
Subjective Evaluation of Basic Emotions from Audio–Visual Data


Abstract
:1. Introduction
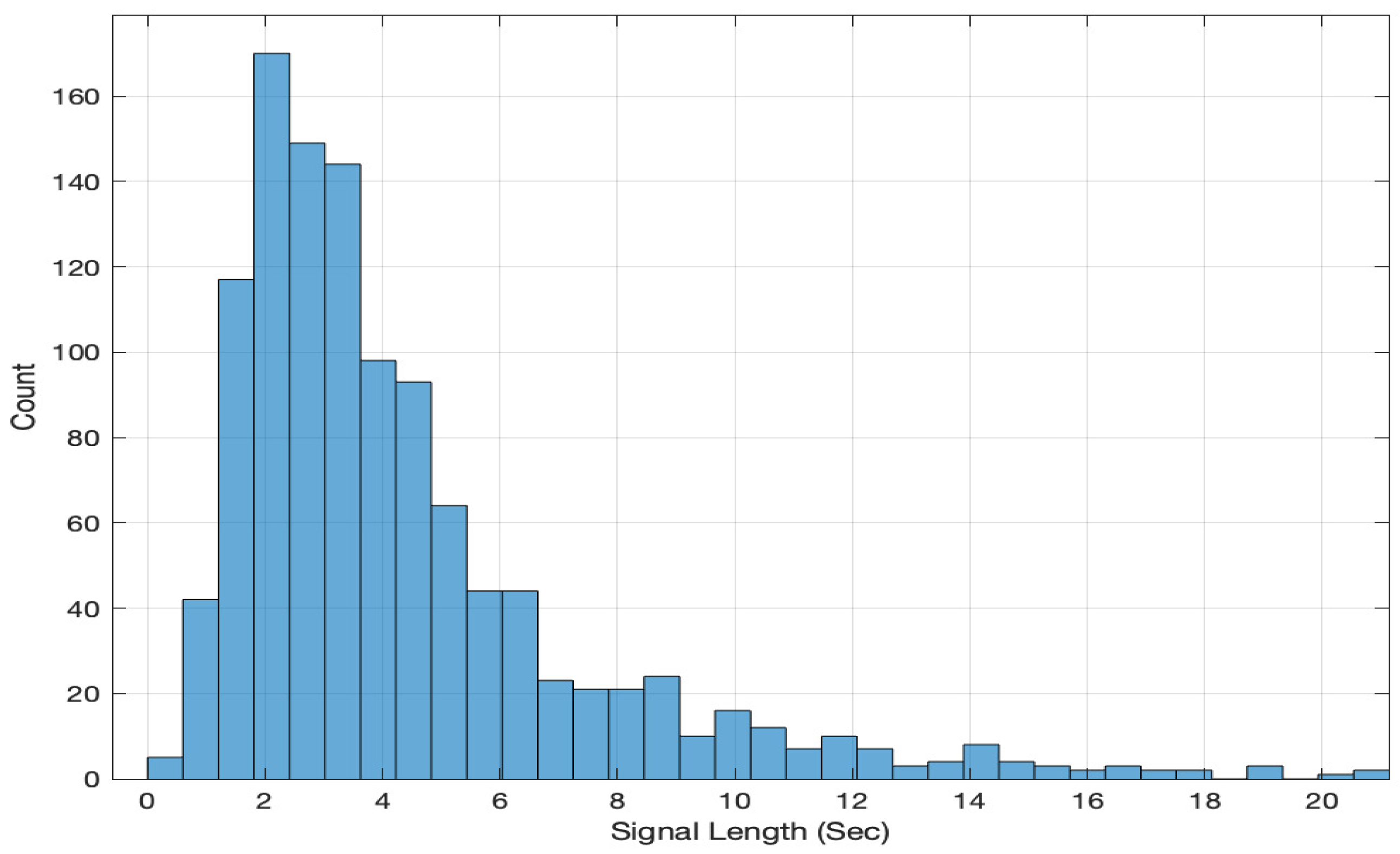
2. Database
- Audio–visual clips with no background music or noise.
- Clips with only one speaker speaking at a time.
3. Perceptual Tests
3.1. Participants
3.2. Procedure
- What is your order of preference in the judgment of emotion between the audio-alone, video-alone, and audio–visual data?
- Is the entire dialogue needed for the perception of the emotion?
- How can you describe each emotion category that you specified in the evaluation sheet based on the audio-alone, video-alone, and audio–visual data?
- What are the auditory and visual cues that you focused on in the judgment of emotions?
- What are the difficulties in the judgment of emotions in all three data modes?
- How much focus do you give to audio (without linguistic content) to judge a particular emotion?
- How much focus do you give to the linguistic content?
- Which pair of emotions is confusing? Why? How are you judging it?
- How do you discriminate angry and happy, neutral and sad, worried and sad?
- If multiple emotions occur, what are they? How do they occur (in sequence, for example) and how do you decide?
- How do you identify emotions if video quality is not good or person is not visible completely?
- Do you identify emotions based on body postures, gestures, and side view, etc.?
- Is your judgement based on other persons’ reactions in the video-alone and audio–visual data?
- If you listen/watch more than once, why you do it? How do you decide emotions in this case?
- Do you identify any audio–visual samples that show face as one emotion and audio as different emotion?
4. Results
5. Discussion
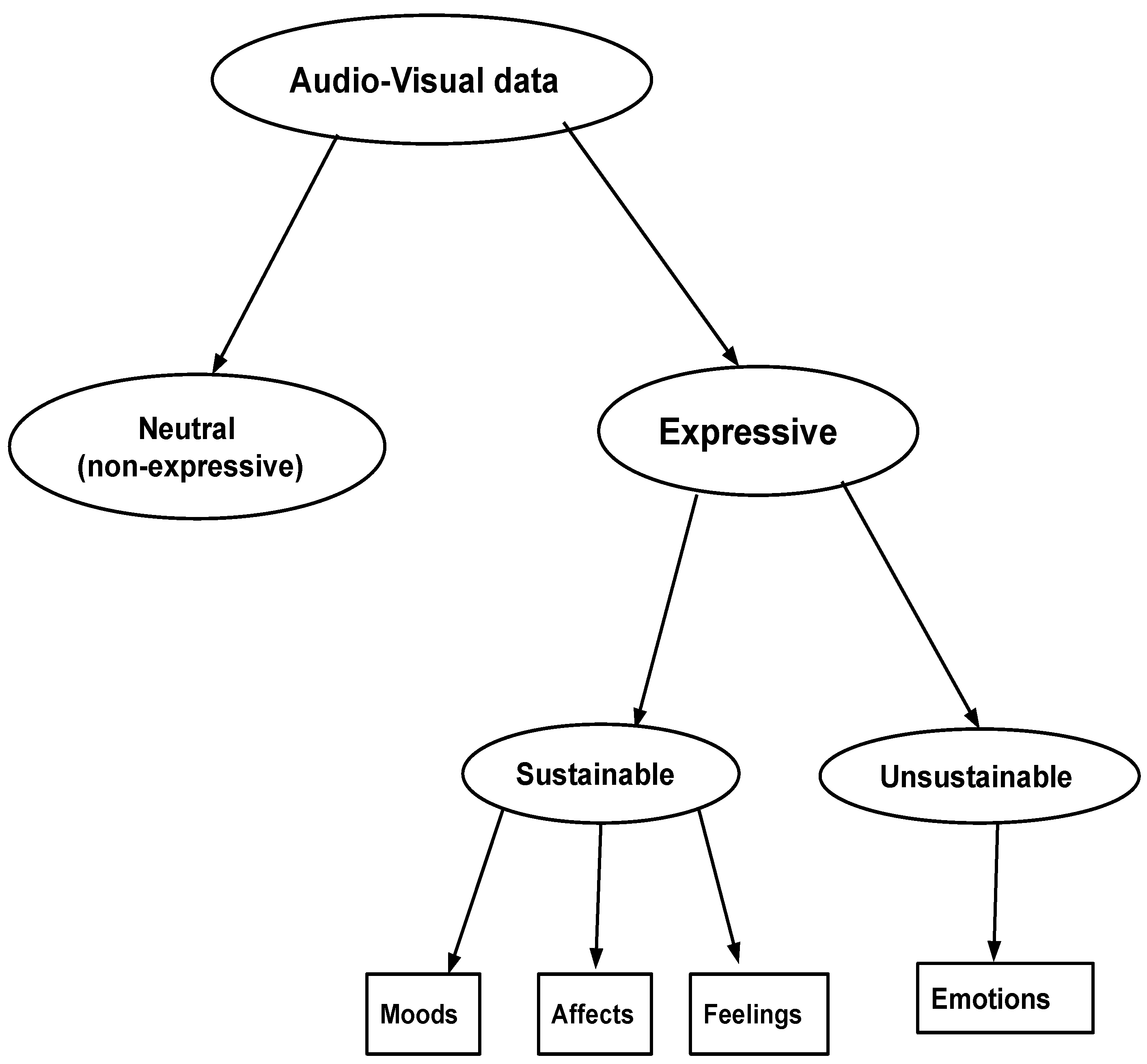
- It was observed that the entire duration of the speech/video may not show emotions properly, but emotions are well-represented only by some segments of the dialogue.
- Emotions are unsustainable and the speaker can not be in an emotional state for a long time. Thus, only some segments contribute to the perception of emotions, while the remaining segments appear to be similar to non-emotional normal speech. Hence, the identification of emotional segments in an entire dialogue is a justified research problem to work on.
- There are different types of temporal prosody patterns (and voice quality variations) for different emotions, and they have a prominent role compared to lexical information.
- For full-blown emotions (such as angry and happy), the identification of emotions is a easier task. The use of lexical information increases the discrimination confidence.
- In most cases, identification of negative emotions takes relatively more time compared to positive emotions both in the audio and video data.
- An angry voice seems to be more intelligible with some creakiness or harshness, whereas in happy voices breathiness (noisy structure), laughter, and some temporal patterns such as rhythm with pleasant voice are present.
- Anger typically shows a sudden change of intensity in a very short period of time. With happiness, intensity rises slowly, but it can stay at a high level for a longer time compared to anger.
- In general, humans can easily perceive emotions from clips of longer duration. This implies that temporal information enables more rapid perception of emotions compared to segments of a shorter duration and it depends on the emotion category.
- Participants listened to/watched some samples more than once if mixed or multiple emotions occurred in them, or if the samples were expressive and therefore difficult to categorize, or when the length of the sample was short.
- Some of the multiple emotion combinations are: excited followed by angry, angry followed by frustrated or disgusted, sad followed by worried, and excited followed by shouting (mostly in angry).
- In the video-alone and audio–video data, the participants perceived emotions not only from actors’ faces but also from their body gestures, or, for example, based on other persons’ reaction in video. Other persons’ reactions also sometimes created confusion in identifying emotions.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Planalp, S. Communicating Emotion: Social, Moral, and Cultural Processes; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Hortensius, R.; Hekele, F.; Cross, E.S. The perception of emotion in artificial agents. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 852–864. [Google Scholar] [CrossRef] [Green Version]
- Schuller, B.; Valstar, M.F.; Cowie, R.; Pantic, M. AVEC 2012: The Continuous Audio/Visual Emotion Challenge—An Introduction; ICMI: Santa Monica, CA, USA, 2012; pp. 361–362. [Google Scholar]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.H.; Lin, J.C.; Wei, W.L. Survey on audiovisual emotion recognition: Databases, features, and data fusion strategies. APSIPA Trans. Signal Inf. Process. 2014, 3, e12. [Google Scholar] [CrossRef] [Green Version]
- Barrett, L.F.; Adolphs, R.; Marsella, S.; Martinez, A.M.; Pollak, S.D. Emotional expressions reconsidered: Challenges to inferring emotion from human facial movements. Psychol. Sci. Public Interest 2019, 20, 1–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piwek, L.; Pollick, F.; Petrini, K. Audiovisual integration of emotional signals from others’ social interactions. Front. Psychol. 2015, 6, 611. [Google Scholar] [CrossRef] [Green Version]
- Paleari, M.; Huet, B.; Chellali, R. Towards multimodal emotion recognition: A new approach. In Proceedings of the CIVR 2010, ACM International Conference on Image and Video Retrieval, Xi’an, China, 5–7 July 2010. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef] [Green Version]
- Morrison, D.; Wang, R.; Silva, L.C.D. Ensemble methods for spoken emotion recognition in call-centres. Speech Commun. 2007, 49, 98–112. [Google Scholar] [CrossRef]
- Devillers, L.; Vaudable, C.; Chastagnol, C. Real-life emotion-related states detection in call centers: A cross-corpora study. In Proceedings of the Interspeech, Chiba, Japan, 26–30 September 2010; pp. 2350–2353. [Google Scholar]
- Pfister, T.; Robinson, P. Real-Time Recognition of Affective States from Nonverbal Features of Speech and Its Application for Public Speaking Skill Analysis. IEEE Trans. Affect. Comput. 2011, 2, 66–78. [Google Scholar] [CrossRef] [Green Version]
- Calvo, R.; D’Mello, S. Affect Detection: An Interdisciplinary Review of Models, Methods, and Their Applications. IEEE Trans. Affect. Comput. 2010, 1, 18–37. [Google Scholar] [CrossRef]
- Lee, C.M.; Narayanan, S.S. Toward detecting emotions in spoken dialogs. IEEE Trans. Speech Audio Process. 2005, 13, 293–303. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Montembeault, M.; Brando, E.; Charest, K.; Tremblay, A.; Roger, É.; Duquette, P.; Rouleau, I. Multimodal emotion perception in young and elderly patients with multiple sclerosis. Mult. Scler. Relat. Disord. 2022, 58, 103478. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Chen, Y.; Lin, Y.; Ding, H.; Zhang, Y. Multichannel perception of emotion in speech, voice, facial expression, and gesture in individuals with autism: A scoping review. J. Speech Lang. Hear. Res. 2022, 65, 1435–1449. [Google Scholar] [CrossRef] [PubMed]
- Panek, M.G.; Karbownik, M.S.; Kuna, P.B. Comparative analysis of clinical, physiological, temperamental and personality characteristics of elderly subjects and young subjects with asthma. PLoS ONE 2020, 15, e0241750. [Google Scholar] [CrossRef]
- Douglas-Cowie, E.; Campbell, N.; Cowie, R.; Roach, P. Emotional speech: Towards a new generation of databases. Speech Commun. 2003, 40, 33–60. [Google Scholar] [CrossRef] [Green Version]
- Lotfian, R.; Busso, C. Building Naturalistic Emotionally Balanced Speech Corpus by Retrieving Emotional Speech From Existing Podcast Recordings. IEEE Trans. Affect. Comput. 2019, 10, 471–483. [Google Scholar] [CrossRef]
- Busso, C.; Narayanan, S. Recording audio–visual emotional databases from actors: A closer look. In Proceedings of the Second International Workshop on Emotion: Corpora for Research on Emotion and Affect, International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 26 May–1 June 2008; pp. 17–22. [Google Scholar]
- Douglas-Cowie, E.; Cowie, R.; Schröder, M. A New Emotion Database: Considerations, Sources and Scope. In Proceedings of the ITRW on Speech and Emotion, Newcastle, UK, 5–7 September 2000; pp. 39–44. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the 2005—Eurospeech, 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Sneddon, I.; McRorie, M.; McKeown, G.; Hanratty, J. The Belfast Induced Natural Emotion Database. IEEE Trans. Affect. Comput. 2012, 3, 32–41. [Google Scholar] [CrossRef]
- Grimm, M.; Kroschel, K.; Narayanan, S.S. The Vera am Mittag German audio–visual emotional speech database. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hannover, Germany, 23–26 June 2008; pp. 865–868. [Google Scholar]
- Navas, E.; Hernáez, I.; Luengo, I. An objective and subjective study of the role of semantics and prosodic features in building corpora for emotional TTS. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1117–1127. [Google Scholar] [CrossRef] [Green Version]
- Erro, D.; Navas, E.; Hernáez, I.; Saratxaga, I. Emotion Conversion Based on Prosodic Unit Selection. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 974–983. [Google Scholar] [CrossRef]
- Tao, J.; Kang, Y.; Li, A. Prosody conversion from neutral speech to emotional speech. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1145–1154. [Google Scholar]
- Iida, A.; Campbell, N.; Higuchi, F.; Yasumura, M. A corpus-based speech synthesis system with emotion. Speech Commun. 2003, 40, 161–187. [Google Scholar] [CrossRef]
- Ayadi, M.E.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Metallinou, A.; Wöllmer, M.; Katsamanis, A.; Eyben, F.; Schuller, B.; Narayanan, S. Context-Sensitive Learning for Enhanced Audiovisual Emotion Classification. IEEE Trans. Affect. Comput. 2012, 3, 184–198. [Google Scholar] [CrossRef]
- Sainz, I.; Saratxaga, I.; Navas, E.; Hernáez, I.; Sánchez, J.; Luengo, I.; Odriozola, I. Subjective Evaluation of an Emotional Speech Database for Basque. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Truong, K.P.; Neerincx, M.A.; van Leeuwen, D.A. Assessing agreement of observer- and self-annotations in spontaneous multimodal emotion data. In Proceedings of the Interspeech 2008—9th Annual Conference of the International Speech Communication Association, Brisbane, QLD, Australia, 22–26 September 2008; pp. 318–321. [Google Scholar]
- Audibert, N.; Aubergé, V.; Rilliard, A. Acted vs. spontaneous expressive speech: Perception with inter-individual variability. In Proceedings of the Programme of the Workshop on Corpora for Research on Emotion and Affect, Marrakech, Morocco, 26 May 2008; pp. 19–23. [Google Scholar]
- Keltner, D.; Sauter, D.; Tracy, J.; Cowen, A. Emotional expression: Advances in basic emotion theory. J. Nonverbal Behav. 2019, 43, 133–160. [Google Scholar] [CrossRef]
- Swerts, M.; Leuverink, K.; Munnik, M.; Nijveld, V. Audiovisual correlates of basic emotions in blind and sighted people. In Proceedings of the Nterspeech 2012 ISCA’s 13th Annual Conference, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Krahmer, E.; Swerts, M. On the role of acting skills for the collection of simulated emotional speech. In Proceedings of the Interspeech 2008, 9th Annual Conference of the International Speech Communication Association, Brisbane, QLD, Australia, 22–26 September 2008; pp. 261–264. [Google Scholar]
- Barkhuysen, P.; Krahmer, E.; Swerts, M. Incremental perception of acted and real emotional speech. In Proceedings of the Interspeech 2007, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007; pp. 1262–1265. [Google Scholar]
- Wilting, J.; Krahmer, E.; Swerts, M. Real vs. acted emotional speech. In Proceedings of the Interspeech 2006—ICSLP, Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Jeong, J.W.; Kim, H.T.; Lee, S.H.; Lee, H. Effects of an Audiovisual Emotion Perception Training for Schizophrenia: A Preliminary Study. Front. Psychiatry 2021, 12, 490. [Google Scholar] [CrossRef]
- Waaramaa-Mäki-Kulmala, T. Emotions in Voice: Acoustic and Perceptual Analysis of Voice Quality in the Vocal Expression of Emotions; Acta Univesitatis Tamperensis; Tampere Unversity Press: Tampere, Finland, 2009. [Google Scholar]
- Swerts, M.; Hirschberg, J. Prosodic predictors of upcoming positive or negative content in spoken messages. J. Acoust. Soc. Am. 2010, 128, 1337–1345. [Google Scholar] [CrossRef] [Green Version]
- Mower, E.; Mataric, M.J.; Narayanan, S.S. Human Perception of audio–visual Synthetic Character Emotion Expression in the Presence of Ambiguous and Conflicting Information. IEEE Trans. Multimed. 2009, 11, 843–855. [Google Scholar] [CrossRef] [Green Version]
- Shahid, S.; Swerts, E.K.M. Real vs. acted emotional speech: Comparing South-asian and Caucasian speakers and observers. In Proceedings of the Speech Prosody, Campinas, Brazil, 6–9 May 2008; pp. 669–672. [Google Scholar]
- Ekman, P. Emotion in the Human Face; Pergamon Press: Oxford, UK, 1972. [Google Scholar]
- Kadiri, S.R.; Gangamohan, P.; Mittal, V.; Yegnanarayana, B. Naturalistic audio–visual Emotion Database. In Proceedings of the 11th International Conference on Natural Language Processing, Goa, India, 18–21 December 2014; pp. 119–126. [Google Scholar]
- Scherer, K.R. Vocal communication of emotion: A review of research paradigms. Speech Commun. 2003, 40, 227–256. [Google Scholar] [CrossRef]
- Kadiri, S.R.; Gangamohan, P.; Mittal, V.; Yegnanarayana, B. Naturalistic Audio–Visual Emotion Database. Available online: https://github.com/SudarsanaKadiri. (accessed on 5 May 2022).
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.C.; Mower, E.; Busso, C.; Lee, S.; Narayanan, S. Emotion recognition using a hierarchical binary decision tree approach. Speech Commun. 2011, 53, 1162–1171. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.A.; Narayanan, S. Paralinguistics in speech and language - State-of-the-art and the challenge. Comput. Speech Lang. 2013, 27, 4–39. [Google Scholar] [CrossRef]
- Schuller, B.; Batliner, A. Computational Paralinguistics: Emotion, Affect and Personality in Speech and Language Processing; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Avots, E.; Sapiński, T.; Bachmann, M.; Kamińska, D. Audiovisual emotion recognition in wild. Mach. Vis. Appl. 2019, 30, 975–985. [Google Scholar] [CrossRef] [Green Version]
- Neumann, M.; Vu, N.T. Investigations on audiovisual emotion recognition in noisy conditions. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 358–364. [Google Scholar]
- Ghaleb, E.; Popa, M.; Asteriadis, S. Multimodal and temporal perception of audio–visual cues for emotion recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 552–558. [Google Scholar]
- Chou, H.C.; Lin, W.C.; Lee, C.C.; Busso, C. Exploiting Annotators’ Typed Description of Emotion Perception to Maximize Utilization of Ratings for Speech Emotion Recognition. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7717–7721. [Google Scholar]
- Middya, A.I.; Nag, B.; Roy, S. Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities. Knowl.-Based Syst. 2022, 244, 108580. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef] [Green Version]
- Jia, N.; Zheng, C.; Sun, W. A multimodal emotion recognition model integrating speech, video and MoCAP. Multimed. Tools Appl. 2022, 1–22. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotions | Expressive States |
|---|---|
| 1. Angry | 1. Confused |
| 2. Disgusted | 2. Excited |
| 3. Frightened | 3. Interested |
| 4. Happy | 4. Relaxed |
| 5. Neutral | 5. Sarcastic |
| 6. Sad | 6. Worried |
| 7. Surprised |
| Audio-Alone | Video-Alone | Audio–Video | |
|---|---|---|---|
| Angry | *** | * | ** |
| Happy | ** | *** | ** |
| Sad | * | ** | *** |
| Angry | Happy | Neutral | Sad | Excited | Worried | Surprised | |
|---|---|---|---|---|---|---|---|
| Angry | * | - | - | - | * | - | - |
| Happy | - | * | - | - | - | - | * |
| Neutral | - | - | * | * | - | - | - |
| Sad | - | - | * | * | - | * | - |
| Angry | Happy | Neutral | Sad | Excited | Worried | Surprised | |
|---|---|---|---|---|---|---|---|
| Angry | * | - | - | - | * | - | - |
| Happy | - | * | - | - | - | - | * |
| Neutral | - | - | * | * | - | - | - |
| Sad | - | - | - | * | - | * | - |
| Angry | Happy | Neutral | Sad | Excited | Worried | Surprised | |
|---|---|---|---|---|---|---|---|
| Angry | * | - | - | - | * | - | - |
| Happy | - | * | - | - | - | - | * |
| Neutral | - | - | * | - | - | - | - |
| Sad | - | - | - | * | - | * | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kadiri, S.R.; Alku, P. Subjective Evaluation of Basic Emotions from Audio–Visual Data. Sensors 2022, 22, 4931. https://doi.org/10.3390/s22134931
Kadiri SR, Alku P. Subjective Evaluation of Basic Emotions from Audio–Visual Data. Sensors. 2022; 22(13):4931. https://doi.org/10.3390/s22134931
Chicago/Turabian StyleKadiri, Sudarsana Reddy, and Paavo Alku. 2022. "Subjective Evaluation of Basic Emotions from Audio–Visual Data" Sensors 22, no. 13: 4931. https://doi.org/10.3390/s22134931
APA StyleKadiri, S. R., & Alku, P. (2022). Subjective Evaluation of Basic Emotions from Audio–Visual Data. Sensors, 22(13), 4931. https://doi.org/10.3390/s22134931