
A Novel Image Inpainting Method Used for Veneer Defects Based on Region Normalization


Abstract
:1. Introduction
- Taking into account the impact of spatial distribution on normalization, region normalization is introduced to divide pixels into different regions before calculating the mean and standard deviation of each area. Region normalization significantly enhances network performance.
- The HDC module is introduced to the detailed network to reconstruct the defective areas of the wood by changing the expansion rate, leading to a continuous texture with exquisite detail.
- The modified novel method in terms of validity and generativeness and demonstrate that the improved network can obtain satisfactory performance results in image inpainting and can not only restore the texture of veneers but also generate the defective regions of veneers.
2. Related Works
2.1. Image Inpainting
2.2. Normalization
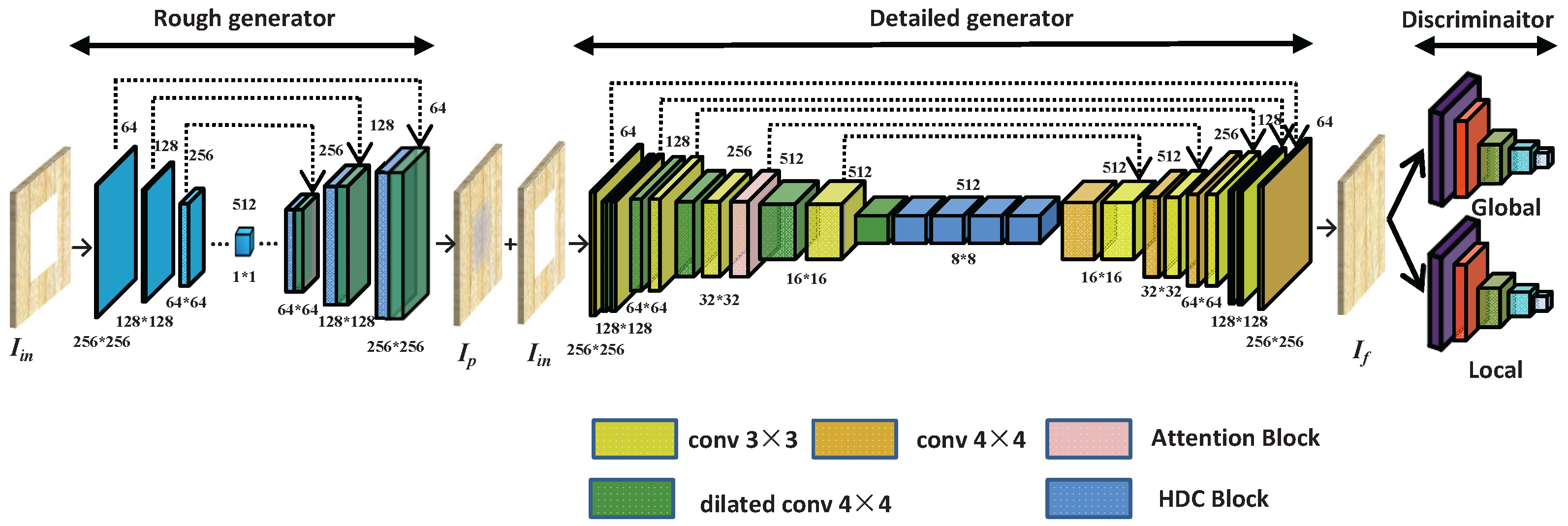
3. Approach
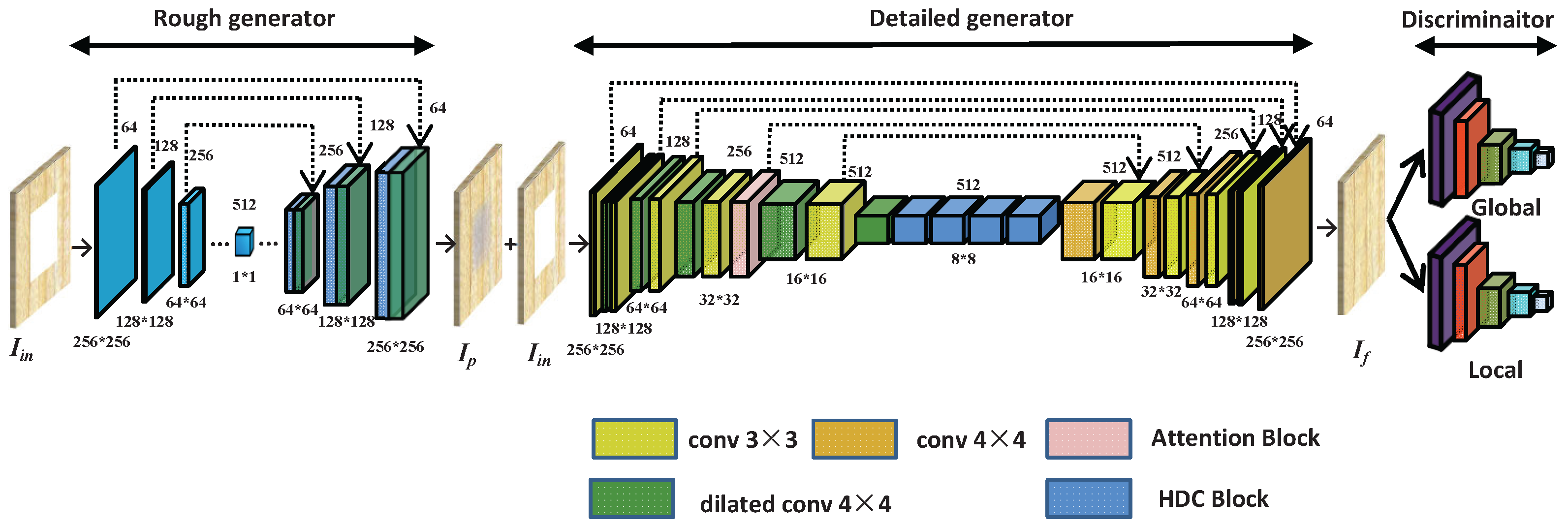
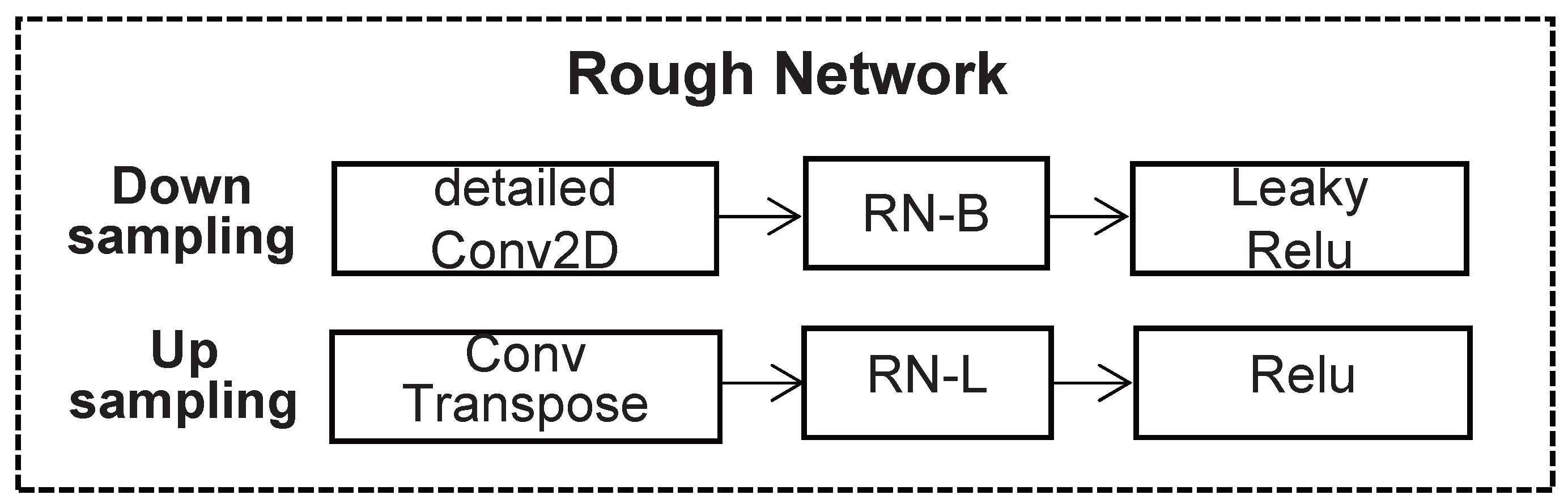
3.1. Rough Inpainting
3.2. Detailed Inpainting
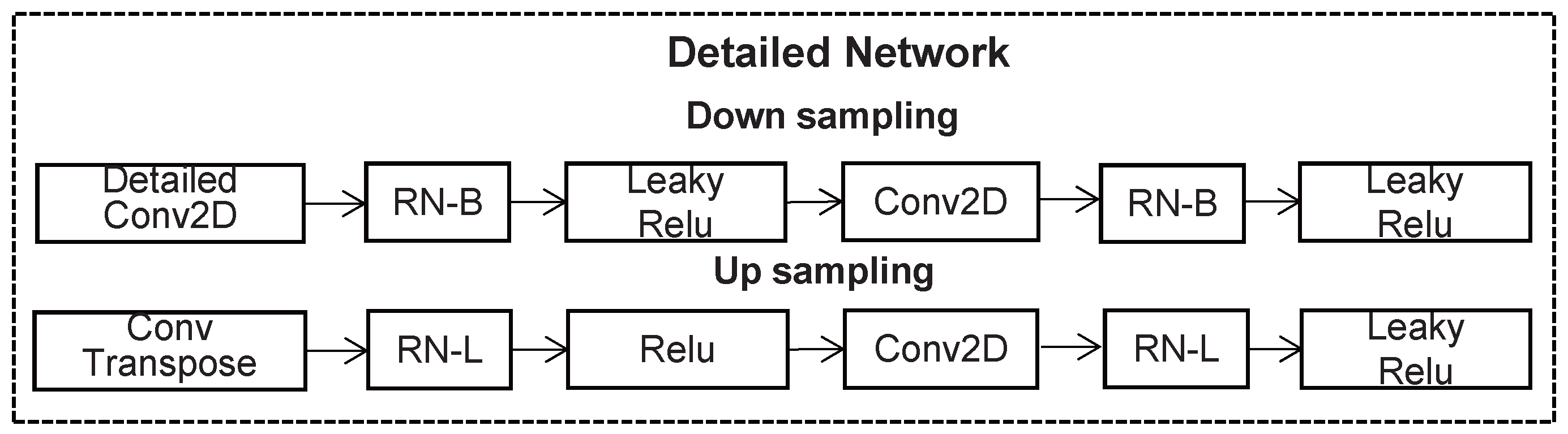
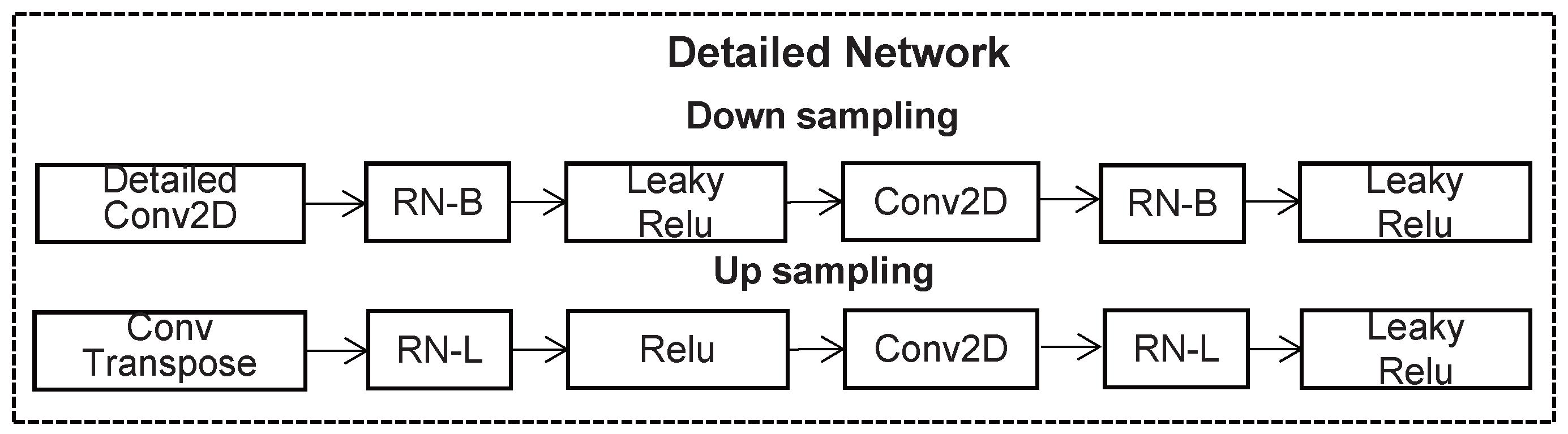
3.2.1. Detailed Network
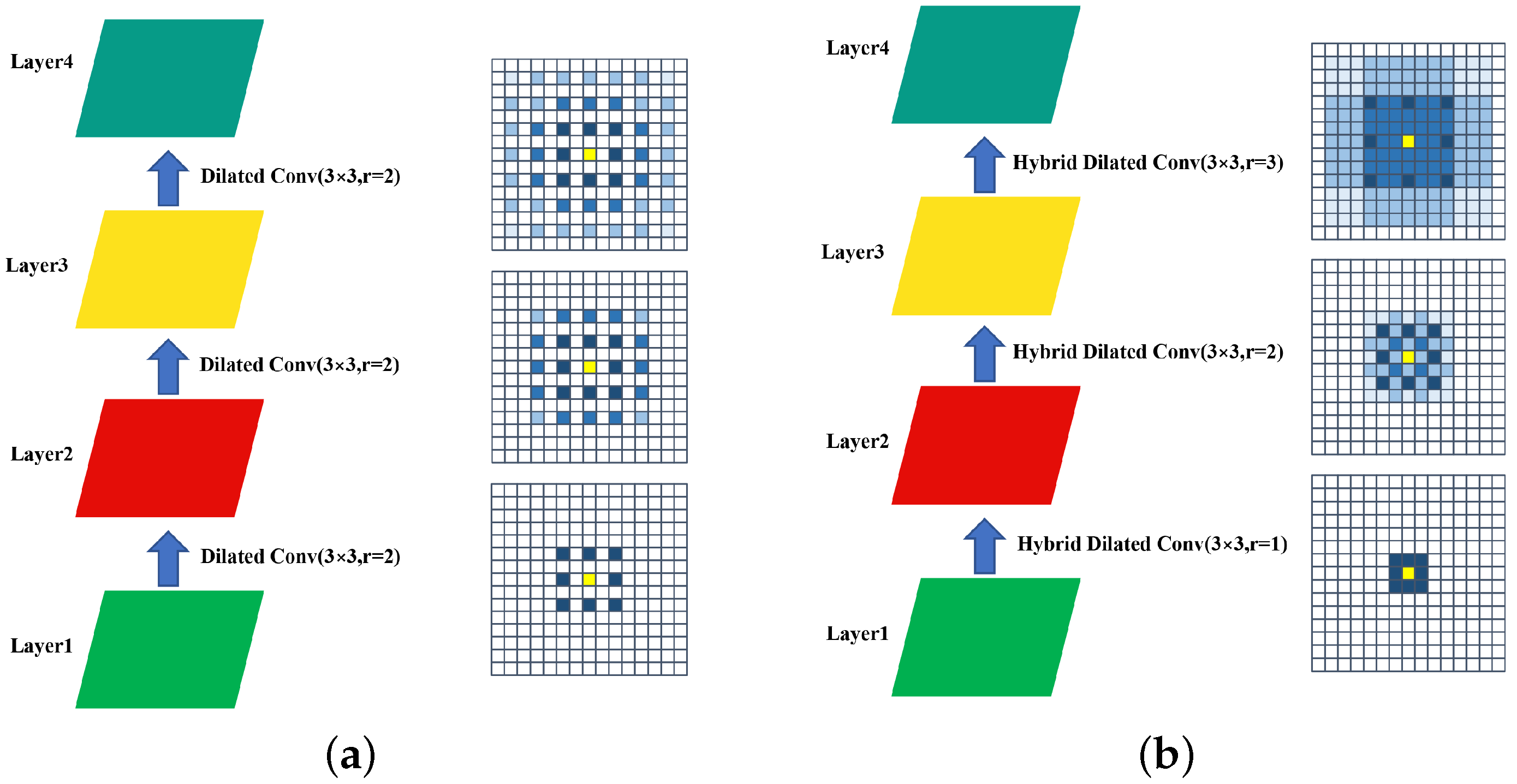
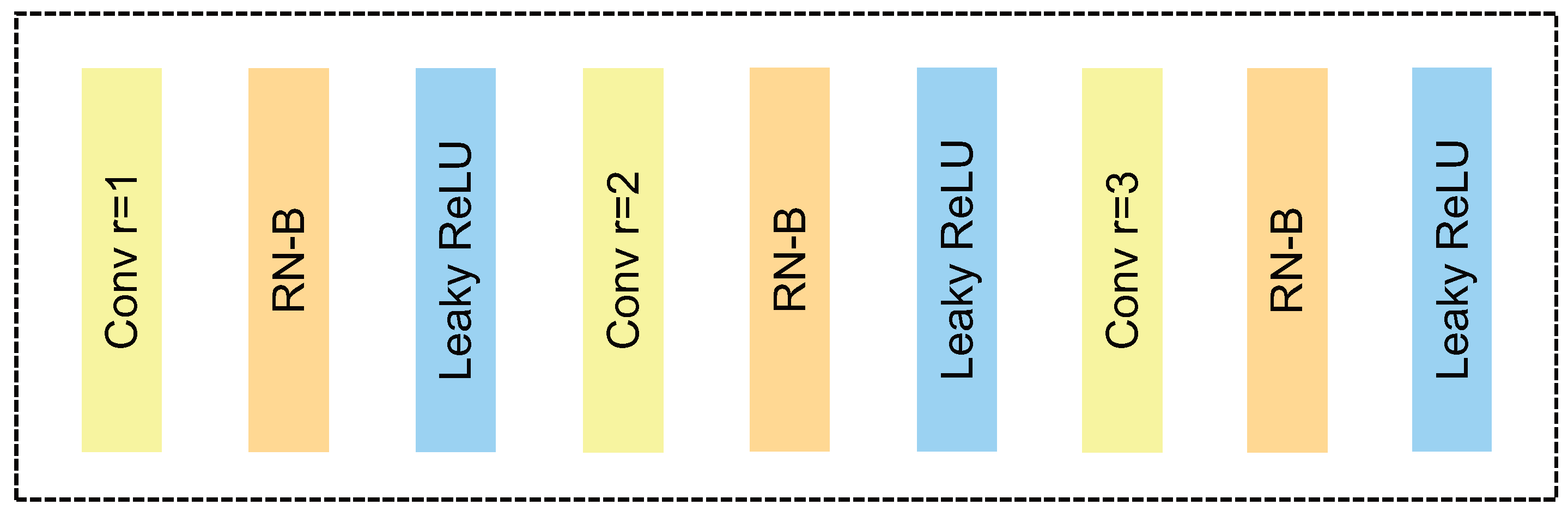
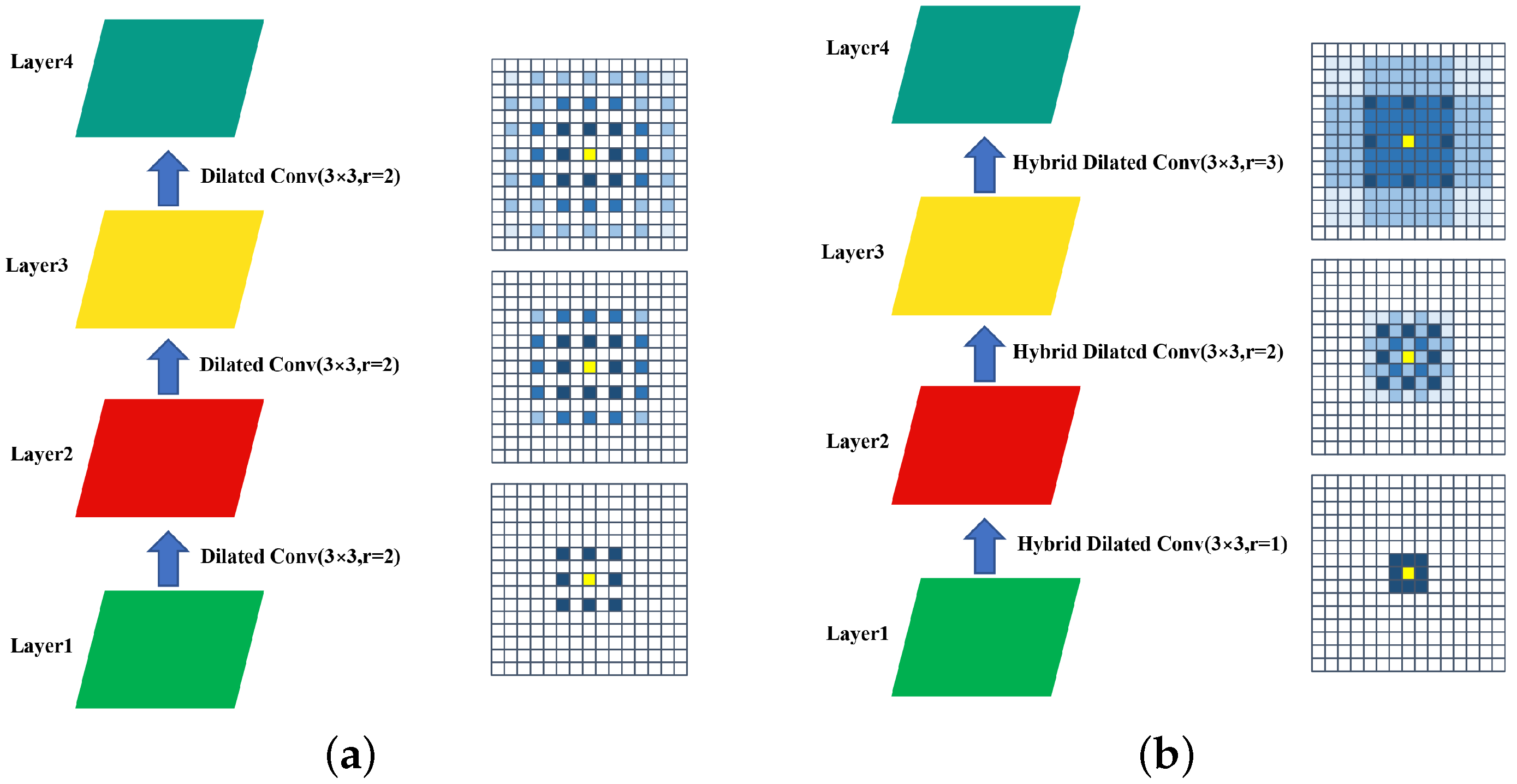
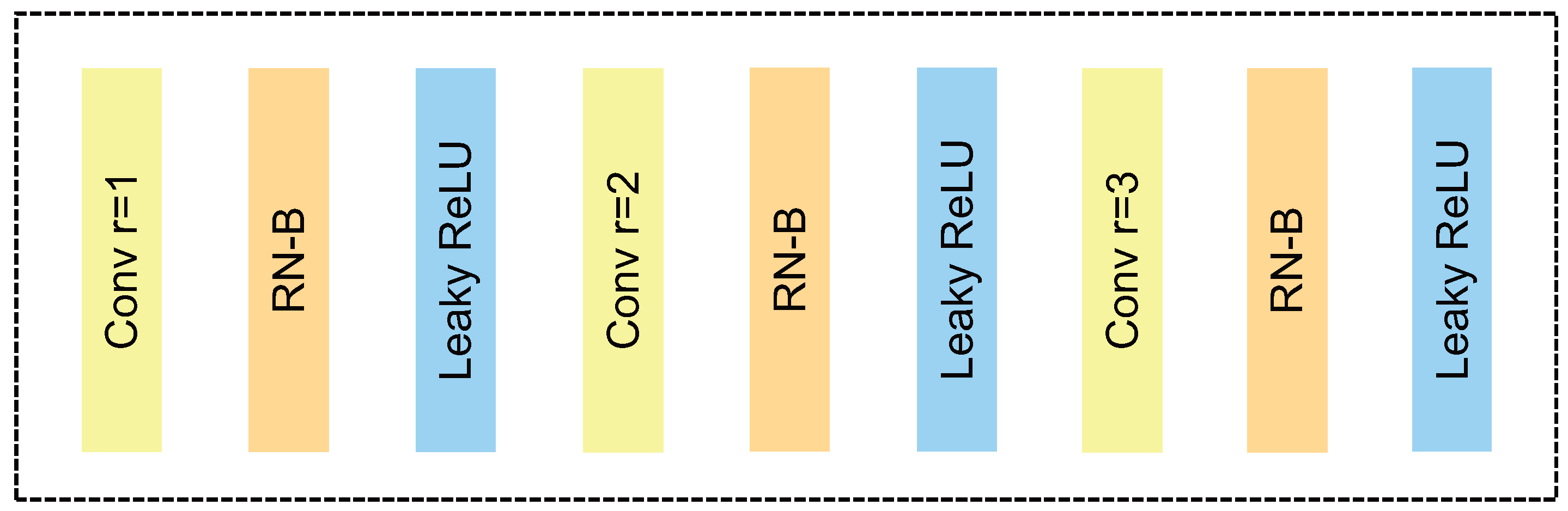
3.2.2. Hybrid Dilated Convolution
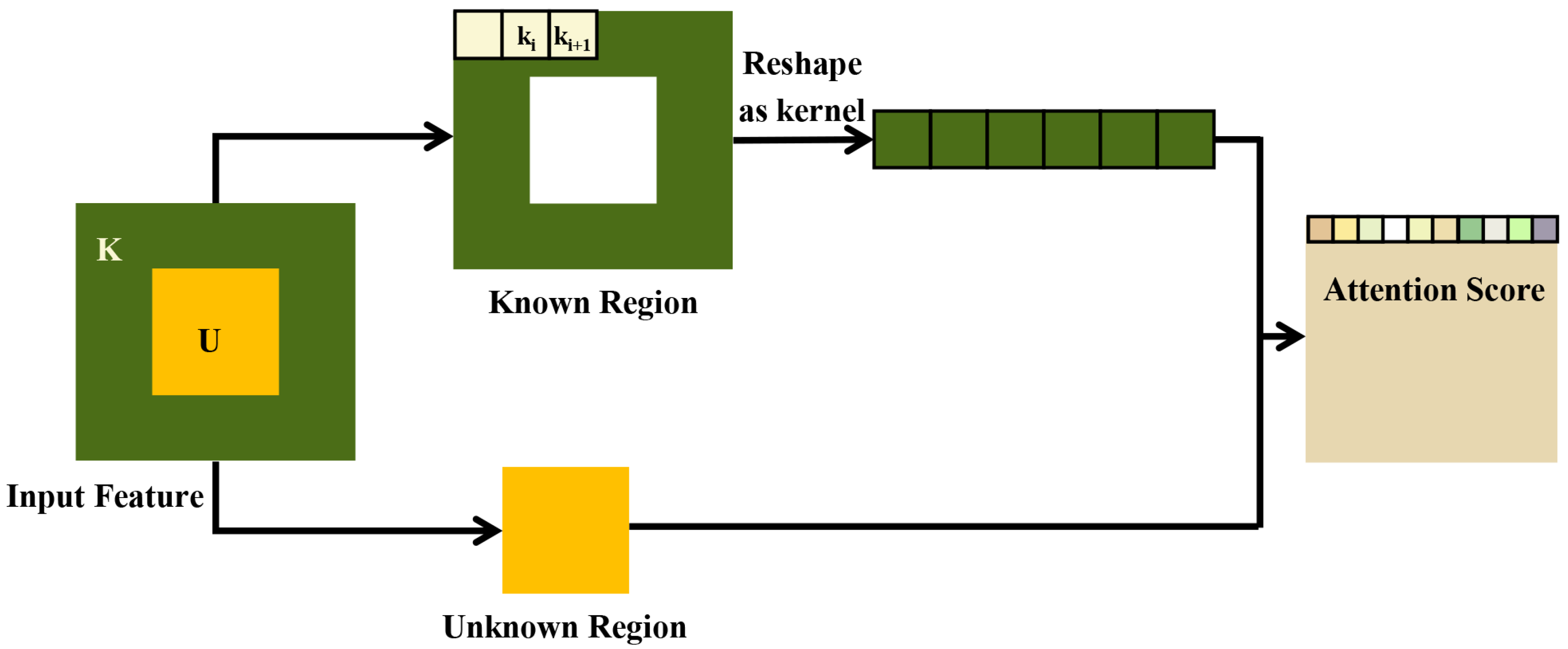
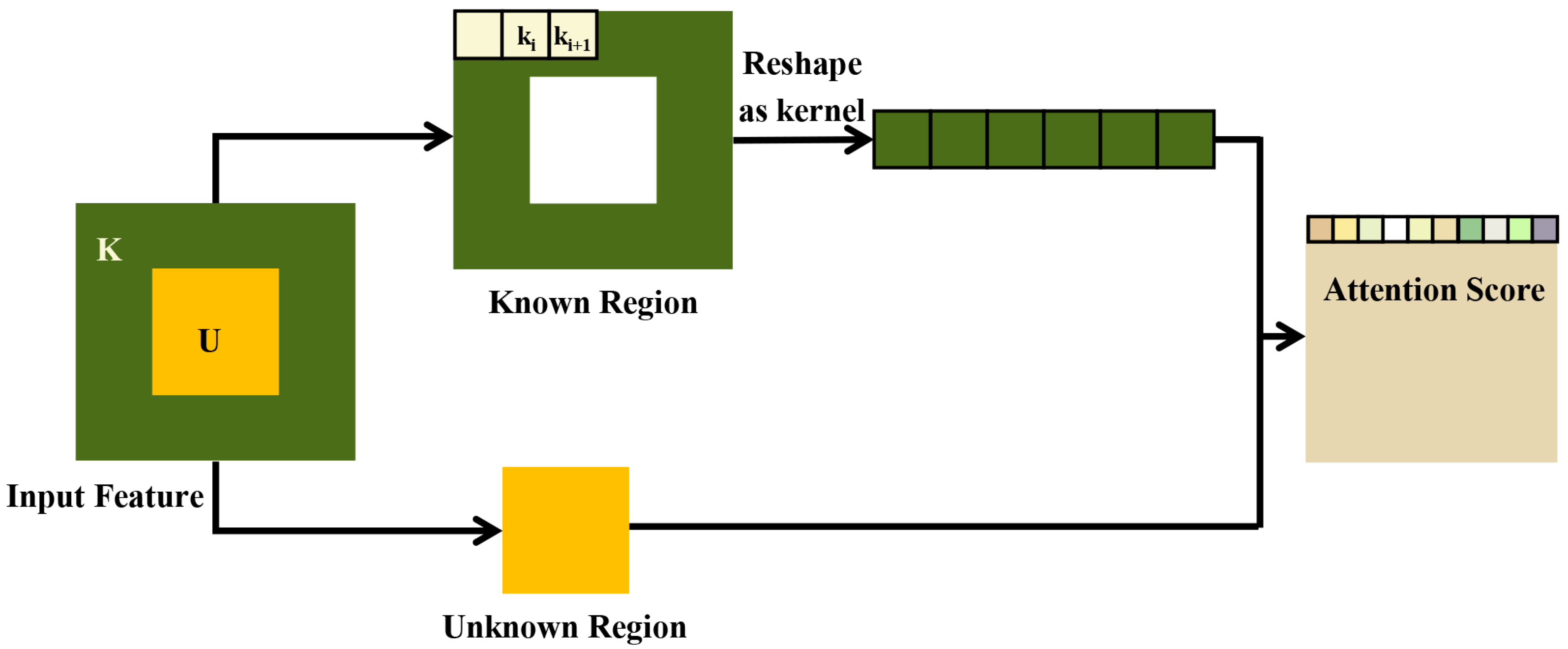
3.2.3. Attention Block
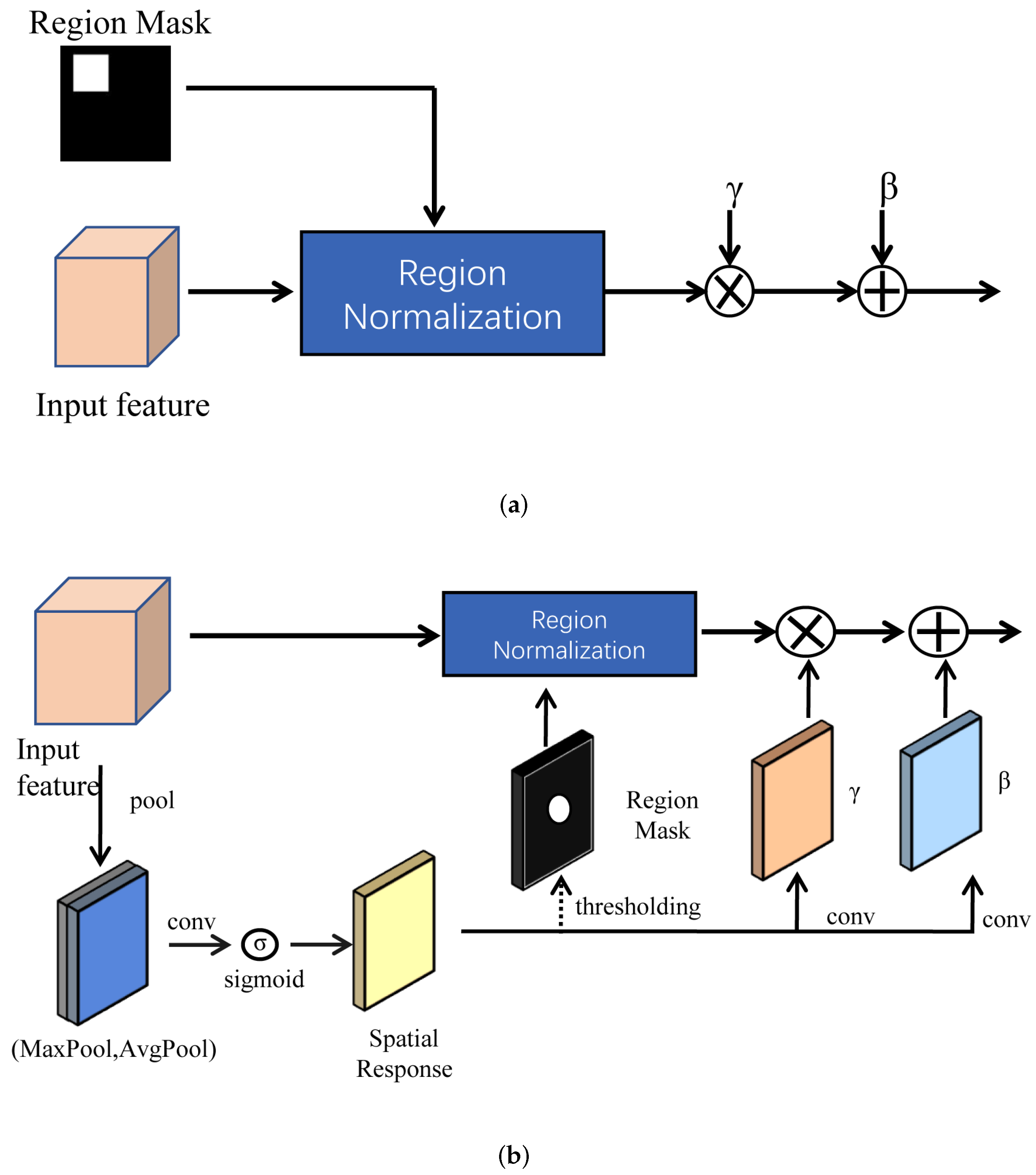
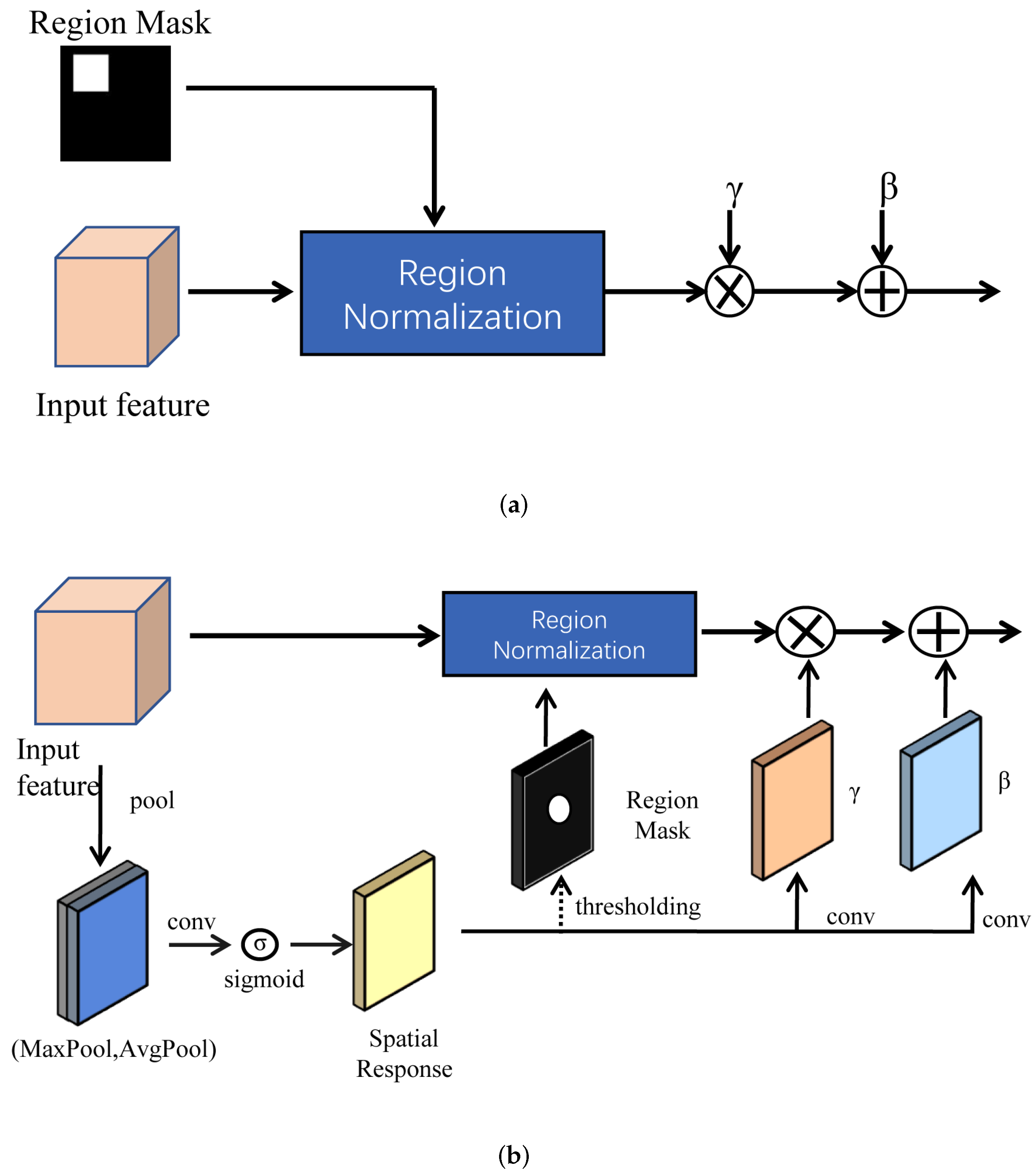
3.3. Region Normalization
3.4. Loss Functions
4. Results and Discussion
4.1. Analysis of Effectiveness Results
4.2. Analysis of Generative Results
4.3. Ablation Studies
4.3.1. The Effect of RN
4.3.2. The Effect of HDC Layer
4.4. Reconstruction Experiments on Defective Regions
4.4.1. Reconstruction on Veneer Defective Areas
4.4.2. Generation of Different Numbers of Defective Regions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| RN | Region Normalization |
| HDC | Hybrid Dilated Convolution |
| GAN | Generative Adversarial Network |
| BN | Batch Normalization |
| IN | Instance Normalization |
| RN-B | Basic Region Normalization |
| RN-L | Later Region Normalization |
| JS | Jensen-Shannon |
| WGAN-GP | Wasserstein GAN-Gradient Penalty |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
References
- Haseli, M.; Layeghi, M.; Hosseinabadi, H.Z. Characterization of Blockboard and Battenboard Sandwich Panels from Date Palm Waste Trunks. Measurement 2018, 124, 329–337. [Google Scholar] [CrossRef]
- Nazerian, M.; Moazami, V.; Farokhpayam, S.; Mohebbi Gargari, R. Production of blockboard from small athel slats end-glued by different type of joint. Maderas. Cienc. Y Tecnol. 2018, 20, 277–286. [Google Scholar] [CrossRef] [Green Version]
- Teixeira, D.; Melo, M. Effect of Battens Edge Bonding in the Properties of Blockboards Produced with Pinus sp. Recycled from Construction Sites. Asian J. Adv. Agric. Res. 2017, 4, 1–11. [Google Scholar] [CrossRef]
- Ding, F.; Zhuang, Z.; Liu, Y.; Jiang, D.; Yan, X.; Wang, Z. Detecting defects on solid wood panels based on an improved SSD algorithm. Sensors 2020, 20, 5315. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Liang, Y.; Liang, H.; Zhang, Y. Recognition of wood surface defects with near infrared spectroscopy and machine vision. J. For. Res. 2019, 30, 2379–2386. [Google Scholar] [CrossRef]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Wang, N.; Wang, W.; Hu, W.; Fenster, A.; Li, S. Thanka Mural Inpainting Based on Multi-scale Adaptive Partial Convolution and Stroke-like Mask. IEEE Trans. Image Process. 2021, 30, 3720–3733. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. (ToG) 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Van Noord, N.; Postma, E. Light-weight pixel context encoders for image inpainting. arXiv 2018, arXiv:1801.05585. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Zhu, X.; Qian, Y.; Zhao, X.; Sun, B.; Sun, Y. A deep learning approach to patch-based image inpainting forensics. Signal Process. Image Commun. 2018, 67, 90–99. [Google Scholar] [CrossRef]
- Wang, M.; Yan, B.; Ngan, K.N. An efficient framework for image/video inpainting. Signal Process. Image Commun. 2013, 28, 753–762. [Google Scholar] [CrossRef]
- Ding, D.; Ram, S.; Rodríguez, J.J. Image inpainting using nonlocal texture matching and nonlinear filtering. IEEE Trans. Image Process. 2018, 28, 1705–1719. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Yu, K.; Cheng, R.; Lakshmanan, L.V.; Lin, X. Efficient algorithms for densest subgraph discovery. arXiv 2019, arXiv:1906.00341. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wei, Y.; Yang, Z.; Wei, W. Image inpainting algorithm based on TV model and evolutionary algorithm. Soft Comput. 2016, 20, 885–893. [Google Scholar] [CrossRef]
- Song, L.; Cao, J.; Song, L.; Hu, Y.; He, R. Geometry-Aware Face Completion and Editing. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Palo Alto, CA, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Darabi, S.; Shechtman, E.; Barnes, C.; Goldman, D.B.; Sen, P. Image melding: Combining inconsistent images using patch-based synthesis. ACM Trans. Graph. (TOG) 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27—30 June 2016; pp. 2536–2544. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 9. [Google Scholar]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6721–6729. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Luo, P.; Ren, J.; Peng, Z.; Zhang, R.; Li, J. Differentiable learning-to-normalize via switchable normalization. arXiv 2018, arXiv:1806.10779. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 4905–4913. [Google Scholar]
- Yu, T.; Zongyu, G.; Jin, X.; Wu, S.; Chen, Z.; Li, W.; Zhang, Z.; Liu, S. Region Normalization for Image Inpainting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 34, pp. 12733–12740. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | GL | GntIpt | Ours |
|---|---|---|---|
| PSNR | 27.45 | 30.22 | 33.11 |
| SSIM | 0.86 | 0.90 | 0.93 |
| MSE | 0.11 | 0.059 | 0.049 |
| PSNR | SSIM | MSE | |
|---|---|---|---|
| 10–20% | 36.61 | 0.969 | 0.000218 |
| 20–30% | 33.26 | 0.937 | 0.000473 |
| 30–40% | 32.11 | 0.912 | 0.000615 |
| 40–50% | 29.05 | 0.901 | 0.001244 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, Y.; Chen, J.; Lou, Y.; Cui, M.; Zhou, H.; Zhou, H.; Sun, L. A Novel Image Inpainting Method Used for Veneer Defects Based on Region Normalization. Sensors 2022, 22, 4594. https://doi.org/10.3390/s22124594
Ge Y, Chen J, Lou Y, Cui M, Zhou H, Zhou H, Sun L. A Novel Image Inpainting Method Used for Veneer Defects Based on Region Normalization. Sensors. 2022; 22(12):4594. https://doi.org/10.3390/s22124594
Chicago/Turabian StyleGe, Yilin, Jiahao Chen, Yunyi Lou, Mingdi Cui, Hongju Zhou, Hongwei Zhou, and Liping Sun. 2022. "A Novel Image Inpainting Method Used for Veneer Defects Based on Region Normalization" Sensors 22, no. 12: 4594. https://doi.org/10.3390/s22124594
APA StyleGe, Y., Chen, J., Lou, Y., Cui, M., Zhou, H., Zhou, H., & Sun, L. (2022). A Novel Image Inpainting Method Used for Veneer Defects Based on Region Normalization. Sensors, 22(12), 4594. https://doi.org/10.3390/s22124594