
Combination of Feature Selection and Resampling Methods to Predict Preterm Birth Based on Electrohysterographic Signals from Imbalance Data

 , ,
, ,  , , and
, , and
Abstract
1. Introduction
1.1. Preterm Labor
1.2. Electrohysterography for Preterm Labor Prediction
1.3. Resampling Methods for Imbalance Data Learning
2. Materials and Methods
2.1. Database Description
2.2. EHG Signal Analysis
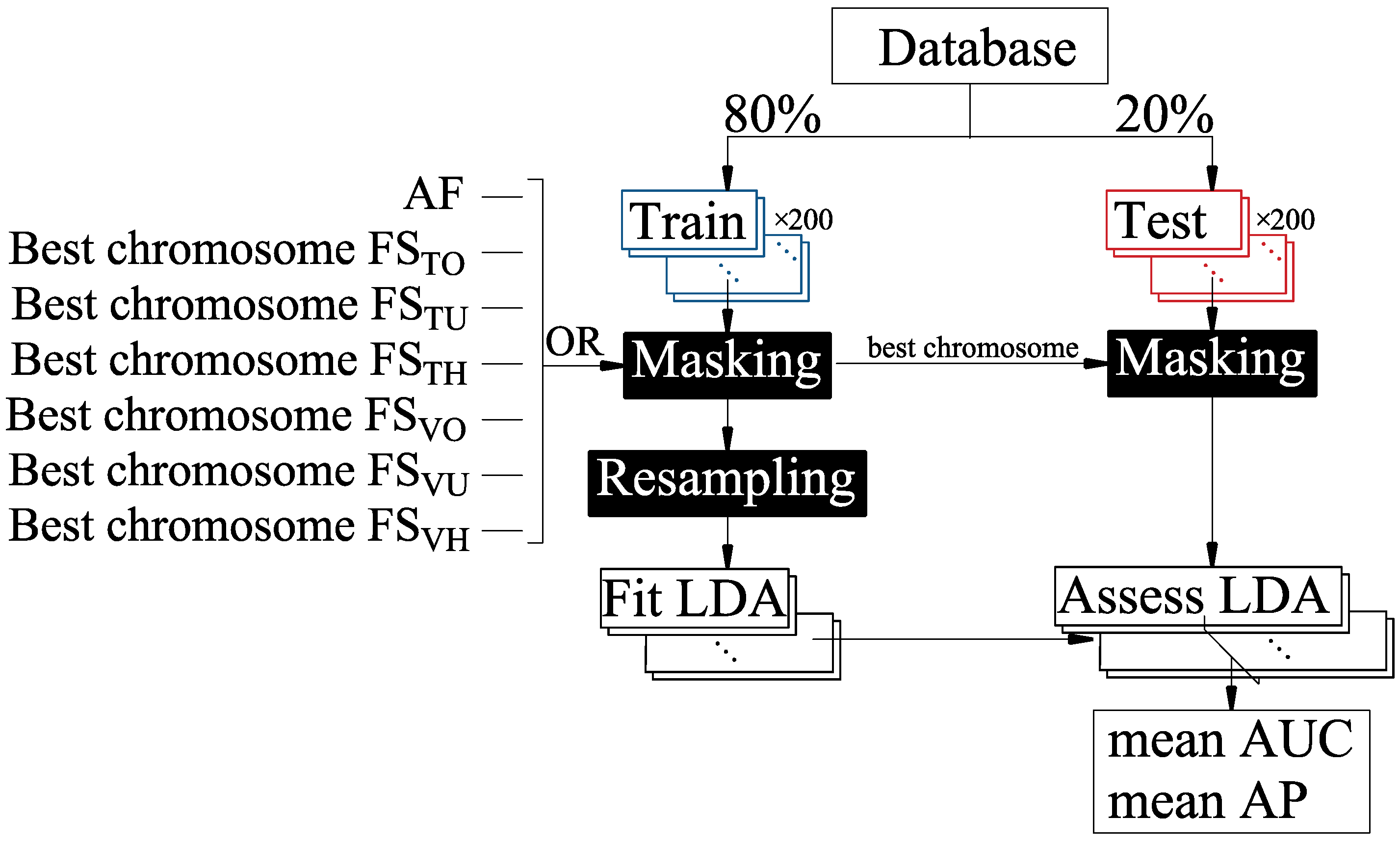
2.3. Classifier Design and Evaluation
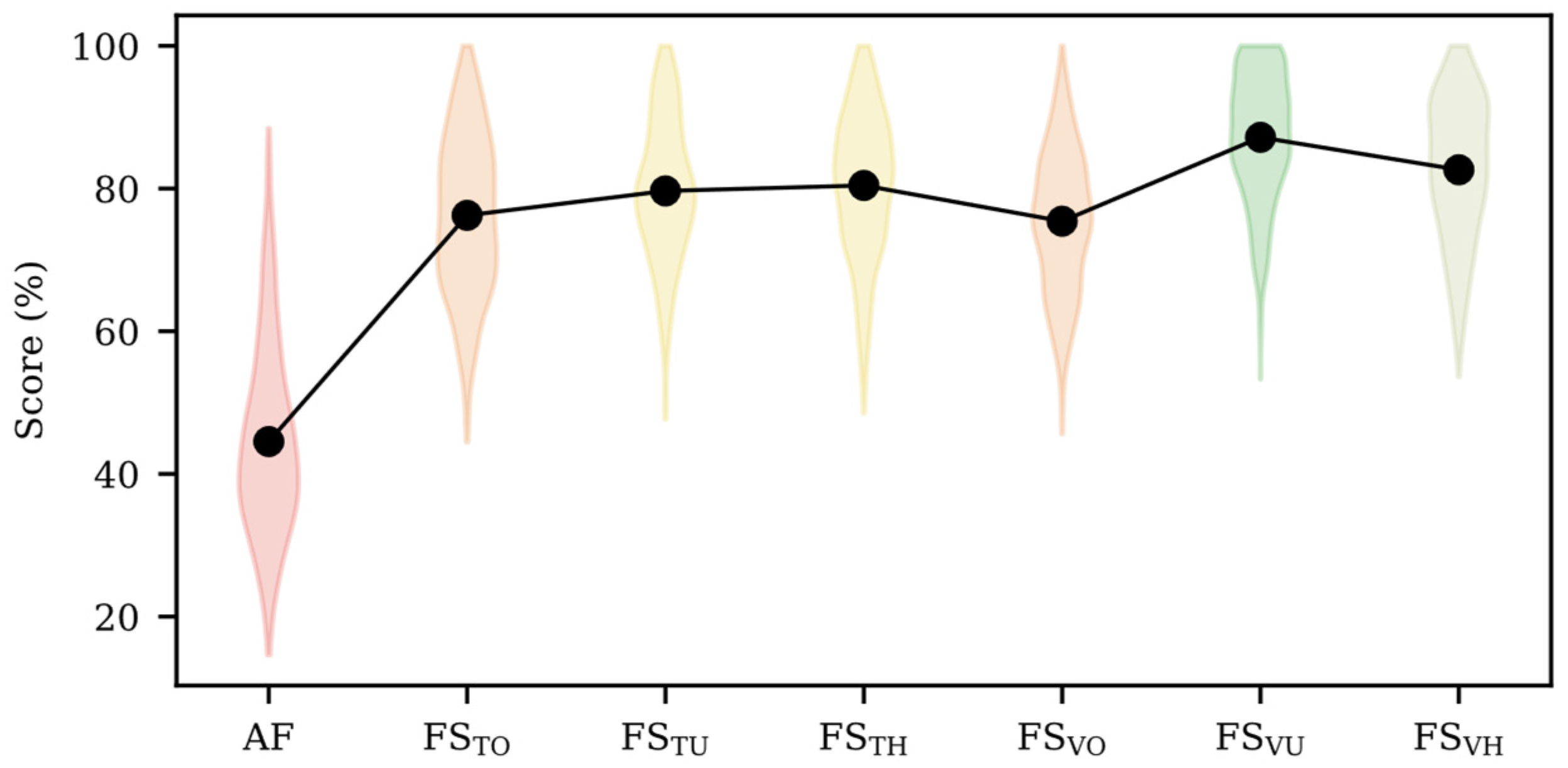
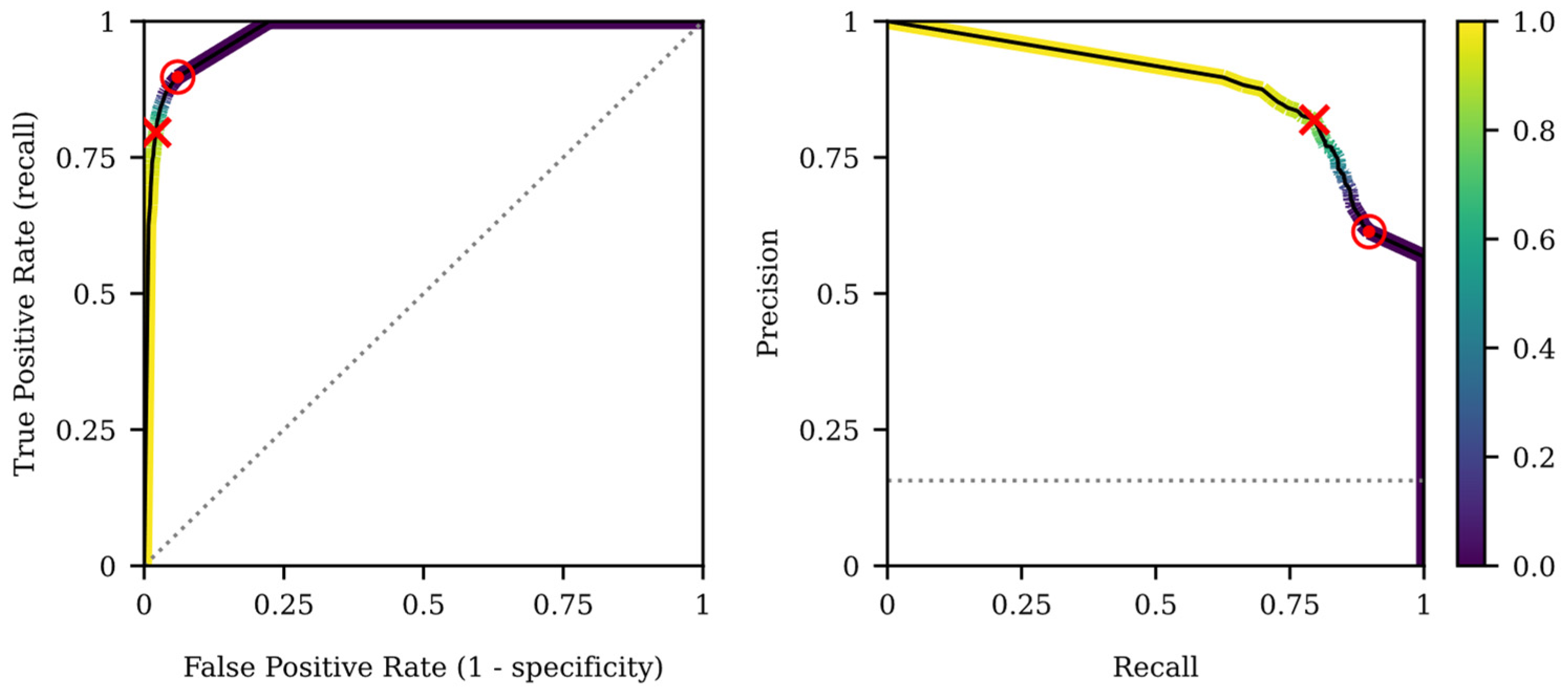
3. Results
4. Discussion
4.1. Imbalanced Data Learning
4.2. Preterm Labor Prediction System
4.3. Limitations, Future Works and Practical Implications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. Recommended definitions, terminology and format for statistical tables related to the perinatal period and use of a new certificate for cause of perinatal deaths. Modifications recommended by FIGO as amended 14 October 1976. Acta Obstet. Gynecol. Scand. 1977, 56, 247–253. [Google Scholar] [CrossRef]
- Vogel, J.P.; Chawanpaiboon, S.; Moller, A.-B.; Watananirun, K.; Bonet, M.; Lumbiganon, P. The global epidemiology of preterm birth. Best Pract. Res. Clin. Obstet. Gynaecol. 2018, 52, 3–12. [Google Scholar] [CrossRef] [PubMed]
- Mandy, G.T. Short-term complications of the preterm infant. UpToDate 2019, 46, 1–17. [Google Scholar]
- Petrou, S.; Yiu, H.H.; Kwon, J. Economic consequences of preterm birth: A systematic review of the recent literature (2009–2017). Arch. Dis. Child. 2019, 104, 456–465. [Google Scholar] [CrossRef]
- Waitzman, N.J.; Jalali, A.; Grosse, S.D. Preterm birth lifetime costs in the United States in 2016: An update. Semin. Perinatol. 2021, 45, 151390. [Google Scholar] [CrossRef]
- Jacob, J.; Lehne, M.; Mischker, A.; Klinger, N.; Zickermann, C.; Walker, J. Cost effects of preterm birth: A comparison of health care costs associated with early preterm, late preterm, and full-term birth in the first 3 years after birth. Eur. J. Health Econ. 2017, 18, 1041–1046. [Google Scholar] [CrossRef] [PubMed]
- Garfield, R.E.; Maner, W.L. Physiology and electrical activity of uterine contractions. Semin. Cell Dev. Biol. 2007, 18, 289–295. [Google Scholar] [CrossRef]
- Leaños-Miranda, A.; Nolasco-Leaños, A.G.; Carrillo-Juárez, R.I.; Molina-Pérez, C.J.; Isordia-Salas, I.; Ramírez-Valenzuela, K.L. Interleukin-6 in amniotic fluid: A reliable marker for adverse outcomes in women in preterm labor and intact membranes. Fetal Diagn. Ther. 2021, 48, 313–320. [Google Scholar] [CrossRef]
- Devedeux, D.; Marque, C.; Mansour, S.; Germain, G.; Duchêne, J. Uterine electromyography: A critical review. Am. J. Obstet. Gynecol. 1993, 169, 1636–1653. [Google Scholar] [CrossRef]
- Fele-Žorž, G.; Kavšek, G.; Novak-Antolič, Ž.; Jager, F. A comparison of various linear and non-linear signal processing techniques to separate uterine EMG records of term and pre-term delivery groups. Med. Biol. Eng. Comput. 2008, 46, 911–922. [Google Scholar] [CrossRef]
- Garcia-Casado, J.; Ye-Lin, Y.; Prats-Boluda, G.; Mas-Cabo, J.; Alberola-Rubio, J.; Perales, A. Electrohysterography in the diagnosis of preterm birth: A review. Physiol. Meas. 2018, 39, 02TR01. [Google Scholar] [CrossRef] [PubMed]
- Schlembach, D.; Maner, W.L.; Garfield, R.E.; Maul, H. Monitoring the progress of pregnancy and labor using electromyography. Eur. J. Obstet. Gynecol. Reprod. Biol. 2009, 144, 2–8. [Google Scholar] [CrossRef] [PubMed]
- Mas-Cabo, J.; Prats-Boluda, G.; Garcia-Casado, J.; Alberola-Rubio, J.; Monfort-Ortiz, R.; Martinez-Saez, C.; Perales, A.; Ye-Lin, Y. Electrohysterogram for ANN-Based Prediction of Imminent Labor in Women with Threatened Preterm Labor Undergoing Tocolytic Therapy. Sensors 2020, 20, 2681. [Google Scholar] [CrossRef]
- Mas-Cabo, J.; Ye-Lin, Y.; Garcia-Casado, J.; Díaz-Martinez, A.; Perales-Marin, A.; Monfort-Ortiz, R.; Roca-Prats, A.; López-Corral, Á.; Prats-Boluda, G. Robust Characterization of the Uterine Myoelectrical Activity in Different Obstetric Scenarios. Entropy 2020, 22, 743. [Google Scholar] [CrossRef] [PubMed]
- Nieto-del-amor, F.; Beskhani, R.; Ye-lin, Y.; Garcia-casado, J.; Diaz-martinez, A. Assessment of Dispersion and Bubble Entropy Measures for Enhancing Preterm Birth Prediction Based on Electrohysterographic Signals. Sensors 2021, 21, 6071. [Google Scholar] [CrossRef]
- Lemancewicz, A.; Borowska, M.; Kuć, P.; Jasińska, E.; Laudański, P.; Laudański, T.; Oczeretko, E. Early diagnosis of threatened premature labor by electrohysterographic recordings—The use of digital signal processing. Biocybern. Biomed. Eng. 2016, 36, 302–307. [Google Scholar] [CrossRef]
- Vrhovec, J.; Macek, A. An Uterine Electromyographic Activity as a Measure of Labor Progression. In Applications of EMG in Clinical and Sports Medicine; InTech: London, UK, 2012. [Google Scholar]
- Hassan, M.; Terrien, J.; Marque, C.; Karlsson, B. Comparison between approximate entropy, correntropy and time reversibility: Application to uterine electromyogram signals. Med. Eng. Phys. 2011, 33, 980–986. [Google Scholar] [CrossRef]
- Nieto-del-Amor, F.; Prats-Boluda, G.; Martinez-De-Juan, J.L.; Diaz-Martinez, A.; Monfort-Ortiz, R.; Diago-Almela, V.J.; Ye-Lin, Y. Optimized Feature Subset Selection Using Genetic Algorithm for Preterm Labor Prediction Based on Electrohysterography. Sensors 2021, 21, 3350. [Google Scholar] [CrossRef]
- Mas-Cabo, J.; Prats-Boluda, G.; Garcia-Casado, J.; Alberola-Rubio, J.; Perales, A.; Ye-Lin, Y. Design and Assessment of a Robust and Generalizable ANN-Based Classifier for the Prediction of Premature Birth by means of Multichannel Electrohysterographic Records. J. Sens. 2019, 2019, 5373810. [Google Scholar] [CrossRef]
- Włodarczyk, T.; Płotka, S.; Szczepański, T.; Rokita, P.; Sochacki-Wójcicka, N.; Wójcicki, J.; Lipa, M.; Trzciński, T. Machine learning methods for preterm birth prediction: A review. Electronics 2021, 10, 586. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012; ISBN 978026208029. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Denil, M.; Trappenberg, T. Overlap versus imbalance. In Proceedings of the Canadian Conference on Artificial Intelligence, Ottawa, ON, Canada, 31 May–2 June 2010; Volume 6085 LNAI, pp. 220–231. [Google Scholar] [CrossRef]
- Vandewiele, G.; Dehaene, I.; Kovács, G.; Sterckx, L.; Janssens, O.; Ongenae, F.; De Backere, F.; De Turck, F.; Roelens, K.; Decruyenaere, J.; et al. Overly optimistic prediction results on imbalanced data: A case study of flaws and benefits when applying over-sampling. Artif. Intell. Med. 2021, 111, 101987. [Google Scholar] [CrossRef] [PubMed]
- Vluymans, S. Learning from imbalanced data. Stud. Comput. Intell. 2019, 807, 81–110. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fergus, P.; Idowu, I.; Hussain, A.; Dobbins, C. Advanced artificial neural network classification for detecting preterm births using EHG records. Neurocomputing 2016, 188, 42–49. [Google Scholar] [CrossRef]
- Smrdel, A.; Jager, F. Separating sets of term and pre-term uterine EMG records. Physiol. Meas. 2015, 36, 341–355. [Google Scholar] [CrossRef]
- Fergus, P.; Cheung, P.; Hussain, A.; Al-Jumeily, D.; Dobbins, C.; Iram, S. Prediction of Preterm Deliveries from EHG Signals Using Machine Learning. PLoS ONE 2013, 8, e77154. [Google Scholar] [CrossRef]
- Ren, P.; Yao, S.; Li, J.; Valdes-Sosa, P.A.; Kendrick, K.M. Improved Prediction of Preterm Delivery Using Empirical Mode Decomposition Analysis of Uterine Electromyography Signals. PLoS ONE 2015, 10, e0132116. [Google Scholar] [CrossRef]
- Koziarski, M.; Woźniak, M.; Krawczyk, B. Combined Cleaning and Resampling algorithm for multi-class imbalanced data with label noise. Knowl.-Based Syst. 2020, 204, 106223. [Google Scholar] [CrossRef]
- Loyola-González, O.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A.; García-Borroto, M. Study of the impact of resampling methods for contrast pattern based classifiers in imbalanced databases. Neurocomputing 2016, 175, 935–947. [Google Scholar] [CrossRef]
- Liu, Y.; An, A.; Huang, X. Boosting prediction accuracy on imbalanced datasets with SVM ensembles. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 9–12 April 2006; Volume 3918 LNAI, pp. 107–118. [Google Scholar] [CrossRef]
- Junsomboon, N.; Phienthrakul, T. Combining over-sampling and under-sampling techniques for imbalance dataset. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; Volume Part F1283, pp. 243–247. [Google Scholar] [CrossRef]
- Park, S.; Park, H. Combined oversampling and undersampling method based on slow-start algorithm for imbalanced network traffic. Computing 2021, 103, 401–424. [Google Scholar] [CrossRef]
- Fujiwara, K.; Huang, Y.; Hori, K.; Nishioji, K.; Kobayashi, M.; Kamaguchi, M.; Kano, M. Over- and Under-sampling Approach for Extremely Imbalanced and Small Minority Data Problem in Health Record Analysis. Front. Public Health 2020, 8, 178. [Google Scholar] [CrossRef] [PubMed]
- Napierala, K.; Stefanowski, J. Types of minority class examples and their influence on learning classifiers from imbalanced data. J. Intell. Inf. Syst. 2016, 46, 563–597. [Google Scholar] [CrossRef]
- Zhou, L. Performance of corporate bankruptcy prediction models on imbalanced dataset: The effect of sampling methods. Knowl.-Based Syst. 2013, 41, 16–25. [Google Scholar] [CrossRef]
- Bekkar, M.; Alitouche, T.A. Imbalanced Data Learning Approaches Review. Int. J. Data Min. Knowl. Manag. Process 2013, 3, 15–33. [Google Scholar] [CrossRef]
- Yijing, L.; Haixiang, G.; Xiao, L.; Yanan, L.; Jinling, L. Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl.-Based Syst. 2016, 94, 88–104. [Google Scholar] [CrossRef]
- Cunningham, J.P.; Ghahramani, Z. Linear dimensionality reduction: Survey, insights, and generalizations. J. Mach. Learn. Res. 2015, 16, 2859–2900. [Google Scholar]
- Fu, G.; Xu, F.; Zhang, B.; Yi, L. Chemometrics and Intelligent Laboratory Systems Stable variable selection of class-imbalanced data with precision-recall criterion. Chemom. Intell. Lab. Syst. 2017, 171, 241–250. [Google Scholar] [CrossRef]
- Ramos-Pérez, I.; Arnaiz-González, Á.; Rodríguez, J.J.; García-Osorio, C. When is resampling beneficial for feature selection with imbalanced wide data? Expert Syst. Appl. 2022, 188, 116015. [Google Scholar] [CrossRef]
- Jager, F.; Libenšek, S.; Geršak, K. Characterization and automatic classification of preterm and term uterine records. PLoS ONE 2018, 13, e0202125. [Google Scholar] [CrossRef] [PubMed]
- Mas-Cabo, J.; Prats-Boluda, G.; Perales, A.; Garcia-Casado, J.; Alberola-Rubio, J.; Ye-Lin, Y. Uterine electromyography for discrimination of labor imminence in women with threatened preterm labor under tocolytic treatment. Med. Biol. Eng. Comput. 2019, 57, 401–411. [Google Scholar] [CrossRef] [PubMed]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Proceedings of the Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, 1–4 July 2001; Volume 2101, pp. 63–66. [Google Scholar] [CrossRef]
- Babatunde, O.; Armstrong, L.; Leng, J.; Diepeveen, D. A Genetic Algorithm-Based Feature Selection. Int. J. Electron. Commun. Comput. Eng. 2014, 5, 899–905. [Google Scholar]
- Nguyen, M.H. Impacts of unbalanced test data on the evaluation of classification methods. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 497–502. [Google Scholar] [CrossRef]
- D’Agostino, R.B. An omnibus test of normality for moderate and large size samples. Biometrika 1971, 58, 341–348. [Google Scholar] [CrossRef]
- Wang, L.; Han, M.; Li, X.; Zhang, N.; Cheng, H. Review of classification methods on unbalanced data sets. IEEE Access 2021, 9, 64606–64628. [Google Scholar] [CrossRef]
- Bin Heyat, M.B.; Akhtar, F.; Abbas, S.J.; Al-Sarem, M.; Alqarafi, A.; Stalin, A.; Abbasi, R.; Muaad, A.Y.; Lai, D.; Wu, K. Wearable Flexible Electronics Based Cardiac Electrode for Researcher Mental Stress Detection System Using Machine Learning Models on Single Lead Electrocardiogram Signal. Biosensors 2022, 12, 427. [Google Scholar] [CrossRef]
- Santos, M.S.; Soares, J.P.; Abreu, P.H.; Araujo, H.; Santos, J. Cross-validation for imbalanced datasets: Avoiding overoptimistic and overfitting approaches. IEEE Comput. Intell. Mag. 2018, 13, 59–76. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R.; Famili, F. Feature selection for high-dimensional class-imbalanced data sets using Support Vector Machines. Inf. Sci. 2014, 286, 228–246. [Google Scholar] [CrossRef]
- Lin, W.J.; Chen, J.J. Class-imbalanced classifiers for high-dimensional data. Brief. Bioinform. 2013, 14, 13–26. [Google Scholar] [CrossRef]
- Vuttipittayamongkol, P.; Elyan, E. Overlap-Based Undersampling Method for Classification of Imbalanced Medical Datasets. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; pp. 358–369. [Google Scholar] [CrossRef]
- Alizadehsani, R.; Roshanzamir, M.; Hussain, S.; Khosravi, A.; Koohestani, A.; Zangooei, M.H.; Abdar, M.; Beykikhoshk, A.; Shoeibi, A.; Zare, A.; et al. Handling of uncertainty in medical data using machine learning and probability theory techniques: A review of 30 years (1991–2020). Ann. Oper. Res. 2021, 1–42. [Google Scholar] [CrossRef] [PubMed]
- Martín-Félez, R.; Mollineda, R.A. On the suitability of combining feature selection and resampling to manage data complexity. In Proceedings of the Conference of the Spanish Association for Artificial Intelligence, Seville, Spain, 9–13 November 2009; Volume 5988 LNAI, pp. 141–150. [Google Scholar] [CrossRef]
- Huang, M.W.; Chiu, C.H.; Tsai, C.F.; Lin, W.C. On combining feature selection and over-sampling techniques for breast cancer prediction. Appl. Sci. 2021, 11, 6574. [Google Scholar] [CrossRef]
- Jain, A.; Ratnoo, S.; Kumar, D. Addressing class imbalance problem in medical diagnosis: A genetic algorithm approach. In Proceedings of the 2017 International Conference on Information, Communication, Instrumentation and Control (ICICIC), Indore, India, 17–19 August 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing imbalanced data—Recommendations for the use of performance metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar] [CrossRef]
- Japkowicz, N. Assessment metrics for imbalanced learning. In Imbalanced Learning: Foundations, Algorithms, and Applications; IEEE: Piscataway, NJ, USA, 2013; pp. 187–206. [Google Scholar] [CrossRef]
- Sofaer, H.R.; Hoeting, J.A.; Jarnevich, C.S. The area under the precision-recall curve as a performance metric for rare binary events. Methods Ecol. Evol. 2019, 10, 565–577. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Yuan, Y.; Su, W.; Zhu, M. Threshold-Free Measures for Assessing the Performance of Medical Screening Tests. Front. Public Health 2015, 3, 57. [Google Scholar] [CrossRef]
- Acharya, U.R.; Sudarshan, V.K.; Rong, S.Q.; Tan, Z.; Lim, C.M.; Koh, J.E.; Nayak, S.; Bhandary, S.V. Automated detection of premature delivery using empirical mode and wavelet packet decomposition techniques with uterine electromyogram signals. Comput. Biol. Med. 2017, 85, 33–42. [Google Scholar] [CrossRef]
- Vuttipittayamongkol, P.; Elyan, E.; Petrovski, A. On the class overlap problem in imbalanced data classification. Knowl.-Based Syst. 2021, 212, 106631. [Google Scholar] [CrossRef]
- Japkowicz, N. Class imbalances: Are we focusing on the right issue. In Proceedings of the Workshop on Learning from Imbalanced Data Sets II, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Jo, T.; Japkowicz, N. Class imbalances versus small disjuncts. ACM Sigkdd Explor. Newsl. 2004, 6, 40–49. [Google Scholar] [CrossRef]
- Serdar, C.C.; Cihan, M.; Yücel, D.; Serdar, M.A. Sample size, power and effect size revisited: Simplified and practical approachin pre-clinical, clinical and laboratory studies. Biochem. Med. 2021, 31, 27–53. [Google Scholar] [CrossRef]
- Berghella, V.; Hayes, E.; Visintine, J.; Baxter, J.K. Fetal fibronectin testing for reducing the risk of preterm birth. Cochrane Database Syst. Rev. 2008, 2008, CD006843. [Google Scholar] [CrossRef]
- Pandey, M.; Chauhan, M.; Awasthi, S. Interplay of cytokines in preterm birth. Indian J. Med. Res. 2017, 146, 316–327. [Google Scholar] [CrossRef] [PubMed]
- Sean Esplin, M.; Elovitz, M.A.; Iams, J.D.; Parker, C.B.; Wapner, R.J.; Grobman, W.A.; Simhan, H.N.; Wing, D.A.; Haas, D.M.; Silver, R.M.; et al. Predictive accuracy of serial transvaginal cervical lengths and quantitative vaginal fetal fibronectin levels for spontaneous preterm birth among nulliparous women. Obstet. Gynecol. Surv. 2017, 72, 397–399. [Google Scholar] [CrossRef][Green Version]
- Lucovnik, M.; Chambliss, L.R.; Garfield, R.E. Costs of unnecessary admissions and treatments for “threatened preterm labor”. Am. J. Obstet. Gynecol. 2013, 209, 217.e1–217.e3. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EHG Temporal Features | EHG Spectral Features | EHG Non-Linear Features | Obstetrical Data |
|---|---|---|---|
| 4 per channel | 18 per channel | 52 per channel | 5 |
| App | MeanF DF1, DF2 NormEn H/L Ratio [D1–D9] Teager Energy SpecMR | LZBin LZMulti (n = 6) TimeRev KFD SD1 SD2 SDRR SD1/SD2 SampEn FuzEn SpEn DispEn BubbEn | Maternal age Parity Abortions Weight Week of gestation at recording time (Wog) |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Population size | N = 222 | Mutation | Uniform |
| Genome length | N = 222 | Mutation Probability | 0.01 |
| Number of generations | 500 | Selection scheme | Tournament of size 2 |
| Crossover | Arithmetic | Elite count | 2 |
| Crossover Probability | 0.8 | Termination condition | No fitness function improvement for 150 consecutive iterations (differential tolerance: 10−6) |
| Approach | Resampling Technique | Abbreviation |
|---|---|---|
| No resampling | Not applicable | RN |
| Oversampling | SMOTE | RO |
| Undersampling | Neighborhood Cleaning Rule | RU |
| Hybrid | SMOTE + Neighborhood Cleaning Rule | RH |
| AUC (%) | AF | FSTO | FSTU | FSTH | FSVO | FSVU | FSVH | |
| RN | 52.1 ± 12.3 | 86.7 ± 8.2 | 90.3 ± 6.6 | 89.9 ± 6.6 | 88.8 ± 5.5 | 94.5 ± 4.6 | 93.5 ± 4.4 | |
| RO | 52.8 ± 12.2 | 86.5 ± 8.0 | 90.6 ± 6.0 | 90.2 ± 6.4 | 89 ± 5.8 | 93.7 ± 4.8 | 92.5 ± 5.2 | |
| RU | 65.6 ± 11.7 | 86.7 ± 8.3 | 90.9 ± 6.3 | 89.2 ± 7.2 | 85.8 ± 6.9 | 92.9 ± 5.3 | 91.2 ± 5.5 | |
| RH | 65.1 ± 12.2 | 85.9 ± 7.9 | 91.5 ± 5.3 | 89.9 ± 6.93 | 87.4 ± 6.2 | 92.3 ± 5.7 | 89.9 ± 6.3 | |
| mean | 59.2 ± 13.9 | 86.5 ± 8.1 | 90.8 ± 6.1 | 89.9 ± 6.8 | 88.2 ± 5.9 | 93.4 ± 5.2 | 91.8 ± 5.5 | |
| AP (%) | AF | FSTO | FSTU | FSTH | FSVO | FSVU | FSVH | |
| RN | 22.9 ± 8.9 | 66.5 ± 16.1 | 70.3 ± 15.4 | 70.6 ± 14.5 | 63.6 ± 14.5 | 84.8 ± 11.7 | 77.8 ± 14.4 | |
| RO | 21.6 ± 7.2 | 65.3 ± 15.8 | 67.1 ± 15.6 | 70.2 ± 15 | 65.4 ± 14.7 | 82.9 ± 11.9 | 75.6 ± 14.3 | |
| RU | 36.7 ± 15.5 | 66.7 ± 15.7 | 69.1 ± 15.5 | 69.6 ± 15.9 | 57.4 ± 14.9 | 78.4 ± 14.1 | 71.5 ± 15.6 | |
| RH | 36.7 ± 14.7 | 64.9 ± 15 | 67.3 ± 15.0 | 70.7 ± 14.9 | 60.6 ± 15.1 | 77.7 ± 14.4 | 69.1 ± 15.9 | |
| mean | 29.9 ± 14.5 | 66 ± 15.8 | 68.5 ± 15.3 | 71.0 ± 15.0 | 62.7 ± 14.9 | 81.0 ± 13.4 | 73.5 ± 15.4 |
| Imbalance Ratio (%) | 20 | 30 | 40 | 50 | 60 |
| AUC (%) | 86.9 ± 8 | 88.9 ± 7.4 | 86.5 ± 8.5 | 89.2 ± 6.9 | 90.4 ± 7.2 |
| AP (%) | 70.7 ± 15.1 | 71.3 ± 15.1 | 72.1 ± 14.6 | 72.7 ± 14.9 | 81.6 ± 13 |
| Imbalance Ratio (%) | 70 | 80 | 90 | 100 | - |
| AUC (%) | 88.5 ± 8.6 | 91.4 ± 5.7 | 92.5 ± 5.7 | 94.5 ± 4.6 | - |
| AP (%) | 76 ± 14.2 | 75.5 ± 14.5 | 81.2 ± 12.7 | 84.8 ± 11.7 | - |
| Maximizing Criteria | F1-Score (%) | G-Mean (%) | Precision (%) | Recall (%) | Specificity (%) |
|---|---|---|---|---|---|
| F1-score | 79.6 ± 13.8 | 87.7 ± 10.1 | 81.9 ± 14.9 | 79.6 ± 17.4 | 97.9 ± 2.7 |
| G-mean | 71.5 ± 17.8 | 91.6 ± 6.7 | 61.4 ± 21.5 | 89.8 ± 12.1 | 94.0 ± 5.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nieto-del-Amor, F.; Prats-Boluda, G.; Garcia-Casado, J.; Diaz-Martinez, A.; Diago-Almela, V.J.; Monfort-Ortiz, R.; Hao, D.; Ye-Lin, Y. Combination of Feature Selection and Resampling Methods to Predict Preterm Birth Based on Electrohysterographic Signals from Imbalance Data. Sensors 2022, 22, 5098. https://doi.org/10.3390/s22145098
Nieto-del-Amor F, Prats-Boluda G, Garcia-Casado J, Diaz-Martinez A, Diago-Almela VJ, Monfort-Ortiz R, Hao D, Ye-Lin Y. Combination of Feature Selection and Resampling Methods to Predict Preterm Birth Based on Electrohysterographic Signals from Imbalance Data. Sensors. 2022; 22(14):5098. https://doi.org/10.3390/s22145098
Chicago/Turabian StyleNieto-del-Amor, Félix, Gema Prats-Boluda, Javier Garcia-Casado, Alba Diaz-Martinez, Vicente Jose Diago-Almela, Rogelio Monfort-Ortiz, Dongmei Hao, and Yiyao Ye-Lin. 2022. "Combination of Feature Selection and Resampling Methods to Predict Preterm Birth Based on Electrohysterographic Signals from Imbalance Data" Sensors 22, no. 14: 5098. https://doi.org/10.3390/s22145098
APA StyleNieto-del-Amor, F., Prats-Boluda, G., Garcia-Casado, J., Diaz-Martinez, A., Diago-Almela, V. J., Monfort-Ortiz, R., Hao, D., & Ye-Lin, Y. (2022). Combination of Feature Selection and Resampling Methods to Predict Preterm Birth Based on Electrohysterographic Signals from Imbalance Data. Sensors, 22(14), 5098. https://doi.org/10.3390/s22145098