
Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN


Abstract
:1. Introduction
2. Materials and Methods
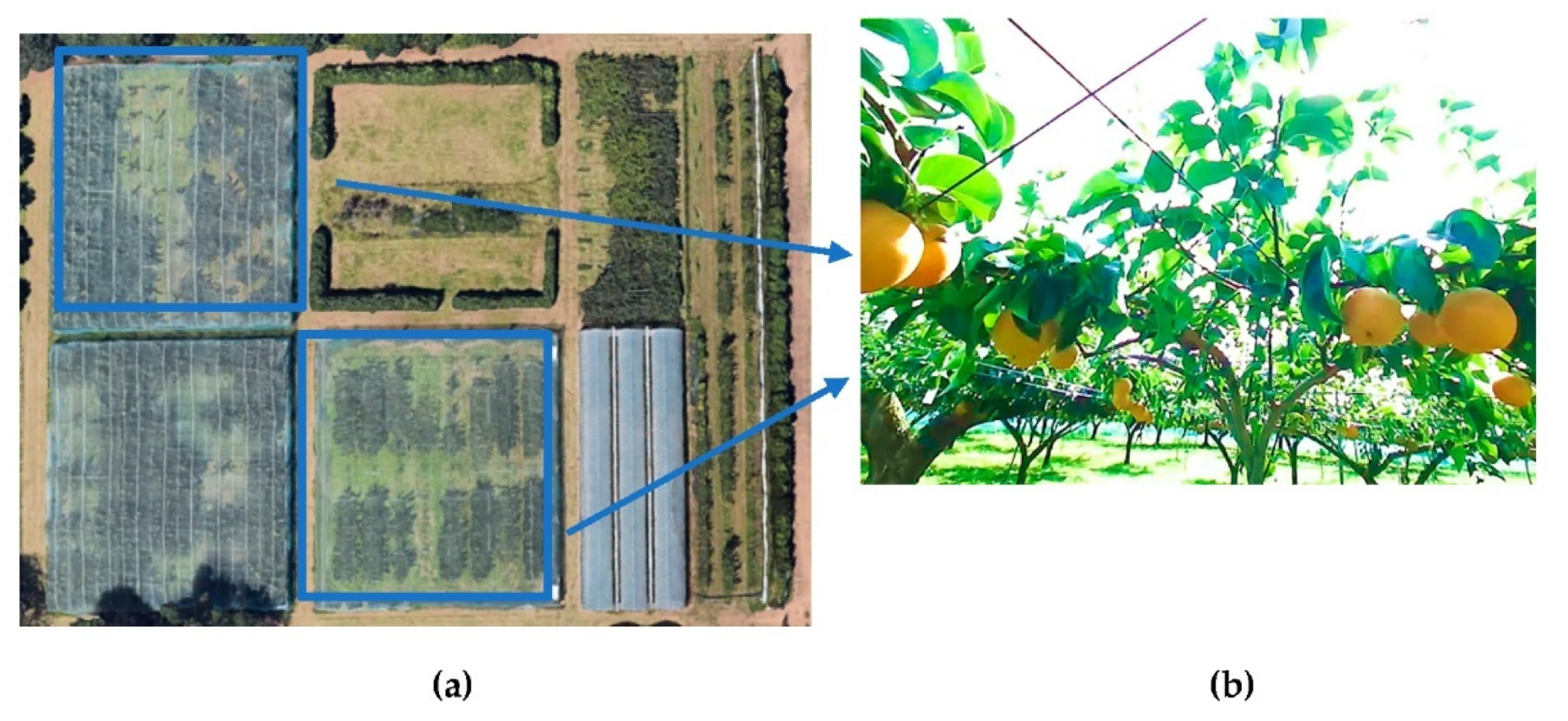
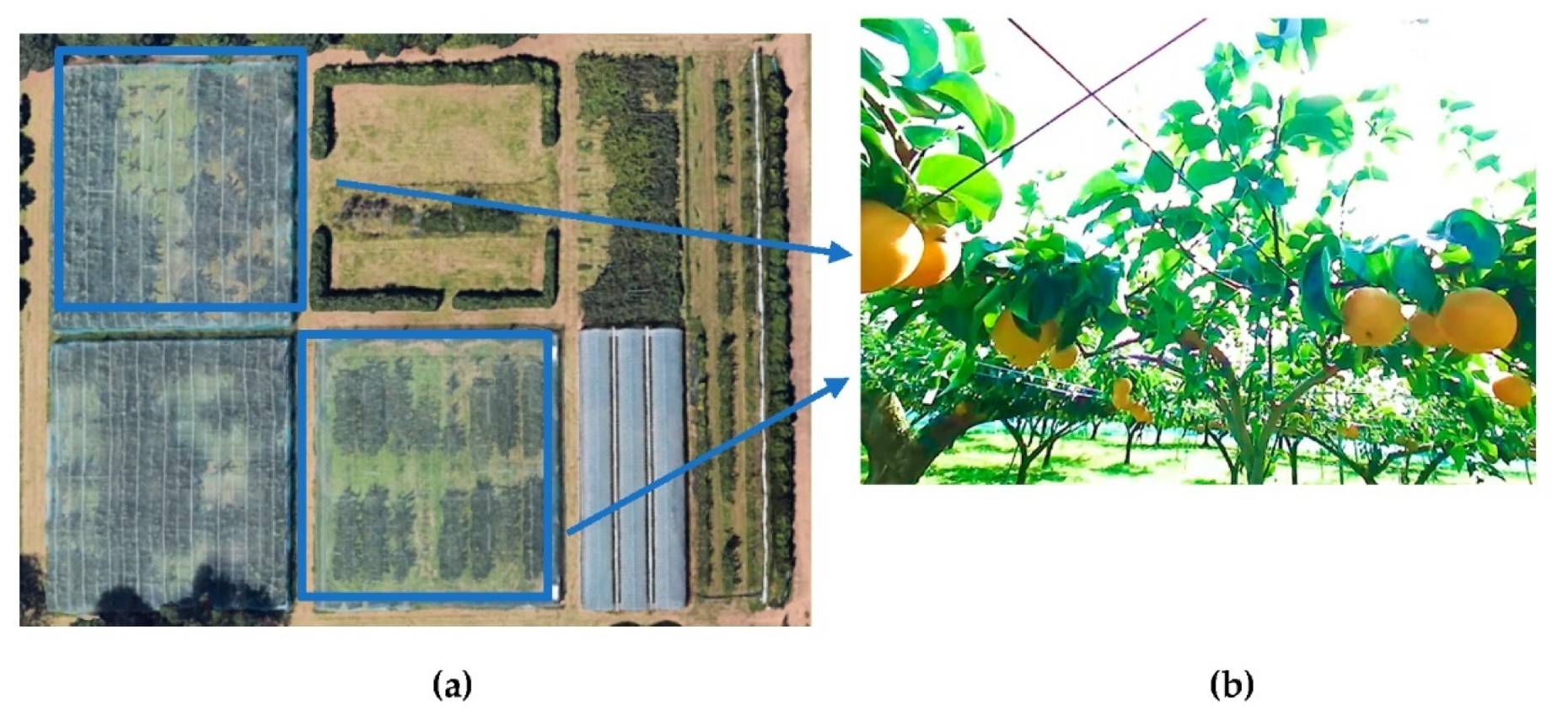
2.1. Field Data Collection
2.2. Instance Segmentation
2.3. Mask R-CNN
2.4. ZED AI Stereo Camera
2.5. Data Preparation
2.5.1. Deep Learning Environment
2.5.2. Video to Image Conversion
2.5.3. Image Annotation
2.6. Data Splitting
2.7. Training Process of Mask R-CNN
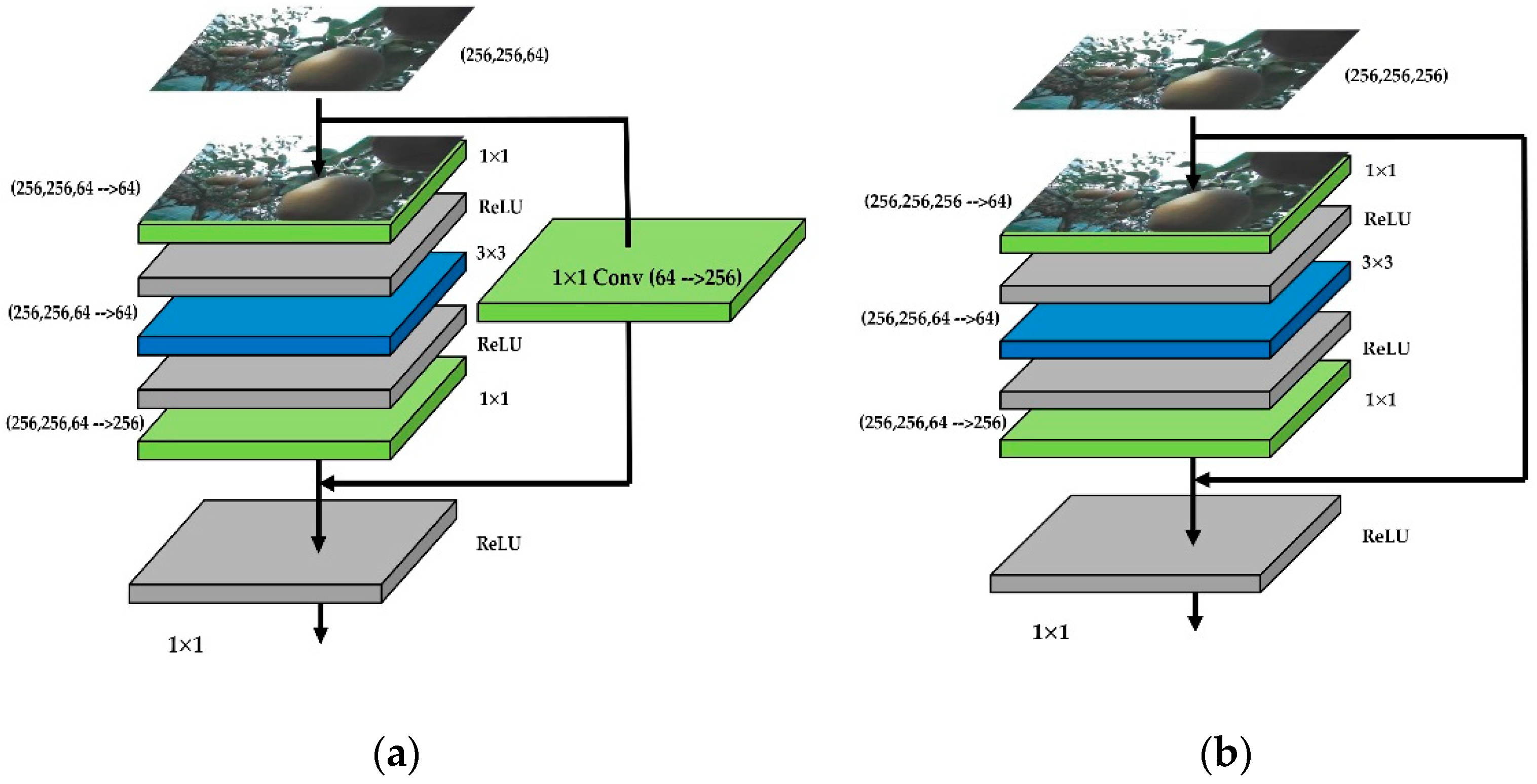
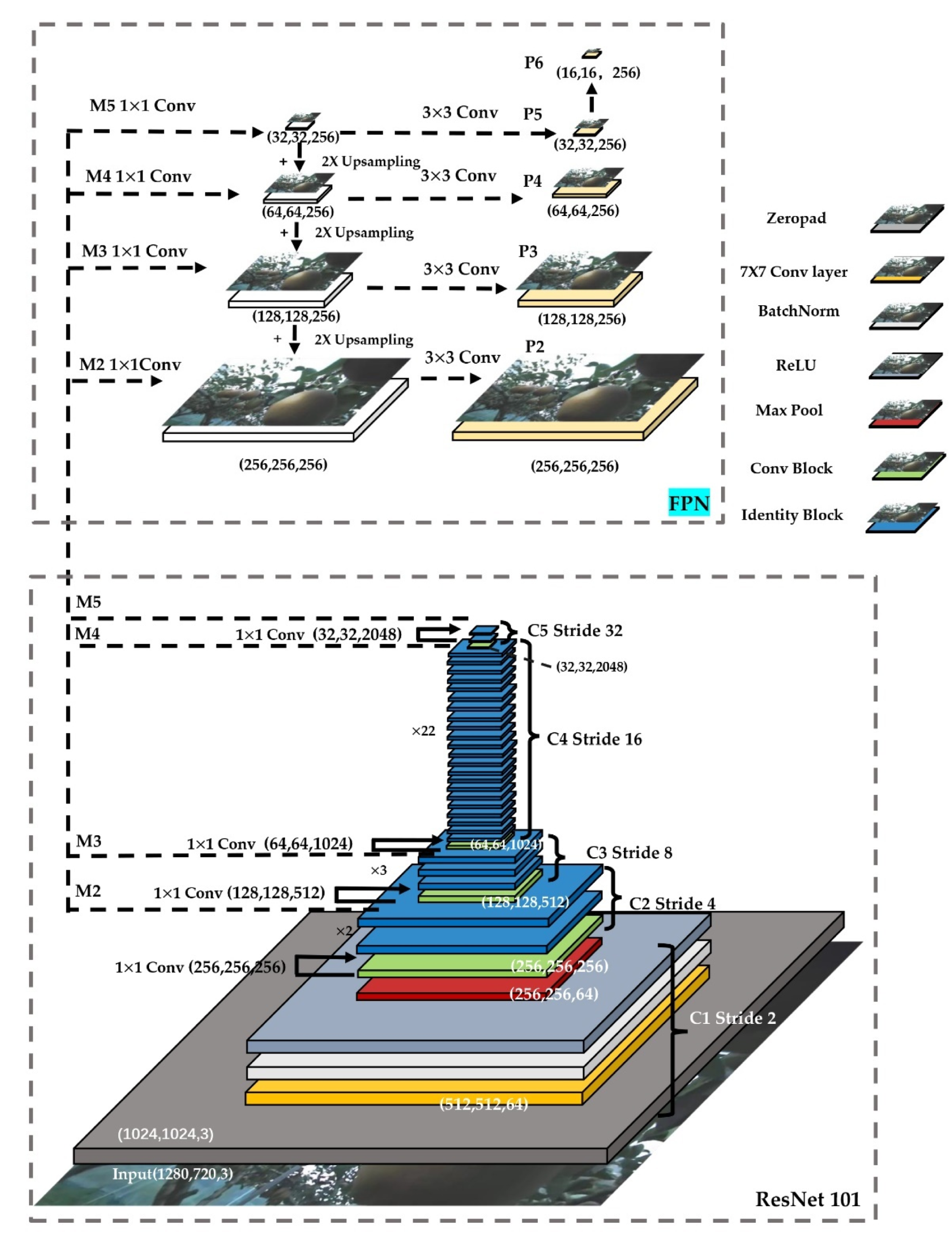
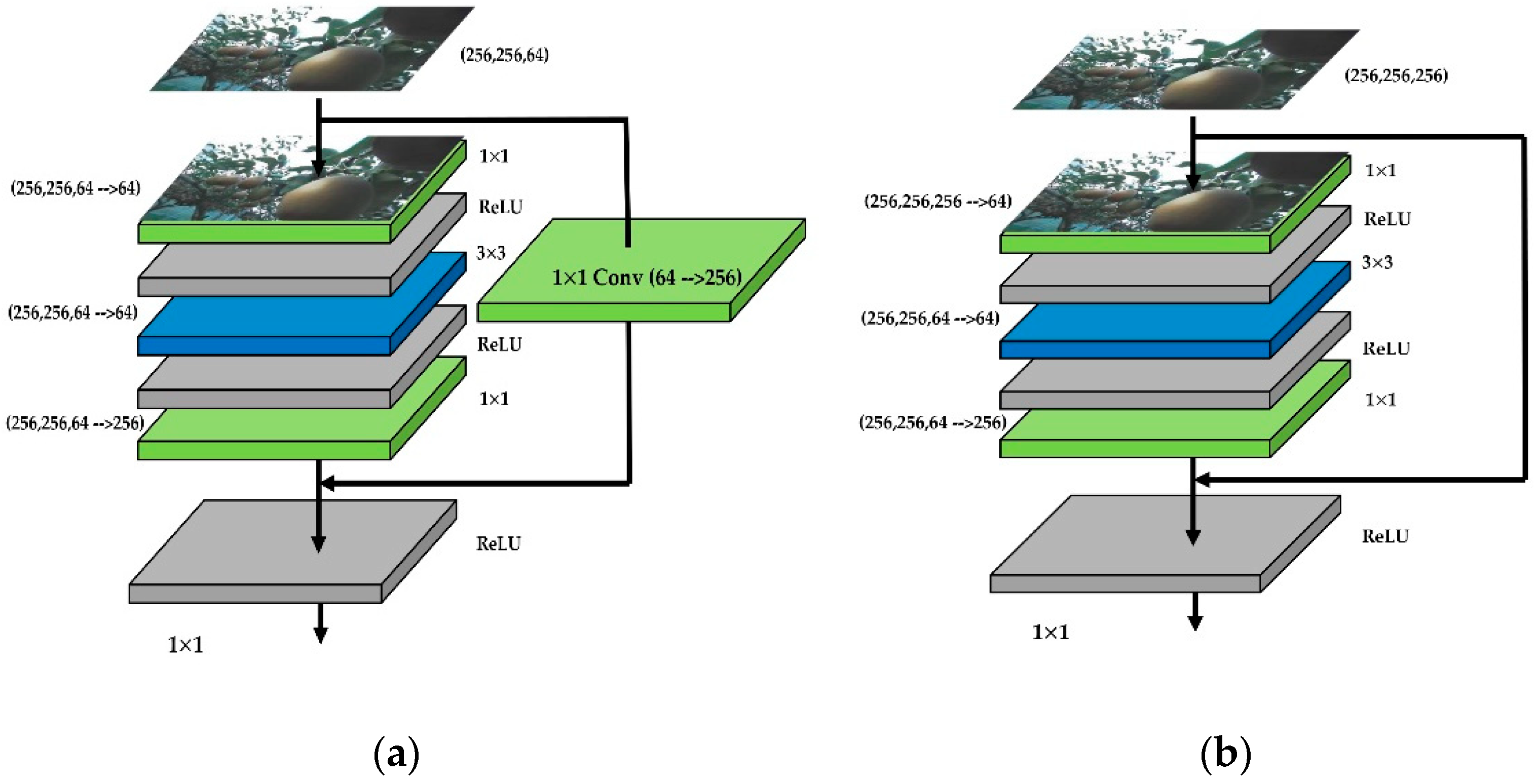
2.7.1. Feature Extraction (Backbone: ResNet101 + FPN)
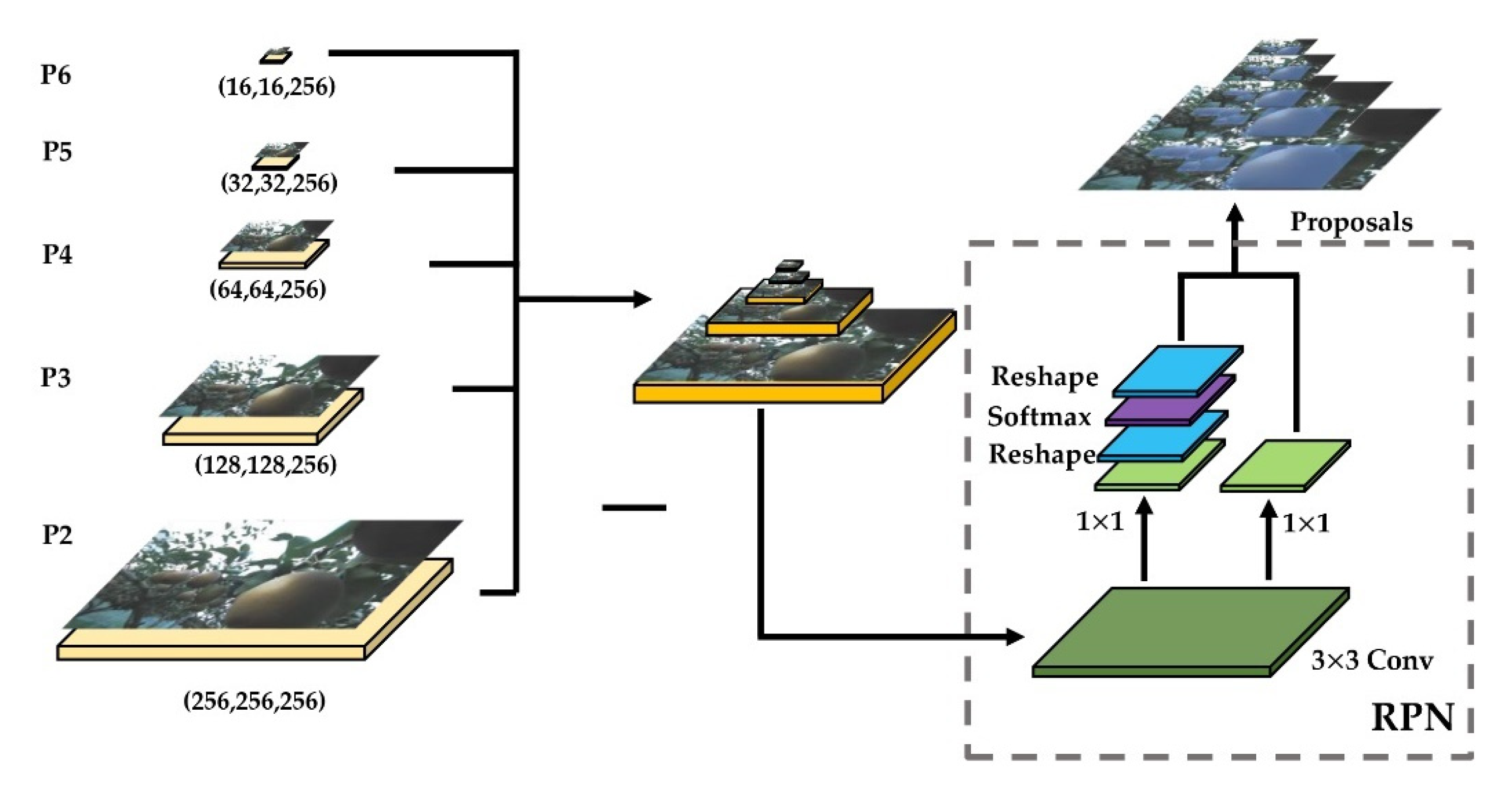
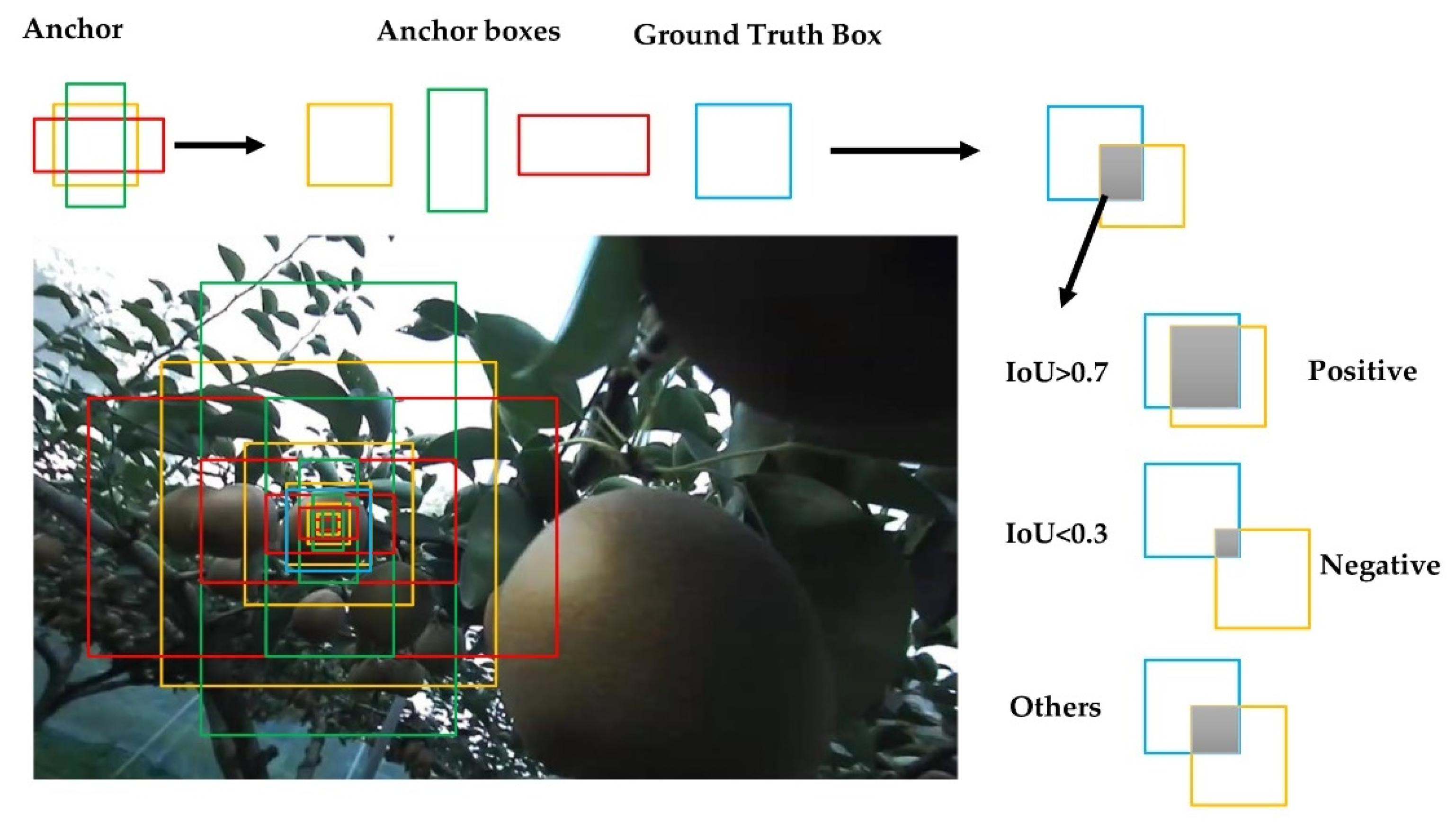
2.7.2. Region Proposal Network (RPN)
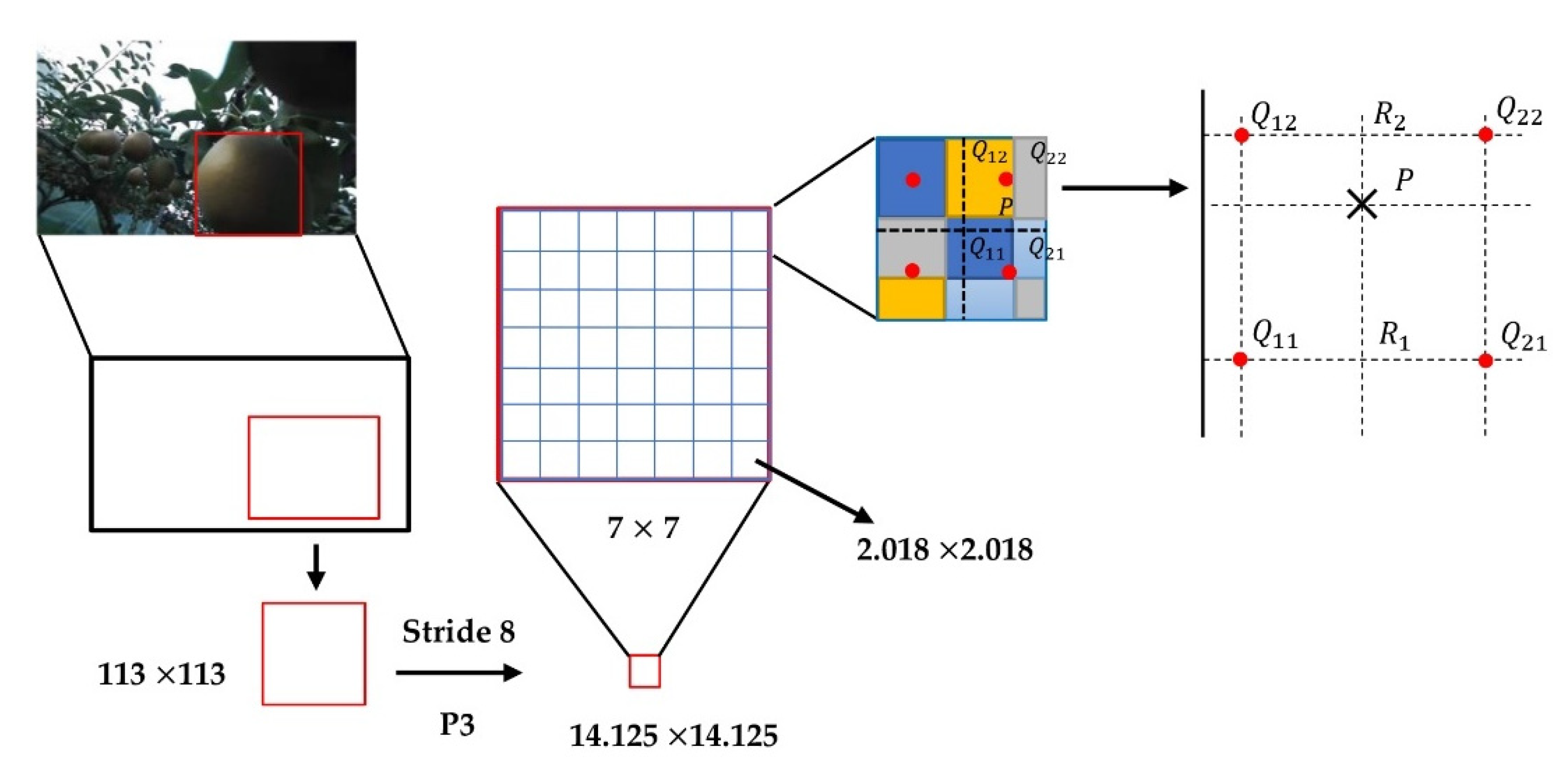
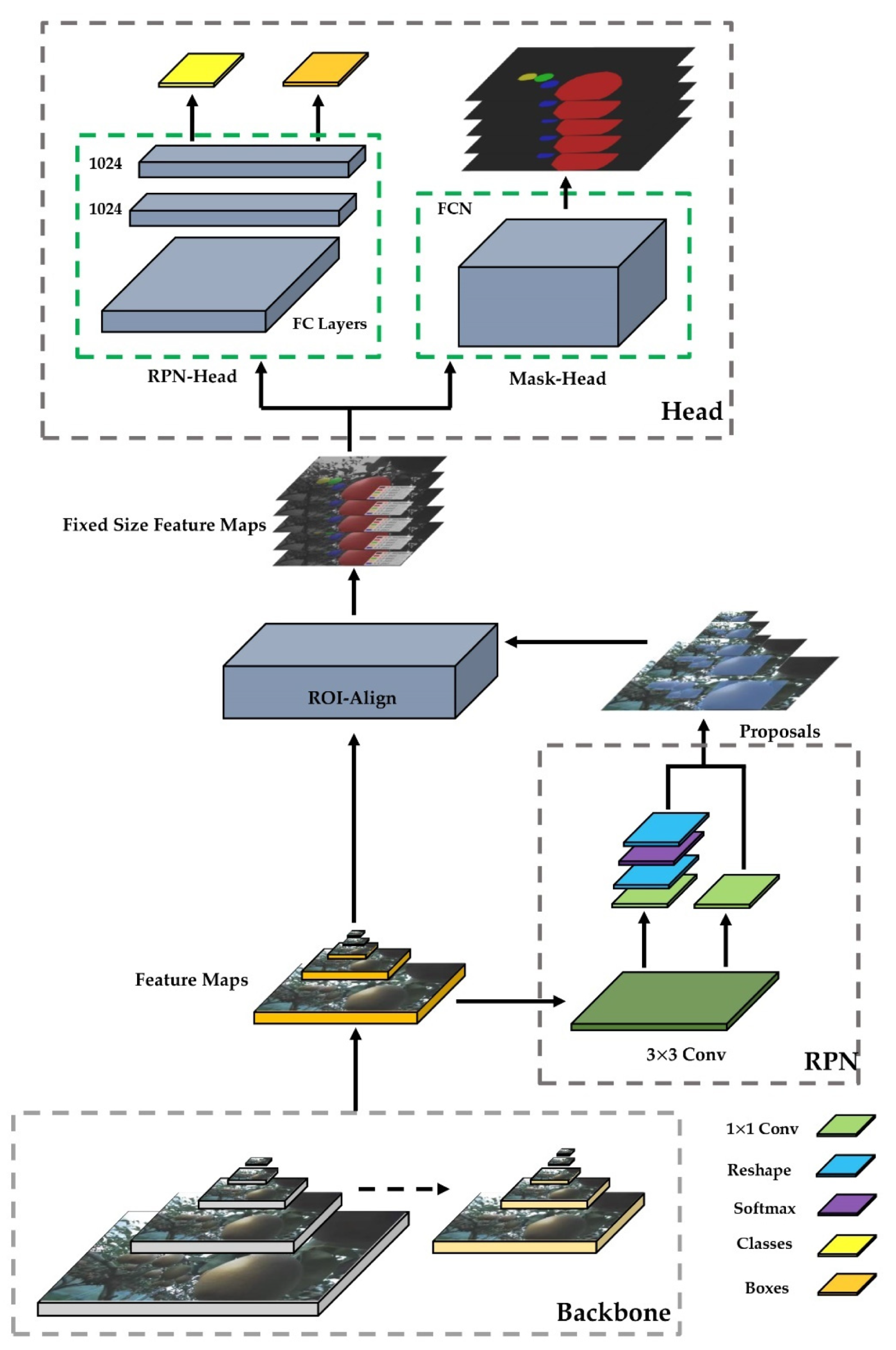
2.7.3. ROIs and ROI-Align
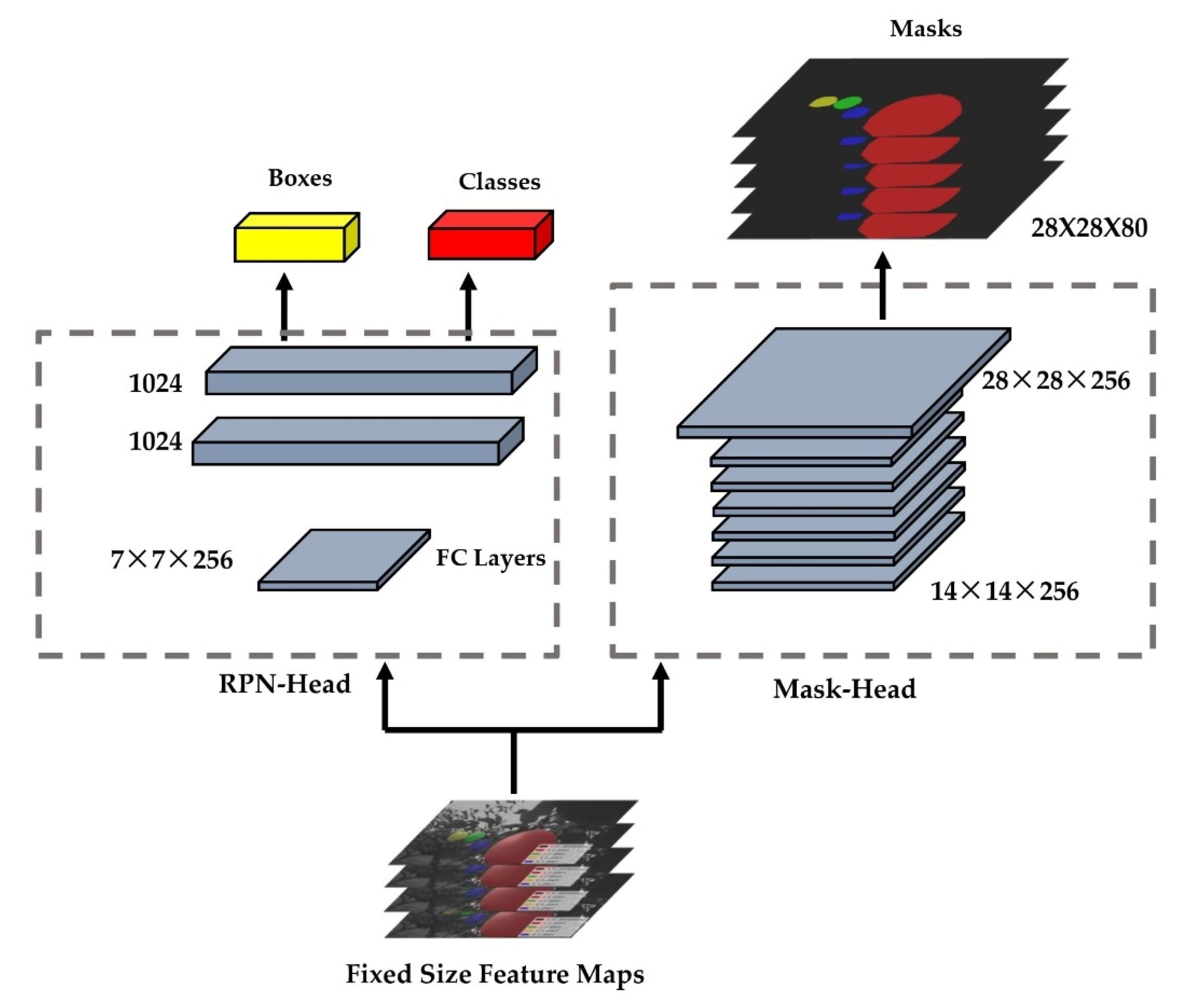
2.7.4. Mask RCNN for Classification and Regression
2.7.5. Loss Function
| Algorithm 1. Training Phase in Mask R-CNN |
| 1. Inputs: |
| 2. Dataset_train: , |
| 3. Datset_val: ,where M, N are the number of images. |
| 4. if mode = “training” |
| 5. Get object index in , |
| 6. Extraction from ResNet101 to |
| 7. Anchor generation from |
| 8. BG and FG generation from via (Equations (1) and (2)) |
| 9. Calculated the via (Equations (4)–(9)) |
| 10. ROIs Generation from |
| 11. Masks, boxes, classes Generation from |
| 12. Calculate the loss of the head layer via (Equation (12)) |
| 13. Save_logs_weights() |
| 14. Return: |
| 15. |
| Algorithm 2. Testing Phase in Mask R-CNN |
| 1. Inputs: |
| 2. Dataset_Test: , where M is the number of images. |
| 3. GPU_COUNT = 1 |
| 4. IMAGES_PER_GPU = 1 |
| 5. if mode =” inference” |
| 6. Model.load_weights () |
| 7. For i in range (): |
| 8. Input |
| 9. Generated |
| 10. |
| 11. Generated |
| 12. Created for detections |
| 13. Return: |
| 14. , masks, class_id, class_name, scores |
| 15. Visualize.display_instances |
| Algorithm. 3 Training Phase in Faster R-CNN |
| 1. Inputs: |
| 2. Dataset_train: , |
| 3. Datset_val: , where M, N is the number of images. |
| 4. if mode = “training” |
| 5. Get object index in . |
| 6. Extraction from (Visual Geometry Group Network) |
| 7. Region proposals generation from |
| 8. ROIs generation from |
| 9. Classification from |
| 10. Calculated |
| 11. Save_logs_weights |
| 12. Return: |
| 13. logs_weights, LRPN |
| Algorithm 4. Testing Phase in Faster R-CNN |
| 1. Inputs: |
| 2. Dataset_Test: , where M is the number of images. |
| 3. if mode =” inference” |
| 4. Model.load_weights |
| 5. For i in range (): |
| 6. Input |
| 7. Generated |
| 8. |
| 9. Generated |
| 10. Return: |
| 11. , |
| 12. Visualize.display_instances |
2.7.6. Model Metrics Function
3. Results
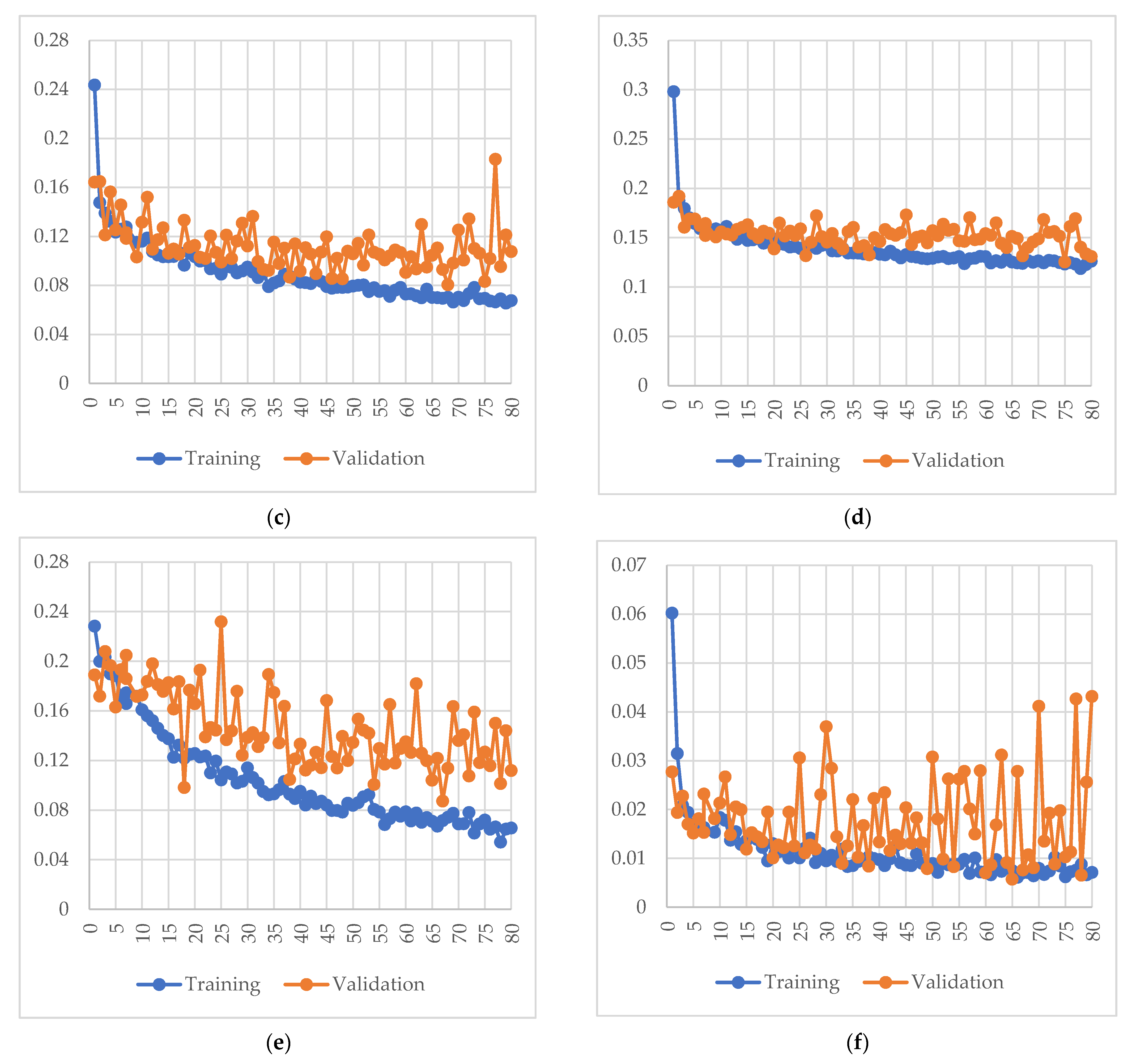
3.1. Training Details
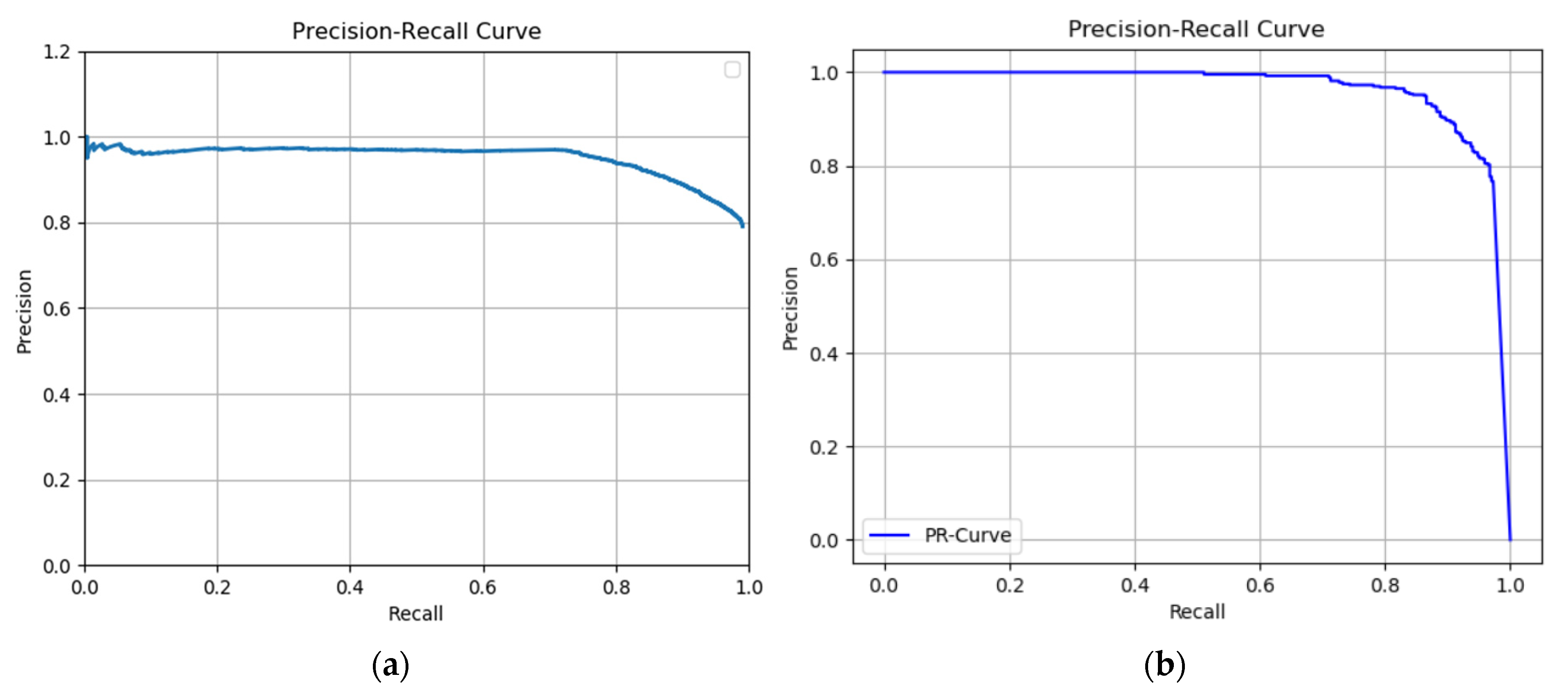
3.2. Evaluation of Model Metrics
3.3. Evaluation of Model Effectiveness
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barua, S. Understanding Coronanomics: The Economic Implications of the Coronavirus (COVID-19) Pandemic. Available online: https://ssrn.com/abstract=3566477 (accessed on 1 April 2020).
- Saito, T. Advances in Japanese pear breeding in Japan. Breed. Sci. 2016, 66, 46–59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schrder, C. Employment in European Agriculture: Labour Costs, Flexibility and Contractual Aspects. 2014. Available online: agricultura.gencat.cat/web/.content/de_departament/de02_estadistiques_observatoris/27_butlletins/02_butlletins_nd/documents_nd/fitxers_estatics_nd/2017/0193_2017_Ocupacio_Agraria-UE-2014.pdf (accessed on 1 April 2020).
- Wei, X.; Jia, K.; Lan, J.; Li, Y.; Zeng, Y.; Wang, C. Automatic method of fruit object extraction under complex agricultural background for vision system of fruit picking robot. Optik 2004, 125, 5684–5689. [Google Scholar] [CrossRef]
- Bechar, A.; Vigneault, C. Agricultural robots for field operations: Concepts and components. Biosyst. Eng. 2016, 149, 94–111. [Google Scholar] [CrossRef]
- Hannan, M.W.; Burks, T.F. Current developments in automated citrus harvesting. In Proceedings of the 2004 ASAE Annual Meeting, Ottawa, ON, Canada, 1–4 August 2004; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2004; p. 043087. [Google Scholar]
- Ertam, F.; Aydın, G. Data classification with deep learning using Tensorflow. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; pp. 755–758. [Google Scholar]
- Boniecki, P.H. Piekarska-Boniecka. The SOFM type neural networks in the process of identification of selected orchard pests. J. Res. Appl. Agric. Eng. 2004, 49, 5–9. [Google Scholar]
- LeCun, Y.; Yoshua, B.; Geoffrey, H. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Kaiming, H.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Dorrer, M.G.; Tolmacheva, A.E. Comparison of the YOLOv3 and Mask R-CNN architectures’ efficiency in the smart refrigerator’s computer vision. J. Phys. Conf. Ser. 2020, 1679, 042022. [Google Scholar] [CrossRef]
- Sobol, Z.; Jakubowski, T.; Nawara, P. Application of the CIE L* a* b* Method for the Evaluation of the Color of Fried Products from Potato Tubers Exposed to C Band Ultraviolet Light. Sustainability (2071-1050) 2020, 12, 3487. [Google Scholar]
- Boniecki, P.; Koszela, K.; Przybylak, A. Classification of Selected Apples Varieties and Dried Carrots using Neural Network Type Kohonen. J. Res. Appl. Agric. Eng. 2010, 55, 11–15. [Google Scholar]
- Jiang, A.; Noguchi, R.; Ahamed, T. Tree Trunk Recognition in Orchard Autonomous Operations under Different Light Conditions Using a Thermal Camera and Faster R-CNN. Sensors 2022, 22, 2065. [Google Scholar] [CrossRef]
- Ortiz, L.E.; Cabrera, V.E.; Goncalves, L.M. Depth data error modeling of the ZED 3D vision sensor from stereolabs. ELCVIA Electron. Lett. Comput. Vis. Image Anal. 2018, 17, 1–15. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kirkland, E.J. Bilinear interpolation. In Advanced Computing in Electron Microscopy; Springer: Boston, MA, USA, 2010; pp. 261–263. [Google Scholar]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tran, T.M. A Study on Determination of Simple Objects Volume Using ZED Stereo Camera Based on 3D-Points and Segmentation Images. Int. J. Emerg. Trends Eng. Res. 2020, 8, 1990–1995. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Murphy, K. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Parico, A.I.B.; Ahamed, T. Real time pear fruit detection and counting using YOLOv4 models and deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Time | Light Condition |
|---|---|---|
| 24 August 2021 | 9:00–10:00 | High light |
| 24 August 2021 | 18:00–19:00 | Low light |
| Model | Validation Set | Testing Set |
|---|---|---|
| Faster R-CNN | 87.90% | 87.52 |
| Mask R-CNN | 95.22% | 99.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, S.; Ahamed, T. Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN. Sensors 2022, 22, 4187. https://doi.org/10.3390/s22114187
Pan S, Ahamed T. Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN. Sensors. 2022; 22(11):4187. https://doi.org/10.3390/s22114187
Chicago/Turabian StylePan, Siyu, and Tofael Ahamed. 2022. "Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN" Sensors 22, no. 11: 4187. https://doi.org/10.3390/s22114187
APA StylePan, S., & Ahamed, T. (2022). Pear Recognition in an Orchard from 3D Stereo Camera Datasets to Develop a Fruit Picking Mechanism Using Mask R-CNN. Sensors, 22(11), 4187. https://doi.org/10.3390/s22114187