
Efficient Feature Learning Approach for Raw Industrial Vibration Data Using Two-Stage Learning Framework


Abstract
:1. Introduction
2. Background
2.1. Prototypical Networks
- Support Set: A random subset of classes from the training set is selected as support set containing K examples from each of the N classes.
- Query Set: A set of “testing” examples called queries.
2.2. Distance Metrics
3. Method
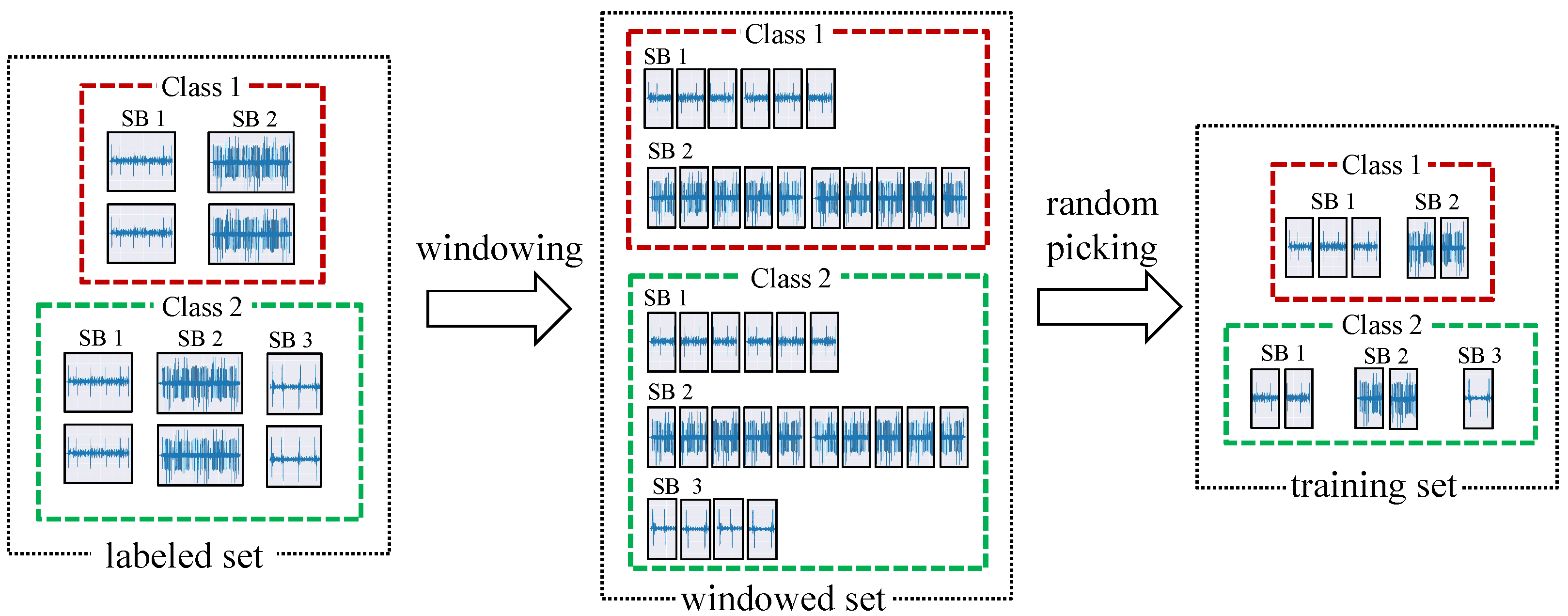
3.1. Mixture-Based Data Selection
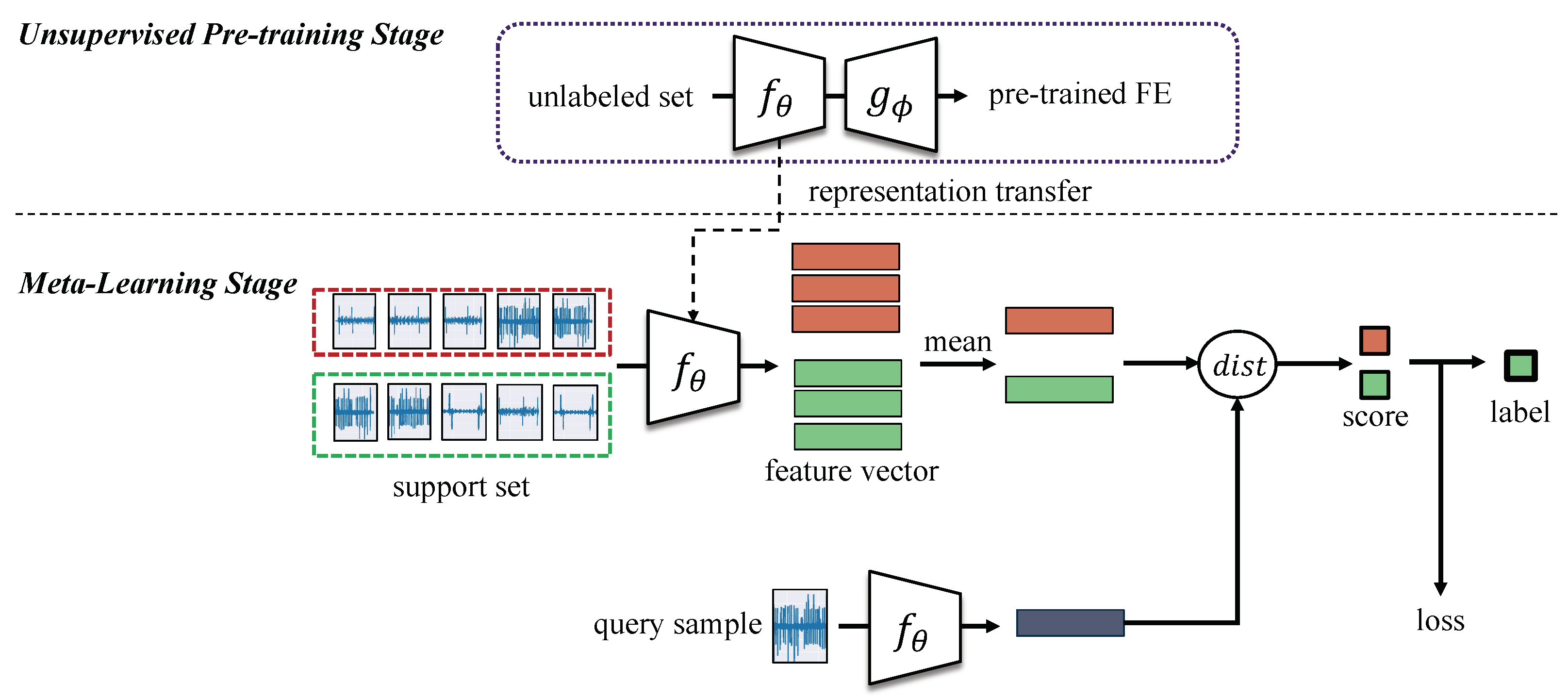
3.2. Two-Stage Learning Framework
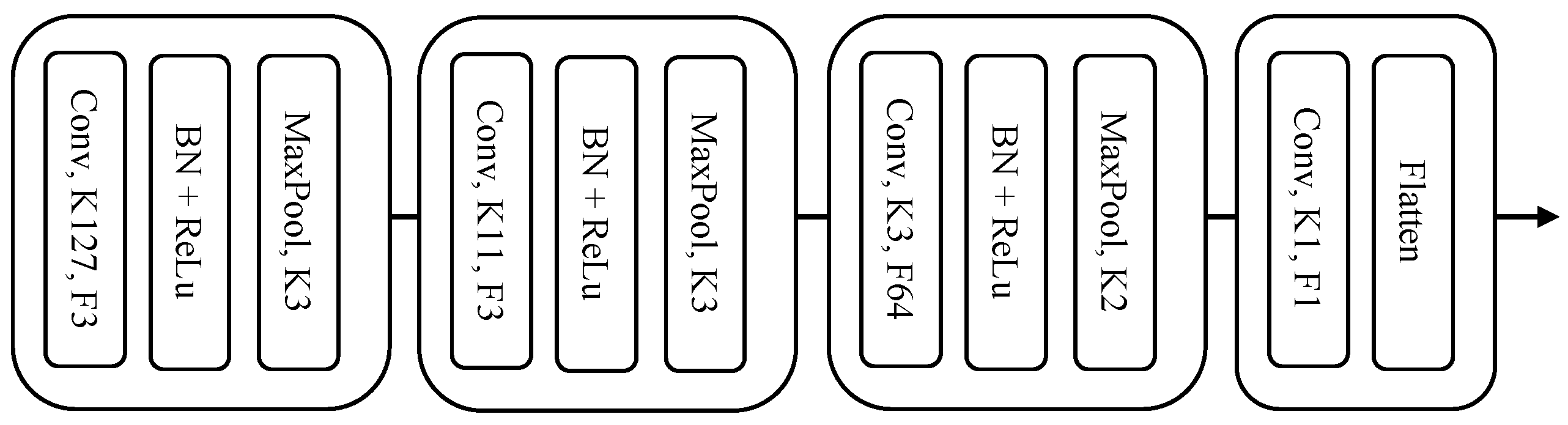
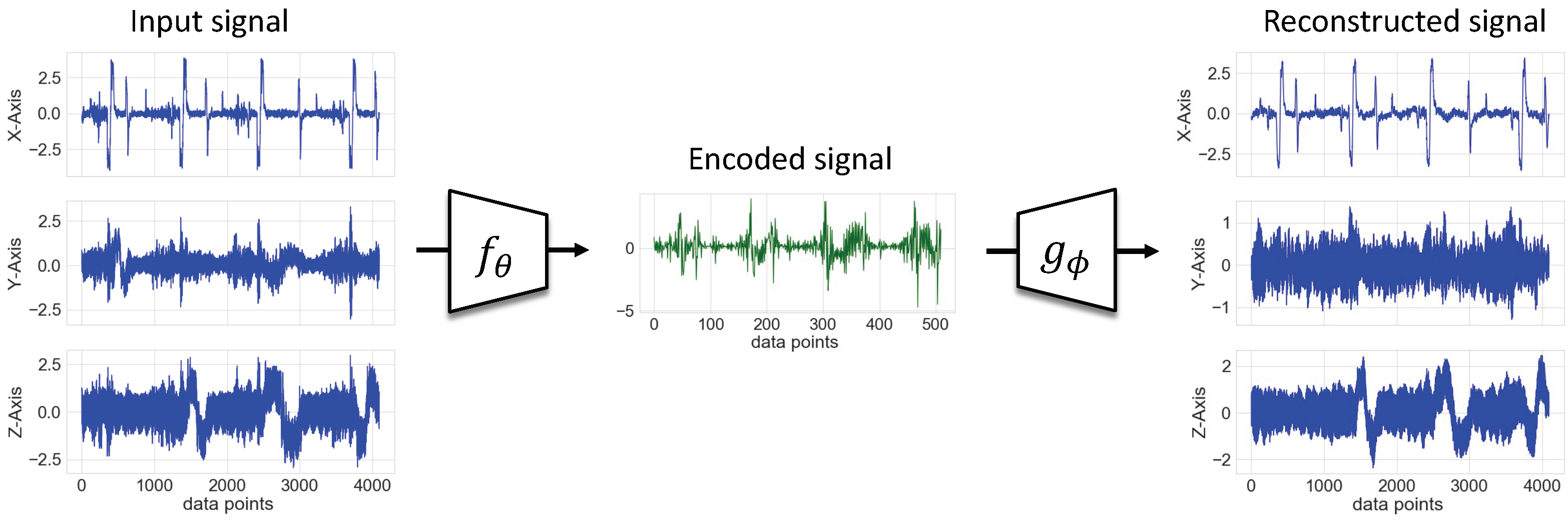
3.2.1. First Stage: Unsupervised Pretraining
| Algorithm 1 First stage: unsupervised pretraining |
Input: Unlabeled data set Output: Pretrained encoder function Initialize randomly for number of epochs do compute MSE error E using Equation (8) Update using gradients of E▹ compute backpropagation end for |
3.2.2. Second Stage: Metric Meta Learning Stage
| Algorithm 2 Second stage: metric-based fine-tuning |
Input: Labeled data set , pretrained encoder function Output: Two-staged trained encoder function ▹ initialize encoder with the pretrained parameters for number of epochs do Sample and from using the Section 3.1 method Generate prototypes using the averaging Equation (1) Calculate L for the minibatches using the loss Equation (3) Update using gradients of L▹ compute backpropagation end for |
4. Real-World Case Study
4.1. Data Description
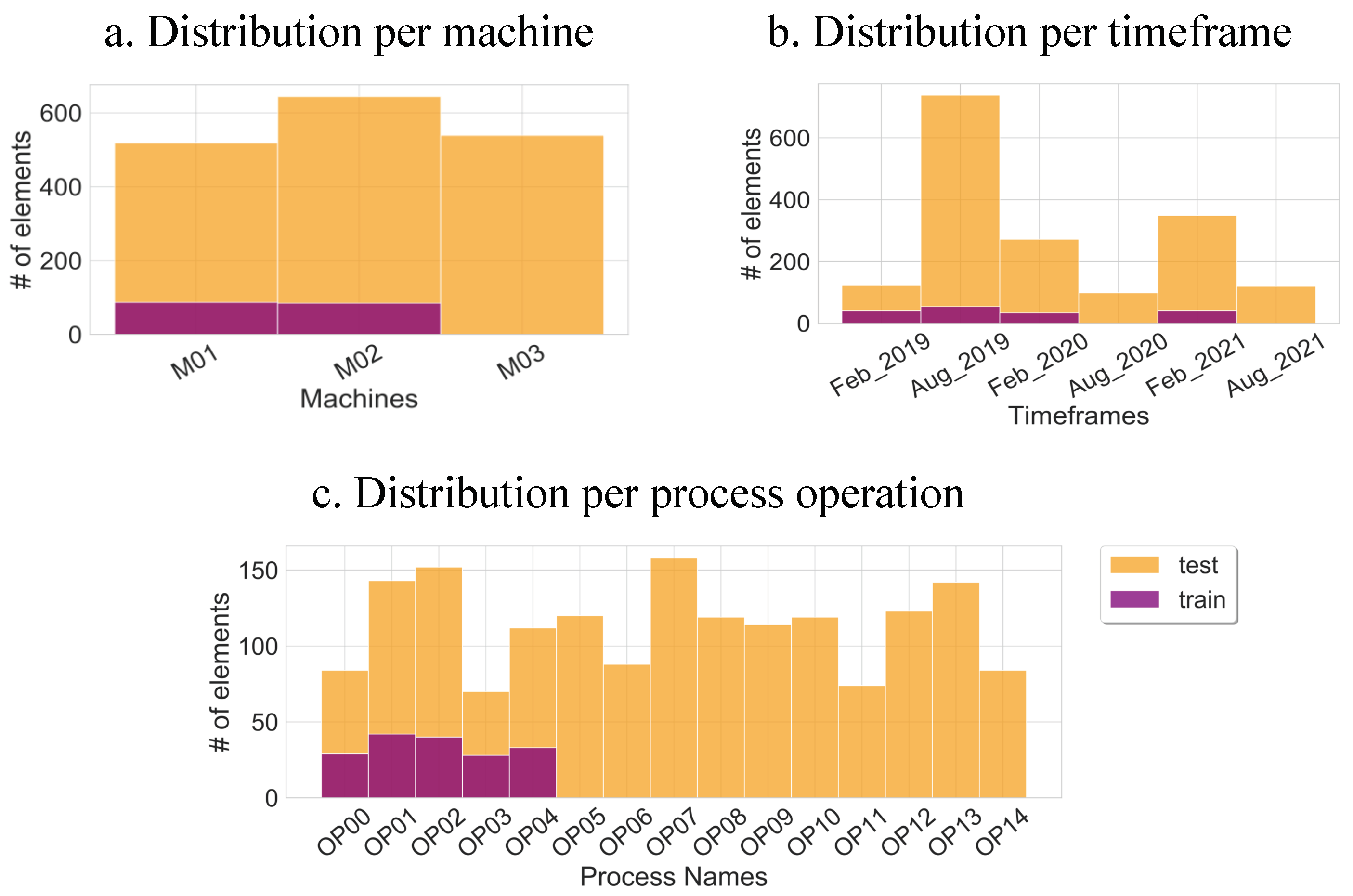
4.2. Data Splitting
- Machine-wise: This allowed the evaluation of the scalability of the models across different machines. We had 3 CNC Machines in consideration (M01, M02, and M03). Even though, they generated data samples representing the same tool process operations, they varied due to external conditions. Both the training and the test sets were uniformly distributed across the three machines as shown in Figure 4. With a uniform distribution, the model was not offered any unnecessary bias across a particular machine. M03 was not included in the training and was placed aside for testing.
- Process-wise: This allowed the evaluation of the generalization of the models across unseen tool processes. In industrial applications, new processes are constantly being added due to technological progress and market demand. The training set only contained 4 different tool operations whereas 11 new tool process operations were introduced in the test set.
- Period-wise: This allowed the evaluation of the robustness of the models across unseen periods. Worn components and aging cause a drift in the data, which affects the data-driven models. For that purpose, the periods of August 2020 and August 2021 were not included in the training and were placed aside for testing.
5. Experiments and Analysis
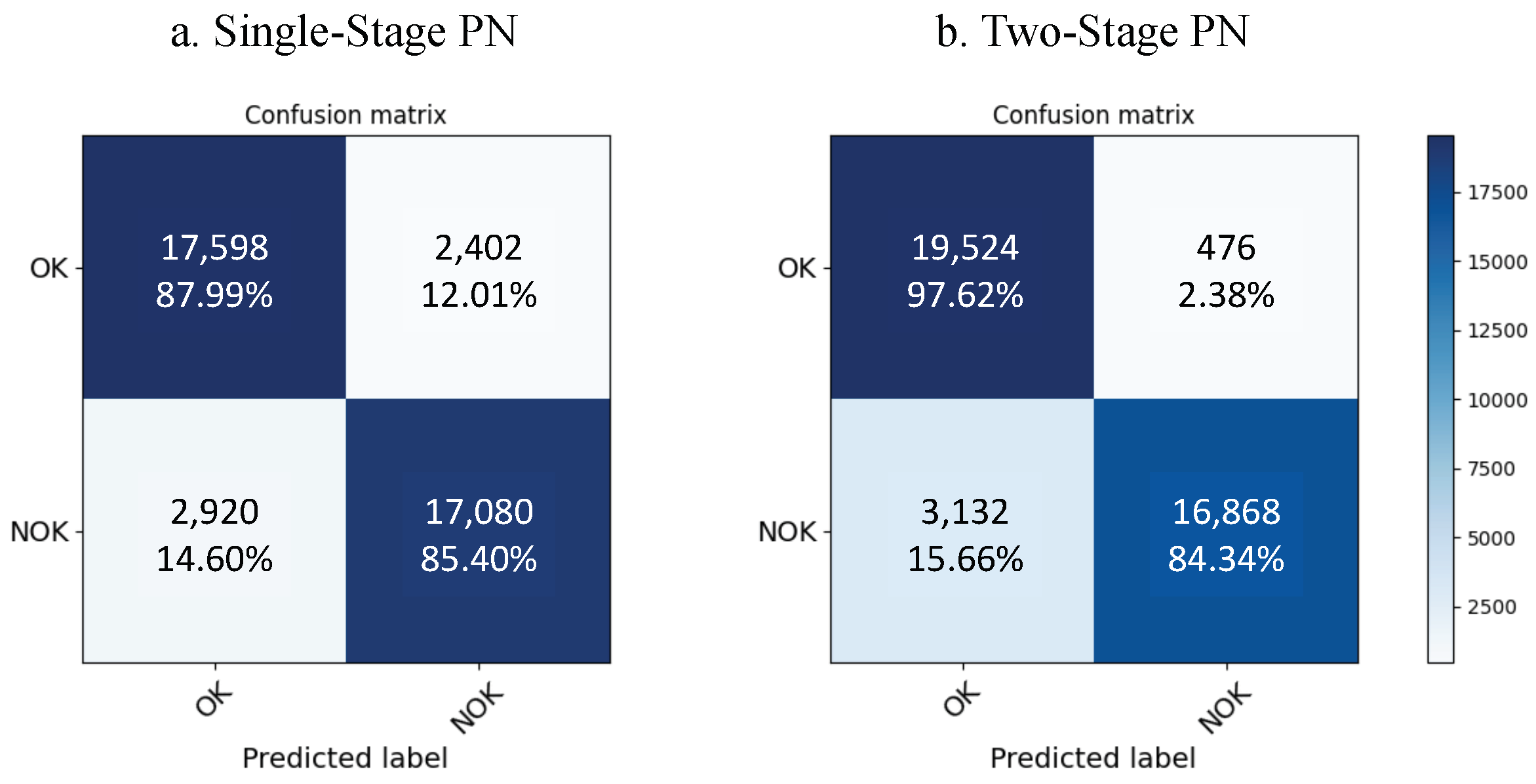
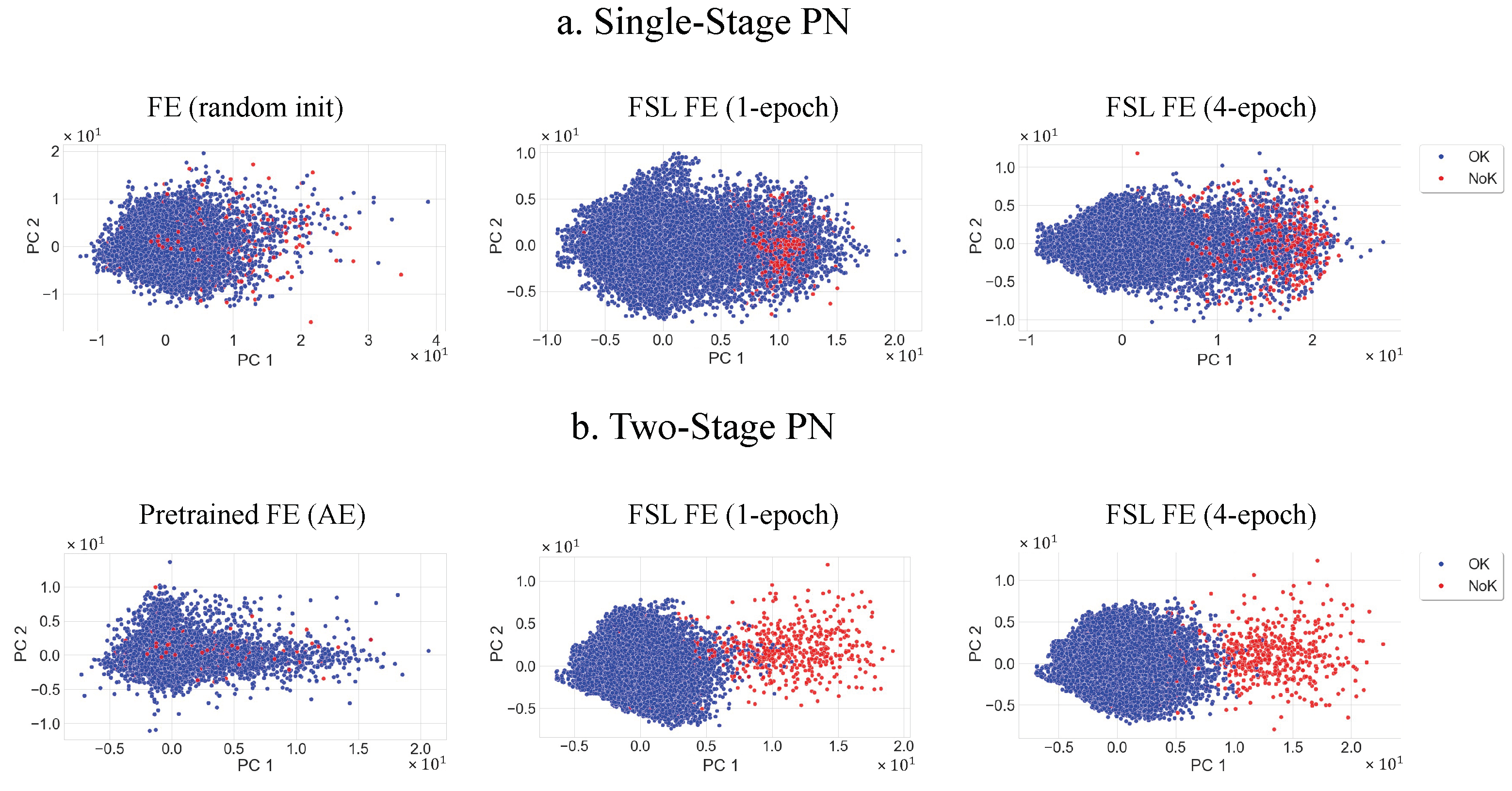
5.1. Single-Stage Prototypical Network
5.2. Two-Stage Prototypical Network
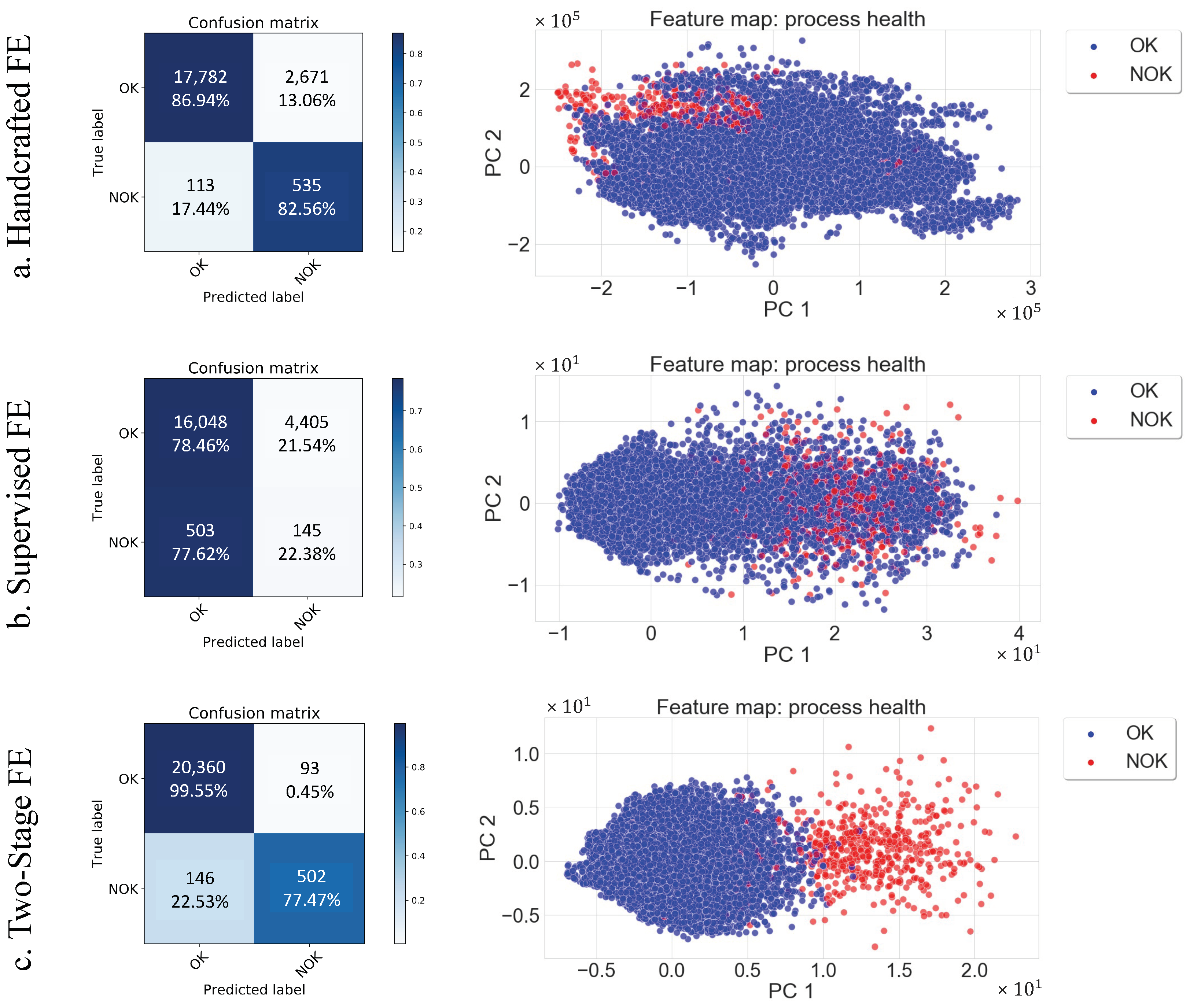
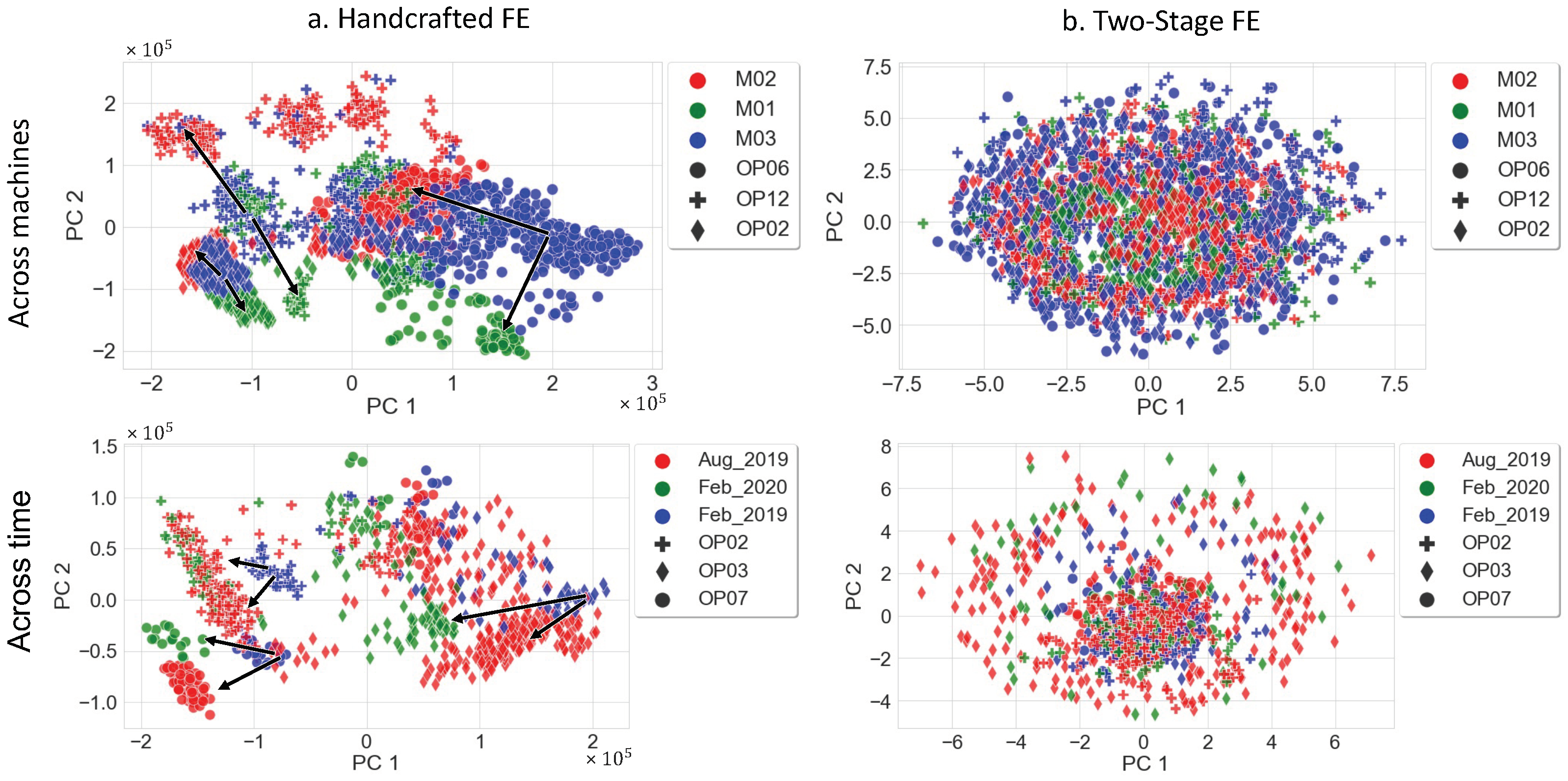
5.3. Handcrafted vs. Supervised vs. Two-Stage FE
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| CNC | Computer numerical control |
| DL | Deep learning |
| DTW | Distance time warping |
| FE | Feature extractor |
| FSL | Few-shot learning |
| IIoT | Industrial Internet of things |
| MDS | Mixture-based data selection |
| MSE | Mean square error |
| NN | Neural network |
| PCA | Principle component analysis |
| PN | Prototypical network |
| TS | Time series |
References
- Mohamed, A.; Hassan, M.; M’Saoubi, R.; Attia, H. Tool Condition Monitoring for High-Performance Machining Systems—A Review. Sensors 2022, 22, 2206. [Google Scholar] [CrossRef]
- Iliyas Ahmad, M.; Yusof, Y.; Daud, M.E.; Latiff, K.; Abdul Kadir, A.Z.; Saif, Y. Machine monitoring system: A decade in review. Int. J. Adv. Manuf. Technol. 2020, 108, 3645–3659. [Google Scholar] [CrossRef]
- Bostrom, A.; Bagnall, A. Binary shapelet transform for multiclass time series classification. In Proceedings of the International Conference on Big Data Analytics and Knowledge Discovery, Valencia, Spain, 1–4 September 2015; pp. 257–269. [Google Scholar]
- Kate, R.J. Using dynamic time warping distances as features for improved time series classification. Data Min. Knowl. Discov. 2016, 30, 283–312. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Chen, M.; Sun, Y.; Qin, X.; Li, H. A two-stage feature selection and intelligent fault diagnosis method for rotating machinery using hybrid filter and wrapper method. Neurocomputing 2018, 275, 2426–2439. [Google Scholar] [CrossRef]
- Yiakopoulos, C.; Gryllias, K.C.; Antoniadis, I.A. Rolling element bearing fault detection in industrial environments based on a K-means clustering approach. Expert Syst. Appl. 2011, 38, 2888–2911. [Google Scholar] [CrossRef]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time series feature extraction on basis of scalable hypothesis tests (tsfresh–a python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Lines, J.; Taylor, S.; Bagnall, A. Time series classification with HIVE-COTE: The hierarchical vote collective of transformation-based ensembles. ACM Trans. Knowl. Discov. Data 2018, 12. [Google Scholar] [CrossRef] [Green Version]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. Inceptiontime: Finding alexnet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Process. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Cabrera, D.; Sancho, F.; Long, J.; Sánchez, R.V.; Zhang, S.; Cerrada, M.; Li, C. Generative adversarial networks selection approach for extremely imbalanced fault diagnosis of reciprocating machinery. IEEE Access 2019, 7, 70643–70653. [Google Scholar] [CrossRef]
- Zareapoor, M.; Shamsolmoali, P.; Yang, J. Oversampling adversarial network for class-imbalanced fault diagnosis. Mech. Syst. Signal Process. 2021, 149, 107175. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. arXiv 2019, arXiv:1904.04232. [Google Scholar]
- Wang, D.; Zhang, M.; Xu, Y.; Lu, W.; Yang, J.; Zhang, T. Metric-based meta-learning model for few-shot fault diagnosis under multiple limited data conditions. Mech. Syst. Signal Process. 2021, 155, 107510. [Google Scholar] [CrossRef]
- Zhang, A.; Li, S.; Cui, Y.; Yang, W.; Dong, R.; Hu, J. Limited data rolling bearing fault diagnosis with few-shot learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Wang, S.; Wang, D.; Kong, D.; Wang, J.; Li, W.; Zhou, S. Few-shot rolling bearing fault diagnosis with metric-based meta learning. Sensors 2020, 20, 6437. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4080–4090. [Google Scholar]
- Sun, J.; Takeuchi, S.; Yamasaki, I. Prototypical Inception Network with Cross Branch Attention for Time Series Classification. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–23 June 2021; pp. 1–7. [Google Scholar]
- Tang, W.; Liu, L.; Long, G. Interpretable time-series classification on few-shot samples. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Jiang, C.; Chen, H.; Xu, Q.; Wang, X. Few-shot fault diagnosis of rotating machinery with two-branch prototypical networks. J. Intell. Manuf. 2022, 33, 1–15. [Google Scholar] [CrossRef]
- Yu, K.; Lin, T.R.; Tan, J. A bearing fault and severity diagnostic technique using adaptive deep belief networks and Dempster–Shafer theory. Struct. Health Monit. 2020, 19, 240–261. [Google Scholar] [CrossRef]
- Xu, H.; Ma, R.; Yan, L.; Ma, Z. Two-stage prediction of machinery fault trend based on deep learning for time series analysis. Digit. Signal Process. 2021, 117, 103150. [Google Scholar] [CrossRef]
- Das, D.; Lee, C.G. A two-stage approach to few-shot learning for image recognition. IEEE Trans. Image Process. 2019, 29, 3336–3350. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Afrasiyabi, A.; Lalonde, J.F.; Gagné, C. Mixture-based feature space learning for few-shot image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canad, 11–17 October 2021; pp. 9041–9051. [Google Scholar]
- Ma, J.; Xie, H.; Han, G.; Chang, S.F.; Galstyan, A.; Abd-Almageed, W. Partner-assisted learning for few-shot image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10573–10582. [Google Scholar]
- Afrasiabi, S.; Afrasiabi, M.; Parang, B.; Mohammadi, M.; Kahourzade, S.; Mahmoudi, A. Two-stage deep learning-based wind turbine condition monitoring using SCADA data. In Proceedings of the 2020 IEEE International Conference on Power Electronics, Drives and Energy Systems (PEDES), Jaipur, India, 16–19 December 2020; pp. 1–6. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Salvador, S.; Chan, P. Toward Accurate Dynamic Time Warping in Linear Time and Space. Intell. Data Anal. 2004, 11, 561–580. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Tnani, M.A.; Feil, M.; Diepold, K. Smart Data Collection System for Brownfield CNC Milling Machines: A New Benchmark Dataset for Data-Driven Machine Monitoring. Procedia CIRP 2022, 107, 131–136. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Train Loss | Test Loss | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|---|
| 1-shot | 0.1340 | 87.31 | 0.765 | 0.767 | 0.759 | 0.773 |
| 3-shot | 0.0304 | 36.95 | 0.848 | 0.847 | 0.856 | 0.835 |
| 5-shot | 0.0053 | 29.33 | 0.860 | 0.859 | 0.869 | 0.848 |
| 7-shot | 0.0048 | 22.76 | 0.876 | 0.873 | 0.893 | 0.855 |
| 10-shot | 0.0079 | 21.73 | 0.882 | 0.878 | 0.906 | 0.853 |
| Distance | Train Accuracy | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| Euclidean | 0.999 | 0.876 | 0.874 | 0.894 | 0.855 |
| DTW | 0.737 | 0.663 | 0.535 | 0.865 | 0.387 |
| Cosine | 1.000 | 0.842 | 0.851 | 0.803 | 0.905 |
| Model | Test Loss | Accuracy | F1-Score | Precision | Recall | Training Time (s) |
|---|---|---|---|---|---|---|
| Single-Stage | 22.76 | 0.876 | 0.873 | 0.893 | 0.855 | 295.91 |
| Two-Stage | 6.582 | 0.910 | 0.903 | 0.973 | 0.843 | 1295.68 |
| Feature Extractor | Accuracy | F1-Score | Precision | Recall | Training Time per Window (s) |
|---|---|---|---|---|---|
| Handcrafted | 0.868 | 0.845 | 0.862 | 0.848 | 2.2502 |
| Supervised | 0.767 | 0.056 | 0.200 | 0.032 | 0.0054 |
| Two-Stage | 0.989 | 0.884 | 0.905 | 0.885 | 0.0054 |
| (a) Handcrafted FE | |||||||
| Within only OK class | |||||||
| U= | Aug_2019 | Feb_2020 | Aug_2019 | M1 | M1 | M2 | OK |
| V= | Feb_2019 | Feb_2019 | Feb_2020 | M2 | M3 | M3 | NOK |
| 37,680.36 | 36,229.76 | 6435.13 | 37,919.52 | 14,147.56 | 37,602.05 | 35,868.79 | |
| (b) Two-Stage FE | |||||||
| Within only OK class | |||||||
| U= | Aug_2019 | Feb_2020 | Aug_2019 | M1 | M1 | M2 | OK |
| V= | Feb_2019 | Feb_2019 | Feb_2020 | M2 | M3 | M3 | NOK |
| 0.484 | 0.529 | 0.146 | 0.337 | 0.513 | 1.001 | 6.22 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tnani, M.-A.; Subarnaduti, P.; Diepold, K. Efficient Feature Learning Approach for Raw Industrial Vibration Data Using Two-Stage Learning Framework. Sensors 2022, 22, 4813. https://doi.org/10.3390/s22134813
Tnani M-A, Subarnaduti P, Diepold K. Efficient Feature Learning Approach for Raw Industrial Vibration Data Using Two-Stage Learning Framework. Sensors. 2022; 22(13):4813. https://doi.org/10.3390/s22134813
Chicago/Turabian StyleTnani, Mohamed-Ali, Paul Subarnaduti, and Klaus Diepold. 2022. "Efficient Feature Learning Approach for Raw Industrial Vibration Data Using Two-Stage Learning Framework" Sensors 22, no. 13: 4813. https://doi.org/10.3390/s22134813
APA StyleTnani, M.-A., Subarnaduti, P., & Diepold, K. (2022). Efficient Feature Learning Approach for Raw Industrial Vibration Data Using Two-Stage Learning Framework. Sensors, 22(13), 4813. https://doi.org/10.3390/s22134813