Abstract
With the development of machine learning, data-driven mechanical fault diagnosis methods have been widely used in the field of PHM. Due to the limitation of the amount of fault data, it is a difficult problem for fault diagnosis to solve the problem of unbalanced data sets. Under unbalanced data sets, faults with little historical data are always difficult to diagnose and lead to economic losses. In order to improve the prediction accuracy under unbalanced data sets, this paper proposes MeanRadius-SMOTE based on the traditional SMOTE oversampling algorithm, which effectively avoids the generation of useless samples and noise samples. This paper validates the effectiveness of the algorithm on three linear unbalanced data sets and four step unbalanced data sets. Experimental results show that MeanRadius-SMOTE outperforms SMOTE and LR-SMOTE in various evaluation indicators, as well as has better robustness against different imbalance rates. In addition, MeanRadius-SMOTE can take into account the prediction accuracy of the overall and minority class, which is of great significance for engineering applications.
1. Introduction
With the continuous innovation of technology, industrial equipment has developed rapidly in the direction of large-scale, automated, integrated, and intelligent, such as aircraft engines, steam turbines, wind turbines, centrifuges, etc. In order to meet the requirements of mechanical equipment reliability and precision in the industrial field, PHM (Prognostics and Health Management) was initiated to ensure the stable operation of mechanical equipment and reduce maintenance costs [1,2,3].
With the development of big data in the industrial field, data-driven mechanical fault diagnosis research has received more and more attention [4,5,6]. Mechanical fault diagnosis generally starts by extracting vibration signals from the operation of the equipment, because vibration signals can provide sufficient fault features to reflect the fault status and serve as the input of the prediction model [7,8]. However, due to the low frequency of some faults, the vibration signals of such faults are too small, and the classifier cannot predict them accurately, which is the problem of unbalanced data sets in fault diagnosis. In the multi-classification mechanical fault diagnosis problem, the machine learning classifier emphasizes the accuracy of the overall prediction, which leads to sacrificing the prediction accuracy of the minority class to ensure the prediction of the majority class samples [9]. However, there are infrequent failures in some mechanical equipment, which will lead to huge economic losses once they occur. Therefore, it is necessary to research the problem of unbalanced data sets in mechanical fault diagnosis.
At present, the research on the problem of unbalanced data sets is relatively mature, but this research in the mechanical fault diagnosis field has just begun [10]. Many fault diagnosis techniques rely on reliable and complete data sets, such as multi-sensing fusion techniques [11]. However, since machinery usually operates under normal conditions, it is difficult to collect enough failure data, so that the actual data set lacks completeness [12,13]. The lack of samples with specific labels can lead to data imbalance problems. In recent years, many scholars have begun to pay attention to this problem and have given their own methods [14,15]. Generally, the solution to the problem of unbalanced data sets is mainly divided into data and algorithm aspects, and sometimes they are combined [16].
For the data aspect, scholars mainly use resampling technology to copy, synthesize, delete, and perform other operations on original samples, to adjust the number of samples to reduce the impact of unbalanced data sets. Resampling techniques are divided into oversampling for minority class samples and undersampling for majority class samples. The main idea of oversampling is to increase the number of minority class samples to achieve class balance. The main methods are divided into replicating samples and generating new samples. ROS (Random Oversampling) is to randomly replicate original samples to expand the number of minority class samples, but it may cause the replication of noise samples to affect the quality of the data set [17]. The method of generating new samples derives new samples from one or more original samples, and the new samples can indirectly reflect the features of the minority class. The most classic oversampling is the SMOTE algorithm [18]. The SMOTE algorithm selects the line connecting the two original samples as the range of the new sample and determines a point on the line as the new sample. However, SMOTE still does not avoid the generation of noise samples, and the new samples are easily affected by the distribution of the original samples, which may cause the new samples to deviate from the actual distribution. Later scholars improved SMOTE in terms of noise reduction and generation algorithms, such as Borderline-SMOTE [19], Adasyn [20], LR-SMOTE [21], etc. Undersampling achieves class balance by reducing the number of majority class samples, such as undersampling based on the clustering algorithm and ENN (Edited Nearest Neighbor) [22]. In fact, most of the unbalanced data sets are caused by too few samples in the minority class, so oversampling is the key research in this field [23].
For the algorithm aspect, with the rapid development of machine learning, many classifiers have responded to the problem of unbalanced data sets. On the premise that each sample is equal, the number of samples determines which class the classifier prefers, so setting the weight of the sample, the threshold of the decision boundary, or the objective function of the classifier can strengthen the ability of the classifier to combat unbalanced data sets [24,25]. Adjusting these can make the classifier’s decision boundary less sensitive to the sample size [26]. Moreover, adding a proper regularization term to the objective function can reduce the impact of the imbalance rate on the classifier [27].
There is no universal solution to the problem of unbalanced data sets in mechanical fault diagnosis; although, scholars have tried in various directions. From the perspective of features, extracting more abundant features from vibration signals is beneficial to solving the problem, because the failure can be reflected in the energy of the vibration of the equipment [28]. In addition to features in the time and frequency domains, there are features based on wavelet packet energy and entropy values [29,30], and the fault features are also extracted using a bag-of-visual-word approach from the infrared thermography images [31]. However, the increase of features will undoubtedly increase the workload of feature screening. From the perspective of resampling, scholars use various existing resampling methods to conduct experiments on mechanical equipment [32]. Once there are more failure types or concurrent failures, existing oversampling algorithms may fail. Therefore, analyzing the commonality of mechanical faults and proposing a new oversampling algorithm is the key to solving this problem in the mechanical field [33,34]. From the perspective of the classifier, scholars mainly set the cost matrix, and change the loss function or network structure to make the classifier aware of this imbalance [35]. These classifiers are often only suitable for identifying faults in stationary parts, such as gears or bearings [36].
Although new oversampling algorithms are emerging, there are still the following problems: (1) The solutions are generally only aimed at the prediction of bearing failures or gear failures, so the methods cannot comprehensively diagnose the running state of complete mechanical equipment. (2) Most of the solutions are aimed at the two-category problem, which is obviously not practical. For a simple secondary planetary gear, there are already as many as eight failure types. (3) The new samples are not effective enough that the existing oversampling methods generate. Although the number has reached a balance, it is far from enough in terms of the amount of fault-type information contained in the sample.
In view of the existing problems, this paper improves SMOTE and proposes an oversampling algorithm called MeanRadius-SMOTE, which is specially used to solve the multi-classification problems in mechanical fault diagnosis. MeanRadius-SMOTE can reduce the production of noise samples and add more samples with the ability to affect the decision boundary, and it is easier to inherit the feature information from the original samples. The complexity of the MeanRadius-SMOTE algorithm is not high compared to SMOTE.
The main contributions of this paper are as follows: To solve the problem of multi-classification unbalanced data sets in mechanical fault diagnosis, a new oversampling algorithm, MeanRadius-SMOTE, is proposed. The algorithm takes into account the performance of prediction of overall and minority class, and especially in the minority class, prediction accuracy is greatly improved. In this paper, a large number of comparative experiments are carried out on data sets with various specifications and imbalance rates, and the effectiveness, stability, and robustness of the algorithm are verified.
The rest of this paper is divided into five parts. In Section 2, the SMOTE algorithm and the improved LR-SMOTE algorithm based on SMOTE are introduced. In Section 3, the specific process of the MeanRadius-SMOTE algorithm is introduced in detail. In Section 4, we mainly introduce the source and processing of the data set, as well as the selection of classifiers and evaluation indicators in the experiment. In Section 5, we introduce the experimental process and experimental results. In the following sections, we discuss and summarize the MeanRadius-SMOTE algorithm based on experiments, and we propose future research directions.
2. Related Works
Since the machine learning algorithm is greedy in the face of multi-classification problems, the classifier will give priority to ensuring the highest overall accuracy, resulting in an inaccurate prediction of some minority class samples. In the real industrial field, in the face of some faults with low probability but high maintenance cost, operators hope that the model can accurately predict these faults. Therefore, this section introduces the commonly used methods to deal with unbalanced data sets, namely, the traditional SMOTE method and the improved LR-SMOTE method.
2.1. SMOTE
The SMOTE algorithm was proposed by Chaw La et al. in 2002 [18], and the algorithm is an improved method based on ROS. In the SMOTE algorithm, new samples are generated based on the original samples, which has a greater probability of obtaining effective features than random oversampling of new samples. The steps of the SMOTE algorithm are as follows:
- (1)
- For each sample x in the training set, calculate their Euclidean distance to each minority class sample xi, and obtain the k nearest neighbors of each minority class sample.
- (2)
- According to the sample imbalance rate, set the sampling ratio N. For xi, randomly select N samples from its k nearest neighbors, denoted as xh.
- (3)
- According to Equation (1), build new samples based on xi and xh until the classes are balanced, denoted as xnew.
Although the SMOTE algorithm overcomes the overfitting problem of the ROS algorithm, SMOTE still has some problems with noise samples and useless samples. Many scholars have improved SMOTE. For example, Han proposed the Borderline-SMOTE algorithm [19]. The algorithm first classifies the original samples into safe, dangerous, and noise, then uses the dangerous samples to generate new samples. It not only reduces the interference of noise points but also enables new samples to better reflect the features of the data set. However, how to accurately divide the three labels is a more difficult problem for different data sets.
2.2. LR-SMOTE
Based on the SMOTE algorithm, Wang proposed the LR-SMOTE algorithm [21]. The algorithm first uses SVM (Support Vector Machine) and K-means to remove the noise samples in the original data set, then changes the generation rules of new samples and considers the center of the samples to generate new samples. The specific steps of the LR-SMOTE algorithm are as follows:
- (1)
- Use SVM to classify the data set, and then for the wrongly classified minority samples use the K-means method to judge and remove the noise samples.
- (2)
- Use K-means to find the center xc of the minority class sample, calculate the distance di from each minority class sample to the center xc, and calculate the average distance dm.
- (3)
- For each minority class sample xi, calculate the ratio Mi of the average distance dm and the distance di.
- (4)
- According to the number of the same samples in the neighbor samples, set the weight of each minority class sample, and then randomly select a minority class sample xi and build new samples xnew according to Equation (2).
- (5)
- Repeat steps 3 and 4 until the number of samples of the majority class and minority class is balanced.
In the LR-SMOTE algorithm, the new samples are generated based on the functional relationship between the sample center and each sample, rather than any two minority samples. Therefore, the new samples will not deviate from the range of the minority samples, and the features are closer to the original sample. LR-SMOTE provides a good direction for generating rules so that the algorithm determines the distribution of samples according to the sample center. This paper also proposes a new algorithm along this way to solve the unbalanced data sets in the mechanical field. We use the MeanRadius-SMOTE algorithm to experiment on a variety of mechanical failure data sets, and the experimental results show that the MeanRadius-SMOTE algorithm is suitable for solving the problem of unbalanced data sets in the mechanical field.
3. Proposed Method
In an oversampling algorithm, new samples at different geometric locations have different improvements in classifier training. In general, the more new samples near the decision boundary, the greater the impact on the classifier. This paper proposes the MeanRadius-SMOTE (MR-SMOTE) algorithm considering the sample center and radius. When using machine learning to predict mechanical failures, we deal with noise samples in advance, so noise reduction is performed in feature preprocessing. Noise reduction is not involved in the MeanRadius-SMOTE, and the noise reduction algorithm will be introduced in the next section.
The MeanRadius-SMOTE algorithm mainly changes the generation rules of the SMOTE algorithm, so that the new samples are more likely to be distributed near the average radius of the minority class samples, and the new samples have a stronger ability to affect the decision boundary of the classifier. In the MeanRadius-SMOTE algorithm, the new sample is determined by vectors of the sample center to the samples, and the distance between the new sample and the sample center follows a normal distribution. The steps of the MeanRadius-SMOTE algorithm are as follows:
- (1)
- According to each minority class sample, calculate the geometric center, denoted as the sample center xc of the minority class sample.
- (2)
- Calculate the Euclidean distance from each minority class sample to the sample center, and then obtain the average distance, denoted as the sample radius dm of the minority class.
- (3)
- Randomly select k minority class samples, and then obtain k vectors vi from the sample center xc to the samples. Compute the resultant vector of k vectors.
- (4)
- Use a normal distribution with mean dm and variance to determine the distance between the new sample and the sample canter. According to Equation (3), build new samples.
- (5)
- Repeat steps 3 and 4 until the number of samples of the majority class and minority class is balanced.
In order to show the flow of the algorithm more conveniently, we draw the flow chart of the MeanRadius-SMOTE algorithm, as shown in Figure 1.
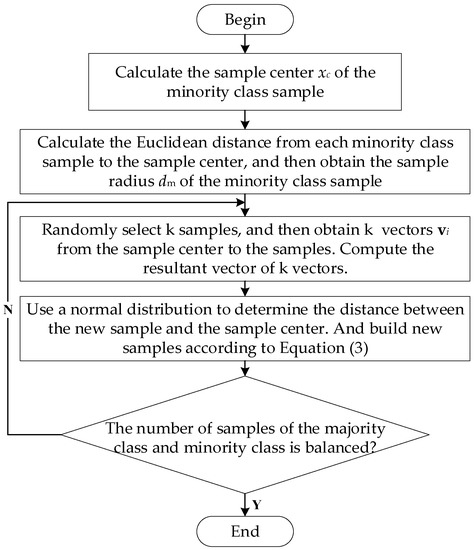
Figure 1.
The flow chart of the MeanRadius-SMOTE algorithm.
In the MeanRadius-SMOTE algorithm, and are hyperparameters of the algorithm, which are determined according to the number of minority class samples and the imbalance rate. If is too large, the direction of the new sample relative to the sample center will become meaningless, and directly affects the distribution of the new sample. As shown in Figure 2, new samples under different are likely to be distributed in colored areas. When is too small, the new sample may be far from the sample center. When is too large, the new sample is too conservative and cannot balance the number of positive and negative samples near the decision boundary. Therefore, in general, the selection range of parameters is 2 to 5 and the selection range of parameters is 4 to 10.
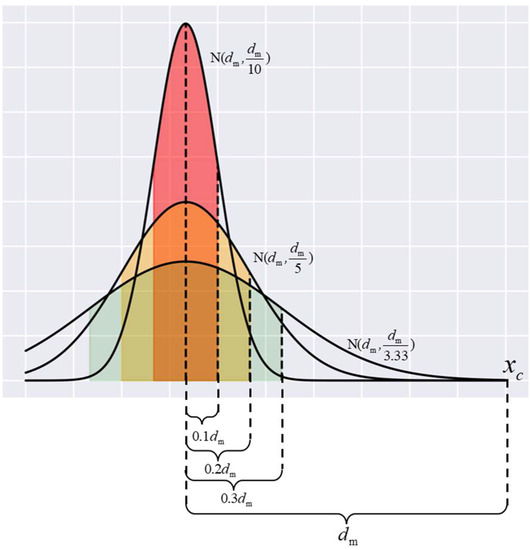
Figure 2.
New samples distribution under different .
For mechanical equipment, some concurrent faults and the original fault have similar vibration states, and the two types of samples often overlap in distribution. Whether the classifier can find an excellent decision boundary is the key to determining the accuracy of the model. In the MeanRadius-SMOTE algorithm, most of the new samples are concentrated around the sample radius to ensure the validity of the new samples. The new sample is determined by samples and is related to the sample center, so that the new sample can better inherit the features of the minority class. The geometric positions of new samples generated by different oversampling algorithms have their own characteristics, so we plot the examples of SMOTE, LR-SMOTE, and MeanRadius-SMOTE on two-dimension feature samples, as shown in Figure 3. The information of the two-dimension feature samples is shown in Table 1.
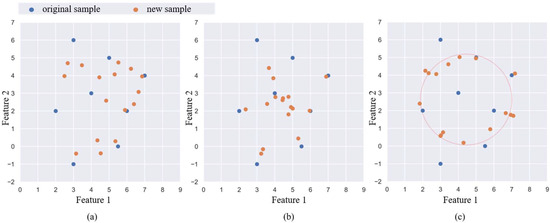
Figure 3.
New samples on oversampling algorithms: (a) SMOTE, (b) LR-SMOTE, (c) MeanRadius-SMOTE.

Table 1.
The information of the two-dimension feature samples.
The new samples of SMOTE are more inclined to be generated in locations with a high density of the original samples. Since LR-SMOTE randomly chooses a sample to determine the orientation of the new sample, the new sample is more clustered and radial. In MeanRadius-SMOTE, the orientation of new samples is relatively random, and the new samples are generated around the sample radius.
4. Experimental Preparation
4.1. Data Set
Our experimental data set is the 2009 PHM data challenge of gearbox [37]. The data set is a typical industrial gearbox data set, which contains 3 shafts, 4 gears, and 6 bearings, and its experimental bench is shown in Figure 4. The data set tests two sets of gears: spur gear and helical gear. The spur gear data set contains 8 health states, and the helical gear data set contains 6 health states. The data set consists of two channels of accelerometer signals and one channel of tachometer signals. The sampling frequency is 66.67 kHz, and the tachometer signals are collected at 10 pulses per revolution. There are five types of shaft speeds: 30 Hz, 35 Hz, 40 Hz, 45 Hz, and 50 Hz, with high and low loads. In the experiment, we chose the low load spur gear operating data at 30 Hz, and we used the vibration data of the two acceleration channels for feature extraction, The 8 health states of spur gears are as follows in Table 2.
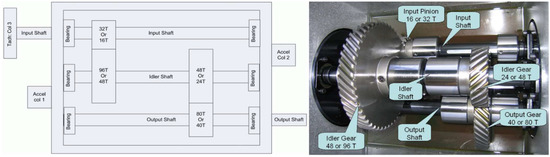
Figure 4.
Gearbox used in PHM 2009 challenge data.
Table 2.
A brief description of the faults.
Mechanical equipment frequently fails in the harsh environment of high temperature and high pressure due to concurrent failures composed of multiple single failures [38]. In the PHM dataset, there are many types of concurrent failures, such as labels 4 to 8. They are all combinations of different types of failures in gears and bearings.
For the vibration signal, we sampled the data set using a sliding window with a stride of 100 and a width of 1000. Then we extracted time–frequency domain features for each vibration signal sample and add labels [39]. The formula of 23 features is shown in Table 3.
Table 3.
The time–frequency domain features.
In the experiment, we used the K-nearest neighbor algorithm to denoise the data set. If the five nearest samples around a sample are not of this class, we consider it to be a noise sample and delete it. After the above preprocessing, we obtained 2656 samples per label, of which 1000 samples per label were taken as the test set. Additional samples were used to construct unbalanced data sets.
4.2. Classifiers
In order to comprehensively evaluate the oversampling algorithm, we chose different classifiers to build the experimental model, which excludes the influence of the classifier and verifies the generality of the oversampling algorithm. Through experiments in a large number of mechanical fault diagnoses, the SVM classifier generally has a good training effect, so we chose SVM to establish a classification model. With the continuous development of the decision tree algorithm, the ensemble learning model is also favored by scholars because of its excellent generalization ability. Therefore, we chose RF (Random Forest) representing bagging ensemble mode, and GBDT (Gradient Boosting Decision Tree) representing boosting ensemble mode for experiments.
4.3. Evaluation Indicators
Traditional evaluation indicators can well evaluate the performance of the model in the two-category problem. However, in the multi-classification problem, due to the partiality of the classifier, these indicators cannot comprehensively evaluate the model on unbalanced data sets. The expectation of the oversampling algorithm in this paper is to improve the prediction performance of the minority class without losing the overall prediction accuracy of the classifier. Therefore, we will use the traditional evaluation indicators and the prediction indicator of the minority class to evaluate the prediction model. For class samples, we define the prediction results as follows, as shown in Table 4:
Table 4.
Predicting results for class i samples.
We choose the following four evaluation indicators:
- (1)
- Accuracy (Acc): The Acc value is the ratio of the number of correctly predicted samples to the total number of samples. The calculation method is as shown in Equation (4):The Acc value evaluates the overall prediction, but in the case of unbalanced data sets, it is not a good indicator to measure the results.
- (2)
- Macro-Precision (Mac-P): The calculation method of the Precision value for class i samples is as shown in Equation (5):In the multi-classification problem, the Precision value is divided into Macro and Micro methods. Micro-Precision focuses more on types of samples with a large number of samples, so it is more susceptible to the majority class. However, Mac-P will treat each type of sample equally, so it can better describe the model’s ability to deal with unbalanced data sets. The calculation method is as shown in Equation (6):
- (3)
- Macro-F1 (Mac-F1): It is contradictory to improve the Precision value and Recall value at the same time. The F1 value is a balance point with high Precision value and high Recall value, and its calculation method is as shown in Equation (7):In the multi-classification problem, The F1 value also has Macro and Micro methods such as the Precision value. This paper selects Mac-F1, which can better take into account the minority class. The calculation method is as shown in Equation (8):
- (4)
- Precision-Minority (Presmall): In order to pay more attention to the prediction effect of the model on the minority class samples after oversampling algorithms, we will calculate the Precision value of the minority class as an indicator, and its calculation method is as shown in Equation (9):
5. Experimental Design and Results
In this paper, we will design unbalanced data sets of various sizes for experiments. According to the distribution of sample data volume within each class, unbalanced data sets can be divided into two forms, linear imbalance and step imbalance. The distribution of sample data volume for the two forms is as shown in Figure 5.
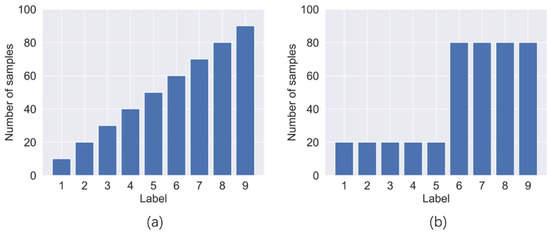
Figure 5.
Two imbalance forms: (a) linear imbalance, (b) step imbalance.
In this paper, we design three linear unbalanced data sets and four step unbalanced data sets. In order to reduce the interference of the class on the Presmall in different experiments, we set the number of samples for labels 4 to 50 as the smallest minority class. We set the normal label as the large sample class, and the imbalance rate is designed to be 30, 20, and 15, through which the number of other labels can be determined. The details of the seven unbalanced data sets are shown in Table 5. For line-1 to 3, their imbalance rates are not the same. Moreover, the label linear order is shuffled. For stage-1 to 4, there are differences in the imbalance rate and the ratio of minority class and majority class labels.
Table 5.
Unbalanced data sets description.
In the experiment, we will use the SMOTE, LR-SMOTE, and MeanRadius-SMOTE to oversample the seven unbalanced data sets, so that each class label becomes balanced. Then, we conduct experiments on the original data set and the three processed data sets on SVM, RF, and GBDT classifiers. In order to eliminate the training bias caused by random data, all experiments were performed with 5-fold cross-validation and repeated 10 times to obtain the average number of indicators.
The experimental results of Acc, Mac-P, and Mac-F1 on the linear unbalanced data sets and step unbalanced data sets are shown in Table 6 and Table 7, where the values with bold mean the largest value in four compared models.
Table 6.
Experimental results of the linear unbalanced data set.
Table 7.
Experimental results of the step unbalanced data set.
From Table 6, it can be found that the oversampling algorithm can effectively improve Acc, Mac-P, and Mac-F1, and MeanRadius-SMOTE is the best in most cases. In some experiments, SMOTE performs better than MeanRadius-SMOTE, but the gap between them is very small. However, in the SVM experiment, MeanRadius-SMOTE improves the three indicators much better than SMOTE and LR-SMOTE.
From Table 7, since there are more minority classes in the step unbalanced data sets, the three indicators are all lower in the experiments without oversampling, and are more affected by the imbalance rate. The SVM classifier combined with any oversampling algorithm is better than the ensemble learning classifier, and there are obvious gaps in the three indicators. On the step unbalanced data sets, MeanRadius-SMOTE outperforms SMOTE and LR-SMOTE in all cases, and the gap is especially significant on the SVM classifier.
By analyzing Acc, Mac-P, and Mac-F1, all oversampling algorithms can effectively improve the overall prediction performance of the classifier on both forms of unbalanced data sets, and the MeanRadius-SMOTE algorithm proposed in this paper has the most obvious effect. We still need to focus on the prediction performance of the algorithm on the minority class; the experimental results of Presmall are shown in Table 8, where the values with bold mean the largest value in four compared models.
Table 8.
Presmall on the data sets.
From Table 8, Presmall does not even exceed five in the None experiments. SMOTE and LR-SMOTE only improved Presmall by around five in most experiments. However, MeanRadius-SMOTE can help the classifier to more accurately predict the minority class, improving Presmall by around six or seven. In addition, MeanRadius-SMOTE is more stable in experiments with different imbalance rates, and does not fluctuate greatly like SMOTE and LR-SMOTE.
To better compare the effects of SMOTE, LR-SMOTE, and MeanRadius-SMOTE, we draw the line charts of Mac-P, Mac-F1, and Presmall, as shown in Figure 6. Since the data of Acc and Mac-F1 are close and their trend is basically the same, we only choose Mac-F1 to draw the line chart.
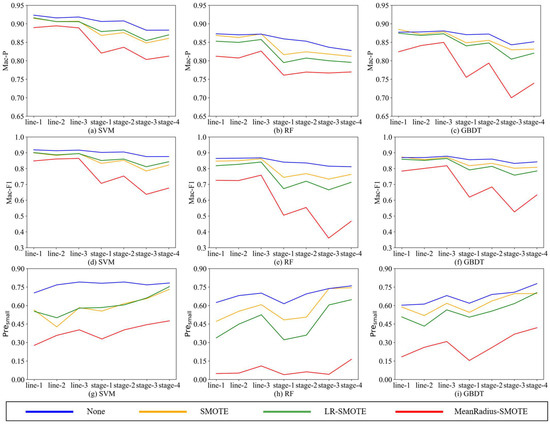
Figure 6.
The line charts of Mac-P, Mac-F1, and Presmall.
According to Figure 6, the following conclusions can be drawn:
- (1)
- Since these seven unbalanced data sets are homologous, the better the oversampling algorithm, the closer the indicators should be. Comparing the nine charts, all indicators are relatively stable in the MeanRadius-SMOTE experiment, which is less affected by the imbalance rate and data set form, and this stabilization is more obvious in the SVM classifier. This shows that MeanRadius-SMOTE has good robustness.
- (2)
- Analyzing the three charts—Figure 6a,d,g, in the seven data sets, MeanRadius-SMOTE on the SVM classifier can not only ensure that the overall prediction indicators reach about 0.9 but also ensure that Presmall is relatively high, about 0.75.
- (3)
- Comparing the three charts—Figure 6g–i, the SVM experiment can achieve a higher Presmall, and in most experiments, Presmall is greatly affected by the data sets, especially in the RF experiments. However, only in the model composed of MeanRadius-SMOTE and SVM do we obtain a very flat line, which shows that this model has good robustness and accuracy in predicting the minority class.
- (4)
- Comparing the three charts—Figure 6a–c, for SMOTE and LR-SMOTE, LR-SMOTE performs better than SMOTE on SVM, while it is the opposite on RF and GBDT. In addition, SMOTE even outperforms MeanRadius-SMOTE in some GBDT experiments. LR-SMOTE is also an oversampling algorithm for binary classification problems, which is more suitable for a classifier that is essentially a binary classification algorithm-SVM. Therefore, it can be inferred that MeanRadius-SMOTE is also more suitable for SVM classifiers.
In summary, MeanRadius-SMOTE shows excellent performance in all experiments, which can take into account the prediction performance of the overall and minority class. In individual experiments, SMOTE is slightly higher than MeanRadius-SMOTE in Acc, Mac-P, and Mac-F1, but lower than MeanRadius-SMOTE in Presmall. We can think that this is the result of sacrificing the prediction performance of the minority class. Therefore, it can still be considered that MeanRadius-SMOTE is better than SMOTE and LR-SMOTE. Furthermore, the model composed of MeanRadius-SMOTE and SVM can improve prediction accuracy and stability.
6. Conclusions and Outlook
Mechanical fault diagnosis has always been a key issue in the PHM. Since the development of machine learning, although mechanical fault diagnosis has been solved by many effective methods, fault diagnosis under unbalanced data sets has always been a stubborn problem. The oversampling algorithm is currently recognized as an effective means to solve the problem of unbalanced data sets. The traditional oversampling algorithm is not only affected by the sample distribution, but also easily generates noise samples, which makes the decision boundary blurred. These drawbacks are not conducive to the classifier making predictions.
Based on the SMOTE, this paper proposes the new algorithm, MeanRadius-SMOTE, combining the sample center and radius. MeanRadius-SMOTE effectively avoids useless samples and noise samples in the process of generating new samples. In this paper, we conduct comparative experiments for SMOTE, LR-SMOTE, and MeanRadius-SMOTE algorithms and use SVM, RF, and GBDT classifiers on three linear unbalanced data sets and four step unbalanced data sets. Experimental results show that the MeanRadius-SMOTE algorithm can effectively balance data classes and improve the prediction performance of machine learning classifiers. From the perspective of various indicators, the MeanRadius-SMOTE algorithm is better than SMOTE and LR-SMOTE, and has better robustness. In the problem of unbalanced data sets, MeanRadius-SMOTE can more accurately predict the minority class without sacrificing the prediction performance of other classes, which is of great significance for mechanical fault diagnosis, and the combined model of MeanRadius-SMOTE and SVM is proved to be much better than other models.
Although this paper proves on PHM09 challenge data that MeanRadius-SMOTE has a good ability to deal with unbalanced data sets, considering the actual situation, future research can be carried out from the following aspects:
- (1)
- In this paper, in order to ensure that the experiment is carried out under a variety of unbalanced data sets, we use artificial unbalanced data sets in experiments. In future research, we will collect the failure unbalanced data sets of actual mechanical equipment to continue the verification experiment.
- (2)
- When constructing the data set in this paper, we only extracted the time–frequency domain features from the vibration signal. Currently, there are more methods to extract features from vibration signals, such as convolutional neural networks, wavelet packet decomposition, etc. Training sets composed of different types of features may have an impact on the performance of MeanRadius-SMOTE.
Author Contributions
Data curation, F.D. and S.Z.; validation, F.D.; investigation, S.Z. and Y.Y.; writing—original draft preparation, F.D. and Y.Y.; writing—review and editing, F.D., S.Z., and Z.C.; supervision, S.Z. and Z.C. All authors have read and agreed to the published version of the manuscript.
Funding
This article was supported by the National Natural Science Foundation of China (71871181); the Basic Research Project of Natural Science of Shaanxi Province (2022JM-433); the Key R&D Program of Shaanxi Province (2022GY-207, 2021ZDLGY10-06).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data in this article are the 2009 PHM data challenge of the gearbox.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yongbo, L.; Wang, S.; Deng, Z. Intelligent fault identification of rotary machinery using refined composite multi-scale Lempel–Ziv complexity. J. Manuf. Syst. 2021, 61, 725–735. [Google Scholar]
- Jiang, W.; Xie, C.; Zhuang, M.; Shou, Y.; Tang, Y. Sensor data fusion with Z-numbers and its application in fault diagnosis. Sensors 2016, 16, 1509. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal. Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Lu, S.; He, Q.; Yuan, T.; Kong, F. Online fault diagnosis of motor bearing via stochastic-resonance-based adaptive filter in an embedded. IEEE Trans. Syst. Man Cybern A 2018, 47, 1111–1122. [Google Scholar] [CrossRef]
- Cai, B.; Zhao, Y.; Liu, H.; Xie, M. A data-driven fault diagnosis methodology in Three-Phase inverters for PMSM drive systems. IEEE Trans. Power Electron. 2017, 32, 5590–5600. [Google Scholar] [CrossRef]
- Cofre-Martel, S.; Droguett, E.; Modarres, M. Big Machinery Data Preprocessing Methodology for Data-Driven Models in Prognostics and Health Management. Sensors 2021, 21, 6841. [Google Scholar] [CrossRef]
- Akilu, Y.; Sinha, J.; Nembhard, A. A novel fault diagnosis technique for enhancing maintenance and reliability of rotating machines. Struct. Health Monit. 2015, 14, 604–621. [Google Scholar]
- Yongbo, L.; Wang, X.; Si, S.; Huang, S. Entropy Based Fault Classification Using the Case Western Reserve University Data: A Benchmark Study. IEEE Trans. Reliab. 2020, 69, 754–767. [Google Scholar]
- Fernandez, A.; Garcia, S.; Luengo, J.; Bernado-Mansilla, E.; Herrera, F. Genetics-based machine learning for rule induction: State of the art, Taxonomy, and Comparative Study. IEEE Trans. Evol. Comput. 2010, 14, 913–941. [Google Scholar] [CrossRef]
- Swana, E.; Doorsamy, W.; Bokoro, P. Tomek Link and SMOTE Approaches for Machine Fault Classification with an Imbalanced Dataset. Sensors 2022, 22, 3246. [Google Scholar] [CrossRef]
- He, Z.; Shao, H.; Jing, L.; Cheng, J.; Yang, Y. Transfer fault diagnosis of bearing installed in different machines using enhanced deep auto-encoder. Measurement 2020, 152, 107393. [Google Scholar]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar] [PubMed]
- Shao, H.; Lin, J.; Zhang, L.; Galar, D.; Kumar, U. A novel approach of multisensory fusion to collaborative fault diagnosis in maintenance. Inf. Fusion 2021, 74, 65–76. [Google Scholar] [CrossRef]
- Martin-Diaz, I.; Morinigo-Sotelo, D.; Duque-Perez, O.; De, R. Early fault detection in induction motors using adaboost with imbalanced small data and optimized sampling. IEEE Trans. Ind. Electron. 2022, 53, 3066–3075. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Pan, T.; He, S. A small sample focused intelligent fault diagnosis scheme of machines via multi-modules learning with gradient penalized generative adversarial networks. IEEE Trans. Ind. Electron. 2021, 68, 10130–10141. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. 2017, 45, 351–400. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Chawla, N.; Hall, L.; Bowyer, K.; Kegelmeyer, W. SMOTE: Synthetic minority over-sampling technique. Artif. Intell. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the Conference on Aristophanes Upstairs and Downstairs, Magdalen Coll, Oxford, UK, 16–18 September 2004. [Google Scholar]
- Haibo, H.; Yang, B.; Garcia, E.; Shutao, L. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl.-Based Syst. 2020, 196, 105846. [Google Scholar] [CrossRef]
- Yen, S.; Lee, Y. Under-sampling approaches for improving prediction of the minority class in an imbalanced dataset. In Proceedings of the International Conference on Intelligent Computing, Kunming, China, 16–19 August 2006. [Google Scholar]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Proceedings of the 8th Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, 1–4 July 2001. [Google Scholar]
- Zhang, C.; Gao, W.; Song, J.; Jiang, J. An imbalanced data classification algorithm of improved autoencoder neural network. In Proceedings of the 8th International Conference on Advanced Computational Intelligence, Chiang Mai, Thailand, 14–16 February 2016. [Google Scholar]
- Cheng, F.; Zhang, J.; Wen, C. Cost-sensitive large margin distribution machine for classification of imbalanced data. Pattern Recognit. Lett. 2016, 80, 107–112. [Google Scholar] [CrossRef]
- Xu, Q.; Lu, S.; Jia, W.; Jiang, C. Imbalanced fault diagnosis of rotating machinery via multi-domain feature extraction and cost-sensitive learning. J. Manuf. Syst. 2020, 31, 1467–1481. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, M.; Lin, M. Deep laplacian auto-encoder and its application into imbalanced fault diagnosis of rotating machinery. Measurement 2020, 31, 1467–1481. [Google Scholar] [CrossRef]
- Yongbo, L.; Du, X.; Wang, X.; Si, S. Industrial gearbox fault diagnosis based on multi-scale convolutional neural networks and thermal imaging. ISA Trans. 2022, in press. [Google Scholar]
- Yongbo, L.; Wang, S.; Yang, Y.; Deng, Z. Multiscale symbolic fuzzy entropy: An entropy denoising method for weak feature extraction of rotating machinery. Mech. Syst. Signal. Process. 2022, 162, 108052. [Google Scholar]
- Zhang, C.; Chen, J.; Guo, X. A gear fault diagnosis method based on EMD energy entropy and SVM. Shock Vib. 2010, 29, 216–220. [Google Scholar]
- Yongbo, L.; Wang, X.; Si, S.; Du, X. A New Intelligent Fault Diagnosis Method of Rotating Machinery under Varying-Speed Conditions Using Infrared Thermography. Complexity 2019, 2019, 2619252. [Google Scholar]
- Farajzadeh-Zanjani, M.; Razavi-Far, R.; Saif, M. Efficient sampling techniques for ensemble learning and diagnosing bearing defects under class imbalanced condition. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016. [Google Scholar]
- Mao, W.; He, L.; Yan, Y.; Wang, J. Online sequential prediction of bearings imbalanced fault diagnosis by extreme learning machine. Mech. Syst. Signal. Process. 2017, 83, 450–473. [Google Scholar] [CrossRef]
- Razavi-Far, R.; Farajzadeh-Zanjani, M.; Saif, M. An integrated class-imbalanced learning scheme for diagnosing bearing defects in induction motors. IEEE Trans. Ind. Inform. 2017, 13, 2758–2769. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal. Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Lan, Y.; Han, X.; Xiong, X.; Huang, J.; Zong, W.; Ding, X.; Ma, B. Two-step fault diagnosis framework for rolling element bearings with imbalanced data based on GSA-WELM and GSA-ELM. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2018, 232, 2937–2947. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Zhang, K.; Zhoudong, H.; Yi, C. Review of multiple fault diagnosis methods. IET Control Theory Appl. 2015, 32, 1143–1157. [Google Scholar]
- Lei, Y.; He, Z.; Zi, Y.; Hu, Q. Fault diagnosis of rotating machinery based on multiple ANFIS combination with GAs. Mech. Syst. Signal. Process. 2007, 21, 2280–2294. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).