
An Efficient Automatic Fruit-360 Image Identification and Recognition Using a Novel Modified Cascaded-ANFIS Algorithm


Abstract
:1. Introduction
2. Related Works
- The studies required expensive sensors such as weight, dew, heat, chemical, gas-sensitive, and infrared light to model the classification.
- The classifiers are only capable of recognizing a few types of fruits, not the whole Fruit-360 dataset.
- The system performance is insufficient, owing primarily to closely related texture, color, and shape properties.
- The classification precision falls short of the standards for typical applications.
- The algorithms required a higher computational power.
- This study proposes a novel structure for the Cascaded-ANFIS algorithm for image classification.
- The system is designed using nine state-of-the-art feature descriptors (including Color Structure (CS), Region Shape (RS), Edge Histogram (EH), Column Layout (CL), Gray-Level Co-Occurrence Matrix (GLCM), Scale-Invariant Feature Transform (SIFT), Speeded Up Robust Features (SURF), Histogram of Oriented Gradients (HOG), and Oriented FAST and rotated BRIEF features (ORB)).
- The total dataset of 131 classes is used for the classification.
- The novel system can reduce the dimension input to different features due to the usage of the feature reduction method.
- Comparison of the accuracy with the state-of-the-art algorithms (including CNN with Stochastic Gradient Descent with Momentum, CNN with Adaptive Moment Estimation, CNN with RMS propagation, Customized Inception V3, Customized VGG 16, Customized MobileNet, Vanilla MobileNet, ShufeNet V2, DCNN, and ResNet18).
- The comparative computational power is relatively inexpensive while providing an accuracy up to 98.36%.
3. Proposed Methodology
3.1. The Fruit-360 Dataset
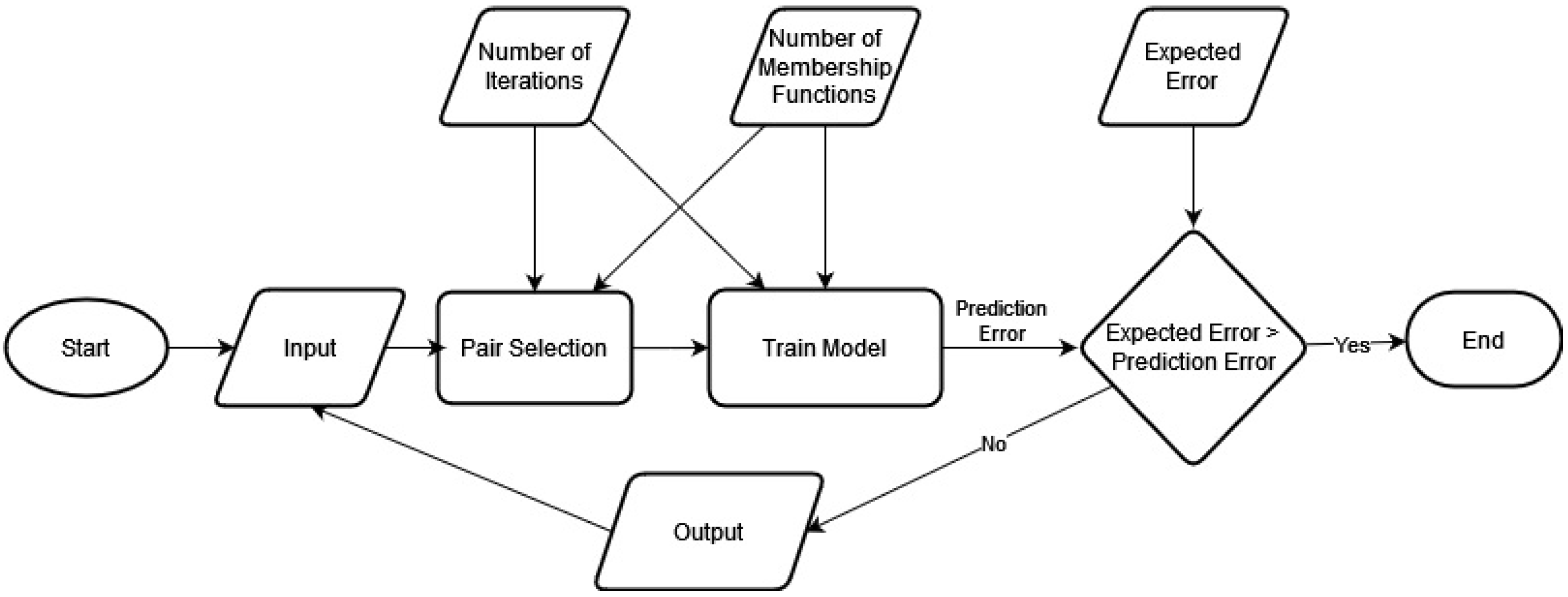
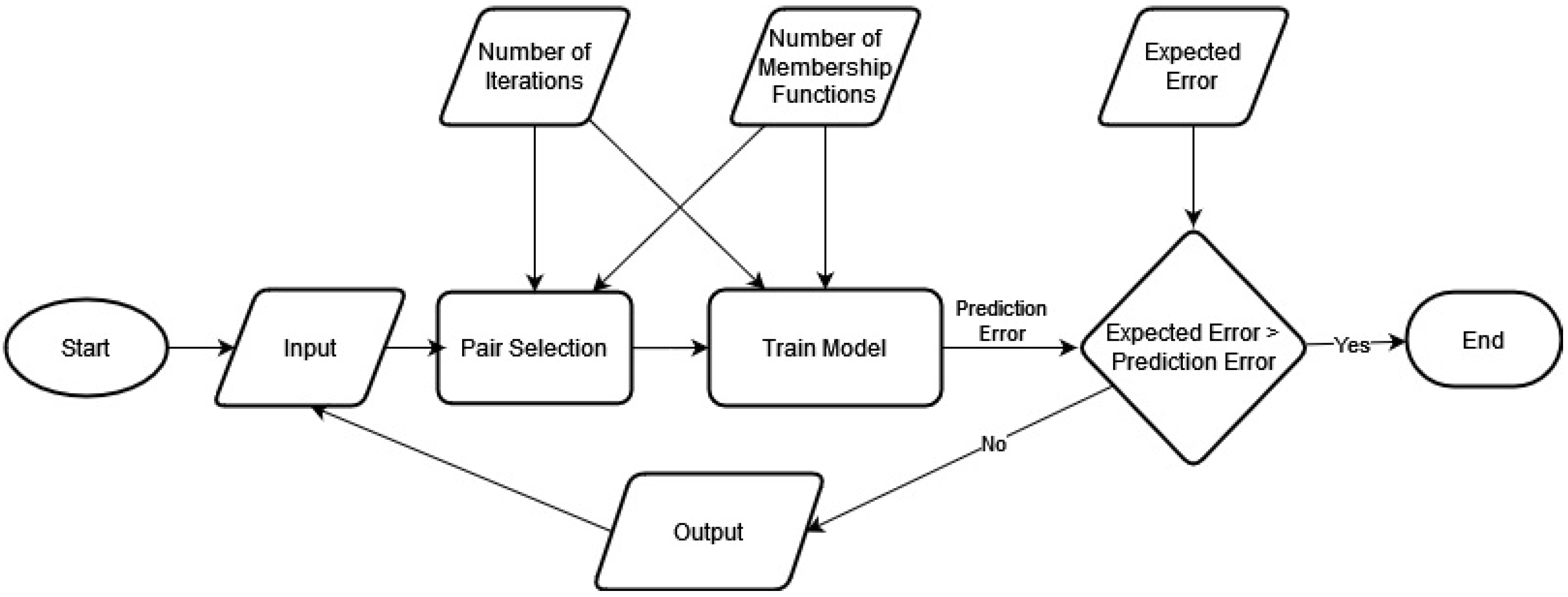
3.2. The Cascaded-ANFIS Algorithm
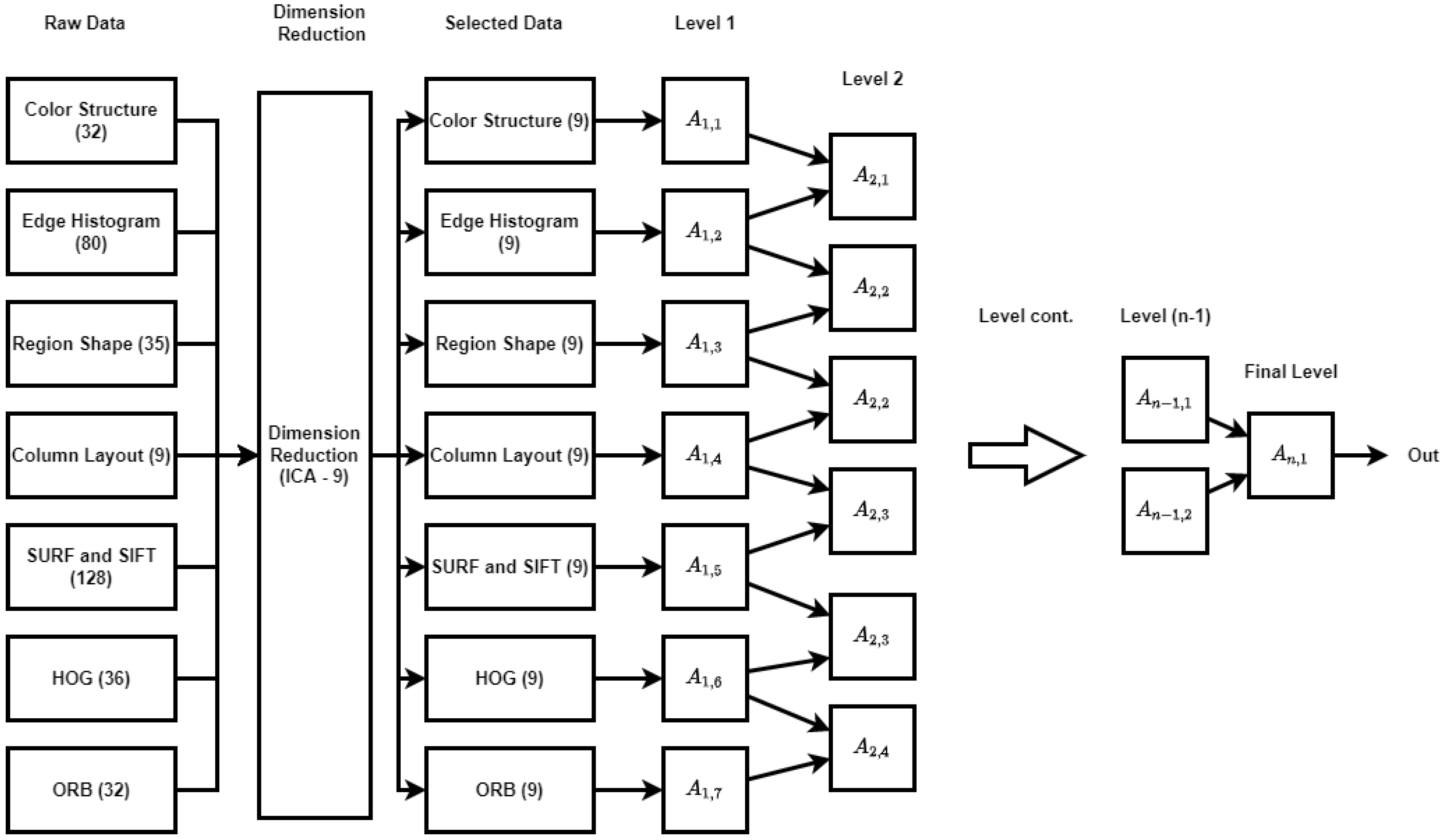
3.3. Image Data Analysis—Feature Extraction
3.4. Application Methodology—Novel Modified Structure for the Cascaded-ANFIS
3.5. Performance Analysis Techniques
4. Results and Discussion
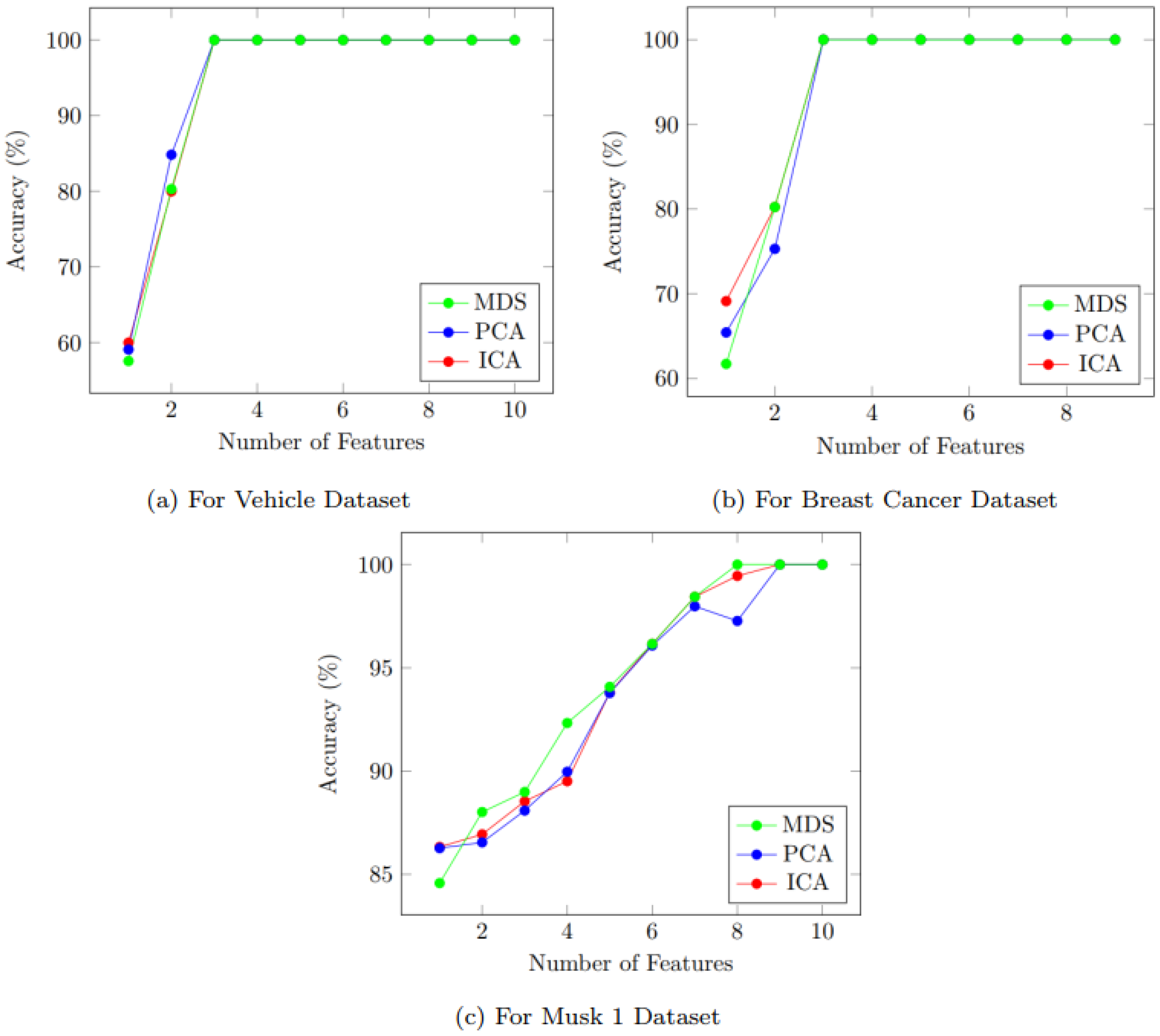
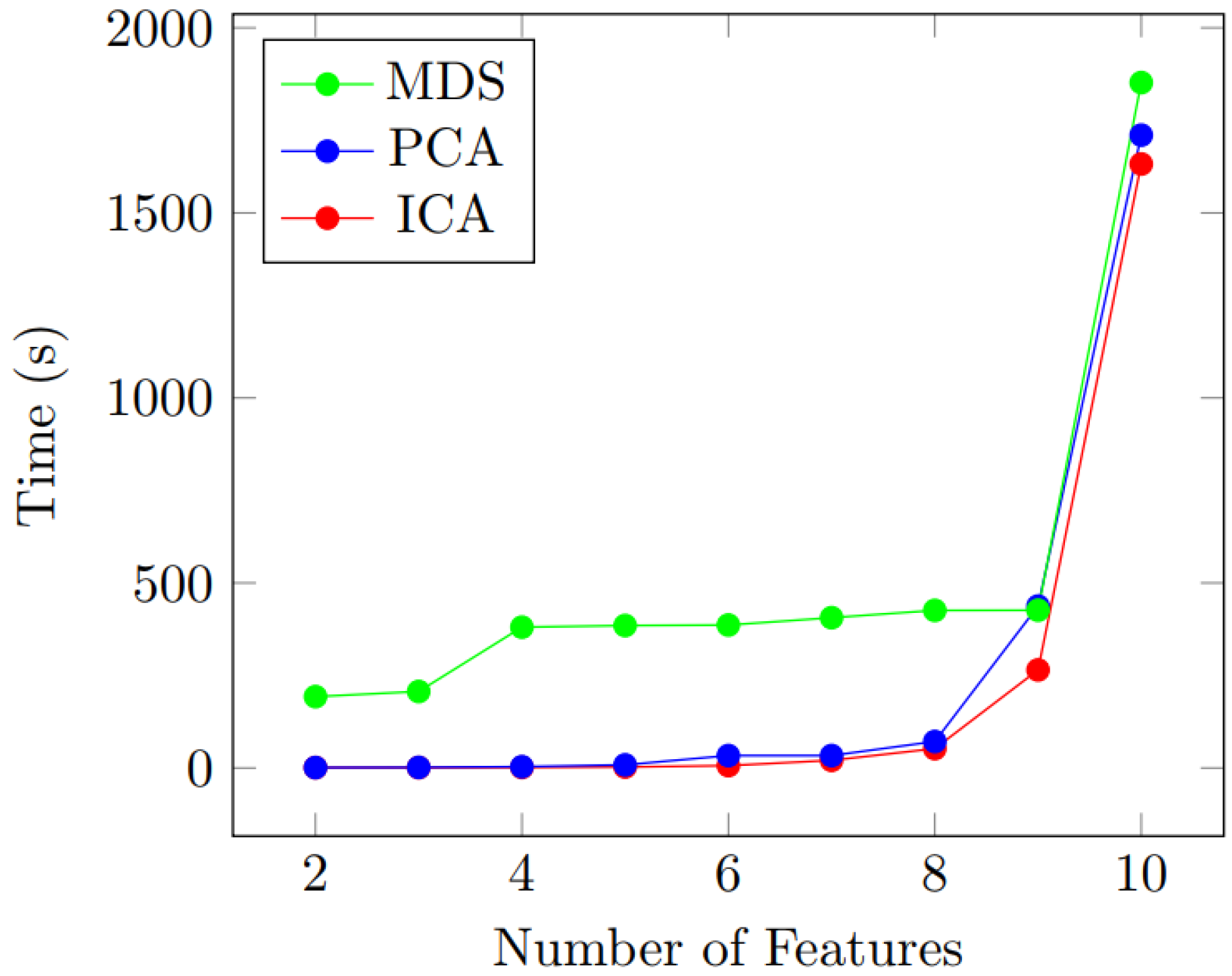
4.1. Feature Dimension Reduction
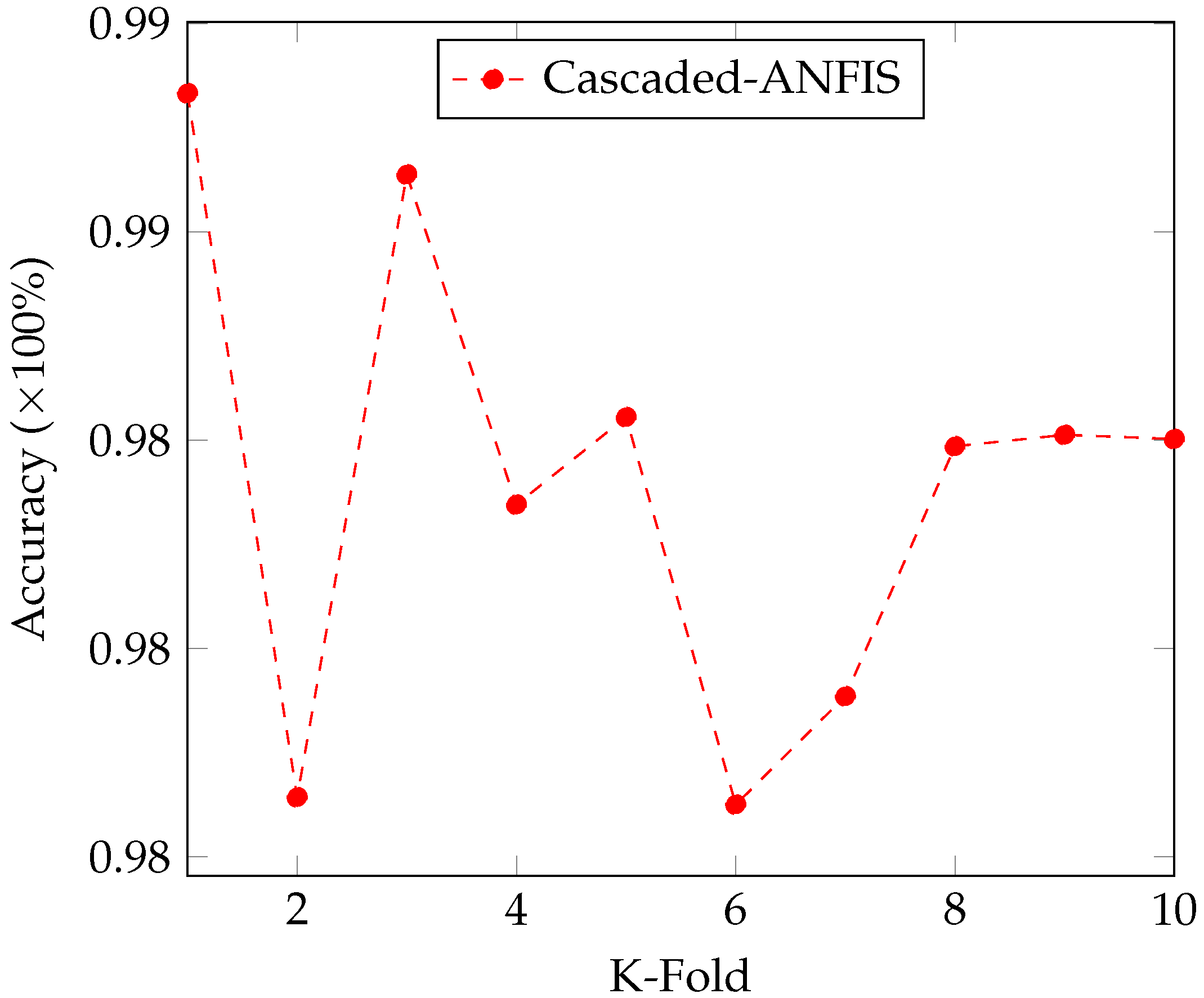
4.2. Learning Behaviour by Iterations
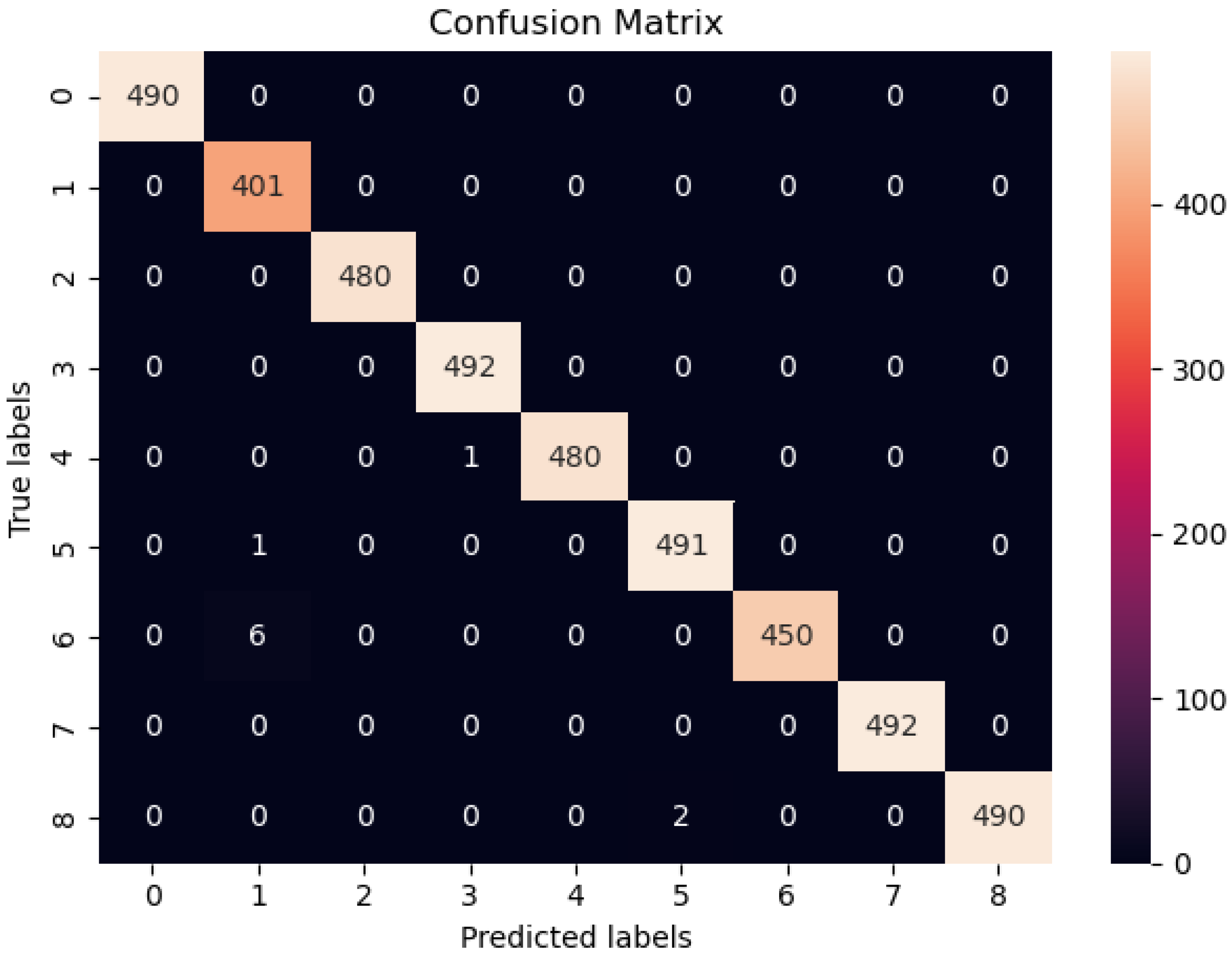
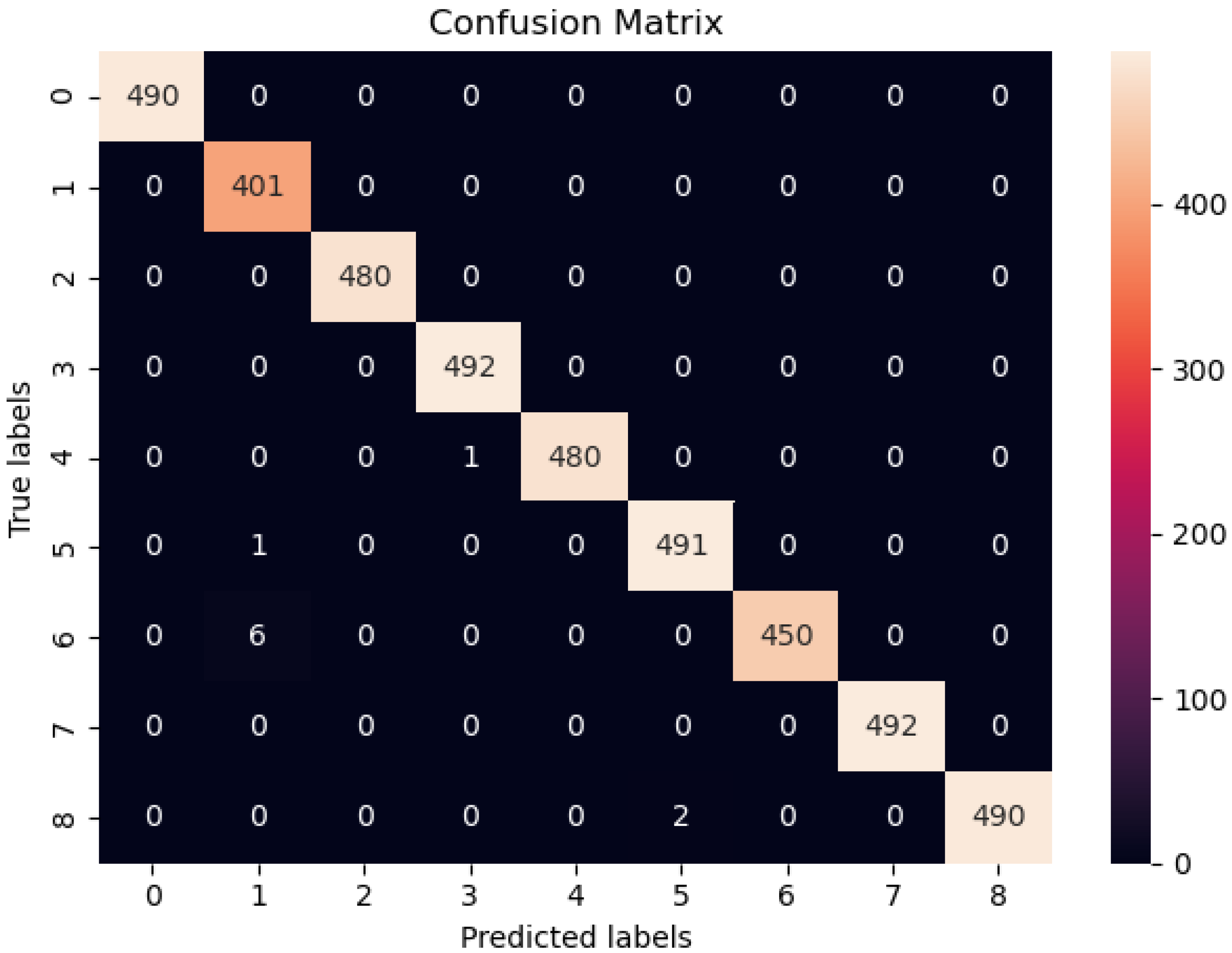
4.3. Confusion Matrix Analysis
The Accuracy Evaluation of the Confusion Matrix
4.4. Comparison of Classification Accuracy against State-of-the-Art Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| ANFIS | Adaptive Network Based Fuzzy Inference System |
| RNN | Recurrent Neural Network |
| ANN | Artificial Neural Network |
| ARIMA | Auto Regressive Integrated Moving Average |
| FIS | Fuzzy Inference System |
| FL | Fuzzy Logic |
| ML | Machine Learning |
| PSO | Particle Swarm Optimization |
| GA | Genetic Algorithms |
| RMSE | Root Mean Square Error |
| CNN | Convolution Neural Network |
| ICA | Independent Component Analysis |
| PCA | Principle Component Analysis |
| MDS | Multi Dimensional Scaling |
References
- Zhang, B.; Huang, W.; Li, J.; Zhao, C.; Fan, S.; Wu, J.; Liu, C. Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables: A review. Food Res. Int. 2014, 62, 326–343. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, L.; Wang, S.; Ji, G. Comment on ‘Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables: A review (Food Research International; 2014, 62: 326–343)’. Food Res. Int. 2015, 70, 142. [Google Scholar] [CrossRef]
- Pennington, J.A.; Fisher, R.A. Classification of fruits and vegetables. J. Food Compos. Anal. 2009, 22, S23–S31. [Google Scholar] [CrossRef]
- Rocha, A.; Hauagge, D.C.; Wainer, J.; Goldenstein, S. Automatic fruit and vegetable classification from images. Comput. Electron. Agric. 2010, 70, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Zhang, Q.; Zhu, Z. Rapid classification of citrus fruits based on raman spectroscopy and pattern recognition techniques. Food Sci. Technol. Res. 2013, 19, 1077–1084. [Google Scholar] [CrossRef] [Green Version]
- Marchal, P.C.; Gila, D.M.; García, J.G.; Ortega, J.G. Expert system based on computer vision to estimate the content of impurities in olive oil samples. J. Food Eng. 2013, 119, 220–228. [Google Scholar] [CrossRef]
- Bolle, R.M.; Connell, J.H.; Haas, N.; Mohan, R.; Taubin, G. Veggievision: A produce recognition system. In Proceedings of the Proceedings Third IEEE Workshop on Applications of Computer Vision. WACV’96, Sarasota, FL, USA, 2–4 December 1996; pp. 244–251. [Google Scholar]
- Seng, W.C.; Mirisaee, S.H. A new method for fruits recognition system. In Proceedings of the 2009 International Conference on Electrical Engineering and Informatics, Bangi, Malaysia, 5–7 August 2009; Volume 1, pp. 130–134. [Google Scholar]
- Wang, S.; Zhang, Y.; Ji, G.; Yang, J.; Wu, J.; Wei, L. Fruit classification by wavelet-entropy and feedforward neural network trained by fitness-scaled chaotic ABC and biogeography-based optimization. Entropy 2015, 17, 5711–5728. [Google Scholar] [CrossRef] [Green Version]
- Pholpho, T.; Pathaveerat, S.; Sirisomboon, P. Classification of longan fruit bruising using visible spectroscopy. J. Food Eng. 2011, 104, 169–172. [Google Scholar] [CrossRef]
- Yang, C.; Lee, W.S.; Williamson, J.G. Classification of blueberry fruit and leaves based on spectral signatures. Biosyst. Eng. 2012, 113, 351–362. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, L. Classification of fruits using computer vision and a multiclass support vector machine. Sensors 2012, 12, 12489–12505. [Google Scholar] [CrossRef]
- Fadhel, M.A.; Hatem, A.S.; Alkhalisy, M.A.E.; Awad, F.H.; Alzubaidi, L. Recognition of the unripe strawberry by using color segmentation techniques. Int. J. Eng. Technol. 2018, 7, 3383–3387. [Google Scholar]
- Breijo, E.G.; Guarrasi, V.; Peris, R.M.; Fillol, M.A.; Pinatti, C.O. Odour sampling system with modifiable parameters applied to fruit classification. J. Food Eng. 2013, 116, 277–285. [Google Scholar] [CrossRef]
- Fan, F.; Ma, Q.; Ge, J.; Peng, Q.; Riley, W.W.; Tang, S. Prediction of texture characteristics from extrusion food surface images using a computer vision system and artificial neural networks. J. Food Eng. 2013, 118, 426–433. [Google Scholar] [CrossRef]
- Omid, M.; Soltani, M.; Dehrouyeh, M.H.; Mohtasebi, S.S.; Ahmadi, H. An expert egg grading system based on machine vision and artificial intelligence techniques. J. Food Eng. 2013, 118, 70–77. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Ji, G.; Phillips, P. Fruit classification using computer vision and feedforward neural network. J. Food Eng. 2014, 143, 167–177. [Google Scholar] [CrossRef]
- Khanmohammadi, M.; Karami, F.; Mir-Marqués, A.; Garmarudi, A.B.; Garrigues, S.; De La Guardia, M. Classification of persimmon fruit origin by near infrared spectrometry and least squares-support vector machines. J. Food Eng. 2014, 142, 17–22. [Google Scholar] [CrossRef]
- Chaivivatrakul, S.; Dailey, M.N. Texture-based fruit detection. Precis. Agric. 2014, 15, 662–683. [Google Scholar] [CrossRef]
- Muhammad, G. Date fruits classification using texture descriptors and shape-size features. Eng. Appl. Artif. Intell. 2015, 37, 361–367. [Google Scholar] [CrossRef]
- Siddiqi, R. Effectiveness of transfer learning and fine tuning in automated fruit image classification. In Proceedings of the 2019 3rd International Conference on Deep Learning Technologies, Xiamen, China, 5–7 July 2019; pp. 91–100. [Google Scholar]
- Latif, G.; Alsalem, B.; Mubarky, W.; Mohammad, N.; Alghazo, J. Automatic Fruits Calories Estimation through Convolutional Neural Networks. In Proceedings of the 2020 6th International Conference on Computer and Technology Applications, Nanjing, China, 21–23 October 2020; pp. 17–21. [Google Scholar]
- Ghosh, S.; Mondal, M.J.; Sen, S.; Chatterjee, S.; Roy, N.K.; Patnaik, S. A novel approach to detect and classify fruits using ShuffleNet V2. In Proceedings of the 2020 IEEE Applied Signal Processing Conference (ASPCON), Kolkata, India, 7–9 October 2020; pp. 163–167. [Google Scholar]
- Postalcıoğlu, S. Performance analysis of different optimizers for deep learning-based image recognition. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2051003. [Google Scholar] [CrossRef]
- Huang, Z.; Cao, Y.; Wang, T. Transfer learning with efficient convolutional neural networks for fruit recognition. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 358–362. [Google Scholar]
- Rathnayake, N.; Dang, T.L.; Hoshino, Y. A Novel Optimization Algorithm: Cascaded Adaptive Neuro-Fuzzy Inference System. Int. J. Fuzzy Syst. 2021, 23, 1955–1971. [Google Scholar] [CrossRef]
- Mureşan, H.; Oltean, M. Fruit recognition from images using deep learning. Acta Univ. Sapientiae Inform. 2018, 10, 26–42. [Google Scholar] [CrossRef] [Green Version]
- Rathnayake, N.; Rathnayake, U.; Dang, T.L.; Hoshino, Y. A Cascaded Adaptive Network-Based Fuzzy Inference System for Hydropower Forecasting. Sensors 2022, 22, 2905. [Google Scholar] [CrossRef] [PubMed]
- Harsanyi, J.C.; Chang, C.I. Hyperspectral image classification and dimensionality reduction: An orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 1994, 32, 779–785. [Google Scholar] [CrossRef] [Green Version]
- Ueda, T.; Hoshiai, Y. Application of principal component analysis for parsimonious summarization of DEA inputs and/or outputs. J. Oper. Res. Soc. Jpn. 1997, 40, 466–478. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Han, J.; Zhao, L.; Meng, D. Leveraging prior-knowledge for weakly supervised object detection under a collaborative self-paced curriculum learning framework. Int. J. Comput. Vis. 2019, 127, 363–380. [Google Scholar] [CrossRef]
- Torgerson, W.S. Multidimensional scaling: I. Theory and method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Siebert, J.P. Vehicle Recognition Using Rule Based Methods; Turing Institute: London, UK, 1987. [Google Scholar]
- Wolberg, W.H.; Mangasarian, O.L. Multisurface method of pattern separation for medical diagnosis applied to breast cytology. Proc. Natl. Acad. Sci. USA 1990, 87, 9193–9196. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef] [Green Version]
- Manjunath, B.S.; Ohm, J.R.; Vasudevan, V.V.; Yamada, A. Color and texture descriptors. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 703–715. [Google Scholar] [CrossRef] [Green Version]
- Wong, K.M.; Po, L.M.; Cheung, K.W. Dominant color structure descriptor for image retrieval. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; Volume 6, pp. VI–365. [Google Scholar]
- Park, D.K.; Jeon, Y.S.; Won, C.S. Efficient use of local edge histogram descriptor. In Proceedings of the 2000 ACM Workshops on Multimedia, Los Angeles, CA, USA, 30 October–3 November 2000; pp. 51–54. [Google Scholar]
- Somnugpong, S.; Khiewwan, K. Content-based image retrieval using a combination of color correlograms and edge direction histogram. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–5. [Google Scholar]
- Lin, C.H.; Liu, C.W.; Chen, H.Y. Image retrieval and classification using adaptive local binary patterns based on texture features. IET Image Process. 2012, 6, 822–830. [Google Scholar] [CrossRef] [Green Version]
- Hall-Beyer, M. GLCM texture: A tutorial. Natl. Counc. Geogr. Inf. Anal. Remote Sens. Core Curric. 2000, 3, 75. [Google Scholar]
- Lowe, G. Sift-the scale invariant feature transform. Int. J. 2004, 2, 2. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Gayathri, N.; Mahesh, K. Improved Fuzzy-Based SVM Classification System Using Feature Extraction for Video Indexing and Retrieval. Int. J. Fuzzy Syst. 2020, 22, 1716–1729. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 INTERNATIONAL Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Rosin, P.L. Measuring corner properties. Comput. Vis. Image Underst. 1999, 73, 291–307. [Google Scholar] [CrossRef] [Green Version]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2011; pp. 778–792. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Bayliss, J.D.; Gualtieri, J.A.; Cromp, R.F. Analyzing hyperspectral data with independent component analysis. In Proceedings of the 26th AIPR Workshop: Exploiting New Image Sources and Sensors. International Society for Optics and Photonics, Washington, DC, USA, 15–17 October 1998; Volume 3240, pp. 133–143. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No of Iterations | SVM | MLP | ANFIS | PSO-ANFIS | GA-ANFIS | Cascaded-ANFIS |
|---|---|---|---|---|---|---|
| 1 | 1.98 | 3.28 | 2.02 | 1.91 | 1.92 | 0.31 |
| 10 | 1.61 | 0.95 | 2.02 | 1.91 | 1.92 | 0.24 |
| 100 | 1.20 | 0.43 | 2.02 | 1.43 | 1.83 | 0.20 |
| Class ID | Class Label | Number of Samples |
|---|---|---|
| 0 | Apple Braedurn | 492 |
| 12 | Apple Red Yellow 2 | 672 |
| 25 | Cauliflower | 702 |
| 32 | Chestnut | 450 |
| 42 | Ginger Root | 297 |
| 44 | Grape Blue | 984 |
| 66 | Mangostan | 300 |
| 73 | Nut Pecan | 534 |
| Metric | Performance Value |
|---|---|
| Average Accuracy | 0.9841 |
| Precision | 0.9841 |
| Recall | 0.9841 |
| FScore | 0.9841 |
| Precision | 0.9846 |
| Recall | 0.9849 |
| FScore | 0.9845 |
| Precision | 0.9843 |
| Recall | 0.9841 |
| FScore | 0.9840 |
| Processor | Intel(R) Core(TM) i9-10900K CPU @ 3.70 GHz 3.70 GHz |
| Installed RAM | 64.0 GB (63.9 GB usable) |
| Windows Edition | Windows 10 Education |
| HDD | 4 TB |
| SSD | 1 TB |
| Reference Study | Algorithm | Size of the Dataset | Test Accuracy | |
|---|---|---|---|---|
| # Classes | # Samples | |||
| Seda Postalcioglu (2019) [24] | CNN with Stochastic Gradient Descent with Momentum | 48 | 50,590 | 98.08 |
| CNN with Adaptive Moment Estimation | 98.83 | |||
| CNN with Root Mean Square Propagation | 99.02 | |||
| Raheel Siddiqi (2019) [21] | Customized Inception v3 | 72 | 48,249 | 99.1 |
| Customized VGG16 | 99.27 | |||
| Ziliang Huang et al. (2019) [25] | Customized MobileNet | 81 | 55,244 | 98.06 |
| Vanilla MobileNet | 95.98 | |||
| Sourodip Ghosh et al. (2020) [23] | ShufeNet V2 | 31 | 29,347 | 96.24 |
| Ghazanfar Latif et al. (2020) [22] | DCNN | 18 | 22,341 | 95 |
| Jorg Martinet al. (2019) [49] | ResNet18 | 116 | 58,428 | 98.7 |
| This Study (2022) | Cascaded-ANFIS | 131 | 67,692 | 98.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rathnayake, N.; Rathnayake, U.; Dang, T.L.; Hoshino, Y. An Efficient Automatic Fruit-360 Image Identification and Recognition Using a Novel Modified Cascaded-ANFIS Algorithm. Sensors 2022, 22, 4401. https://doi.org/10.3390/s22124401
Rathnayake N, Rathnayake U, Dang TL, Hoshino Y. An Efficient Automatic Fruit-360 Image Identification and Recognition Using a Novel Modified Cascaded-ANFIS Algorithm. Sensors. 2022; 22(12):4401. https://doi.org/10.3390/s22124401
Chicago/Turabian StyleRathnayake, Namal, Upaka Rathnayake, Tuan Linh Dang, and Yukinobu Hoshino. 2022. "An Efficient Automatic Fruit-360 Image Identification and Recognition Using a Novel Modified Cascaded-ANFIS Algorithm" Sensors 22, no. 12: 4401. https://doi.org/10.3390/s22124401
APA StyleRathnayake, N., Rathnayake, U., Dang, T. L., & Hoshino, Y. (2022). An Efficient Automatic Fruit-360 Image Identification and Recognition Using a Novel Modified Cascaded-ANFIS Algorithm. Sensors, 22(12), 4401. https://doi.org/10.3390/s22124401