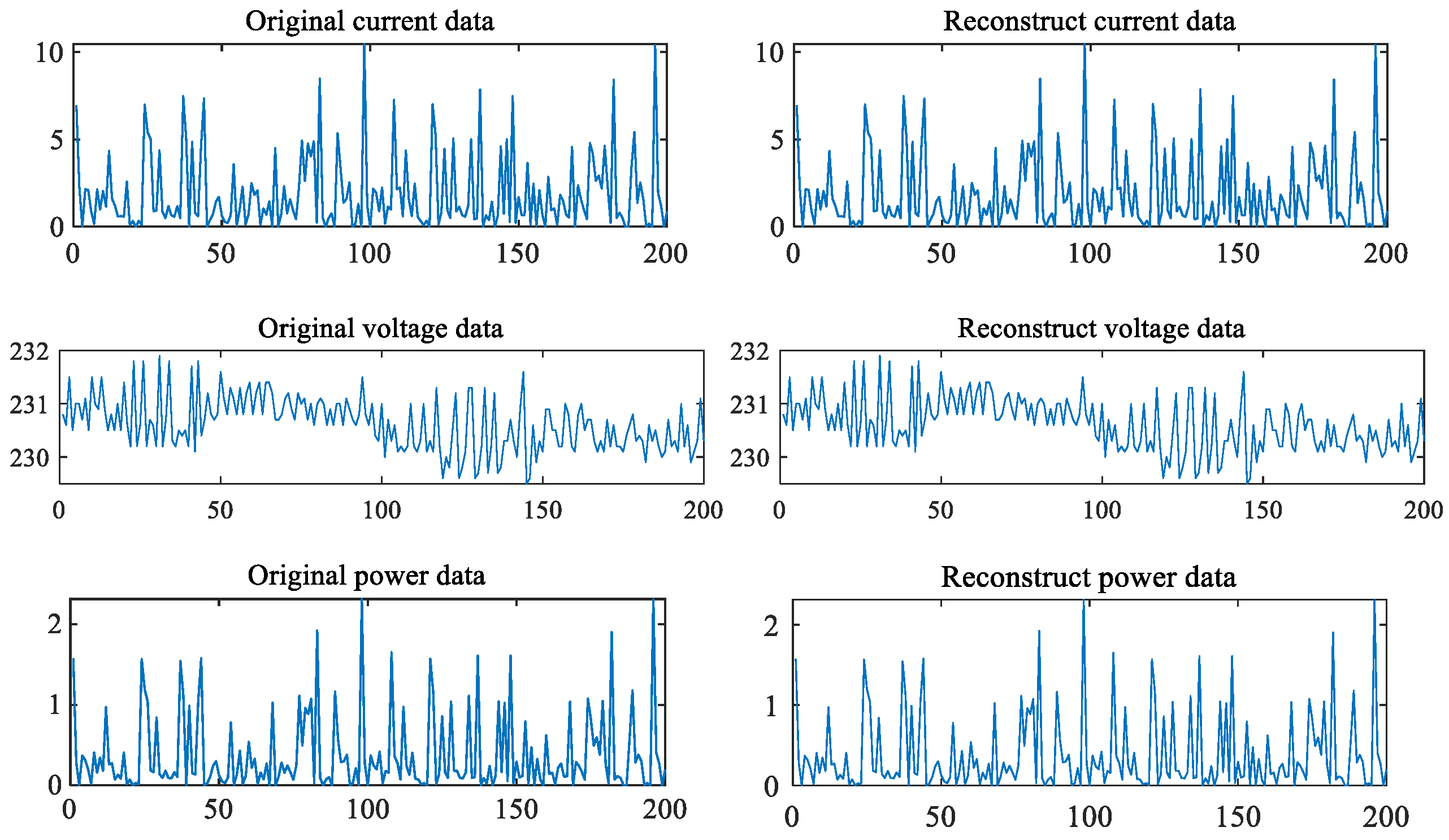{kind=link}
| Layers | Process | Output Size |
|---|---|---|
| Layer 1 | Embedding | [128, 50, 50] |
| Layer 2 | Bi-LSTM | [128, 50, 32] |
| Layer 3 | Bi-LSTM | [128, 32] |
| Layer 4 | FC | [128, 16] |
| Layer 5 | FC | [128, 7820] |
| Model | Bi-LSTM | Transformer | ||||
|---|---|---|---|---|---|---|
| Voltage | Current | Power | Voltage | Current | Power | |
| Original size(in bytes) | 922 | 888 | 1007 | 922 | 888 | 1007 |
| Compressed size(in bytes) | 174 | 276 | 304 | 167 | 296 | 317 |
| CR | 5.30 | 3.22 | 3.31 | 5.52 | 3.00 | 3.18 |
| Algorithm | Ours | AC [24] | Huffman [23] |
|---|---|---|---|
| CR | 4.06 | 3.31 | 1.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Zhu, H.; He, Z.; Lu, Y.; Song, F. Deep Lossless Compression Algorithm Based on Arithmetic Coding for Power Data. Sensors 2022, 22, 5331. https://doi.org/10.3390/s22145331
Ma Z, Zhu H, He Z, Lu Y, Song F. Deep Lossless Compression Algorithm Based on Arithmetic Coding for Power Data. Sensors. 2022; 22(14):5331. https://doi.org/10.3390/s22145331
Chicago/Turabian StyleMa, Zhoujun, Hong Zhu, Zhuohao He, Yue Lu, and Fuyuan Song. 2022. "Deep Lossless Compression Algorithm Based on Arithmetic Coding for Power Data" Sensors 22, no. 14: 5331. https://doi.org/10.3390/s22145331
APA StyleMa, Z., Zhu, H., He, Z., Lu, Y., & Song, F. (2022). Deep Lossless Compression Algorithm Based on Arithmetic Coding for Power Data. Sensors, 22(14), 5331. https://doi.org/10.3390/s22145331