
A Novel Remote Sensing Image Registration Algorithm Based on Feature Using ProbNet-RANSAC


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A semi-automatic method of creating training data for remote sensing image registration was proposed that could greatly reduce the workload of labeling and make it possible to train a deep convolutional neural network.
- We derived the model estimation based on RANSAC from a probability perspective, and a deep convolutional neural network of ProbNet was built to evaluate the quality of corresponding feature points according to probability.
- We used the probability generated by ProbNet to guide the sampling of a minimum set of RANSAC, which could acquire a more accurate transformation model.
2. Methodology
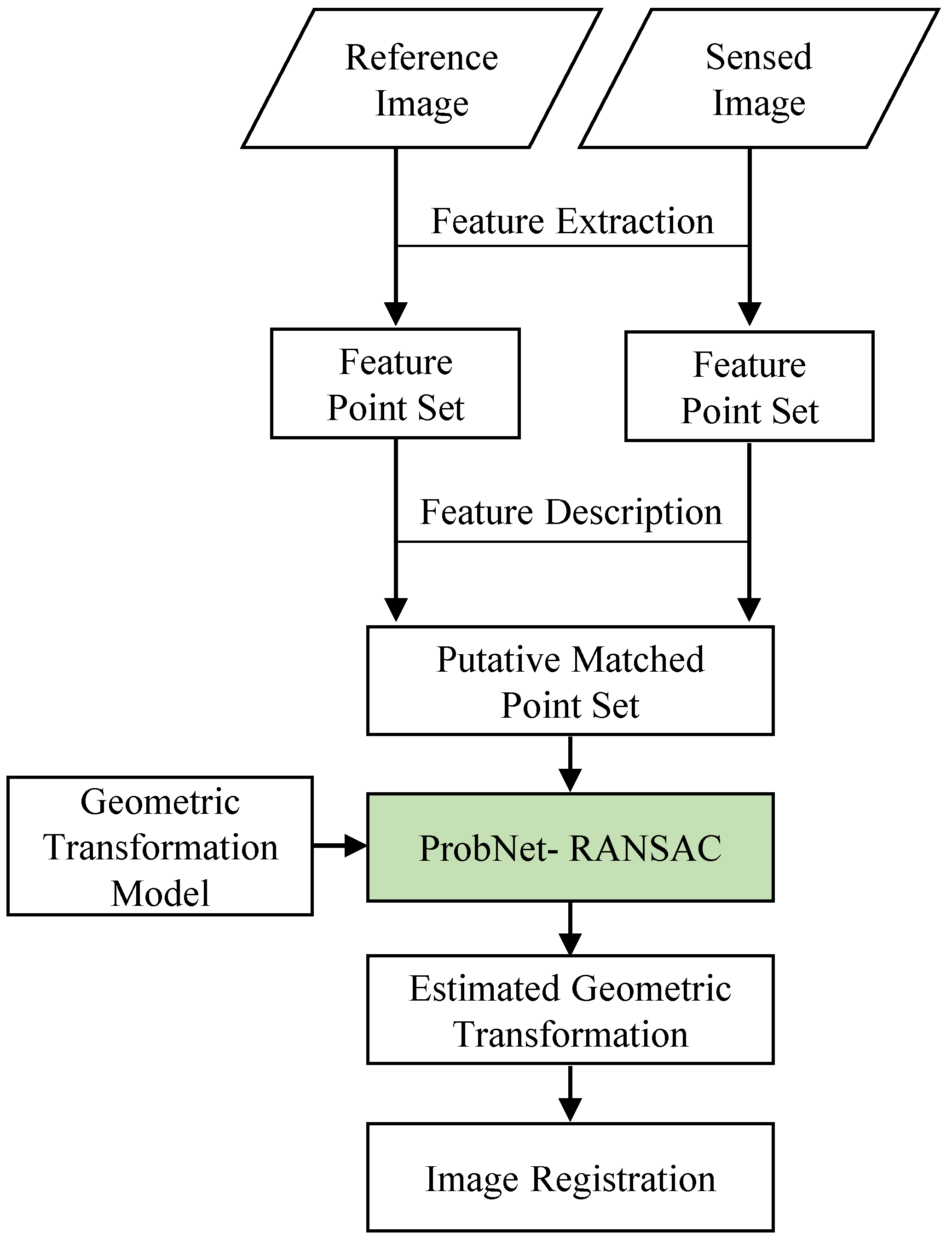
2.1. The Whole Workflow of Image Registration Based on Feature by Using ProbNet-Ransac
2.2. The Pipeline of Geometric Transformation Model Estimation Based on ProbNet-Ransac
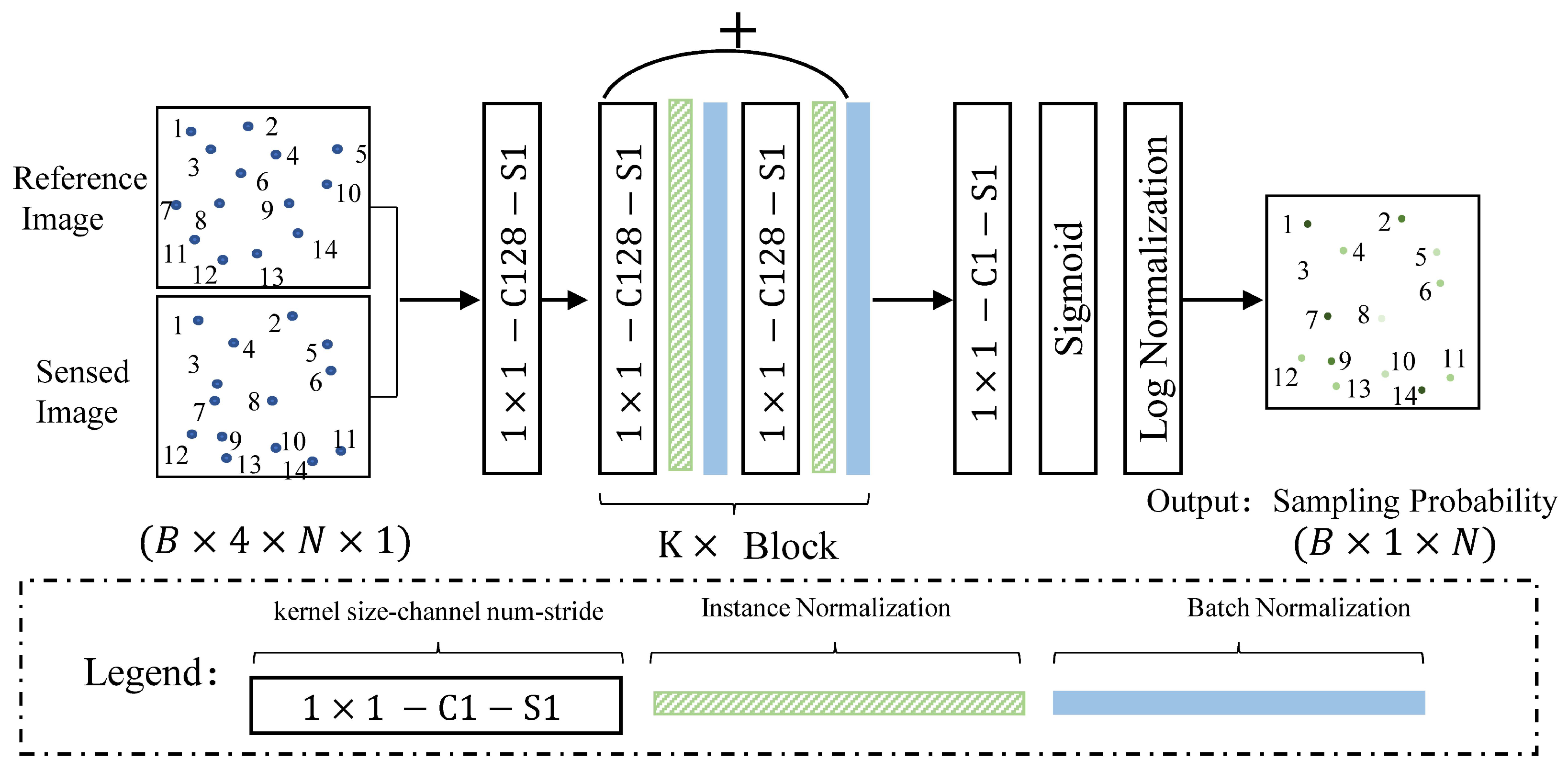
2.2.1. The Architecture of Deep Convolution Neural Network (ProbNet)
2.2.2. The Optimization of ProbNet
3. Experiment and Results
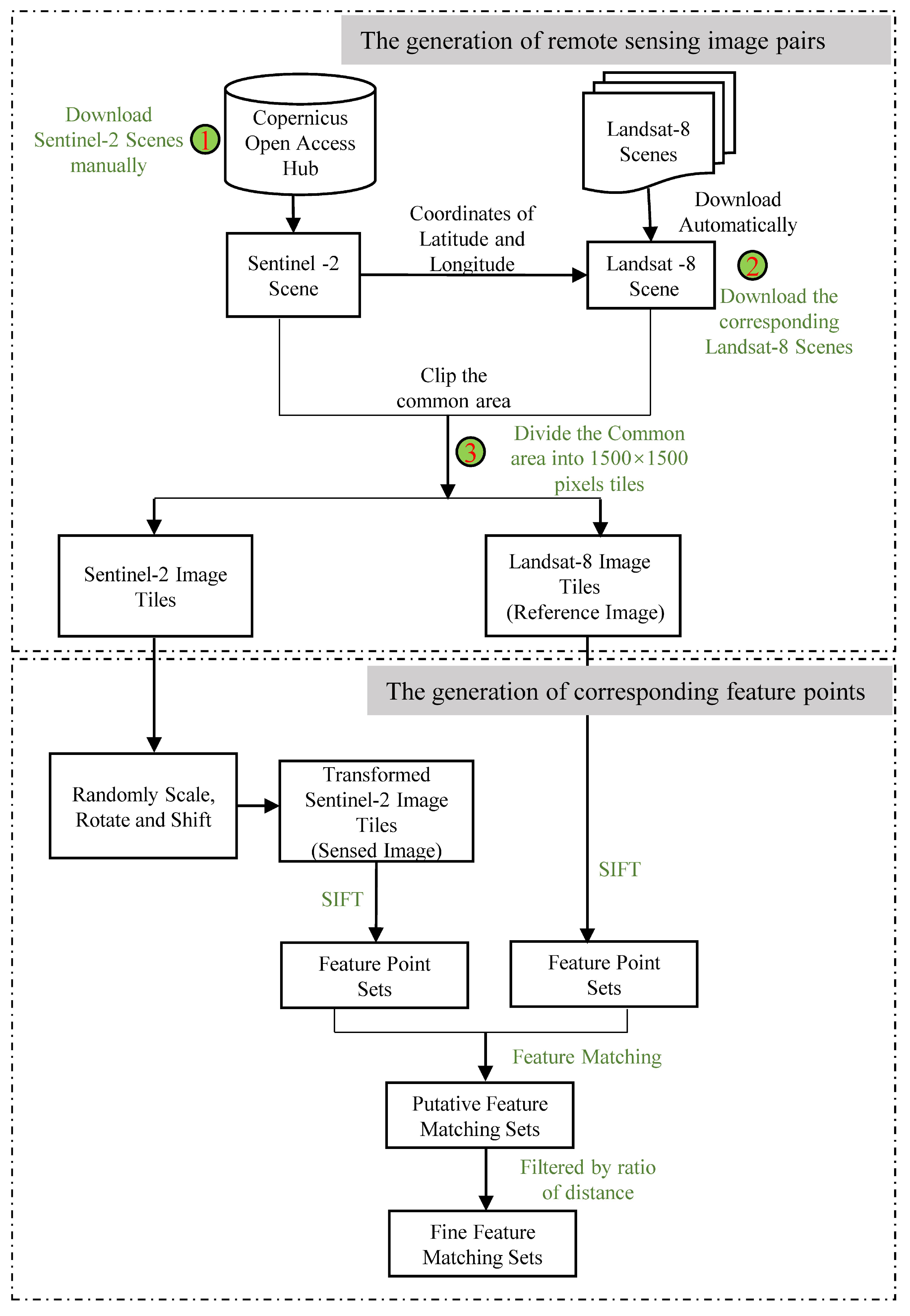
3.1. The Generation of Training Data
- The generation of remote sensing image pairs. The Level-1C products of Sentinel-2 and Level-2 products of Landsat-8 remote sensing images were used as image sources. Firstly, we manually downloaded the Sentinel-2 images from the Copernicus Open Access Hub. Secondly, for each Sentinel-2 image, we used the python script to automatically download the corresponding Landsat-8 image according to the coordinates of latitude and longitude of the Sentinel-2 image. Finally, we cropped the common area of the pair of images by using the GDAL [30] and divided the common area into image tiles with a size of pixels. Each pair of image tiles was aligned due to the Level-1C products of Sentinel-2 and Level-2 products of Landsat-8 having been rigorously geometrically corrected.
- The generation of corresponding feature points. For each pair of image tiles, we regarded the Landsat-8 image tile as a reference image, and then randomly scaled, rotated, and shifted the Sentinel-2 image tile to mimic the geometrical deformation between the image pairs and regarded the transformed tile as a sensed image. The value of the scaling, rotation, and displacement formed a homography matrix H. The range of rotation was , and the range of scaling was , and the range of shift was pixels. After the generation of the reference and sensed image pairs, we used the SIFT algorithm from the VLFeat MATLAB library [29] to detect feature points from each image and match them to acquire the putative corresponding feature points. Then we used the ratio of the nearest-to-second-nearest descriptor distance to filter out obviously wrong correspondence points in order to acquire the fine feature corresponding sets. The threshold of ratio was set to . The fine corresponding point set for each pair of images was regarded as a sample of the training data, and its label was the homography matrix H. The number of corresponding feature points was different for each pair of images due to the difference between image contents.
3.2. The Details of Training of ProbNet
3.3. Qualitative Experiment
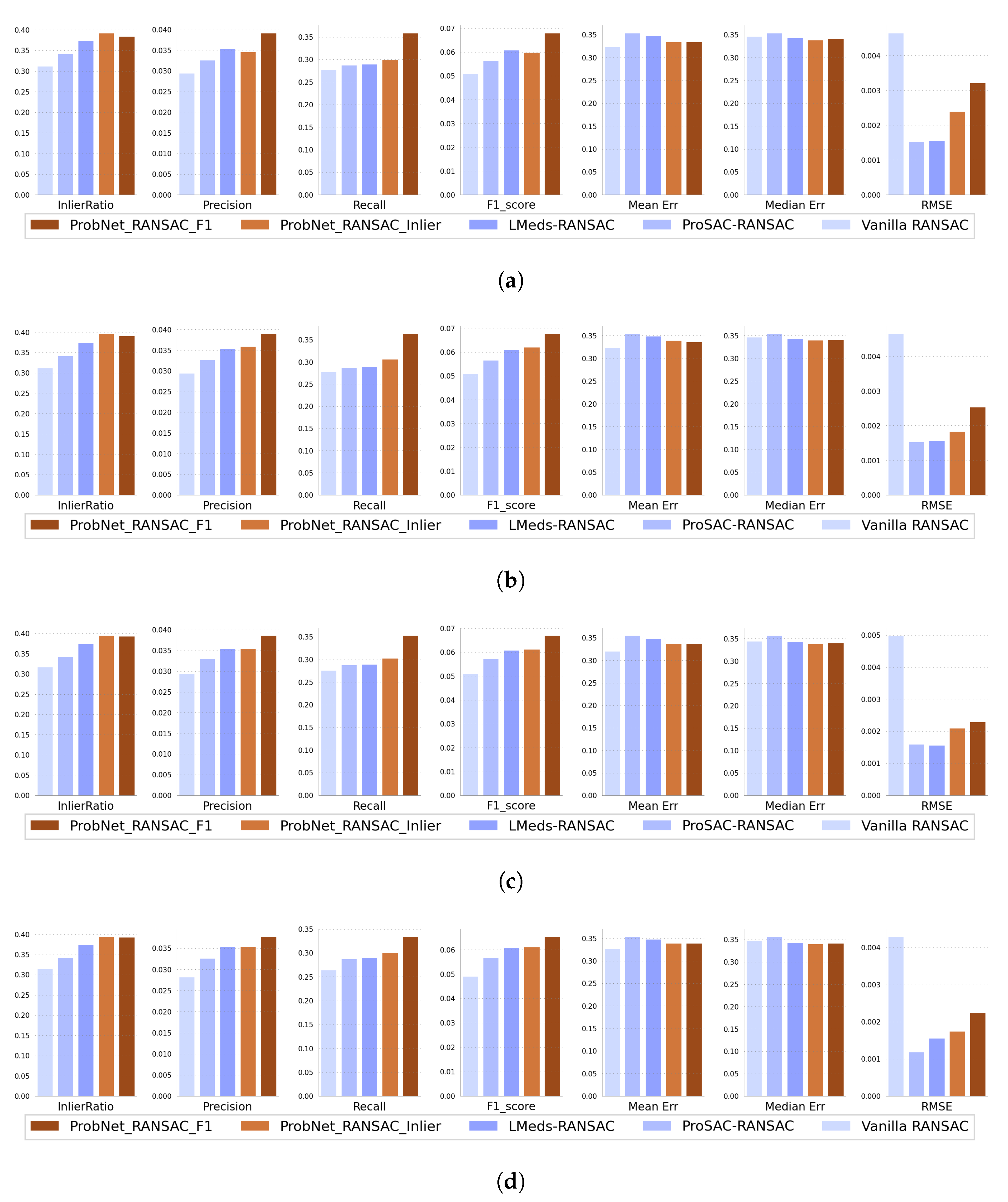
3.4. Quantitative Experiments
4. Discussion
4.1. Analysis of Qualitative Experiment
4.2. Analysis of Quantitative Experiment
4.3. The Effects of Loss Function of ProbNet
4.4. The Initialization of ProbNet
4.5. The Efficiency of ProbNet Ransac
5. Conclusions
- The proposed method could effectively register different remote sensing images; its registration result was satisfactory by the checkerboard visualization of images after registration, and it should be generalizable to other optical remote sensing images.
- Regarding the three different task losses including reprojection error, the negative F1 score, and the negative number of inliers, the minimized reprojection error would bias ProbNet towards a smaller number of inliers, while a negative number of inliers or a negative F1 score could effectively optimize ProbNet.
- To accelerate the training of ProbNet, a special initialization of ProbNet was conducted by minimizing the Kullback-–Leibler divergence between the ground accuracy probability distribution and predicted probability distribution for each corresponding feature point. After 3000 epochs, the predicted probability was a good approximation to the ground accuracy probability.
- Regarding the measures of InlierRatio, Precision, Recall, and F1 score, the proposed methods trained by minimizing the negative number of inliers or negative F1 score had significant advantages over the other three popular methods including vanilla RANSAC, ProSAC RANSAC, and LMeds RANSAC. However, for the measures of Mean Error, Median Error, and RMSE, the advantages of the proposed method diminished due to these measures being calculated for their respective inliers; the number of inliers of the proposed methods were the largest. This was also supported by the experiment of minimizing the task loss of reprojection error, and the smaller number of inliers also led to a decrease in the reprojection error.
Author Contributions
Funding
Conflicts of Interest
References
- Toth, C.; Jóźków, G. Remote sensing platforms and sensors: A survey. ISPRS J. Photogramm. Remote. Sens. 2016, 115, 22–36. [Google Scholar] [CrossRef]
- Paul, S.; Pati, U.C. A comprehensive review on remote sensing image registration. Int. J. Remote. Sens. 2021, 42, 5400–5436. [Google Scholar] [CrossRef]
- Wong, A.; Clausi, D.A. ARRSI: Automatic registration of remote-sensing images. IEEE Trans. Geosci. Remote. Sens. 2007, 45, 1483–1493. [Google Scholar] [CrossRef]
- Zhang, X.; Leng, C.; Hong, Y.; Pei, Z.; Cheng, I.; Basu, A. Multimodal Remote Sensing Image Registration Methods and Advancements: A Survey. Remote. Sens. 2021, 13, 5128. [Google Scholar] [CrossRef]
- Zitova, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Goshtasby, A.A. Image Registration: Principles, Tools and Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Rasmy, L.; Sebari, I.; Ettarid, M. Automatic sub-pixel co-registration of remote sensing images using phase correlation and Harris detector. Remote. Sens. 2021, 13, 2314. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, S.; Jiao, L.; Tian, D.; Wang, S. A novel coarse-to-fine scheme for automatic image registration based on SIFT and mutual information. IEEE Trans. Geosci. Remote. Sens. 2013, 52, 4328–4338. [Google Scholar] [CrossRef]
- Yang, H.; Li, X.; Zhao, L.; Chen, S. A novel coarse-to-fine scheme for remote sensing image registration based on SIFT and phase correlation. Remote. Sens. 2019, 11, 1833. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Zhang, Y.; Zhang, Z.; Lai, G. A coarse-to-fine registration strategy for multi-sensor images with large resolution differences. Remote. Sens. 2019, 11, 470. [Google Scholar] [CrossRef] [Green Version]
- Joshi, K.; Patel, M.I. Recent advances in local feature detector and descriptor: A literature survey. Int. J. Multimed. Inf. Retr. 2020, 9, 231–247. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yu, G.; Morel, J.M. ASIFT: An algorithm for fully affine invariant comparison. Image Process. On Line 2011, 1, 11–38. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Barroso-Laguna, A.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Key.Net: Keypoint Detection by Handcrafted and Learned CNN Filters. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Tian, Y.; Fan, B.; Wu, F. L2-net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- Dong, Y.; Jiao, W.; Long, T.; Liu, L.; He, G.; Gong, C.; Guo, Y. Local deep descriptor for remote sensing image feature matching. Remote. Sens. 2019, 11, 430. [Google Scholar] [CrossRef] [Green Version]
- Fraser, C.S.; Dial, G.; Grodecki, J. Sensor orientation via RPCs. ISPRS J. Photogramm. Remote. Sens. 2006, 60, 182–194. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Chum, O.; Matas, J. Matching with PROSAC-progressive sample consensus. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 220–226. [Google Scholar]
- Ni, K.; Jin, H.; Dellaert, F. Groupsac: Efficient consensus in the presence of groupings. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 2193–2200. [Google Scholar]
- Matas, J.; Chum, O. Randomized RANSAC with sequential probability ratio test. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2, pp. 1727–1732. [Google Scholar]
- Lebeda, K.; Matas, J.; Chum, O. Fixing the locally optimized ransac–full experimental evaluation. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; Volume 2. [Google Scholar]
- Raguram, R.; Chum, O.; Pollefeys, M.; Matas, J.; Frahm, J.M. USAC: A universal framework for random sample consensus. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2022–2038. [Google Scholar] [CrossRef]
- Brachmann, E.; Krull, A.; Nowozin, S.; Shotton, J.; Michel, F.; Gumhold, S.; Rother, C. DSAC-differentiable ransac for camera localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6684–6692. [Google Scholar]
- Yi, K.M.; Trulls, E.; Ono, Y.; Lepetit, V.; Salzmann, M.; Fua, P. Learning to find good correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2666–2674. [Google Scholar]
- Schulman, J.; Heess, N.; Weber, T.; Abbeel, P. Gradient estimation using stochastic computation graphs. arXiv 2015, arXiv:1506.05254. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998; Volume 135. [Google Scholar]
- GDAL/OGR Contributors. GDAL/OGR Geospatial Data Abstraction Software Library; Open Source Geospatial Foundation: Chicago, IL, USA, 2022. [Google Scholar] [CrossRef]
- Kingma, D.P.; Adam, J.B. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ordóñez, Á.; Argüello, F.; Heras, D.B. GPU Accelerated FFT-based Registration of Hyperspectral Scenes. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 4869–4878. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Revaud, J.; De Souza, C.; Humenberger, M.; Weinzaepfel, P. R2d2: Reliable and repeatable detector and descriptor. In Proceedings of the NeurIPS 2019—2019 Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Liang, C.; Zhao, C. A Novel Remote Sensing Image Registration Algorithm Based on Feature Using ProbNet-RANSAC. Sensors 2022, 22, 4791. https://doi.org/10.3390/s22134791
Dong Y, Liang C, Zhao C. A Novel Remote Sensing Image Registration Algorithm Based on Feature Using ProbNet-RANSAC. Sensors. 2022; 22(13):4791. https://doi.org/10.3390/s22134791
Chicago/Turabian StyleDong, Yunyun, Chenbin Liang, and Changjun Zhao. 2022. "A Novel Remote Sensing Image Registration Algorithm Based on Feature Using ProbNet-RANSAC" Sensors 22, no. 13: 4791. https://doi.org/10.3390/s22134791
APA StyleDong, Y., Liang, C., & Zhao, C. (2022). A Novel Remote Sensing Image Registration Algorithm Based on Feature Using ProbNet-RANSAC. Sensors, 22(13), 4791. https://doi.org/10.3390/s22134791