
Machine-Learning Approach for Automatic Detection of Wild Beluga Whales from Hand-Held Camera Pictures

 ,
,  ,
,
Abstract
:1. Introduction
- Shortage. Belugas are infrequently seen by humans and only emerge on the water surface for a few seconds at a time;
- Distracter objects. Objects, such as waves, shadows, foam, and sun glare, can be visually similar to belugas, and have to be distinguished to reduce the false-positive detection rate. More precisely, these objects are regarded as distracter samples (or false positives), as seen in Figure 1;
- Multiple objects. Belugas swim in groups and stay close to each other on the scene, making detection difficult when more than one beluga appears overlapped or occluded (see Figure 1i);
- Partially visible. Mostly, a beluga’s body can be observed only partially (see Figure 1d);
- Image orientations. Beluga postures or behaviors captured in a snapshot are quite variable since different parts of bodies can be emerged or submerged (e.g., blowing, logging, etc.) (see Figure 1g);
- Low efficiency in data annotation. The annotation of belugas on long-term captured images requires checking each image and drawing boxes around belugas in a wide sea view, which is slow and requires intensive human labor.
2. Materials and Methods
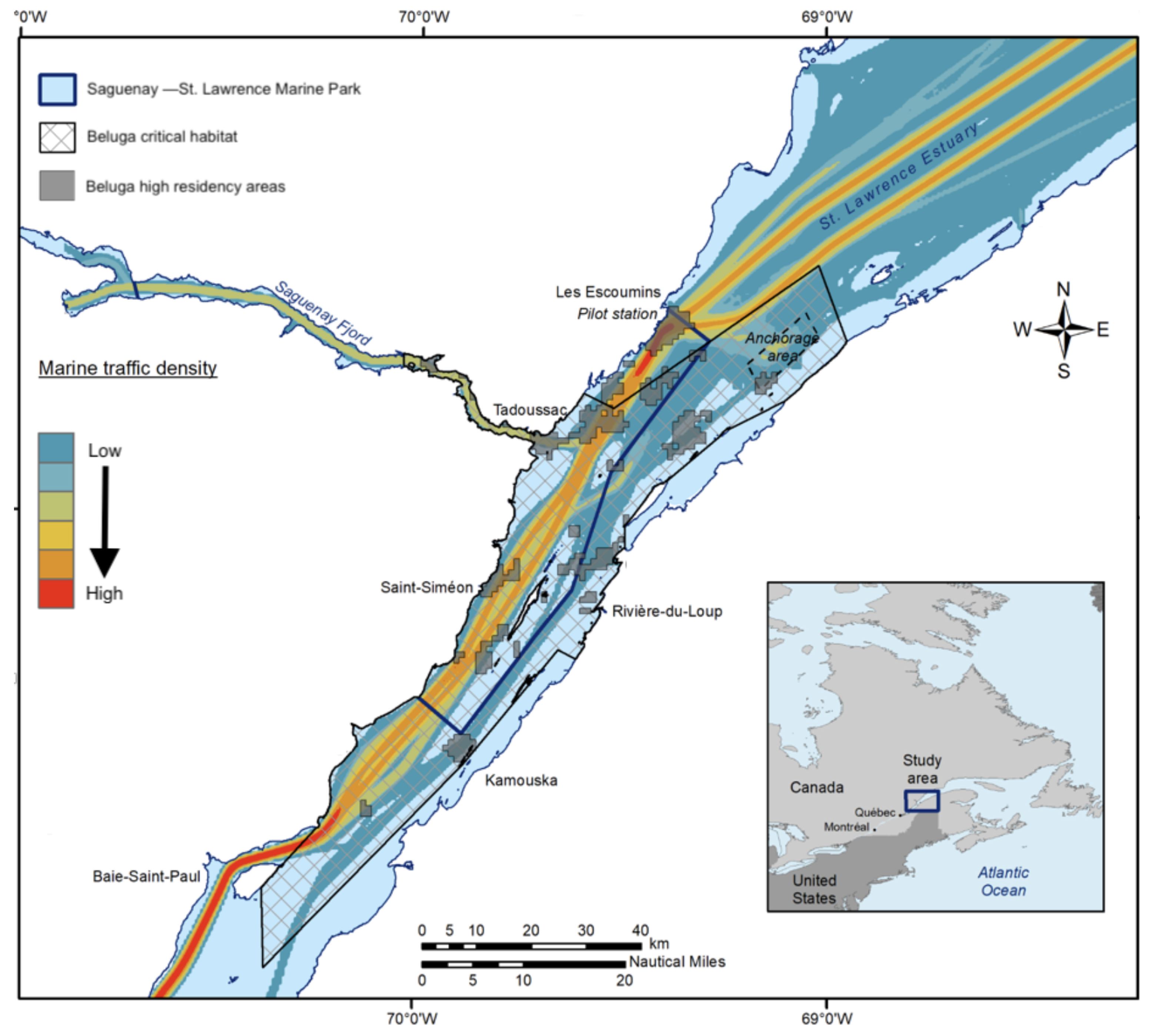
2.1. Data Collection
2.2. Proposed Approach
2.3. Beluga-5k
2.4. Annotation
2.5. Object-Detection Algorithms
2.6. Evaluation Metrics for Object Detection
2.7. Training and Inference
3. Results
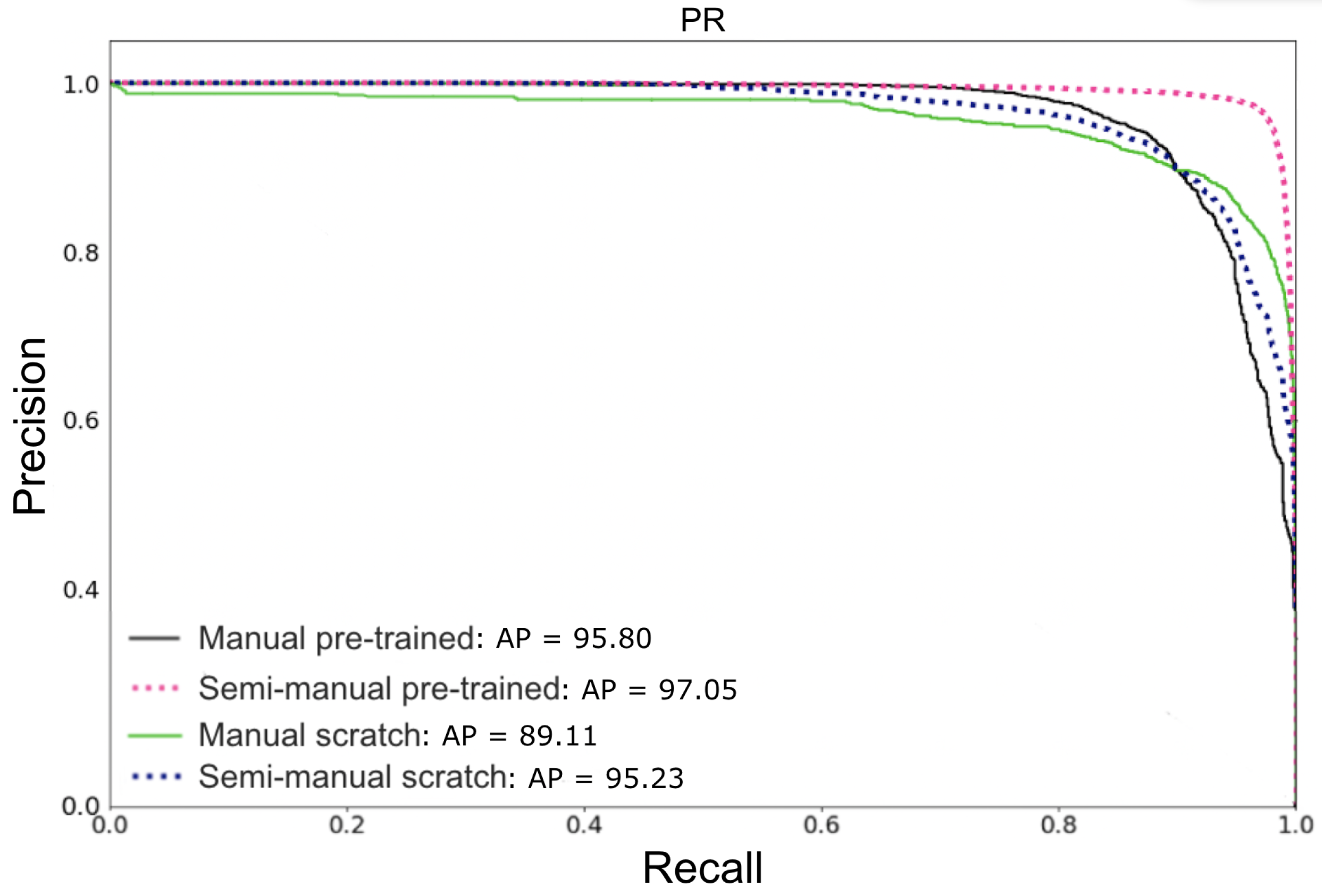
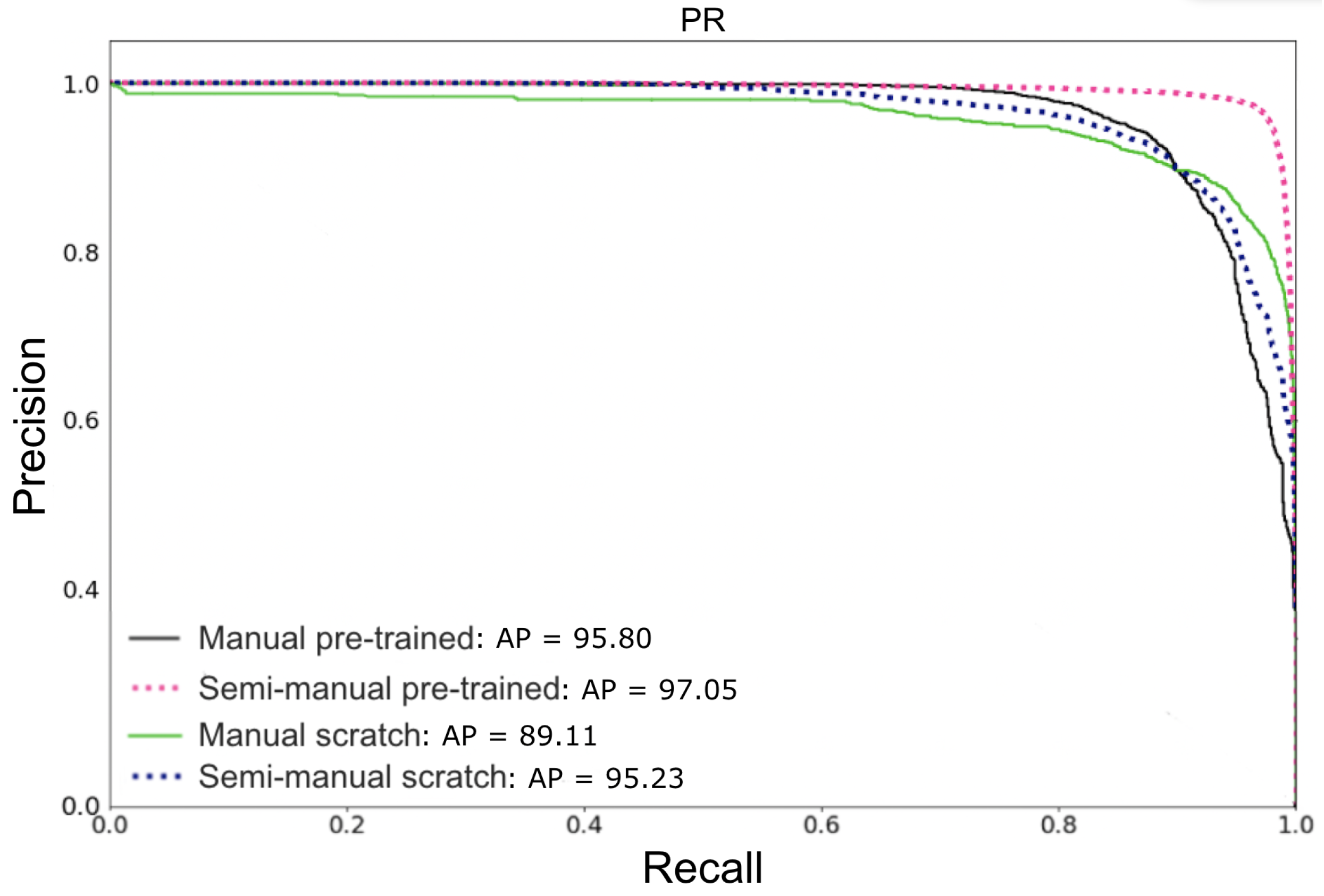
3.1. Improving Manual with Semi-Manual Annotations
3.2. Off-the-Shelf Object Detectors for Belugas
3.3. Performance of Beluga Detection under the Pre-Trained and Scratch Models
3.4. Detection on Images
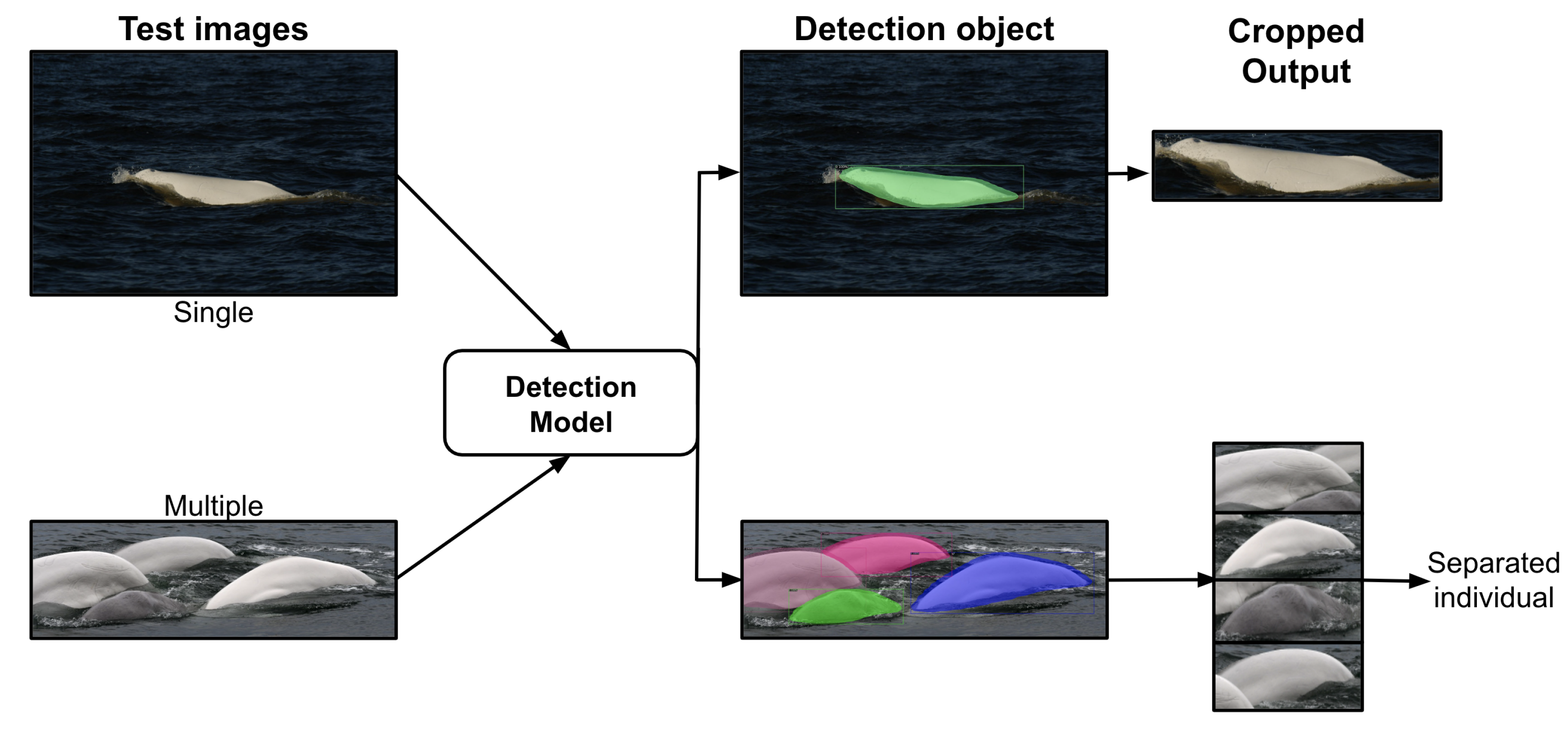
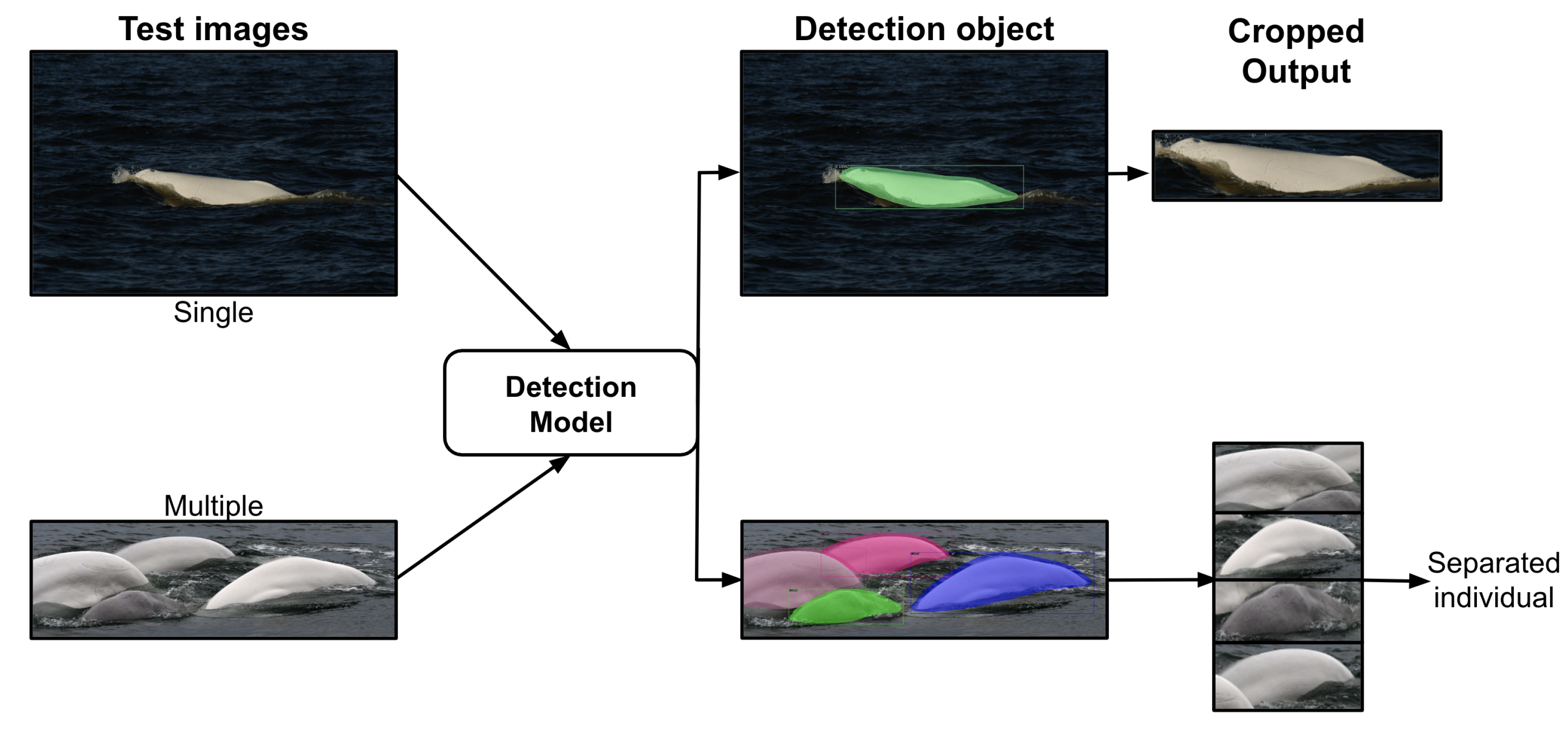
3.5. Case Studies for Single- and Multiple-Beluga Images
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, H.D. The industrialisation of the world ocean. Ocean. Coast. Manag. 2000, 43, 11–28. [Google Scholar] [CrossRef]
- Weir, C.; Dolman, S. Comparative Review of the Regional Marine Mammal Mitigation Guidelines Implemented During Industrial Seismic Surveys, and Guidance Towards a Worldwide Standard. J. Int. Wildl. Law Policy 2007, 10, 1–27. [Google Scholar] [CrossRef]
- Wright, A.; Cosentino, M. JNCC guidelines for minimising the risk of injury and disturbance to marine mammals from seismic surveys: We can do better. Mar. Pollut. Bull. 2015, 100, 231–239. [Google Scholar] [CrossRef]
- Read, A.J.; Drinker, P.; Northridge, S. Bycatch of marine mammals in U.S. and global fisheries. Conserv. Biol. J. Soc. Conserv. Biol. 2006, 20, 163–169. [Google Scholar] [CrossRef]
- Parente, C.; Araújo, M. Effectiveness of Monitoring Marine Mammals during Marine Seismic Surveys off Northeast Brazil. J. Integr. Coast. Zone Manag. 2011, 11, 409–419. [Google Scholar] [CrossRef] [Green Version]
- Harwood, L.; Joynt, A. Factors Influencing the Effectiveness of Marine Mammal Observers on Seismic Vessels, with Examples from the Canadian Beaufort Sea; Fisheries and Oceans Canada: Ottawa, ON, Canada, 2009. [Google Scholar] [CrossRef]
- McCoy, E.; Burce, R.; David, D.; Aca, E.Q.; Hardy, J.; Labaja, J.; Snow, S.J.; Ponzo, A.; Araujo, G. Long-Term Photo-Identification Reveals the Population Dynamics and Strong Site Fidelity of Adult Whale Sharks to the Coastal Waters of Donsol, Philippines. Front. Mar. Sci. 2018, 5, 271. [Google Scholar] [CrossRef]
- Michaud, R. St. Lawrence Estuary Beluga (Delphinapterus leucas) Population Parameters Based on Photo-Identification Surveys, 1989–2012; DFO Canadian Science Advisory Secretariat Research Document 2013/130; Canadian Science Advisory Secretariat: Ottawa, ON, Canada, 2014; p. iv + 27. [Google Scholar]
- Meek, P.D.; Ballard, G.A.; Fleming, P.J.S. The pitfalls of wildlife camera trapping as a survey tool in Australia. Aust. Mammal. 2015, 37, 13–22. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Urian, K.; Gorgone, A.; Read, A.; Balmer, B.; Wells, R.; Berggren, P.; Durban, J.; Eguchi, T.; Rayment, W.; Hammond, P. Recommendations for photo-identification methods used in capture-recapture models with cetaceans. Mar. Mammal Sci. 2014, 31, 298–321. [Google Scholar] [CrossRef] [Green Version]
- Maire, F.; Alvarez, L.M.; Hodgson, A. Automating Marine Mammal Detection in Aerial Images Captured during Wildlife Surveys: A Deep Learning Approach. In AI 2015: Advances in Artificial Intelligence; Pfahringer, B., Renz, J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 379–385. [Google Scholar]
- Borowicz, A.; Le, H.; Humphries, G.; Nehls, G.; Höschle, C.; Kosarev, V.; Lynch, H.J. Aerial-trained deep learning networks for surveying cetaceans from satellite imagery. PLoS ONE 2019, 14, e0212532. [Google Scholar] [CrossRef] [Green Version]
- Guirado, E.; Tabik, S.; Rivas, M.L.; Alcaraz-Segura, D.; Herrera, F. Whale counting in satellite and aerial images with deep learning. Sci. Rep. 2019, 9, 14259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, N.; Scully-Power, P.; Blumenstein, M. Shark Detection from Aerial Imagery Using Region-Based CNN, a Study. In AI 2018: Advances in Artificial Intelligence; Mitrovic, T., Xue, B., Li, X., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 224–236. [Google Scholar]
- Renò, V.; Dimauro, G.; Labate, G.; Stella, E.; Fanizza, C.; Cipriano, G.; Carlucci, R.; Maglietta, R. A SIFT-based software system for the photo-identification of the Risso’s dolphin. Ecol. Inform. 2019, 50, 95–101. [Google Scholar] [CrossRef]
- Mejias, L.; Duclos, G.; Hodgson, A.; Maire, F. Automated marine mammal detection from aerial imagery. In Proceedings of the OCEANS 2013 MTS/IEEE—San Diego: An Ocean in Common, San Diego, CA, USA, 23–26 September 2013. [Google Scholar]
- Karnowski, J.; Hutchins, E.; Johnson, C. Dolphin detection and tracking. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision Workshops, WACVW 2015, Waikoloa, HI, USA, 5–9 January 2015; pp. 51–56. [Google Scholar] [CrossRef]
- Park, M.; Yang, W.; Cao, Z.; Kang, B.; Connor, D.; Lea, M.A. Marine Vertebrate Predator Detection and Recognition in Underwater Videos by Region Convolutional Neural Network. In Pacific Rim Knowledge Acquisition Workshop; Springer: Cham, Swizterland, 2019; pp. 66–80. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; Volume 1, pp. 91–99. [Google Scholar]
- Pedersen, M.; Haurum, J.B.; Gade, R.; Moeslund, T.B.; Madsen, N. Detection of marine animals in a new underwater dataset with varying visibility. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 18–26. [Google Scholar]
- Dawkins, M.; Sherrill, L.; Fieldhouse, K.; Hoogs, A.; Richards, B.; Zhang, D.; Prasad, L.; Williams, K.; Lauffenburger, N.; Wang, G. An Open-Source Platform for Underwater Image and Video Analytics. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 898–906. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Harasyn, M.L.; Chan, W.S.; Ausen, E.L.; Barber, D.G. Detection and tracking of belugas, kayaks and motorized boats in drone video using deep learning. Drone Syst. Appl. 2022, 10, 77–96. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Skalski, P. Make Sense. 2019. Available online: https://github.com/SkalskiP/make-sense/ (accessed on 5 October 2021).
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for Multi-Scale Remote Sensing Target Detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef] [PubMed]
- Hosang, J.H.; Benenson, R.; Schiele, B. Learning non-maximum suppression. arXiv 2017, arXiv:1705.02950. [Google Scholar]
- Bloice, M.D.; Roth, P.M.; Holzinger, A. Biomedical image augmentation using Augmentor. Bioinformatics 2019, 35, 4522–4524. [Google Scholar] [CrossRef] [PubMed]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; Lechevallier, Y., Saporta, G., Eds.; Physica-Verlag HD: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of | ||||||
|---|---|---|---|---|---|---|
| Image | Individuals | Training Images | Validation Images | Test Images | Candidates | Average Number of Candidates per Image |
| Single | 427 | 3182 | 100 | 1590 | 4872 | 1 |
| Multiple | - | 50 | 0 | 200 | 706 | 3.5 |
| Total | 427 | 3232 | 100 | 1790 | 5578 | - |
| Bakcbone | Manual | Semi-Manual |
|---|---|---|
| YOLO v3-Tiny | 85.23 | 96.31 |
| Bakcbone | mAP@0.5 (%) | Average Time (ms) |
|---|---|---|
| Mask-RCNN | 98.80 | 542.1 |
| SSD | 87.82 | 383.2 |
| YOLO v3-Tiny | 97.05 | 135.2 |
| Beluga | Test Images | Ground Truth Candidates | TP | FP | FN | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|---|
| Single | 1590 | 1590 | 1587 | 1 | 2 | 99.94 | 99.87 |
| Multiple | 200 | 706 | 688 | 12 | 6 | 98.29 | 99.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Araújo, V.M.; Shukla, A.; Chion, C.; Gambs, S.; Michaud, R. Machine-Learning Approach for Automatic Detection of Wild Beluga Whales from Hand-Held Camera Pictures. Sensors 2022, 22, 4107. https://doi.org/10.3390/s22114107
Araújo VM, Shukla A, Chion C, Gambs S, Michaud R. Machine-Learning Approach for Automatic Detection of Wild Beluga Whales from Hand-Held Camera Pictures. Sensors. 2022; 22(11):4107. https://doi.org/10.3390/s22114107
Chicago/Turabian StyleAraújo, Voncarlos M., Ankita Shukla, Clément Chion, Sébastien Gambs, and Robert Michaud. 2022. "Machine-Learning Approach for Automatic Detection of Wild Beluga Whales from Hand-Held Camera Pictures" Sensors 22, no. 11: 4107. https://doi.org/10.3390/s22114107
APA StyleAraújo, V. M., Shukla, A., Chion, C., Gambs, S., & Michaud, R. (2022). Machine-Learning Approach for Automatic Detection of Wild Beluga Whales from Hand-Held Camera Pictures. Sensors, 22(11), 4107. https://doi.org/10.3390/s22114107