1. Introduction
Relation extraction (RE) is the task of identifying the semantic relation between two or more entities. For example, given the sentence “Sam[Entity1] was born in 1596[Entity2]”, the target relation-type (class) between the entities would be person:date of birth.
In TACRED [
1] that is a widely used supervised RE dataset, we found that some classes suffer from (1) label noise that refers to the errors in labels [
2] and (2) low source availability as shown in
Table 1, and let denote those classes as minority classes, MCs. Due to those problems, several neural network models failed to learn MCs and got zero or very low F1 scores on MCs. For example, our experimental results showed that the average F1 test scores on MCs of C-GCN [
3], KnowBERT [
4], and LUKE [
5] were 0%, 0%, 14.3%, respectively; the experimental results of [
6] also confirmed the poor performance of 52 neural network models on MCs (details are provided in
Appendix E).
Although there have been many studies that dealt with label noise or low source availability, few studies have been done to directly address MCs in RE.
As for label noise, first, manually annotated RE datasets, such as Semeval-2010-Task-8 [
7], ACE 2005 (
https://catalog.ldc.upenn.edu/LDC2006T06 (accessed on 25 June 2022)), and the FewRel Dataset [
8], have been regarded as relatively clean, and the studies on these datasets have rarely considered the noise problem in their approach. However, a few researchers recently referred to the label noise problem in TACRED.
Table 2 shows the samples of training dataset under label noise. Alt et al. [
6] confirmed that the TACRED dev and test datasets were also corrupted; hence, they corrected the noisy instances and analyzed the error cases. Moreover, Stoica et al. [
9] re-categorized relations in TACRED and re-annotated labels. Although those studies highlighted out the label noise problem, they focused on the dataset itself and did not deal with the learning with the noise label.
Table 1.
Top seven classes in TACRED training dataset ordered by the level of label noise in descending order (a) and those ordered by the number of correct instances in ascending order (b).
per and
org are the abbreviation of person and organization,
Noise denotes the the level of label noise for each class which is calculated by
, and
Correct denotes the number of correct labels for each class. Noisy labels, i.e., wrong labels are determined by the refined annotation [
9]. Four classes marked in bold font suffer both of noise label and low source availability regime, i.e., MC. MC instances are totally 227 out of 68,124 training instances (0.33%) and the positive class which has most instances, 2443, is
person:title (3.6%).
Table 1.
Top seven classes in TACRED training dataset ordered by the level of label noise in descending order (a) and those ordered by the number of correct instances in ascending order (b).
per and
org are the abbreviation of person and organization,
Noise denotes the the level of label noise for each class which is calculated by
, and
Correct denotes the number of correct labels for each class. Noisy labels, i.e., wrong labels are determined by the refined annotation [
9]. Four classes marked in bold font suffer both of noise label and low source availability regime, i.e., MC. MC instances are totally 227 out of 68,124 training instances (0.33%) and the positive class which has most instances, 2443, is
person:title (3.6%).
| (a) | |
|---|
| Class | Noise |
| per:country_of_death | 83.3% |
| per:countries_of_residence | 80.7% |
| org:shareholders | 73.7% |
| per:other_family | 68.7% |
| org:member_of | 66.4% |
| per:cities_of_residence | 65.8% |
| org:dissolved | 65.2% |
| (b) | |
| Class | Correct |
| per:country_of_death | 1 |
| org:dissolved | 8 |
| per:country_of_birth | 15 |
| org:shareholders | 20 |
| per:stateorprovince_of_birth | 29 |
| per:stateorprovince_of_death | 33 |
| org:member_of | 41 |
In contrast, distant supervision for RE (DS-RE) inherently has suffered from the label noise problem and numerous studies have been conducted to solve it. Most of the existing studies mainly adopted multi-instance learning and focused on alleviating bag-level noise using sentence-level attention [
10,
11,
12,
13] or used extra information for entities [
14,
15]. However, no unified validation dataset for DS-RE has been proposed. Most researchers have used held-out evaluation and depended on human evaluation, which involves manually checking the subset of test instances. To tackle this problem, Gao et al. [
16] published the manually annotated test set for NYT10 [
17] and Wiki20 by using Wiki80 [
8] that is a widely used DS-RE dataset. The study confirmed that previous models on NYT10 failed in MC prediction.
Next, as for low source availability, the imbalanced distribution is a widely acknowledged problem in RE task [
18,
19,
20]. Negative instances, i.e.,
no relation, far exceed other instances. Moreover, even among the positive instances, the amount of clean MC instances is minimal and not sufficient for training a model. For example, the class with the most instances, i.e.,
person:title in TACRED accounts for only 3.6% of the entire training dataset and MC is much smaller, as shown in
Table 1. Some studies have tackled the label sparsity in RE by adopting data augmentation [
21,
22,
23]. However, Xu et al. [
21] simply reversed the dependency path of the head and tail entities to prevent overfitting. Eyal et al. [
23] validated the efficacy of their approaches on a subset of the dataset under certain scenarios. Papanikolaou et al. [
22] focused on the data generation itself and required exhaustively finetuning separate models on each class. As for data augmentation, several studies have proposed masked language modeling (MLM) based data generation [
24,
25] for text classification. However, they do not apply to RE because they cannot guarantee the class-invariant between entities, and most labels of RE are corrupted.
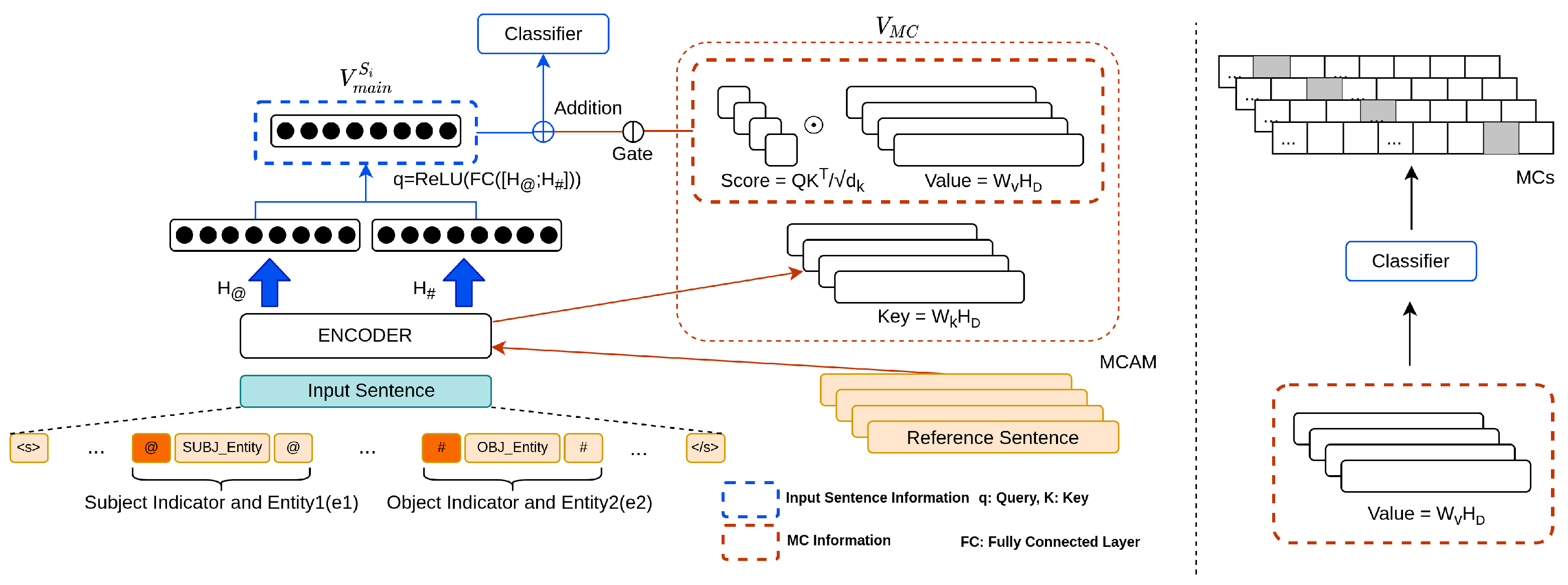
In this paper, we tackle the MC problem in RE and introduced (1) a minority class attention module (MCAM) with the class-specific reference sentence (Ref), and (2) the augmentation methods particularized to RE. We applied our methods to TACRED.
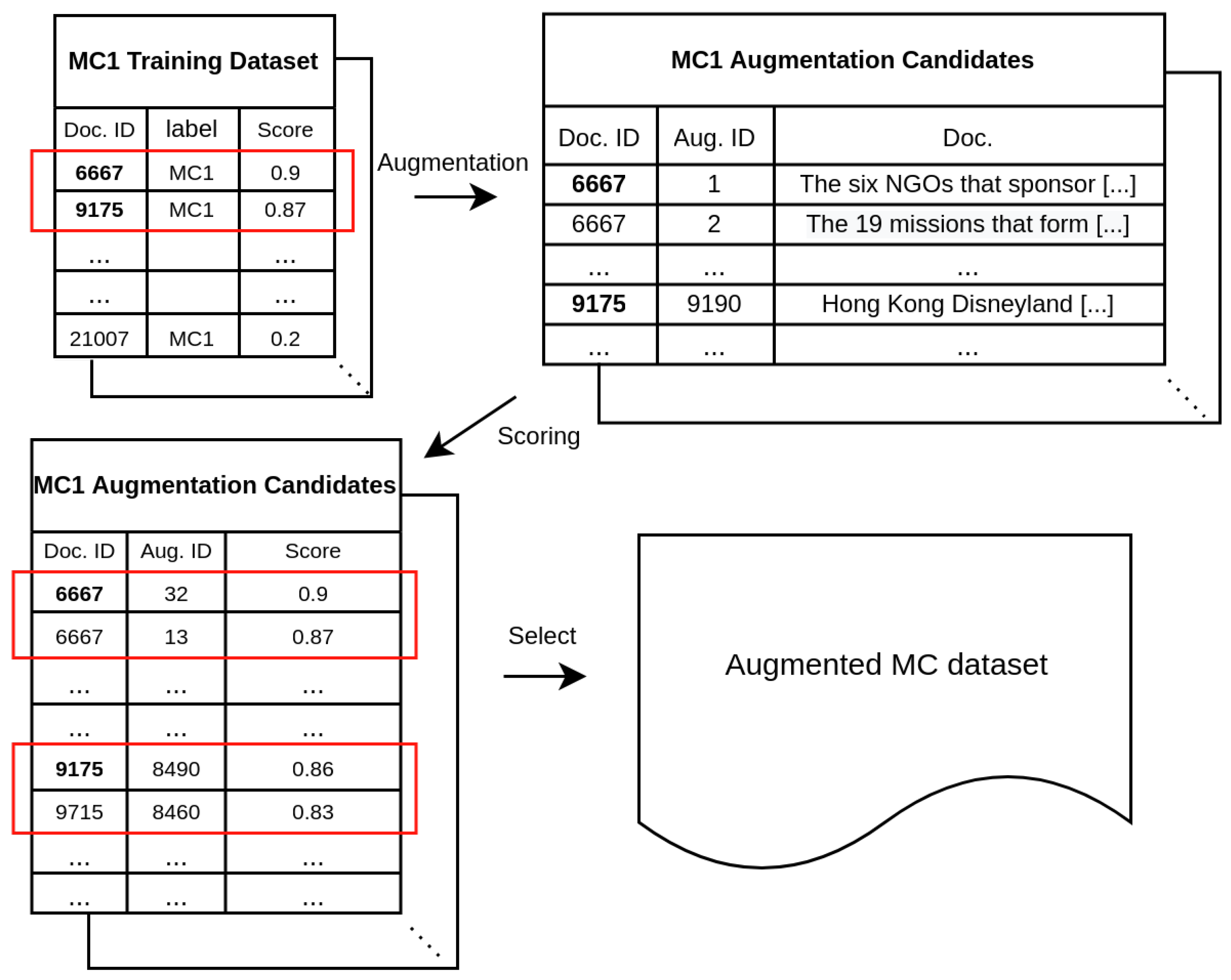
The Ref is a description that narrates the definition of the keywords in the MC relation-type. Take, relation type organization and dissolved, for example, the Ref of it is constructed by using the definition of origanization and dissolve. We adopted only one Ref for the targeted MC, which differs from previous studies that unselectively used external knowledge for entire classes. The vector of Ref can be seen as an MC label representation. For MCAM, it is used for identifying clean instances of corresponding MC and to construct the vector that represents MCs information. In detail, MCAM calculates the reliability score by comparing the input sentence of an MC instance and its corresponding Ref, where Refs are considered as criteria for distinguishing clean instances of each MC. Based on this score, reliable samples are selected for augmentation, and additionally, the vector of MC information is constructed. Our experiments show that the proposed methods achieved a state-of-the-art (SOTA) F1 score on TACRED, as well as dramatically enhanced MC F1 scores.
In brief, the main contributions of this study are as follows:
We propose MCAM that identifies noisy instances and improves MC prediction by constructing the vectors that represent the MCs information.
We propose simple yet effective data generation methods particularized to RE that coordinate with MCAM and minimize the risk of relation-type change.
Experimental results demonstrate the efficacy of the proposed approaches that enhance the overall model performance and MC prediction and is robust to spurious association.
2. Related Work
Distant Supervision (DS [
26]) inherently has a label noise problem, and numerous approaches have been proposed to tackle it. DS involves automatic data labeling based on the assumption that if two entities in the knowledge bases (KBs) are related, the relation may hold in all sentences where these entities are found. Although DS is an effective method for generating abundant training instances by using openly available KBs (e.g., Yago, Freebase, DBpedia, Wikidata), the training instances inevitably contain significant label noise. To alleviate the label noise problem, Riedel et al. [
17] and Hoffmann et al. [
27] relaxed the assumption and used the multi-instance learning (MIL) [
28] framework which was originally proposed to solve the task with ambiguous samples. For example, Riedel et al. [
17] used the
expressed-at-least-once assumption; it assume that at least one sentence exists where the predefined relation between the entities holds among the sentences mentioning the same entity pair. Moreover, under MIL, sentences mentioning the same entities were merged into
a bag for each triple
.
Based on MIL, several researchers for DS-RE have focused on reducing the bag-level noise mainly by using an attention mechanism [
10,
11,
12,
13]. For example, Lin et al. [
10] used sentence-level attention and assigned a different weight for each sentence in the same bag, and aggregated the informative representation of the sentences for the bag representation. Yuan et al. [
12] used the sentence-level attention, captured the correlation among the relations, and integrated the relevant sentence bags into a super-bag to minimize bag-level noise. In addition to the attention mechanism, some studies used extra knowledge from KBs to enrich the entity and label representation to clarify the relation between entities [
14,
15]. For example, Ji et al. [
14] used entity descriptions for the entity embedding, and Hu et al. [
15] used entity descriptions for label embedding and a bag representation robust to noisy instances. However, in real-world settings, entities are infinite and the descriptions in KBs are limited; hence, they are rarely applicable. Moreover, a model depending on the entity information is prone to use the so-called shallow heuristic methods (i.e., leveraging spurious association); consequently, it is likely to fail generalization on challenging samples [
29,
30]. In contrast, our approaches use Refs as criteria for determining clean MC instances, which are separate from noisy instances; and adopt only one Ref for each MC relation-type that is independent of the potentially infinite entity. Moreover, this study differs from previous studies in that we selectively used external knowledge for the targeted classes only.
Regarding alleviating imbalance distribution and solving low source availability, very few studies have applied data augmentation to RE. The reason is probably the difficulty of relation-type invariance. Papanikolaou et al. [
22] fine-tuned GPT-2 on each relation-type and generated augmentation dataset, which is not applicable to the RE task with many relation-types. Xu et al. [
21] augmented the dataset by changing the order of the dependency path of the head and tail entities. However, the study mainly focused on preventing overfitting and not on handling imbalanced distribution. As for generating synthetic data, several studies proposed MLM based approaches [
24,
25]. Nevertheless, they did not consider the label noise and not guarantee the relation-type invariant. Unlike previous studies, we introduce a method for generating synthetic data particularized to RE tasks that are not exhaustive and independent of label corruption by considering the bi-directional transformer-based architecture with the target entities unchanged, i.e., preserving a relation-type.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}