
A Systematic Review of Wi-Fi and Machine Learning Integration with Topic Modeling Techniques



Abstract
:1. Introduction
- Which tasks and applications relative to Wi-Fi signals have been tackled with Machine Learning techniques?
- What are the most widely used Machine Learning methods applied to Wi-Fi data?
- How did this field of research develop with respect to the evolution of Wi-Fi technology?
2. Related Works
3. Preliminaries
3.1. The Wi-Fi Technology
Probe Requests
3.2. Wi-Fi as a Data Source
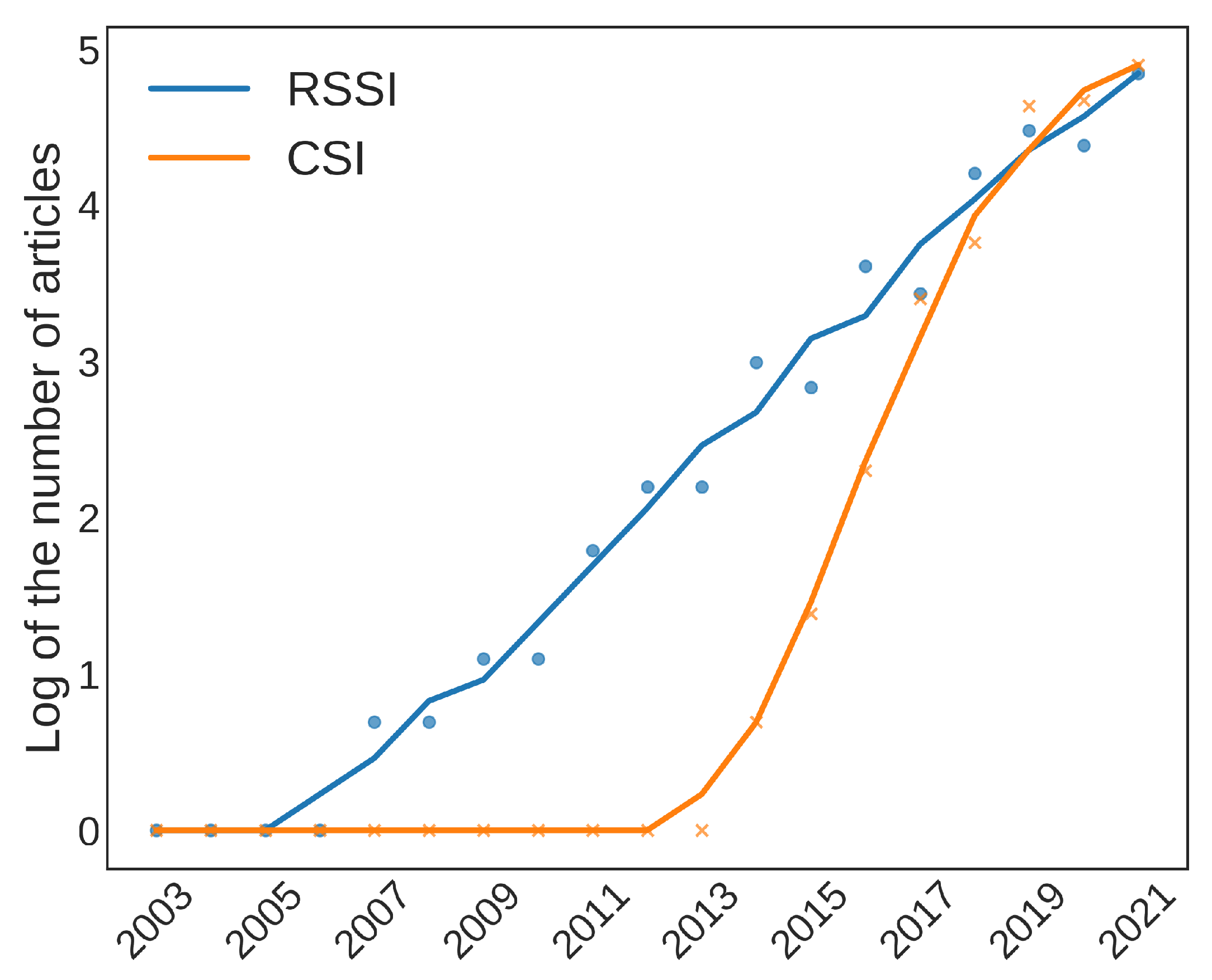
3.2.1. Received Signal Strength
3.2.2. Channel State Information
3.3. Overview of Machine Learning
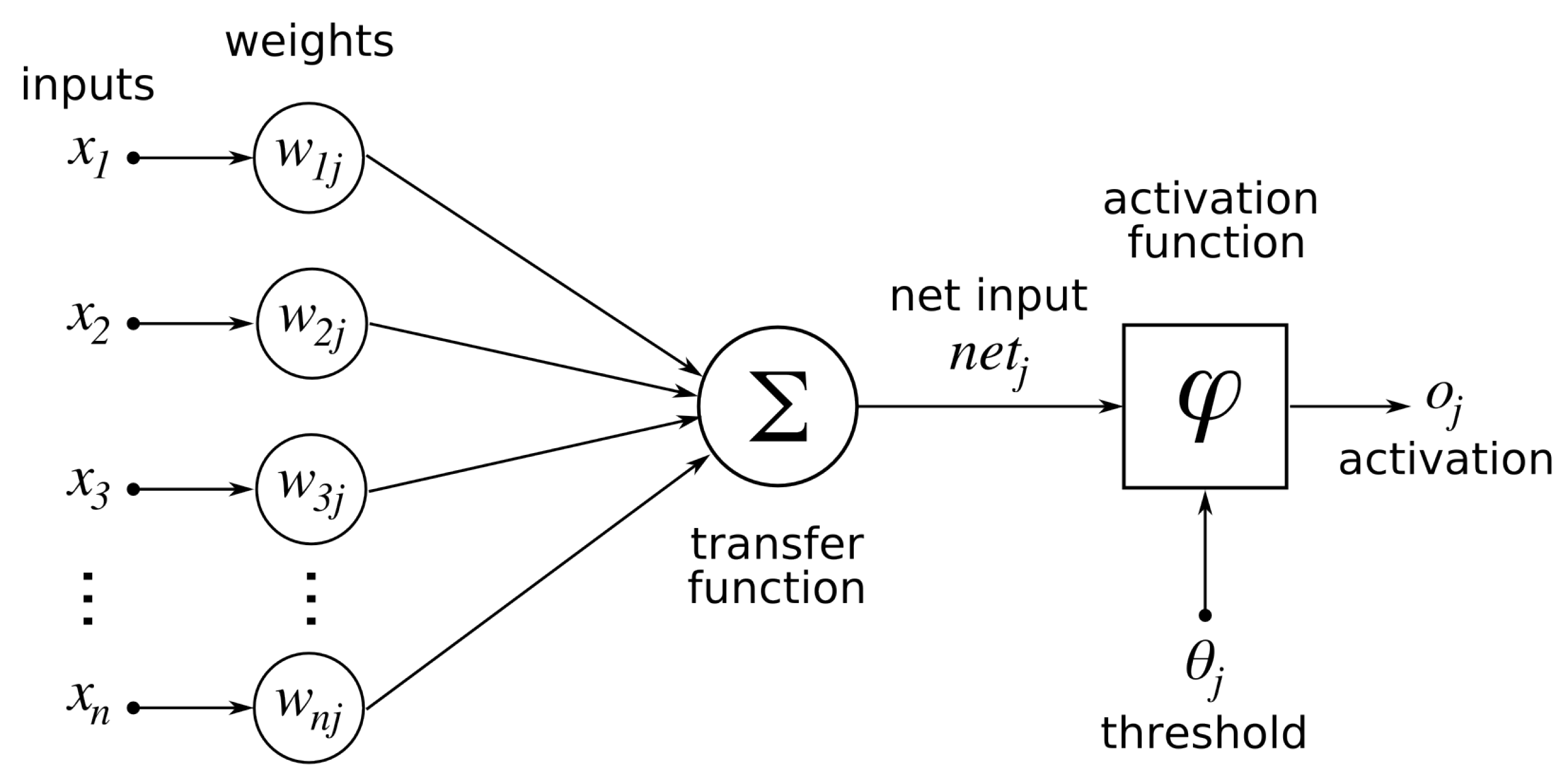
3.3.1. The Neural Network and Its Descendants
3.3.2. K-Nearest Neighbors
3.3.3. Support Vector Machine
3.3.4. Decision Tree and Random Forest
4. Review’s Methodology
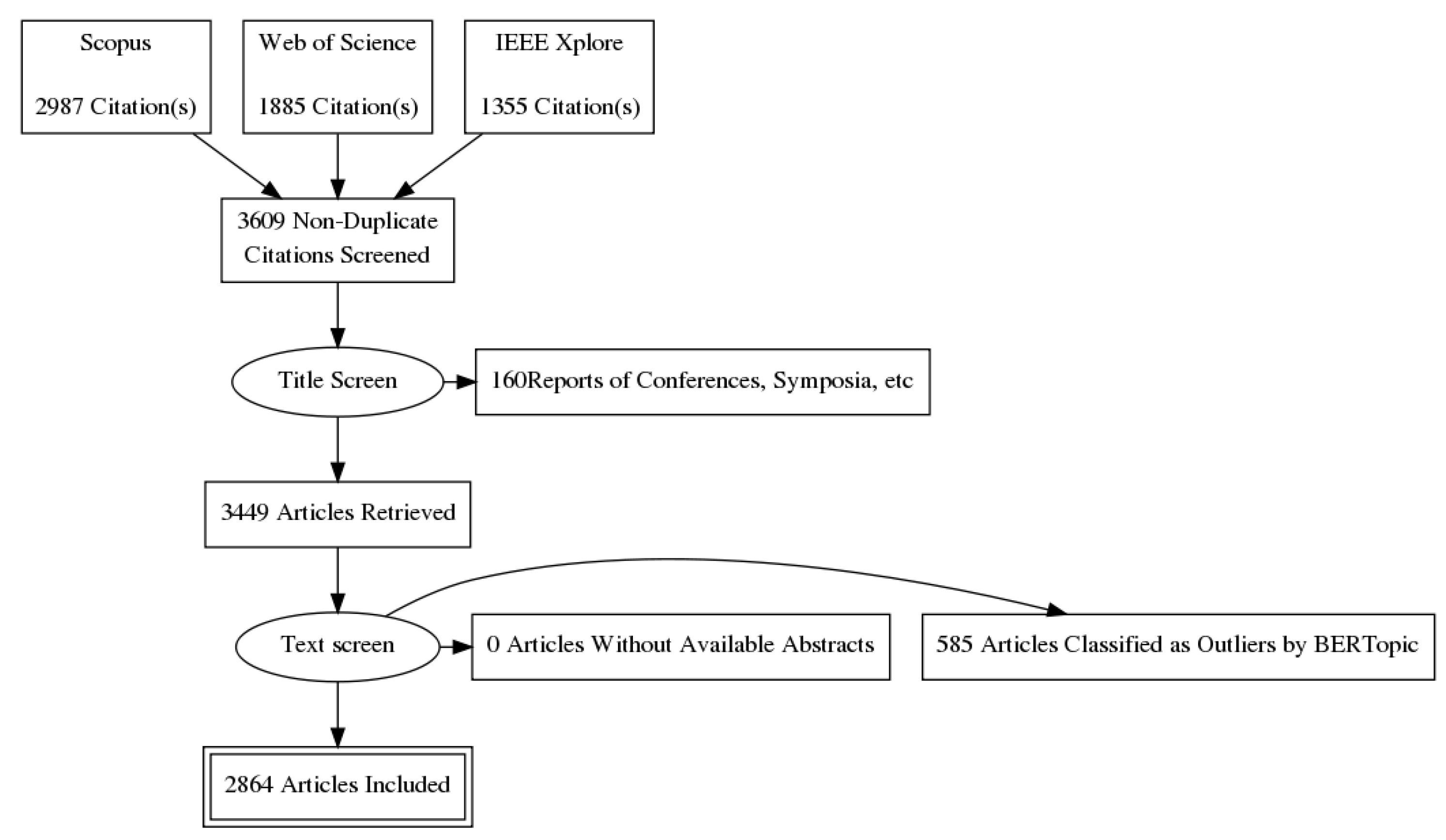
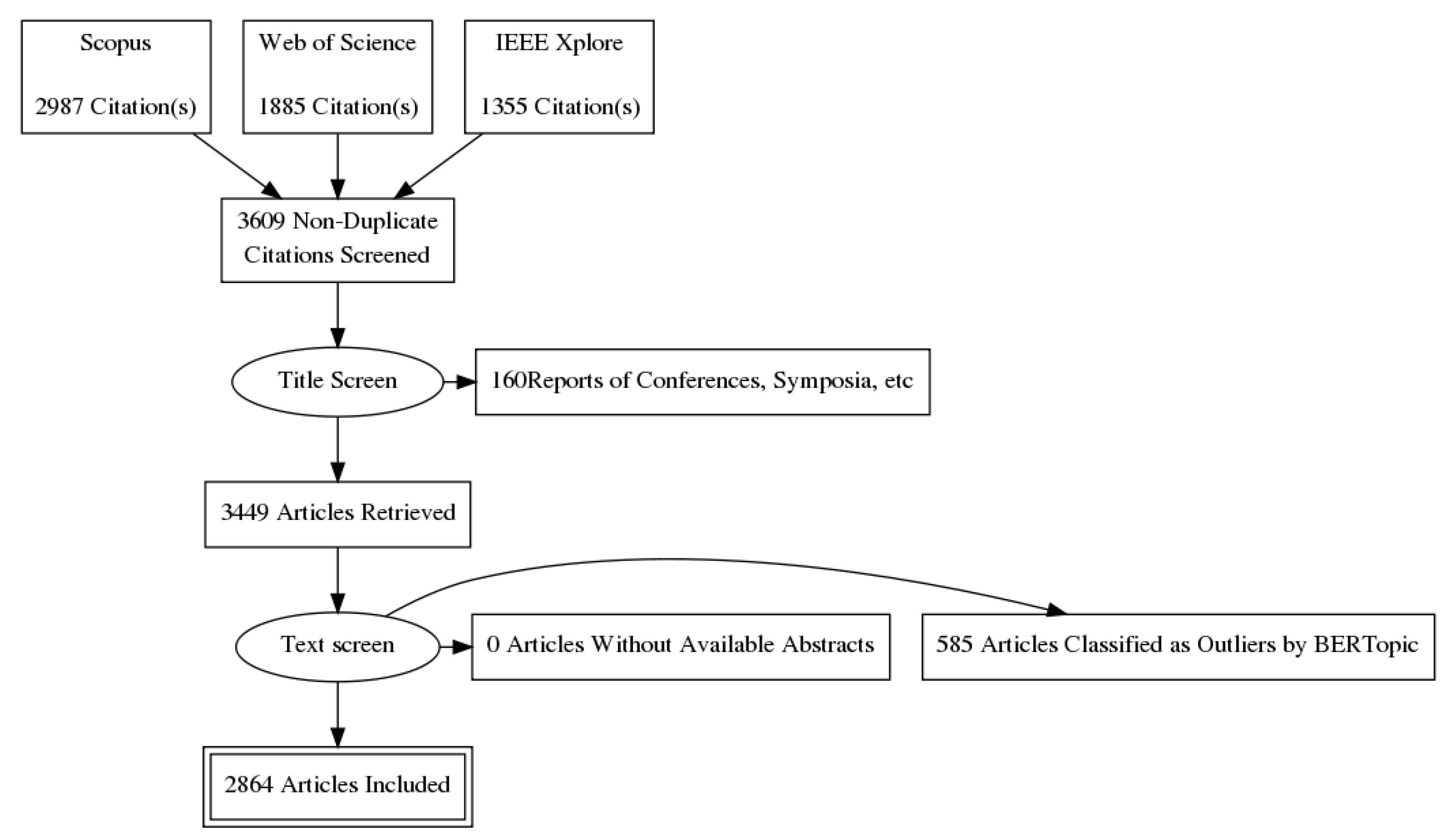
4.1. Data Retrieving and Screening
- conference;
- workshop;
- symposium;
- meeting;
- forum;
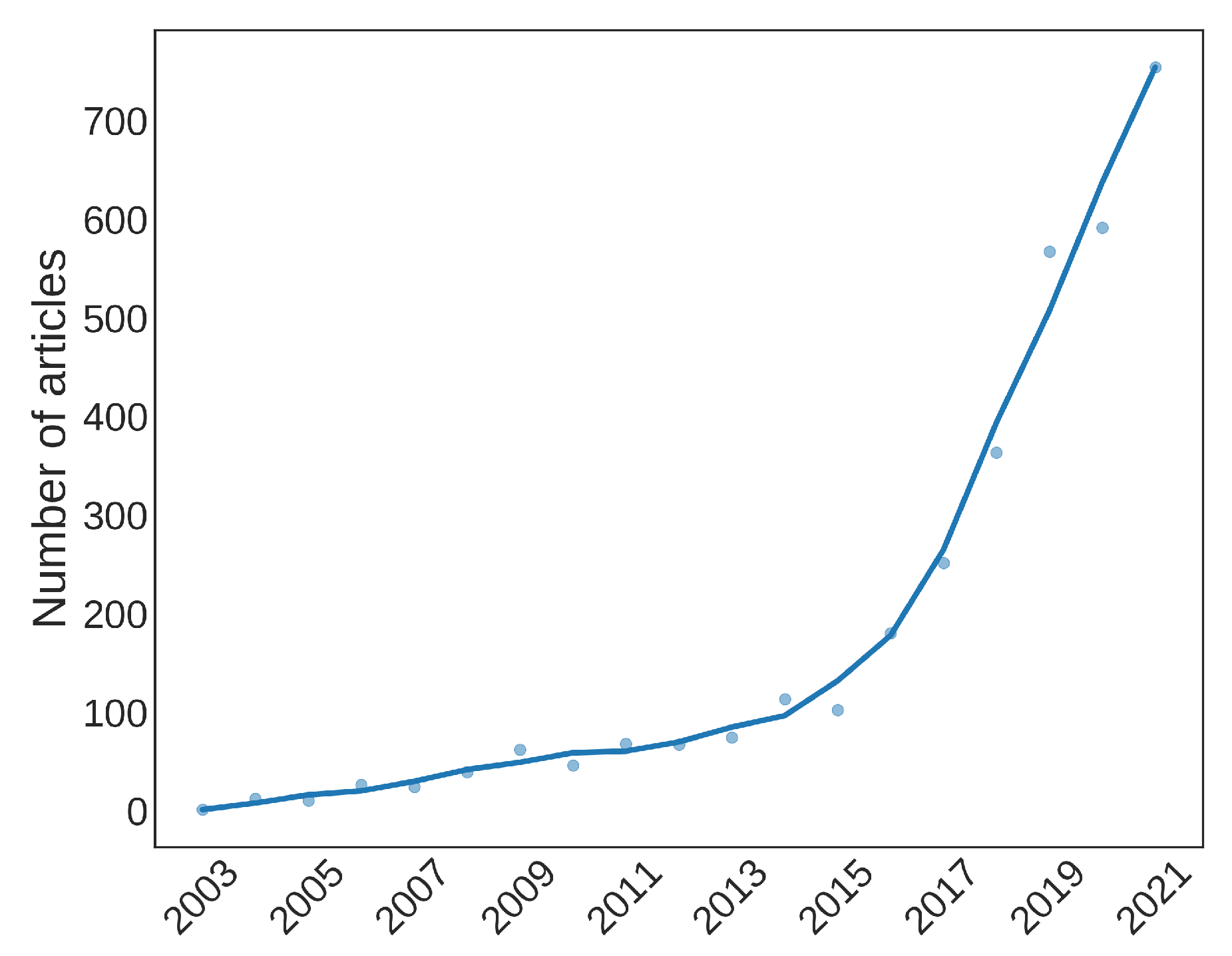
Dataset Exploration
4.2. Topic Modeling
4.2.1. Data Preprocessing
- Tokenization, i.e., splitting the text into tokens, usually into single words.
- Stop words’ removal, including both English stop words (e.g., “the”, “is”, “which”) and ad hoc non-discriminative words: “Wi-Fi”, “method”, “paper”, etc.
- Lemmatization, that is, the process of reducing a term to its root, e.g., “are” and “am” become “be”, and “better” becomes “good”.
- N-gram extraction, i.e., sequences of n words from a sample of the text that satisfy statistical constraints. In this work we use unigrams, bi-grams, and tri-grams.
4.2.2. The BERTopic Algorithm
4.2.3. Results Interpretation
4.3. Reproducibility
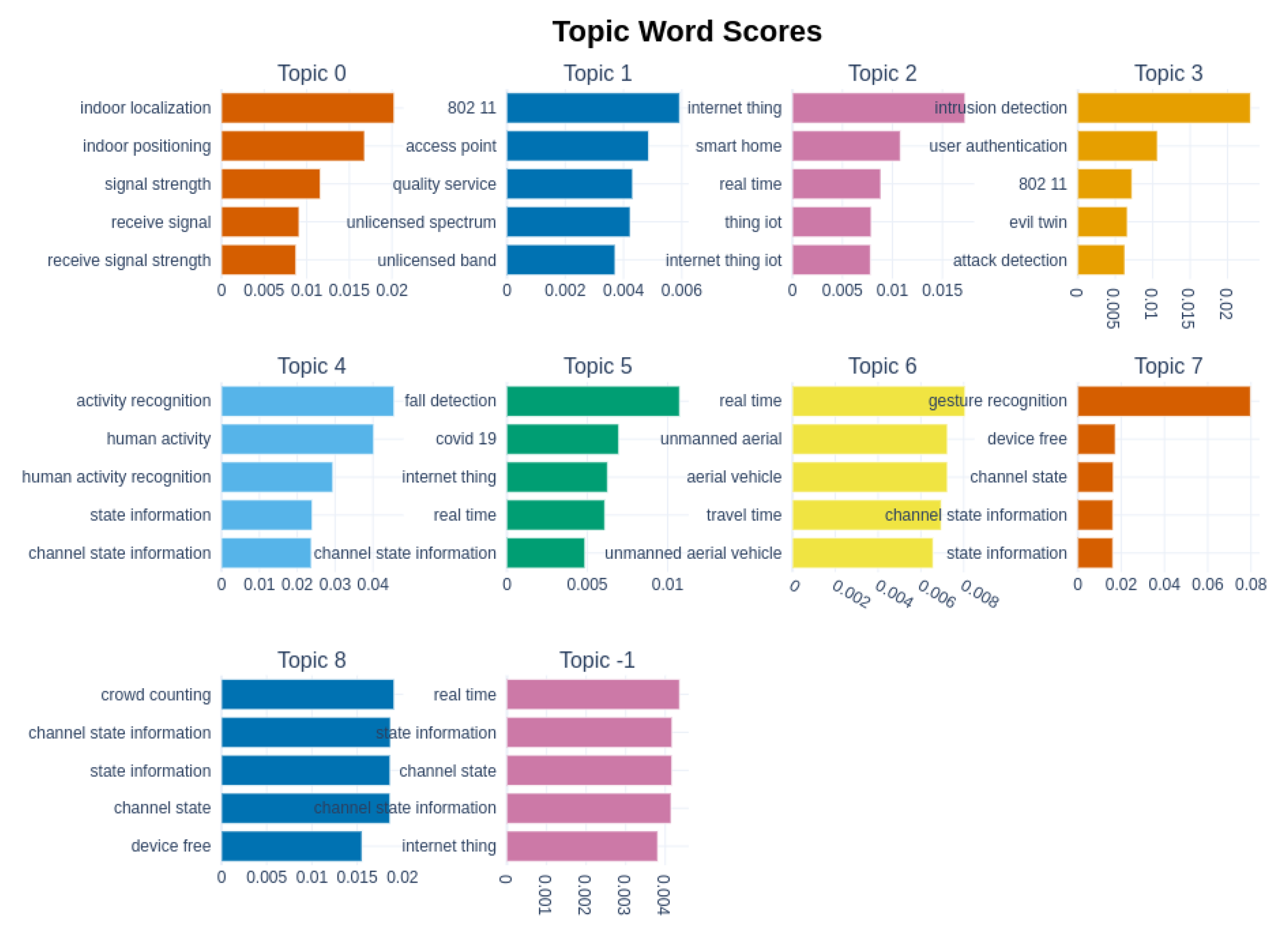
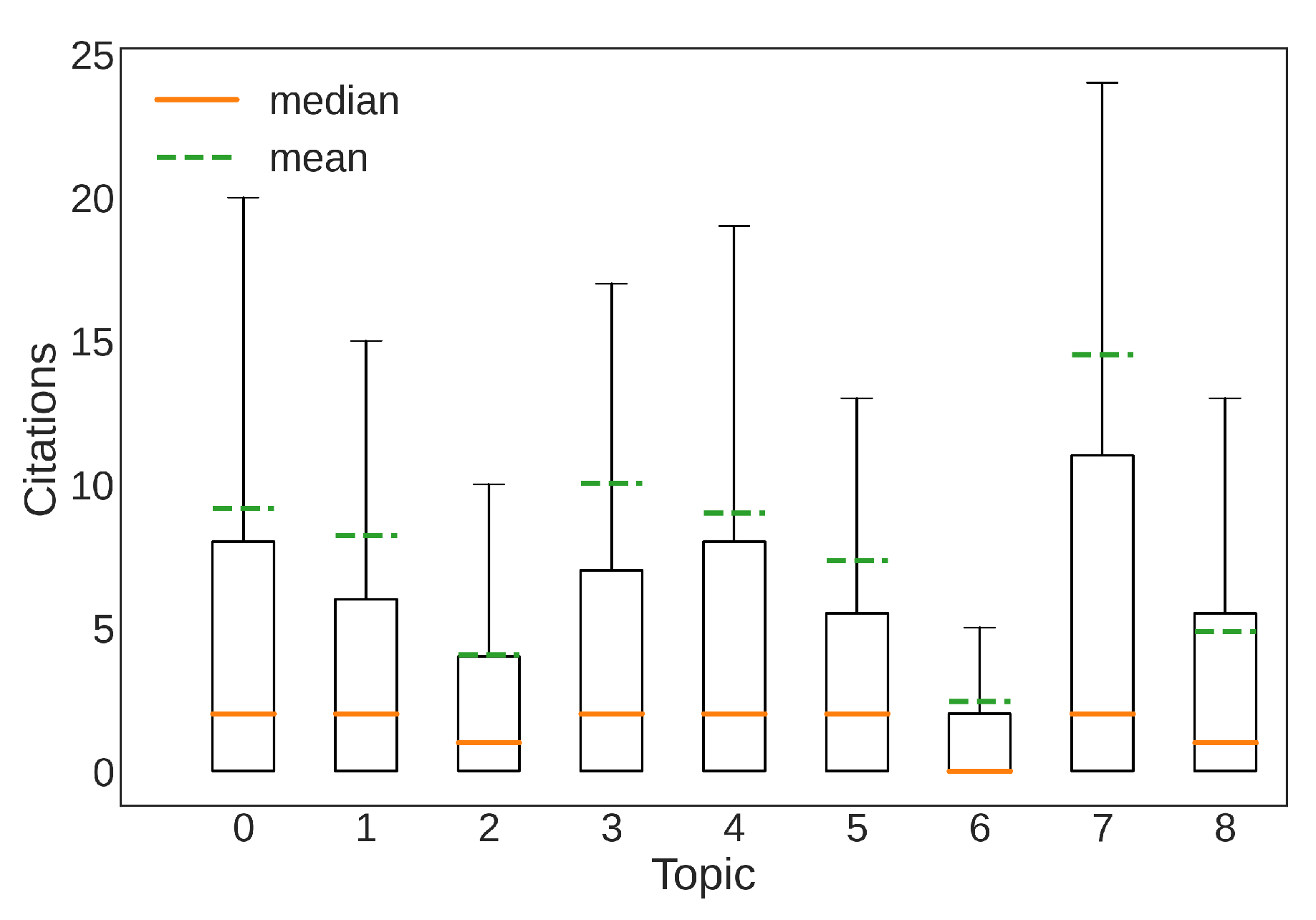
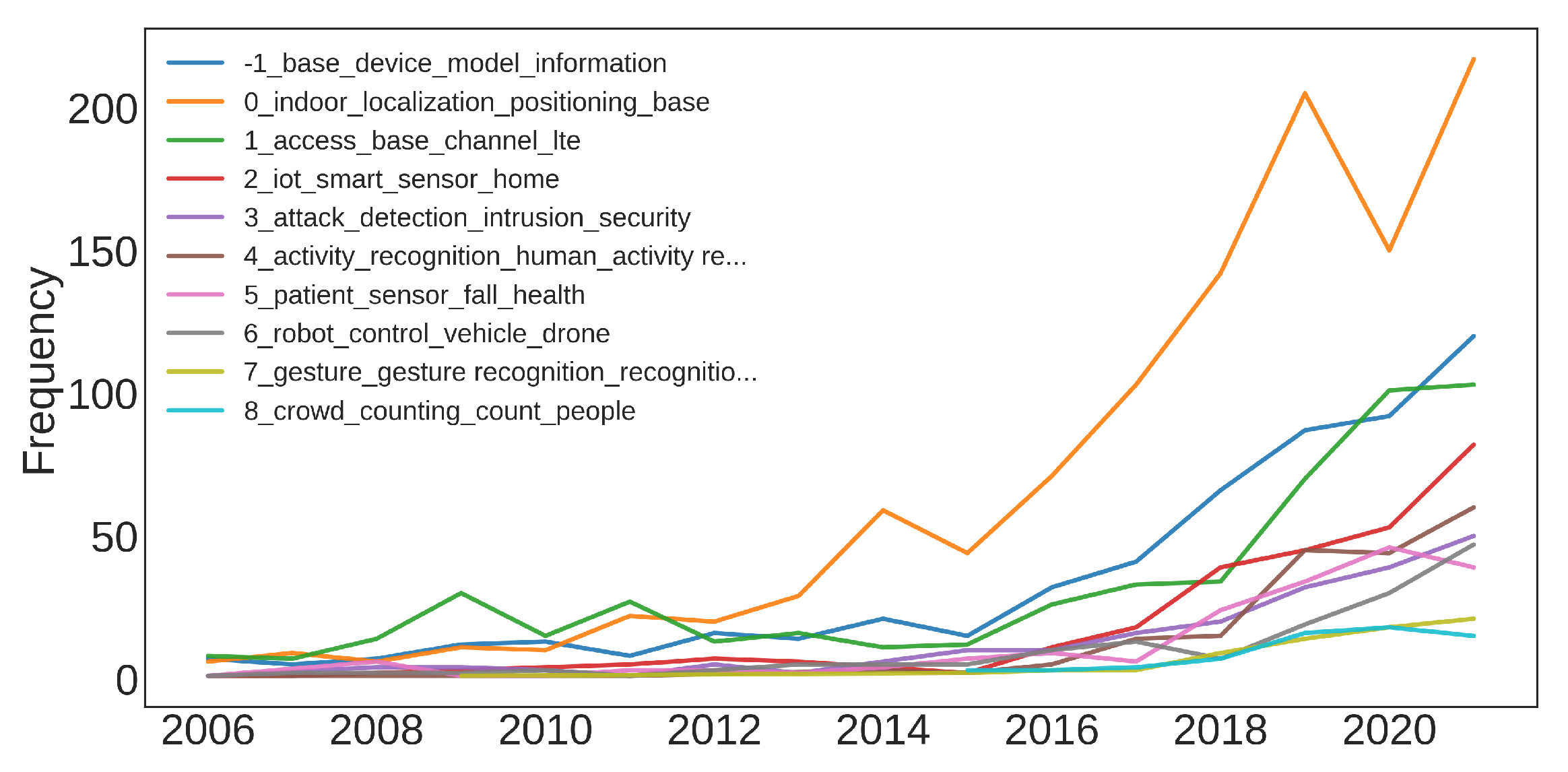
5. Topic Modeling Results
- Topic 0: Indoor Localization
- Topic 1: ML for Improving Wireless Networks’ Performances
- Topic 2: IoT and Smart Houses
- Topic 3: Privacy and Intrusion detection
- Topic 4: Human Activity Recognition
- Topic 5: Human Condition Monitoring
- Topic 6: Wi-Fi and ML for improving UAVs networks
- Topic 7: Gesture Recognition
- Topic 8: Crowd Monitoring and People Counting
6. Answers to the Research Questions
6.1. RQ 1
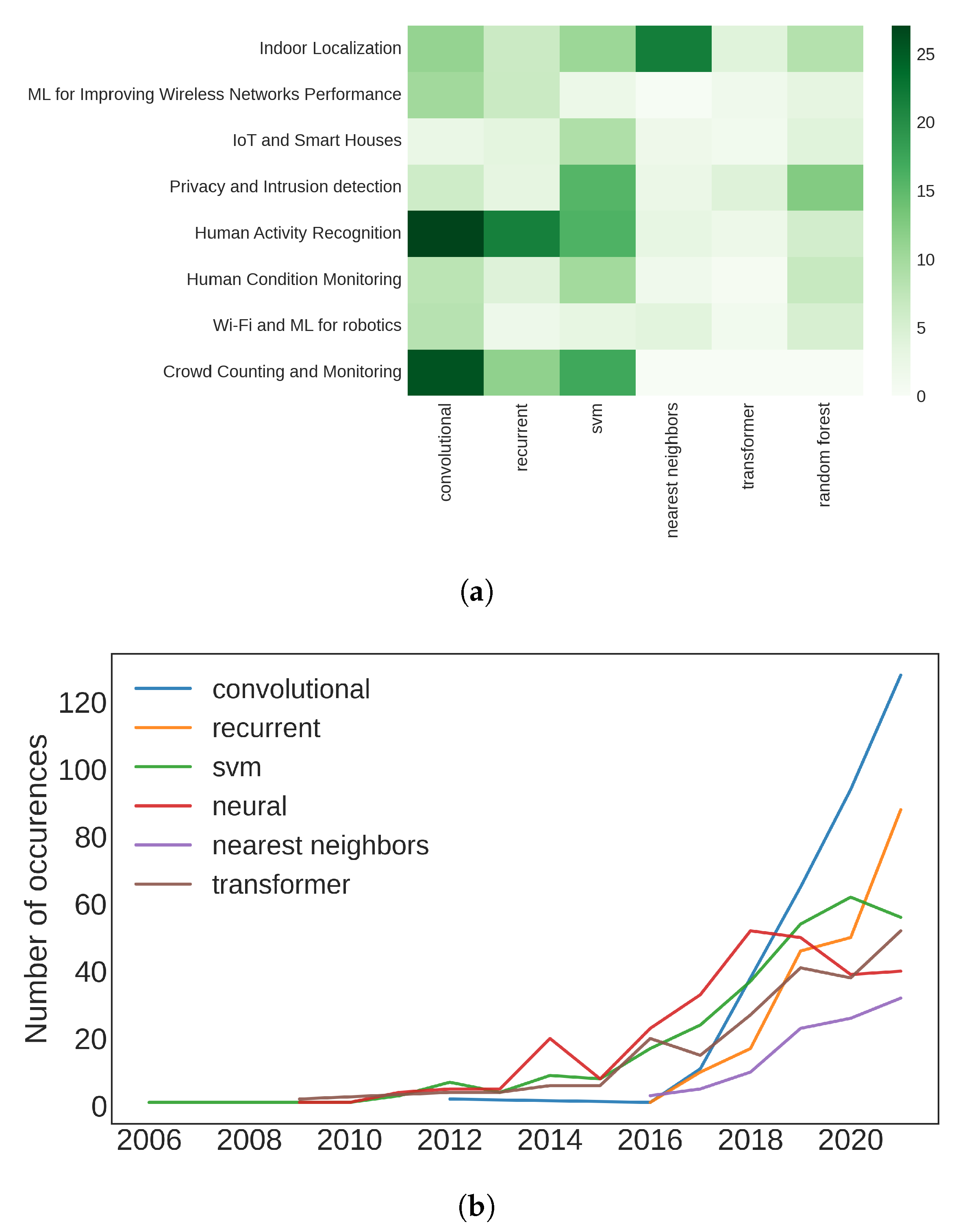
6.2. RQ 2
- Neural Networks, even if this term refers to a superset that includes the following models;
- Convolutional Neural Networks;
- Recurrent Neural Networks, for which we also used the terms Long-Short Term Memory and Gated Recurrent Unit;
- Transformers;
- Support Vector Machines;
- K-Nearest Neighbors;
- Random forests and decision trees.
6.3. RQ 3
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tzeng, C.L. Global Wi-Fi Enabled Devices Shipment Forecast, 2020–2024; Market Intelligence & Consulting Institute (MIC): Taiwan, China, 2020. [Google Scholar]
- Barnett, T.; Jain, S.; Andra, U.; Khurana, T. Cisco visual networking index (vni) complete forecast update, 2017–2022. In Americas/EMEAR Cisco Knowledge Network (CKN) Presentation; EMEAR Cisco Knowledge Network (CKN): San Jose, CA, USA, 2018. [Google Scholar]
- Varghese, A.; Tandur, D. Wireless requirements and challenges in Industry 4.0. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics (IC3I), Mysuru, India, 27–29 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 634–638. [Google Scholar]
- Bolcskei, H. MIMO-OFDM wireless systems: Basics, perspectives, and challenges. IEEE Wirel. Commun. 2006, 13, 31–37. [Google Scholar]
- Ma, Y.; Zhou, G.; Wang, S. WiFi sensing with channel state information: A survey. ACM Comput. Surv. CSUR 2019, 52, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Wallach, H.M. Topic modeling: Beyond bag-of-words. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 977–984. [Google Scholar]
- Amado, A.; Cortez, P.; Rita, P.; Moro, S. Research trends on Big Data in Marketing: A text mining and topic modeling based literature analysis. Eur. Res. Manag. Bus. Econ. 2018, 24, 1–7. [Google Scholar] [CrossRef]
- Mazzei, D.; Chiarello, F.; Fantoni, G. Analyzing social robotics research with natural language processing techniques. Cogn. Comput. 2021, 13, 308–321. [Google Scholar] [CrossRef]
- Bellavista-Parent, V.; Torres-Sospedra, J.; Perez-Navarro, A. New trends in indoor positioning based on WiFi and machine learning: A systematic review. In Proceedings of the 2021 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Virtual, 29 November–2 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Roy, P.; Chowdhury, C. A survey of machine learning techniques for indoor localization and navigation systems. J. Intell. Robot. Syst. 2021, 101, 63. [Google Scholar] [CrossRef]
- Nessa, A.; Adhikari, B.; Hussain, F.; Fernando, X.N. A survey of machine learning for indoor positioning. IEEE Access 2020, 8, 214945–214965. [Google Scholar] [CrossRef]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using WiFi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Singh, N.; Choe, S.; Punmiya, R. Machine Learning Based Indoor Localization Using Wi-Fi RSSI Fingerprints: An Overview. IEEE Access 2021, 9, 127150–127174. [Google Scholar] [CrossRef]
- Rastogi, S.; Singh, J. A systematic review on machine learning for fall detection system. Comput. Intell. 2021, 37, 951–974. [Google Scholar] [CrossRef]
- Ramasamy Ramamurthy, S.; Roy, N. Recent trends in machine learning for human activity recognition—A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1254. [Google Scholar] [CrossRef]
- Jiang, H.; Cai, C.; Ma, X.; Yang, Y.; Liu, J. Smart home based on WiFi sensing: A survey. IEEE Access 2018, 6, 13317–13325. [Google Scholar] [CrossRef]
- Guo, L.; Wang, L.; Liu, J.; Zhou, W. A survey on motion detection using WiFi signals. In Proceedings of the 2016 12th International Conference on Mobile Ad-Hoc and Sensor Networks (MSN), Hefei, China, 16–18 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 202–206. [Google Scholar]
- Toch, E.; Lerner, B.; Ben-Zion, E.; Ben-Gal, I. Analyzing large-scale human mobility data: A survey of machine learning methods and applications. Knowl. Inf. Syst. 2019, 58, 501–523. [Google Scholar] [CrossRef]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A survey on machine-learning techniques for UAV-based communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef] [Green Version]
- Szott, S.; Kosek-Szott, K.; Gawłowicz, P.; Gómez, J.T.; Bellalta, B.; Zubow, A.; Dressler, F. WiFi Meets ML: A Survey on Improving IEEE 802.11 Performance with Machine Learning. arXiv 2021, arXiv:2109.04786. [Google Scholar]
- Pahlavan, K.; Krishnamurthy, P. Evolution and impact of Wi-Fi technology and applications: A historical perspective. Int. J. Wirel. Inf. Networks 2021, 28, 3–19. [Google Scholar] [CrossRef]
- Poole, I.; Wi-Fi/WLAN Channels, Frequencies, Bands & Bandwidths. Adrio Communications Ltd. 2016. Available online: https://www.radioelectronics.com/info/wireless/wi-fi/80211-channels-number-frequencies-bandwidth.php (accessed on 15 February 2022).
- IEEE Std 802.11; IEEE Standard for Information Technology-Telecommunications and Information Exchange between Systems-Local and Metropolitan Area Networks-Specific Requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications. IEEE Computer Society LAN/MAN Standards Committee: New York, NY, USA, 2007.
- Mitchell, B. 802.11 Standards Explained: 802.11 ax, 802.11 ac, 802.11 b/g/n, 802.11 a; Lifewire: New York, NY, USA, 2020. [Google Scholar]
- Freudiger, J. How talkative is your mobile device? An experimental study of Wi-Fi probe requests. In Proceedings of the 8th ACM Conference on Security & Privacy in Wireless and Mobile Networks, New York, NY, USA, 22–26 June 2015; pp. 1–6. [Google Scholar]
- IEEE Standards Association. Guidelines for Use of Extended Unique Identifier (EUI), Organizationally Unique Identifier (OUI), and Company ID (CID); IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Vattapparamban, E.; Çiftler, B.S.; Güvenç, I.; Akkaya, K.; Kadri, A. Indoor occupancy tracking in smart buildings using passive sniffing of probe requests. In Proceedings of the 2016 IEEE International Conference on Communications Workshops (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 38–44. [Google Scholar]
- Song, X.; Zhou, Y.; Qi, H.; Qiu, W.; Xue, Y. DuLoc: Dual-Channel Convolutional Neural Network Based on Channel State Information for Indoor Localization. IEEE Sensors J. 2022, 22, 8738–8748. [Google Scholar] [CrossRef]
- Hao, Z.; Duan, Y.; Dang, X.; Liu, Y.; Zhang, D. Wi-SL: Contactless fine-grained gesture recognition uses channel state information. Sensors 2020, 20, 4025. [Google Scholar] [CrossRef]
- Wang, Z.; Dou, W.; Ma, M.; Feng, X.; Huang, Z.; Zhang, C.; Guo, Y.; Chen, D. A Survey of User Authentication Based on Channel State Information. Wirel. Commun. Mob. Comput. 2021, 2021, 6636665. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Cunningham, P.; Cord, M.; Delany, S.J. Supervised learning. In Machine Learning Techniques for Multimedia; Springer: Berlin/Heidelberg, Germany, 2008; pp. 21–49. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Ghahramani, Z. Unsupervised learning. In Proceedings of the Summer School on Machine Learning, Tubingen, Germany, 2–14 February 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 72–112. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 193–208. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef]
- Burnham, J.F. Scopus database: A review. Biomed. Digit. Libr. 2006, 3, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Web of Science. Available online: https://www.webofscience.com/wos/woscc/basic-search (accessed on 20 March 2022).
- IEEE Xplore Digital Library. Available online: https://ieeexplore.ieee.org/Xplore/home.jsp (accessed on 20 March 2022).
- Andrews, J.G.; Claussen, H.; Dohler, M.; Rangan, S.; Reed, M.C. Femtocells: Past, present, and future. IEEE J. Sel. Areas Commun. 2012, 30, 497–508. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-based fingerprinting for indoor localization: A deep learning approach. IEEE Trans. Veh. Technol. 2016, 66, 763–776. [Google Scholar] [CrossRef] [Green Version]
- Ferris, B.; Fox, D.; Lawrence, N.D. Wifi-slam using gaussian process latent variable models. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 2480–2485. [Google Scholar]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer learning via dimensionality reduction. In Proceedings of the AAAI, Stanford, CA, USA, 22–24 October 2008; Volume 8, pp. 677–682. [Google Scholar]
- Dimatteo, S.; Hui, P.; Han, B.; Li, V.O. Cellular traffic offloading through WiFi networks. In Proceedings of the 2011 IEEE 8th International Conference on Mobile ad hoc and Sensor Systems, Washington, DC, USA, 17–22 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 192–201. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion detection in 802.11 networks: Empirical evaluation of threats and a public dataset. IEEE Commun. Surv. Tutorials 2015, 18, 184–208. [Google Scholar] [CrossRef]
- Zhao, M.; Li, T.; Abu Alsheikh, M.; Tian, Y.; Zhao, H.; Torralba, A.; Katabi, D. Through-wall human pose estimation using radio signals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7356–7365. [Google Scholar]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Astels, S. hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Jian, Y.; Tai, C.L.; Venkateswaran, S.K.; Agarwal, M.; Liu, Y.; Blough, D.M.; Sivakumar, R. Algorithms for addressing line-of-sight issues in mmWave WiFi networks using access point mobility. J. Parallel Distrib. Comput. 2022, 160, 65–78. [Google Scholar] [CrossRef]
- Seeram, S.S.S.G.; Reddy, A.Y.; Basil, N.; Suman, A.V.S.; Anuraj, K.; Poorna, S. Performance Comparison of Machine Learning Algorithms in Symbol Detection Using OFDM. In Inventive Communication and Computational Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 455–466. [Google Scholar]
- Kunarak, S.; Duangchan, T. Vertical Handover Decision based on Hybrid Artificial Neural Networks in HetNets of 5G. In Proceedings of the 2021 IEEE Region 10 Symposium (TENSYMP), Jeju, Korea, 23–25 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Urban, R.; Drexler, P. Intelligent Channel Assignment for WI-FI System Based on Reinforcement Learning. In Proceedings of the PIERS Proceedings, Guangzhou, China, 25–28 August 2014. [Google Scholar]
- Huang, Y.F.; Chen, H.H. Applications of Intelligent Radio Technologies in Unlicensed Cellular Networks-A Survey. KSII Trans. Internet Inf. Syst. TIIS 2021, 15, 2668–2717. [Google Scholar]
- Ma, J.; Wang, H.; Zhang, D.; Wang, Y.; Wang, Y. A survey on wi-fi based contactless activity recognition. In Proceedings of the 2016 International IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1086–1091. [Google Scholar]
- Basri, C.; El Khadimi, A. Survey on indoor localization system and recent advances of WIFI fingerprinting technique. In Proceedings of the 2016 5th International Conference on Multimedia Computing and Systems (ICMCS), Marrakech, Morocco, 29 September–1 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 253–259. [Google Scholar]
- Liu, F.; Liu, J.; Yin, Y.; Wang, W.; Hu, D.; Chen, P.; Niu, Q. Survey on WiFi-based indoor positioning techniques. IET Commun. 2020, 14, 1372–1383. [Google Scholar] [CrossRef]
- Ahmed, H.F.T.; Ahmad, H.; Aravind, C. Device free human gesture recognition using Wi-Fi CSI: A survey. Eng. Appl. Artif. Intell. 2020, 87, 103281. [Google Scholar] [CrossRef]
- Xu, Z.; Mei, L.; Choo, K.K.R.; Lv, Z.; Hu, C.; Luo, X.; Liu, Y. Mobile crowd sensing of human-like intelligence using social sensors: A survey. Neurocomputing 2018, 279, 3–10. [Google Scholar] [CrossRef]
- Khan, U.M.; Kabir, Z.; Hassan, S.A. Wireless health monitoring using passive WiFi sensing. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1771–1776. [Google Scholar]
- Mauldin, T.R.; Canby, M.E.; Metsis, V.; Ngu, A.H.; Rivera, C.C. SmartFall: A smartwatch-based fall detection system using deep learning. Sensors 2018, 18, 3363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garcia-Ceja, E.; Riegler, M.; Nordgreen, T.; Jakobsen, P.; Oedegaard, K.J.; Tørresen, J. Mental health monitoring with multimodal sensing and machine learning: A survey. Pervasive Mob. Comput. 2018, 51, 1–26. [Google Scholar] [CrossRef]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled iot devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef]
- Yang, J.; Chen, Y.; Trappe, W.; Cheng, J. Detection and localization of multiple spoofing attackers in wireless networks. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 44–58. [Google Scholar] [CrossRef]
- Hsu, F.H.; Wang, C.S.; Hsu, Y.L.; Cheng, Y.P.; Hsneh, Y.H. A client-side detection mechanism for evil twins. Comput. Electr. Eng. 2017, 59, 76–85. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Conti, M.; Mancini, L.V.; Spolaor, R.; Verde, N.V. Analyzing android encrypted network traffic to identify user actions. IEEE Trans. Inf. Forensics Secur. 2015, 11, 114–125. [Google Scholar] [CrossRef]
- Shi, C.; Liu, J.; Liu, H.; Chen, Y. Smart user authentication through actuation of daily activities leveraging WiFi-enabled IoT. In Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Chennai, India, 10–14 July 2017; pp. 1–10. [Google Scholar]
- Fang, Y.; Deng, Z.; Xue, C.; Jiao, J.; Zeng, H.; Zheng, R.; Lu, S. Application of an improved K nearest neighbor algorithm in WiFi indoor positioning. In Proceedings of the China Satellite Navigation Conference (CSNC) 2015 Proceedings: Volume III, Xi’an, China, 13–15 May 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 517–524. [Google Scholar]
- Li, D.; Zhang, B.; Li, C. A feature-scaling-based k-nearest neighbor algorithm for indoor positioning systems. IEEE Internet Things J. 2015, 3, 590–597. [Google Scholar] [CrossRef]
- Paśko, Ł; Mądziel, M.; Stadnicka, D.; Dec, G.; Carreras-Coch, A.; Solé-Beteta, X.; Pappa, L.; Stylios, C.; Mazzei, D.; Atzeni, D. Plan and Develop Advanced Knowledge and Skills for Future Industrial Employees in the Field of Artificial Intelligence, Internet of Things and Edge Computing. Sustainability 2022, 14, 3312. [Google Scholar]
- Hsieh, C.H.; Chen, J.Y.; Nien, B.H. Deep learning-based indoor localization using received signal strength and channel state information. IEEE Access 2019, 7, 33256–33267. [Google Scholar] [CrossRef]
- Aun, Y.; Gan, M.L.; Khaw, Y.M.J. Automatic Attendance Taking: A Proof of Concept on Privacy Concerns in 802.11 MAC Address Probing. In Proceedings of the International Conference on Advances in Cyber Security, Penang, Malaysia, 30 July–1 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 274–288. [Google Scholar]
- Cominelli, M.; Kosterhon, F.; Gringoli, F.; Cigno, R.L.; Asadi, A. IEEE 802.11 CSI randomization to preserve location privacy: An empirical evaluation in different scenarios. Comput. Netw. 2021, 191, 107970. [Google Scholar] [CrossRef]
- Gu, X.; Wu, W.; Gu, X.; Ling, Z.; Yang, M.; Song, A. Probe request based device identification attack and defense. Sensors 2020, 20, 4620. [Google Scholar] [CrossRef] [PubMed]
- Uras, M.; Cossu, R.; Ferrara, E.; Bagdasar, O.; Liotta, A.; Atzori, L. Wifi probes sniffing: An artificial intelligence based approach for mac addresses de-randomization. In Proceedings of the 2020 IEEE 25th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Pisa, Italy, 14–16 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Georgievska, S.; Rutten, P.; Amoraal, J.; Ranguelova, E.; Bakhshi, R.; de Vries, B.L.; Lees, M.; Klous, S. Detecting high indoor crowd density with Wi-Fi localization: A statistical mechanics approach. J. Big Data 2019, 6, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Lau, B.P.L.; Koh, Z.; Yuen, C.; Ng, B.K.K. Understanding crowd behaviors in a social event by passive wifi sensing and data mining. IEEE Internet Things J. 2020, 7, 4442–4454. [Google Scholar] [CrossRef] [Green Version]
- Jamil, S.; Khan, S.; Basalamah, A.; Lbath, A. Classifying smartphone screen ON/OFF state based on wifi probe patterns. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 2–16 September 2016; pp. 301–304. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Author | Year | Reference | Citations |
|---|---|---|---|
| Andrews J.G. | 2012 | [55] | 950 |
| Wang X. | 2017 | [56] | 583 |
| Ferris B. | 2007 | [57] | 415 |
| Pan S.J. | 2008 | [58] | 367 |
| Dimatteo S. | 2011 | [59] | 261 |
| Kolias C. | 201 | [60] | 218 |
| Zhao M. | 2018 | [61] | 216 |
| Paper Type | Number of Papers | Perc |
|---|---|---|
| Conference Paper | 1943 | 56% |
| Article | 1173 | 34% |
| Proceeding Paper | 269 | 8% |
| Chapter | 34 | 1% |
| Review | 30 | 1% |
| Others | 9 | - |
| Topic | Count | Perc |
|---|---|---|
| 0 | 1136 | 33% |
| 1 | 537 | 16% |
| 2 | 280 | 8% |
| 3 | 218 | 6% |
| 4 | 200 | 6% |
| 5 | 191 | 6% |
| 6 | 160 | 5% |
| 7 | 72 | 2% |
| 8 | 70 | 2% |
| −1 | 585 | 17% |
| Topic | Size | NN | CNN | RNN | Transf | SVM | KNN | RF |
|---|---|---|---|---|---|---|---|---|
| 0 | 835 | 196 | 29 | 46 | 12 | 80 | 206 | 74 |
| 1 | 529 | 161 | 54 | 33 | 10 | 11 | 3 | 16 |
| 2 | 354 | 160 | 89 | 61 | 8 | 50 | 8 | 15 |
| 3 | 270 | 47 | 6 | 10 | 3 | 23 | 6 | 11 |
| 4 | 211 | 44 | 12 | 7 | 14 | 32 | 5 | 27 |
| 5 | 194 | 51 | 15 | 8 | 2 | 20 | 2 | 13 |
| 6 | 156 | 35 | 13 | 2 | 2 | 6 | 6 | 7 |
| 7 | 138 | 102 | 57 | 7 | 33 | 7 | 7 | 2 |
| 8 | 80 | 30 | 25 | 7 | 6 | 16 | 5 | 4 |
| −1 | 682 | 187 | 59 | 46 | 14 | 49 | 39 | 48 |
| Tot | 3449 | 1013 | 359 | 227 | 104 | 294 | 287 | 217 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atzeni, D.; Bacciu, D.; Mazzei, D.; Prencipe, G. A Systematic Review of Wi-Fi and Machine Learning Integration with Topic Modeling Techniques. Sensors 2022, 22, 4925. https://doi.org/10.3390/s22134925
Atzeni D, Bacciu D, Mazzei D, Prencipe G. A Systematic Review of Wi-Fi and Machine Learning Integration with Topic Modeling Techniques. Sensors. 2022; 22(13):4925. https://doi.org/10.3390/s22134925
Chicago/Turabian StyleAtzeni, Daniele, Davide Bacciu, Daniele Mazzei, and Giuseppe Prencipe. 2022. "A Systematic Review of Wi-Fi and Machine Learning Integration with Topic Modeling Techniques" Sensors 22, no. 13: 4925. https://doi.org/10.3390/s22134925
APA StyleAtzeni, D., Bacciu, D., Mazzei, D., & Prencipe, G. (2022). A Systematic Review of Wi-Fi and Machine Learning Integration with Topic Modeling Techniques. Sensors, 22(13), 4925. https://doi.org/10.3390/s22134925