
Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery



Abstract
:1. Introduction
- Train and test fully supervised deep learning models to segment cotton bolls from both indoor and infield images;
- Develop weakly supervised methods based on class activation maps and multi-instance learning to segment cotton bolls from both indoor and infield images;
- Compare the supervised and weakly supervised methods in terms of their performance on boll counting and annotation efficiency.
2. Materials and Methods
2.1. Data Source and Pre-Screening
2.2. Annotation Approaches
2.3. Fully Supervised Learning Approaches
2.3.1. Mask R-CNN
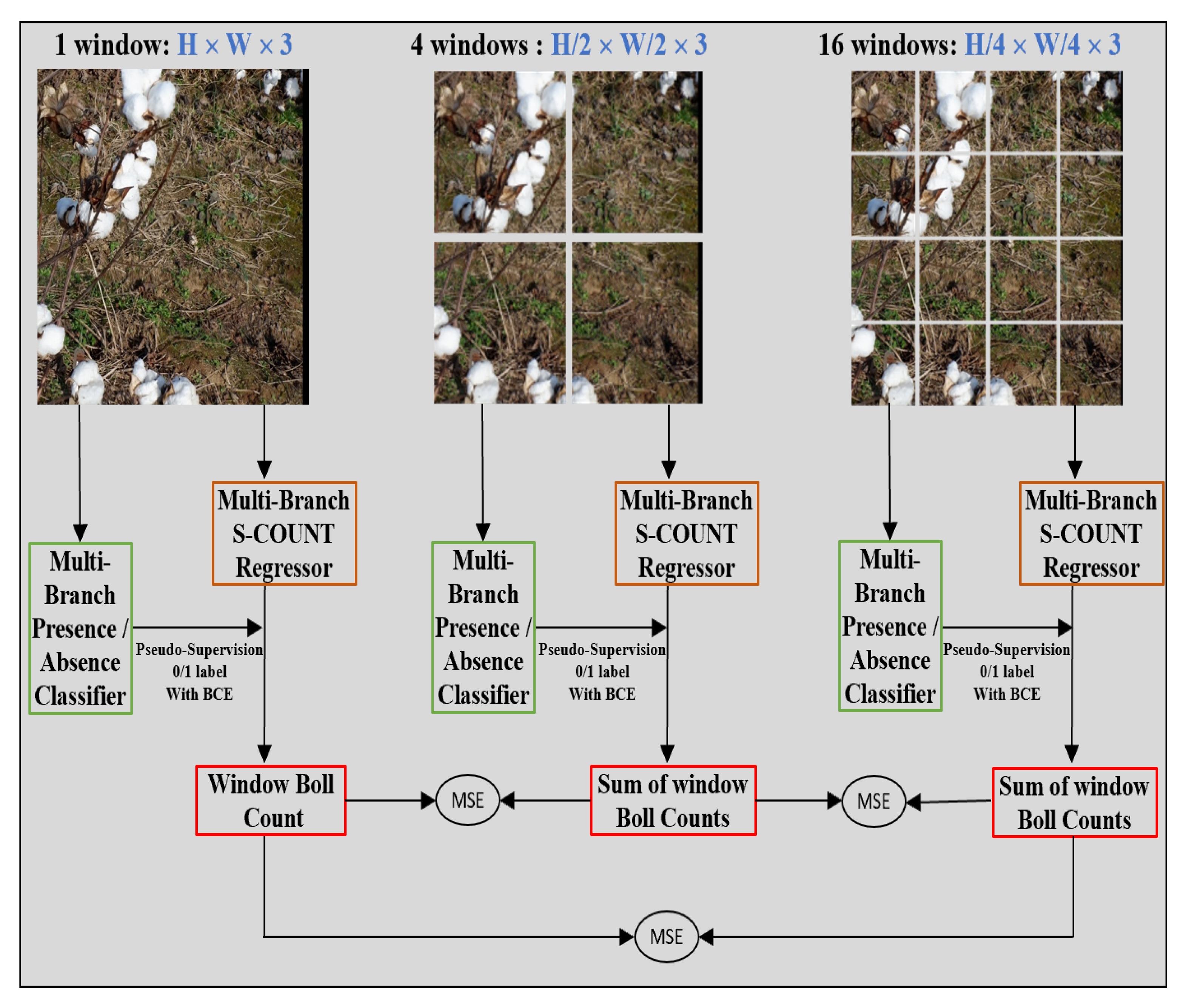
2.3.2. Supervised Count Regression: S-Count
2.4. Weakly Supervised Learning
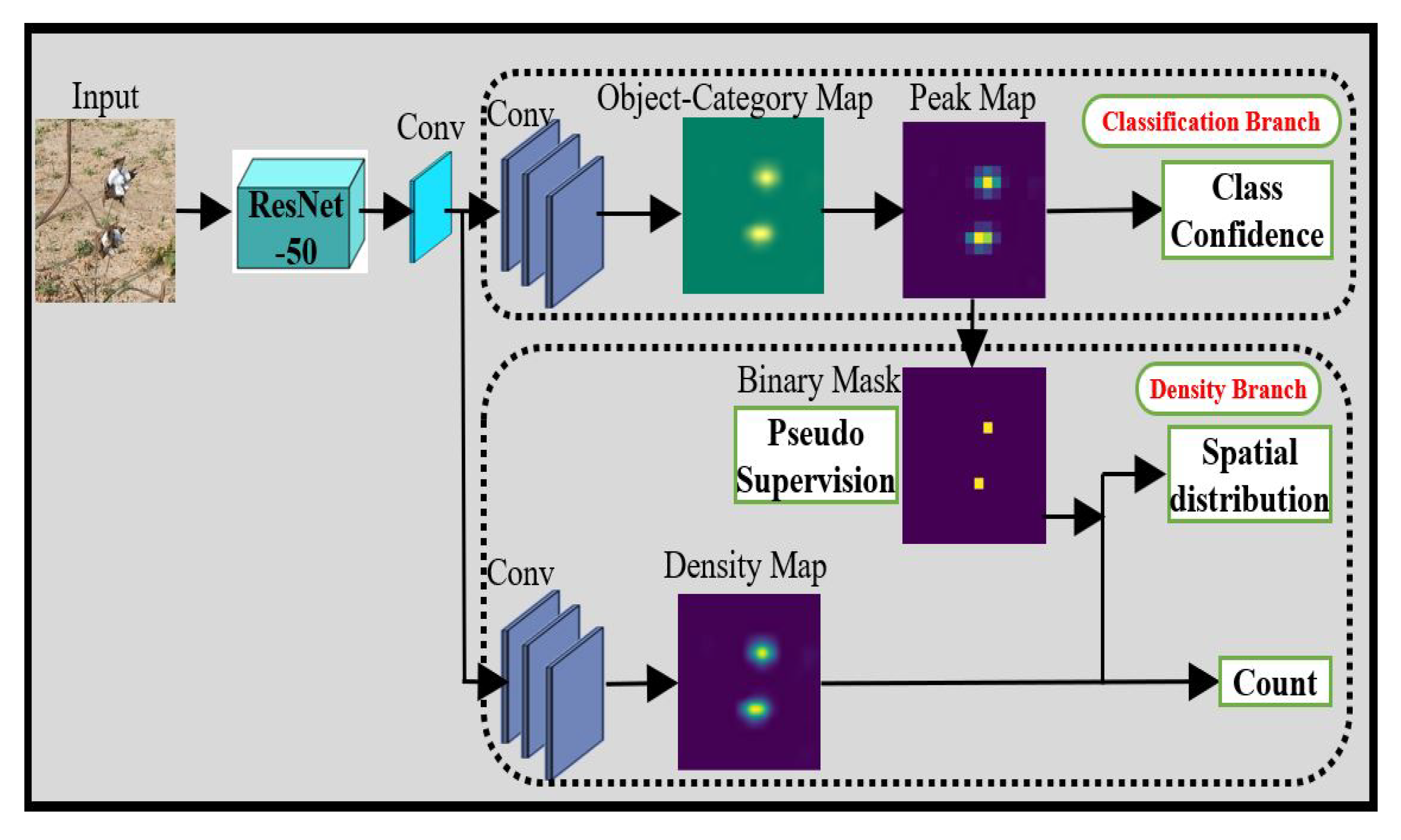
2.4.1. MIL-CAM Based Weakly Supervised Counting: WS-Count
2.4.2. CAM Based Counting with Partial Labels: CountSeg
2.5. Boll Counting
2.6. Evaluation Metrics
2.7. Implementation Details
3. Results and Discussion
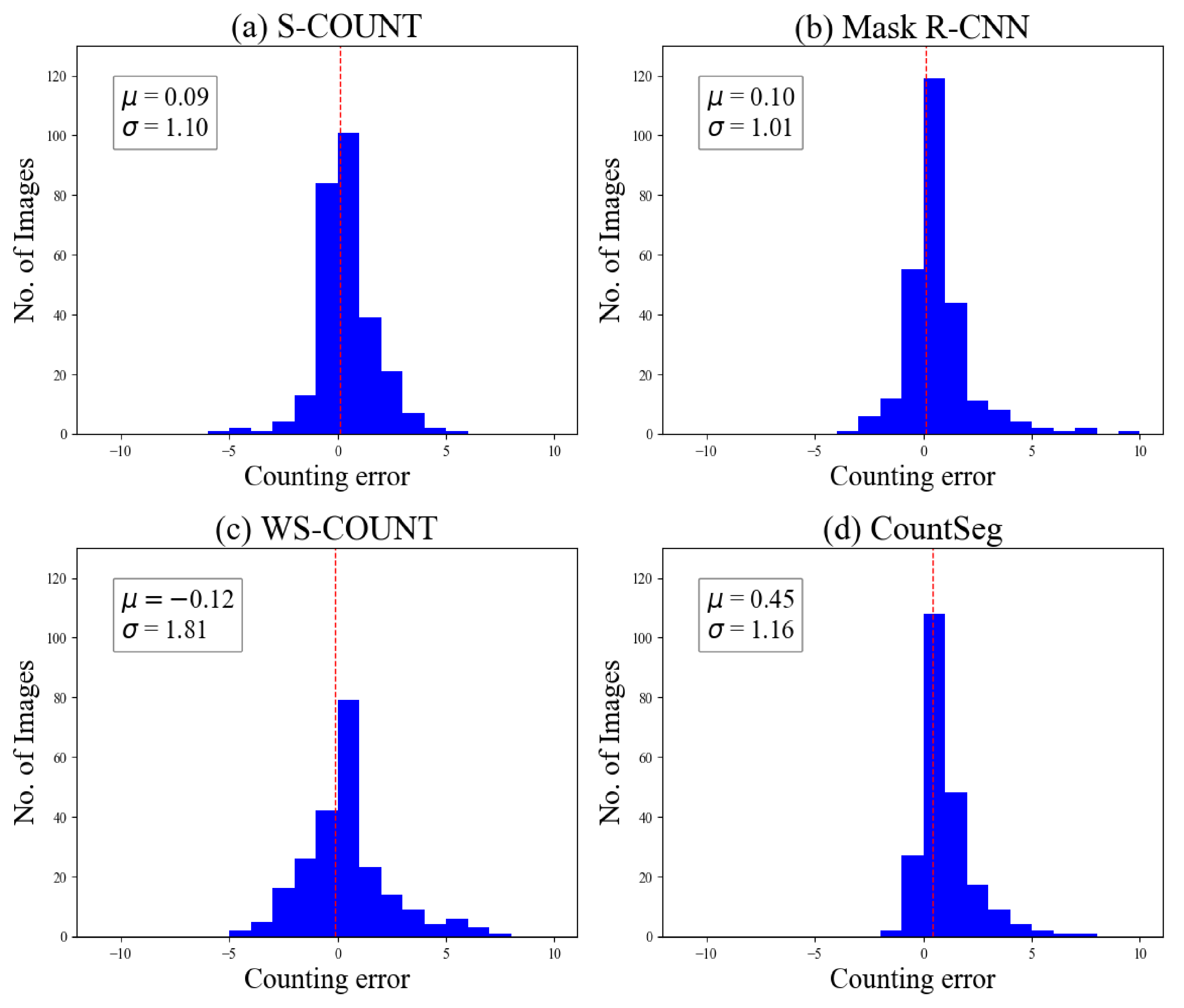
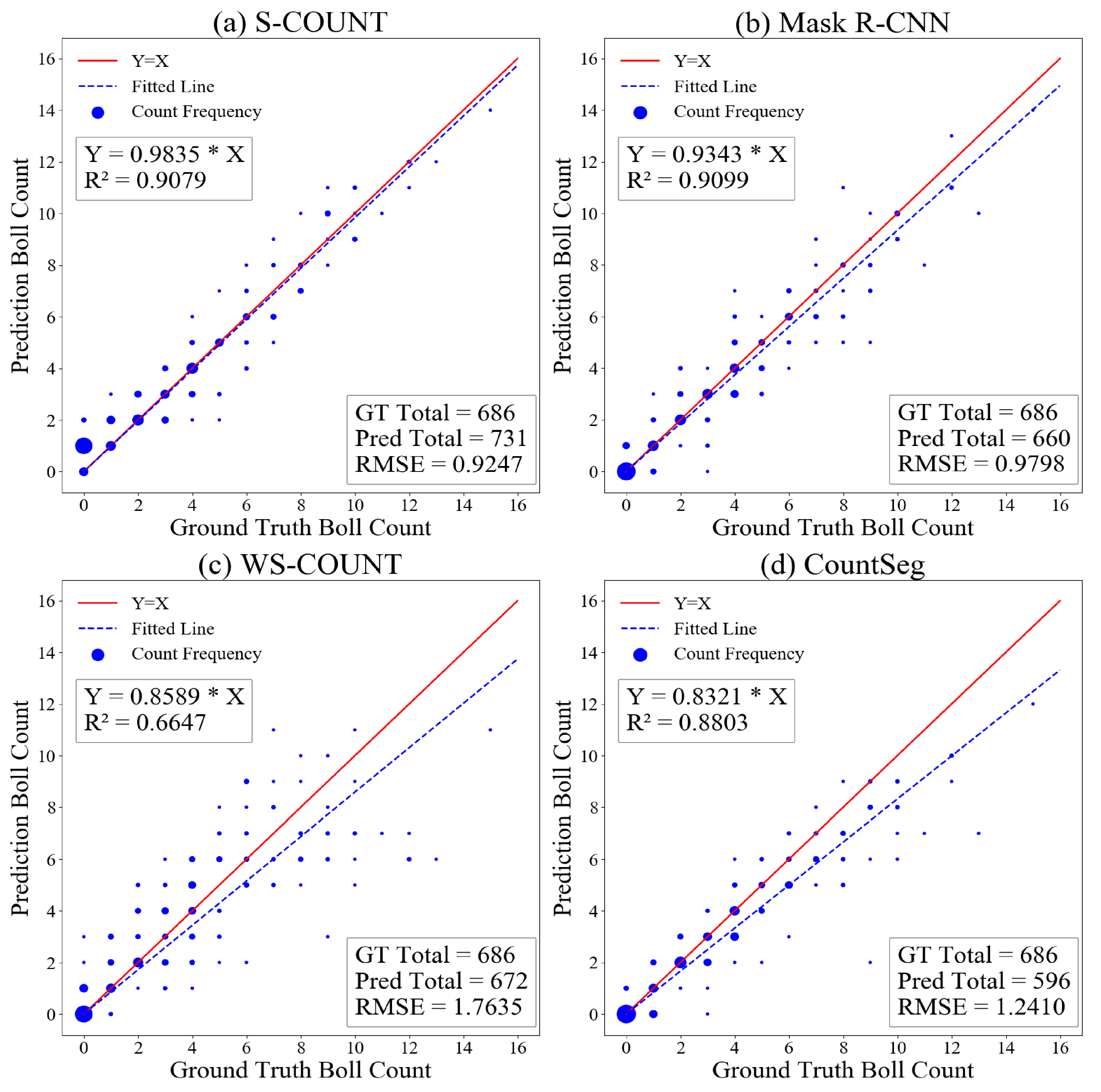
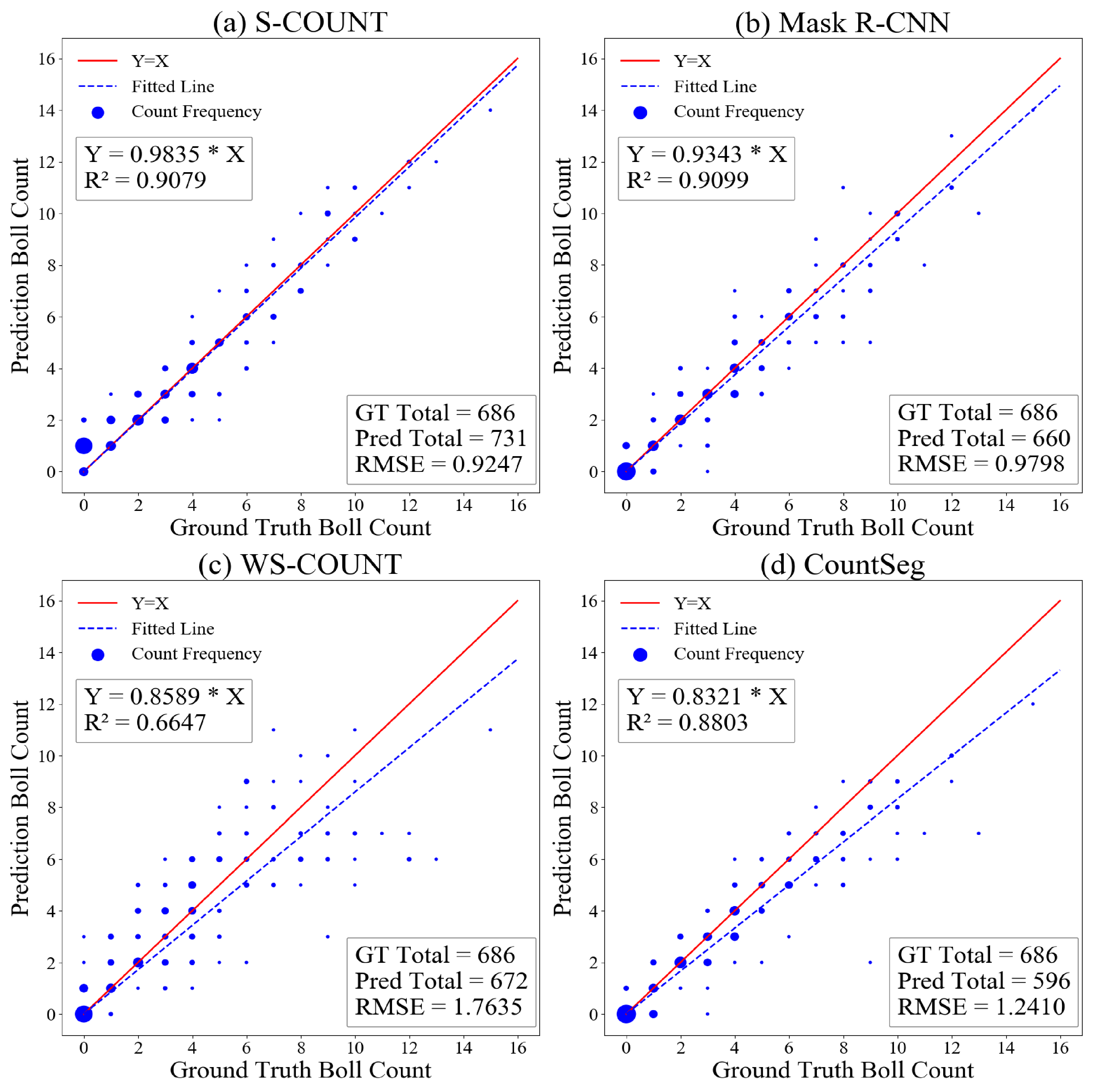
3.1. Model Performance on Boll Counting Accuracy
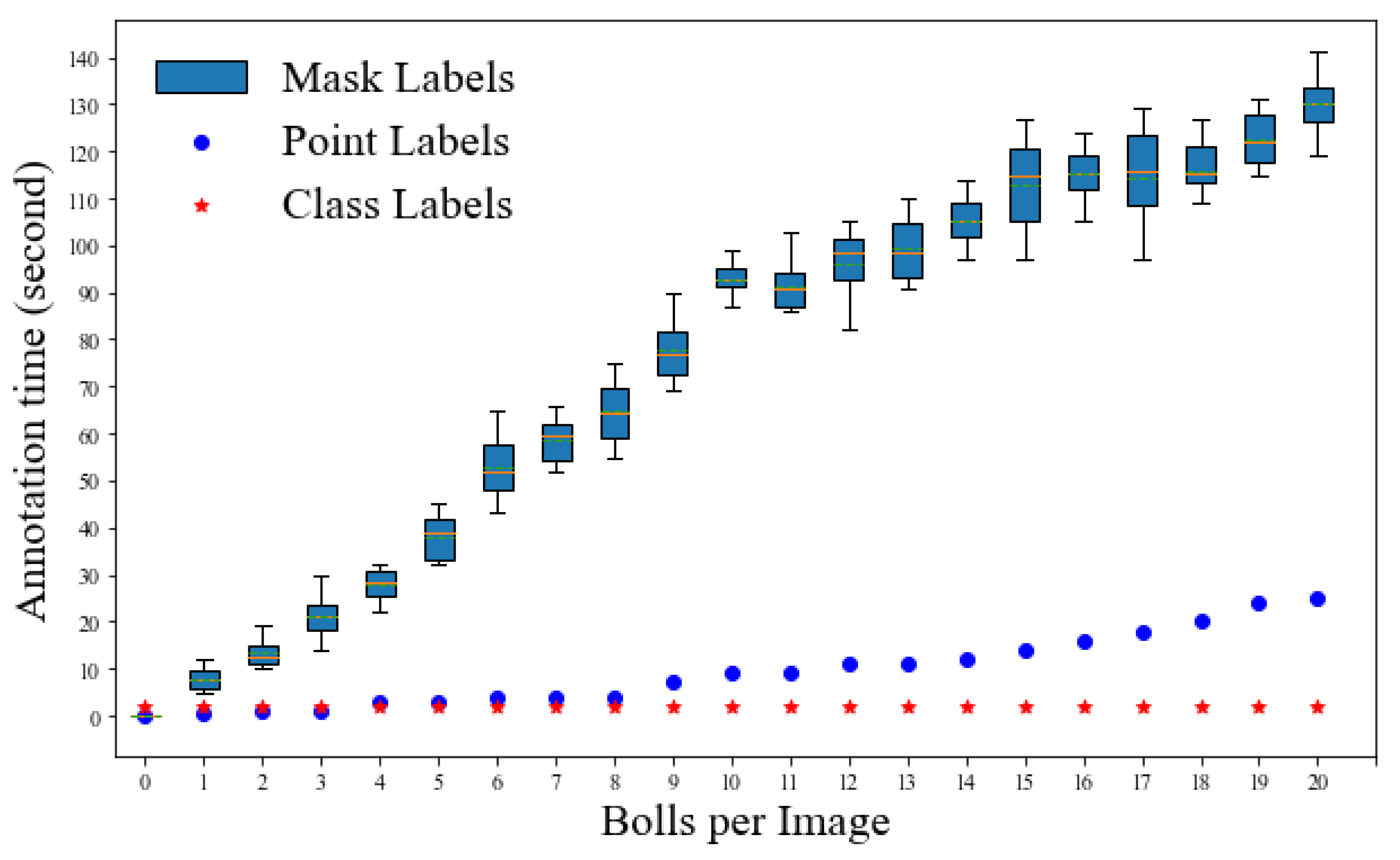
3.2. Annotation Time Comparison
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAOSTAT. FAOSTAT Statistical Database; FAO (Food and Agriculture Organization of the United Nations): Rome, Italy, 2019. [Google Scholar]
- Pabuayon, I.L.B.; Kelly, B.R.; Mitchell-McCallister, D.; Coldren, C.L.; Ritchie, G.L. Cotton boll distribution: A review. Agron. J. 2021, 113, 956–970. [Google Scholar] [CrossRef]
- Normanly, J. High-Throughput Phenotyping in Plants: Methods and Protocols; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Pabuayon, I.L.B.; Yazhou, S.; Wenxuan, G.; Ritchie, G.L. High-throughput phenotyping in cotton: A review. J. Cotton Res. 2019, 2, 1–9. [Google Scholar] [CrossRef]
- Uddin, M.S.; Bansal, J.C. Computer Vision and Machine Learning in Agriculture; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Jiang, Y.; Li, C. Convolutional Neural Networks for Image-Based High-Throughput Plant Phenotyping: A Review. Plant Phenomics 2020, 2020, 4152816. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep neural networks based recognition of plant diseases by leaf image classification. Comput. Intell. Neurosci. 2016, 2016, 3289801. [Google Scholar] [CrossRef] [Green Version]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Plant disease detection and classification by deep learning. Plants 2019, 8, 468. [Google Scholar] [CrossRef] [Green Version]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning–Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Xu, R.; Sun, S.; Robertson, J.S.; Paterson, A.H. DeepFlower: A deep learning-based approach to characterize flowering patterns of cotton plants in the field. Plant Methods 2020, 16, 1–17. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Paterson, A.H.; Robertson, J.S. DeepSeedling: Deep convolutional network and Kalman filter for plant seedling detection and counting in the field. Plant Methods 2019, 15, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Petti, D.J.; Li, C. Graph Neural Networks for Plant Organ Tracking. In Proceedings of the 2021 ASABE Annual International Virtual Meeting, online, 12–16 July 2021; American Society of Agricultural and Biological Engineers: St. Joseph, MN, USA, 2021; p. 1. [Google Scholar]
- Tan, C.; Li, C.; He, D.; Song, H. Towards real-time tracking and counting of seedlings with a one-stage detector and optical flow. Comput. Electron. Agric. 2022, 193, 106683. [Google Scholar] [CrossRef]
- Sun, S.; Li, C.; Paterson, A.H.; Chee, P.W.; Robertson, J.S. Image processing algorithms for infield single cotton boll counting and yield prediction. Comput. Electron. Agric. 2019, 166, 104976. [Google Scholar] [CrossRef]
- Sun, S.; Li, C.; Chee, P.W.; Paterson, A.H.; Jiang, Y.; Xu, R.; Robertson, J.S.; Adhikari, J.; Shehzad, T. Three-dimensional photogrammetric mapping of cotton bolls in situ based on point cloud segmentation and clustering. ISPRS J. Photogramm. Remote Sens. 2020, 160, 195–207. [Google Scholar] [CrossRef]
- Sun, S.; Li, C.; Chee, P.W.; Paterson, A.H.; Meng, C.; Zhang, J.; Ma, P.; Robertson, J.S.; Adhikari, J. High resolution 3D terrestrial LiDAR for cotton plant main stalk and node detection. Comput. Electron. Agric. 2021, 187, 106276. [Google Scholar] [CrossRef]
- Li, Y.; Cao, Z.; Lu, H.; Xiao, Y.; Zhu, Y.; Cremers, A.B. In-field cotton detection via region-based semantic image segmentation. Comput. Electron. Agric. 2016, 127, 475–486. [Google Scholar] [CrossRef]
- Cholakkal, H.; Sun, G.; Khan, F.S.; Shao, L. Object counting and instance segmentation with image-level supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12397–12405. [Google Scholar]
- Zhang, D.; Han, J.; Cheng, G.; Yang, M.H. Weakly Supervised Object Localization and Detection: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2002, 15, 577–584. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Wang, H.; Li, H.; Qian, W.; Diao, W.; Zhao, L.; Zhang, J.; Zhang, D. Dynamic Pseudo-Label Generation for Weakly Supervised Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 1461. [Google Scholar] [CrossRef]
- Lin, C.; Wang, S.; Xu, D.; Lu, Y.; Zhang, W. Object instance mining for weakly supervised object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11482–11489. [Google Scholar]
- Durand, T.; Mordan, T.; Thome, N.; Cord, M. Wildcat: Weakly supervised learning of deep convnets for image classification, pointwise localization and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 642–651. [Google Scholar]
- Wang, J.; Yao, J.; Zhang, Y.; Zhang, R. Collaborative learning for weakly supervised object detection. arXiv 2018, arXiv:1802.03531. [Google Scholar]
- Zhou, Y.; Zhu, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Weakly supervised instance segmentation using class peak response. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3791–3800. [Google Scholar]
- Chamanzar, A.; Nie, Y. Weakly supervised multi-task learning for cell detection and segmentation. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 513–516. [Google Scholar]
- Qu, H.; Wu, P.; Huang, Q.; Yi, J.; Riedlinger, G.M.; De, S.; Metaxas, D.N. Weakly supervised deep nuclei segmentation using points annotation in histopathology images. In Proceedings of the International Conference on Medical Imaging with Deep Learning, PMLR, London, UK, 8–10 July 2019; pp. 390–400. [Google Scholar]
- Bollis, E.; Pedrini, H.; Avila, S. Weakly Supervised Learning Guided by Activation Mapping Applied to a Novel Citrus Pest Benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, virtual, 14–19 June 2020. [Google Scholar]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.R.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S.; et al. A weakly supervised deep learning framework for sorghum head detection and counting. Plant Phenomics 2019, 2019, 1525874. [Google Scholar] [CrossRef] [Green Version]
- Tong, P.; Zhang, X.; Han, P.; Bu, S. Point in: Counting Trees with Weakly Supervised Segmentation Network. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9546–9552. [Google Scholar]
- Yu, G.; Zare, A.; Xu, W.; Matamala, R.; Reyes-Cabrera, J.; Fritschi, F.B.; Juenger, T.E. Weakly Supervised Minirhizotron Image Segmentation with MIL-CAM. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 433–449. [Google Scholar]
- Bellocchio, E.; Ciarfuglia, T.A.; Costante, G.; Valigi, P. Weakly supervised fruit counting for yield estimation using spatial consistency. IEEE Robot. Autom. Lett. 2019, 4, 2348–2355. [Google Scholar] [CrossRef]
- Cheng, B.; Parkhi, O.; Kirillov, A. Pointly-Supervised Instance Segmentation. arXiv 2021, arXiv:2104.06404. [Google Scholar]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). Version: 2.0.10. 2016. Available online: http://www.robots.ox.ac.uk/vgg/software/via/ (accessed on 1 March 2021).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cholakkal, H.; Sun, G.; Khan, S.; Khan, F.S.; Shao, L.; Van Gool, L. Towards partial supervision for generic object counting in natural scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1604–1622. [Google Scholar] [CrossRef] [PubMed]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. GitHub Repository. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 1 March 2021).
- Jung, A.B. Imgaug. GitHub Repository. 2018. Available online: https://github.com/aleju/imgaug (accessed on 1 March 2021).
- Bellocchio, E. WS-COUNT. GitHub Repository. 2019. Available online: https://github.com/isarlab-department-engineering/WS-COUNT (accessed on 1 March 2021).
- Sun, G. Object Counting and Instance Segmentation with Image-Level Supervision. GitHub Repository. 2020. Available online: https://github.com/GuoleiSun/CountSeg (accessed on 1 March 2021).
- University of Georgia. The Georgia Advanced Computing Resource Center (GACRC). 2015. Available online: https://gacrc.uga.edu/ (accessed on 1 March 2021).
- Bellocchio, E.; Costante, G.; Cascianelli, S.; Fravolini, M.L.; Valigi, P. Combining Domain Adaptation and Spatial Consistency for Unseen Fruits Counting: A Quasi-Unsupervised Approach. IEEE Robot. Autom. Lett. 2020, 5, 1079–1086. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, J.; Peng, J.; Zhang, L. Boosting Weakly Supervised Object Detection with Progressive Knowledge Transfer. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 615–631. [Google Scholar]
- Sun, S.; Li, C.; Paterson, A.H.; Jiang, Y.; Xu, R.; Robertson, J.S.; Snider, J.L.; Chee, P.W. In-field High Throughput Phenotyping and Cotton Plant Growth Analysis Using LiDAR. Front. Plant Sci. 2018, 9, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saeed, F.; Li, C. Plant organ segmentation from point clouds using Point-Voxel CNN. In Proceedings of the 2021 ASABE Annual International Virtual Meeting, online, 12–16 July 2021; American Society of Agricultural and Biological Engineers: St. Joseph, MN, USA, 2021; p. 1. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Set | No. of Images | No. of Tiles Generated | No. of Bolls |
|---|---|---|---|
| Training + Testing | 285 | 4266 | 23,651 |
| Full Plant Testing | 5 | 84 | 217 |
| Total | 290 | 4350 | 23,868 |
| Boll Count per Image | Training Tiles | Validation Tiles | Testing Tiles | Total |
|---|---|---|---|---|
| 0 | 919 | 50 | 21 | 990 |
| [1, 5] | 1852 | 102 | 48 | 2002 |
| [6, 10] | 710 | 42 | 6 | 758 |
| [11, 15] | 231 | 6 | 3 | 240 |
| above 15 | 300 (DNC) | 54 (DNC) | 6 | 360 |
| Total | 3712 | 200 | 84 | 4350 |
| Boll Count/Image | 0 | [1–5] | [6–10] | [11–15] | Total |
|---|---|---|---|---|---|
| Train/Test split | 919/50 | 1852/102 | 710/42 | 231/6 | 3712/200 |
| S-Count | 0.582 ± 0.25 | 1.069 ± 0.16 | 1.556 ± 0.26 | 2.430 ± 1.04 | 1.181 ± 0.16 |
| WS-Count | 0.708 ± 0.07 | 1.431 ± 0.25 | 2.489 ± 0.23 | 5.314 ± 0.39 | 1.826 ± 0.05 |
| CountSeg | 0.286 ± 0.06 | 0.869 ± 0.02 | 1.978 ± 0.14 | 3.805 ± 0.45 | 1.284 ± 0.08 |
| Mask R-CNN | 0.566 ± 0.20 | 0.982 ± 0.04 | 1.586 ± 0.42 | 2.884 ± 1.03 | 1.175 ± 0.20 |
| Image ID | Boll_008 | Boll_022 | Boll_041 | Boll_116 | Boll_127 |
|---|---|---|---|---|---|
| Actual Count | 41 | 34 | 100 | 20 | 22 |
| S-Count | 43.6 ± 4.22 | 41.8 ± 11.12 | 87.8 ± 7.50 | 16.4 ± 1.67 | 21.4 ± 1.67 |
| WS-Count | 48.2 ± 1.31 | 40.2 ± 3.49 | 86.4 ± 2.79 | 23.2 ± 1.48 | 18.8 ± 1.30 |
| CountSeg | 37.8 ± 2.49 | 34.2 ± 0.84 | 81.8 ± 3.56 | 17.0 ± 0.00 | 18.0 ± 1.414 |
| Mask R-CNN | 46.0 ± 6.16 | 34.8 ± 1.90 | 89.0 ± 3.94 | 17.2 ± 0.84 | 21.2 ± 0.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adke, S.; Li, C.; Rasheed, K.M.; Maier, F.W. Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery. Sensors 2022, 22, 3688. https://doi.org/10.3390/s22103688
Adke S, Li C, Rasheed KM, Maier FW. Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery. Sensors. 2022; 22(10):3688. https://doi.org/10.3390/s22103688
Chicago/Turabian StyleAdke, Shrinidhi, Changying Li, Khaled M. Rasheed, and Frederick W. Maier. 2022. "Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery" Sensors 22, no. 10: 3688. https://doi.org/10.3390/s22103688
APA StyleAdke, S., Li, C., Rasheed, K. M., & Maier, F. W. (2022). Supervised and Weakly Supervised Deep Learning for Segmentation and Counting of Cotton Bolls Using Proximal Imagery. Sensors, 22(10), 3688. https://doi.org/10.3390/s22103688