
Data-Driven Machine-Learning Methods for Diabetes Risk Prediction



Abstract
:1. Introduction
- Type I diabetes or juvenile diabetes: In this type, insulin-producing pancreatic cells are destroyed by an autoimmune mechanism (that is, by antibodies produced by the body itself). It mainly affects young people, insulin is completely absent, and the patient requires insulin therapy from the beginning [2].
- Type II diabetes: It is characterized by increased resistance of the body to insulin with the result that what is produced is not sufficient to meet the metabolic needs of the body. Type 2 diabetes is the most common cause of diabetes in adults. An important predisposing factor for the development of type 2 diabetes is obesity. Other predisposing factors are age and family history. If necessary, anti-diabetic drugs are used. In case the treatment fails, it is recommended to administer insulin to control these patients as well [3].
- Gestational diabetes: It is a type of diabetes that first appears during pregnancy (excluding women with pre-pregnancy diabetes). This type is similar to type 2 diabetes. Obese women are more likely to develop gestational diabetes. Gestational diabetes is reversible and resolves after childbirth but can cause perinatal complications and maternal and neonatal health problems [4].
2. Related Work
3. Materials and Methods
3.1. Dataset Description
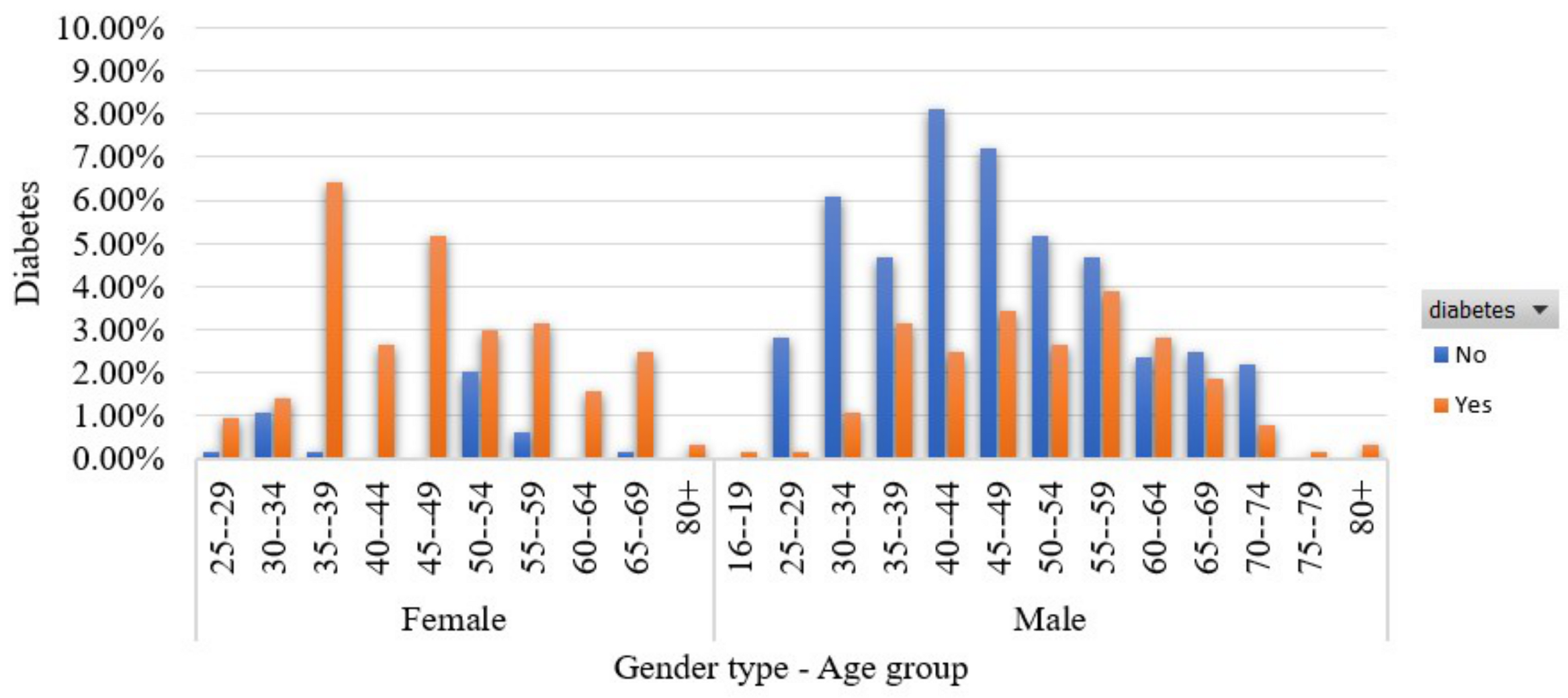
- Age (years) [37]: This feature captures the participant’s age.
- Gender [38]: This feature refers participant’s gender. The number of men is 328 (63.1%) while the number of women is 192 (36.9%).
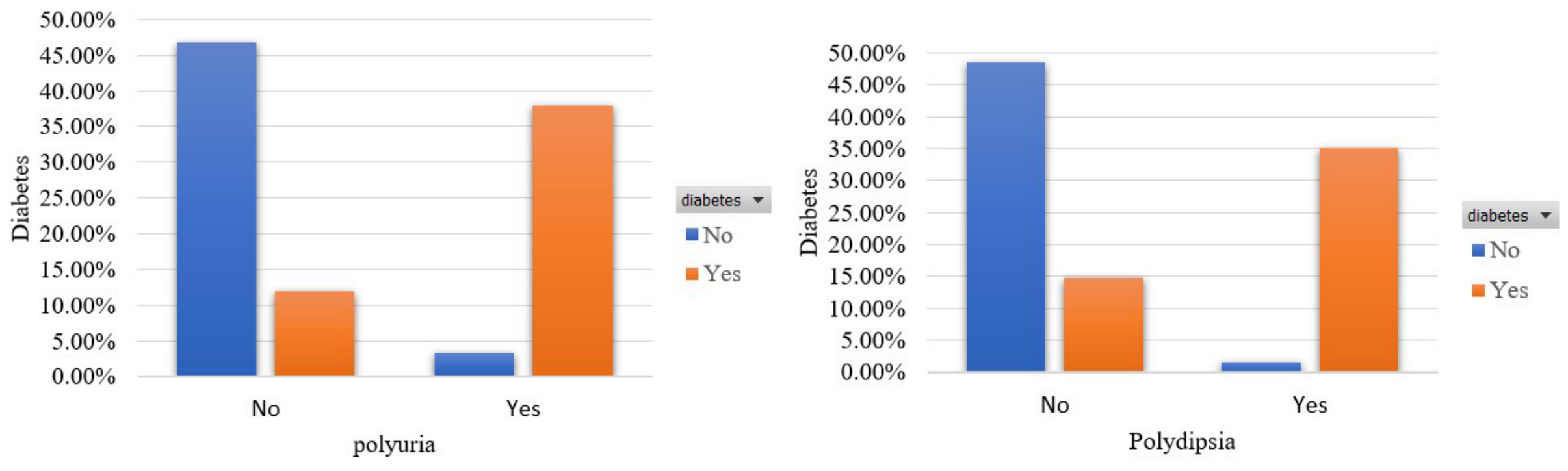
- Polyuria [39]: This feature captures whether the participant experienced excessive urination or not. The percentage of participants who had excessive urination is 49.6%.
- Polydipsia [39]: This feature captures whether the participant experienced excessive thirst/excess drinking or not. The percentage of participants who experienced excessive thirst/excessive alcohol consumption is 44.8%.
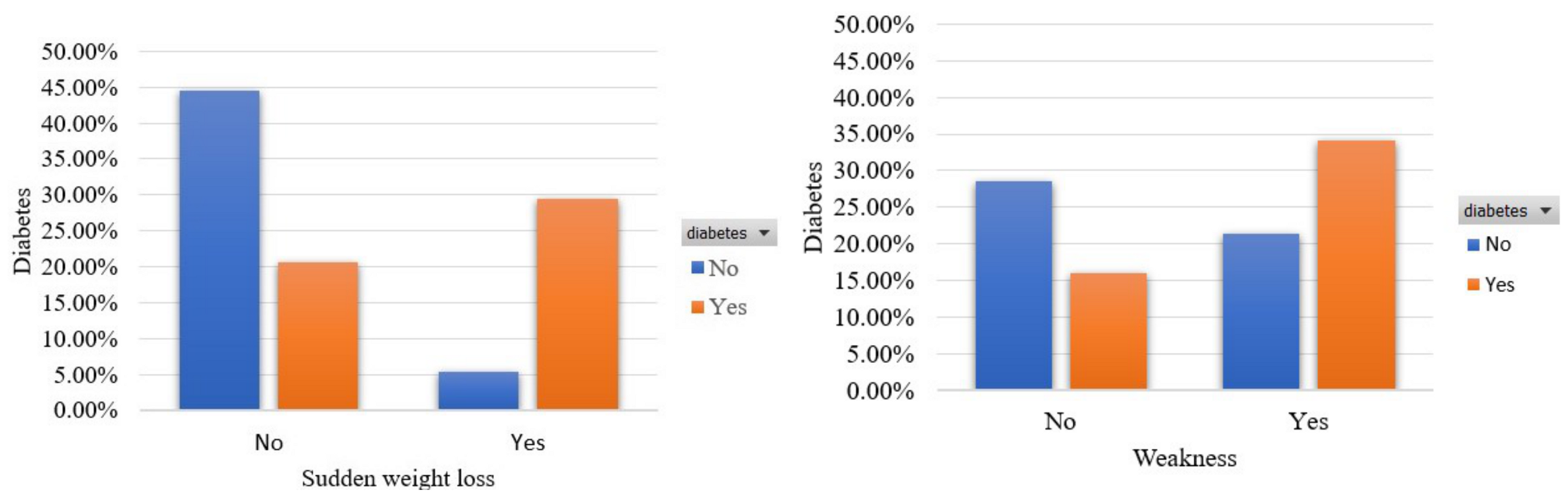
- Sudden weight loss [40]: This feature captures whether the participant had an episode of sudden weight loss or not. The percentage of participants who had an episode of sudden weight loss is 41.7%.
- Weakness [41]: This feature captures whether the participant had an episode of feeling weak. The percentage of participants who had an episode of feeling weak is 58.6%.
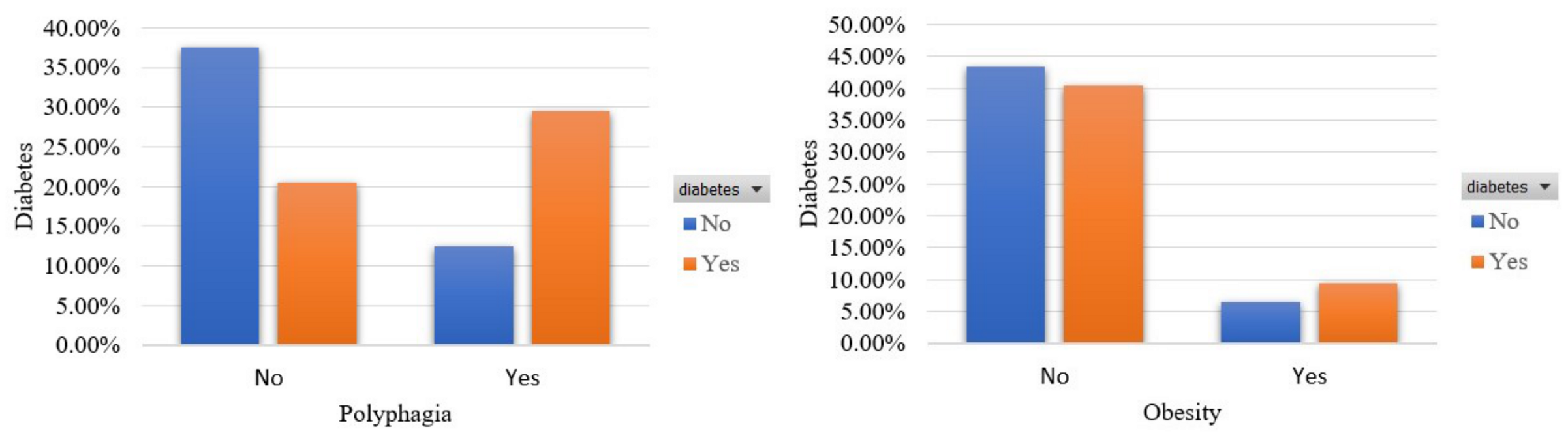
- Polyphagia [42]: This feature captures whether the participant had an episode of excessive/extreme hunger or not. The percentage of participants who had an episode of excessive/extreme hunger is 45.6%.
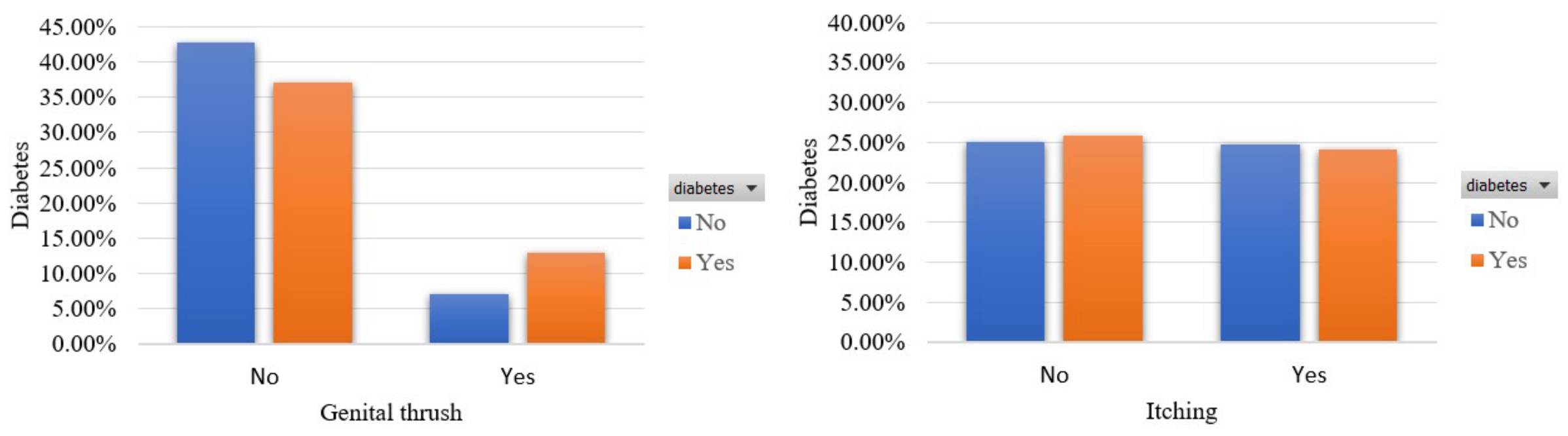
- Genital thrush [43]: This feature captures whether the participant had a yeast infection or not. The percentage of participants who had a yeast infection is 22.3%.
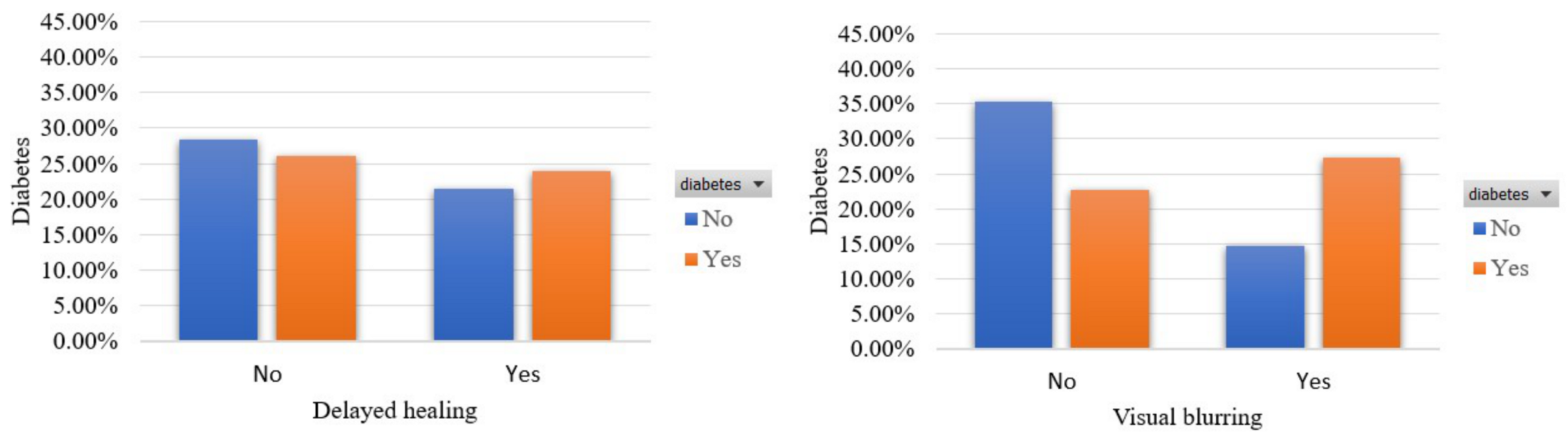
- Visual blurring [44]: This feature captures whether the participant had an episode of blurred vision or not. The percentage of participants who had an episode of blurred vision is 44.8%.
- Itching [45]: This feature captures whether the participant had an episode of itch. The percentage of participants who had an episode of itching is 48.7%.
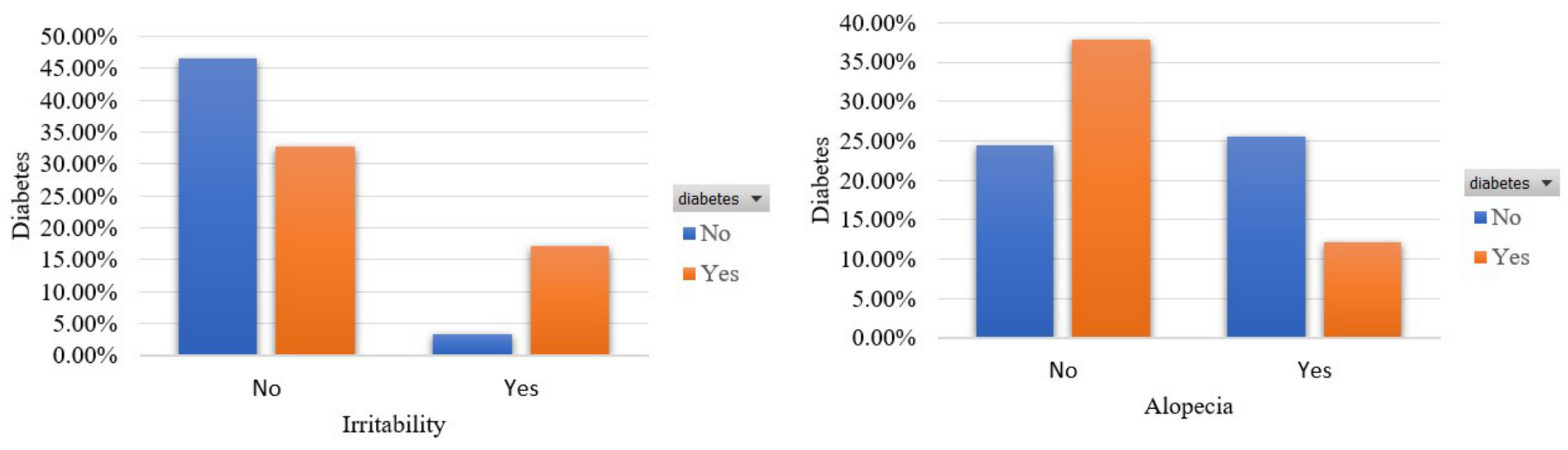
- Irritability [46]: This feature captures whether the participant had an episode of irritability. The percentage of participants who had an episode of irritability is 24.2%.
- Delayed healing [47]: This feature captures whether the participant had a noticed delayed healing when wounded or not. The percentage of participants who had noticed delayed healing when wounded is 46%.
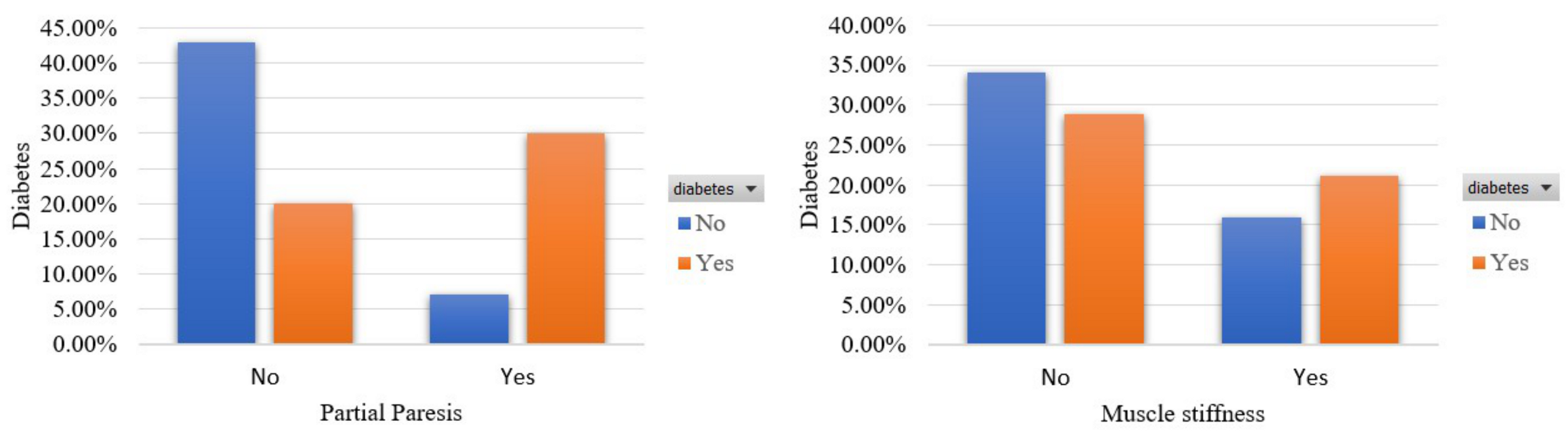
- Partial paresis [48]: This feature captures whether the participant had an episode of weakening of a muscle/group of muscles or not. The percentage of participants who had an episode of weakening of a muscle/group of muscles is 43.1%.
- Muscle stiffness [49]: This feature captures whether the participant had an episode of muscle stiffness. The percentage of participants who had an episode of muscle stiffness is 37.5%.
- Alopecia [50]: This feature captures whether the participant experienced hair loss or not. The percentage of participants who experienced hair loss is 34.4%.
- Obesity [51]: This feature captures whether the participant can be considered obese or not. The percentage of participants who are considered obese is 16.9%.
- Diabetes: This feature refers to whether the participant has been diagnosed with diabetes type 2 or not. The percentage of participants who suffer from diabetes type 2 is 61.5%.
3.2. Diabetes Risk Prediction
3.2.1. Data Preprocessing
3.2.2. Features Importance
3.2.3. Features Exploration
3.3. Machine-Learning Models
3.3.1. Naive Bayes
3.3.2. Bayesian Network
3.3.3. Support Vector Machine
3.3.4. Logistic Regression
3.3.5. Artificial Neural Network
3.3.6. K-Nearest Neighbors
3.3.7. J48
3.3.8. Logistic Model Tree
3.3.9. Random Forest
3.3.10. Reduced Error Pruning Tree
3.3.11. Random Trees
3.3.12. Rotation Forest
3.3.13. AdaBoostM1
3.3.14. Stochastic Gradient Descent
3.3.15. Stacking
3.4. Evaluation Metrics
4. Results and Discussion
4.1. Experiments Setup
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zimmet, P.Z.; Magliano, D.J.; Herman, W.H.; Shaw, J.E. Diabetes: A 21st century challenge. Lancet Diabetes Endocrinol. 2014, 2, 56–64. [Google Scholar] [CrossRef]
- Atkinson, M.A.; Eisenbarth, G.S.; Michels, A.W. Type 1 diabetes. Lancet 2014, 383, 69–82. [Google Scholar] [CrossRef] [Green Version]
- Chatterjee, S.; Khunti, K.; Davies, M.J. Type 2 diabetes. Lancet 2017, 389, 2239–2251. [Google Scholar] [CrossRef]
- McIntyre, H.D.; Catalano, P.; Zhang, C.; Desoye, G.; Mathiesen, E.R.; Damm, P. Gestational diabetes mellitus. Nat. Rev. Dis. Prim. 2019, 5, 47. [Google Scholar] [CrossRef]
- Ramachandran, A. Know the signs and symptoms of diabetes. Indian J. Med Res. 2014, 140, 579. [Google Scholar]
- Wu, Y.; Ding, Y.; Tanaka, Y.; Zhang, W. Risk factors contributing to type 2 diabetes and recent advances in the treatment and prevention. Int. J. Med Sci. 2014, 11, 1185. [Google Scholar] [CrossRef] [Green Version]
- Bellou, V.; Belbasis, L.; Tzoulaki, I.; Evangelou, E. Risk factors for type 2 diabetes mellitus: An exposure-wide umbrella review of meta-analyses. PLoS ONE 2018, 13, e0194127. [Google Scholar] [CrossRef]
- Kumar, A.; Bharti, S.K.; Kumar, A. Type 2 diabetes mellitus: The concerned complications and target organs. Apollo Med. 2014, 11, 161–166. [Google Scholar] [CrossRef]
- Daryabor, G.; Atashzar, M.R.; Kabelitz, D.; Meri, S.; Kalantar, K. The effects of type 2 diabetes mellitus on organ metabolism and the immune system. Front. Immunol. 2020, 11, 1582. [Google Scholar] [CrossRef]
- Uusitupa, M.; Khan, T.A.; Viguiliouk, E.; Kahleova, H.; Rivellese, A.A.; Hermansen, K.; Pfeiffer, A.; Thanopoulou, A.; Salas-Salvadó, J.; Schwab, U.; et al. Prevention of type 2 diabetes by lifestyle changes: A systematic review and meta-analysis. Nutrients 2019, 11, 2611. [Google Scholar] [CrossRef] [Green Version]
- Kyrou, I.; Tsigos, C.; Mavrogianni, C.; Cardon, G.; Van Stappen, V.; Latomme, J.; Kivelä, J.; Wikström, K.; Tsochev, K.; Nanasi, A.; et al. Sociodemographic and lifestyle-related risk factors for identifying vulnerable groups for type 2 diabetes: A narrative review with emphasis on data from Europe. BMC Endocr. Disord. 2020, 20, 134. [Google Scholar] [CrossRef] [Green Version]
- Huang, I.; Lim, M.A.; Pranata, R. Diabetes mellitus is associated with increased mortality and severity of disease in COVID-19 pneumonia–a systematic review, meta-analysis, and meta-regression. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 395–403. [Google Scholar] [CrossRef]
- Fazakis, N.; Dritsas, E.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Cholesterol Risk Prediction with Machine Learning Techniques in ELSA Database. In Proceedings of the 13th International Joint Conference on Computational Intelligence (IJCCI), Valletta, Malta, 25–27 October 2021; pp. 445–450. [Google Scholar]
- Dritsas, E.; Fazakis, N.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Hypertension Risk Prediction with ML Techniques in ELSA Database. In Proceedings of the International Conference on Learning and Intelligent Optimization, Athens, Greece, 20–25 June 2021; Springer: Cham, Switzerland, 2021; pp. 113–120. [Google Scholar]
- Moll, M.; Qiao, D.; Regan, E.A.; Hunninghake, G.M.; Make, B.J.; Tal-Singer, R.; McGeachie, M.J.; Castaldi, P.J.; Estepar, R.S.J.; Washko, G.R.; et al. Machine learning and prediction of all-cause mortality in COPD. Chest 2020, 158, 952–964. [Google Scholar] [CrossRef]
- Alexiou, S.; Dritsas, E.; Kocsis, O.; Moustakas, K.; Fakotakis, N. An approach for Personalized Continuous Glucose Prediction with Regression Trees. In Proceedings of the 2021 sixth South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Preveza, Greece, 24–26 September 2021; pp. 1–6. [Google Scholar]
- Dritsas, E.; Alexiou, S.; Konstantoulas, I.; Moustakas, K. Short-term Glucose Prediction based on Oral Glucose Tolerance Test Values. In Proceedings of the International Joint Conference on Biomedical Engineering Systems and Technologies—HEALTHINF, Online. 9–11 February 2022; Volume 5, pp. 249–255. [Google Scholar]
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. NPJ Digit. Med. 2021, 4, 3. [Google Scholar] [CrossRef]
- Dritsas, E.; Alexiou, S.; Moustakas, K. Cardiovascular Disease Risk Prediction with Supervised Machine Learning Techniques. In Proceedings of the eighth International Conference on Information and Communication Technologies for Ageing Well and e-Health, ICT4AWE, Online, 23–25 April 2022; pp. 315–321. [Google Scholar]
- Dritsas, E.; Trigka, M. Stroke Risk Prediction with Machine Learning Techniques. Sensors 2022, 22, 4670. [Google Scholar] [CrossRef]
- Wang, W.; Chakraborty, G.; Chakraborty, B. Predicting the risk of chronic kidney disease (ckd) using machine learning algorithm. Appl. Sci. 2020, 11, 202. [Google Scholar] [CrossRef]
- Speiser, J.L.; Karvellas, C.J.; Wolf, B.J.; Chung, D.; Koch, D.G.; Durkalski, V.L. Predicting daily outcomes in acetaminophen-induced acute liver failure patients with machine learning techniques. Comput. Methods Programs Biomed. 2019, 175, 111–120. [Google Scholar] [CrossRef]
- Konstantoulas, I.; Kocsis, O.; Dritsas, E.; Fakotakis, N.; Moustakas, K. Sleep Quality Monitoring with Human Assisted Corrections. In Proceedings of the International Joint Conference on Computational Intelligence (IJCCI), Valletta, Malta, 25–27 October 2021; pp. 435–444. [Google Scholar]
- Yarasuri, V.K.; Indukuri, G.K.; Nair, A.K. Prediction of hepatitis disease using machine learning technique. In Proceedings of the 2019 Third International conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 12–14 December 2019; pp. 265–269. [Google Scholar]
- Saba, T. Recent advancement in cancer detection using machine learning: Systematic survey of decades, comparisons and challenges. J. Infect. Public Health 2020, 13, 1274–1289. [Google Scholar] [CrossRef]
- Hasan, M.K.; Alam, M.A.; Das, D.; Hossain, E.; Hasan, M. Diabetes prediction using ensembling of different machine learning classifiers. IEEE Access 2020, 8, 76516–76531. [Google Scholar] [CrossRef]
- Kaur, H.; Kumari, V. Predictive modelling and analytics for diabetes using a machine learning approach. Appl. Comput. Inform. 2020, 18, 90–100. [Google Scholar] [CrossRef]
- Kopitar, L.; Kocbek, P.; Cilar, L.; Sheikh, A.; Stiglic, G. Early detection of type 2 diabetes mellitus using machine learning-based prediction models. Sci. Rep. 2020, 10, 11981. [Google Scholar] [CrossRef]
- Tigga, N.P.; Garg, S. Prediction of type 2 diabetes using machine learning classification methods. Procedia Comput. Sci. 2020, 167, 706–716. [Google Scholar] [CrossRef]
- Maniruzzaman, M.; Rahman, M.; Ahammed, B.; Abedin, M. Classification and prediction of diabetes disease using machine learning paradigm. Health Inf. Sci. Syst. 2020, 8, 7. [Google Scholar] [CrossRef]
- Fazakis, N.; Kocsis, O.; Dritsas, E.; Alexiou, S.; Fakotakis, N.; Moustakas, K. Machine learning tools for long-term type 2 diabetes risk prediction. IEEE Access 2021, 9, 103737–103757. [Google Scholar] [CrossRef]
- Islam, M.; Ferdousi, R.; Rahman, S.; Bushra, H.Y. Likelihood prediction of diabetes at early stage using data mining techniques. In Computer Vision and Machine Intelligence in Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2020; pp. 113–125. [Google Scholar]
- Alpan, K.; İlgi, G.S. Classification of diabetes dataset with data mining techniques by using WEKA approach. In Proceedings of the 2020 fourth International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; pp. 1–7. [Google Scholar]
- Patel, S.; Patel, R.; Ganatra, N.; Patel, A. Predicting a risk of diabetes at early stage using machine learning approach. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 5277–5284. [Google Scholar]
- Elsadek, S.N.; Alshehri, L.S.; Alqhatani, R.A.; Algarni, Z.A.; Elbadry, L.O.; Alyahyan, E.A. Early Prediction of Diabetes Disease Based on Data Mining Techniques. In Proceedings of the International Conference on Computational Intelligence in Data Science, Chennai, India, 18–20 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 40–51. [Google Scholar]
- Early Classification of Diabetes. Available online: https://www.kaggle.com/datasets/andrewmvd/early-diabetes-classification (accessed on 25 June 2022).
- Yi, S.W.; Park, S.; Lee, Y.h.; Balkau, B.; Yi, J.J. Fasting glucose and all-cause mortality by age in diabetes: A prospective cohort study. Diabetes Care 2018, 41, 623–626. [Google Scholar] [CrossRef] [Green Version]
- Harreiter, J.; Kautzky-Willer, A. Sex and gender differences in prevention of type 2 diabetes. Front. Endocrinol. 2018, 9, 220. [Google Scholar] [CrossRef] [Green Version]
- Marks, B.E. Initial Evaluation of Polydipsia and Polyuria. In Endocrine Conditions in Pediatrics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 107–111. [Google Scholar]
- Hamman, R.F.; Wing, R.R.; Edelstein, S.L.; Lachin, J.M.; Bray, G.A.; Delahanty, L.; Hoskin, M.; Kriska, A.M.; Mayer-Davis, E.J.; Pi-Sunyer, X.; et al. Effect of weight loss with lifestyle intervention on risk of diabetes. Diabetes Care 2006, 29, 2102–2107. [Google Scholar] [CrossRef] [Green Version]
- Peterson, M.D.; Zhang, P.; Choksi, P.; Markides, K.S.; Al Snih, S. Muscle weakness thresholds for prediction of diabetes in adults. Sport. Med. 2016, 46, 619–628. [Google Scholar] [CrossRef] [Green Version]
- Batchelor, D.J.; German, A.J. Polyphagia. In BSAVA Manual of Canine and Feline Gastroenterology; BSAVA Library: Gloucester, UK, 2019; pp. 46–48. [Google Scholar]
- Schneider, C.R.; Moles, R.; El-Den, S. Thrush: Detection and management in community pharmacy. Pharm. J. R. Pharm. Soc. Publ. 2018, 2018, 1–10. [Google Scholar]
- Tamhankar, M.A. Transient Visual Loss or Blurring. In Liu, Volpe, and Galetta’s Neuro-Ophthalmology; Elsevier: Amsterdam, The Netherlands, 2019; pp. 365–377. [Google Scholar]
- Stefaniak, A.; Chlebicka, I.; Szepietowski, J. Itch in diabetes: A common underestimated problem. Adv. Dermatol. Allergol. Dermatol. I Alergol. 2019, 38, 177–183. [Google Scholar] [CrossRef]
- Barata, P.C.; Holtzman, S.; Cunningham, S.; O’Connor, B.P.; Stewart, D.E. Building a definition of irritability from academic definitions and lay descriptions. Emot. Rev. 2016, 8, 164–172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blakytny, R.; Jude, E. The molecular biology of chronic wounds and delayed healing in diabetes. Diabet. Med. 2006, 23, 594–608. [Google Scholar] [CrossRef] [PubMed]
- Andersen, H.; Nielsen, S.; Mogensen, C.E.; Jakobsen, J. Muscle strength in type 2 diabetes. Diabetes 2004, 53, 1543–1548. [Google Scholar] [CrossRef] [Green Version]
- Miyake, H.; Kanazawa, I.; Tanaka, K.I.; Sugimoto, T. Low skeletal muscle mass is associated with the risk of all-cause mortality in patients with type 2 diabetes mellitus. Ther. Adv. Endocrinol. Metab. 2019, 10, 2042018819842971. [Google Scholar] [CrossRef]
- Su, L.H.; Chen, L.S.; Lin, S.C.; Chen, H.H. Association of androgenetic alopecia with mortality from diabetes mellitus and heart disease. JAMA Dermatol. 2013, 149, 601–606. [Google Scholar] [CrossRef] [Green Version]
- Chobot, A.; Górowska-Kowolik, K.; Sokołowska, M.; Jarosz-Chobot, P. Obesity and diabetes—Not only a simple link between two epidemics. Diabetes/Metab. Res. Rev. 2018, 34, e3042. [Google Scholar] [CrossRef] [Green Version]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2019, 76, 380–389. [Google Scholar] [CrossRef]
- Pavithra, V.; Jayalakshmi, V. Hybrid feature selection technique for prediction of cardiovascular diseases. Mater. Today Proc. 2021; in press. [Google Scholar]
- Gnanambal, S.; Thangaraj, M.; Meenatchi, V.; Gayathri, V. Classification algorithms with attribute selection: An evaluation study using WEKA. Int. J. Adv. Netw. Appl. 2018, 9, 3640–3644. [Google Scholar]
- Aldrich, C. Process variable importance analysis by use of random forests in a shapley regression framework. Minerals 2020, 10, 420. [Google Scholar] [CrossRef]
- Chormunge, S.; Jena, S. Correlation based feature selection with clustering for high dimensional data. J. Electr. Syst. Inf. Technol. 2018, 5, 542–549. [Google Scholar] [CrossRef]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 1, 403–412. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Li, J.; Yang, Y. The research of the fast SVM classifier method. In Proceedings of the 2015 12th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2015; pp. 121–124. [Google Scholar]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef]
- Masih, N.; Naz, H.; Ahuja, S. Multilayer perceptron based deep neural network for early detection of coronary heart disease. Health Technol. 2021, 11, 127–138. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers-A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Bhargava, N.; Sharma, G.; Bhargava, R.; Mathuria, M. Decision tree analysis on j48 algorithm for data mining. Proc. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1114–1119. [Google Scholar]
- Truong, X.L.; Mitamura, M.; Kono, Y.; Raghavan, V.; Yonezawa, G.; Truong, X.Q.; Do, T.H.; Tien Bui, D.; Lee, S. Enhancing prediction performance of landslide susceptibility model using hybrid machine learning approach of bagging ensemble and logistic model tree. Appl. Sci. 2018, 8, 1046. [Google Scholar] [CrossRef] [Green Version]
- Palimkar, P.; Shaw, R.N.; Ghosh, A. Machine learning technique to prognosis diabetes disease: Random forest classifier approach. In Advanced Computing and Intelligent Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 219–244. [Google Scholar]
- Elomaa, T.; Kaariainen, M. An analysis of reduced error pruning. J. Artif. Intell. Res. 2001, 15, 163–187. [Google Scholar] [CrossRef] [Green Version]
- Joloudari, J.H.; Hassannataj Joloudari, E.; Saadatfar, H.; Ghasemigol, M.; Razavi, S.M.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Nadai, L. Coronary artery disease diagnosis; ranking the significant features using a random trees model. Int. J. Environ. Res. Public Health 2020, 17, 731. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation forest: A new classifier ensemble method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on Machine Learning, Bari, Italy, 3–6 July 1996. [Google Scholar]
- Netrapalli, P. Stochastic gradient descent and its variants in machine learning. J. Indian Inst. Sci. 2019, 99, 201–213. [Google Scholar] [CrossRef]
- Pavlyshenko, B. Using stacking approaches for machine learning models. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 255–258. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Waikato Environment for Knowledge Analysis. Available online: https://www.weka.io/ (accessed on 25 June 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Work | Use Case | Dataset | Proposed Models | Metrics |
|---|---|---|---|---|
| [26] | Diabetes Prediction | Pima Indian Diabetes Dataset | Soft Weighted Voting | AUC: 0.950 Sensitivity: 0.789 Specificity: 0.934 |
| [27] | Diabetes Classification | Pima Indian Diabetes Dataset | SVM/KNN | SVM: Accuracy 0.89, Precision 0.88 KNN: Recall 0.9, F1 score 0.88 |
| [28] | Diabetes Detection | Not Publicly Available | Simple Linear Regression | RMSE: 0.838 |
| [29] | Diabetes Prediction | Pima Indian Diabetes Dataset | Random Forest | Accuracy: 94.1% |
| [30] | Classification and prediction of diabetes | National Health and Nutrition Examination Survey | Random Forest | Accuracy: 94.25% AUC: 0.95 |
| [31] | Diabetes Detection | ELSA Database | Weighted Majority Voting | AUC: 0.884 |
| [32] | Diabetes Prediction | [36] | Random Forest | Accuracy: 94.1% 10-fold cross-validation Accuracy: 99% Percentage split (80:20) |
| [33] | Diabetes Prediction | [36] | KNN | Accuracy: 98.07% |
| [34] | Diabetes Prediction | [36] | Random Forest | Accuracy, Precision, Recall, F-Measure: 97.5% |
| [35] | Diabetes Prediction | [36] | Random Forest | Accuracy: 97.88% |
| Feature | Pearson Rank | Feature | Gain Ratio | Feature | Naive Bayes (AUC) | Feature | Random Forest (AUC) |
|---|---|---|---|---|---|---|---|
| polyuria | 0.7046 | polydipsia | 0.4317 | polyuria | 0.3329 | polyuria | 0.3337 |
| polydipsia | 0.6969 | polyuria | 0.4143 | polydipsia | 0.3189 | polydipsia | 0.3189 |
| sudden_weight_loss | 0.5017 | gender | 0.2117 | sudden_weight_loss | 0.2229 | age | 0.2537 |
| gender | 0.4922 | sudden_weight_loss | 0.2088 | gender | 0.2089 | sudden_weight_loss | 0.2232 |
| partial_paresis | 0.4757 | partial_paresis | 0.1814 | partial_paresis | 0.2084 | gender | 0.2092 |
| polyphagia | 0.3450 | irritability | 0.1218 | polyphagia | 0.1454 | partial_paresis | 0.2084 |
| irritability | 0.3398 | polyphagia | 0.0895 | irritability | 0.1174 | polyphagia | 0.1456 |
| alopecia | 0.2771 | alopecia | 0.0588 | alopecia | 0.1099 | irritability | 0.1175 |
| visual_blurring | 0.2564 | age | 0.0533 | visual_blurring | 0.1098 | alopecia | 0.1118 |
| weakness | 0.2547 | visual_blurring | 0.0489 | weakness | 0.1093 | visual_blurring | 0.1103 |
| genital_thrush | 0.1441 | weakness | 0.0477 | age | 0.0584 | weakness | 0.1096 |
| age | 0.1124 | genital_thrush | 0.0209 | genital_thrush | 0.0468 | genital_thrush | 0.0471 |
| muscle_stiffness | 0.1068 | muscle_stiffness | 0.0086 | muscle_stiffness | 0.0324 | muscle_stiffness | 0.0327 |
| obesity | 0.0808 | obesity | 0.0074 | obesity | 0.0180 | obesity | 0.0191 |
| delayed_healing | 0.0471 | delayed_healing | 0.0016 | delayed_healing | 0.0046 | delayed_healing | 0.0049 |
| itching | 0.0156 | itching | 0.0002 | itching | −0.0273 | itching | −0.0260 |
| Models | Parameters |
|---|---|
| BayesNet | estimator: simpleEstimator searchAlgorithm: K2 useADTree: False |
| NB | useKernelEstimator: False useSupervisedDiscretization: False |
| SVM | eps = 0.001 gamma = 0.0 kernel type: radial basis function loss = 0.1 |
| LR | ridge = useConjugateGradientDescent: False |
| ANN | hidden layers: ‘a’ learning rate = 0.3 momentum = 0.2 training time = 500 |
| KNN | K = 1 Serach Algorithm: LinearNNSearch with Euclidean |
| J48 | reducedErrorPruning: False savelnstanceData: False subtreeRaising: True |
| LMT | errorOnProbabilities: False fastRegression: True numInstances = 15 useAIC: False |
| RF | maxDepth = 0 numIterations = 100 numFeatures = 0 |
| RT | maxDepth = 0 minNum = 1.0 minVarianceProp = 0.001 |
| RepTree | maxDepth = −1 minNum = 2.0 minVarianceProp = 0.001 |
| RotF | classifier: J48 numberOfGroups: False projectionFilter: PrincipalComponents |
| AdaBoostM1 | classifier: DecisionStump resume: False useResampling: False |
| SGD | epochs = 500 epsilon = 0.001 lamda = learningRate = 0.01 lossFunction: Hinge loss (SVM) |
| Stacking | Base Models: RF, KNN Meta-model:LR |
| Accuracy | Precision | Recall | F-Measure | AUC | |
|---|---|---|---|---|---|
| BayesNet | 88.75 ± 5.04% | 88.9 ± 4.8% | 88.8 ± 4.9% | 88.7 ± 5.1% | 95.6 ± 2.1% |
| NB | 88.91 ± 5.02% | 89.1 ± 4.7% | 88.9 ± 5% | 88.9 ± 5.1% | 95.5 ± 2.4% |
| SVM | 95.62 ± 2.06% | 95.7 ± 1.8% | 95.6 2.1% | 95.6 ± 2.1% | 95.6 ± 2.1% |
| LR | 93.44 ± 2.64% | 93.4 ± 2.6% | 93.4 ± 2.6% | 93.4 ± 2.7% | 97.6 ± 1.4% |
| ANN | 96.45 ± 2.00% | 97.3 ± 2.40% | 97.3 ± 2.40% | 97.2 ± 2.30% | 99.1 ± 2.60% |
| KNN | 98.59 ± 1.72% | 98.6 ± 1.62% | 98.6 ± 1.70% | 98.6 ± 1.70% | 98.9 ± 1.30% |
| J48 | 97.19 ± 2.74% | 97.2 ± 2.70% | 97.2 ± 2.70% | 97.2 ± 2.70% | 97.2 ± 2.20% |
| LMT | 97.19 ± 1.61% | 97.2 ± 1.60% | 97.2 ± 1.60% | 97.2 ± 1.60% | 98.3 ± 1.30% |
| RF | 98.59 ± 1.15% | 98.6 ± 1.10% | 98.6 ± 1.12% | 98.6 ± 1.12% | 99.9 ± 0.20% |
| RT | 97.97 ± 2.09% | 98 ± 2.10% | 98 ± 2.10% | 98 ± 2.10% | 98 ± 2.10% |
| RepTree | 93.12 ± 3.23% | 93.2 ± 3.00% | 93.1 ± 3.20% | 93.1 ± 3.20% | 96.4 ± 2.30% |
| RotF | 98.28 ± 2.01% | 98.3 ± 1.17% | 98.3 ± 2.00% | 98.3 ± 2.00% | 99.9 ± 0.20% |
| AdaBoostM1 | 90.78 ± 2.59% | 91.2 ± 2.40% | 90.8 ± 2.60% | 90.8 ± 2.60% | 97.1 ± 2.10% |
| SGD | 94.22 ± 2.56% | 94.3 ± 2.40% | 94.2 ± 2.60% | 94.2 ± 2.60% | 94.2 ± 2.60% |
| Stacking | 98.49 ± 1.10% | 98.5 ± 1.10% | 98.5 ± 1.11% | 98.5 ± 1.11% | 99.7 ± 0.20% |
| Accuracy | |||||
|---|---|---|---|---|---|
| Proposed models | [32] | [33] | [34] | [35] | |
| BayesNet | 88.75% | - | 86.92% | - | - |
| NB | 88.91% | 87.4% | 87.11% | 87.1% | - |
| SVM | 95.62% | - | 92.11% | 92.1% | - |
| LR | 93.44% | 92.4% | - | - | - |
| ANN | 96.45% | - | - | 96.3% | 96.34% |
| KNN | 98.59% | - | 98.07% | - | - |
| J48 | 97.19% | 95.6% | 95.96% | - | - |
| RF | 98.59% | 97.4% | 97.5% | 97.5% | 97.88% |
| RT | 97.97% | - | 96.15% | - | - |
| Accuracy | Precision | Recall | F-Measure | AUC | |
|---|---|---|---|---|---|
| BayesNet | 88.28% | 88.3% | 88.3% | 88.3% | 95.9% |
| NB | 89.06% | 89.1% | 89.1% | 89.1% | 95.8% |
| SVM | 97.66% | 97.7% | 97.7% | 97.7% | 97.6% |
| LR | 92.97% | 93% | 93% | 93% | 98.5% |
| ANN | 97.66% | 97.7% | 97.7% | 97.7% | 99.9% |
| KNN | 99.22% | 99.2% | 99.2% | 99.2% | 98.9% |
| J48 | 95.53% | 95.5% | 95.5% | 95.5% | 96.1% |
| LMT | 96.87% | 96.9% | 96.9% | 96.9% | 99.4% |
| RF | 99.22% | 99.2% | 99.2% | 99.2% | 100% |
| RT | 97.66% | 97.7% | 97.7% | 97.7% | 97.7% |
| RepTree | 92.19% | 92.2% | 92.2% | 92.2% | 95.2% |
| RotF | 97.66% | 97.7% | 97.7% | 97.7% | 99.9% |
| AdaBoostM1 | 92.97% | 93% | 93% | 93% | 97.5% |
| SGD | 93.75% | 93.8% | 93.8% | 93.8% | 93.7% |
| Stacking | 99.20% | 99.2% | 99.2% | 99.2% | 100% |
| Accuracy | ||||
|---|---|---|---|---|
| NB | LR | J48 | RF | |
| Proposed models | 89.06% | 92.97% | 95.53% | 99.22% |
| [32] | 88% | 91% | 95% | 99% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dritsas, E.; Trigka, M. Data-Driven Machine-Learning Methods for Diabetes Risk Prediction. Sensors 2022, 22, 5304. https://doi.org/10.3390/s22145304
Dritsas E, Trigka M. Data-Driven Machine-Learning Methods for Diabetes Risk Prediction. Sensors. 2022; 22(14):5304. https://doi.org/10.3390/s22145304
Chicago/Turabian StyleDritsas, Elias, and Maria Trigka. 2022. "Data-Driven Machine-Learning Methods for Diabetes Risk Prediction" Sensors 22, no. 14: 5304. https://doi.org/10.3390/s22145304
APA StyleDritsas, E., & Trigka, M. (2022). Data-Driven Machine-Learning Methods for Diabetes Risk Prediction. Sensors, 22(14), 5304. https://doi.org/10.3390/s22145304