
A Water Level Measurement Approach Based on YOLOv5s


Abstract
:1. Introduction
2. Algorithms and Data
2.1. Algorithms
2.1.1. YOLOv5s
2.1.2. Image Classification
2.2. Data
2.2.1. Water Gauge Image Data
2.2.2. SVHN
3. Method Description
3.1. Water Gauge Detection Based on YOLOv5s
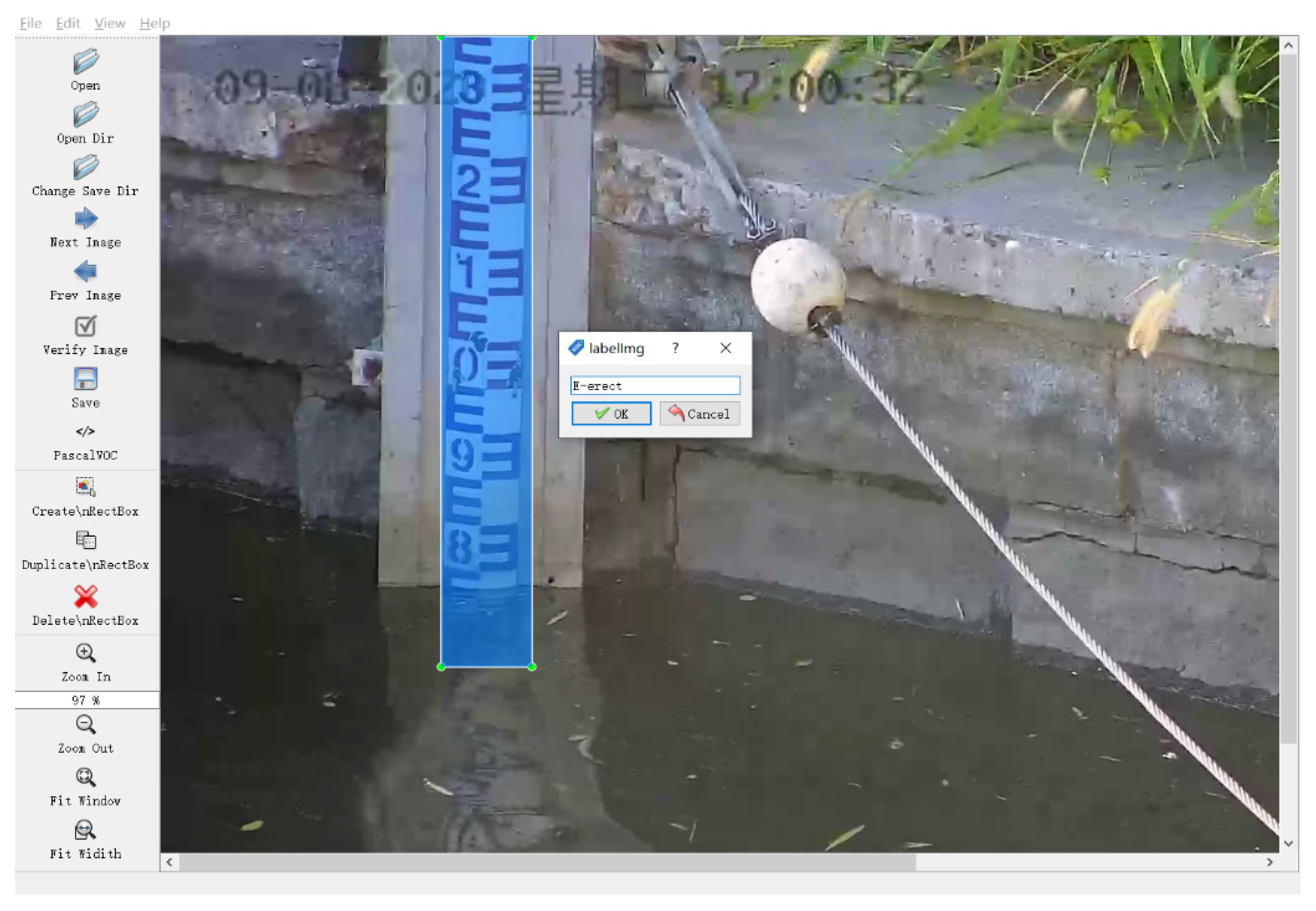
3.1.1. Image Samples Annotation
3.1.2. Water Gauge Location and Recognition
3.2. Water Surface Line Recognition
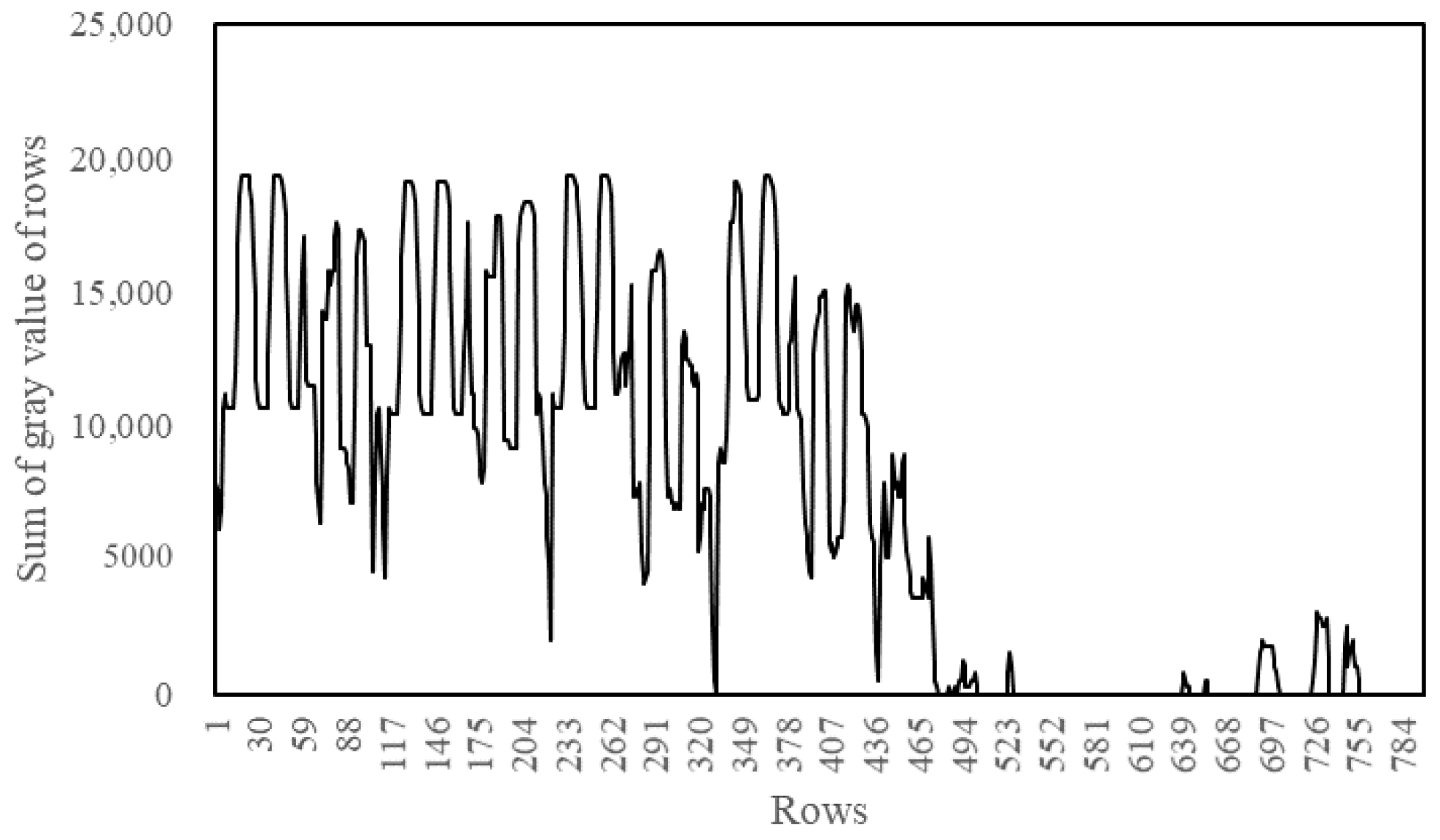
3.2.1. Image Preprocessing
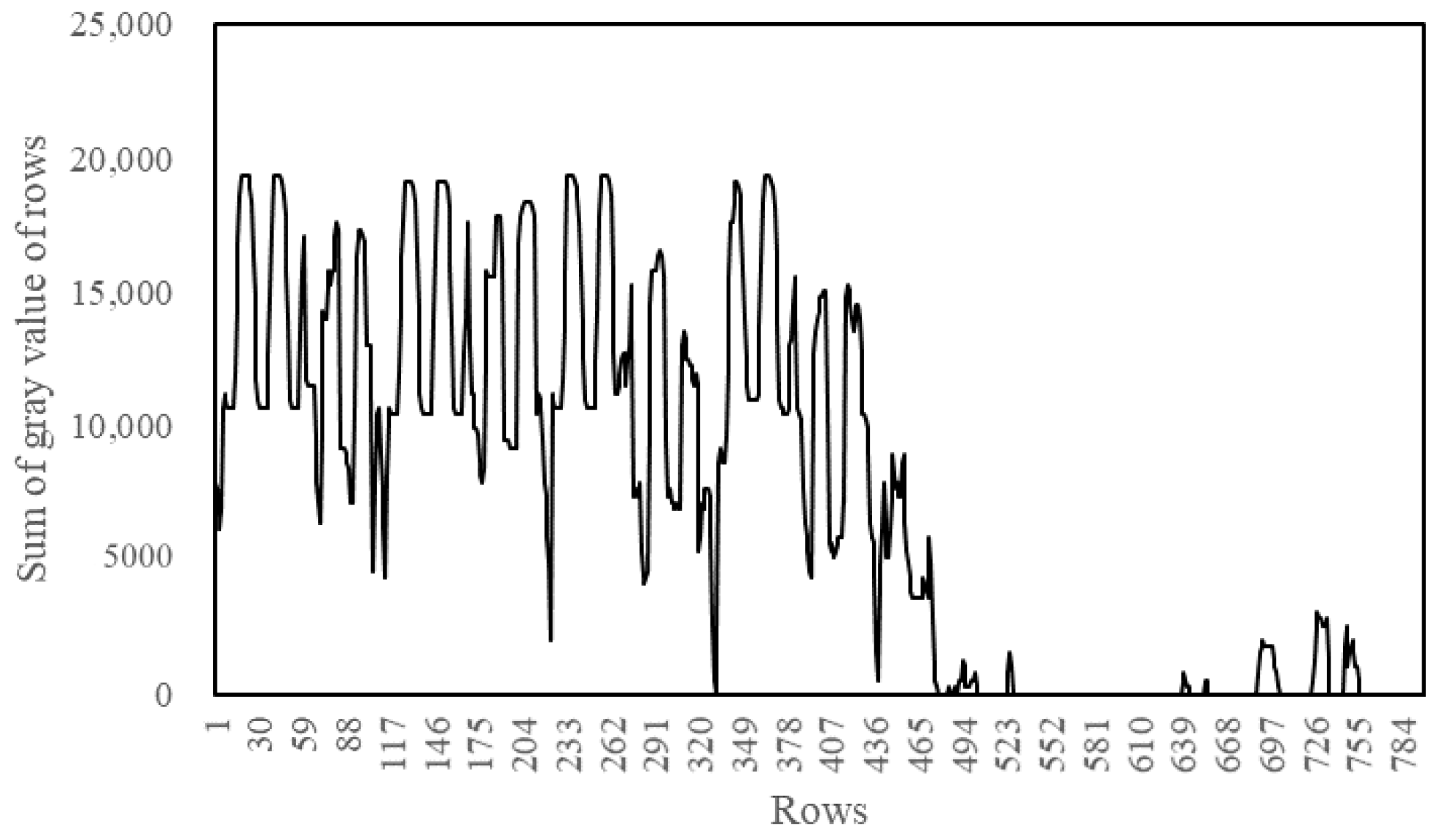
3.2.2. Binary Image Horizontal Projection
3.3. Character Location and Recognition of the Water Gauge
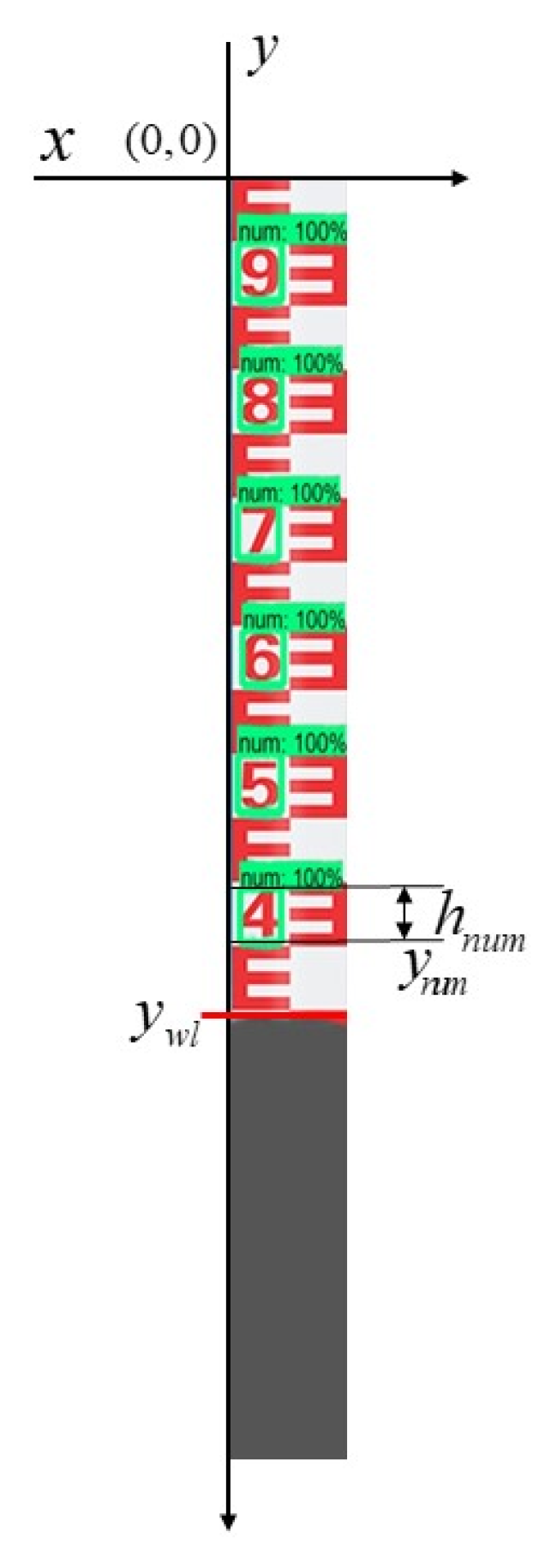
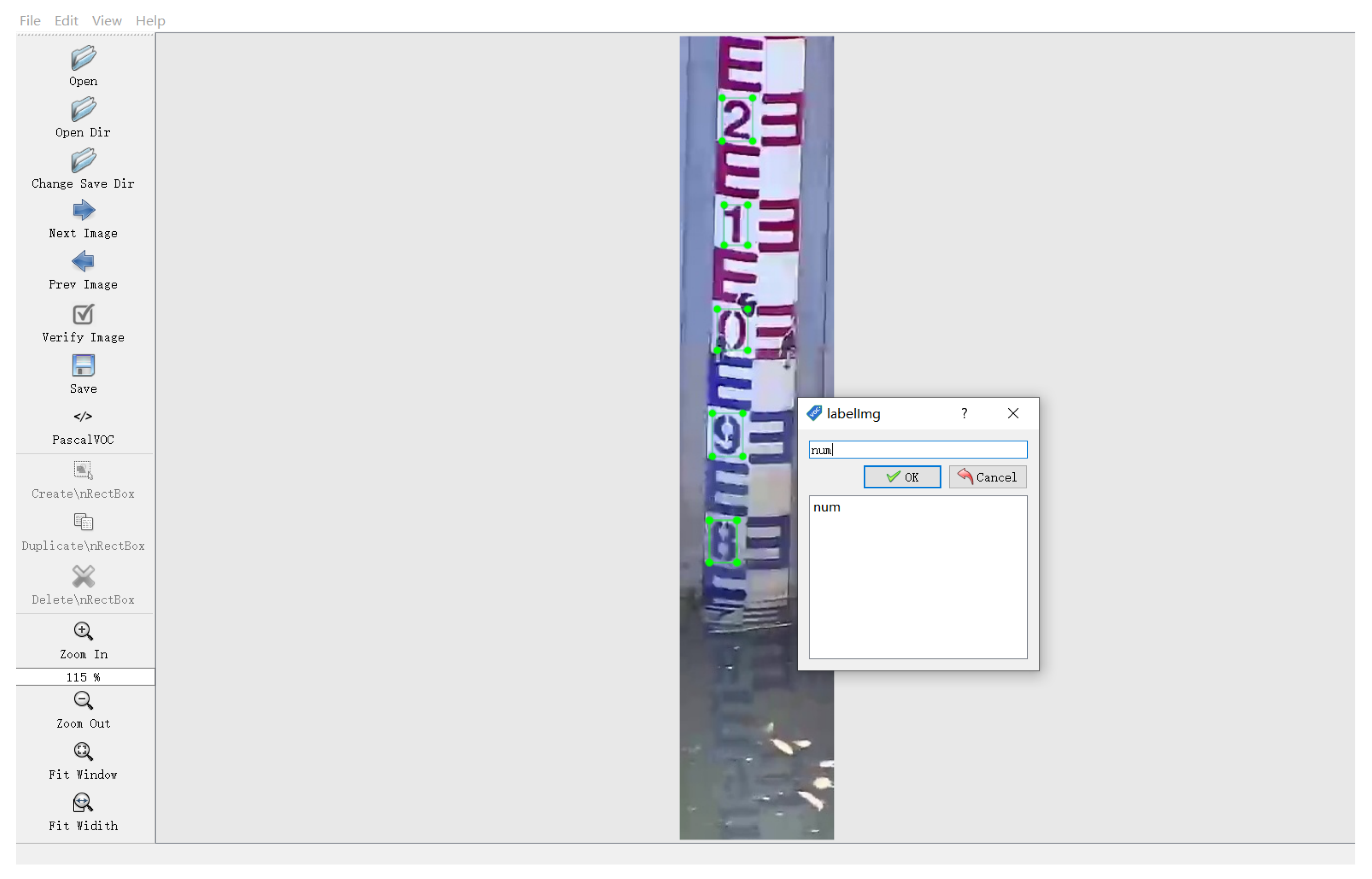
3.3.1. Character Location
3.3.2. Character Recognition
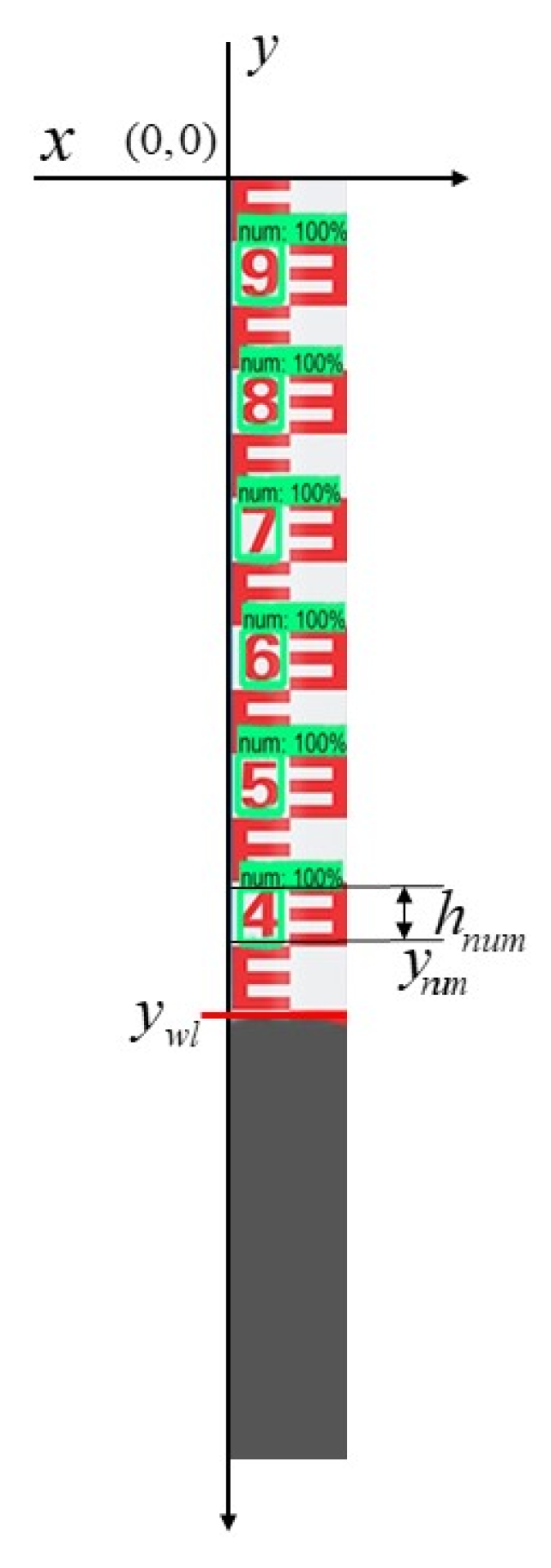
3.4. Determination of Water Level Data
4. Results and Discussion
4.1. Experimental Environment
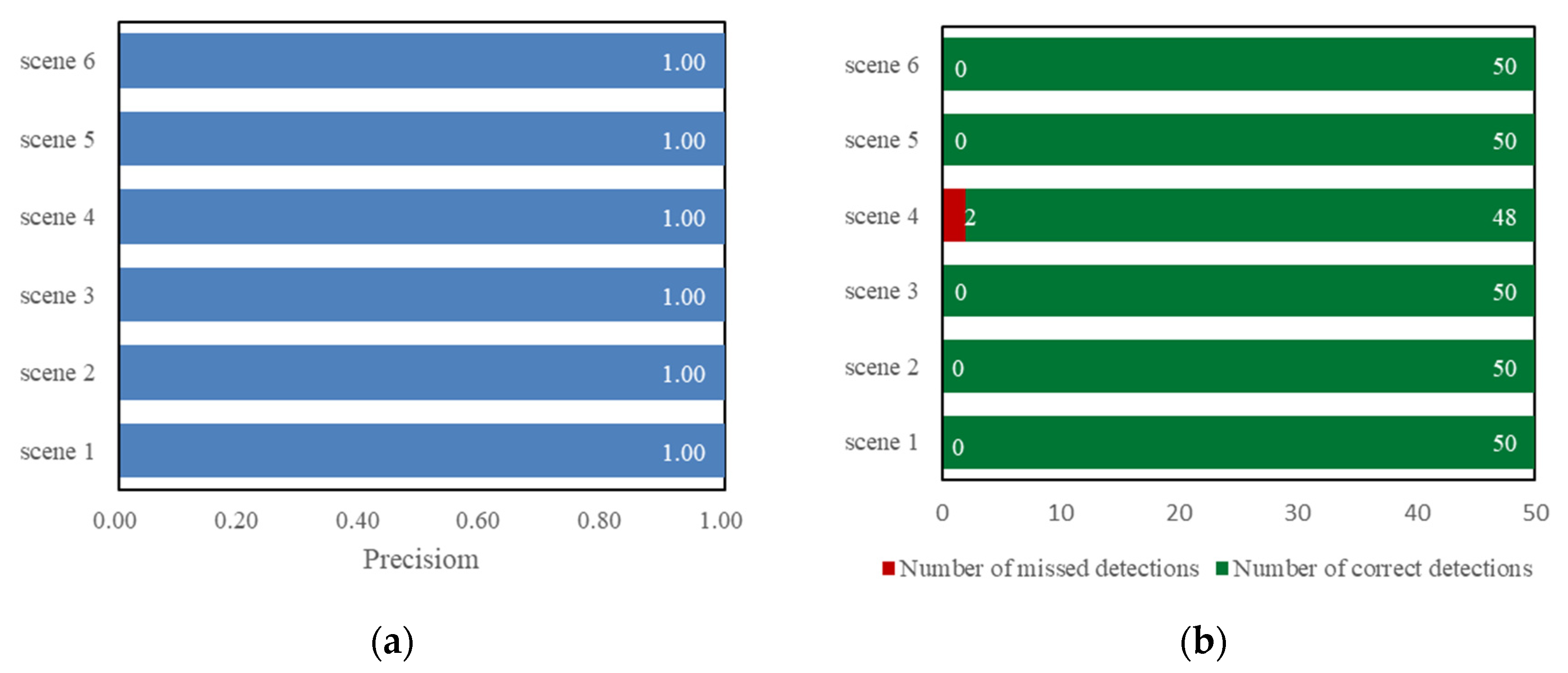
4.2. Water Gauge Detection Performance
4.3. Water Surface Line Recognition Performance
4.4. Scale Character Location and Recognition Performance
4.4.1. Character Location Performance
4.4.2. Character Recognition Performance
4.5. Performance Comparison of Water Gauge Reading
4.5.1. Comparison Method
4.5.2. Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, R.; Teng, C.; Kumar, S.; Marques, C.; Min, R. Polymer Optical Fiber Liquid Level Sensor: A Review. IEEE Sensors J. 2021, 22, 1081–1091. [Google Scholar] [CrossRef]
- Paul, J.D.; Buytaert, W.; Sah, N. A Technical Evaluation of Lidar-Based Measurement of River Water Levels. Water Resour. Res. 2020, 56, e2019WR026810. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Duan, Q.; Chu, X.; Yang, C. Fluviograph Design Based on an Ultra-Small Pressure Sensor. Sensors 2019, 19, 4615. [Google Scholar] [CrossRef] [Green Version]
- Girum, K.B.; Crehange, G.; Lalande, A. Learning With Context Feedback Loop for Robust Medical Image Segmentation. IEEE Trans. Med. Imaging 2021, 40, 1542–1554. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowledge-Based Syst. 2020, 213, 106617. [Google Scholar] [CrossRef]
- Hu, C.-H.; Yu, J.; Wu, F.; Zhang, Y.; Jing, X.-Y.; Lu, X.-B.; Liu, P. Face illumination recovery for the deep learning feature under severe illumination variations. Pattern Recognit. 2020, 111, 107724. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, Y.; Liu, H.; Zhang, L.; Wang, H. Visual Measurement of Water Level under Complex Illumination Conditions. Sensors 2019, 19, 4141. [Google Scholar] [CrossRef] [Green Version]
- Eltner, A.; Elias, M.; Sardemann, H.; Spieler, D. Automatic Image-Based Water Stage Measurement for Long-Term Observations in Ungauged Catchments. Water Resour. Res. 2018, 54, 10362–10371. [Google Scholar] [CrossRef]
- Lo, S.-W.; Wu, J.-H.; Lin, F.-P.; Hsu, C.-H. Visual Sensing for Urban Flood Monitoring. Sensors 2015, 15, 20006–20029. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Chai, E.; Zhi, M. Rapid pedestrian detection algorithm based on deformable part model. Proc. SPIE 2017, 10420, 104200Q. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Processing Syst. (NIPS) 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. Adv. Neural Inf. Processing Syst. (NIPS) 2016, 29, 379–387. [Google Scholar]
- Devries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with CutOut. arXiv 2017, arXiv:1708.04552. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- Kiryati, N.; Eldar, Y.; Bruckstein, A. A probabilistic Hough transform. Pattern Recognit. 1991, 24, 303–316. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Yan, S.; Shi, W.; Yang, X.; Guo, Y.; Gulliver, T.A. A Novel Underwater Acoustic Signal Denoising Algorithm for Gaussian/Non-Gaussian Impulsive Noise. IEEE Trans. Veh. Technol. 2020, 70, 429–445. [Google Scholar] [CrossRef]
- Seetharaman, R.; Tharun, M.; Anandan, K. A Novel approach in Hybrid Median Filtering for Denoising Medical images. Mater. Sci. Eng. 2021, 1187, 012028. [Google Scholar] [CrossRef]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A Semantic Attention-Based Mask Oriented Bounding Box Representation for Multi-Category Object Detection in Aerial Images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef] [Green Version]
- Bosquet, B.; Mucientes, M.; Brea, V.M. STDnet-ST: Spatio-temporal ConvNet for small object detection. Pattern Recognit. 2021, 116, 107929. [Google Scholar] [CrossRef]
- Zeng, Y.; Dai, T.; Chen, B.; Xia, S.T.; Lu, J. Correlation-based Structural Dropout for Convolutional Neural Networks. Pattern Recognit. 2021, 120, 108117. [Google Scholar] [CrossRef]
- Zhu, L.; Xie, Z.; Liu, L.; Tao, B.; Tao, W. IoU-uniform R-CNN: Breaking through the limitations of RPN. Pattern Recognit. 2021, 112, 107816. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel | Feature Maps | Activation Function |
|---|---|---|---|
| Conv layer | 4 4 | 32 | ReLU |
| Max-pooling | 2 2 | — | — |
| Conv layer | 3 3 | 64 | ReLU |
| Conv layer | 3 3 | 64 | ReLU |
| Max-pooling | 2 2 | — | — |
| Flatten layer | — | — | — |
| Dense layer | — | — | ReLU |
| Dropout layer | — | — | — |
| Dense layer | — | — | softmax |
| Scene | Error ≤ 1 cm/Percentage | Error > 1 cm and Error ≤ 3 cm /Percentage | Error > 3 cm/Percentage | Speed (FPS) | |
|---|---|---|---|---|---|
| Good daylight | 95/95% | 5/5% | 0/0 | 11.3 | |
| Infrared lighting at night | 100/100% | 0/0 | 0/0 | 10.7 | |
| Strong light | 99/99% | 1/1% | 0/0 | 11.4 | |
| Transparent water body | 46/46% | 45/45% | 9/9% | 11.2 | |
| Rainfall | 95/95% | 5/5% | 0/0 | 11.4 | |
| Dirty water gauge | Slightly | 49/98% | 1/2% | 0/0 | 8.5 |
| Severe | 0/0 | 0/0 | 50/100% | 8.4 | |
| Model | Precision | Number of Missed Objects/Percentage | Speed (FPS) |
|---|---|---|---|
| YOLOv5s | 99.7% | 46/4.6% | 31 |
| Class | Accuracy | Average Accuracy |
|---|---|---|
| 0 | 100% | 99.6% |
| 1 | 100% | |
| 2 | 100% | |
| 3 | 98% | |
| 4 | 100% | |
| 5 | 100% | |
| 6 | 100% | |
| 7 | 100% | |
| 8 | 98% | |
| 9 | 100% |
| Scene | Item | ||||||
|---|---|---|---|---|---|---|---|
| Processing Time (s) | Error ≤ 1 cm/Percentage | Error > 1 cm and Error ≤ 3 cm/Percentage | Error > 3 cm/Percentage | Average Error (cm) | |||
| Daylight | 0.34 | 95/95% | 5/5% | 0/0 | 0.57 | 0.77 | |
| Infrared Lighting at night | 0.22 | 98/98% | 2/2% | 0/0 | 0.54 | ||
| Strong light | 0.22 | 97/97% | 2/2% | 1/1% | 0.63 | ||
| Transparent water body | 0.68 | 45/45% | 44/44% | 11/11% | 1.74 | ||
| Rainfall | 0.16 | 91/91% | 9/9% | 0/0 | 0.64 | ||
| Dirty water gauge | Slightly | 0.23 | 45/90% | 5/10% | 0/0 | 0.62 | |
| Severely | 0.24 | 0/0 | 0/0 | 50/100% | 5.37 | — | |
| Scene | Item | ||||||
|---|---|---|---|---|---|---|---|
| Processing Time (s) | Error ≤ 1 cm/Percentage | Error > 1 cm and Error ≤ 3 cm/Percentage | Error > 3 cm/Percentage | Average Error (cm) | |||
| Daylight | 1.50 | 56/56% | 37/37% | 7/7% | 1.38 | 2.92 | |
| Infrared lighting at night | 1.42 | 16/16% | 75/75% | 9/9% | 1.97 | ||
| Strong light | 1.51 | 43/43% | 17/17% | 40/40% | 2.67 | ||
| Transparent water body | 1.53 | 3/3% | 5/5% | 92/92% | 5.37 | ||
| Rainfall | 1.51 | 9/9% | 9/9% | 82/82% | 4.72 | ||
| Dirty water gauge | Slightly | 1.49 | 3/6% | 30/60% | 17/34% | 1.44 | |
| Severely | 1.55 | 0/0 | 0/0 | 50/100% | 5.97 | — | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, G.; Yang, M.; Wang, H. A Water Level Measurement Approach Based on YOLOv5s. Sensors 2022, 22, 3714. https://doi.org/10.3390/s22103714
Qiao G, Yang M, Wang H. A Water Level Measurement Approach Based on YOLOv5s. Sensors. 2022; 22(10):3714. https://doi.org/10.3390/s22103714
Chicago/Turabian StyleQiao, Guangchao, Mingxiang Yang, and Hao Wang. 2022. "A Water Level Measurement Approach Based on YOLOv5s" Sensors 22, no. 10: 3714. https://doi.org/10.3390/s22103714
APA StyleQiao, G., Yang, M., & Wang, H. (2022). A Water Level Measurement Approach Based on YOLOv5s. Sensors, 22(10), 3714. https://doi.org/10.3390/s22103714