
PRAPNet: A Parallel Residual Atrous Pyramid Network for Polyp Segmentation

Abstract
:1. Introduction
- (1)
- We offer a novel parallel residual atrous pyramid module for accurate polyp segmentation. Including this module in the FCN-based pixel-level intestinal polyposis prediction framework allows for a more accurate and precise segmentation of the intestinal polyp area, which can greatly enhance the segmentation results when compared with other state-of-the-art approaches. Our proposed improvement can make an effective use of a tiny quantity of picture data.
- (2)
- A practical system is established for the intestinal polyp segmentation task that includes all the key implementation details of the method in this paper.
2. Methods
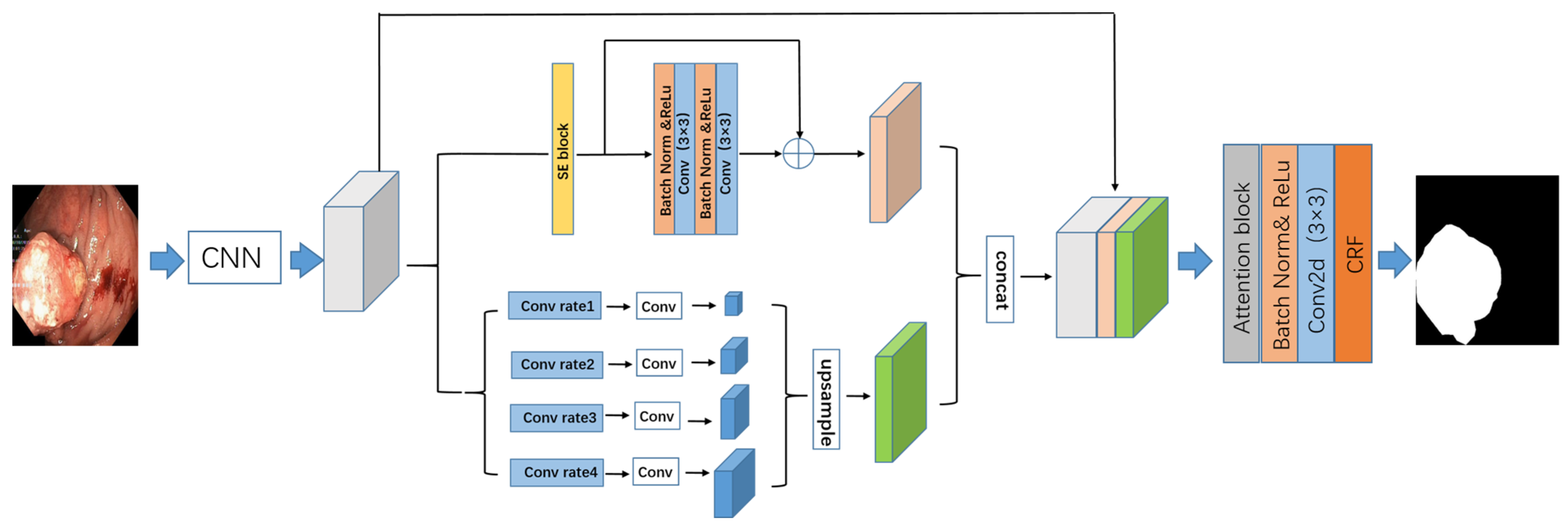
2.1. Proposed Network Structure
2.2. Parallel Residual Atrous Pyramid Model
2.3. Attention Units
2.4. Conditional Random Field
3. Experiment
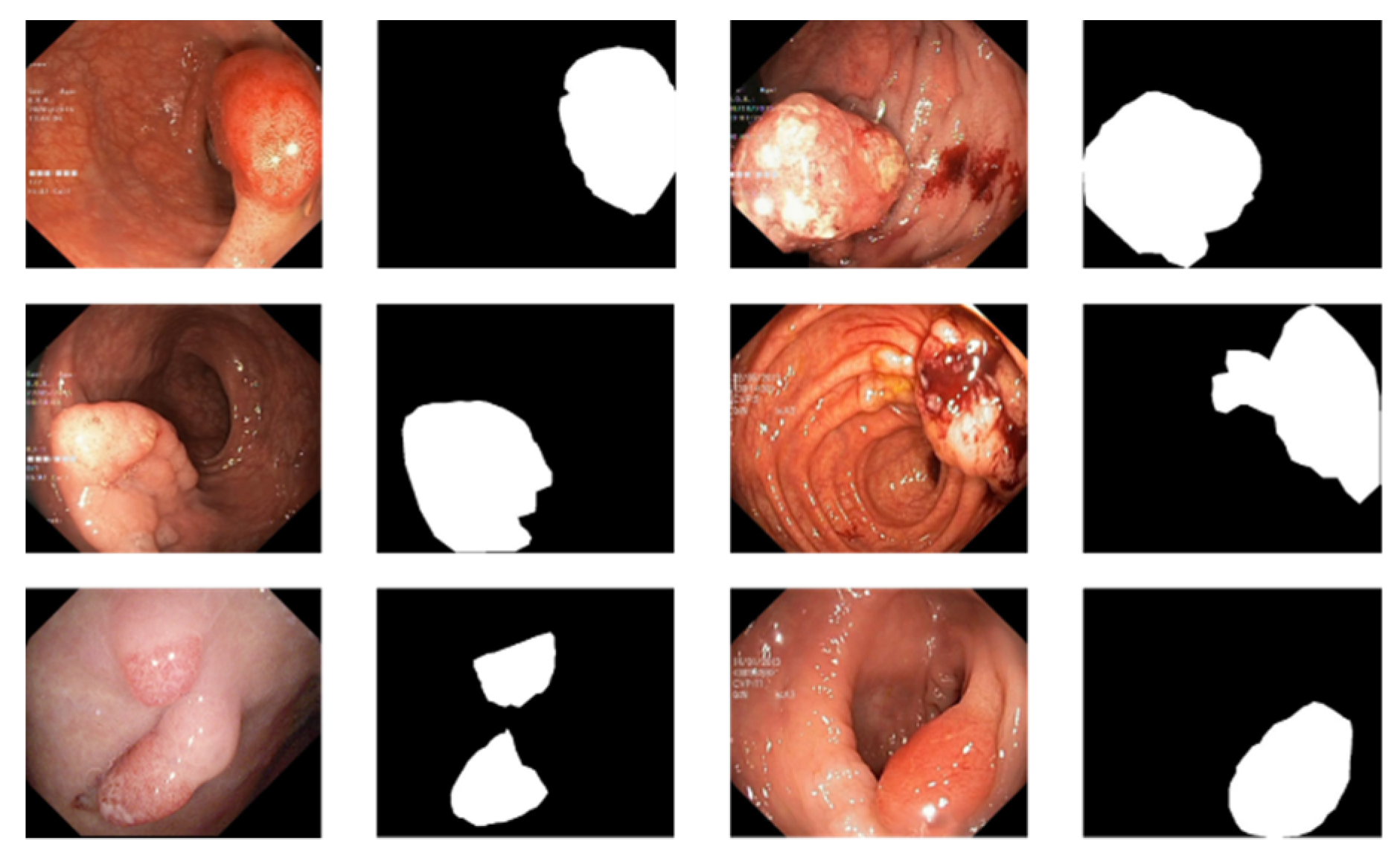
3.1. Data Preprocessing
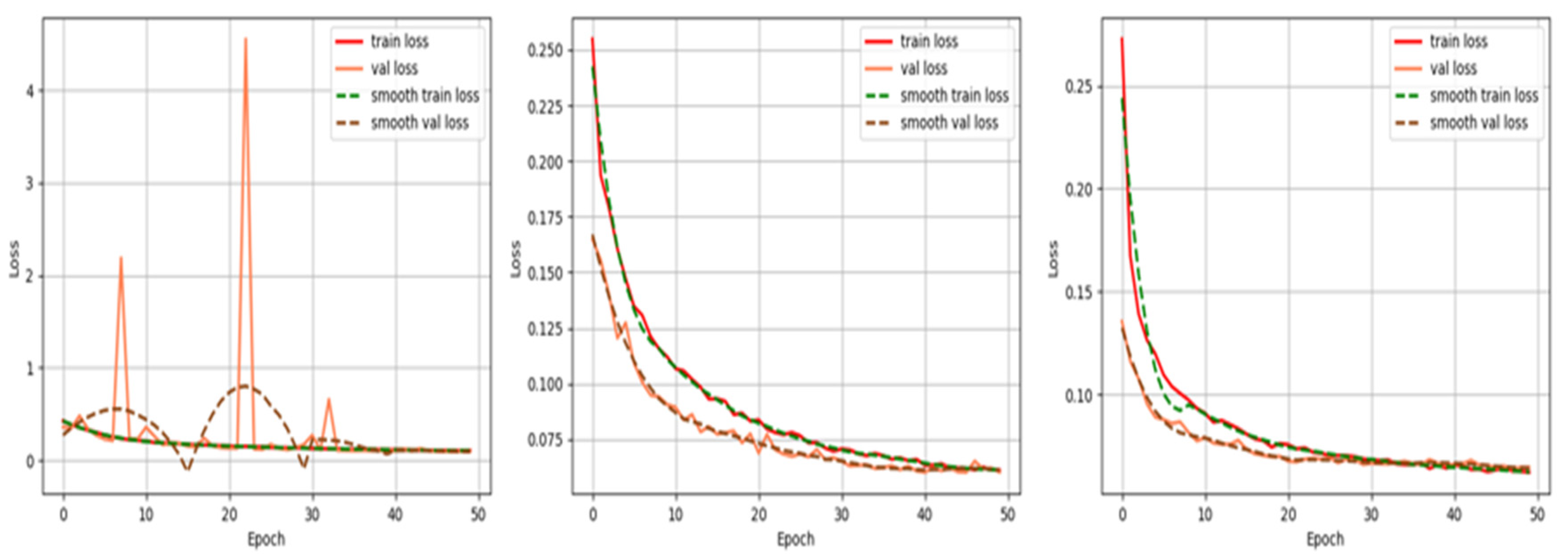
3.2. Implementation Details
3.3. Experimental Metrics
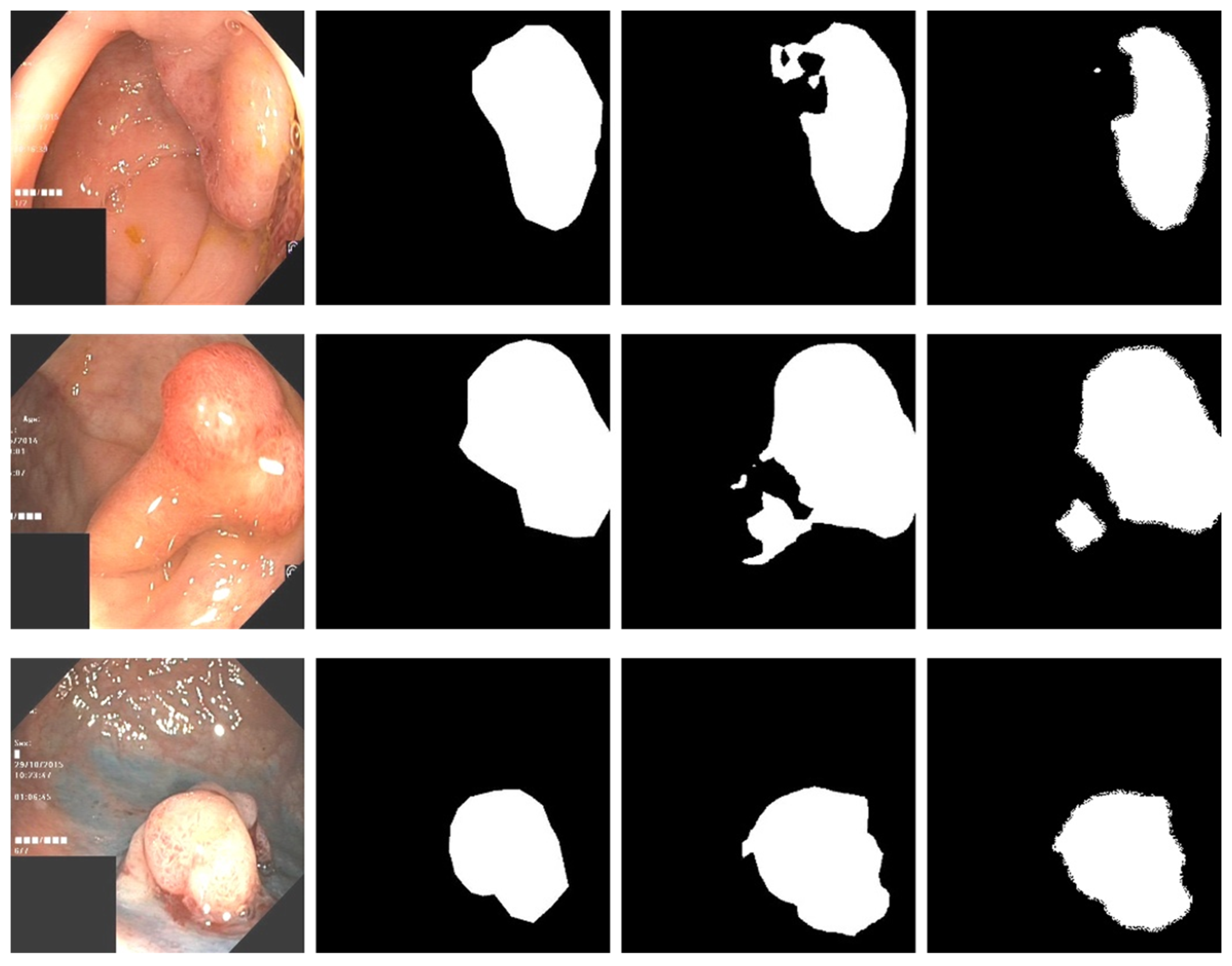
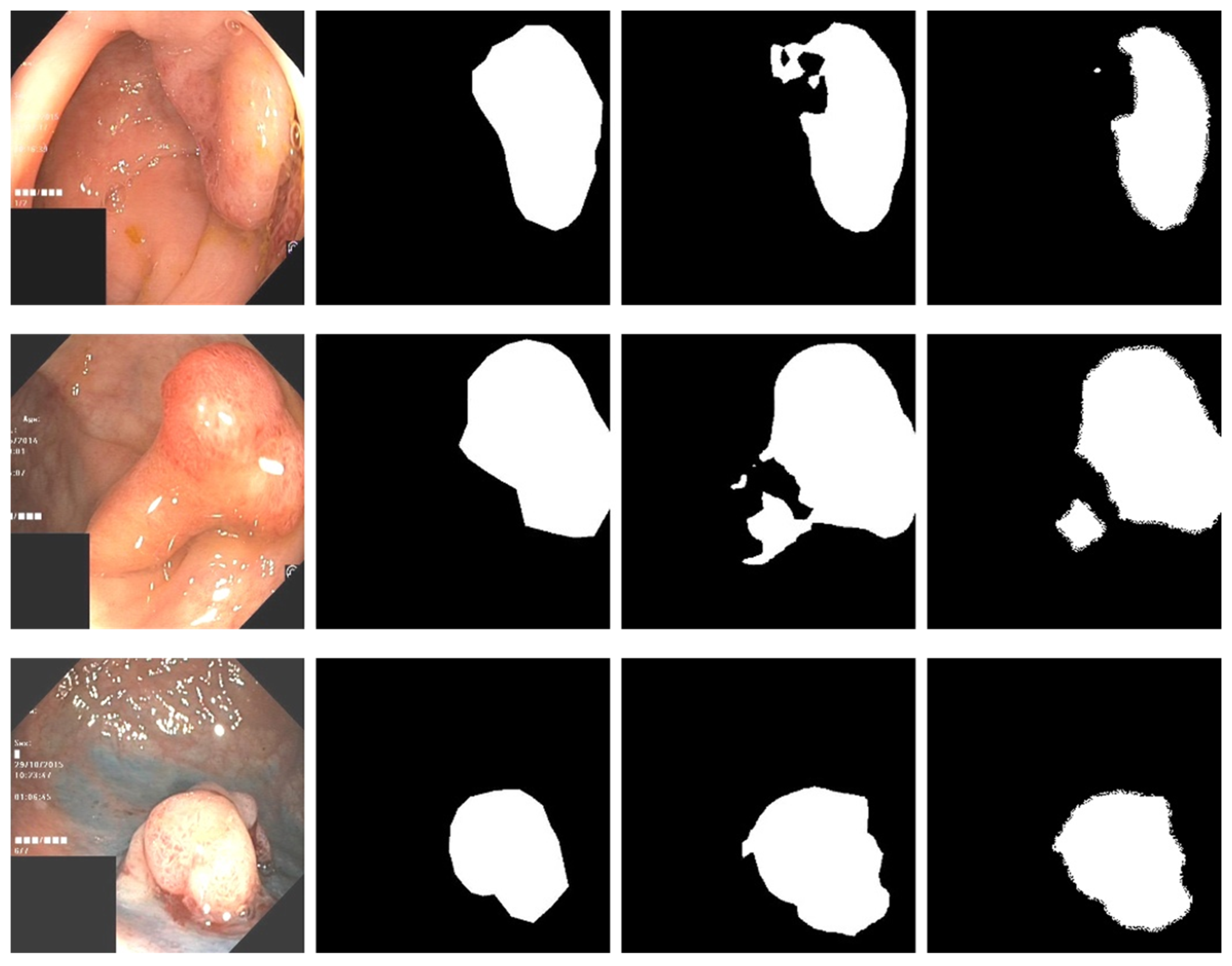
3.4. Experimental Results
4. Discussion
- (1)
- Integrating the parallel residual atrous pyramid module proposed in this paper into other polyp segmentation models to verify its enhancement of the model results.
- (2)
- Using a larger batch size and a smaller downsampling rate on a platform with more computing power for optimal training (the experiments in this paper were limited by the computing power of the machine).
- (3)
- Optimizing the model by referring to other excellent design concepts to achieve an improvement in performance.
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Zauber, A.G.; Winawer, S.J.; O’Brien, M.J.; Lansdorp-Vogelaar, I.; van Ballegooijen, M.; Hankey, B.F.; Shi, W.; Bond, J.H.; Schapiro, M.; Panish, J.F. Colonoscopic polypectomy and long-term prevention of colorectal-cancer deaths. N. Engl. J. Med. 2012, 366, 687–696. [Google Scholar] [CrossRef] [PubMed]
- Silva, J.; Histace, A.; Romain, O.; Dray, X.; Granado, B. Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer. Int. J. Comput. Assist. Radiol. Surg. 2014, 9, 283–293. [Google Scholar] [CrossRef] [PubMed]
- Van Rijn, J.C.; Reitsma, J.B.; Stoker, J.; Bossuyt, P.M.; Van Deventer, S.J.; Dekker, E. Polyp miss rate determined by tandem colonoscopy: A systematic review. Off. J. Am. Coll. Gastroenterol. 2006, 101, 343–350. [Google Scholar] [CrossRef]
- Winawer, S.J.; Zauber, A.G.; Ho, M.N.; O’Brien, M.J.; Gottlieb, L.S.; Sternberg, S.S.; Waye, J.D.; Schapiro, M.; Bond, J.H.; Panish, J.F.; et al. Prevention of colorectal cancer by colonoscopic polypectomy. N. Engl. J. Med. 1993, 329, 1977–1981. [Google Scholar] [CrossRef]
- Haggar, F.; Boushey, R. Colorectal cancer epidemiology: Incidence, mortality, survival, and risk factors. Clin. Colon Rectal Surg. 2009, 22, 191–197. [Google Scholar] [CrossRef] [Green Version]
- Kiesslich, R.; Burg, J.; Vieth, M.; Gnaendiger, J.; Enders, M.; Delaney, P.; Polglase, A.; Mclaren, W.; Janell, D.; Thomas, S.J.G. Confocal laser endoscopy for diagnosing intraepithelial neoplasias and colorectal cancer in vivo. Gastroenterology 2004, 127, 706–713. [Google Scholar] [CrossRef] [PubMed]
- Mori, Y.; Kudo, S.E. Detecting colorectal polyps via machine learning. Nat. Biomed. Eng. 2018, 2, 713–714. [Google Scholar] [CrossRef]
- Jia, X.; Xing, X.; Yuan, Y.; Xing, L.; Meng, Q.H. Wireless Capsule Endoscopy: A New Tool for Cancer Screening in the Colon with Deep-Learning-Based Polyp Recognition. Proc. IEEE 2019, 108, 178–197. [Google Scholar] [CrossRef]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse Attention for Salient Object Detection; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.M.; Zhao, Y.; Yan, S. Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6488–6496. [Google Scholar]
- Pogorelov, K.; Randel, K.R.; Griwodz, C.; Lange, T.D.; Halvorsen, P. KVASIR: A Multi-Class Image Dataset for Computer Aided Gastrointestinal Disease Detection. In Proceedings of the ACM on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; Johansen, H.D. Kvasir-SEG: A Segmented Polyp Dataset. In International Conference on Multimedia Modeling; Springer: Cham, Switzerland, 2020; pp. 451–462. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2017, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P.A. Integrating Online and Offline Three-Dimensional Deep Learning for Automated Polyp Detection in Colonoscopy Videos. IEEE J. Biomed. Health Inform. 2017, 21, 65–75. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; De Lange, T.; Halvorsen, P.; Johansen, H.D. ResUNet++: An Advanced Architecture for Medical Image Segmentation. In Proceedings of the IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; pp. 225–2255. [Google Scholar]
- Armato, S.G.; Petrick, N.A.; Brandao, P.; Mazomenos, E.; Ciuti, G.; Caliò, R.; Bianchi, F.; Menciassi, A.; Dario, P.; Koulaouzidis, A. Fully convolutional neural networks for polyp segmentation in colonoscopy. In Proceedings of the Medical Imaging 2017: Computer-Aided Diagnosis, Orlando, FL, USA, 13–16 February 2017. [Google Scholar]
- Akbari, M.; Mohrekesh, M.; Nasr-Esfahani, E.; Soroushmehr, S.; Karimi, N.; Samavi, S.; Najarian, K. Polyp Segmentation in Colonoscopy Images Using Fully Convolutional Network. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 69–72. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Ye, J.C. Framing U-Net via Deep Convolutional Framelets: Application to Sparse-View CT. IEEE Trans. Med. Imaging 2018, 37, 1418–1429. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saood, A.; Hatem, I.J. COVID-19 lung CT image segmentation using deep learning methods: U-Net versus SegNet. BMC Med. Imaging 2021, 21, 19. [Google Scholar] [CrossRef] [PubMed]
- Branch, M.; Carvalho, A.S. Polyp Segmentation in Colonoscopy Images using U-Net-MobileNetV2. arXiv 2021, arXiv:2103.15715. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wang, J.; Huang, Q.; Tang, F.; Meng, J.; Su, J.; Song, S. Stepwise Feature Fusion: Local Guides Global. arXiv 2022, arXiv:2203.03635. [Google Scholar]
- Zhang, Y.; Liu, H.; Hu, Q. TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 14–24. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef] [Green Version]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2018, 99, 52–58. [Google Scholar] [CrossRef]
- Xu, T.; Qiu, Z.; Das, W.; Wang, C.; Wang, Y.J.I. Deep Mouse: An End-to-End Auto-Context Refinement Framework for Brain Ventricle & Body Segmentation in Embryonic Mice Ultrasound Volumes. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Lafferty, J.; Mccallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object detectors emerge in Deep Scene CNNs. arXiv 2014, arXiv:1412.6856. [Google Scholar]
- Lou, A.; Guan, S.; Ko, H.; Loew, M. CaraNet: Context Axial Reverse Attention Network for Segmentation of Small Medical Objects. arXiv 2021, arXiv:2108.07368. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. PraNet: Parallel Reverse Attention Network for Polyp Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Swizerland, 2020; pp. 263–273. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Strength | Weakness |
|---|---|---|
| SFFormer-L [24] | These transformer-based models have the perceptual field of the entire image and can take advantage of global contextual information | These models are not as successful at acquiring local information as CNNs and do not take full advantage of the local information on different scales |
| TransFuse-L [25] | ||
| U-Net [14] | These models take full advantage of global contextual information and enhance the perception of local contextual information | These network models do not take into account the balance between global and multi-scale information and there is a large number of repetitive operations |
| U-Net++ [33] | ||
| ResUNet++ [17] | ||
| PraNet [34] | These two models fully exploit the edge information using the reverse attention mechanism, making the segmentation results appear with fine edges | These two network models mainly focus on the edge information of polyps and do not fully utilize the contextual information of different regions |
| CaraNet [32] | ||
| PRAPNet | The model proposed in this paper fully takes into account the global contextual information and multi-scale contextual information of different regions | Due to the use of a two-branch architecture in the proposed decoding module, additional computation may be added by channel redundancy |
| Learning Rate | Dice | mIoU | Precision |
|---|---|---|---|
| 1 × 10−3 | 0.901 | 0.856 | 0.902 |
| 1 × 10−4 | 0.942 | 0.901 | 0.934 |
| 1 × 10−5 | 0.942 | 0.904 | 0.936 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Xu, C.; An, Z.; Qian, K.; Tan, W.; Wang, D.; Fang, Q. PRAPNet: A Parallel Residual Atrous Pyramid Network for Polyp Segmentation. Sensors 2022, 22, 4658. https://doi.org/10.3390/s22134658
Han J, Xu C, An Z, Qian K, Tan W, Wang D, Fang Q. PRAPNet: A Parallel Residual Atrous Pyramid Network for Polyp Segmentation. Sensors. 2022; 22(13):4658. https://doi.org/10.3390/s22134658
Chicago/Turabian StyleHan, Jubao, Chao Xu, Ziheng An, Kai Qian, Wei Tan, Dou Wang, and Qianqian Fang. 2022. "PRAPNet: A Parallel Residual Atrous Pyramid Network for Polyp Segmentation" Sensors 22, no. 13: 4658. https://doi.org/10.3390/s22134658
APA StyleHan, J., Xu, C., An, Z., Qian, K., Tan, W., Wang, D., & Fang, Q. (2022). PRAPNet: A Parallel Residual Atrous Pyramid Network for Polyp Segmentation. Sensors, 22(13), 4658. https://doi.org/10.3390/s22134658