
A Repair Method for Missing Traffic Data Based on FCM, Optimized by the Twice Grid Optimization and Sparrow Search Algorithms

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
- (1)
- the t-SNE algorithm was used to reduce the dimension of data in AR mode to verify the correlation between multi-dimensional data and ensure the quality of the data matrix in the FCM algorithm.
- (2)
- TGO algorithm was adopted to select the initial clustering center for the FCM algorithm.
- (3)
- Sparrow search algorithm was adopted to optimize m and K of FCM.
3.1. Three Data Repair Mode
- (1)
- Time correlation repair mode (TR) means to combine ‘weekly correlation’ traffic flow data into a matrix for data repair. The ‘weekly correlation’ data refers to the traffic data of the target traffic sensor for 7 consecutive days in the same week. Some studies [29,30] showed that traffic flow on working and non-working days followed different rules. Therefore, ‘week correlation’ data in this paper refers to the traffic flow data of the same traffic sensor on consecutive 5 working days in the same week. The data format is shown in Table 1.
- (2)
- Spatial correlation repair mode (SR) means that the data of the ‘adjacent’ traffic sensor are used to predict the missing value of the data of the target traffic sensor. The ‘adjacent’ includes lane adjacency and position adjacency. The study [14] showed that the lane flow distribution of most roads was uneven. Therefore, ‘adjacent’ in this paper refers to location adjacency. We selected the traffic flow data of adjacent traffic sensors in different sections of the same road to perform curve fitting with the data of the target traffic sensor, and calculated the missing value of the target traffic sensor according to the fitting results. The data format is similar to that of the TR mode.
- (3)
- Attribute value correlation repair mode (AR) replaces missing traffic values with other correct attribute values of the same traffic data. Studies [31,32] have shown a strong correlation between attribute values such as traffic flow, speed, and time occupancy, and the above attribute values could be used for data clustering analysis. This paper assumes that some traffic flow data of the infrared-based traffic sensor were wrong, which is regarded as missing data, and the speed and time share data are correct. The data format of AR mode is shown in Table 2.
3.2. Conventional Fuzzy C-Means Imputation Algorithm
3.3. Twice Grid Optimization Algorithm
3.4. Sparrow Search Algorithm

3.5. Data Repair Method Based on TGO-SSA-FCM Algorithm

3.6. Evaluation Metrics
4. Results
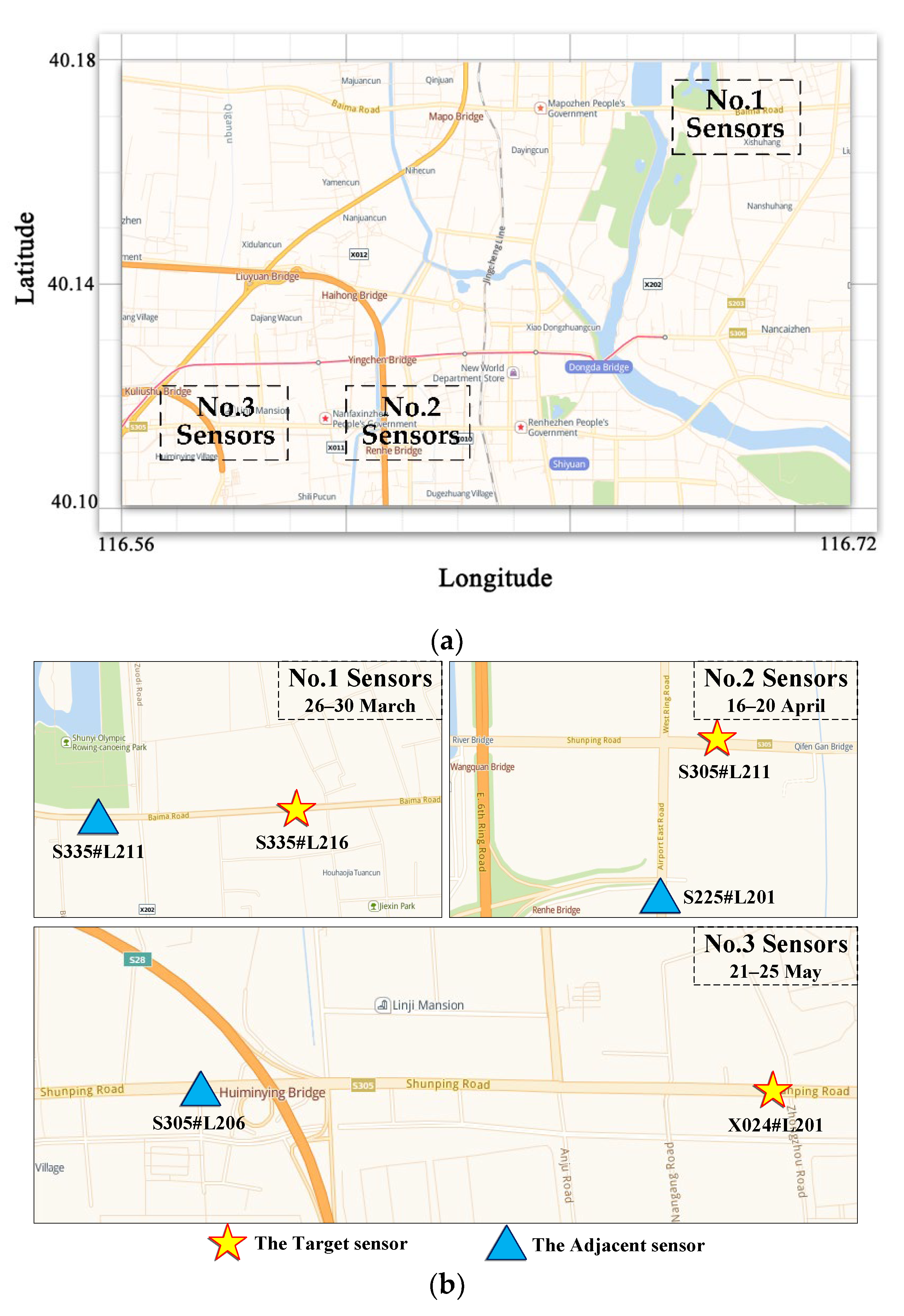
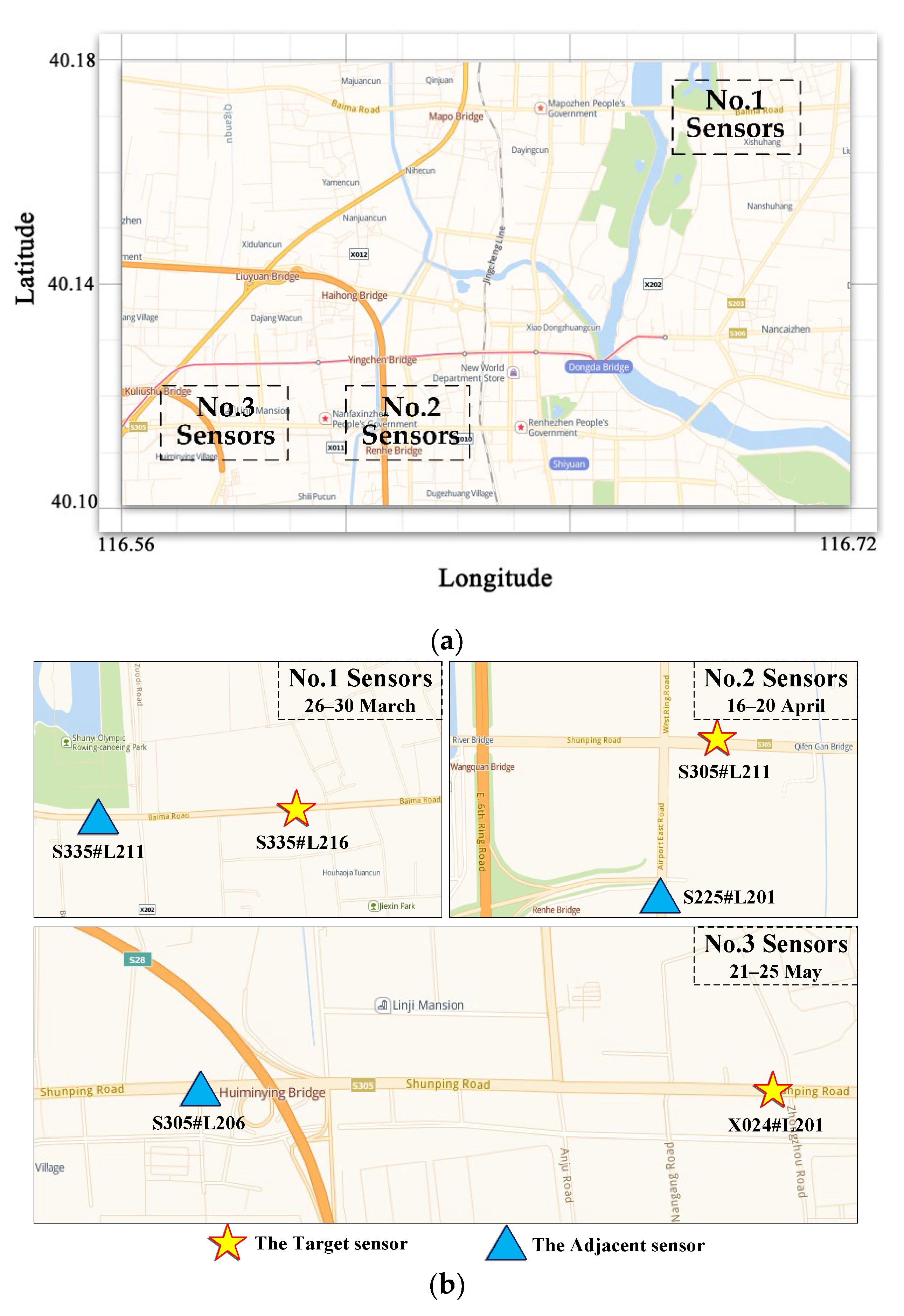
4.1. Datasets
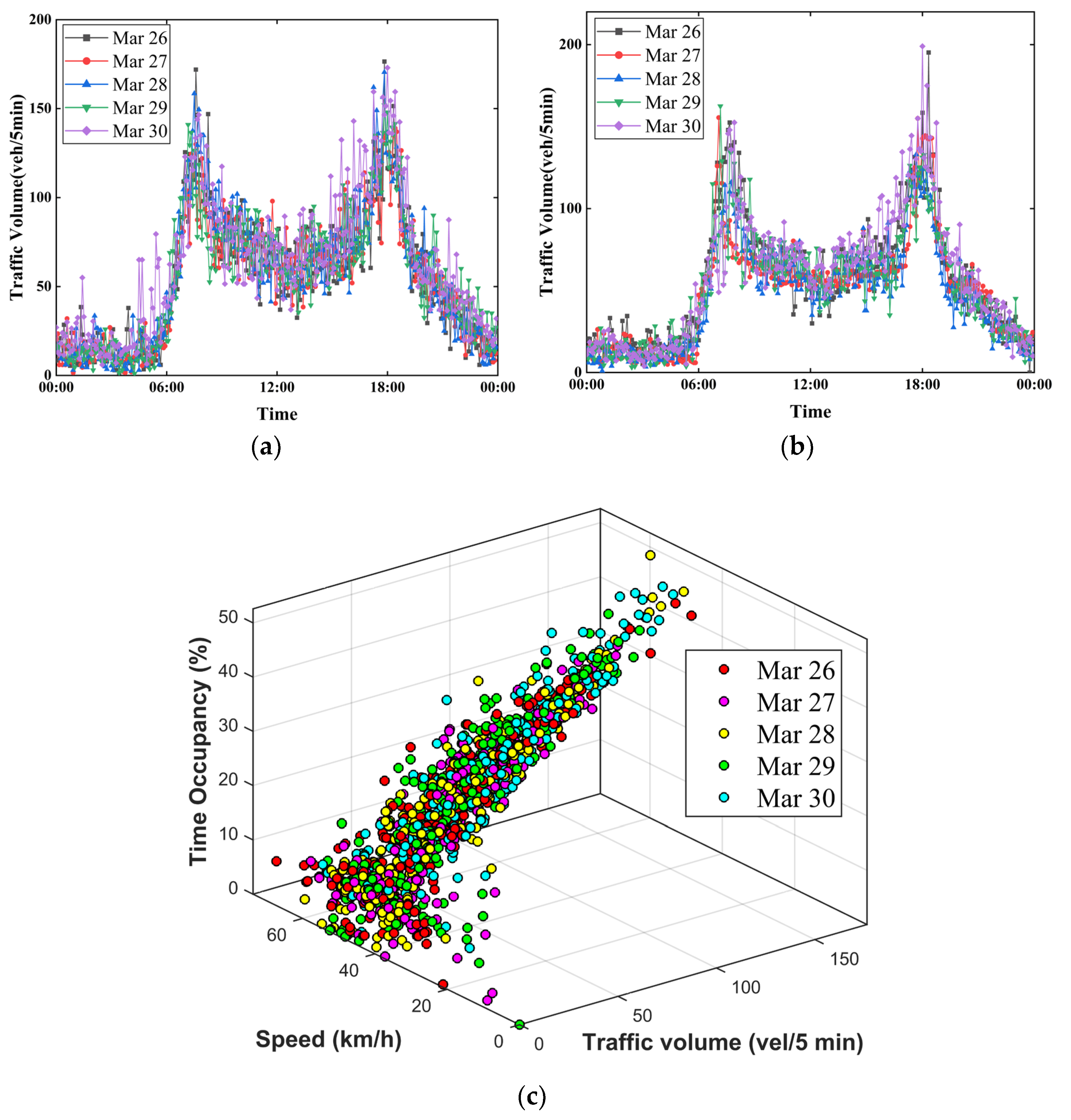
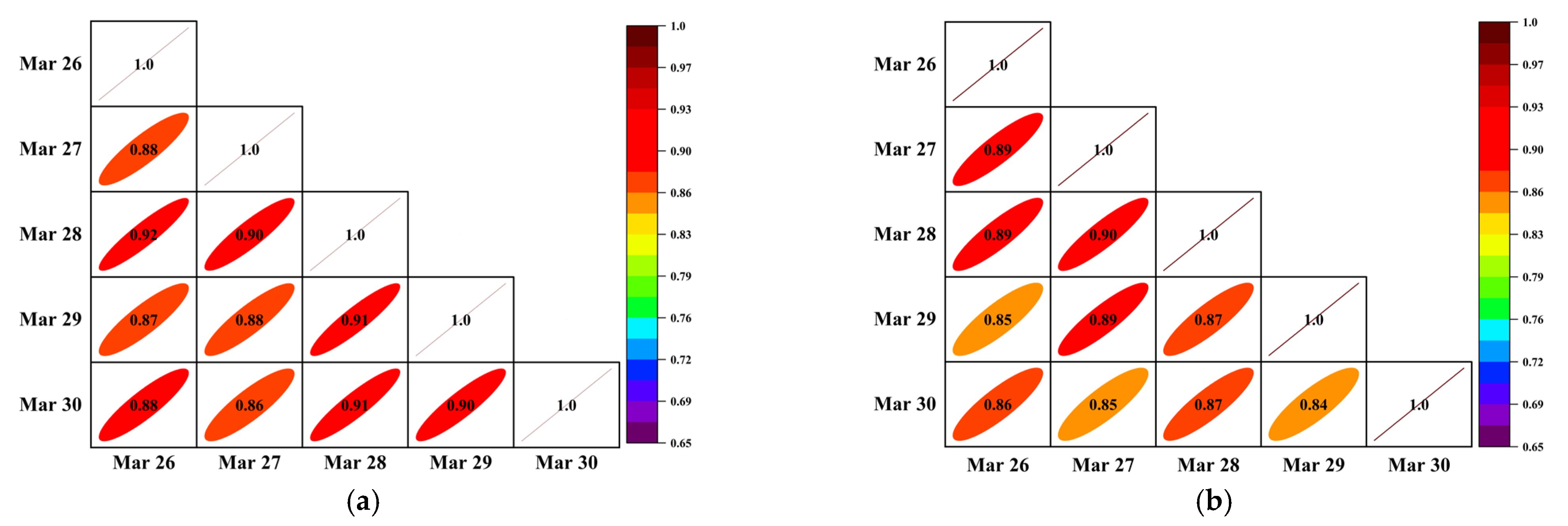
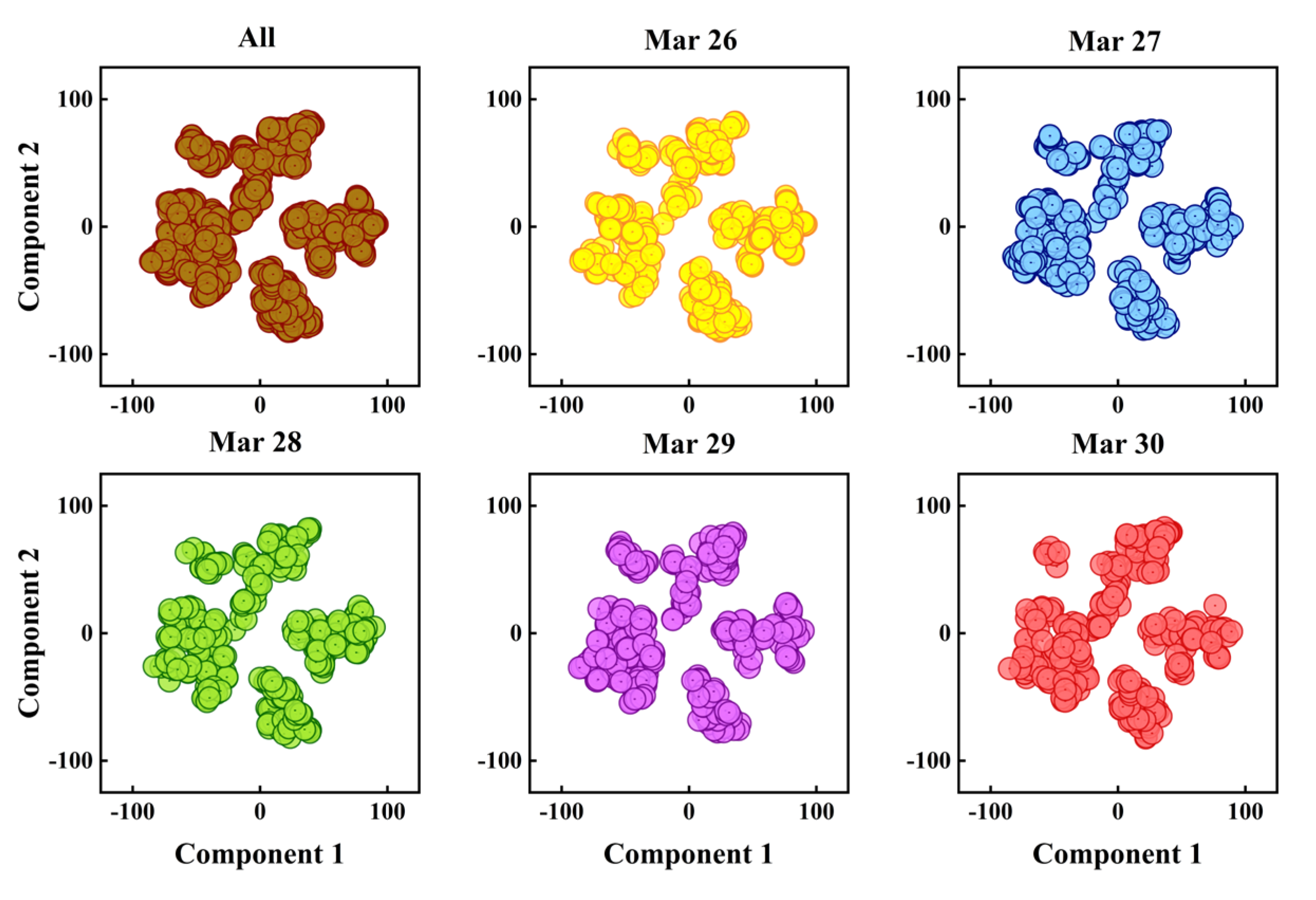
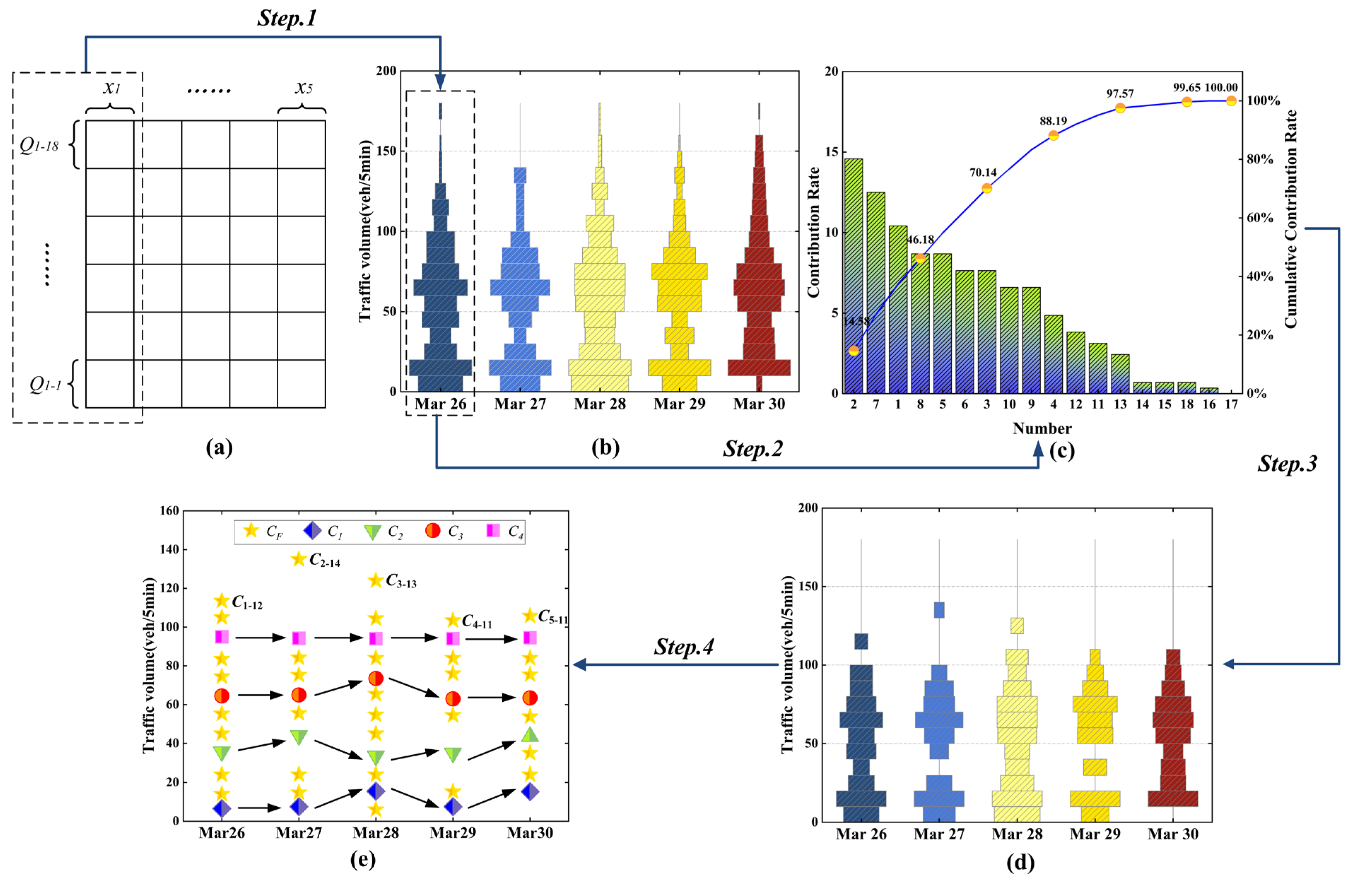
4.2. Spatial-Temporal Correlation Analysis for Traffic Data
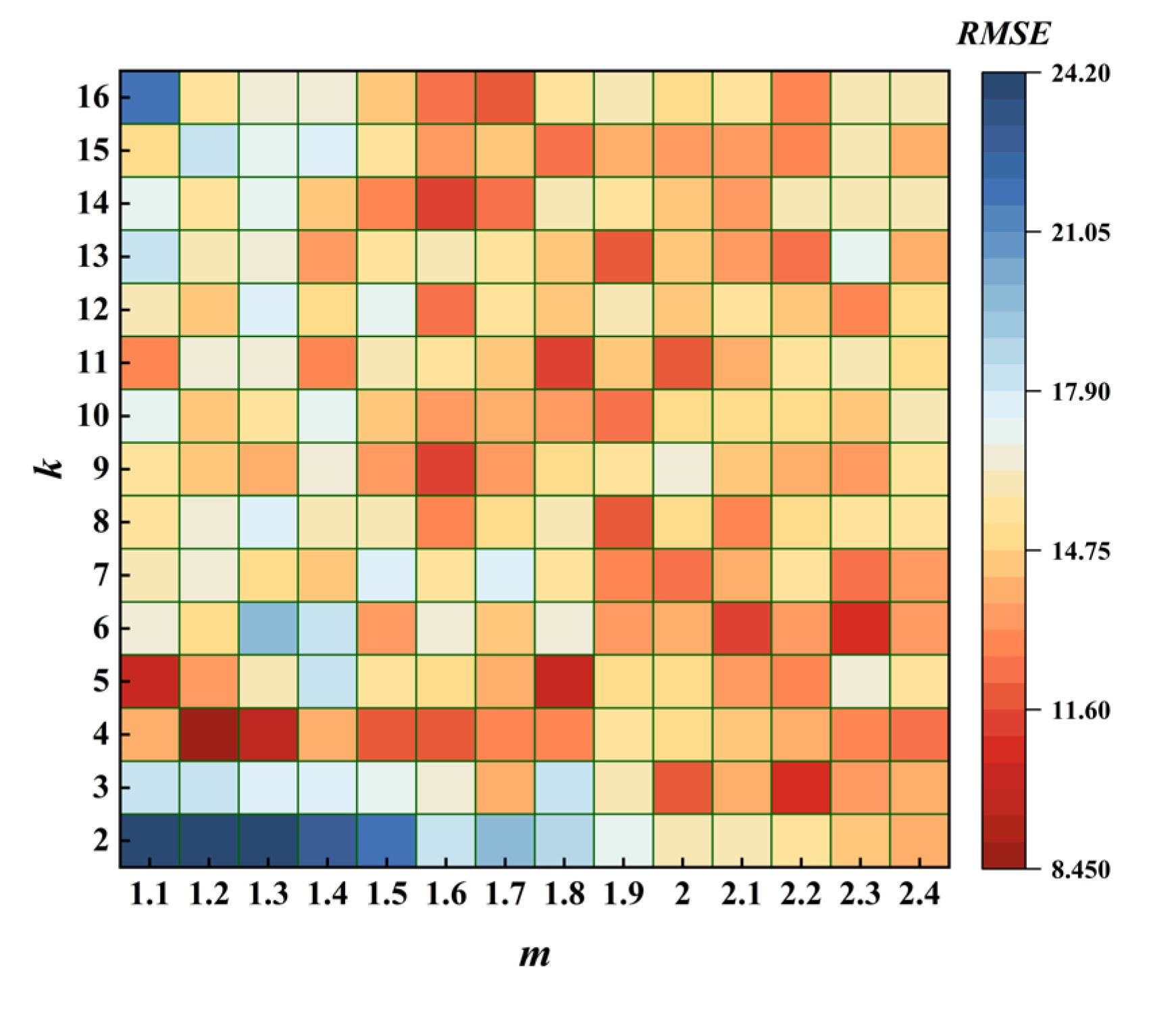
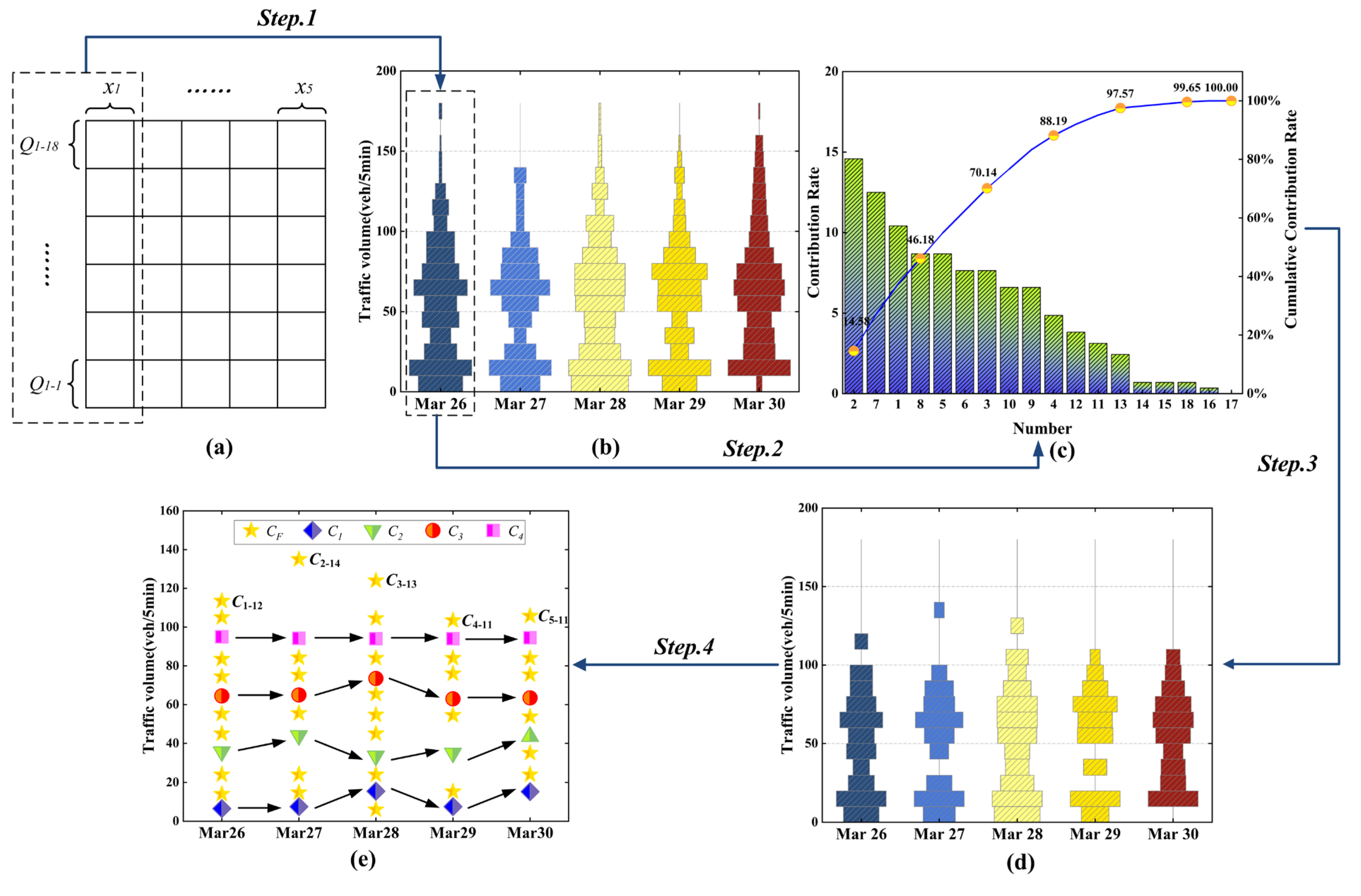
4.3. Preselection of Model Parameters
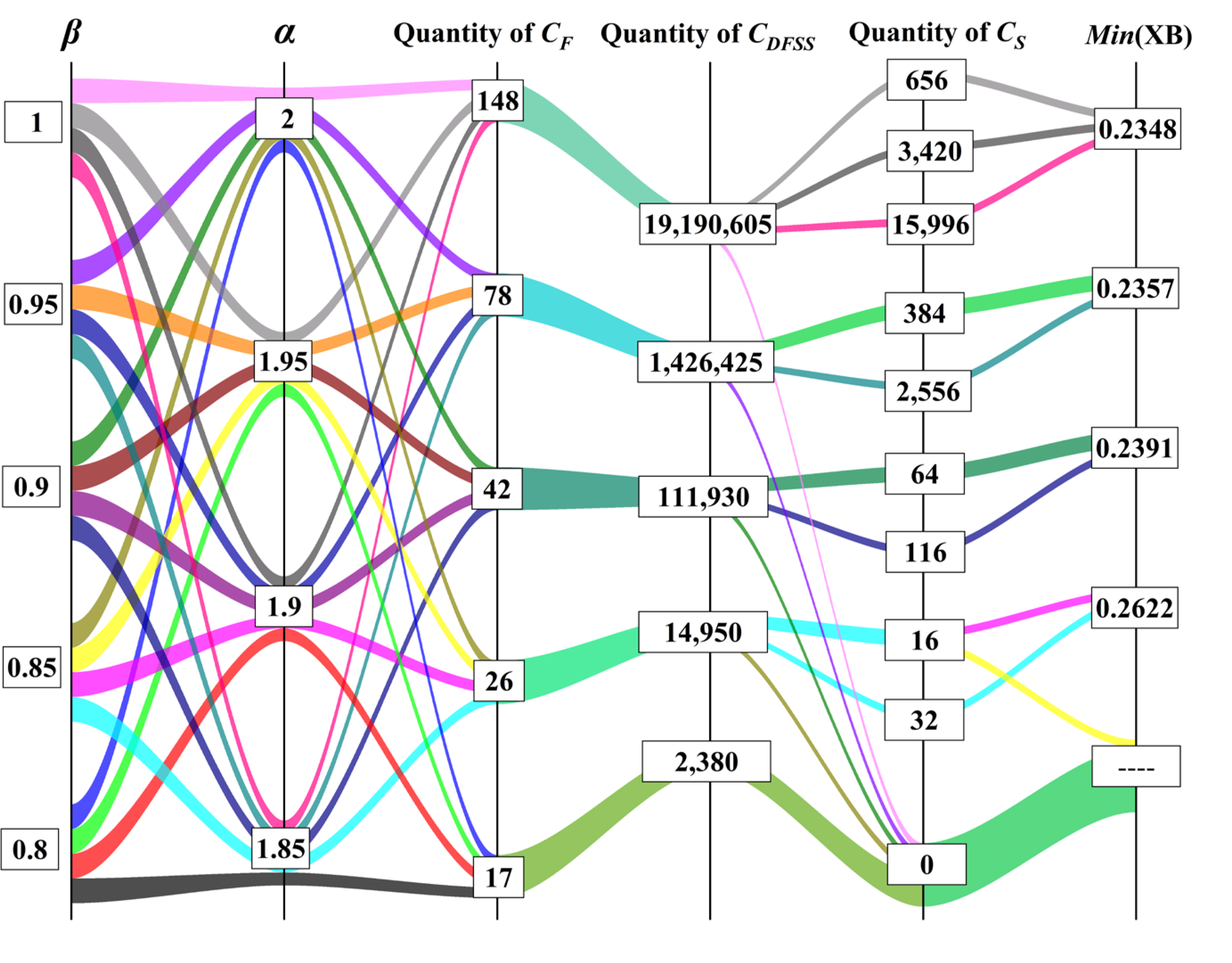
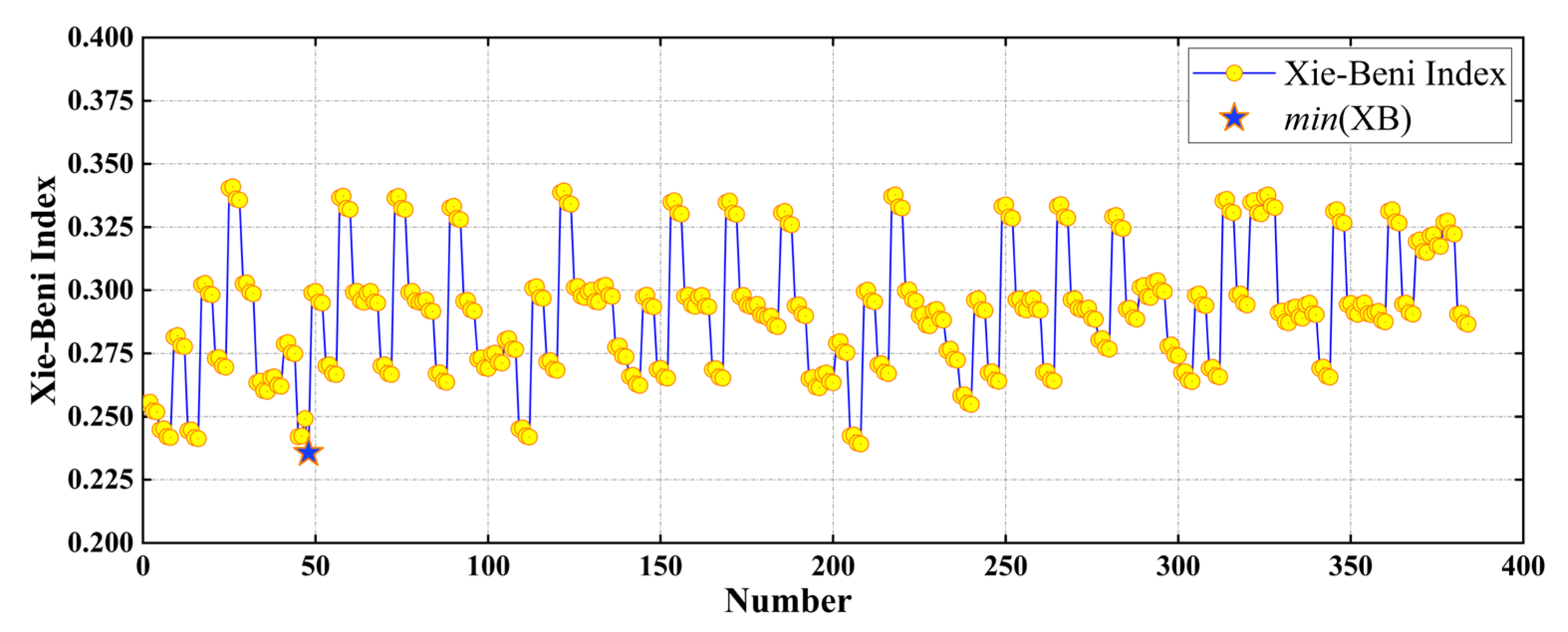
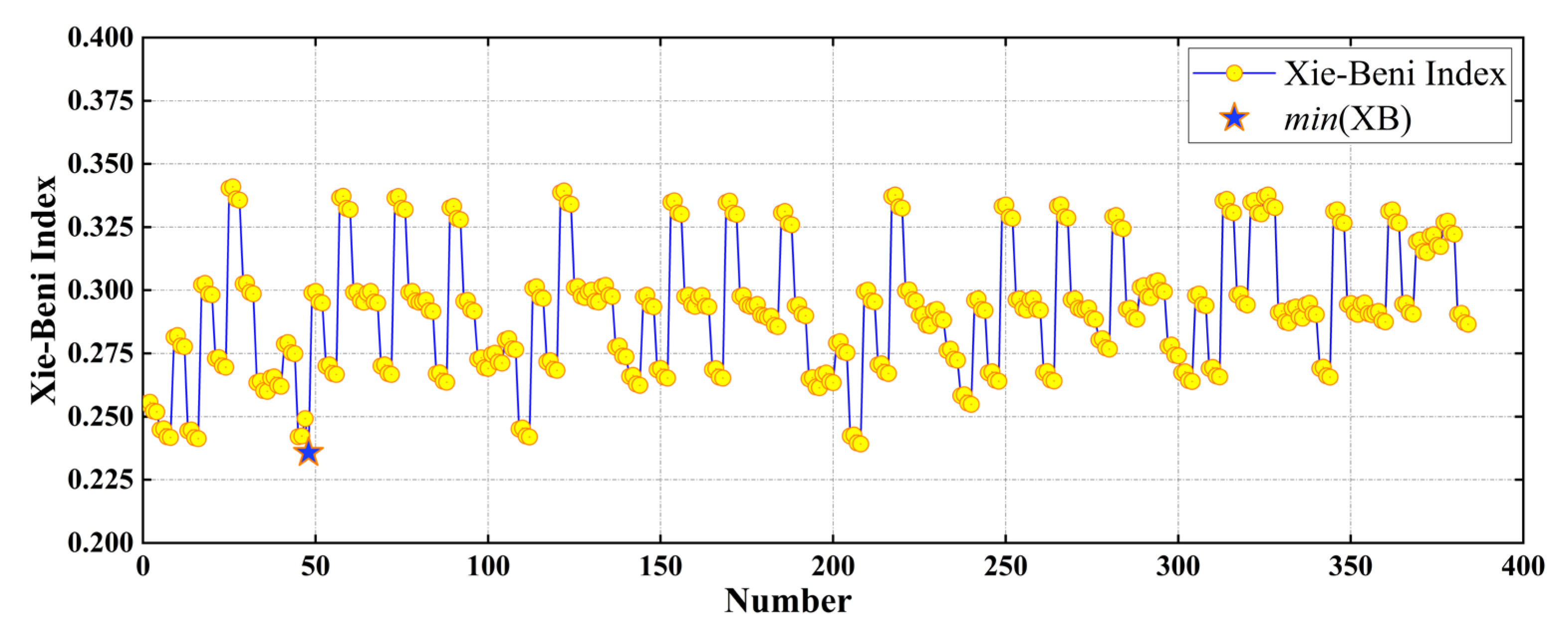
4.4. Example of TGO Algorithm
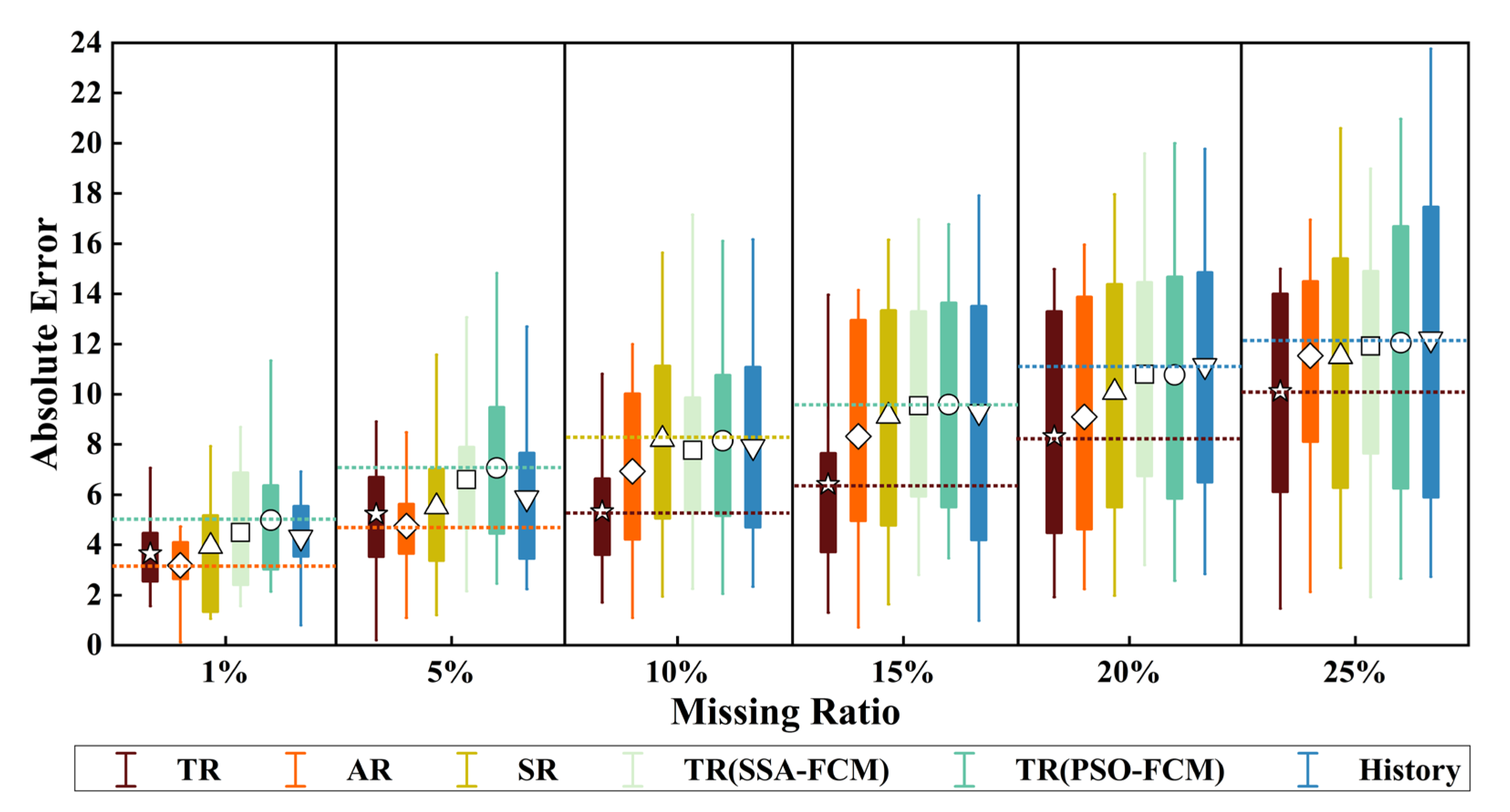
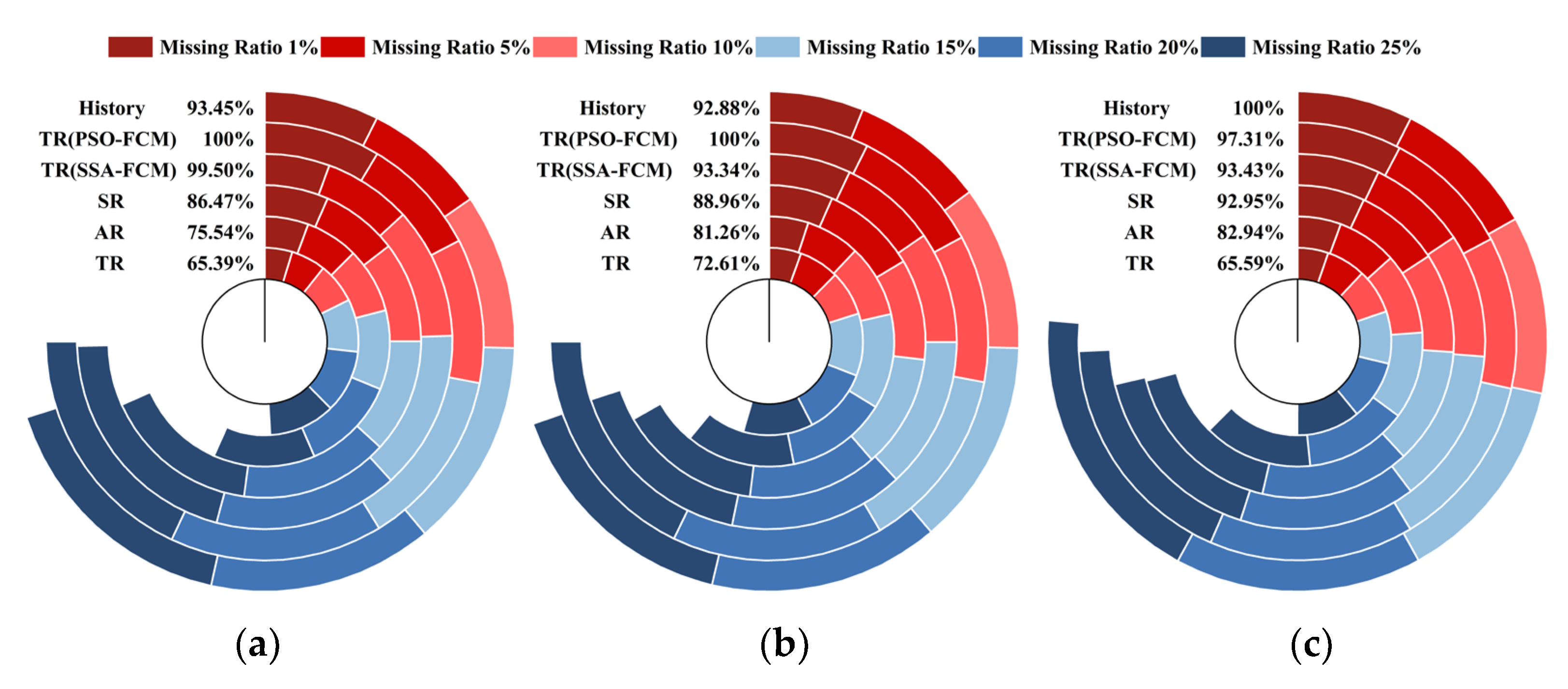
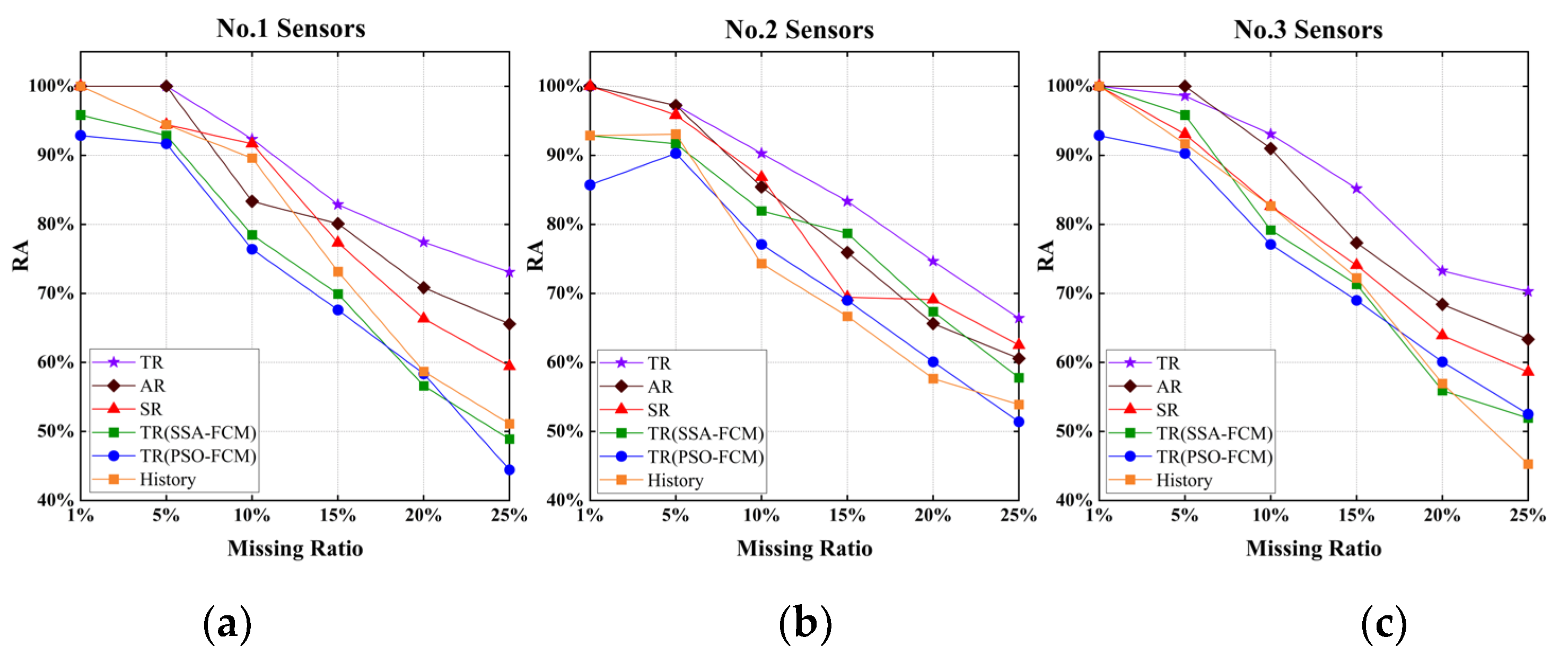
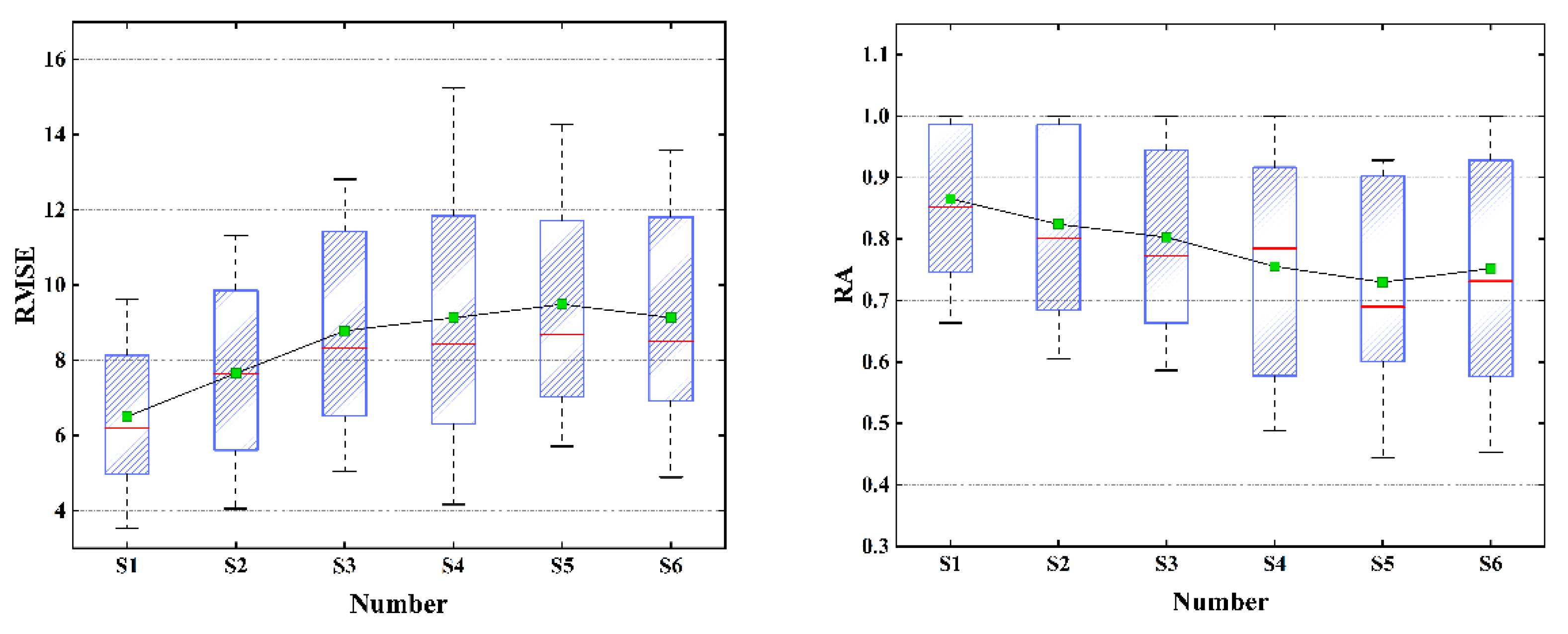
4.5. Experimental Results
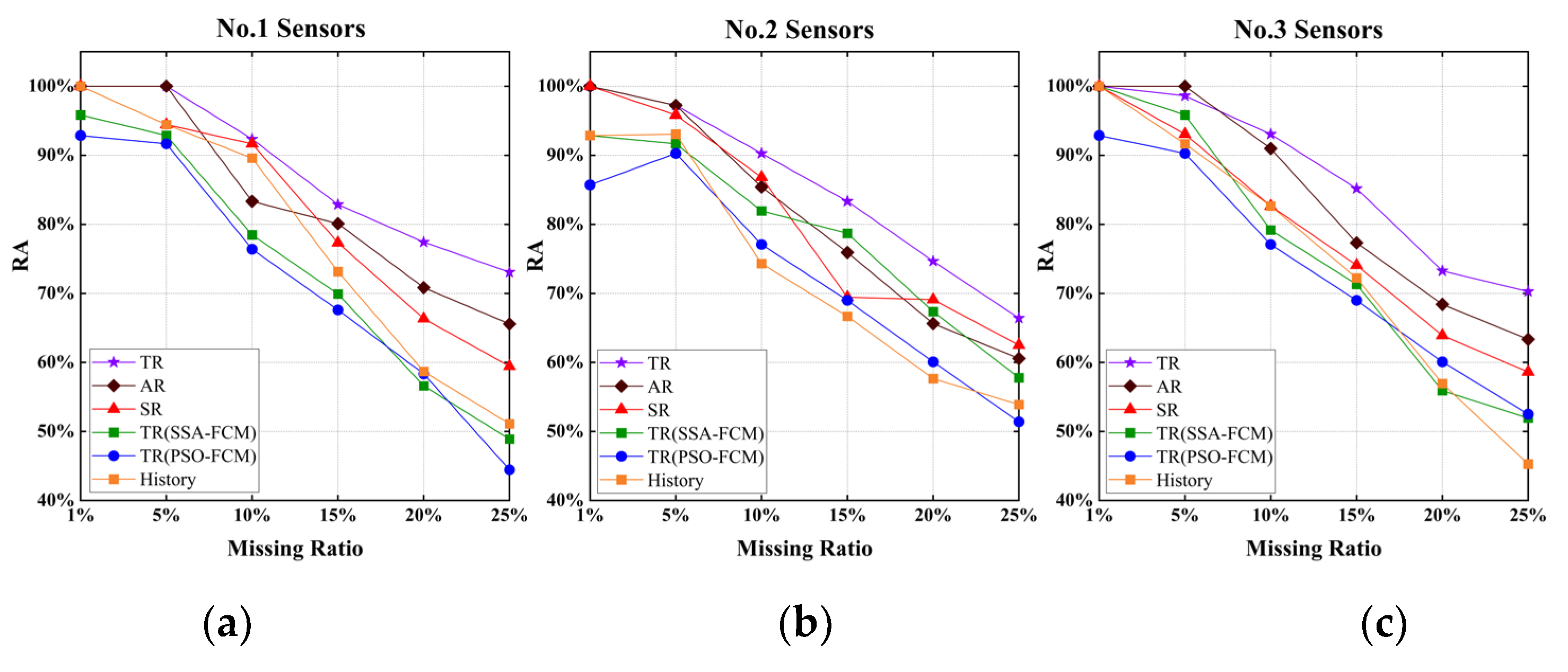
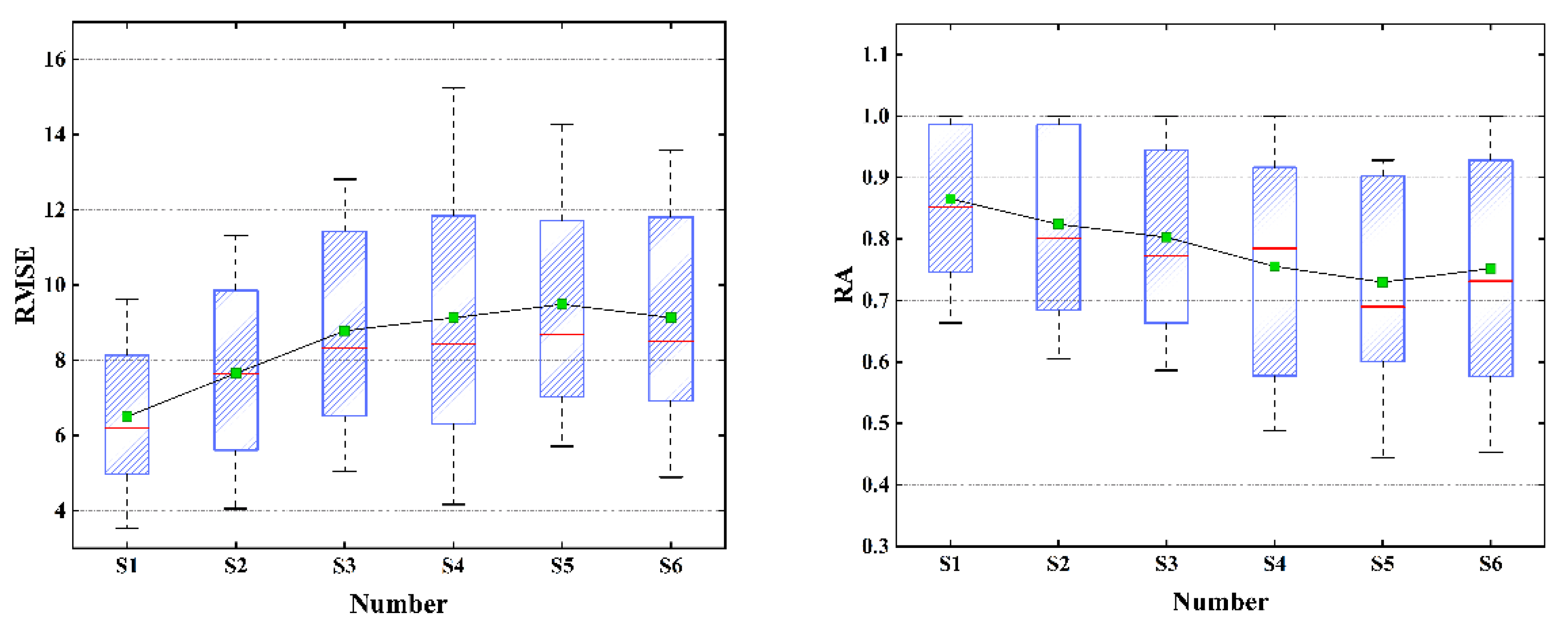
4.6. Comparisons and Analyses of the Results
- (1)
- The repair effect of S1 was much better than that of S4 because the TGO algorithm was used to optimize the initial clustering center of FCM, and the clustering center of the FCM algorithm had a small XB index in the initialization stage, which ensured the accuracy of the clustering.
- (2)
- S2 even achieved a better repair effect than S1 when the missing ratio was low. However, with the increase in the missing ratio, the repair effect was gradually surpassed by S1. The main reason was that there was no absolute correspondence between traffic flow, speed, and time occupancy in AR mode. For example, under normal circumstances, when the flow data was small the speed would be relatively high, and the time occupancy was low. However, although the flow data was small, the driver’s visual range was limited at night under the influence of lighting and other factors, which would cause a decrease in speed compared to the same flow during the day. Therefore, the inevitable volatility of the data itself would continue to accumulate with the increase of the missing rate, resulting in a decrease in the repair effect of S2 when the missing rate was high.
- (3)
- The repair effect of S3 was relatively accurate, but the flow direction ratio of the traffic flow at the intersection was not fixed, which led to a decrease in the repair effect of S3. For example, for the third group of sensors, there were two intersections between the two sensors, and the repair effect of S3 was close to that of S4–S6. It could be concluded that the fitting of upstream and downstream sensor data has certain defects, and S3 would be feasible when the intersection flow direction ratio could be obtained stably.
- (4)
- The effects of S4, S5, and S6 were similar. The effect of S4 was slightly better than that of S5, especially in the analysis of the second group of sensor data. Under the same initial clustering centers, the PSO algorithm fell more easily into local optimization than the SSA algorithm. S6 occasionally had unexpected effects in the case of a low miss ratio. However, due to the volatility of traffic flow data, the error of each time interval would accumulate, and led to a significant decrease in repair effect with the increase of loss ratio.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pavlyuk, D. Temporal Aggregation Effects in Spatiotemporal Traffic Modelling. Sensors 2020, 20, 6931. [Google Scholar] [CrossRef]
- Pozanco, A.; Fernández, S.; Borrajo, D. Urban traffic control assisted by ai planning and relational learning. In Proceedings of the 9th International Workshop on Agents in Traffic and Transportation, Madrid, Spain, 10 July 2016. [Google Scholar]
- Castro-Neto, M.; Jeong, Y.; Jeong, M.; Han, L.D. Online-SVR for short-term traffic flow prediction under typical and atypical traffic conditions. Expert. Syst. Appl. 2009, 36, 6164–6173. [Google Scholar] [CrossRef]
- Cui, Z.; Henrickson, K.; Ke, R.; Wang, Y. Traffic Graph Convolutional Recurrent Neural Network: A Deep Learning Framework for Network-Scale Traffic Learning and Forecasting. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4883–4894. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Sun, T.; Jiao, P. Spatio-Temporal Segmented Traffic Flow Prediction with ANPRS Data Based on Improved XGBoost. J. Adv. Transp. 2021, 2021 Pt 1, 5559562. [Google Scholar] [CrossRef]
- Lai, X.C.; Zhang, L.Y. An overview of missing value filling methods. In Theory and Method of Data Missing Value Filling Based on Machine Learning, 1st ed.; Machinery Industry Press: Beijing, China, 2020; pp. 3–7. [Google Scholar]
- Chan, R.K.C.; Lim, J.M.; Parthiban, R. A neural network approach for traffic prediction and routing with missing data imputation for intelligent transportation system. Expert Syst. Appl. 2021, 171, 114573. [Google Scholar] [CrossRef]
- Zambrano-Martinez, J.; Calafate, C.; Soler, D.; Cano, J.; Manzoni, P. Modeling and Characterization of Traffic Flows in Urban Environments. Sensors 2018, 18, 2020. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Grant-Muller, S.; Mussone, L.; Montgomery, F. A Study of Hybrid Neural Network Approaches and the Effects of Missing Data on Traffic Forecasting. Neural Comput. Appl. 2001, 10, 277–286. [Google Scholar] [CrossRef]
- Zhong, M.; Lingras, P.; Sharma, S. Estimation of missing traffic counts using factor, genetic, neural, and regression techniques. Transp. Res. Part C Emerg. Technol. 2004, 12, 139–166. [Google Scholar] [CrossRef]
- Chiou, J.; Zhang, Y.; Chen, W.; Chang, C. A functional data approach to missing value imputation and outlier detection for traffic flow data. Transp. B Transp. Dyn. 2014, 2, 106–129. [Google Scholar] [CrossRef]
- Qu, L.; Hu, J.; Li, L.; Zhang, Y. PPCA-Based Missing Data Imputation for Traffic Flow Volume: A Systematical Approach. IEEE Trans. Intell. Transp. Syst. 2009, 10, 512–522. [Google Scholar]
- Tang, J.; Zhang, G.; Wang, Y.; Wang, H.; Liu, F. A hybrid approach to integrate fuzzy C-means based imputation method with genetic algorithm for missing traffic volume data estimation. Transp. Res. Part C Emerg. Technol. 2015, 51, 29–40. [Google Scholar] [CrossRef]
- Shang, Q.; Yang, Z.; Gao, S.; Tan, D. An Imputation Method for Missing Traffic Data Based on FCM Optimized by PSO-SVR. J. Adv. Transp. 2018, 2018, 5559562. [Google Scholar] [CrossRef]
- Cheng, Z.; Wang, W.; Lu, J.; Xing, X. Classifying the traffic state of urban expressways: A machine-learning approach. Transp. Res. Part A Policy Pract. 2020, 137, 411–428. [Google Scholar] [CrossRef]
- Huang, J.; Mao, B.; Bai, Y.; Zhang, T.; Miao, C. An Integrated Fuzzy C-Means Method for Missing Data Imputation Using Taxi GPS Data. Sensors 2020, 20, 1992. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Meng, X.; Gan, W.; Chen, Y. Traffic Data Imputation Algorithm Based on Improved Low-Rank Matrix Decomposition. J. Sens. 2019, 2019, 7092713. [Google Scholar] [CrossRef]
- Han, Y.; He, Z. Simultaneous Incomplete Traffic Data Imputation and Similarity Pattern Discovery with Bayesian Nonparametric Tensor Decomposition. J. Adv. Transport 2020, 2020, 8810753. [Google Scholar] [CrossRef]
- Henrickson, K.; Zou, Y.; Wang, Y. Flexible and Robust Method for Missing Loop Detector Data Imputation. Transp. Res. Rec. J. Transp. Res. Board 2015, 2527, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Mao, G. Missing Data Estimation for Traffic Volume by Searching an Optimum Closed Cut in Urban Networks. IEEE Trans. Intell. Transp. Syst. 2019, 20, 75–86. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, D.; Gao, J.; Chen, J.; Jiang, K. A novel approach of tensor-based data missing estimation for Internet of Vehicles. Int. J. Commun. Syst. 2020, 33, e4433. [Google Scholar] [CrossRef]
- Chen, X.; Wei, Z.; Li, Z.; Liang, J.; Cai, Y.; Zhang, B. Ensemble correlation-based low-rank matrix completion with applications to traffic data imputation. Knowl.-Based Syst. 2017, 132, 249–262. [Google Scholar] [CrossRef]
- Kazemi, A.; Meidani, H. IGANI: Iterative Generative Adversarial Networks for Imputation With Application to Traffic Data. IEEE Access 2021, 9, 112966–112977. [Google Scholar] [CrossRef]
- Hathaway, R.J.; Bezdek, J.C. Clustering incomplete relational data using the non-Euclidean relational fuzzy c-means algorithm. Pattern Recognit. Lett. 2002, 23, 151–160. [Google Scholar] [CrossRef]
- Tian, L.; Jiang, J.; Tian, L. Safety analysis of traffic flow characteristics of highway tunnel based on artificial intelligence flow net algorithm. Clust. Comput. 2019, 22 (Suppl. S1), 573–582. [Google Scholar] [CrossRef]
- Ming, L.K.; Kiong, L.C.; Soong, L.W. Autonomous and deterministic supervised fuzzy clustering with data imputation capabilities. Appl. Soft. Comput. 2011, 11, 1117–1125. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Chen, Q. Comparative study of several new swarm intelligence optimization algorithms. Comput. Eng. Appl. 2020, 56, 1–12. [Google Scholar]
- Jia, X.; Dong, X.; Chen, M.; Yu, X. Missing data imputation for traffic congestion data based on joint matrix factorization. Knowl-Based Syst 2021, 225, 107114. [Google Scholar] [CrossRef]
- Su, F.; Dong, H.; Jia, L.; Sun, X. On urban road traffic state evaluation index system and method. Mod. Phys. Lett. B 2017, 31, 1650428. [Google Scholar] [CrossRef]
- Xia, J.; Huang, W.; Guo, J. A clustering approach to online freeway traffic state identification using ITS data. KSCE J. Civ. Eng. 2012, 16, 426–432. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, P.; Xu, C.; Bao, J. Understand the impact of traffic states on crash risk in the vicinities of Type A weaving segments: A deep learning approach. Accid. Anal. Prev. 2021, 159, 106293. [Google Scholar] [CrossRef]
- Liang, H.; Chen, H.; Guo, J.; Jiang, Y. An Evaluation Model of the Stuck Risks Based on Remote Sensor Network and Fuzzy Logic. IEEE Sens. J. 2021, 21, 23658–23666. [Google Scholar] [CrossRef]
- Hathaway, R.J.; Bezdek, J.C. Fuzzy c-means clustering of incomplete data. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2001, 31, 735–744. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cui, L.; Li, G.; Lin, Q.; Du, Z.; Gao, W.; Chen, J.; Lu, N. A novel artificial bee colony algorithm with depth-first search framework and elite-guided search equation. Inform. Sci. 2016, 367–368, 1012–1044. [Google Scholar] [CrossRef]
- Xie, L.; Beni, G. A vilidity measure for fuzzy clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Aydilek, I.B.; Arslan, A. A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inform. Sci. 2013, 233, 25–35. [Google Scholar] [CrossRef]
- Yi, D.; Su, J.; Liu, C.; Quddus, M.; Chen, W. A machine learning based personalized system for driving state recognition. Transp. Res. Part C Emerg. Technol. 2019, 105, 241–261. [Google Scholar] [CrossRef]
- Ozkan, I.; Türkşen, I.B. MiniMax ε-stable cluster validity index for Type-2 fuzziness. Inform. Sci. 2012, 184, 64–74. [Google Scholar] [CrossRef]
- Zahid, N.; Abouelala, O. Unsupervised fuzzy clustering. Pattern Recognit. Lett. 1999, 20, 123–129. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Period | Monday | Tuesday | Wednesday | Thursday | Friday |
|---|---|---|---|---|---|
| 00:00–00:05 | 19.50 | 20.50 | 14.00 | 16.50 | 23.00 |
| 00:05–00:10 | 16.00 | ? | 17.00 | 15.00 | 19.50 |
| 23:50–23:55 | 12.00 | ? | 15.50 | ? | 20.00 |
| 23:55–00:00 | 20.00 | 12.50 | ? | 27.00 | 23.50 |
| Time Period | Flow (veh) | Speed (km/h) | Occupation (%) |
|---|---|---|---|
| 00:00–00:05 | 19.50 | 53.06 | 7.69 |
| 00:05–00:10 | ? | 63.70 | 4.71 |
| 23:50–23:55 | 11.5 | 42.51 | 4.87 |
| 23:55–00:00 | ? | 47.94 | 6.08 |
| Parameters | 26 March | 27 March | 28 March | 29 March | 30 March | Baseline |
|---|---|---|---|---|---|---|
| Di | 0.8849 | 0.8740 | 0.8756 | 0.8807 | 0.8672 | 0.9302 |
| Si | 0.9513 | 0.9395 | 0.9413 | 0.9467 | 0.9323 |
| Number | Name | The Mode of Input Data | Method |
|---|---|---|---|
| S1 | TR | TR mode data | TGO-SSA-FCM (Principle 1&2) |
| S2 | AR | AR mode data | TGO-SSA-FCM (Principle 1) |
| S3 | SR | SR & TR mode data | Curve fitting |
| S4 | TR (SSA-FCM) | TR mode data | SSA-FCM |
| S5 | TR (PSO-FCM) | TR mode data | PSO-FCM |
| S6 | History | TR mode data | Historical mean |
| Date | Model Summary | Parameters | ||||||
|---|---|---|---|---|---|---|---|---|
| Model | F | Sig. | Constant | b1 | b2 | b3 | ||
| D1 | Quadratic | 0.813 | 619.943 | 0.000 | −3.448 | 1.196 | −0.002 | |
| D2 | Cubic | 0.828 | 454.469 | 0.000 | 4.107 | 0.662 | 0.011 | −6.947 × 10−5 |
| D3 | Linear | 0.841 | 1510.432 | 0.000 | 3.534 | 1.108 | ||
| D4 | Quadratic | 0.810 | 608.382 | 0.000 | −0.920 | 1.303 | −0.003 | |
| D5 | Power | 0.784 | 1038.502 | 0.000 | 2.525 | 0.790 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Dong, B.; Li, S.; Chu, R. A Repair Method for Missing Traffic Data Based on FCM, Optimized by the Twice Grid Optimization and Sparrow Search Algorithms. Sensors 2022, 22, 4304. https://doi.org/10.3390/s22114304
Li P, Dong B, Li S, Chu R. A Repair Method for Missing Traffic Data Based on FCM, Optimized by the Twice Grid Optimization and Sparrow Search Algorithms. Sensors. 2022; 22(11):4304. https://doi.org/10.3390/s22114304
Chicago/Turabian StyleLi, Pengcheng, Baotian Dong, Sixian Li, and Rusi Chu. 2022. "A Repair Method for Missing Traffic Data Based on FCM, Optimized by the Twice Grid Optimization and Sparrow Search Algorithms" Sensors 22, no. 11: 4304. https://doi.org/10.3390/s22114304
APA StyleLi, P., Dong, B., Li, S., & Chu, R. (2022). A Repair Method for Missing Traffic Data Based on FCM, Optimized by the Twice Grid Optimization and Sparrow Search Algorithms. Sensors, 22(11), 4304. https://doi.org/10.3390/s22114304