
BPCNN: Bi-Point Input for Convolutional Neural Networks in Speaker Spoofing Detection



Abstract
:1. Introduction
- Proposing a bi-point input for CNN (BPCNN). It feeds a pair of two segments, rather than one segment, into a CNN at one time. The main advantage of BPCNN is to increase the amount of the available information at one time with hardly changing the CNN structure.
- Proposing various methods for combining the two segments in various levels: embedding-level combination, feature map-level combination, and two-channel input.
- Evaluating the performances of the proposed method in both logical and physical access tasks in various conditions and analyzing the effect and strength of the proposed method via the ablation studies.
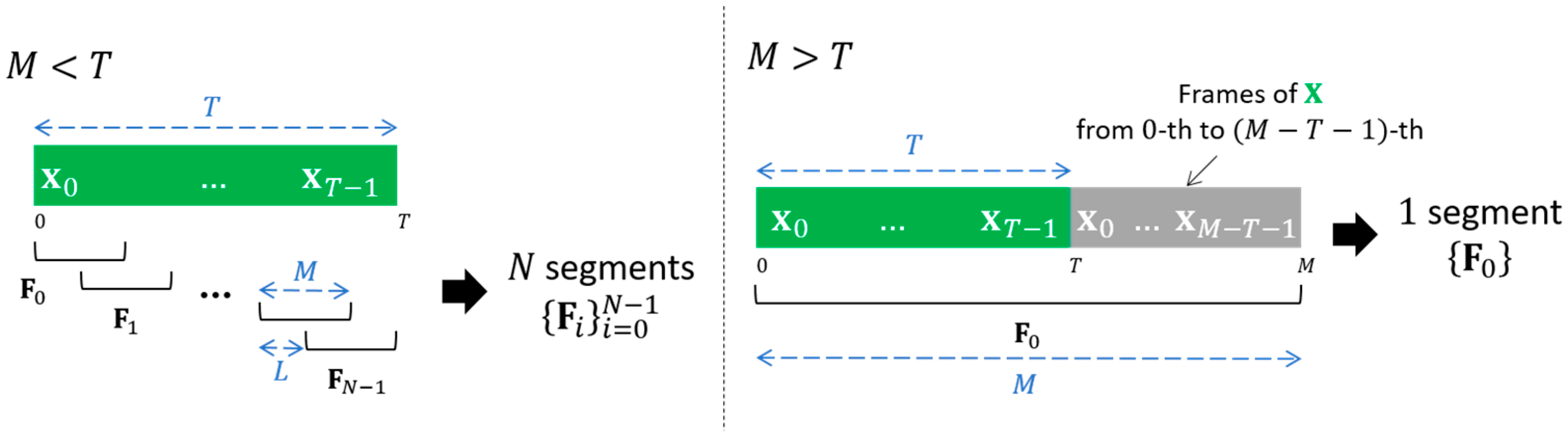
2. Conventional Feature Segmentation
| Algorithm 1 Pseudocode of Conventional Feature Segmentation | ||
| Input | ||
| : A feature with the length of | ||
| : The segment length | ||
| : The shift interval for segmentation | ||
| Output | ||
| : A list of the segments | ||
| 1. | if : | |
| 2. | # Empty list | |
| 3. | # The quotient | |
| 4. | # The remainder | |
| 5. | for to : | |
| 6. | # The -th segment | |
| 7. | ||
| 8. | if : | |
| 9. | # The last frames of | |
| 10. | ||
| 11. | return | |
| 12. | else if : | |
| 13. | # Set to have the length of | |
| 14. | return | |
| 15. | else: | # The case of |
| 16. | # itself becomes a segment | |
| 17. | return | |
3. The Proposed Method
3.1. Bidirectional Feature Segmentation
| Algorithm 2 Pseudocode of Bidirectional Feature Segmentation | ||
| Input | ||
| : A feature with the length of | ||
| : The flipped order of | ||
| : The segment length | ||
| : The shift interval for segmentation | ||
| Output | ||
| : A list of the segment pairs | ||
| 1. | if : | |
| 2. | # Empty list | |
| 3. | # The quotient | |
| 4. | # The remainder | |
| 5. | for to : | |
| 6. | # The -th forward segment | |
| 7. | # The -th backward segment | |
| 8. | ||
| 9. | if : | |
| 10. | # The last frames of | |
| 11. | # The last frames of | |
| 12. | ||
| 13. | return | |
| 14. | else if : | |
| 15. | # Set to have the length of | |
| 16. | # Set to have the length of | |
| 17. | return | |
| 18. | else: | # The case of |
| 19. | # itself becomes a forward segment | |
| 20. | # itself becomes a backward segment | |
| 21. | return | |
3.2. Bi-Point Input
3.2.1. Embedding-Level Combination
3.2.2. Feature Map-Level Combination
3.2.3. Two-Channel Input
3.2.4. Statistics-Level Combination
4. Experiments
4.1. Database
4.2. Experimental Setup
5. Results
5.1. Experimental Results and Discussion
5.2. Ablation Study
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. The Oracle Evaluation Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Method | LA | PA | ||||
|---|---|---|---|---|---|---|---|
| SE-ResNet | Baseline | 11.655 | 8.211 | 7.195 | 3.197 | 1.255 | 0.901 |
| concat | 10.156 | 7.967 | 7.956 | 2.127 | 0.708 | 1.007 | |
| vmax | 10.102 | 9.517 | 7.480 | 2.118 | 1.327 | 1.503 | |
| vmean | 10.605 | 9.081 | 8.226 | 2.599 | 1.156 | 1.526 | |
| fmax | 10.536 | 7.576 | 10.510 | 2.304 | 1.105 | 0.896 | |
| 2ch | 11.543 | 9.261 | 8.019 | 3.282 | 1.040 | 0.790 | |
| Fusion | 10.335 | 8.038 | 7.313 | 1.643 | 0.619 | 0.553 | |
| X-vector Network (TDNN) | Baseline | 13.680 | 8.157 | 5.830 | 8.297 | 3.538 | 1.408 |
| concat | 12.618 | 6.352 | 5.820 | 3.964 | 1.493 | 1.166 | |
| vmax | 11.013 | 6.741 | 7.396 | 3.936 | 1.027 | 1.028 | |
| vmean | 13.068 | 7.804 | 6.349 | 3.626 | 1.497 | 1.248 | |
| statc | 12.071 | 6.309 | 7.028 | 3.555 | 1.581 | 1.156 | |
| Fusion | 10.428 | 6.171 | 5.112 | 1.879 | 0.885 | 0.768 | |
| DenseNet | Baseline | 10.986 | 9.095 | 7.127 | 2.675 | 1.360 | 0.702 |
| concat | 10.129 | 6.868 | 6.378 | 1.393 | 0.542 | 0.557 | |
| vmax | 8.484 | 6.717 | 6.841 | 1.116 | 0.719 | 0.492 | |
| vmean | 10.075 | 7.981 | 7.699 | 1.708 | 0.564 | 0.469 | |
| fmax | 9.762 | 7.628 | 6.881 | 1.470 | 0.702 | 0.493 | |
| 2ch | 9.966 | 7.828 | 6.497 | 2.510 | 0.796 | 0.486 | |
| Fusion | 8.688 | 5.901 | 5.626 | 0.763 | 0.392 | 0.276 | |
| MobileNetV2 | Baseline | 9.939 | 7.695 | 7.507 | 4.223 | 1.885 | 0.785 |
| concat | 8.513 | 6.067 | 7.775 | 2.593 | 1.398 | 0.878 | |
| vmax | 8.987 | 7.439 | 5.138 | 2.769 | 2.150 | 0.714 | |
| vmean | 9.029 | 7.533 | 7.599 | 2.587 | 1.847 | 0.967 | |
| fmax | 9.720 | 6.186 | 5.806 | 2.029 | 1.371 | 0.874 | |
| 2ch | 9.669 | 6.242 | 8.279 | 3.344 | 0.935 | 0.692 | |
| Fusion | 7.017 | 5.748 | 4.961 | 1.664 | 1.006 | 0.510 | |
| ShuffleNetV2 | Baseline | 17.919 | 7.303 | 6.744 | 4.374 | 2.102 | 1.283 |
| concat | 12.101 | 6.609 | 6.812 | 2.102 | 0.885 | 0.790 | |
| vmax | 14.004 | 7.032 | 7.939 | 2.102 | 0.823 | 0.691 | |
| vmean | 15.892 | 6.405 | 6.637 | 2.366 | 0.869 | 0.696 | |
| fmax | 12.397 | 7.454 | 8.840 | 2.123 | 1.061 | 0.768 | |
| 2ch | 15.309 | 8.786 | 6.706 | 3.444 | 1.227 | 0.951 | |
| Fusion | 10.904 | 6.578 | 5.695 | 1.542 | 0.579 | 0.485 | |
| MNASNet | Baseline | 9.384 | 6.092 | 8.064 | 4.019 | 2.224 | 0.857 |
| concat | 8.554 | 6.080 | 9.680 | 3.097 | 0.774 | 0.614 | |
| vmax | 8.403 | 5.398 | 5.682 | 3.384 | 0.818 | 0.526 | |
| vmean | 9.027 | 5.384 | 5.970 | 2.935 | 0.923 | 0.525 | |
| fmax | 8.539 | 4.840 | 7.709 | 3.185 | 0.846 | 0.525 | |
| 2ch | 8.403 | 6.840 | 7.575 | 3.582 | 1.039 | 0.452 | |
| Fusion | 6.839 | 4.690 | 5.998 | 2.188 | 0.542 | 0.321 | |
References
- Wu, Z.; Kinnunen, T.; Evans, N.; Yamagishi, J.; Hanilci, C.; Sahidullah, M.; Sizov, A. ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 1–5. [Google Scholar]
- Kinnunen, T.; Sahidullah, M.; Delgado, H.; Todisco, M.; Evans, N.; Yamagishi, J.; Lee, K.A. The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 1–6. [Google Scholar]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: Future horizons in spoofed and fake audio detection. arXiv 2019, arXiv:1904.05441. [Google Scholar]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 47–54. [Google Scholar]
- Kamble, M.R.; Patil, H.A. Novel energy separation based instantaneous frequency features for spoof speech detection. In Proceedings of the 2017 25th European Signal Processing Conference, Kos, Greece, 26 October 2017; pp. 106–110. [Google Scholar]
- Yoon, S.-H.; Koh, M.-S.; Park, J.-H.; Yu, H.-J. A new replay attack against automatic speaker verification systems. IEEE Access 2020, 8, 36080–36088. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Yoon, S.; Yu, H.-J. Multiple-point input and time-inverted speech signal for the ASVspoof 2021 challenge. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 37–41. [Google Scholar]
- Tomilov, A.; Svishchev, A.; Volkova, M.; Chirkovskiy, A.; Kondratev, A.; Lavrentyeva, G. STC antispoofing systems for the ASVspoof2021 challenge. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 61–67. [Google Scholar]
- Chen, X.; Zhang, Y.; Zhu, G.; Duan, Z. UR channel-robust synthetic speech detection system for ASVspoof 2021. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 75–82. [Google Scholar]
- Benhafid, Z.; Selouani, S.A.; Yakoub, M.S.; Amrouche, A. LARIHS ASSERT reassessment for logical access ASVspoof 2021 challenge. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 94–99. [Google Scholar]
- LeCun, Y.; Bottou, A.; Orr, G.B.; Muller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Lai, C.; Abad, A.; Richmond, K.; Yamagishi, J.; Dehak, N.; King, S. Attentive filtering networks for audio replay attack detection. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6316–6320. [Google Scholar]
- Wang, H.; Dinkel, H.; Wang, S.; Qian, Y.; Yu, K. Cross-domain replay spoofing attack detection using domain adversarial training. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2938–2942. [Google Scholar]
- Yoon, S.-H.; Yu, H.-J. A simple distortion-free method to handle variable length sequences for recurrent neural networks in text dependent speaker verification. Appl. Sci. 2020, 10, 4092. [Google Scholar] [CrossRef]
- Cai, W.; Wu, H.; Cai, D.; Li, M. The DKU replay detection system for the ASVspoof 2019 challenge: On data augmentation, feature representation, classification, and fusion. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1023–1027. [Google Scholar]
- Lavrentyeva, G.; Novoselov, S.; Tseren, A.; Volkova, M.; Gorlanov, A.; Kozlov, A. STC antispoofing systems for the ASVspoof2019 challenge. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1033–1037. [Google Scholar]
- Alzantot, M.; Wang, Z.; Srivastava, M.B. Deep residual neural networks for audio spoofing detection. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1078–1082. [Google Scholar]
- Wu, H.; Liu, S.; Meng, H.; Lee, H. Defense against adversarial attacks on spoofing countermeasures of ASV. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6564–6568. [Google Scholar]
- von Platen, P.; Tao, F.; Tur, G. Multi-task Siamese neural network for improving replay attack detection. In Proceedings of the Interspeech, Shanghai, China, 26–29 October 2020; pp. 1076–1080. [Google Scholar]
- Parasu, P.; Epps, J.; Sriskandaraja, K.; Suthokumar, G. Investigating Light-ResNet architecture for spoofing detection under mismatched conditions. In Proceedings of the Interspeech, Shanghai, China, 26–29 October 2020; pp. 1111–1115. [Google Scholar]
- Monteiro, J.; Alam, J.; Falk, T.H. A multi-condition training strategy for countermeasures against spoofing attacks to speaker recognizers. In Proceedings of the Odyssey Speaker Language Recognition Workshop, Tokyo, Japan, 1–5 November 2020; pp. 296–303. [Google Scholar]
- Halpern, B.M.; Kelly, F.; van Son, R.; Alexander, A. Residual networks for resisting noise: Analysis of an embedding-based spoofing countermeasures. In Proceedings of the Odyssey Speaker Language Recognition Workshop, Tokyo, Japan, 1–5 November 2020; pp. 326–332. [Google Scholar]
- Chettri, B.; Kinnunen, T.; Benetos, E. Subband modeling for spoofing detection in automatic speaker verification. In Proceedings of the Odyssey Speaker Language Recognition Workshop, Tokyo, Japan, 1–5 November 2020; pp. 341–348. [Google Scholar]
- Cai, W.; Chen, J.; Zhang, J.; Li, M. On-the-fly data loader and utterance-level aggregation for speaker and language recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1038–1051. [Google Scholar] [CrossRef]
- Lai, C.; Chen, N.; Villalba, J.; Dehak, N. ASSERT: Anti-spoofing with squeeze-excitation and residual networks. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1013–1017. [Google Scholar]
- Yoon, S.-H.; Yu, H.-J. Multiple points input for convolutional neural networks in replay attack detection. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6444–6448. [Google Scholar]
- Wang, Q.; Lee, K.A.; Koshinaka, T. Using multi-resolution feature maps with convolutional neural networks for anti-spoofing in ASV. In Proceedings of the Odyssey Speaker Language Recognition Workshop, Tokyo, Japan, 1–5 November 2020; pp. 138–142. [Google Scholar]
- Yoon, S.-H.; Koh, M.-S.; Yu, H.-J. Phase spectrum of time-flipped speech signals for robust spoofing detection. In Proceedings of the Odyssey Speaker Language Recognition Workshop, Tokyo, Japan, 1–5 November 2020; pp. 319–325. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 770–778. [Google Scholar]
- Schuster, M.; Paliwai, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Snyder, D.; Garcia-Romeo, D.; Shell, G.; Povey, D.; Khudanpur, S. Deep neural network embeddings for text-independent speaker verification. In Proceedings of the Interspeech, 2017, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- Snyder, D.; Garcia-Romeo, D.; Shell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust DNN embeddings for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, AL, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Comput. Speech Lang. 2020, 64, 101114. [Google Scholar] [CrossRef]
- Sahidullah, M.; Kinnunen, T.; Hanilci, C. A comparison of features for synthetic speech detection. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 1–6. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Automatic Speech Recognition and Understanding (ASRU) Workshop, Waikoloa, HI, USA, 11–15 December 2011; pp. 1–4. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-aware neural architectures search for mobile. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of Adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, L.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS 2017 Workshop Autodiff Submission, Long Beach, CA, USA, 9 December 2017. [Google Scholar]




| Model | Method | LA | PA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dev. | Eval. | Dev. | Eval. | Dev. | Eval. | Dev. | Eval. | Dev. | Eval. | Dev. | Eval. | ||
| SE-ResNet | Baseline | 0 | 14.099 | 0 | 10.388 | 0 | 12.551 | 2.152 | 3.197 | 0.811 | 1.255 | 0.519 | 0.985 |
| concat | 0 | 15.486 | 0 | 11.148 | 0 | 9.410 | 1.261 | 2.641 | 0.370 | 0.945 | 0.612 | 1.007 | |
| vmax | 0 | 13.635 | 0 | 12.157 | 0 | 10.633 | 1.279 | 2.118 | 0.704 | 1.327 | 0.998 | 1.975 | |
| vmean | 0 | 13.637 | 0 | 9.081 | 0 | 12.211 | 1.573 | 3.300 | 0.593 | 1.337 | 0.926 | 1.702 | |
| fmax | 0 | 15.812 | 0 | 9.868 | 0 | 13.353 | 1.388 | 2.875 | 0.534 | 1.105 | 0.484 | 0.934 | |
| 2ch | 0 | 13.923 | 0 | 11.434 | 0 | 12.498 | 2.538 | 4.378 | 0.597 | 1.063 | 0.316 | 0.912 | |
| Fusion | 0 | 13.131 | 0 | 9.001 | 0 | 10.236 | 0.737 | 1.940 | 0.261 | 0.653 | 0.168 | 0.614 | |
| X-vector Network (TDNN) | Baseline | 0.009 | 17.321 | 0 | 13.395 | 0 | 6.947 | 3.965 | 8.297 | 1.797 | 3.538 | 0.908 | 1.664 |
| concat | 0.009 | 15.690 | 0 | 7.900 | 0 | 6.718 | 1.762 | 3.964 | 0.667 | 1.520 | 0.834 | 1.366 | |
| vmax | 0 | 14.750 | 0.002 | 8.171 | 0 | 8.811 | 1.296 | 3.936 | 0.721 | 1.072 | 0.721 | 1.056 | |
| vmean | 0.082 | 16.558 | 0 | 11.081 | 0 | 7.763 | 2.170 | 3.897 | 0.797 | 1.708 | 0.856 | 1.520 | |
| statc | 0.040 | 16.927 | 0 | 8.620 | 0.002 | 12.143 | 2.037 | 3.892 | 0.926 | 1.752 | 0.797 | 1.156 | |
| Fusion | 0.004 | 14.451 | 0 | 8.389 | 0 | 8.552 | 0.628 | 2.205 | 0.444 | 0.950 | 0.610 | 0.902 | |
| DenseNet | Baseline | 0 | 16.232 | 0 | 10.130 | 0 | 9.818 | 2.296 | 3.155 | 0.850 | 1.360 | 0.337 | 0.713 |
| concat | 0 | 12.120 | 0 | 7.139 | 0 | 11.405 | 0.854 | 1.593 | 0.353 | 0.658 | 0.296 | 0.580 | |
| vmax | 0 | 11.109 | 0 | 10.744 | 0 | 8.743 | 0.700 | 1.116 | 0.366 | 0.857 | 0.222 | 0.492 | |
| vmean | 0 | 12.509 | 0 | 12.628 | 0 | 12.158 | 1.090 | 1.708 | 0.296 | 0.564 | 0.238 | 0.476 | |
| fmax | 0 | 14.279 | 0 | 14.535 | 0 | 11.828 | 0.630 | 1.609 | 0.333 | 0.845 | 0.242 | 0.508 | |
| 2ch | 0 | 13.963 | 0 | 9.258 | 0 | 11.951 | 2.164 | 2.798 | 0.370 | 0.956 | 0.226 | 0.542 | |
| Fusion | 0 | 11.027 | 0 | 7.410 | 0 | 10.023 | 0.444 | 0.885 | 0.148 | 0.425 | 0.129 | 0.303 | |
| MobileNetV2 | Baseline | 0 | 19.511 | 0 | 11.299 | 0 | 8.292 | 2.667 | 4.666 | 1.076 | 2.233 | 0.409 | 0.785 |
| concat | 0 | 13.584 | 0 | 8.307 | 0 | 10.414 | 1.649 | 3.466 | 0.667 | 1.597 | 0.386 | 0.878 | |
| vmax | 0 | 12.794 | 0 | 10.223 | 0 | 8.767 | 1.333 | 3.217 | 1.022 | 2.206 | 0.279 | 0.872 | |
| vmean | 0 | 12.387 | 0 | 8.280 | 0 | 10.416 | 1.185 | 2.996 | 0.799 | 1.873 | 0.501 | 1.039 | |
| fmax | 0 | 13.433 | 0 | 9.950 | 0 | 8.768 | 1.076 | 3.228 | 0.756 | 1.592 | 0.388 | 0.928 | |
| 2ch | 0 | 14.167 | 0 | 10.727 | 0 | 8.537 | 1.889 | 4.533 | 0.337 | 0.962 | 0.279 | 0.901 | |
| Fusion | 0 | 10.809 | 0 | 7.815 | 0 | 8.363 | 0.741 | 2.387 | 0.407 | 0.978 | 0.185 | 0.520 | |
| ShuffleNetV2 | Baseline | 0 | 20.479 | 0 | 11.748 | 0 | 11.051 | 4.170 | 4.374 | 1.392 | 2.255 | 0.904 | 1.382 |
| concat | 0 | 13.664 | 0 | 9.433 | 0 | 8.849 | 1.240 | 2.161 | 0.462 | 0.917 | 0.388 | 0.867 | |
| vmax | 0 | 19.443 | 0 | 10.265 | 0 | 10.007 | 1.146 | 2.102 | 0.503 | 0.823 | 0.388 | 0.746 | |
| vmean | 0 | 17.975 | 0 | 9.705 | 0 | 9.912 | 1.390 | 2.366 | 0.335 | 0.869 | 0.353 | 0.696 | |
| fmax | 0 | 18.204 | 0 | 9.571 | 0 | 10.048 | 1.094 | 2.123 | 0.514 | 1.128 | 0.412 | 0.779 | |
| 2ch | 0.002 | 19.798 | 0 | 10.472 | 0.038 | 9.764 | 2.168 | 3.737 | 0.739 | 1.260 | 0.593 | 0.951 | |
| Fusion | 0 | 13.923 | 0 | 8.744 | 0 | 8.620 | 0.760 | 1.581 | 0.279 | 0.603 | 0.207 | 0.492 | |
| MNASNet | Baseline | 0 | 19.050 | 0 | 10.608 | 0 | 11.205 | 2.263 | 5.052 | 0.834 | 2.232 | 0.353 | 0.995 |
| concat | 0 | 11.652 | 0 | 10.249 | 0 | 11.624 | 1.207 | 3.570 | 0.255 | 0.912 | 0.370 | 0.614 | |
| vmax | 0 | 17.362 | 0 | 11.895 | 0 | 11.107 | 1.630 | 4.416 | 0.353 | 1.156 | 0.168 | 0.718 | |
| vmean | 0 | 14.333 | 0 | 7.207 | 0 | 8.863 | 1.316 | 4.388 | 0.279 | 1.321 | 0.164 | 0.685 | |
| fmax | 0 | 15.894 | 0 | 7.570 | 0 | 11.327 | 1.037 | 3.642 | 0.316 | 0.969 | 0.152 | 0.615 | |
| 2ch | 0 | 17.933 | 0 | 9.341 | 0 | 10.331 | 1.540 | 3.687 | 0.409 | 1.238 | 0.240 | 0.857 | |
| Fusion | 0 | 13.705 | 0 | 7.029 | 0 | 9.463 | 0.663 | 2.732 | 0.148 | 0.636 | 0.094 | 0.359 | |
| Model | Method | LA | PA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Proposed | ST | Proposed | ST | ||||||
| Dev. | Eval. | Dev. | Eval. | Dev. | Eval. | Dev. | Eval. | ||
| SE-ResNet | concat | 0 | 7.967 | 0 | 8.484 | 0.370 | 0.708 | 1.329 | 1.835 |
| vmax | 0 | 9.517 | 0 | 8.989 | 0.704 | 1.327 | 0.983 | 1.520 | |
| vmean | 0 | 9.081 | 0 | 9.012 | 0.593 | 1.156 | 0.945 | 1.414 | |
| fmax | 0 | 7.576 | 0 | 8.893 | 0.534 | 1.105 | 1.238 | 1.913 | |
| 2ch | 0 | 9.261 | 0 | 7.941 | 0.597 | 1.040 | 1.403 | 1.896 | |
| average | 0 | 8.680 | 0 | 8.664 | 0.560 | 1.067 | 1.180 | 1.716 | |
| X-vector Network (TDNN) | concat | 0 | 6.352 | 0 | 8.267 | 0.667 | 1.493 | 1.760 | 3.108 |
| vmax | 0.002 | 6.741 | 0.004 | 8.674 | 0.721 | 1.027 | 1.630 | 2.665 | |
| vmean | 0 | 7.804 | 0 | 10.524 | 0.797 | 1.497 | 1.817 | 3.814 | |
| statc | 0 | 6.309 | 0 | 9.488 | 0.926 | 1.581 | 1.630 | 2.924 | |
| average | 0.001 | 6.802 | 0.001 | 9.238 | 0.778 | 1.400 | 1.709 | 3.128 | |
| DenseNet | concat | 0 | 6.868 | 0 | 6.472 | 0.353 | 0.542 | 0.908 | 1.194 |
| vmax | 0 | 6.717 | 0 | 6.499 | 0.366 | 0.719 | 1.133 | 1.414 | |
| vmean | 0 | 7.981 | 0 | 7.108 | 0.296 | 0.564 | 1.148 | 1.587 | |
| fmax | 0 | 7.628 | 0 | 5.944 | 0.333 | 0.702 | 0.908 | 1.332 | |
| 2ch | 0 | 7.828 | 0 | 7.548 | 0.370 | 0.796 | 0.737 | 0.961 | |
| average | 0 | 7.404 | 0 | 6.714 | 0.344 | 0.665 | 0.967 | 1.298 | |
| MobileNetV2 | concat | 0 | 6.067 | 0 | 6.717 | 0.667 | 1.398 | 1.004 | 2.034 |
| vmax | 0 | 7.439 | 0 | 5.710 | 1.022 | 2.150 | 0.595 | 1.731 | |
| vmean | 0 | 7.533 | 0 | 8.239 | 0.799 | 1.847 | 1.037 | 2.311 | |
| fmax | 0 | 6.186 | 0 | 6.172 | 0.756 | 1.371 | 0.815 | 1.979 | |
| 2ch | 0 | 6.242 | 0 | 7.738 | 0.337 | 0.935 | 0.980 | 2.217 | |
| average | 0 | 6.693 | 0 | 6.915 | 0.716 | 1.540 | 0.886 | 2.054 | |
| ShuffleNetV2 | concat | 0 | 6.609 | 0 | 9.166 | 0.462 | 0.885 | 1.649 | 1.924 |
| vmax | 0 | 7.032 | 0 | 6.564 | 0.503 | 0.823 | 1.630 | 2.299 | |
| vmean | 0 | 6.405 | 0 | 7.136 | 0.335 | 0.869 | 1.353 | 2.278 | |
| fmax | 0 | 7.454 | 0 | 7.330 | 0.514 | 1.061 | 1.294 | 1.869 | |
| 2ch | 0 | 8.786 | 0 | 8.144 | 0.739 | 1.227 | 1.702 | 2.846 | |
| average | 0 | 7.257 | 0 | 7.668 | 0.511 | 0.973 | 1.526 | 2.243 | |
| MNASNet | concat | 0 | 6.080 | 0 | 6.079 | 0.255 | 0.774 | 0.908 | 1.974 |
| vmax | 0 | 5.398 | 0 | 5.452 | 0.353 | 0.818 | 0.651 | 1.951 | |
| vmean | 0 | 5.384 | 0 | 7.098 | 0.279 | 0.923 | 0.963 | 2.427 | |
| fmax | 0 | 4.840 | 0 | 4.756 | 0.316 | 0.846 | 0.776 | 2.095 | |
| 2ch | 0 | 6.840 | 0 | 6.349 | 0.409 | 1.039 | 0.926 | 2.869 | |
| average | 0 | 5.708 | 0 | 5.947 | 0.322 | 0.880 | 0.845 | 2.263 | |
| Model | Method | LA | PA | ||
|---|---|---|---|---|---|
| Dev. | Eval. | Dev. | Eval. | ||
| SE-ResNet | Baseline | 0 | 8.211 | 0.811 | 1.255 |
| BO | 0 | 8.347 | 1.279 | 1.763 | |
| Augment | 0 | 7.940 | 1.316 | 2.443 | |
| Proposed | 0 | 8.680 | 0.560 | 1.067 | |
| X-vector Network (TDNN) | Baseline | 0 | 8.157 | 1.797 | 3.538 |
| BO | 0 | 9.557 | 1.464 | 2.858 | |
| Augment | 0 | 10.415 | 1.595 | 4.145 | |
| Proposed | 0 | 6.802 | 0.778 | 1.400 | |
| DenseNet | Baseline | 0 | 9.095 | 0.850 | 1.360 |
| BO | 0 | 6.705 | 1.131 | 1.581 | |
| Augment | 0 | 6.947 | 1.094 | 1.713 | |
| Proposed | 0 | 7.404 | 0.344 | 0.776 | |
| MobileNetV2 | Baseline | 0 | 7.695 | 1.076 | 1.885 |
| BO | 0 | 7.791 | 0.945 | 1.763 | |
| Augment | 0 | 7.043 | 0.926 | 2.521 | |
| Proposed | 0 | 6.693 | 0.716 | 1.540 | |
| ShuffleNetV2 | Baseline | 0 | 7.303 | 1.392 | 2.102 |
| BO | 0 | 8.985 | 1.514 | 2.024 | |
| Augment | 0 | 6.293 | 1.499 | 2.549 | |
| Proposed | 0 | 7.257 | 0.511 | 0.973 | |
| MNASNet | Baseline | 0 | 6.092 | 0.834 | 2.224 |
| BO | 0 | 6.960 | 0.834 | 2.100 | |
| Augment | 0 | 7.400 | 0.867 | 2.632 | |
| Proposed | 0 | 5.708 | 0.322 | 0.880 | |
| Model | Method | LA | PA | ||
|---|---|---|---|---|---|
| Dev. | Eval. | Dev. | Eval. | ||
| SE-ResNet | 2ch | 0 | 9.261 | 0.597 | 1.040 |
| 2ch_s | 0 | 8.226 | 0.996 | 1.731 | |
| DenseNet | 2ch | 0 | 7.828 | 0.370 | 0.796 |
| 2ch_s | 0 | 9.257 | 1.203 | 1.527 | |
| MobileNetV2 | 2ch | 0 | 6.242 | 0.337 | 0.935 |
| 2ch_s | 0 | 8.267 | 0.869 | 1.863 | |
| ShuffleNetV2 | 2ch | 0 | 8.786 | 0.739 | 1.227 |
| 2ch_s | 0 | 7.775 | 1.538 | 1.958 | |
| MNASNet | 2ch | 0 | 6.840 | 0.409 | 1.039 |
| 2ch_s | 0 | 8.620 | 0.869 | 1.885 | |
| Model | Method | LA | PA | ||
|---|---|---|---|---|---|
| Dev. | Eval. | Dev. | Eval. | ||
| SE-ResNet | Baseline | 0 | 8.211 | 0.811 | 1.255 |
| OTF | 0 | 9.626 | 1.292 | 1.787 | |
| Proposed | 0 | 8.680 | 0.560 | 1.067 | |
| X-vector Network (TDNN) | Baseline | 0 | 8.157 | 1.797 | 3.538 |
| OTF | 0.002 | 8.158 | 1.723 | 3.455 | |
| Proposed | 0 | 6.802 | 0.778 | 1.400 | |
| DenseNet | Baseline | 0 | 9.095 | 0.850 | 1.360 |
| OTF | 0 | 7.162 | 1.111 | 1.393 | |
| Proposed | 0 | 7.404 | 0.344 | 0.776 | |
| MobileNetV2 | Baseline | 0 | 7.695 | 1.076 | 1.885 |
| OTF | 0 | 7.163 | 1.111 | 2.498 | |
| Proposed | 0 | 6.693 | 0.716 | 1.540 | |
| ShuffleNetV2 | Baseline | 0 | 7.303 | 1.392 | 2.102 |
| OTF | 0 | 10.200 | 1.589 | 2.493 | |
| Proposed | 0 | 7.257 | 0.511 | 0.973 | |
| MNASNet | Baseline | 0 | 6.092 | 0.834 | 2.224 |
| OTF | 0 | 5.914 | 0.996 | 2.709 | |
| Proposed | 0 | 5.708 | 0.322 | 0.880 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, S.; Yu, H.-J. BPCNN: Bi-Point Input for Convolutional Neural Networks in Speaker Spoofing Detection. Sensors 2022, 22, 4483. https://doi.org/10.3390/s22124483
Yoon S, Yu H-J. BPCNN: Bi-Point Input for Convolutional Neural Networks in Speaker Spoofing Detection. Sensors. 2022; 22(12):4483. https://doi.org/10.3390/s22124483
Chicago/Turabian StyleYoon, Sunghyun, and Ha-Jin Yu. 2022. "BPCNN: Bi-Point Input for Convolutional Neural Networks in Speaker Spoofing Detection" Sensors 22, no. 12: 4483. https://doi.org/10.3390/s22124483
APA StyleYoon, S., & Yu, H.-J. (2022). BPCNN: Bi-Point Input for Convolutional Neural Networks in Speaker Spoofing Detection. Sensors, 22(12), 4483. https://doi.org/10.3390/s22124483