1. Introduction
The recognition of facial expression is a basic function of the human brain [
1]. Macro-expressions are intuitive reflections of human emotions, while micro-expressions (MEs) are more spontaneous expressions that are difficult to suppress or disguise. Analysis of MEs can therefore reveal genuine emotions, which is very useful in many sectors. Álvarez-Pato et al. in [
2] showed that analyzing human emotions effectively can be used to predict consumer response. In addition, ME recognition has been employed in many fields, including lie detection, psychoanalysis, police interrogation, and national security [
3]. However, this type of expression occurs in a very quick period of time (less than 0.5 seconds) and only involves very minuscule facial muscles, thus making the detection and analysis tasks very challenging [
4].
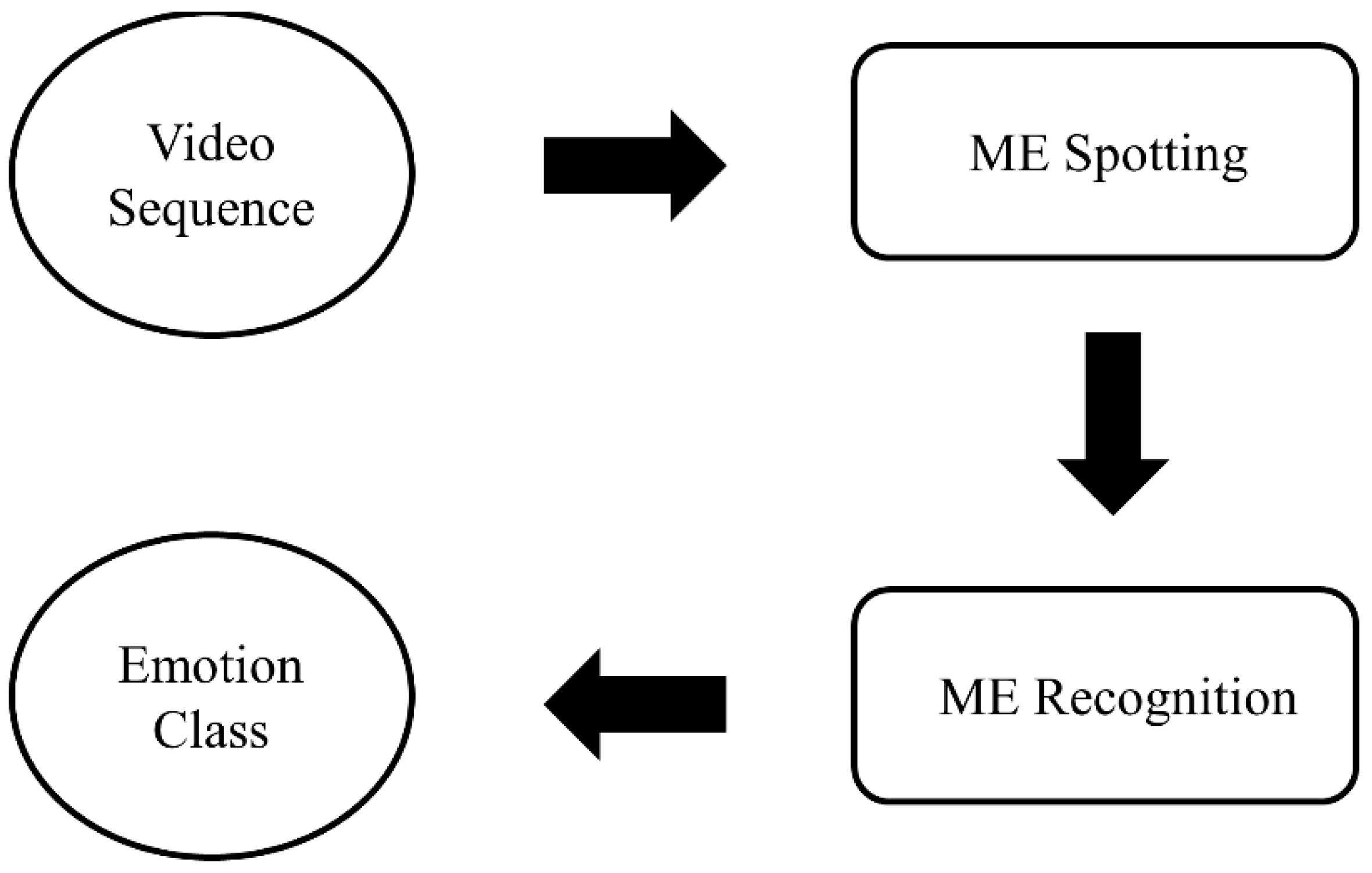
When a person tries to suppress their real emotions, they will try to maintain their neutral facial expression. However, the moment they fail to conceal their emotions, MEs will manifest. As a result, ME only occurs when the expression starts to appear from the neutral expression (onset), which is peaked at the apex frame and then reverts to the neutral expression again (offset) [
5]. From a raw long ME video, a sliced sequence of onset-offset frames is defined as a “short video”, as visualized in
Figure 1.
Apart from the beginning and ending frames that have special names, there is one frame between the onset and offset frames, called the apex frame, that contains the most expressive frame with maximum facial movement differences. Some researchers analyze only the apex frame for ME analysis, rather than the whole sequence of images, as this frame signifies the peak facial muscle movements, which is very informative for ME analysis [
6]. Li et al. [
7] showed that a single apex frame can provide sufficient information for an effective ME analysis system, and hence improving apex frame feature learning can significantly increase the deep model performance used for ME recognition. Owing to the importance of the apex frame, several studies [
8,
9,
10,
11,
12] were dedicated to locate this most crucial frame accurately. However, the detection of the apex frame itself is very challenging due to the inconspicuous changes and the transient nature of ME.
Although the characteristics of MEs have made the development of this field intractable, their value has led to the continuous refinement of ME analysis techniques by researchers. The studies by Haggard et al. [
13] and Ekman et al. [
14] which detected and analyzed ME by slowing down the video playback are generally considered as the starting point for video-based ME research development. As the field has progressed, handcrafted ME features have been coupled with machine learning, as used in [
6,
15,
16], followed by the current trend of using deep learning techniques. The main weakness of the conventional machine learning approach is the sub-optimal selection of the features [
17], whereby the deep learning approach overcomes this limitation through optimized learning from a large amount of data. In fact, the application of deep learning technology has produced prominent results in several fields such as the trajectory control of robot manipulators [
18], multiple hand gesture classification for teleoperated robot [
19], electrocardiogram patterns monitoring [
20] and automated ME analysis [
21,
22,
23].
Yet, most studies tend to classify MEs without concern for effective ME spotting, whereby better ME spotting will lead to a more effective ME analysis [
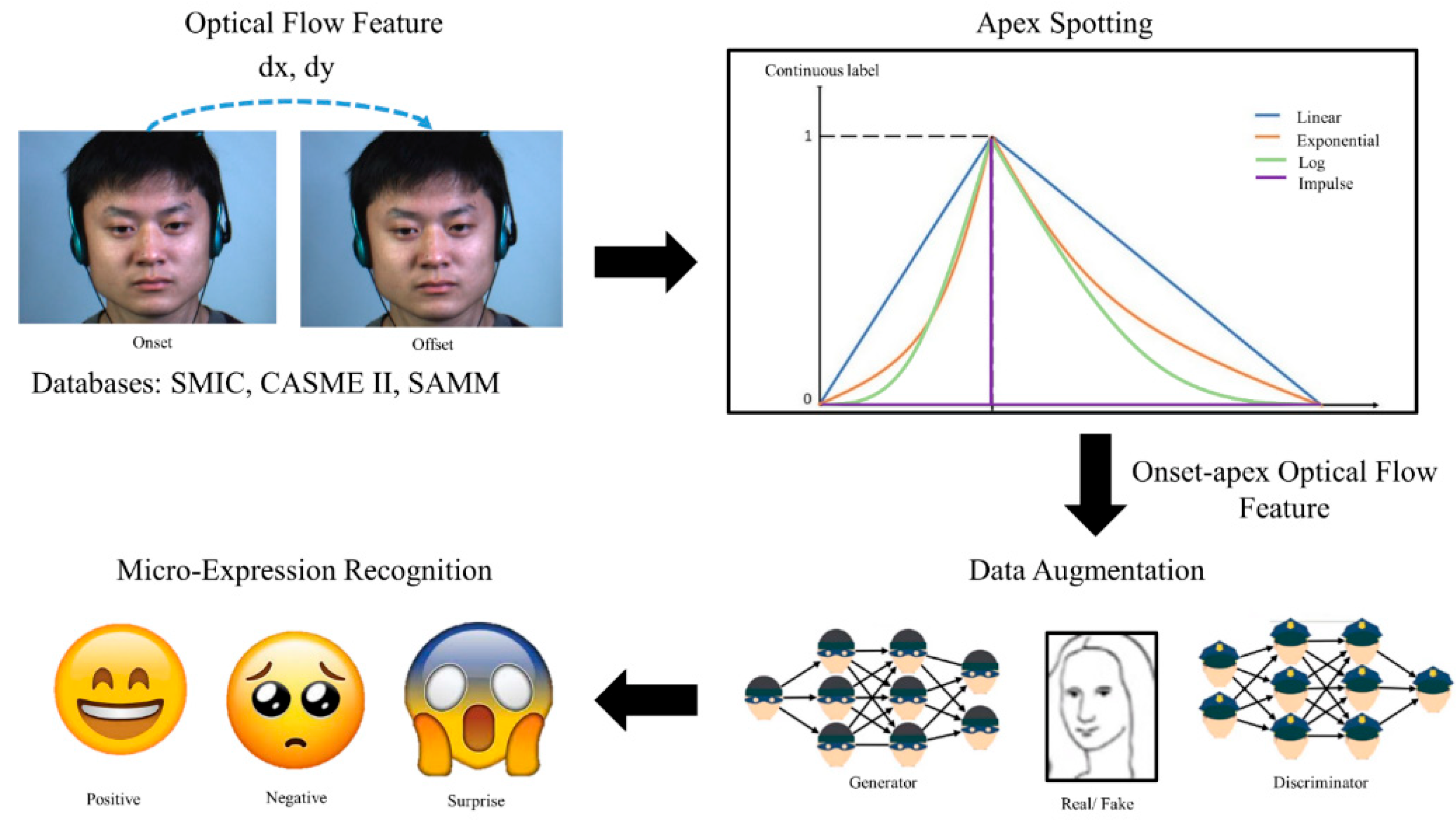
24]. Furthermore, a well-established automated ME analysis system based on deep learning is even less common. Therefore, in this paper, we have designed an optimized deep learning network to automatically analyze the MEs, involving both the spotting and recognition parts. However, the primary weakness of the existing methods can be traced to the lack of training data for optimal deep model fitting. Thus, this project proposes conditional generative adversarial networks (GAN) as a method to augment the training data through competing CNN networks between discriminator and generator networks. To further finetune the classification capability, the optimization of CNN networks has also been performed to produce better ME recognition.
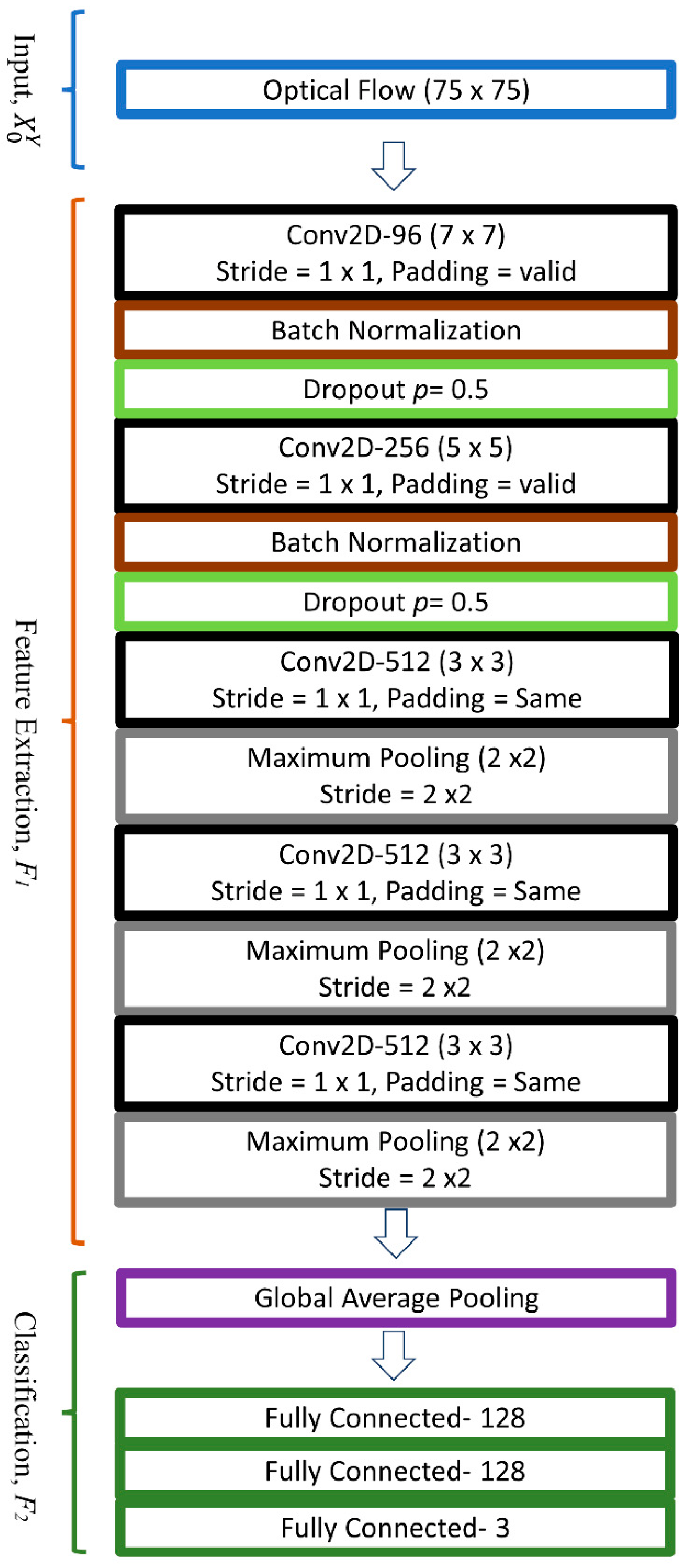
As discussed above, the main contribution of this paper is the introduction of an optimized deep learning-based automated ME analysis system for both apex spotting and emotion classification modules. Firstly, we are the first to optimize the network and labeling process used in [
12] for the apex spotting task. Secondly, we design a compact conditional DC-GAN to increase the amount of training data through synthetic optical flow images. Thirdly, we devise an optimized compact convolutional neural network (CNN), named Optimal Compact Network (OC-Net), to automatically classify the MEs into correct respective emotion categories, which produced the best classification performance compared to the state-of-the-art techniques. This paper is organized as follows: the related works are discussed in
Section 2; while
Section 3 details the materials and types of pre-processing features used, followed by the proposed methods and model architecture. Then,
Section 4 reports and discusses the spotting and recognition performance. Finally, conclusions are given in
Section 5 to highlight the advantages of the proposed network.
4. Results and Discussion
For the apex spotting task, CASME II and SAMM data are fed into the modified VGG-M model separately to analyze the spotting performance of various continuous labeling functions. The ME data are divided according to the ratio of 4:1 into respective training and testing sets, which then undergo a 5-fold cross-validation process. An ADAM optimizer with a total epoch = 1000, a batch size equal to 64 frames and a 0.0001 learning rate is set to train the models. Then, the likelihood of each tested frame being the apex frame of each ME video is predicted using the trained model. After the likelihood value of each frame is obtained, two schemes are utilized; the Max scheme is utilized to find the maximum probability frame, and the SW-Max scheme locates the sliding window (window size = 9) with the maximum probability as the apex frame, which means the neighboring frames’ probabilities are also considered during the decision-making process.
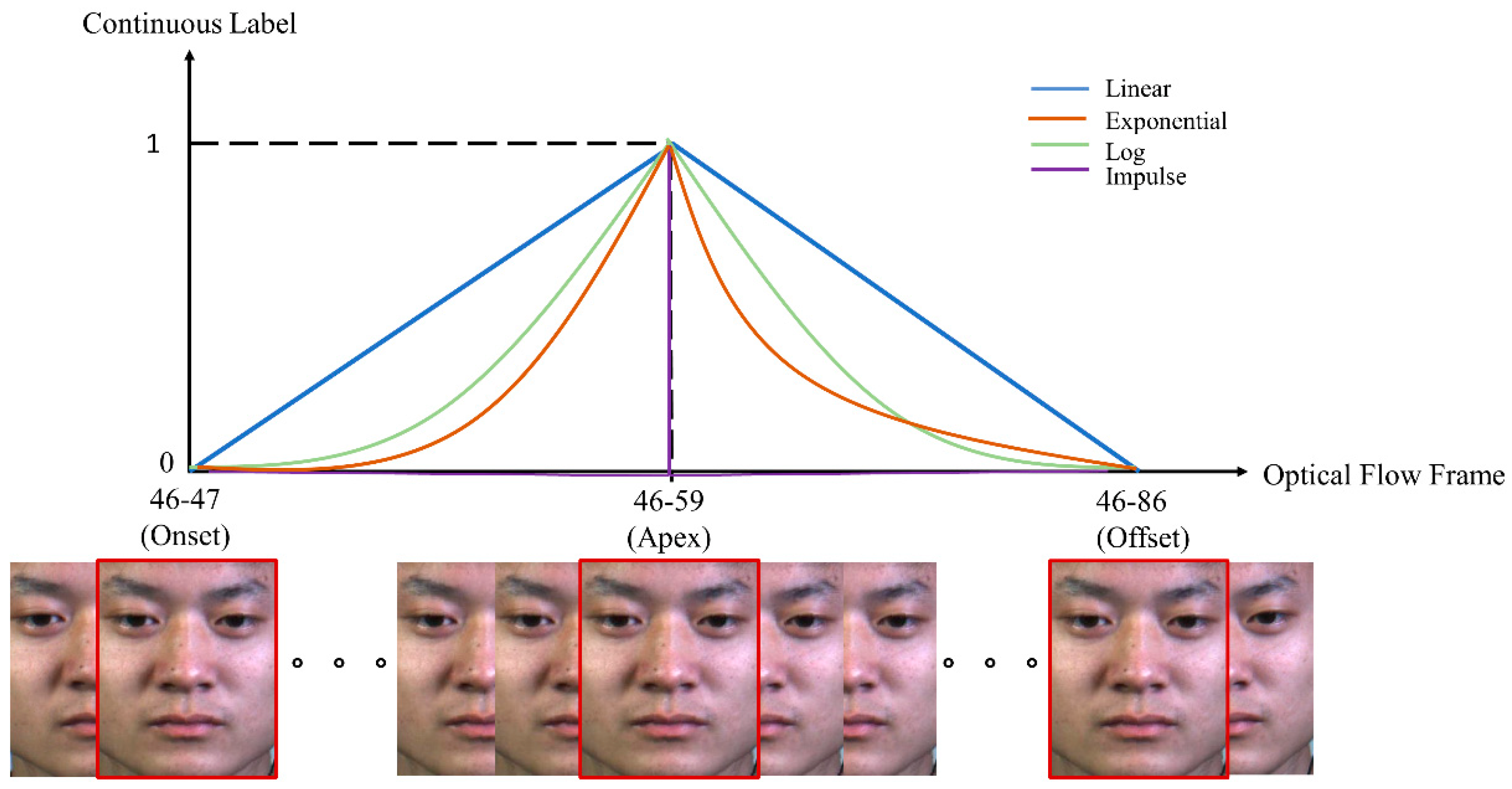
A previous study showed that a linear continuous function can cope well with the SW-Max scheme that performs better than the exponential function, with the best average MAE of 14.37 frames. Hereby, we investigate further the relationship between various continuous functions and the ME analysis performance through log and impulse functions.
Table 3 shows the average error performance of these functions in locating the apex frames. From the table, we can see that the impulse function is not suitable for the apex spotting application as the errors are relatively large compared to the other functions. The maximum MAE value, which is the worst performance is achieved by impulse function with an error of 24.33 frames when locating the apex frame, tested on the SAMM dataset, while the performance of the proposed log function is stunning, especially when the ME log continuous label is further processed using the SW-Max scheme with a low error rate of only 10.36 frames, tested on the CASME II dataset. This improvement is even better compared to the best method in [
12] with the lowest MAE value of 11.36 frames.
On average, the SW-Max scheme coupled with the log continuous label managed to locate the apex frames with only 12.44 frames of error. Furthermore, the SW-Max scheme generally outperforms the Max method according to the results tabulated in
Table 3. The maximum MAE of the Max scheme is 24.33 frames when it is processed using impulse continuous labels based on the SAMM dataset, while the SW-Max scheme has a much lower maximum error of only 14.96 MAE. After analyzing
Table 3, the results show that single frame information is less effective, whereby the neighboring frame information can smooth out the error in predicting the apex frame.
Apart from that, the feedforward property is also found to be able to improve the apex spotting performance, and hence, we concatenate the short path connections in
Figure 6 to further analyze the performance of the log continuous function.
Table 4 tabulates the MAE values of the model with feedforward properties in generating the log continuous label for apex frame spotting, tested on the CASME II dataset. The log continuous label generated by the feedforward network managed to represent the ME data better compared to the original VGG-M. The best MAE achieved is only 10.28 frames, but a linear continuous label with the aid of the feedforward networks by Koo et al. performs even better with the lowest MAE of 8.46 frames. Thus, a linear continuous function is the best overall function for labeling the apex frame network. Therefore, in this study, apex frames for the SMIC data are located using the network with a concatenated short path to the modified VGG-M coupled with the linear continuous labeling function.
For each ME emotion category, 100 synthetic optical flows are generated as the augmented data, resulting in a total of 300 synthetic data generated using the proposed conditional DC-GAN. These augmented data are only applicable during the training process, and not in the testing process. A leave-one-subject-out validation method is applied in analyzing the ME recognition task performance on CASME II, SAMM, and SMIC, which is tabulated in
Table 5. In other words, the initial ME training data of 67 subjects are now augmented by 300 artificially generated data.
Modified VGG-M shown in
Table 1 is also used as the benchmark for the ME recognition task, whereby the single output node is changed to three nodes. The overall ME recognition performance of the modified VGG-M model significantly improved from 72.34% accuracy and 58.50% F1-score to 78.3% accuracy and 67.57% F1-score when the training data are augmented using synthetic data. The model trained by a combination of real ME data and synthetic data managed to categorize the emotions better for both CASME II and SMIC datasets. Improvement of around 12.88% accuracy and 19.31% F1-score for the CASME II dataset can be observed on average, while for the SMIC dataset, the accuracy value improved by 8.13%, and the F1-score by 12.2%. On the other hand, model performance on the SAMM dataset decreased by 4.04% regarding accuracy and 6.06% regarding F1-score.
For the ME recognition task, the proposed OC-Net is trained using an ADAM optimizer with a learning rate of 0.00006 for 500 epochs with leave-one-subject-out cross-validation. The full performance results are tabulated in
Table 6. Modified VGG-M is also used as the benchmark for ME recognition performance as both the modified VGG-M and OC-Net are compact CNN models with five convolution layers and three fully connected layers. When OC-Net performance is compared to the modified VGG-M, whereby no data augmentation scheme is applied, the accuracy and F1-score improved from 72.34% and 58.50% to 78.53% and 67.80%, respectively.
Table 7 shows the comparison between OC-Net variants in classifying ME emotion categories. The analysis is performed by adding dropout layers to the model layer one-by-one. The results indicate that the insertion of dropout layers
p = 0.5 improved ME recognition performance from 65.31% to the best F1-score of 67.80%. OC-Net with larger feature maps in the early layer performs better than the modified VGG-M, which underwent down-sampled processes in the early stage. Even without the dropout layers, OC-Net still achieved an F1-score 6.81% better than that of the modified VGG-M. This performance improvement can be attributed to the deep model’s better ability in handling early layer feature loss due to the pooling operations. Besides that, OC-Net with dropout layers right after every BN layer also produced the best ME recognition performance.
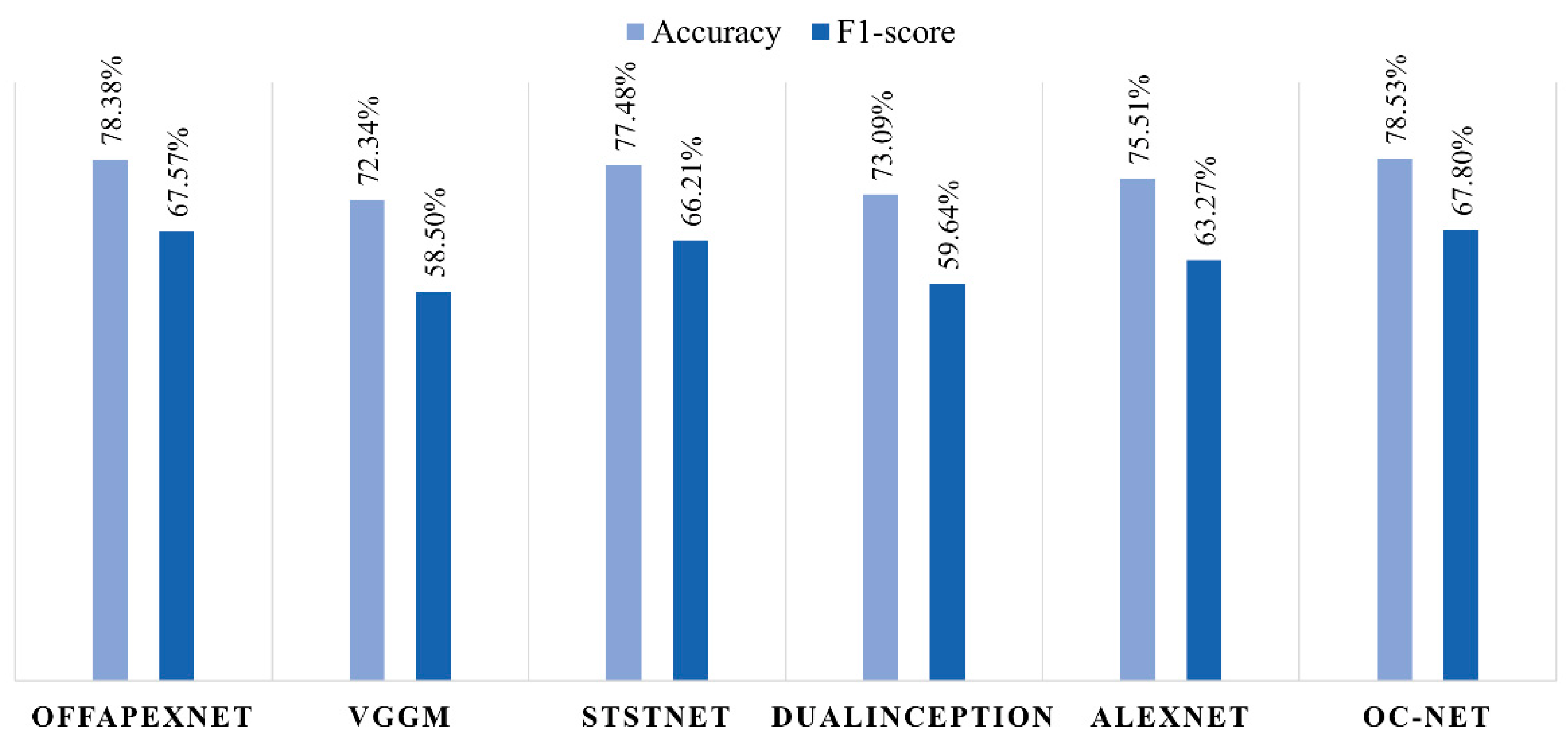
When compared to the other state-of-the-art CNN models in micro-expression analysis, OC-Net still produces the best emotion recognition in terms of accuracy and F1-score. Only OffApexNet [
25], with an accuracy of 78.38% and F1-score of 67.57%, came in a close second to OC-Net’s performance. STSTNet [
26] recognized the ME with a performance of 77.48% accuracy and 66.21% F1-score, which is ranked in third place, followed by AlexNet [
36], DualInception [
27], and VGG-M [
11]. STSTNet uses a unique set of inputs, which are fed with three-dimensional optical flow features: horizontal and vertical components of the optical flow and optical strain, while the other models use standardized inputs of two-dimensional optical flow features.
Figure 13 illustrates the ME recognition performance of different state-of-the-art CNN models in micro-expression recognition systems.
Based on the good performance of data augmentation using GAN as shown in
Table 5, the following experiments use synthetic optical flows, which are fed into OC-Net during the training phase.
Table 8 shows that the model performance improved from 78.53% accuracy to 79.14%, while F1-score improved from 67.80% to 68.71%. Moreover, the impact of GAN is minimal for the CASME II dataset as the performance results remained the same for OC-Net ME recognition with and without GAN data. On the other hand, the ability of OC-Net in classifying the SAMM dataset also improved. It is also observable that OC-Net with synthetic optical flow performs better than the modified VGG-M.
Overall, the ME recognition results of the CASME II are much better than the other two databases. This is mainly because the micro-expressions used in the CASME II database were all taken from Chinese youth, which is in contrast with the SAMM database that utilized 28 subjects from 13 different ethnic groups. In fact, different ethnic groups have different typical appearances, both in terms of face shape and skull shape. Murray et al. [
47] showed that face shape and face surface will surely affect facial expression representation. In addition, the SAMM database has the widest variety of negative expressions among the three tested databases with five types of expressions: contempt, disgust, fear, anger, and sadness. Although these types of expressions are the same in a sense, whereby all emotions are considered as negative emotions, the way they are expressed and manifested is totally different. Thus, it is hard to evoke the augmented data for the negative cases accurately, as the labeling scheme is only singular. In the case of the SMIC database, the performance of the SMIC database is greatly diminished by the absence of ground truth apex frame information. Although the apex spotting method we used produced only small errors on CASME II and SAMM, there is no performance guarantee of the extracted apex location in SMIC, as no ground truth is provided.
The proposed method only focuses on the fine-cropped facial area which perpendicularly faces the camera. Future research could include different angles of facial ME such as a slightly sideways head, which occurs frequently in real life, as humans are very mobile. Increasing ethnic diversity is also a notable future research direction to further increase the system’s robustness. Additionally, in this paper, we have mentioned that the wide range of negative expressions could be better sorted in future studies to produce a more balanced dataset between emotions. This would lead to better learning of each category by the deep learning models. Finally, more variants of DC-GAN can be implemented to generate more high-quality synthetic data in order to produce a more diverse training dataset for better model optimization.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}