
A Dynamic Convolution Kernel Generation Method Based on Regularized Pattern for Image Super-Resolution



Abstract
:1. Introduction
2. Proposed Dynamic Convolution Kernel Generation Based on Regularized Pattern for Image Super-Resolution
2.1. Proposed Regularized Pattern Extraction Method
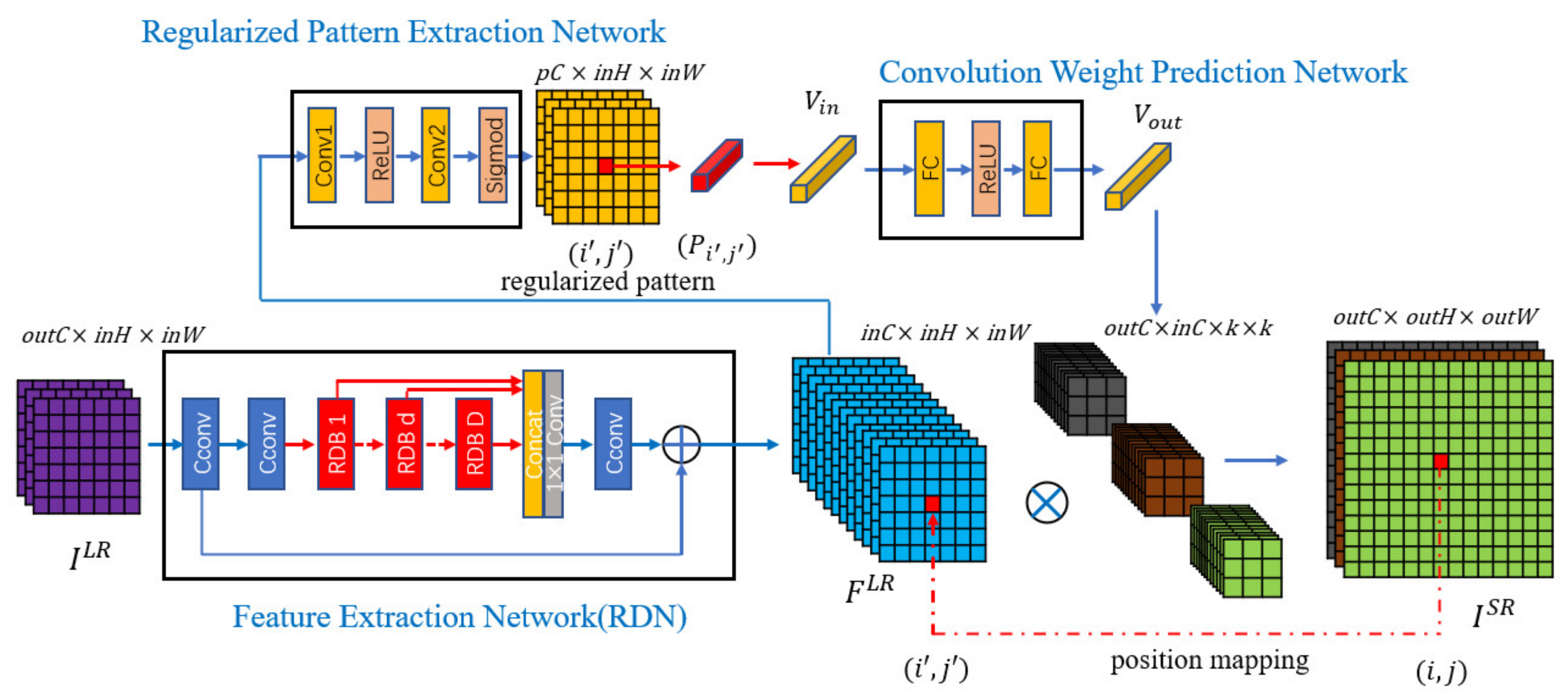
2.2. Proposed Dynamic Convolution Kernel Generation Method
- Sixth, for the generated SR image patch, the L1 loss function is used to measure the error between the SR image patch and the HR image patchwhere is the error between and in current task with the scale factor . In each task, the regularized pattern extraction network parameters and convolution weight prediction network parameters are updated using gradient descent:where and are the parameters before the update, and are the parameters after the update, and is the learning rate.
- By continuously extracting different scale factors from the distribution as different tasks to train the model, the parameters and are continuously updated. The purpose of meta-learning training is to obtain appropriate parameters and , so that the sum of task losses of all the scale factors sampled in the distribution is the smallest.
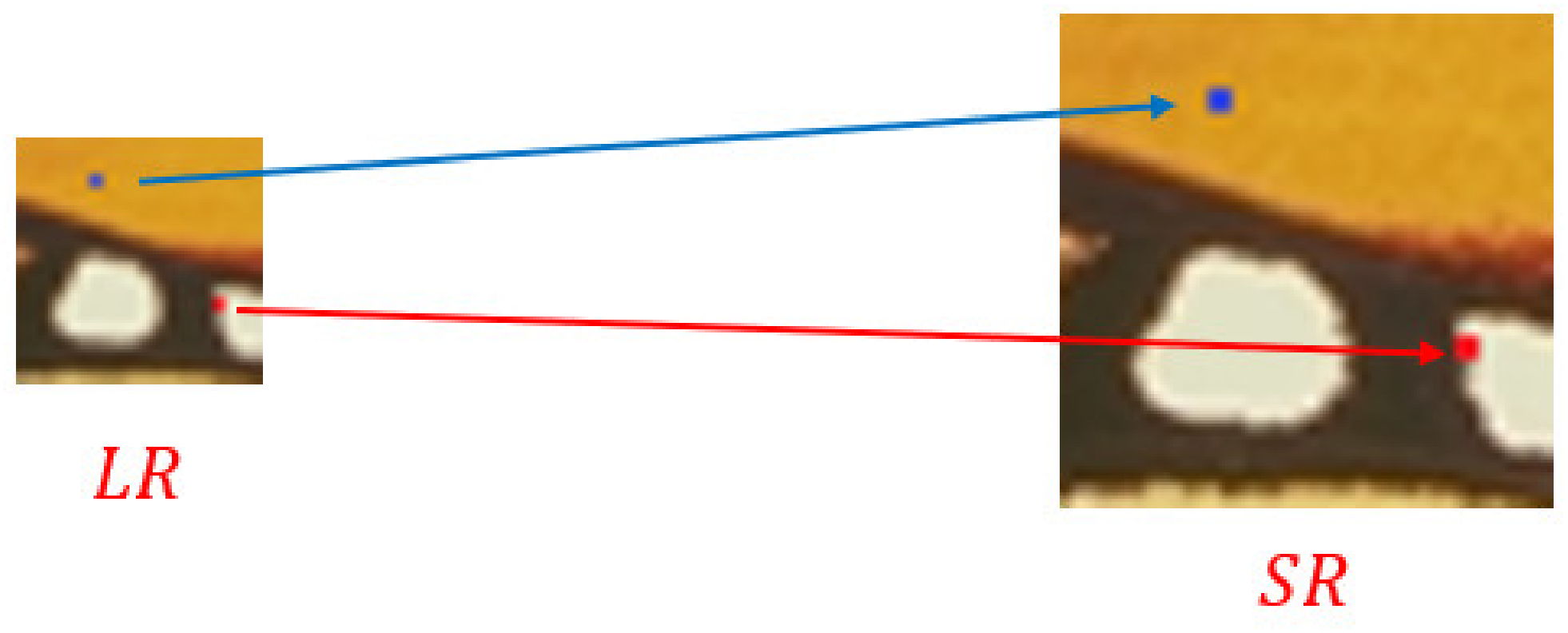
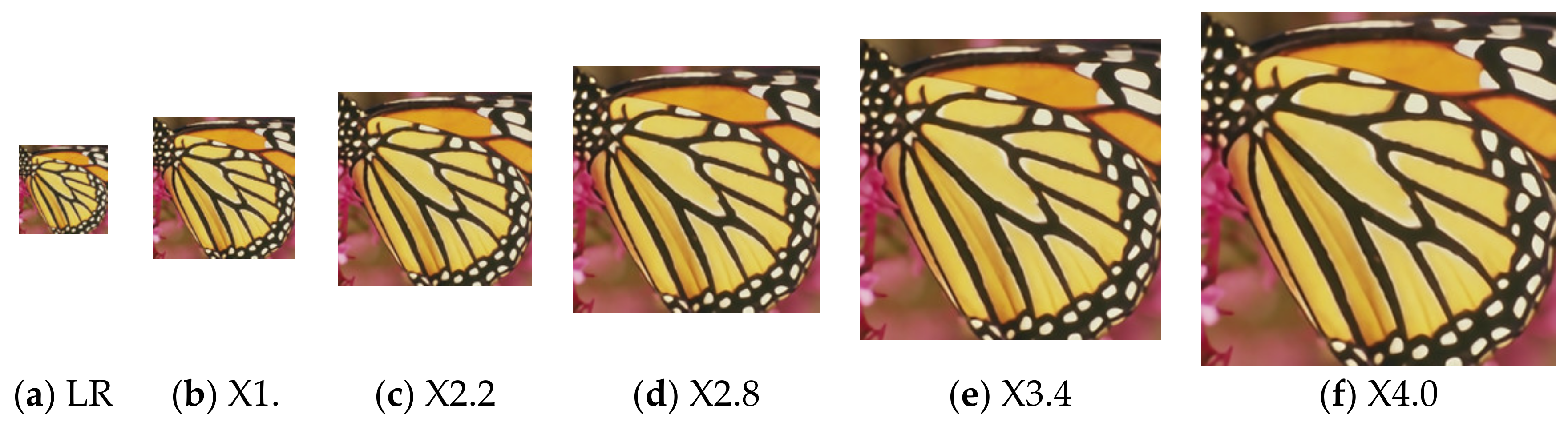
- Finally, we use the trained network for the inference. Suppose that the scale factor of the current task is , the length of the input LR image corresponding to the current task is , and the width is , so the length of the SR image is ⌊⌋, and the width is ⌊⌋. For each pixel in the SR image, the convolution weight prediction network generates a convolution kernel matching its regularized pattern according to Equation (7). Then the generated convolution kernel is used to map the LR features of the corresponding positions to RGB values according to Equation (9), and finally, the SR image is formed. Figure 2 is an example of SR images generated with scale factors of 1.6, 2.2, 2.8, 3.4, and 4.0, respectively.
2.3. Justification of the Proposed Dynamic Convolution Kernel Generation Method
2.4. Proposed Image Super-Resolution Approach
3. Experimental Results
3.1. Experimental Setup
3.2. Implementation Details
3.3. Performance Evaluation on the Proposed Regularized Pattern Extraction Method
3.4. Performance Evaluation on the Proposed Convolution Weight Prediction Method
3.5. Performance Evaluation on the Inference Time
3.6. The Superior of the Proposed Method in Texture Reconstruction
3.7. Performance Comparison with Other SOTA Methods
3.8. Qualitative Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jian, M.; Lam, K. Simultaneous Hallucination and Recognition of Low-Resolution Faces Based on Singular Value Decomposition. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1761–1772. [Google Scholar] [CrossRef]
- Jian, M.; Cui, C.; Nie, X.; Zhang, H.; Nie, L.; Yin, Y. Multi-view face hallucination using SVD and a mapping model. Inf. Sci. 2019, 488, 181–189. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 184–189. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2790–2798. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 4549–4557. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 1874–1883. [Google Scholar]
- Lim, B.; Son, S.; Kim, H. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 1132–1140. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 2472–2481. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual Feature Aggregation Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2356–2365. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.; Zhang, L. Second-order Attention Network for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE Computer Society: Los Alamitos, CA, USA, 2019; pp. 11057–11066. [Google Scholar]
- Li, L.; Feng, H.; Zheng, B.; Ma, L.; Tian, J. DID: A nested dense in dense structure with variable local dense blocks for super-resolution image reconstruction. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2582–2589. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. arXiv 2020, arXiv:2004.05439. [Google Scholar] [CrossRef] [PubMed]
- Ha, D.; Dai, A.; Le, Q.V. HyperNetworks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A Magnification-Arbitrary Network for Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE Computer Society: Los Alamitos, CA, USA, 2019; pp. 1575–1584. [Google Scholar]
- Chen, Y.; Liu, S.; Wang, X. Learning Continuous Image Representation with Local Implicit Image Function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 416–423. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Morel, A. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference (BMVC), Guildford, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24-30 June 2010; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Metric | B100 [19] | Urban100 [20] | Manga109 [21] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| X2 | X3 | X4 | X2 | X3 | X4 | X2 | X3 | X4 | ||
| Baseline model | PSNR SSIM | 32.34 0.9011 | 29.27 0.8089 | 27.75 0.7417 | 33.00 0.9359 | 28.90 0.8668 | 26.68 0.8042 | 39.31 0.9781 | 34.41 0.9491 | 31.36 0.9173 |
| RPB-RDN (Ours) | PSNR SSIM | 32.36 0.9014 | 29.30 0.8095 | 27.76 0.7421 | 33.04 0.9363 | 28.95 0.8677 | 26.73 0.8054 | 39.35 0.9782 | 34.46 0.9494 | 31.39 0.9177 |
| Methods | X1.1 | X1.2 | X1.3 | X1.4 | X1.5 | X1.6 | X1.7 | X1.8 | X1.9 | X2.0 |
|---|---|---|---|---|---|---|---|---|---|---|
| Bicubic | 36.56 | 35.01 | 33.84 | 32.93 | 32.14 | 31.49 | 30.90 | 30.38 | 29.97 | 29.55 |
| Meta-RDN [16] | 42.82 | 40.04 | 38.28 | 36.95 | 35.86 | 34.90 | 34.13 | 33.45 | 32.86 | 32.35 |
| Ours | 43.03 | 40.11 | 38.34 | 36.96 | 35.86 | 34.91 | 34.14 | 33.46 | 32.86 | 32.36 |
| Methods | X2.1 | X2.2 | X2.3 | X2.4 | X2.5 | X2.6 | X2.7 | X2.8 | X2.9 | X3.0 |
| Bicubic | 29.18 | 28.87 | 28.57 | 28.31 | 28.13 | 27.89 | 27.66 | 27.51 | 27.31 | 27.19 |
| Meta-RDN [16] | 31.82 | 31.41 | 31.06 | 30.62 | 30.45 | 30.13 | 29.82 | 29.67 | 29.40 | 29.30 |
| Ours | 31.88 | 31.45 | 31.07 | 30.75 | 30.48 | 30.17 | 29.95 | 29.72 | 29.49 | 29.30 |
| Methods | X3.1 | X3.2 | X3.3 | X3.4 | X3.5 | X3.6 | X3.7 | X3.8 | X3.9 | X4.0 |
| Bicubic | 26.98 | 26.89 | 26.59 | 26.60 | 26.42 | 26.35 | 26.15 | 26.07 | 26.01 | 25.96 |
| Meta-RDN [16] | 28.87 | 28.79 | 28.68 | 28.54 | 28.32 | 28.27 | 28.04 | 27.92 | 27.82 | 27.75 |
| Ours | 29.09 | 28.90 | 28.73 | 28.57 | 28.42 | 28.27 | 28.15 | 28.01 | 27.88 | 27.76 |
| Methods | X2 | X3 | X4 |
|---|---|---|---|
| RDN | 12.8 | 12.9 | 13.0 |
| Meta-RDN [16] | 14.4 | 14.8 | 16.4 |
| LIIF-RDN [17] | 21.3 | 22.7 | 24.9 |
| RPB-RDN (Ours) | 15.1 | 15.3 | 16.5 |
| Methods | Metric | X2 | X3 | X4 |
|---|---|---|---|---|
| Meta-RDN [16] | PSNR(dB)/SSIM | 34.22/0.9312 | 30.30/0.8601 | 28.08/0.7976 |
| LIIF-RDN [17] | 34.19/0.9309 | 30.31/0.8601 | 28.09/0.7975 | |
| RPB-RDN (Ours) | 34.38/0.9318 | 30.45/0.8611 | 28.17/0.7981 |
| Dataset | The PSNR (dB) Performance | |||||
|---|---|---|---|---|---|---|
| Scale Factor | Bicubic | RDN [10] | Meta-RDN [16] | LIIF-RDN [17] | Ours | |
| Set5 [22] | X2 X3 X4 | 33.66 30.39 28.42 | 38.24 34.71 32.47 | 38.22 34.63 32.38 | 38.17 34.68 32.50 | 38.23 34.74 32.50 |
| Set14 [23] | X2 X3 X4 | 30.24 27.55 26.00 | 34.01 30.57 28.81 | 34.04 30.55 28.84 | 33.97 30.53 28.80 | 34.05 30.56 28.86 |
| B100 [19] | X2 X3 X4 | 29.56 27.21 25.96 | 32.34 29.26 27.72 | 32.35 29.30 27.75 | 32.32 29.26 27.74 | 32.36 29.30 27.76 |
| Urban100 [20] | X2 X3 X4 | 26.88 24.46 23.14 | 32.89 28.80 26.61 | 32.92 28.82 26.55 | 32.87 28.82 26.68 | 33.04 28.95 26.73 |
| Manga109 [21] | X2 X3 X4 | 30.80 26.95 24.89 | 39.18 34.13 31.00 | 39.18 34.14 31.03 | 39.01 34.13 31.18 | 39.35 34.46 31.39 |
| Dataset | The SSIM Performance | |||||
| Scale factor | Bicubic | RDN [10] | Meta-RDN [16] | LIIF-RDN [17] | Ours | |
| Set5 [22] | X2 X3 X4 | 0.9299 0.8682 0.8104 | 0.9614 0.9296 0.8990 | 0.9611 0.9298 0.8989 | 0.9610 0.9293 0.8986 | 0.9611 0.9298 0.8990 |
| Set14 [23] | X2 X3 X4 | 0.8688 0.7742 0.7027 | 0.9212 0.8468 0.7871 | 0.9213 0.8466 0.7872 | 0.9208 0.8470 0.7876 | 0.9214 0.8470 0.7881 |
| B100 [19] | X2 X3 X4 | 0.8431 0.7385 0.6675 | 0.9017 0.8093 0.7419 | 0.9019 0.8096 0.7423 | 0.9010 0.8096 0.7422 | 0.9014 0.8095 0.7421 |
| Urban100 [20] | X2 X3 X4 | 0.8403 0.7349 0.6577 | 0.9353 0.8653 0.8028 | 0.9361 0.8674 0.8054 | 0.9350 0.8662 0.8040 | 0.9363 0.8677 0.8054 |
| Manga109 [21] | X2 X3 X4 | 0.9339 0.8556 0.7866 | 0.9780 0.9484 0.9151 | 0.9782 0.9483 0.9154 | 0.9780 0.9487 0.9170 | 0.9782 0.9494 0.9177 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, H.; Ma, L.; Tian, J. A Dynamic Convolution Kernel Generation Method Based on Regularized Pattern for Image Super-Resolution. Sensors 2022, 22, 4231. https://doi.org/10.3390/s22114231
Feng H, Ma L, Tian J. A Dynamic Convolution Kernel Generation Method Based on Regularized Pattern for Image Super-Resolution. Sensors. 2022; 22(11):4231. https://doi.org/10.3390/s22114231
Chicago/Turabian StyleFeng, Hesen, Lihong Ma, and Jing Tian. 2022. "A Dynamic Convolution Kernel Generation Method Based on Regularized Pattern for Image Super-Resolution" Sensors 22, no. 11: 4231. https://doi.org/10.3390/s22114231
APA StyleFeng, H., Ma, L., & Tian, J. (2022). A Dynamic Convolution Kernel Generation Method Based on Regularized Pattern for Image Super-Resolution. Sensors, 22(11), 4231. https://doi.org/10.3390/s22114231