1. Introduction
Many smart technologies have been applied in agriculture [
1]. “Smart farm” has become a common word which refers to farms applying intelligent and autonomous technologies such as IoT (Internet of Things) and AI (Artificial Intelligence) on crop monitoring and robots for post-harvesting. Tomato is an important horticultural crop and is popular in smart farms in many countries. Many types of research related to tomatoes are made to increase the tomato quality and production, such as leaf disease detection [
2,
3,
4,
5]. These researchers used different deep convolution neural networks to classify the tomato leaf images to different types of diseases. There is also other research such as tomato fruit detection and counting [
6], tomato flower detection and counting [
7], tomato leaf area estimation [
8], and tomato harvesting by a robot [
9].
Tomato sucker pruning is an important activity, but there is no public research about how to remove tomato suckers automatically.
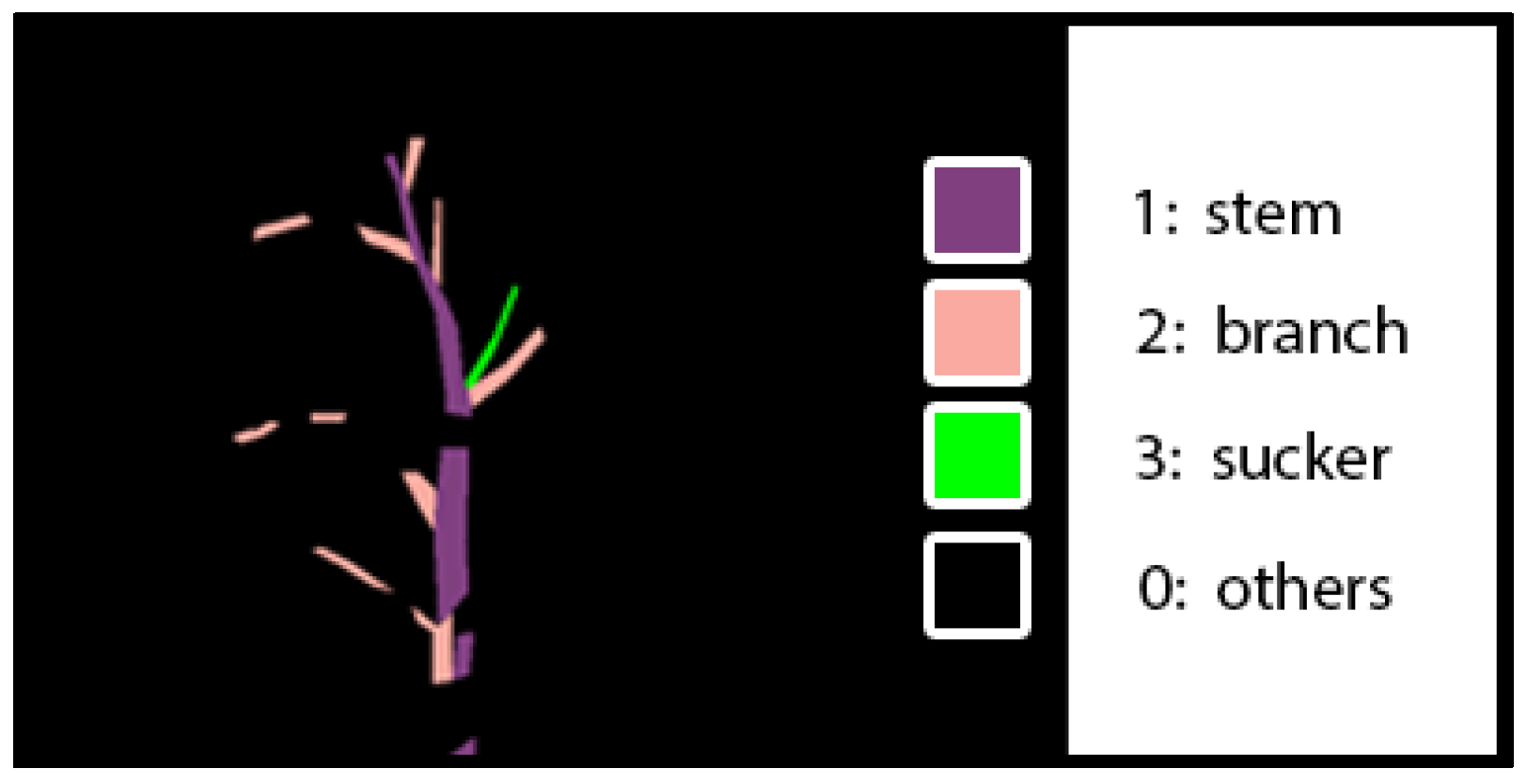
Figure 1 shows an example of a tomato sucker which is green in the right image of
Figure 1. A sucker is always between a stem and a branch. It should be cut off when it is small before it becomes a stem. Usually, farmers remove suckers from their experiences. In 2007, Ara et al.’s research [
10] demonstrated that pruning affects not only yield but also fruit characters. Their experiments showed that tomato yield is much higher, tomato fruit width is larger, and tomato fruit wall is thicker with pruning. Pruning also has a positive affection on the disease and insect infestation of tomato plants [
11]. Because of these benefits, we study this subject.
The research on grape pruning [
12] or apple pruning [
13] showed that branches should be segmented before finding a pruning point. Therefore, in this research, we studied an approach for sucker tomato detection by semantic segmentation neural network. The result of this neural network shows which parts of images are suckers. With this result, other algorithms can be applied to find the position of sucker cut-off points in the future. This is the primary step for future tomato pruning by robots automatically.
Before building our own semantic segmentation neural network, we surveyed current semantic segmentation neural networks such as UNet [
14], SegNet [
15], and Deeplab V3 [
16]. Although these networks can reach high accuracy, their numbers of parameters are high, which leads to intensive device memory. We will implement this AI program on embedded or low-resource systems so that this is a weak point of these networks. On the other hand, some real-time image semantic segmentation networks research has been public recently, such as ICNet [
17], BiSeNet [
18], and Fast-SCNN [
19]. However, these networks do not meet the accuracy requirements. We get pressure on both accuracy and time of execution. This paper proposes a new semantic segmentation neural network that can run in real-time on low-memory GPU with high performance. We used Depth-wise Convolution [
20] to reduce computation. We also used a Bottleneck residual block [
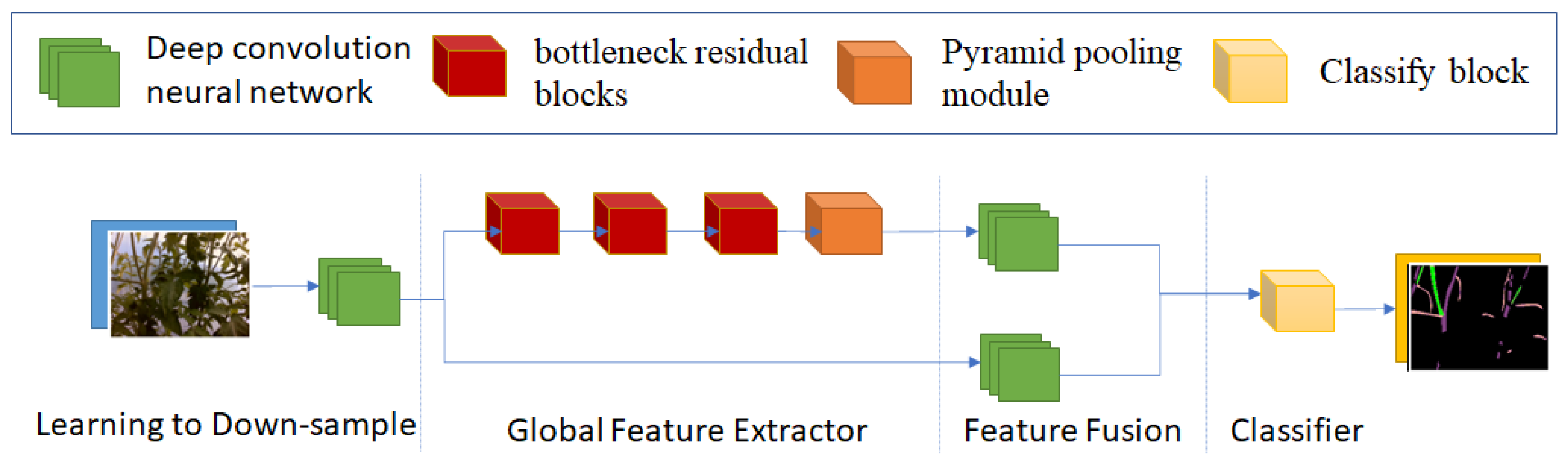
21], which is used commonly in real-time networks, to extract features of images. To get the global context feature, which is quite important to distinguish tomato plant parts, a Pyramid Pooling block [
22] was added to the network. Moreover, we adopted a deep layer cascade (LC) method [
23] to optimize the network’s output. We find that decreasing the resolution of layers leads to losing a lot of information with our dataset. Furthermore, we cannot increase the feature channels too much because it costs memory and time. Therefore, we focused on different ways to extract features. We implemented three different feature blocks to get image features and keep the number of feature channels low.
For training, evaluating, and comparing the proposed neural network with other networks, we made an RGB-D tomato dataset. Although RGB-D images gain a lot of attention in the recognition task of computer vision, they are mostly applied to indoor semantic segmentation research [
24,
25,
26] or salient object detection research [
27,
28,
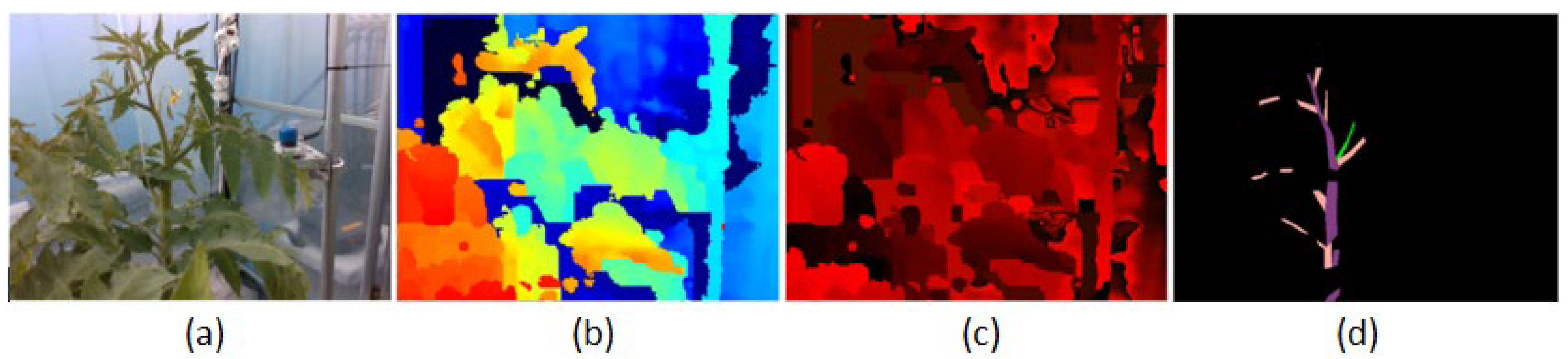
29]. The interesting part of the research is how to fuse the feature of depth images and RGB images. Although the moment and the way fusion happens may be different, the processes that extract RGB and Depth image features are usually separate. Our research works on tomato plant parts which are very closed to each other. Leaves take an especially high appearance rate and cover the other tomato parts. The depth information is not that different between adjacent objects. We did some experiments using complete depth information and RGB images as inputs. Their results are not accurate. However, the depth information can help us to separate the close and the far tomato plants when they are captured in one image. Sometimes, in an RGB image, a stem crosses the other stem at its node like in the left image of
Figure 2. In reality, stem 2 is further than stem 1 if we look from the camera. From the viewpoint of the 2D image, stem 1 is between a branch and stem 2. It is similar to a sucker and is often recognized as a sucker by many models. We want to use depth information to reduce this misunderstanding. The depth or the distance of a sucker to the camera is often similar to that of its stem. In the example of
Figure 2, the depth of stem 1 is higher than the depth of stem 2. This information gives the network more data to recognize that stem 1 is not a sucker, and it helps the model distinguish a real sucker from other parts. Therefore, we propose a new method for fusion depth information. We do not use full-depth information. We only use the depth information for objects that models may have difficulty predicting.
Finally, our research works on RGB-D images, so we designed a suitable structure for depth image processing to efficiently exploit the depth information. Our model has a better balance between accuracy and time of execution.
In summary, our contributions are:
We propose a semantic segmentation neural network. This real-time network can be executed on low GPU devices with a low number of parameters and has a better balance between accuracy and time of execution to other networks.
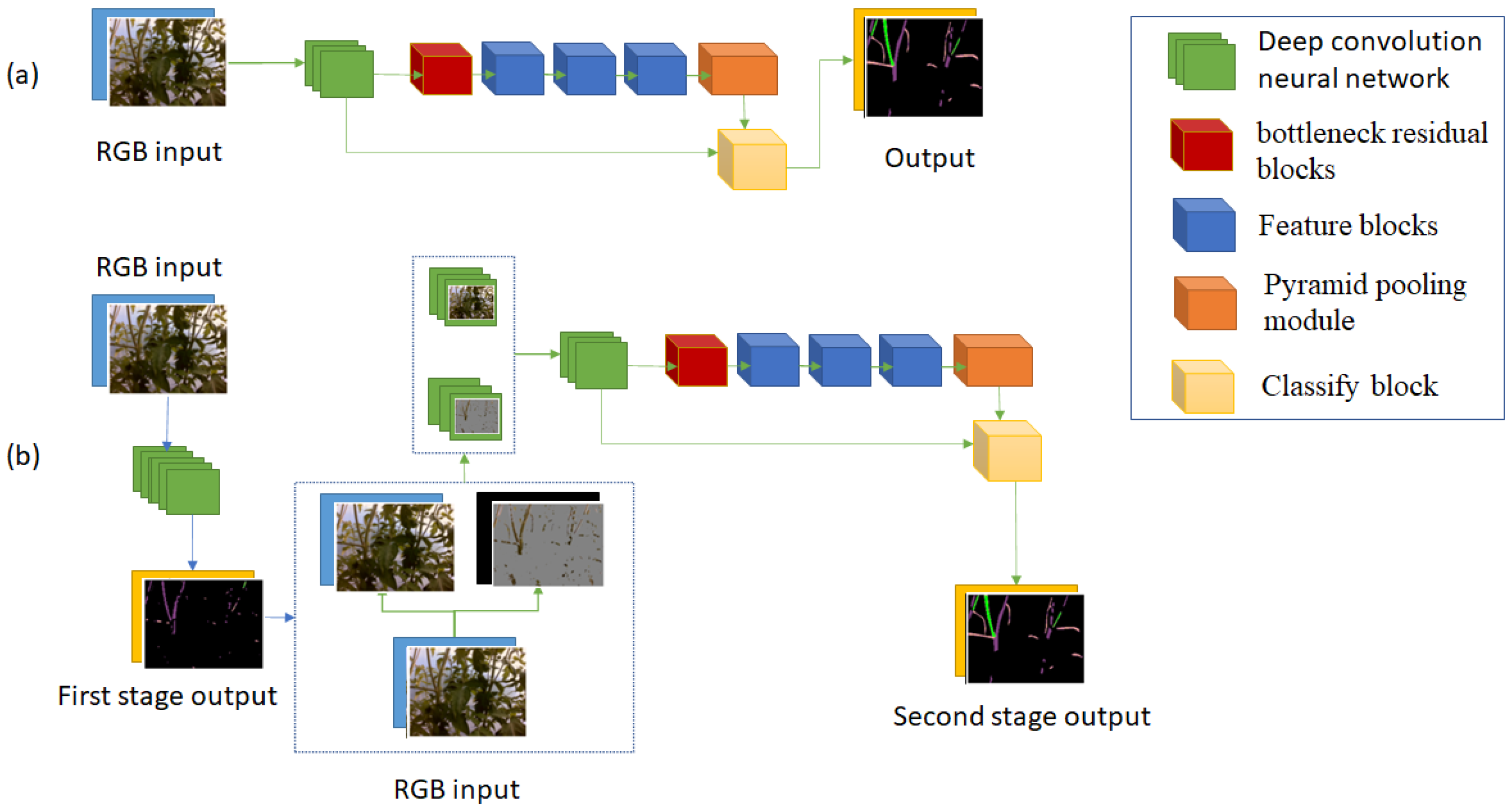
We propose a two-stage neural network by adapting the idea deep layer cascade (LC) method [
23] in a different way which is easier in implementation, training, and applying depth information. It gives remarkable progress in prediction.
We propose a method that uses both depth information and RGB images in prediction for better results.
We make a new RGB-D dataset with more than 600 images of tomato plants.
5. Experiment and Discussion
5.1. Setup Experiment
In this part, we demonstrate our model performance on three different tasks. First, we focused on accuracy and speed by comparing our proposed neural network with Fast-CNN and Deeplabv3_resnet50 implemented by the Torchvision library. We chose Fast-CNN because it is a real-time network proven to be better than the other real-time networks [
19]. Deeplabv3 is not a real-time network, but it is one of the best segmentation neural networks at the moment. Secondly, we prove that using depth information and multi-stages improves the model’s accuracy by comparing three proposed neural network versions.
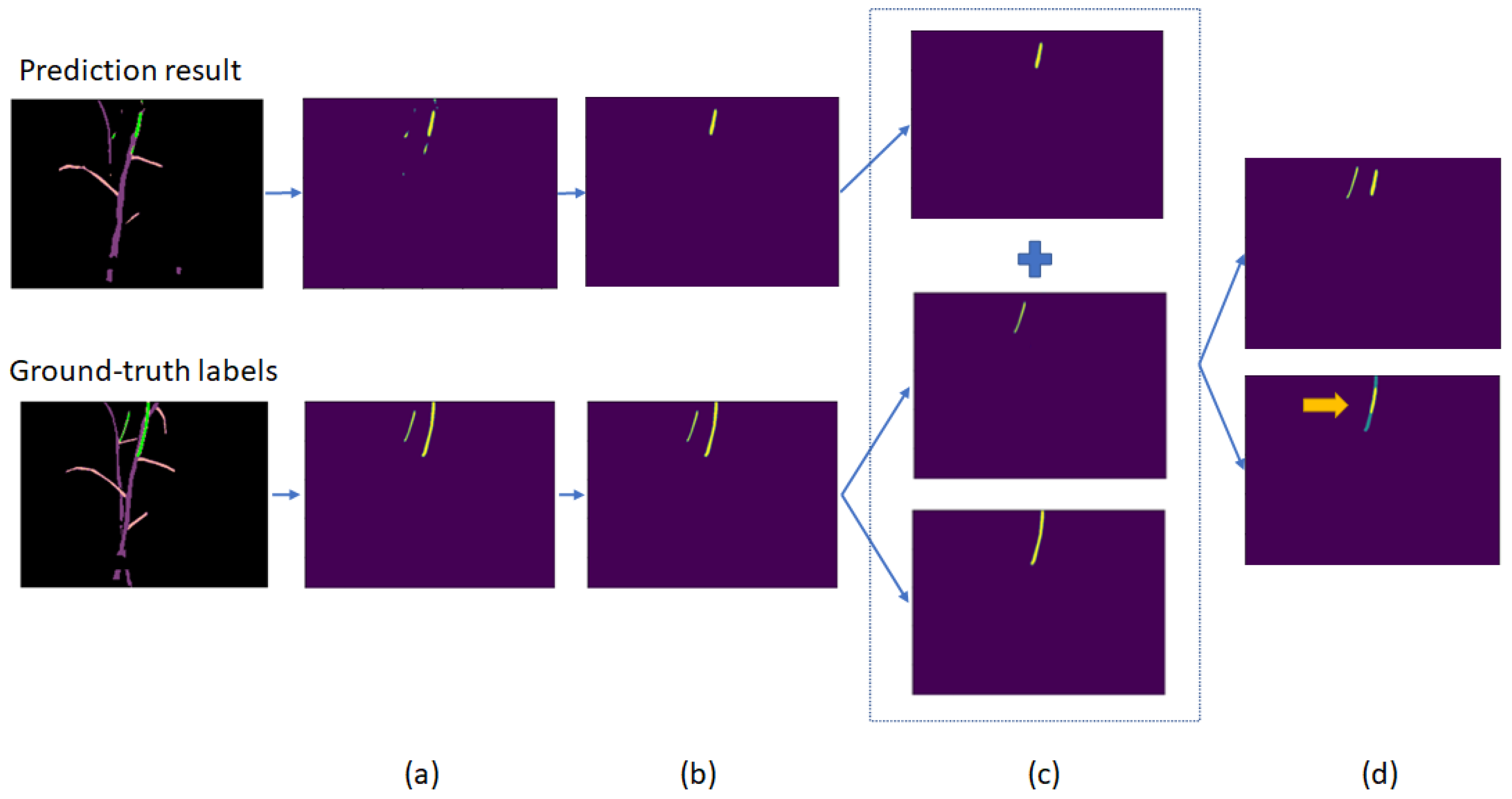
Secondly, we focus on detecting suckers, so we used the method proposed in
Section 4.3 to calculate the percentage of correctly detected suckers to rank models.
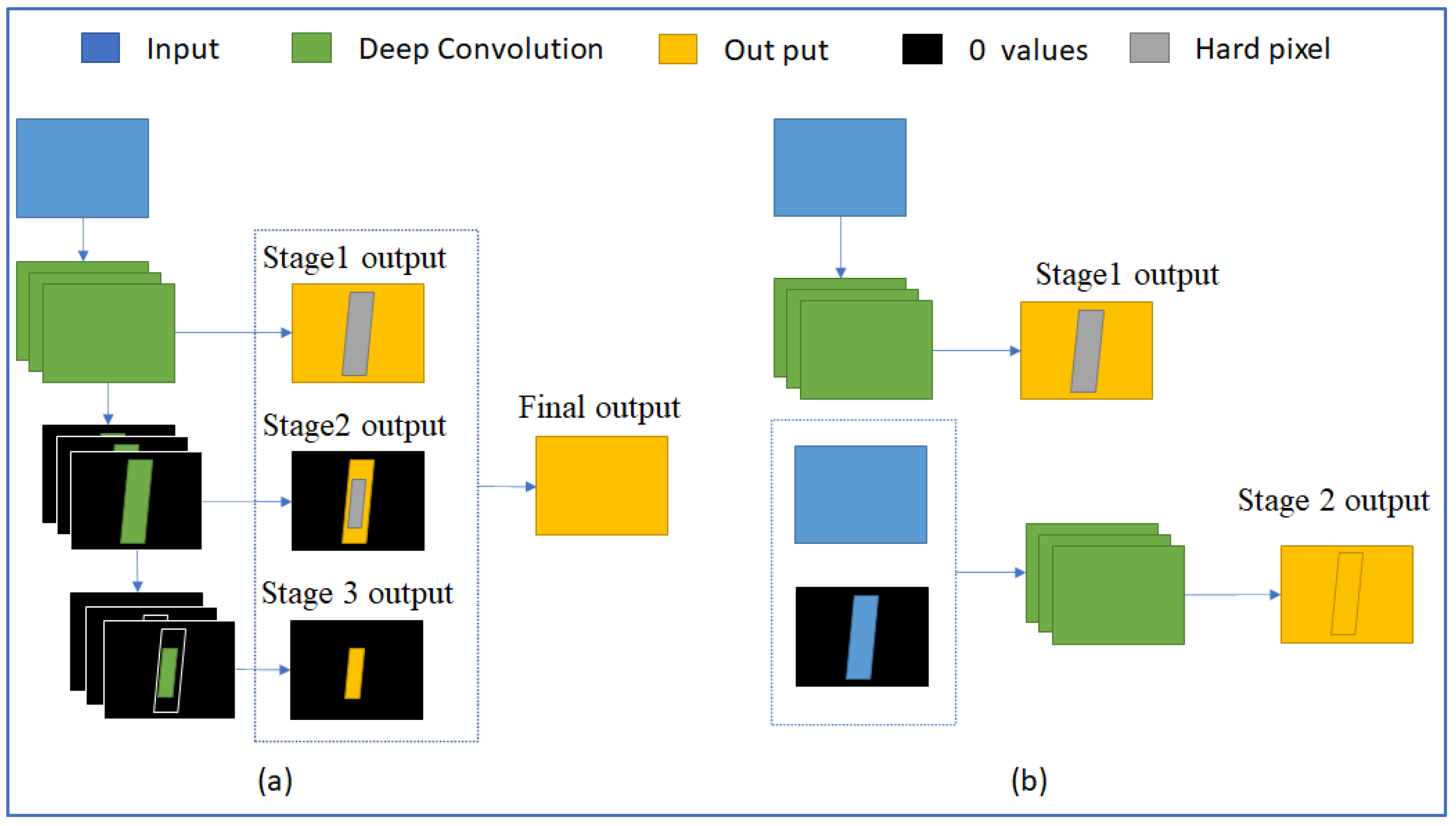
Finally, to prove the benefit of using depth information and a two-stage model, we build two more semantic segmentation neural network versions, which are modified from the proposed neural network. Version 1 is the network with the structure of the second stage and no depth information. Version 2 is the network that has two stages but no depth images. The structure of Version 1 and Version 2 are shown in
Figure 10.
We write our program in python 3.9 and use PyTorch 1.8 and TorchVision 1.9 library to train and test on a machine with GPU Nvidia Geforce RTX 3090 with CUDA Version 11.2.
We use some augmentation techniques on RGB images: blurring, horizontal flipping, scaling up with a random rate from 1.0 to 2.0, color channel noise, and brightness. Since these operations do not change objects’ spatial structure, the depth information is still correct for new RGB images.
Because our proposed neural network has two stages, the way of training is different. Firstly, we optimized the first stage by using only stage 1 backward to get the best weight of stage 1. Then we optimized only second stage 2 to get the best output. We did not use pre-train weight during training. After many experiments, we found that the network has the best result with batch size = 12, epochs = 40, and learning rate = 0.025, decreasing gradually with each iteration with a rate = 0.997 on the tomato dataset.
We used 80% of images in the dataset for training, 10% for evaluation, and 10% for testing the three models.
5.2. Experimental Result
In this experiment, we use Class IOU (intersection over union), which is very popular to evaluate the accuracy of semantic segmentation neural networks, percentage of tomato sucker detection, and Fps (frames per second) to assess the neural networks.
Table 8 shows the best result of DeepLab V3, Fast -SCNN, and the proposed neural network. The proposed neural network has the smallest number of parameters. It has the best IOU score at 64.05%. Its finding sucker score is lower than DeepLab V3 finding sucker score but much higher than Fast-SCNN finding sucker score. Its Fps is less than Fast-SCNN Fps but is much higher than DeepLab V3 Fps. This result proves that our proposed neural network has the best performance in real-time networks, and the accuracy of our proposed neural network and the other non-real-time network is approximate in tomato sucker detection.
Table 9 shows that the proposed neural network has the best results. Version 1 with one stage is not as good as the two-stage models, but it is the fastest model at 160.7 Fps. Applying a two-stage network structure makes Version 2 and the proposed neural network run slower. The proposed neural network has a higher IOU score and percentage of sucker detection than Version 2, although both neural networks applied the two-stage structure. It is because the input of the proposed neural network used extra depth information, while version 2 used only RGB images.
There is always a trade-off between accuracy and execution time. If a network runs faster, its accuracy is lower.
Table 8 shows that the Fps values decrease gradually from Fast-SCNN to the proposed Neural Network to Deeplab V3 while their values of percentage of sucker detection increase, respectively. Similarly, the speed of Version 1 is the highest, as it has the lowest IOU score and percentage of sucker detection.
The more feature channels the neural network has, the more parameters the model has, and the more accurate and slower it would be. For example, Deeplab V3 has 41,999,705 parameters and an IOU score at 63.88, and it runs at 77.6 frames per second, while Fast-SCNN has 1,135,604 parameters and an IOU score at 55.65 and runs at 188.3 frames per second. However, our proposed neural network has a smaller number of parameters but a higher IOU score because its structure is more complicated. It has two stages, two inputs, and two outputs, so it runs slower and gets high accuracy. This can be seen more clearly when we compare Version 1 and Version 2. Their number of parameters is almost equal. Version 2 has two stages. Version 1 has only one stage, so its Fps is higher than other Version 2, but its IOU score and percentage of sucker detection are lower.
These data tables prove that our proposed neural network has the best balance between time execution and accuracy. To increase the accuracy, this neural network uses more complicated and more information of the input instead of increasing the number of parameters.
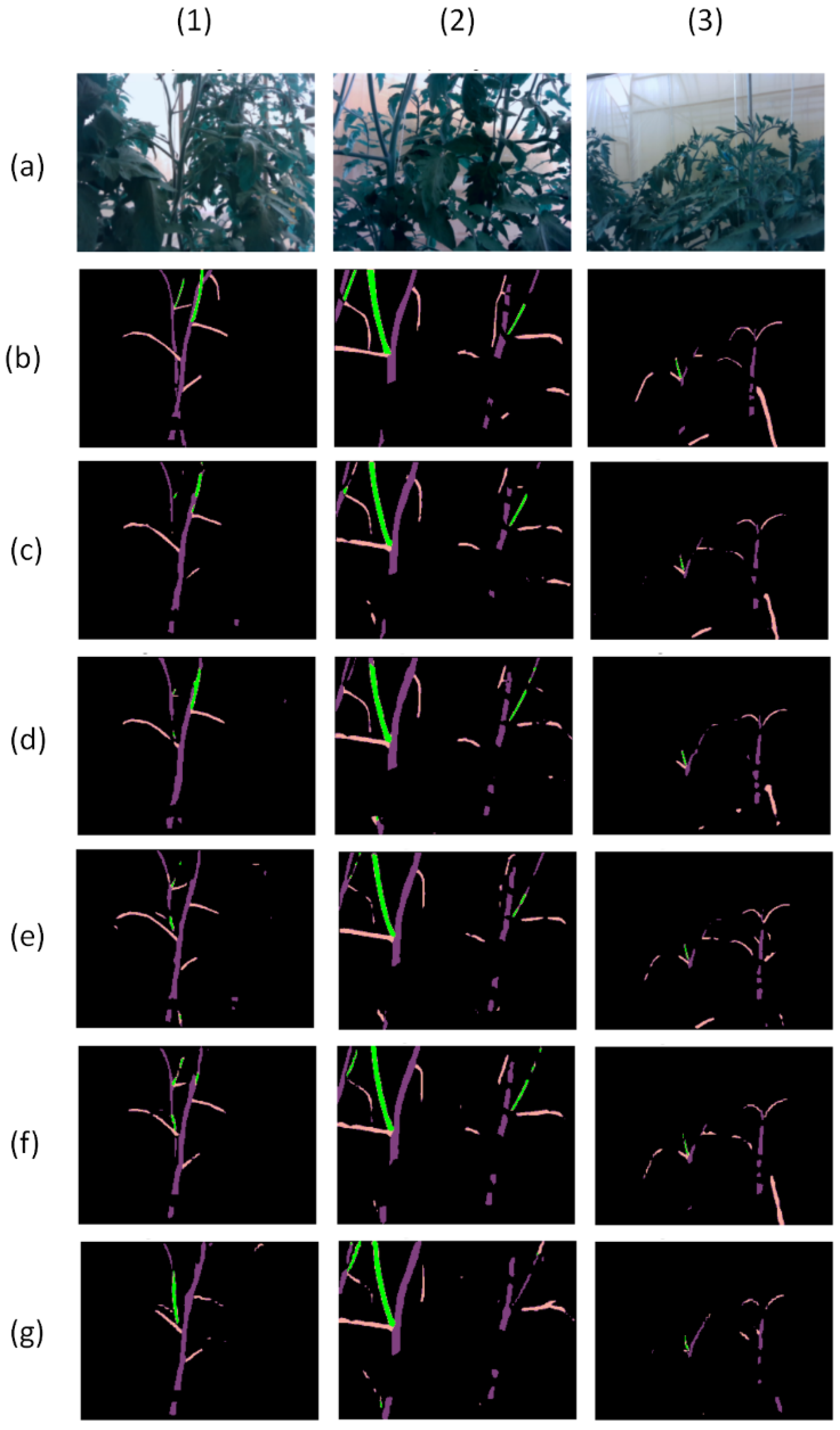
Figure 11 presents three examples and prediction results of the above six models. The first example is one case where five models misunderstand the behind stem as a sucker, except our proposed in this experiment. In the second example, the proposed neural network and Fast-SCNN can detect two suckers, while Deeplab V3 can detect three suckers. In the third example, three neural networks can detect a sucker, but Fast-SCNN did not recognize lots of branch parts. These examples show that Deeplab V3 can detect the most tomato suckers, the proposed neural network can avoid some errors in some exceptional cases, and Fast-SCNN has the most errors in prediction.
5.3. Discussion
The tomato sucker RGB-D images are captured at the greenhouse by the Realsense camera. The depth information could be affected by daylight. The result could be better if we optimize the depth of information. The Dataset should be extended for better training.
If model speed prediction is the most critical factor, we can choose the p neural network Version 1. If the depth of information is not good, Version 2 should be selected.
Although the proposed neural network performs best in our experiment, it can detect 80.2% suckers, and the result usually has noises. To continue developing a method of finding a cut-off point, we must consider some constraints, such as the noise area threshold; the valid suckers are the suckers between stems and branches to eliminate the error.
The proposed neural network has good performance on the tomato dataset and tomato sucker detection but could not have such performance on the other dataset and other functions. Firstly, in our study, there are only four classes to segment. If the number of classes increases, it requires more parameters. Secondly, the proposed neural network does not decrease the resolution of images as much as the other neural networks do during the extracting feature process because stems, branches, and suckers are thin and long. If the target objects are in different shapes, the performance of other networks could be improved.
The training process of the proposed neural network is longer and more complicated than other neural networks. If neural networks have one stage, the training process runs one time to optimize the parameters, while for the neural networks with two stages, the training process must run twice. Firstly, we must set the first stage output as the final output, and the training process could optimize the first stage’s parameters. Then the second output is set as the final output, and the second stage parameters could be optimized by the training process.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}