1. Introduction
A non-orthogonal multiple access (NOMA) system has been classified as promoting a multiple access structure for future wireless systems to boost system throughput and spectral efficacy. NOMA could utilize the present resources more effectively by resourcefully benefiting from the users’ channel environments and providing numerous users with distinct quality of service (QoS) demands. NOMA enables several users to achieve simultaneous arrival to the same time-frequency block by superpositioning them in the code or power domains [
1]. The concept of NOMA is established on that the user with a weak channel condition can be combined with the user with a good channel condition in the same time slot and on the same allocated subcarrier to ensure that the bandwidth block could be effectively exploited [
2].
In the NOMA scheme, receiver equipment will receive the multiplexing of symbols from different users in the system; therefore, elimination of interference from other users is necessary for coordinated decoding.
Generally, multiuser detection (MUD) in NOMA can be managed through SIC, which was carried out in the power domain. In the SIC technique, symbols from several users are decoded consecutively based on the allocated signal power and the channel state information (CSI) [
3]. Complete realization of CSI or channel status for individual users is challenging, since pilot symbols that are utilized in channel estimation may interfere with symbols from other users, thus influencing the performance of classical channel estimation procedures, such as minimum mean square error and least square estimators [
4]. Machine learning (ML) algorithms have the capability to adapt to variations in channel between user and base station (BS); therefore, ML is regarded as a strong contender for future radio networks [
5].
1.1. Related Works
In [
6], the authors introduced DL-based detector for the multiuser downlink OFDM-NOMA system. The authors mainly depended on pilot signals for the channel information, and according to these pilot responses, a DL based joint channel estimation and symbol detection was achieved without additional processing for channel estimation. The simulation’s outcomes revealed that the proposed DL scheme outperforms the conventional SIC-based detector. On the other hand, the proposed scheme needed to be initially trained offline for different channel conditions and the simulation results were presented in terms of BER only.
In [
7], the authors suggested a deep learning framework to perform signal recovery in the MIMO-NOMA system when the Rayleigh fading channel is considered. The proposed technique can simultaneously carry out the channel estimation process and signal detection. Simulations were conducted for the proposed DL scheme, and the results were compared with the conventional SIC procedure in terms of the symbol error rate (SER) and throughput. According to the simulation results, the proposed DL scheme can address channel impairment, but the examined NOMA cell was limited for two users and an offline training stage was also required. Also, the DNN training phase needed two components, the received signal, and the labels, which were used as supervised data to help the DNN to optimize the parameters.
In [
8], the authors proposed a data-driven deep learning estimator for time- and frequency-selective channels. The proposed algorithm was designed such that a pre-training scheme and pilot symbols were utilized as inputs for the DNN to attain a desired initialization, which can further enhance the performance of the DL estimator. The DNN was trained offline in both the pre-training and training stages, while in the testing stage, the channels could be dynamically tracked by the DNN with only pilots identified, and then the transmitted symbols were detected. The performance of a DL estimator with different numbers of layers was investigated and the numerical results demonstrated that the proposed DL estimator outperformed the standard channel estimator in terms of efficiency and robustness.
In [
9], a deep learning approach was employed to estimate the downlink channel and to reduce the training overhead in a fog radio access network. The Gated Recurrent Unit (GRU) was utilized to learn the hidden correlations among the channel matrices from different users, and a bidirectional GRU was also employed to further improve the estimation performance. Simulation results were provided to demonstrate the performance gains, but the examined performance metrics were limited to the loss function and mean square error.
Based on the deep learning (DL) algorithm, the authors in [
10] introduced a sliding window Gated Recurrent Unit (GRU) channel estimator to acquire knowledge for the time-varying Rayleigh fading channel. Interleaver and channel coding schemes were merged with the proposed sliding window estimator to further enhance system performance. The simulation results proved the ability of the suggested procedure to follow the channel in a reliable way and achieve better mean square error (MSE). Moreover, the sliding window-based GRU estimator was examined with different numbers of pilot symbols, and the robustness against the variations in the channel characteristics was analyzed.
In [
11], the authors went to conclude that DL algorithm can be utilized in signal detection for uplink analysis in NOMA network. The authors proposed a DL approach to characterize the complex channel parameters, where restricted Boltzmann machines (RBM) were implemented as a pre-training phase for the original input sequence for the network. The proposed learning scenario based on LSTM layer could track the environment statistics automatically via offline learning and an iterative support detection procedure was suggested to identify the transmitted symbols. Performance analysis for the proposed DL scheme was evaluated merely in terms of the sum data rate and block error rate.
In [
12], a pilot-aided receiver structure was presented for an uplink single input, multi output (SIMO) NOMA system, which incorporated a combined channel estimation and signal detection scheme for random channels. The authors brought together a deep learning model with SIC detection structure to minimize the learnable parameters. Furthermore, signal detection accuracy improvement and noise interference reduction were achieved by adding noise and interference elimination factors at the SIC detection stage. The simulation results indicated that BER performance based on the proposed DL scheme was more acceptable than the traditional MMSE procedure and the complexity of the receiver was diminished.
In [
13], the authors proposed a semi-blind mutual detection scheme-based DL to distinguish users’ symbols in the co-operative NOMA system. The proposed method was capable of detecting the signal without the need for further channel estimation process since it could achieve a simultaneous detection on the basis of pilot responses. The DL model was trained offline over a Rayleigh fading channel and the trained network was deployed in the online detection phase. In addition, the trained model was inspected using Rician and Na-agami-m fading channels and simulation outcomes proved the capability of the proposed scheme in outperforming conventional detectors.
In [
14], the authors examined deep neural network (DNN) for combined channel estimation and signal detection in an OFDM system. This approach considered OFDM system and fading channel as a black box and the presented DNN network is trained offline using simulated data. The simulation results revealed that the proposed DL approach had the capability to learn and investigate the complicated attributes of the wireless channels. In addition, the results of the DL approach proved its dominance over conventional methods when fewer pilot symbols were utilized, and cyclic prefix was ignored.
1.2. Research Gap and Motivation
Based on the previous works, many deep neural networks (DNN) approaches have been proposed explicitly to address the issues associated with channel state information (CSI), channel estimation, and signal detection. To the best of authors’ knowledge, there has been no study that has investigated the combination between Deep learning (DL)-based channel estimation algorithm and the optimal power allocation scheme for multiuser detection in a downlink non-orthogonal multiple access (NOMA) system in fading channels. Most of the works are managing the issues of power optimization and deep learning-based channel estimation separately.
In addition, many of the proposed DNN approaches for channel estimation require pre-training to obtain the appropriate DNN weights initialization, which may lead to an increase of the number of hidden layers with a huge number of neurons in each layer. In order to enhance the aforementioned schemes, this work proposes a framework that examine the integration between DNN-based channel estimation and the optimum power allocation scheme in a multiuser NOMA system and then inspect the system performance. Furthermore, in our proposed system structure, we manage to eliminate the need for a pre-training stage, minimize the number of DNN layers, and minimize the number of pilot symbols, and at the same time, we can realize a notable improvement in network convergence.
1.3. Contributions to Knowledge
The detailed contributions of this work are outlined as follows:
In this work, a framework is proposed that highlights how the channel estimation-based Deep Learning (DL) and power optimization scheme are jointly utilized for multiuser (MU) detection in the PD-NOMA system.
A structured and mathematical analysis is introduced to derive a non-complex analytical form for the optimum power coefficient for each user on the basis of maximizing the sum rates in a downlink NOMA system.
An optimized power scheme and fixed power scheme are both evaluated and compared when the proposed Deep Learning-based channel estimation scheme is implemented.
To validate the efficiency of the proposed Deep Learning channel estimation scheme, the DNN model is inspected using a Rayleigh fading channel and Rician fading channel.
As a benchmark comparison, we have also conducted the simulation environment related to the work that consider the DL for joint channel estimation and signal detection and compared it with our proposed DL scheme. The simulation results emphasized that reliability can be guaranteed by our proposed DL channel estimation scheme even when cell capacity is increased.
In addition, different from the aforementioned works, in our proposed DL channel estimation algorithm, we implement a minimum number of DNN layers and a minimum number of pilot symbols to achieve a remarkable improvement in system performance. Moreover, no additional interference cancelation or noise elimination factors are utilized on the receiver side.
The rest of this paper is organized as follows.
Section 2 presents the system model. In
Section 3, the characterization for the optimization problem is introduced. In
Section 4, the optimization analysis is discussed in detail. In
Section 5, RNN and LSTM DL schemes are described.
Section 6 discusses the LSTM and NOMA framework. The channel estimation algorithm is summarized in
Section 7. In
Section 8, the simulation environment is described. In
Section 9, the simulation results are discussed. Finally, the conclusions and future work are drawn in
Section 10.
2. System Model
The downlink NOMA system is examined in this section, where the base station (BS) and users come across various channel gains. In this system, the NOMA cell is considered, where one BS with a single antenna is assumed to serve three users concurrently and every user equipment also has a single antenna. Typically, in NOMA scheme each user receives the combined signal sent from BS that comprise a target signal and interfering signal sent through the same time-frequency block. Consequently, multiplexing a number of signals using distinct power levels is essential to distinguish the signals and to reinforce the SIC procedure at the receiver side [
15]. In PD-NOMA, users that are characterized by good channel environments are usually allocated low power, while users with poor channel conditions can share high power levels.
Users are labeled in accordance with their fading channel and the separation from base station. In the examined cell, the nearby device is indicated as near user and the device at the edge of the cell is viewed as far user. In this work, we assume that we have three users in the cell and Rayleigh fading channel is considered with zero mean. Hence, the fading channel for each user can be mathematically characterized as follows, for the near user
, for the middle user
, and for the far user
, where
denotes the fading channel between the BS and the user
i and
k represents the path loss exponent [
16].
In this paper, Additive White Gaussian Noise (AWGN) is assumed at the receiver side of each user, and the noise power is indicated as
. Without loss of generality, it can be assumed that
. Total power transferred from BS to all devices in the cell is specified as
. In the NOMA system, the receiver at each user has the ability to carry out SIC to eliminate signals associated to other users with poor channel environments. On the other hand, symbols from users with good channel conditions could not be removed and treated as interference. In the downlink scenario, the BS can send the superposition coded signal
that can be expressed as [
12,
16]:
where
,
, and
are the power coefficients allocated to the near user, middle user, and far user individually. Likewise,
,
, and
denote the desired symbols concerned to near, middle, and far user, respectively. Hence, the signal received at far user can be represented as [
17]:
where
represent the fading channel among BS and far user, while
represents AWGN noise component at far user with zero mean and
variance. The far user is usually described by poor channel condition, and their particular signal
can be assigned additional power by BS compared to other users. Thus, according to SIC scheme, the far user can directly decode their own signal
from received signal
. The received signal for a far user device can be easily represented as [
17]:
The first term in (3) represents the required signal for a far user, while the second term denotes the interference term from middle and near users. Based on Equation (3), the possible rate for far user could be expressed as [
18]:
Likewise, the attainable bit rate for middle user can also be expressed as:
Typically, the near user has good channel condition along with BS; thus, their signal
is assigned low power, and therefore, the received signal for the near user can be shown as:
The first term in Equation (6) represents the near user expected signal, while the second term denotes the interfering term from middle and far users. On the other hand, it can be observed from Equation (6) that the interfering term is predominant due to the additional power that can be assigned to the far user. Therefore, at the near user side, SIC is performed, where immediate decoding for far user signal
is accomplished, then removed from the composite signal. Next, the middle user signal
is decoded and removed from the remaining signal. Finally, the near user achieved rate
can be expressed as [
18]:
4. Optimization Analysis
In this part, the optimization analysis is realized with regards to three users in the NOMA system and the objective function can simply reformulated as follows [
24]:
where
and
is the lowest rate required in the system. According to the analysis above, the constraints can also be represented as follows:
The constraints
are linear in terms of
, then
are convex. Hence,
need to be calculated [
21]. Initially, we can find the first derivative for
in Equation (14) with respect to each of the power coefficients
,
, and
. After some mathematical processing,
can be represented as follows [
24,
25]:
At this point, a general formula can be derived for the first derivative of the objective function in terms of
[
24,
25]:
The second derivative of the objective function
with respect to each of the power coefficients
,
, and
can also be derived as follows:
A general formula can also be found for the second derivative of the objective function in terms of
as follows:
Based on the objective function, and
and
, it can be proved that the objective function is concave and has a unique global maximum [
23]. The Lagrange function and the KKT necessary conditions could be employed to achieve optimal power factors [
25,
26]:
where
and
represent Lagrange multipliers for the three user scenarios.
Optimality conditions can be written as follows:
Slackness conditions can be represented as follows:
Lagrange multipliers also need to satisfy the following:
In the subsequent steps, Lagrange multipliers should be proved to be positive. This could be accomplished as follows:
Based on Equations (35)–(39), this can be substituted in the optimality conditions for Lagrange as follows:
Let
,
,
, and
. Therefore, the above written optimality conditions for Lagrange can be rewritten as:
Based on Equation (40) and after few mathematical substitutions, the following expression can be written as:
Performing a few mathematical analyses and based on the fact that
, we can simply prove that
and
are positive and the left-hand side of Equation (43) is positive. Furthermore, since
are negative scalar, the right-hand side of Equation (43) can be proved to be positive, which concludes that
is positive. Additionally, Equation (42) can be reformulated as follows:
where
is positive by inspection and
is negative quantity; therefore, the left-hand side must be positive, which implies that
is positive quantity.
Similarly,
can be proved to be positive value. In accordance with the above-mentioned analysis, the examined constraints are feasible, and the closed form representation for the power factors can be determined from the slackness conditions as follows:
For the following analysis, it can be assumed that and , , then Equation (45) can be written as and Equation (46) can be rewritten as .
Based on mathematical substitutions and arrangements, the closed form representation for each of the power coefficients can be derived as follows:
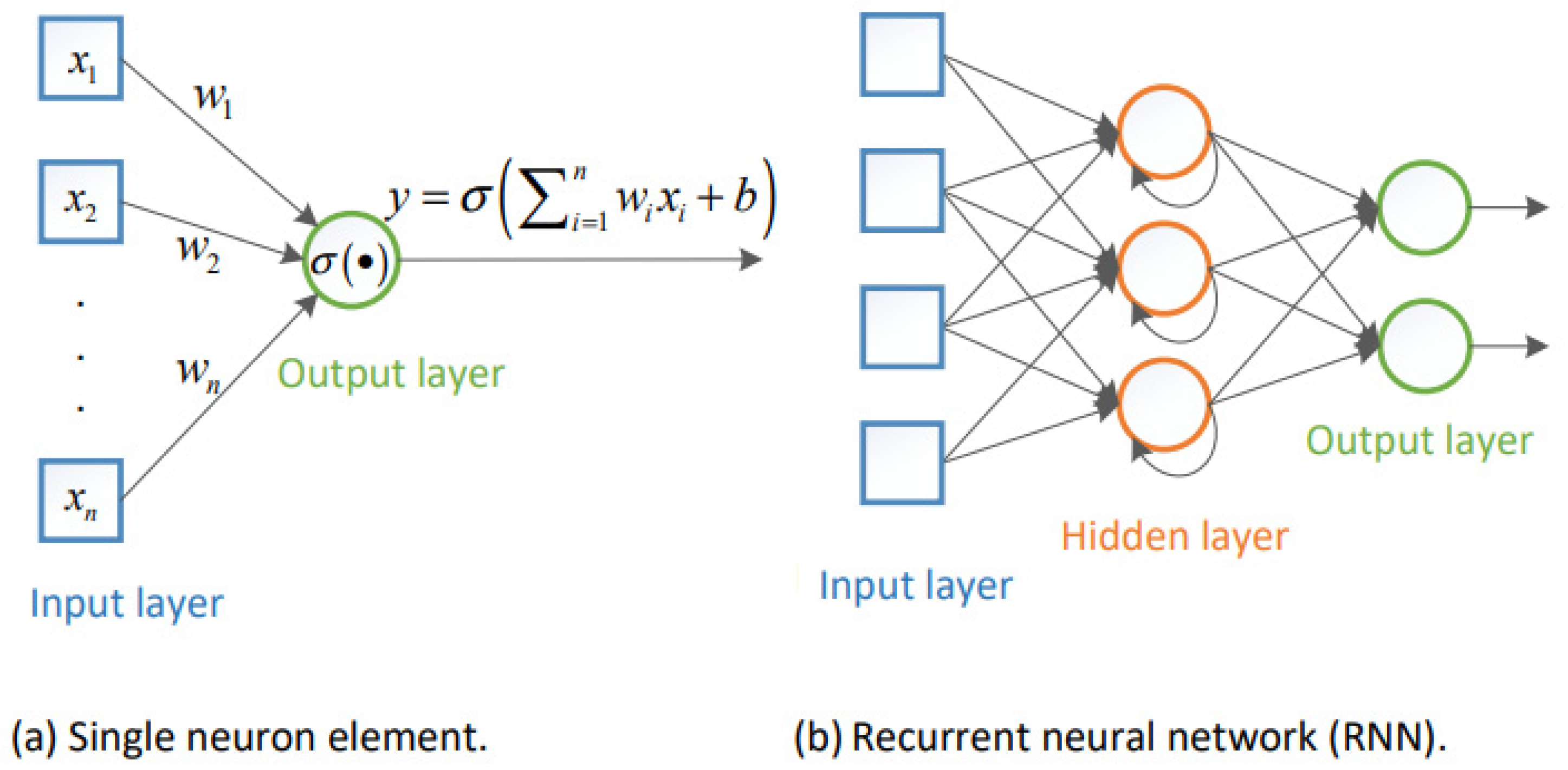
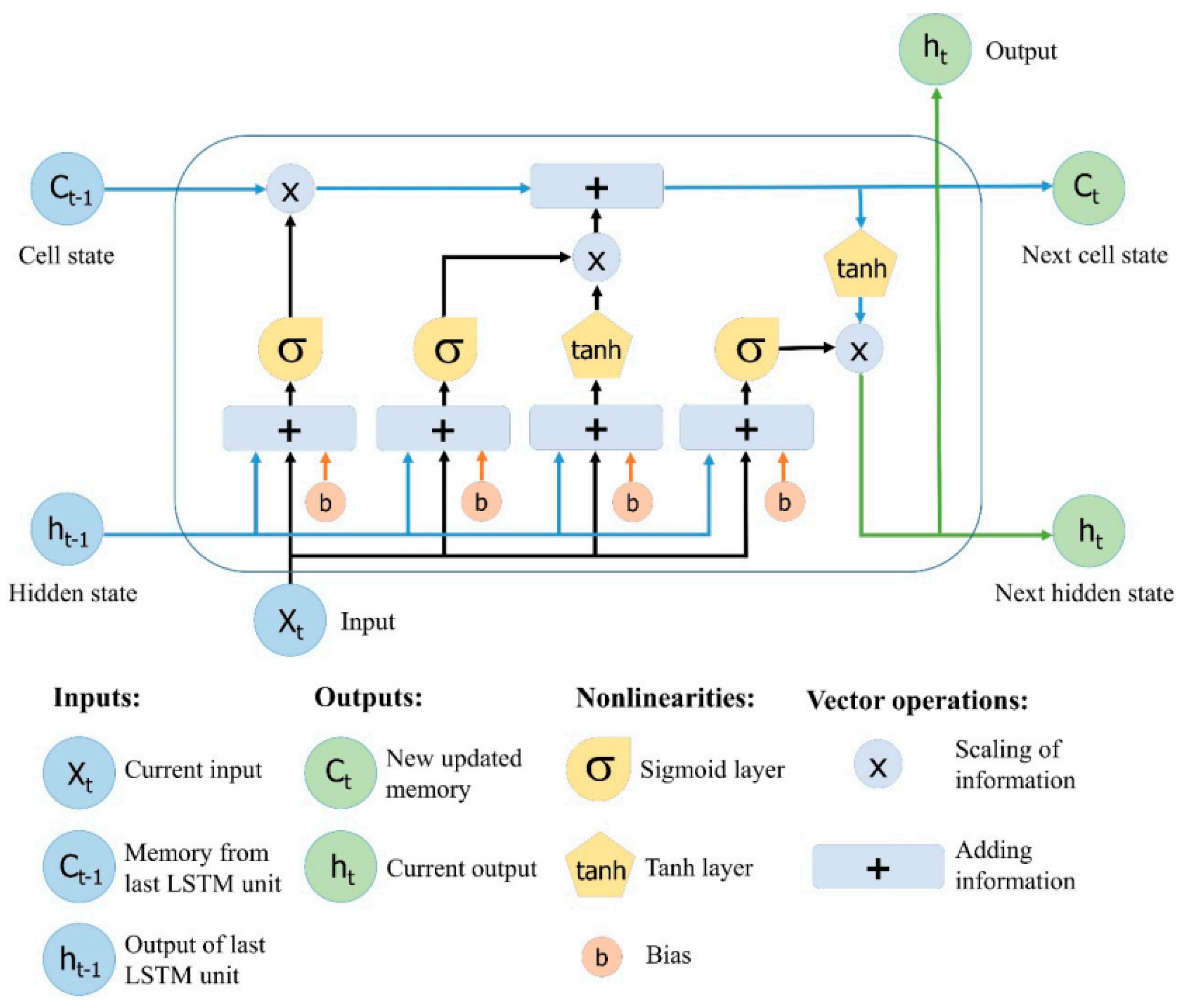
5. RNNs and LSTM
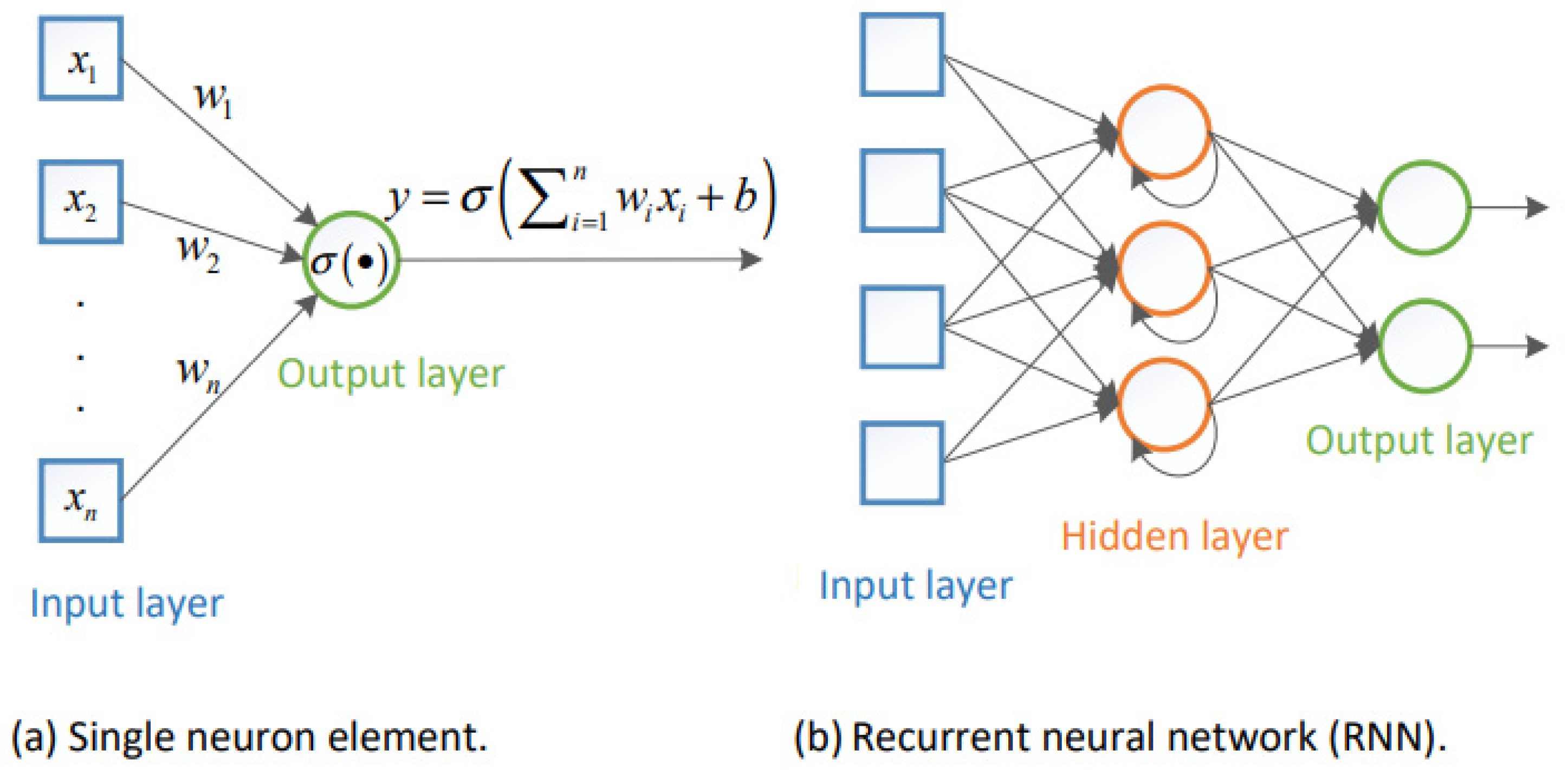
Recurrent Neural Networks (RNNs) are regarded as a class of supervised learning procedures, and they can develop successive sequences for prediction and detection [
27]. As shown in
Figure 1, RNNs involve hidden layers composed of artificial neurons with feedback loops; therefore, they have dual inputs, i.e., the present and the recent previous response.
In RNNs, hidden layers are capable to act as storage for the network at a specific time; this structure enables the RNNs to handle the preceding data for a prolonged period of time; additionally, RNNs can represent time dependencies for any sequence with a lower numeral of neurons. On the other hand, traditional RNN based on backpropagation through time (BTT) experiences slow learning and a vanishing gradient problem [
28].
Therefore, RNNs will not be the best candidate for signals that may be sent through fading channels that may disperse the signal and originate long-term dependencies among its samples [
5]. Long short-term memory (LSTM) network, which is a one category of RNNs, is frequently used with sequences and time series data for categorization, where it can take advantage of time dependencies between sequences [
5].
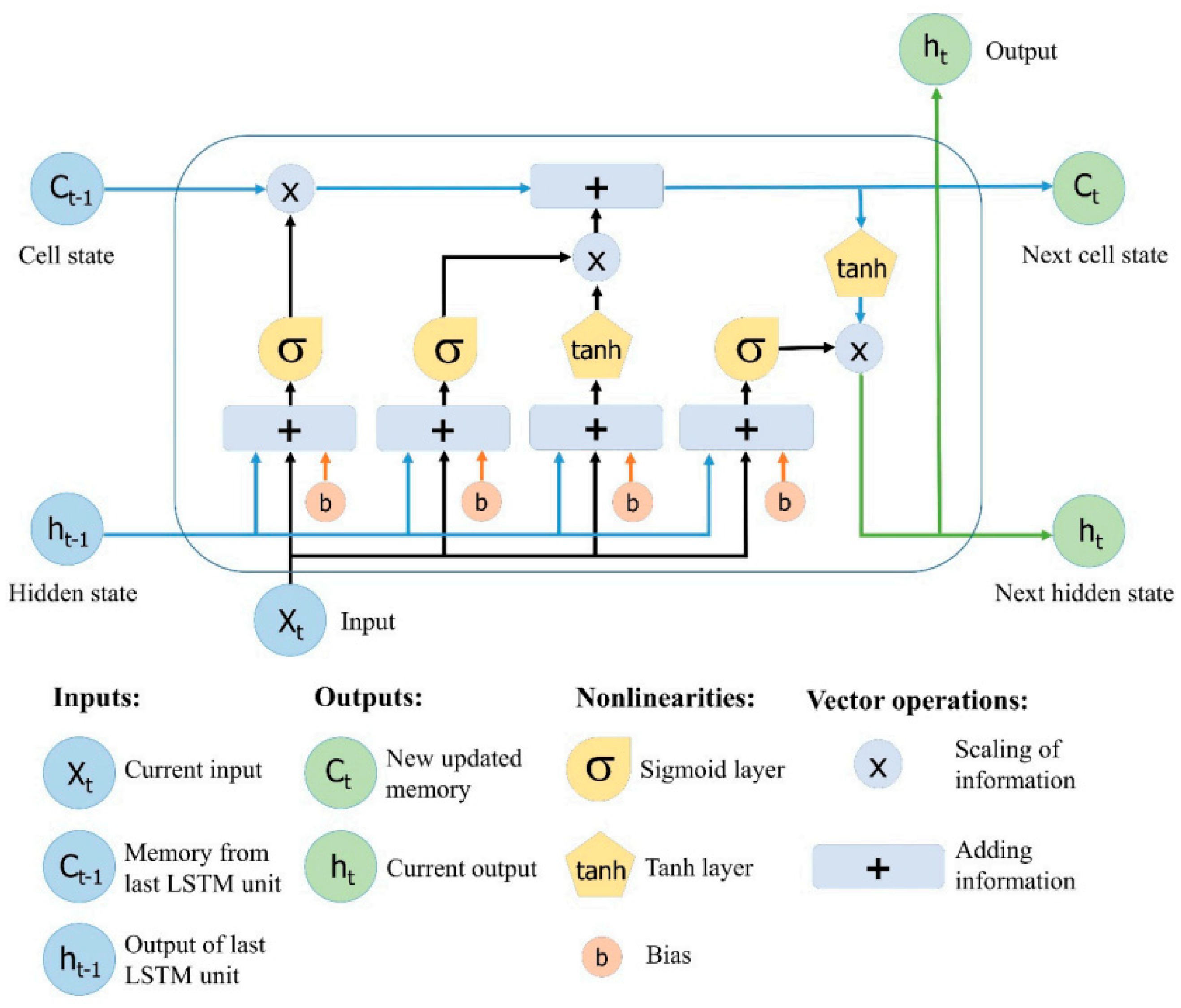
LSTM network can develop knowledge among time steps of the data sequence and manage the long-term dependency process of time series data. Based on their underlying design, the LSTM network includes LSTM cells, and each cell contains a set of gates that are capable of saving and gaining access to data over extended periods of time and of counteracting the error from backpropagation [
5,
28]. LSTM is able to receive a vector complex data, hence integrating the magnitude and phase parts of the received sequence concurrently. LSTM network can be considered as a proper selection to realize multiuser detection (MUD) and prediction when time series data are available [
29].
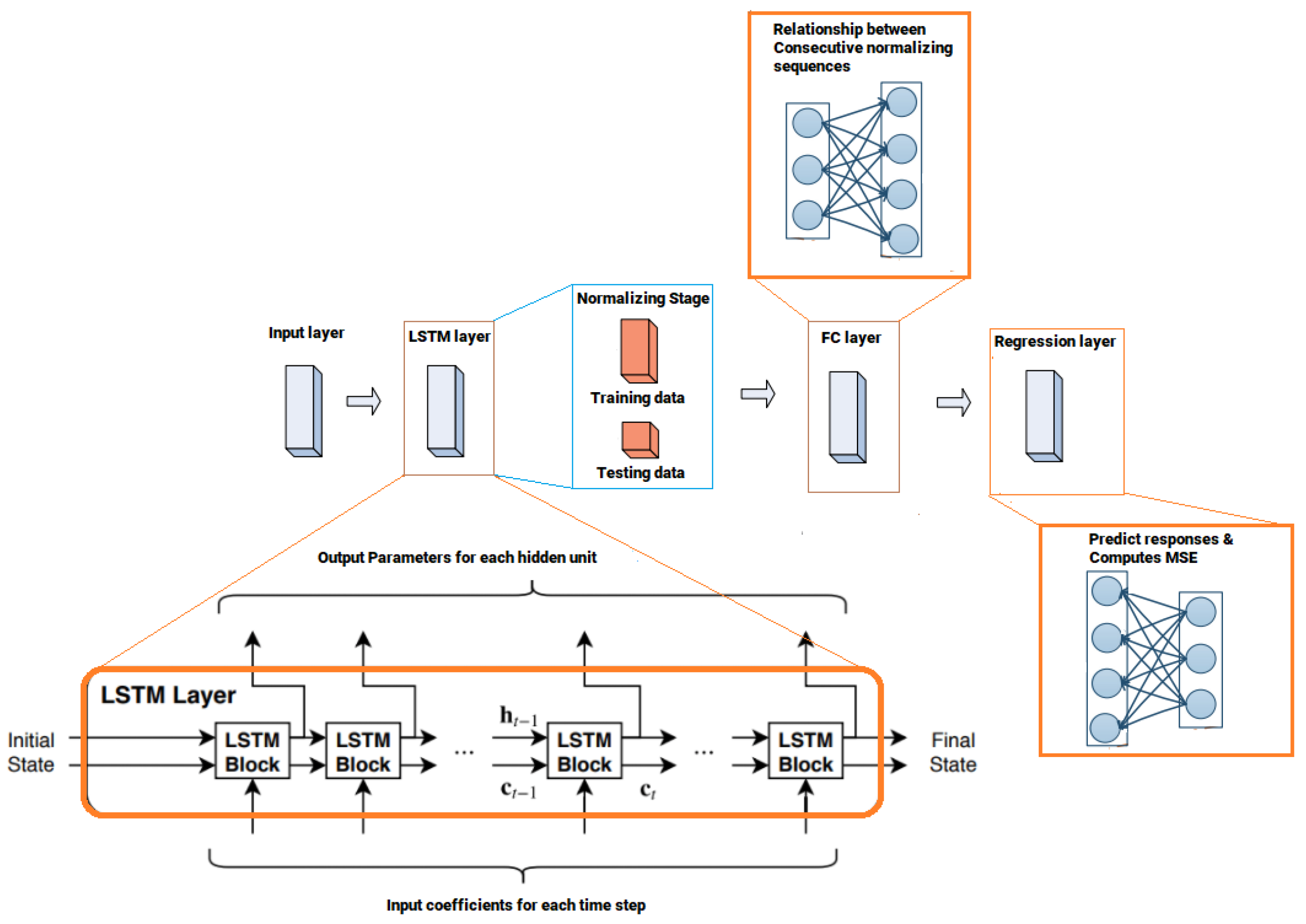
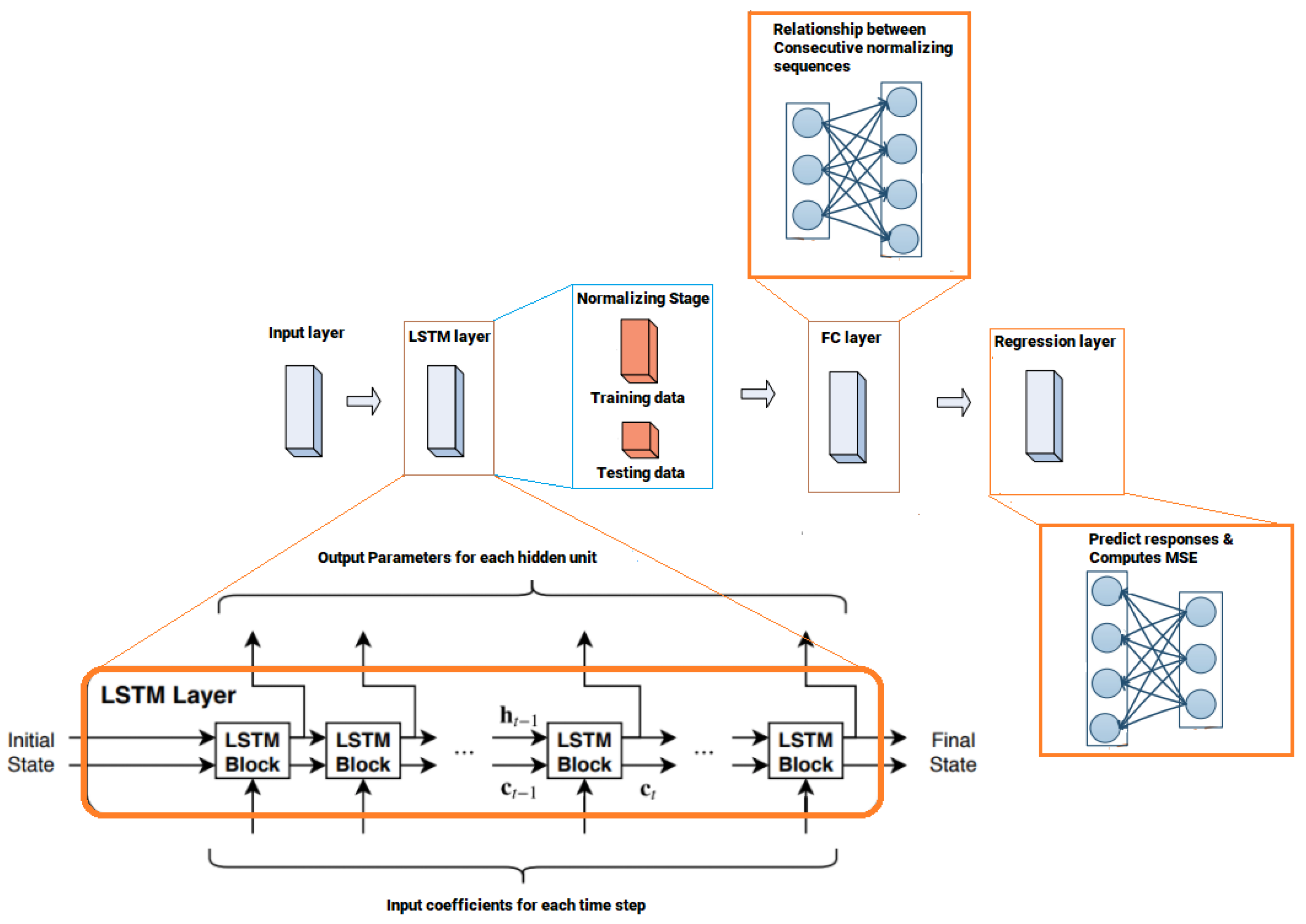
8. Simulation Environment
In this section, a description of the simulation settings and parameters is introduced. Our examined downlink NOMA cell contains one base station (BS) and three distinct users in which the BS and each user in the cell is supplied with one antenna. For the downlink NOMA scenario, the modulated signals are superimposed and transmitted by BS to the users through uncorrelated Rayleigh and Rician fading channels affected by additive white gaussian noise (AWGN), where the noise spectral density dBm and path loss exponent is 4.
In this paper, simulations are conducted using MATLAB to simulate and to emphasize the following: first, to evaluate the effectiveness of embedding the proposed DL-based LSTM network to accurately estimate the channel parameters for each user in downlink NOMA cell. Second, to integrate the proposed DL channel estimation algorithm with the derived optimized power allocation scheme and compare it with the NOMA system when fixed power factors are considered along with the proposed DL scheme. Monte-Carlo simulations are conducted with
iterations, and at the start of every single set of iterations, pilot symbols are generated at random and recognized at the BS and at the receiver side of each user. The main simulation parameters are summarized in
Table 1.
In our simulation environment, we assume that the channel state information (CSI) is not available at the receiver side. Therefore, for the sake of comparison and in order to investigate the efficiency of the proposed DL algorithm, two methods for channel estimation are implemented at the receiver side for each user. The first method, which is the proposed scheme, uses DNN-based LSTM layer to estimate the desired channel coefficients. The gradient descent algorithm is applied in conjunction with LSTM layer, and the LSTM layer is attached to a fully connected layer, where each neuron in the former layer is fully connected to every neuron in the consequent layer. The second channel estimation scheme implemented at each receiver side is initiated based on the minimum mean square error (MMSE) [
33]. The MMSE technique will be applied as a conventional channel estimation technique for each user in NOMA cell, and in the simulations results, we refer to the MMSE scheme as conventional NOMA, to clarify that users are using the MMSE procedure for estimating the channel coefficients before recovering the original signal.
Channel taps that are employed to model the Rayleigh fading wireless channel are generated on the basis of ITU channel models. Throughout the simulations, NOMA system parameters are employed on the basis of the long-term evolution (LTE) standard [
34]. Both training and implementation phases are conducted online throughout the simulations, and the fading coefficients in the testing stage are generated such that these coefficients are not the same as in the training stage. At the end of the training stage, which includes training and testing data, the trained network will be utilized as online channel estimator for the users rather than the conventional NOMA scheme that use the MMSE procedure for channel estimation.
Initially, different power factors are allocated for each user according to their distance from the BS and the current channel gain. Power allocation coefficients
,
, and
are defined for near, middle, and far users, respectively. In the fixed power allocation (FPA) scenario, we can assign
,
, and
. Alternatively, in the optimized power scheme, power factors are apportioned between users according to the analytical form derived earlier for each user in
Section 4. The propagation distances for each user with respect to base station are initially assigned in the simulation files as follows
,
, and
. Quadrature phase shift keying QPSK is utilized as a modulation scheme for the data symbols and pilot sequences. The applied transmitted power mainly varies from 0 to 30 dBm.
9. Simulation Results and Discussion
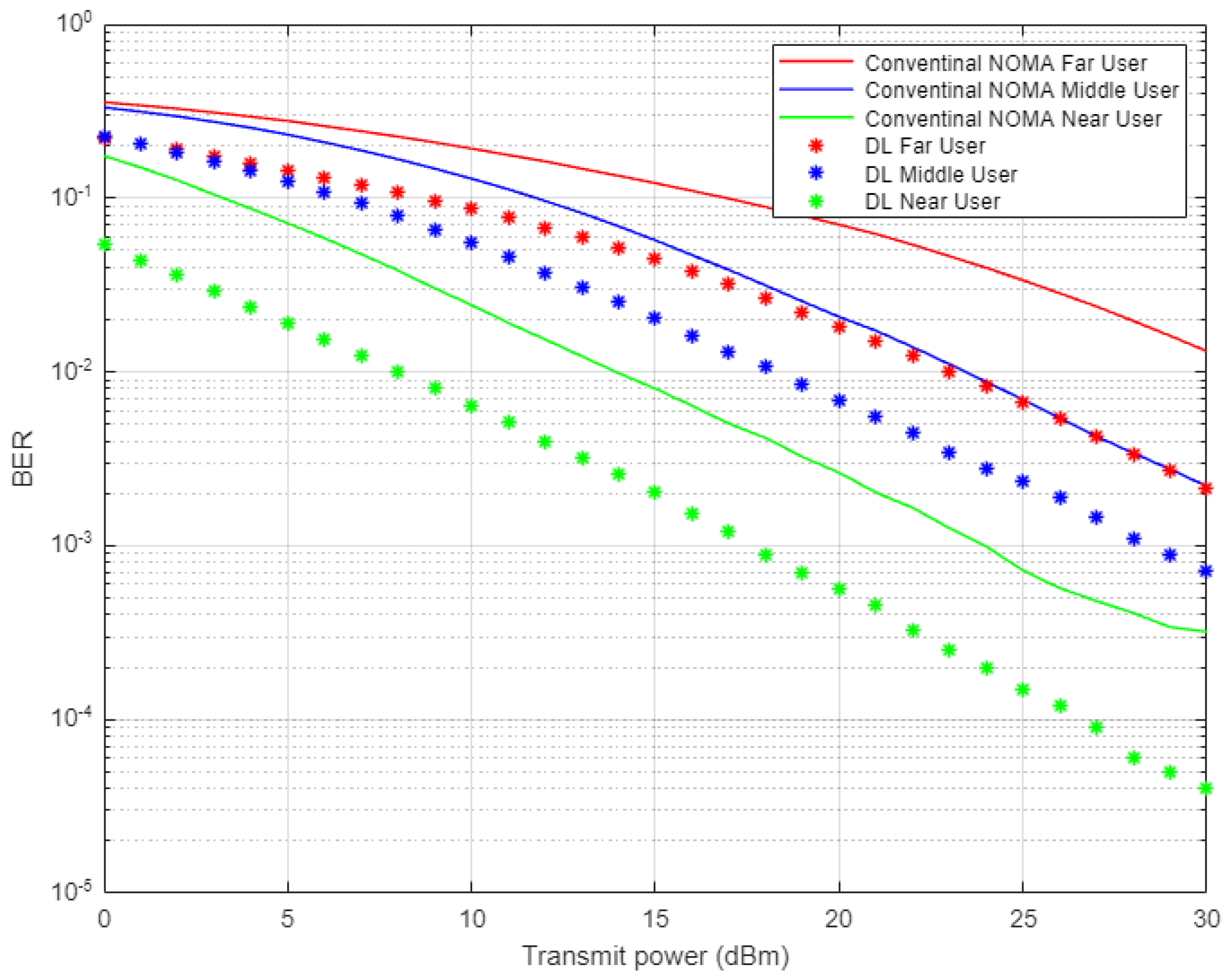
In
Figure 4, the simulation results illustrate the comparison between the proposed DL scheme for channel estimation and conventional NOMA scheme that employs MMSE procedure for estimating the channel parameters. The estimated channel coefficients using both schemes will be used in signal recognition for far, middle, and near users and the simulation results are shown in terms of bit error rate (BER) versus transmitted power. All users in the NOMA cell-based DL channel estimation show sufficient improvement in lowering the bit errors compared to the conventional NOMA scenario, especially when the assigned power is increased. It can be noticed that for certain BER values, such as 10
−2, the power saving achieved by DL scheme is approximately 5–8 dBm for far and middle users, while for the near user, the power saving is up to 4 dBm.
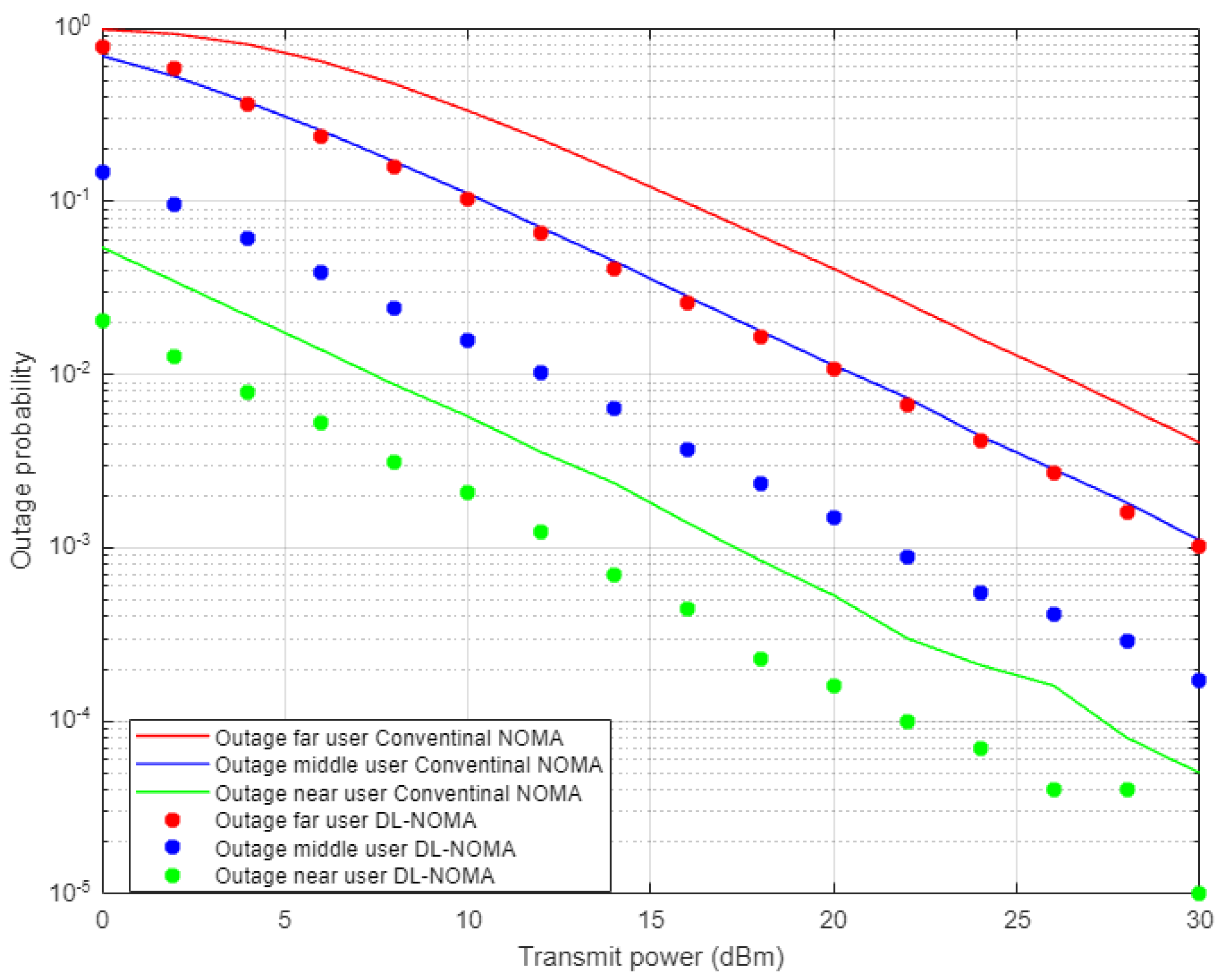
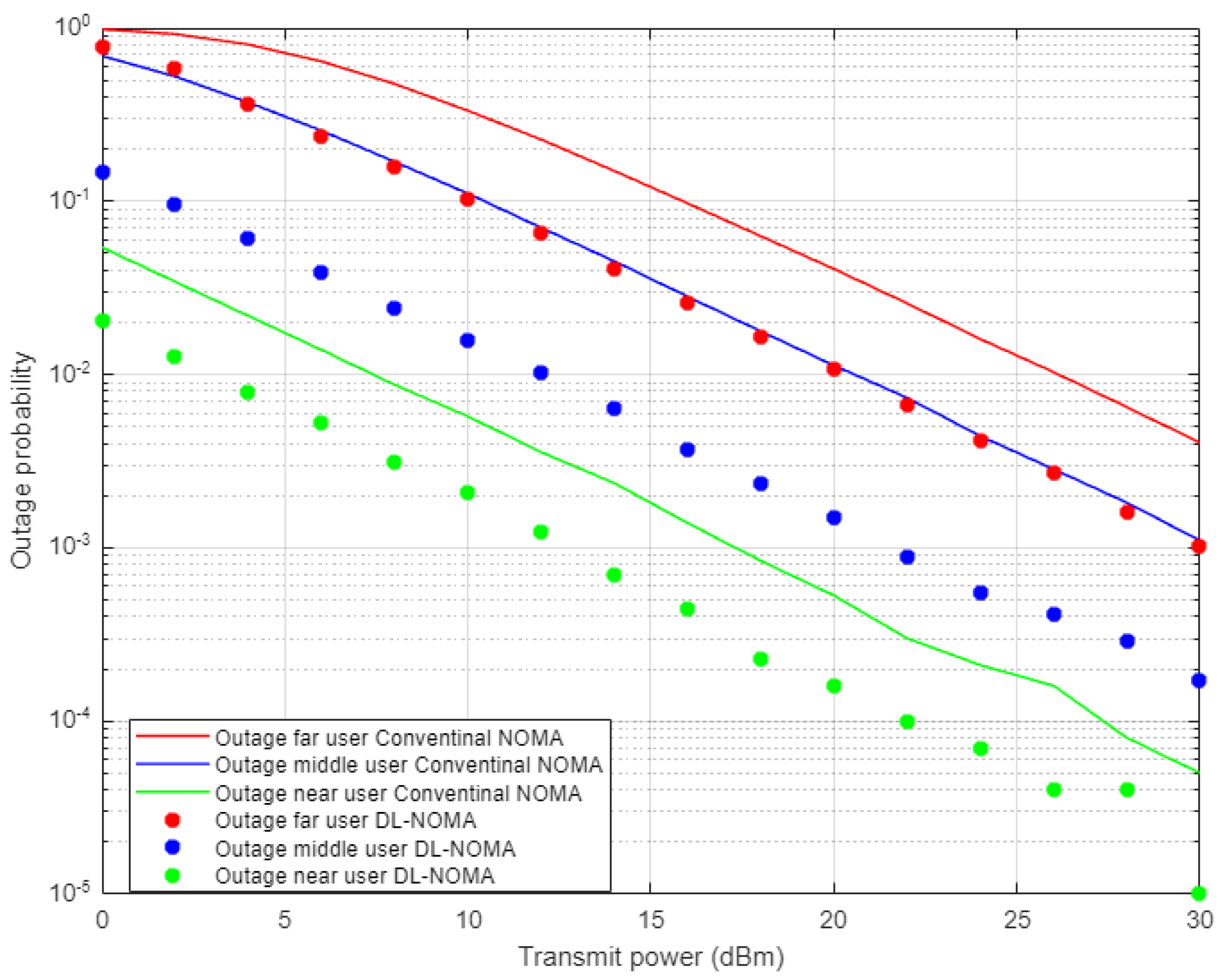
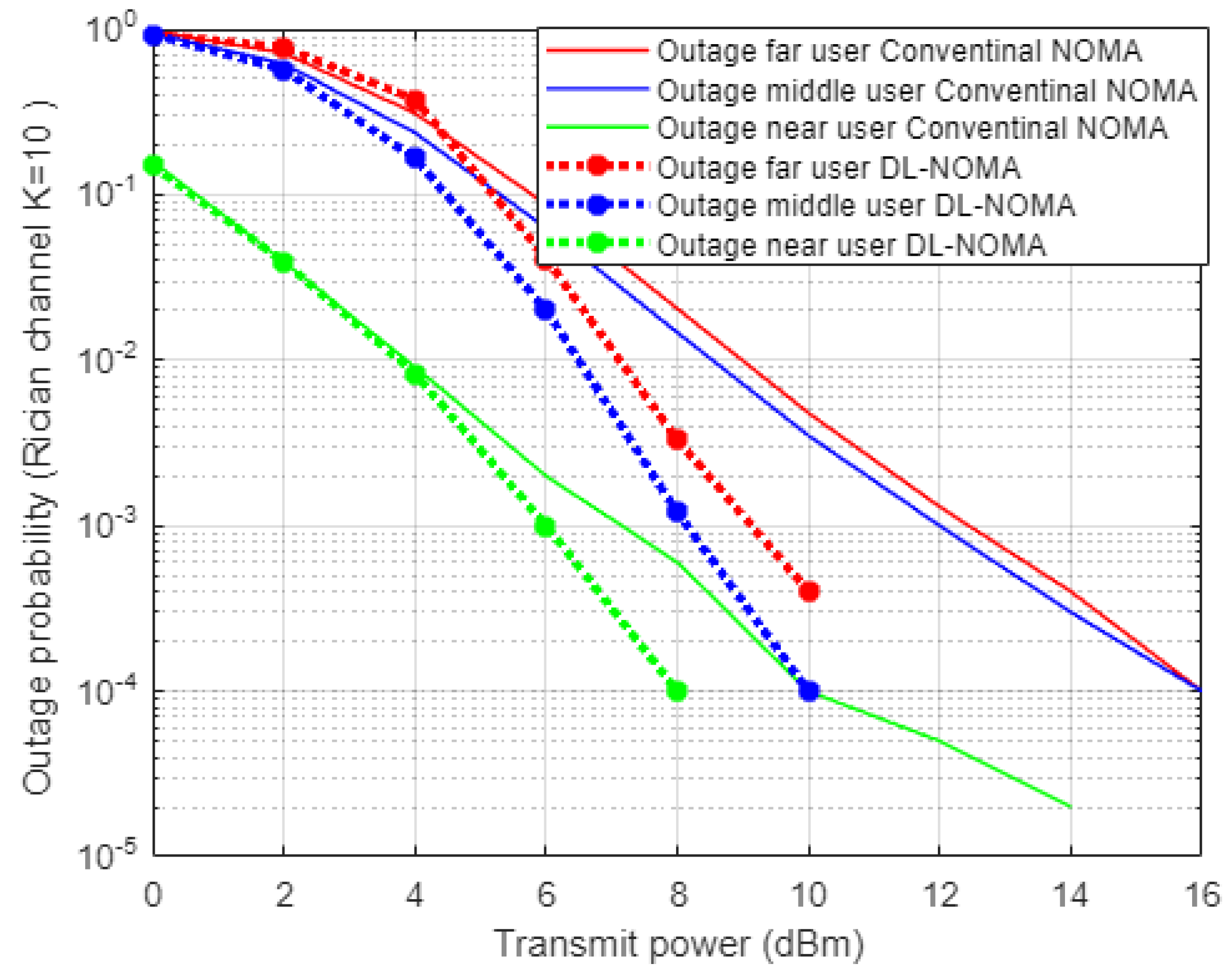
Figure 5 demonstrates the results for outage probability metric versus transmitted power for the three examined users in NOMA system on the basis of DL and conventional NOMA channel estimator schemes. Far user and near user simulation results indicate an approximately 5 dBm improvement in power saving to achieve a certain outage probability (10
−3) when DL-based channel estimation scenario is implemented compared to the conventional estimation scheme. Likewise, the middle user with the DL estimation scheme shows more enhancement in power saving compared to the MMSE procedure, by 5–7 dBm approximately, which proves the superiority of the proposed DL estimation scheme.
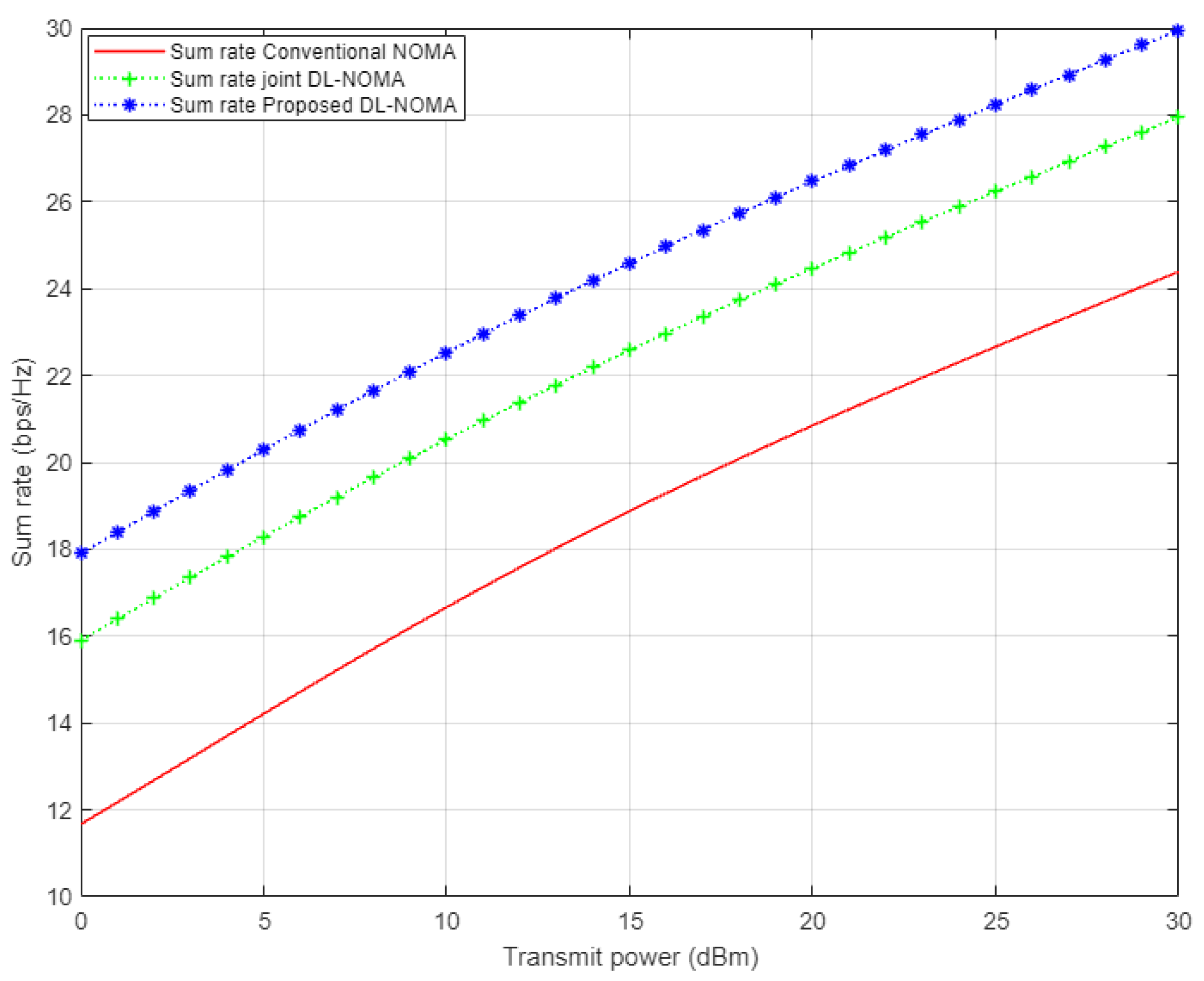
Figure 6 displays the simulation results for the sum rate versus the transmitted energy for the three examined users in the NOMA cell. In this figure, three different channel estimation schemes are inspected, i.e., the proposed DL approach, conventional NOMA based on the MMSE scheme, and the DL algorithm for joint channel estimation and signal detection that was applied in [
14]. Based on the simulation results, it can be clearly noticed that the proposed DL channel estimation scheme shows dominance over the conventional NOMA scenario, with 6 b/s/Hz approximately, and also indicates an improvement over the DL algorithm implemented in [
14] by 2 b/s/Hz. These results verify the effectiveness of the proposed DL scheme in estimating the channel coefficients before being utilized in the decoding process.
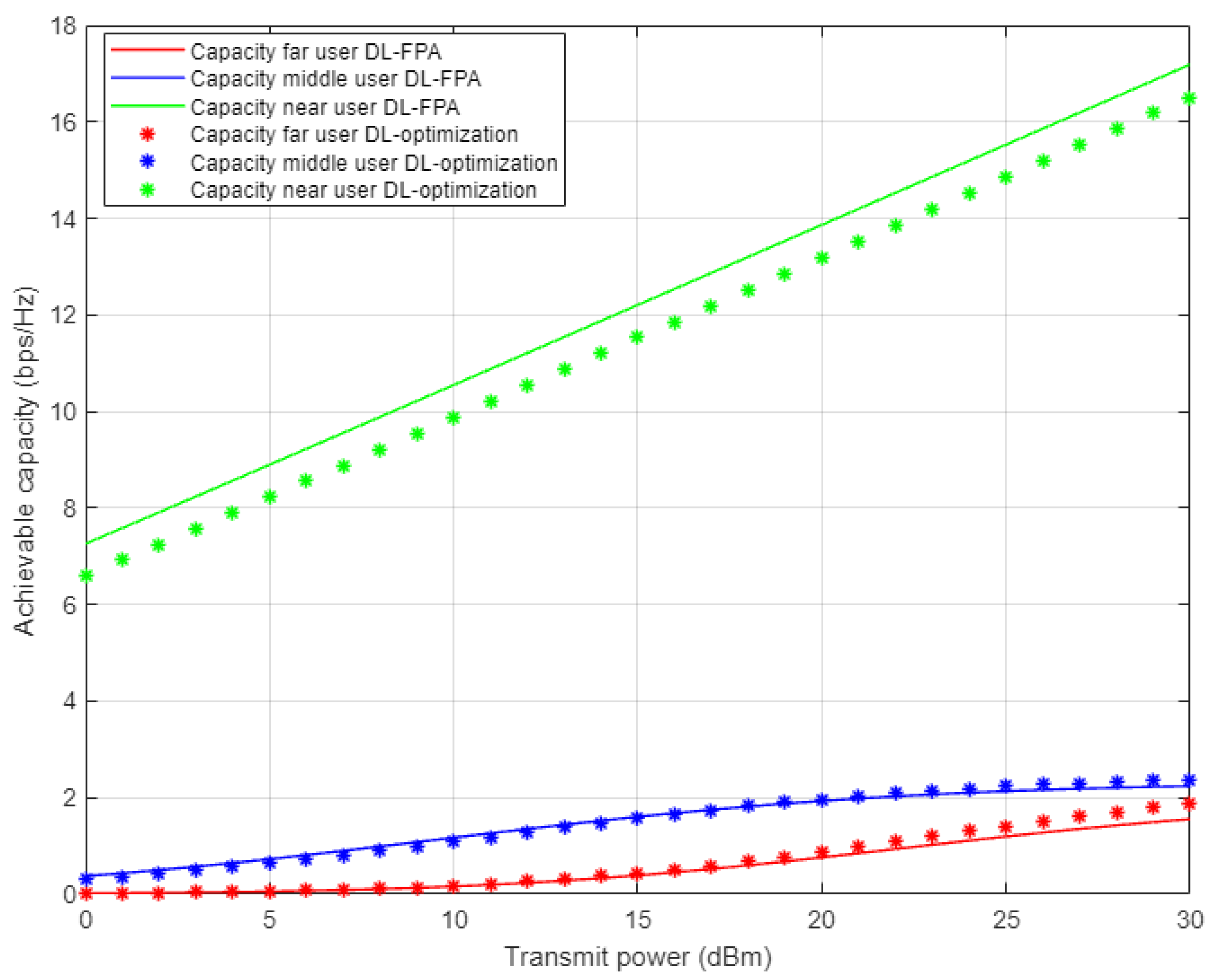
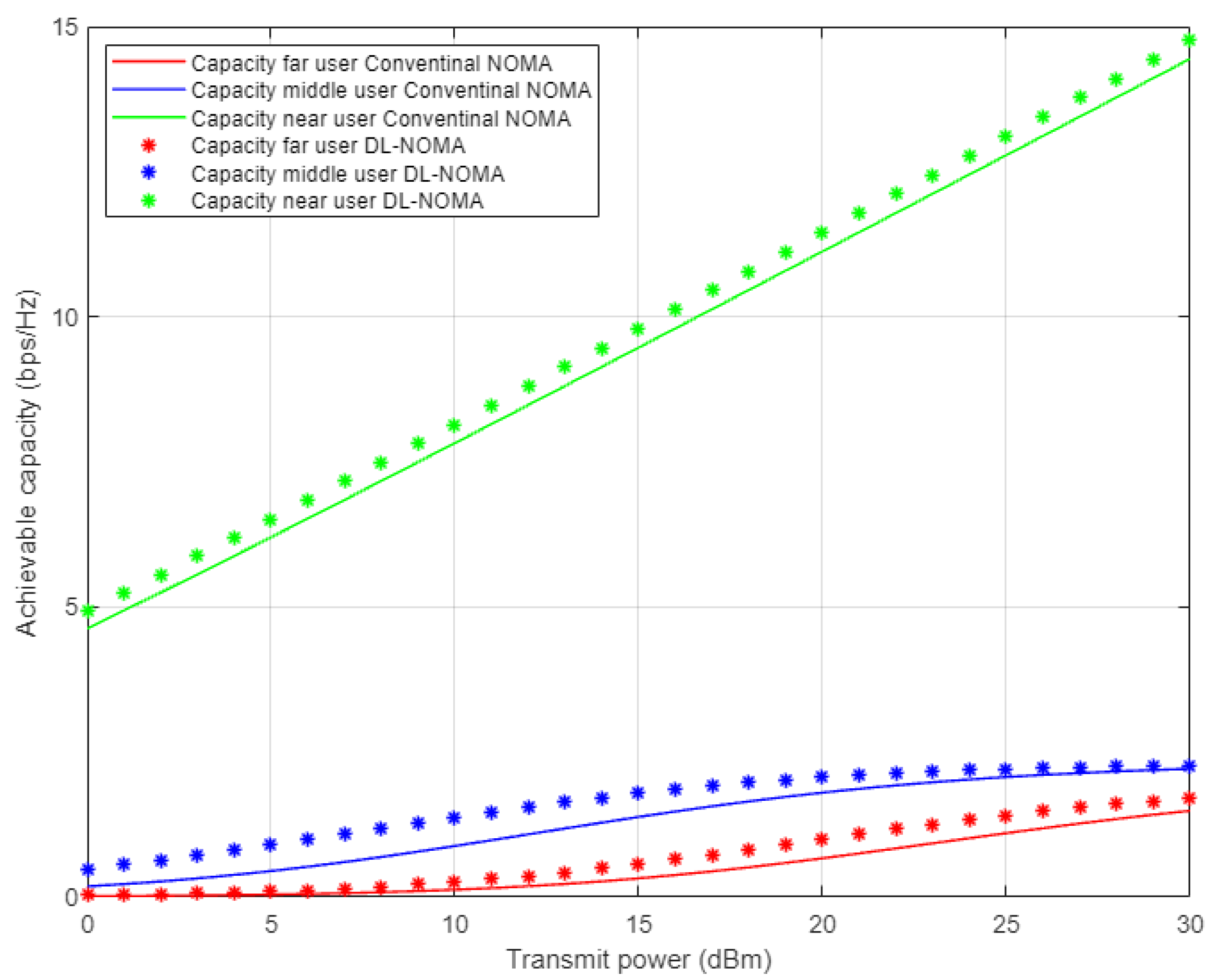
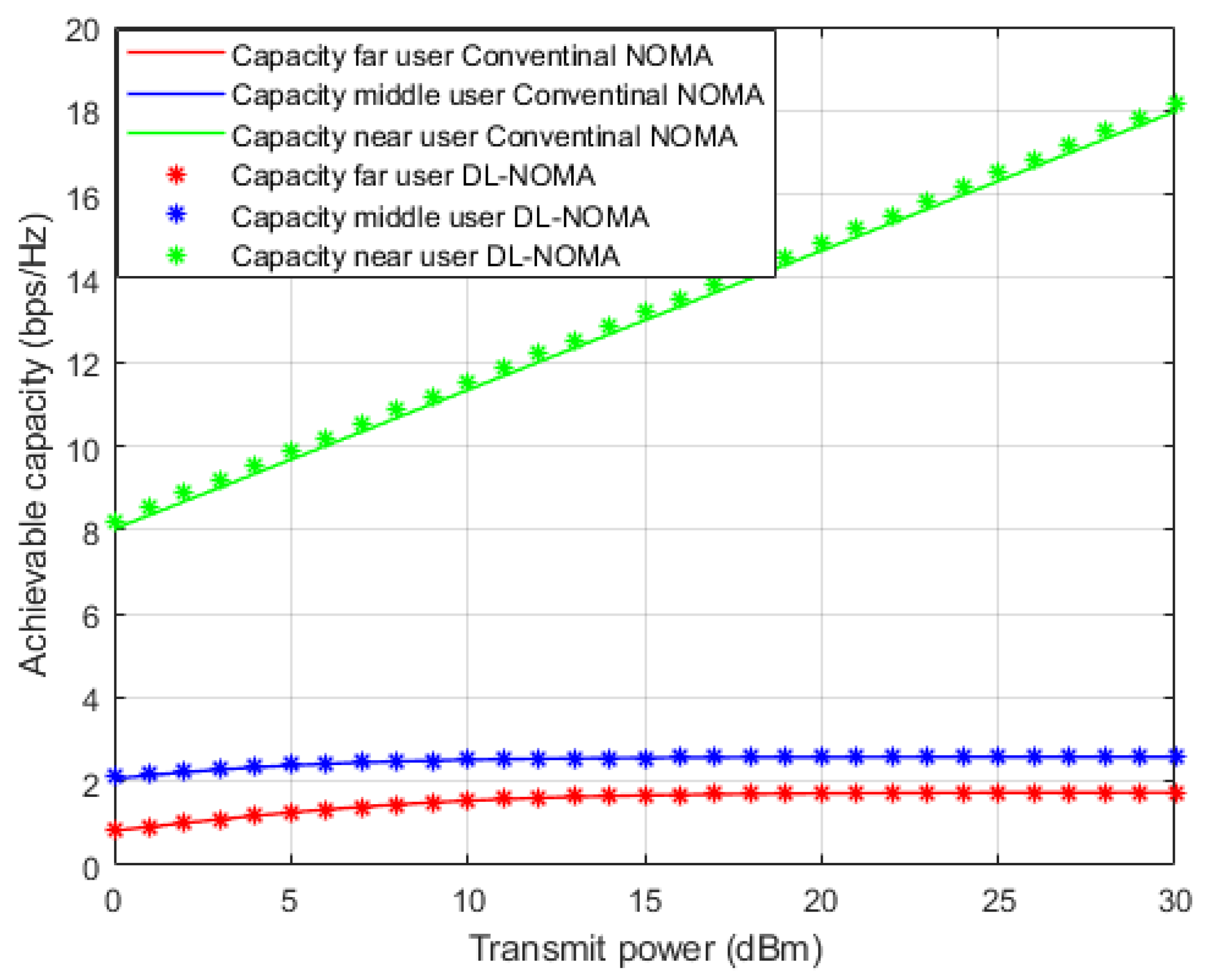
Figure 7 illustrates the simulation results for the individual capacity metric for each user in the NOMA cell when both the proposed DL-assisted channel estimation and conventional NOMA-based MMSE channel estimation schemes are employed. As expected, when power level starts to increase, the achieved capacity for the near user shows significant difference by at least 8 b/s/Hz approximately over far and middle users’ rates. This may be justified by the good channel condition for the near user compared to other users in the cell. Furthermore, the proposed DL approach still delivers noticeable enhancements with respect to other users, but with little impact especially for the far user, due to interference and weak channel conditions.
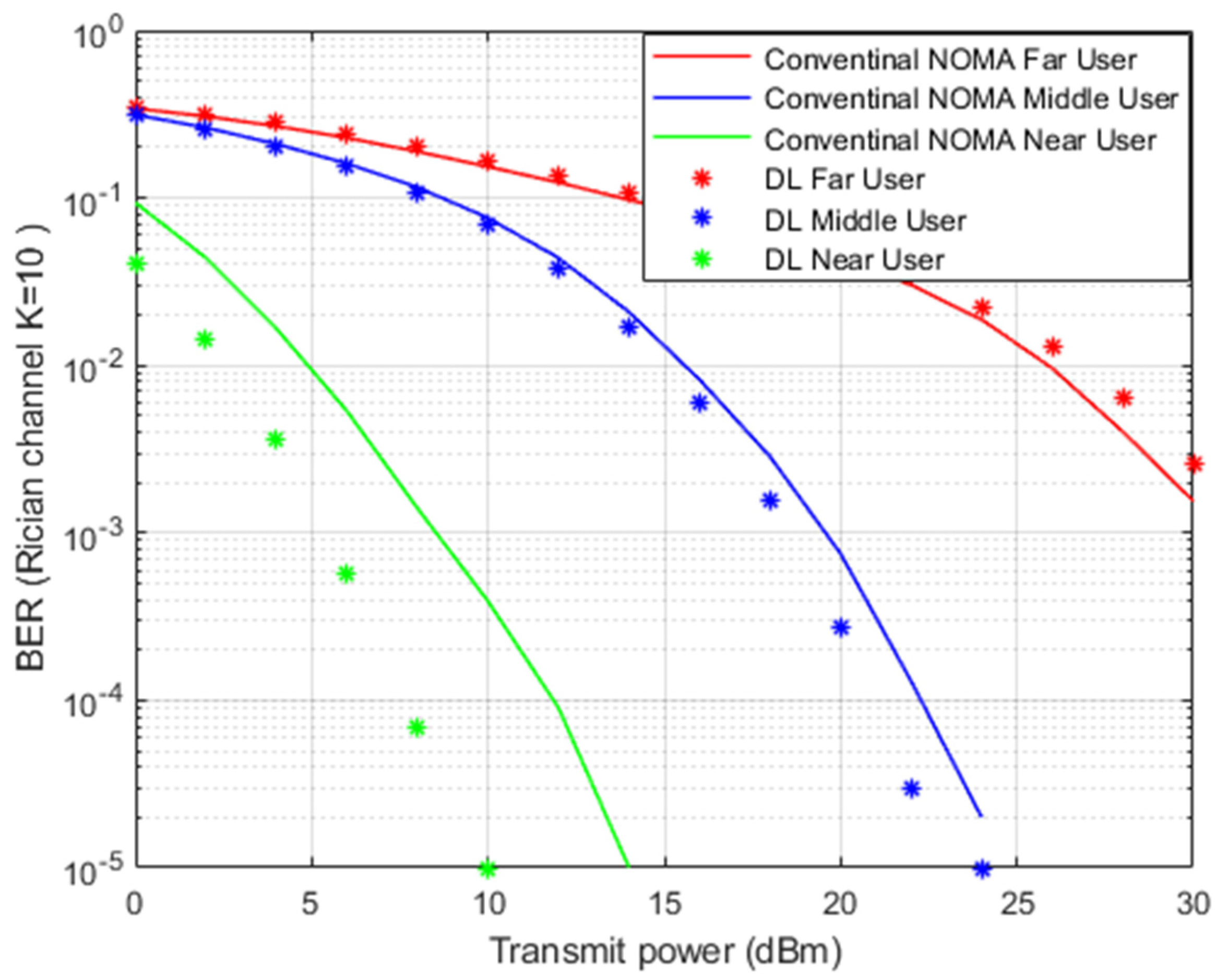
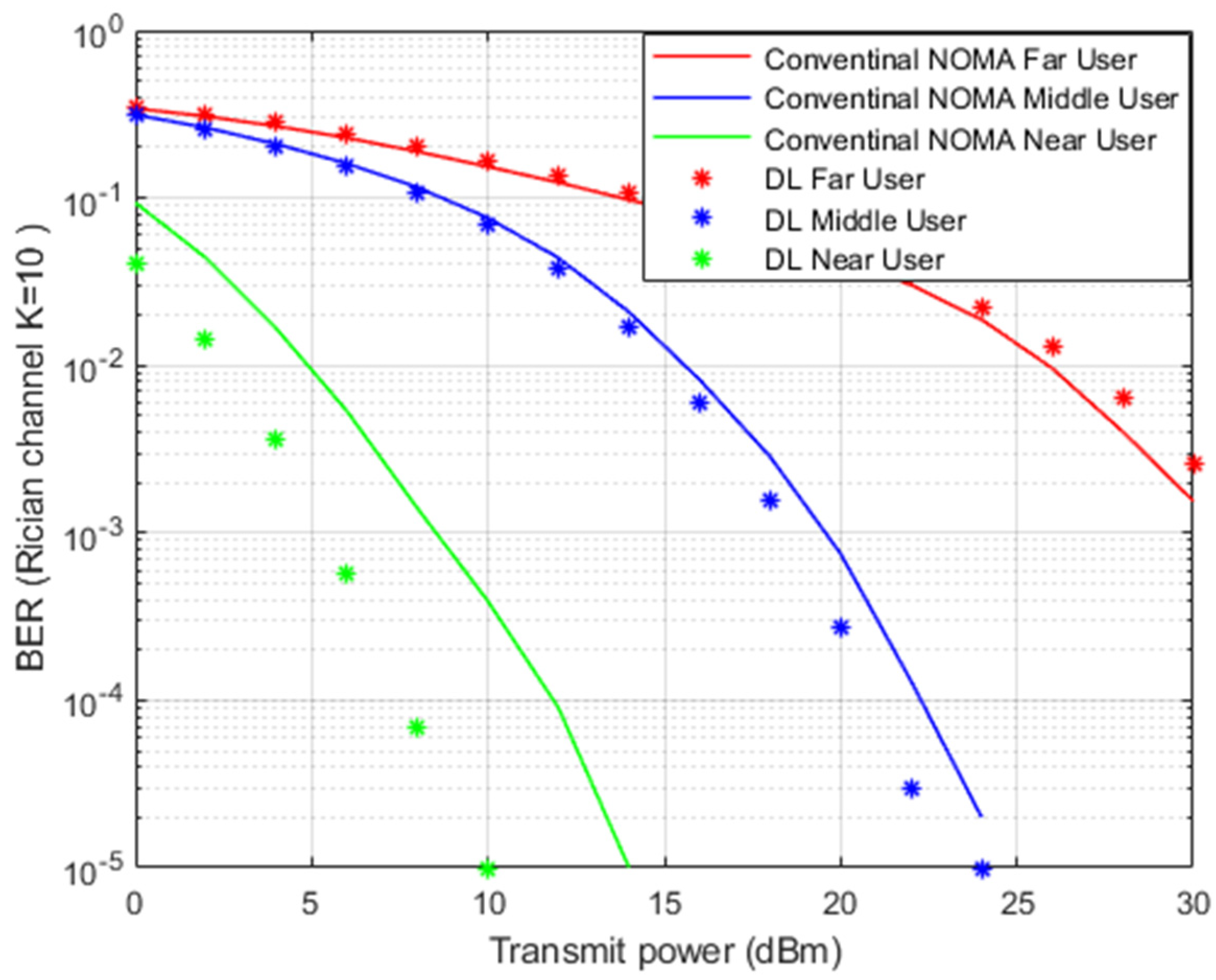
Figure 8 illustrates the simulation results for BER versus transmitted power when the Rician channel is implemented. The proposed DL channel estimation scheme and conventional MMSE scheme will be further inspected by the Rician channel model.
Rician fading is a stochastic model for radio propagation, where the signal arrives at the receiver by several different paths, and hence, exhibits multipath interference. Rician fading occurs when one of the paths, typically a line of sight (LOS) signal or some strong reflection signals, is much stronger than the others. A Rician fading channel can be described by two parameters The first one is the Rician factor K defined as the ratio of the signal power in the line-of-sight component to the scattered power in other components. The other main parameter is , which represents the total power from both paths and acts as a scaling factor to the distribution. In our simulation file for the Rician channel, we assign K = 10, sample rate = 9600 Hz, and maximum doppler shift = 100.
In
Figure 8, simulation outcomes for near and middle users indicate a noticeable improvement in lowering the bit errors when the proposed DL scheme is applied compared to the conventional MMSE scenario. The near user shows a substantial improvement in terms of power saving due to the relaxed channel conditions and elimination of interference by the SIC method. In the far user situation, the impact of DL in tracking the channel parameters is limited due to the interference and weak channel conditions.
Figure 9 demonstrates the simulation results for outage probability metric versus power transmitted when the Rician channel is considered, and both DL and MMSE channel estimation schemes are inspected. Far and middle users’ simulation results show an improvement within approximately 4 dBm of power saving to achieve a certain outage probability when the DL-based channel estimation scenario is conducted compared to the MMSE scheme. In terms of the near user, the simulation outcomes indicate that the proposed DL channel estimation scheme starts showing improvement regarding the outage probability when the power allocated to the near user is more than 4 dBm, which also proves the dominance of the proposed DL method.
In
Figure 10, the simulation results regarding the individual capacity for each user are illustrated when the Rician channel model is employed, and both the DL-assisted channel estimation and conventional NOMA based on the MMSE channel estimation schemes are applied. It is worth mentioning that for both far and middle users, DL-based channel estimation shows comparable capacity compared to the MMSE scheme, which can be justified, as the DL scheme is not sufficient enough to mitigate the interference and weak channel conditions for far and middle users in the Rician channel. On the other hand, comparable to the Rayleigh fading results, the achieved capacity for the near user shows a significant difference by at least 6 b/s/Hz compared to far and middle users for the same applied power level. This enhancement in capacity can be justified by the line of site component between transmitter and receiver in the Rician channel and the relaxed fading channel between the near user and BS.
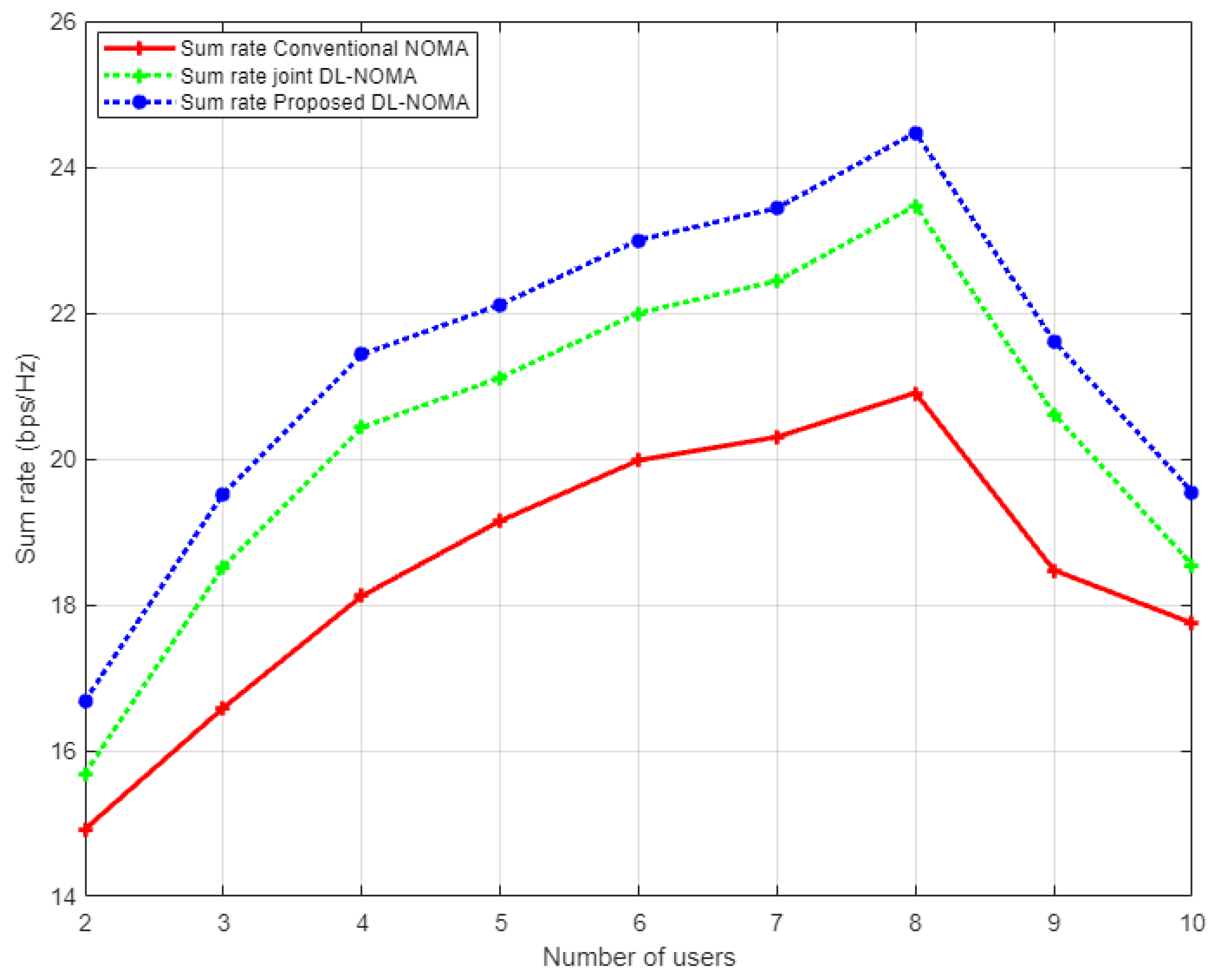
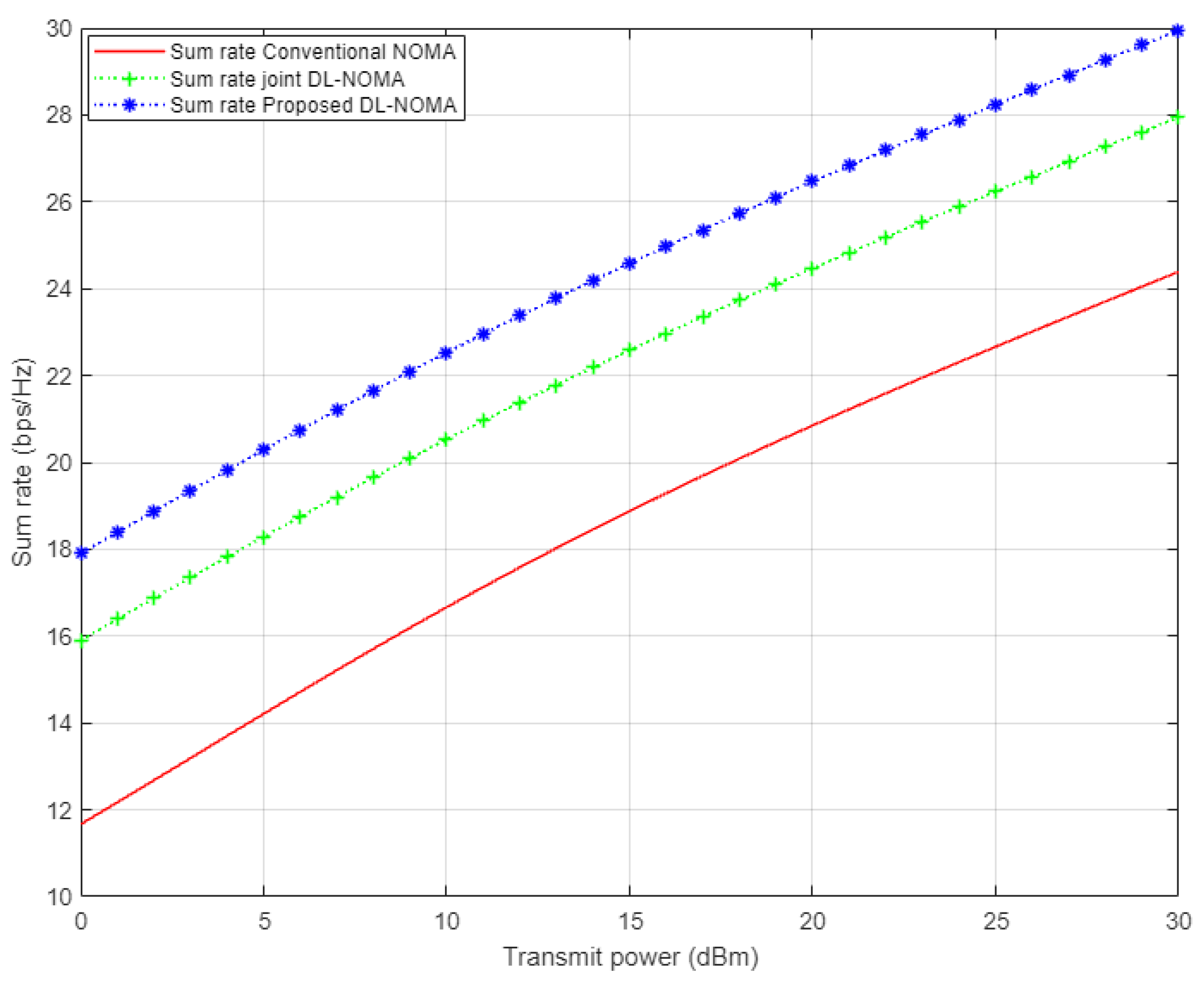
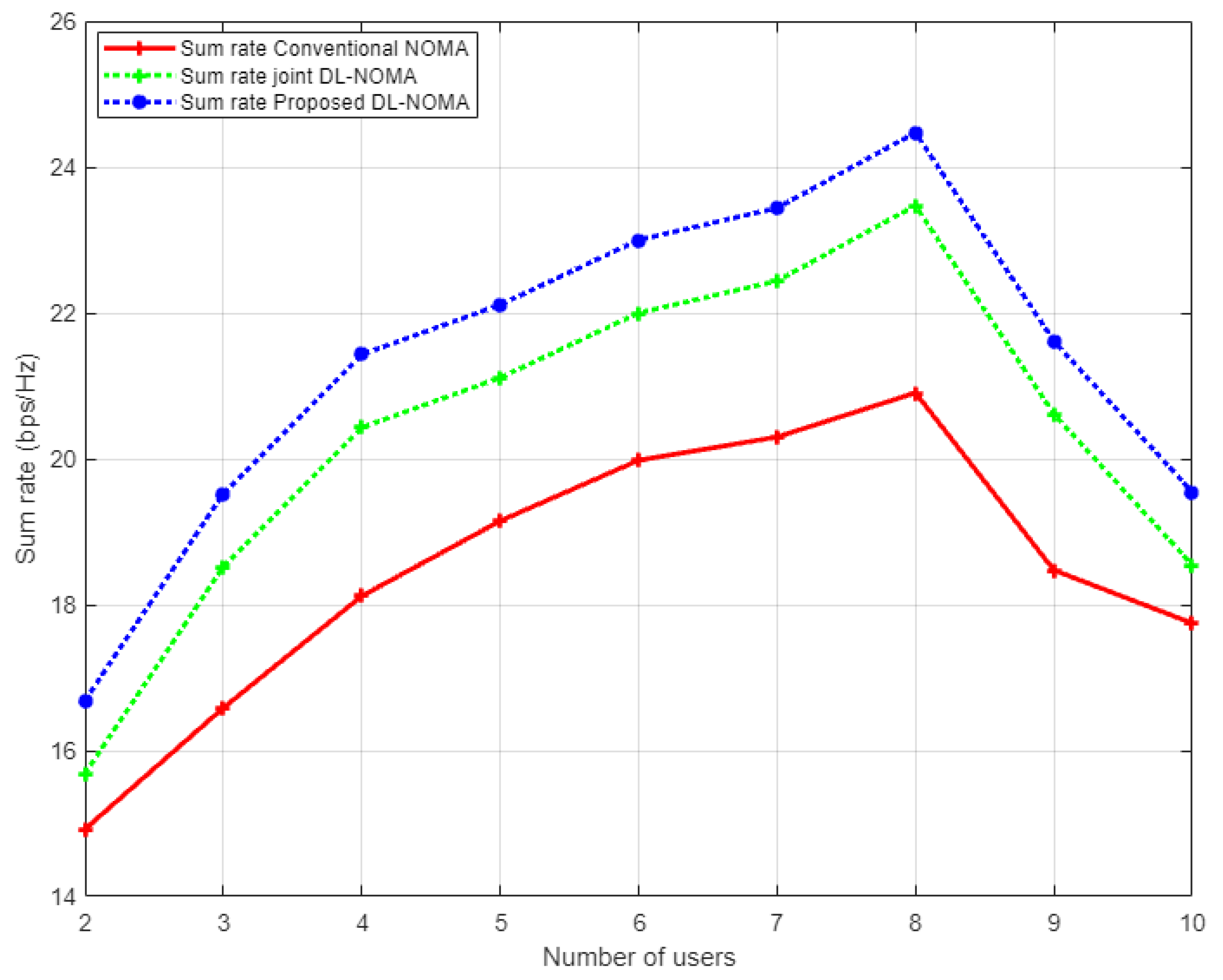
Figure 11 illustrates the simulation results for the sum rate versus the number of users examined in the NOMA cell when the Rayleigh channel model is implemented. In this figure and as a benchmark comparison, we have conducted the simulation environment related to the work in [
14], which implements the DL algorithm based on joint channel estimation and signal detection as a one-shot process. As indicated from the figure, our proposed DL-based channel estimation scheme achieves a substantial higher sum rate compared to both the conventional NOMA scheme based on the MMSE procedure, and the DL scheme for joint channel estimation and signal detection discussed in [
14]. It can be clearly noticed that as the number of users in the cell increases, our proposed DL channel estimation scheme remains superior in showing higher rates compared to other schemes. These results indicate that reliability can be guaranteed by the proposed scheme even when the cell capacity is increased. On the other hand, it is worth mentioning that as the total number of users keeps increasing in the cell, the interference will also increase, and consequently, the performance will degrade, and the sum rate will start to decrease.
In
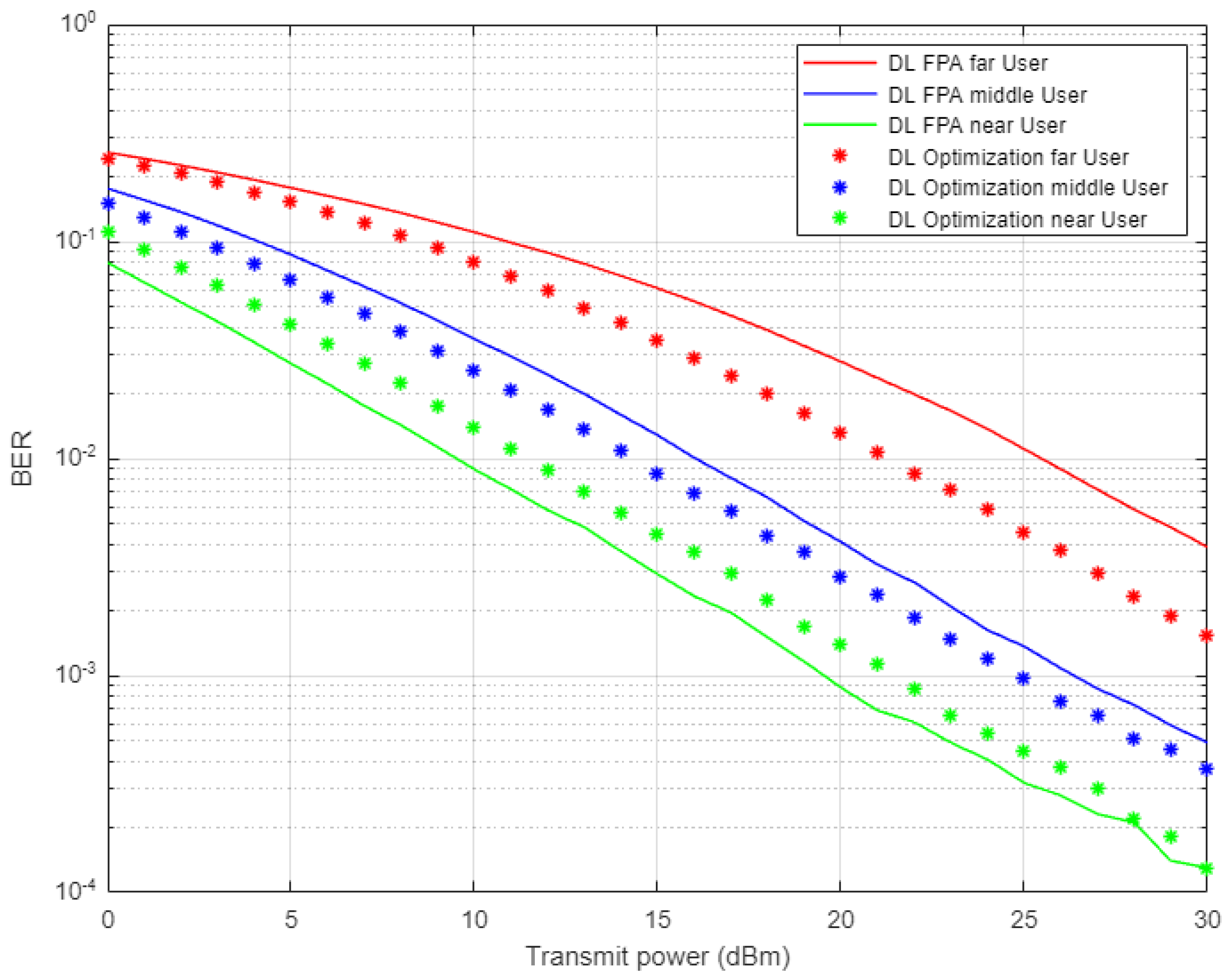
Figure 12, two different simulation scenarios are conducted here to generate this figure; the first one when a fixed power allocation (FPA) scheme is applied for each user in the system. The other scenario is the optimized power scheme that is implemented according to the analytical power factors derived earlier. Both scenarios are employed in combination with the proposed DL for the channel estimation scheme. Simulation results for far and middle users prove the superiority of the power-optimized structure over the FPA structure in terms of BER. For the near user results, the proposed DL-based channel estimation jointly with FPA provides little enhancement in terms of the received bits error over the optimized power scheme, which could be justified in that for the near user scenario, a good channel condition is more beneficial than the allocated power.
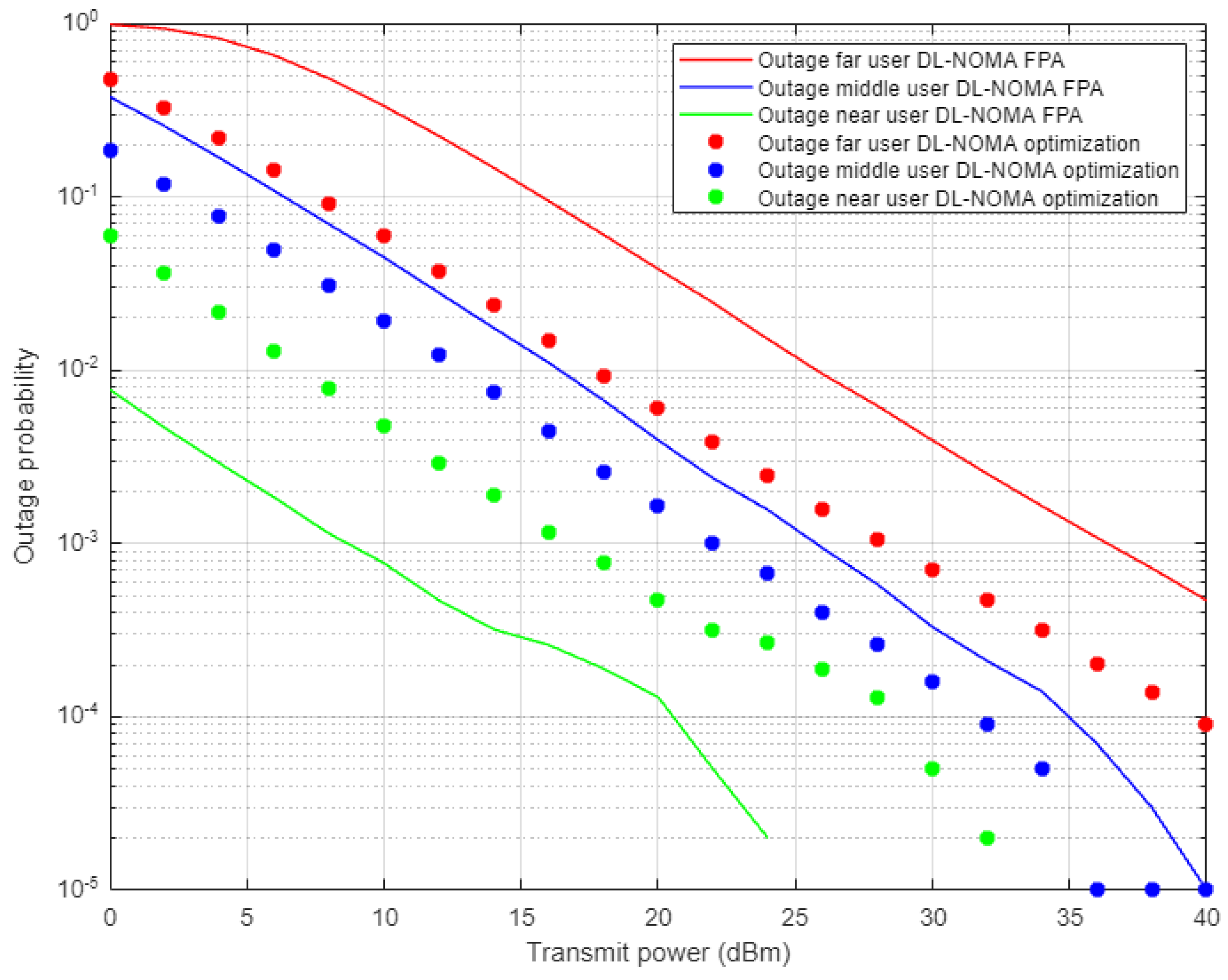
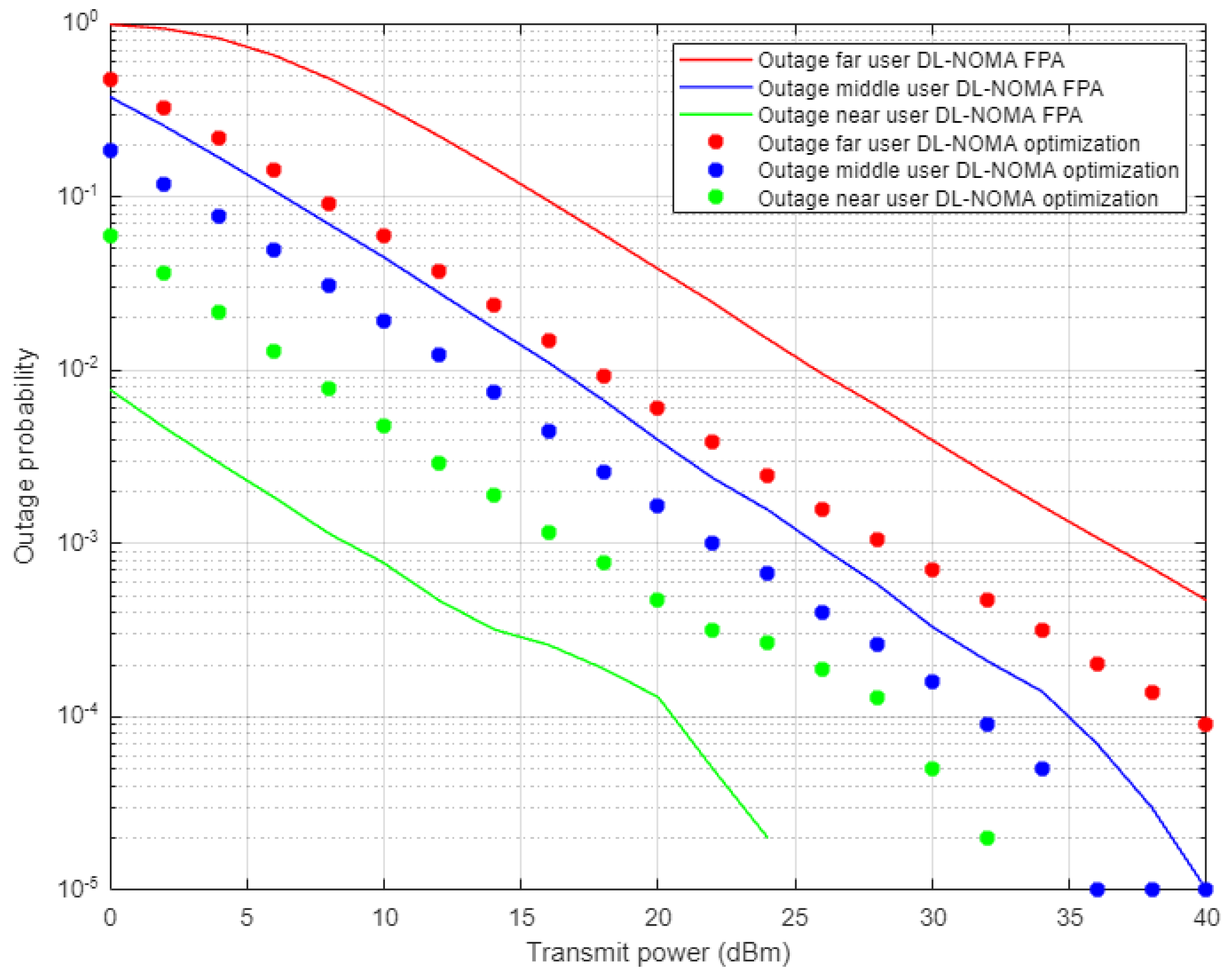
Figure 13 illustrates the outage probability results against the power transmitted for far, middle, and near users when the optimized power scheme and FPA schemes are applied, and both scenarios are conducted in combination with the proposed DL-based channel estimation in NOMA cell. Far user results show an enhancement in outage probability and the power saving is approximately 5–6 dBm when both the DL and optimized scheme are applied compared to the FPA results. Similarly, for the middle user case, both the DL and optimized scheme provide a noticeable improvement in the outage probability, but with less power saving, i.e., 2–3 dBm approximately. Alternatively, the near user with the joint DL channel estimation scenario and FPA scheme show considerable outage improvement compared to the optimized power case. These results also confirm the results obtained for the outage propagability metric, which indicates that FPA coefficients, jointly with high channel gain, are more sufficient for the near user than the power optimization scheme.
In
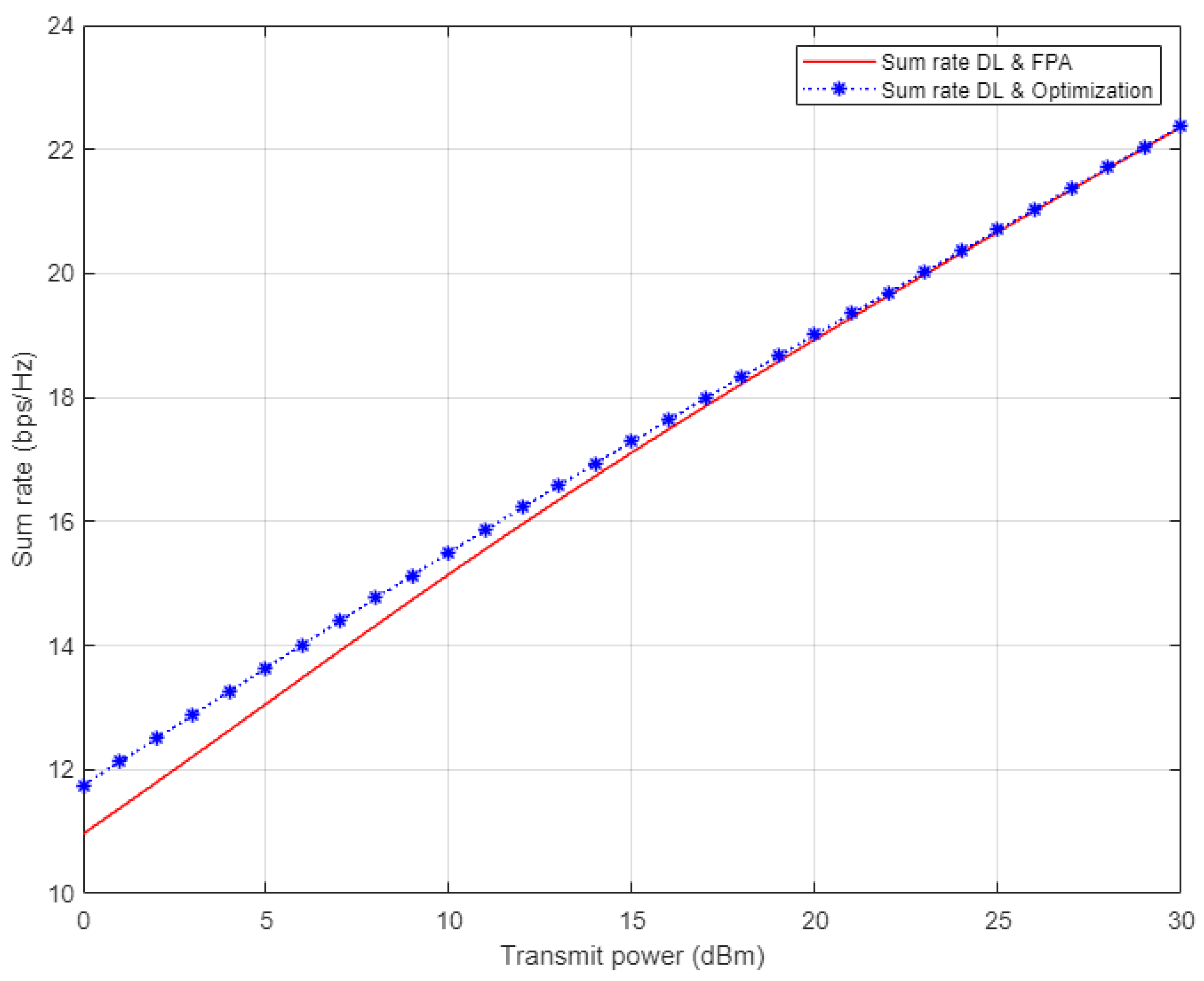
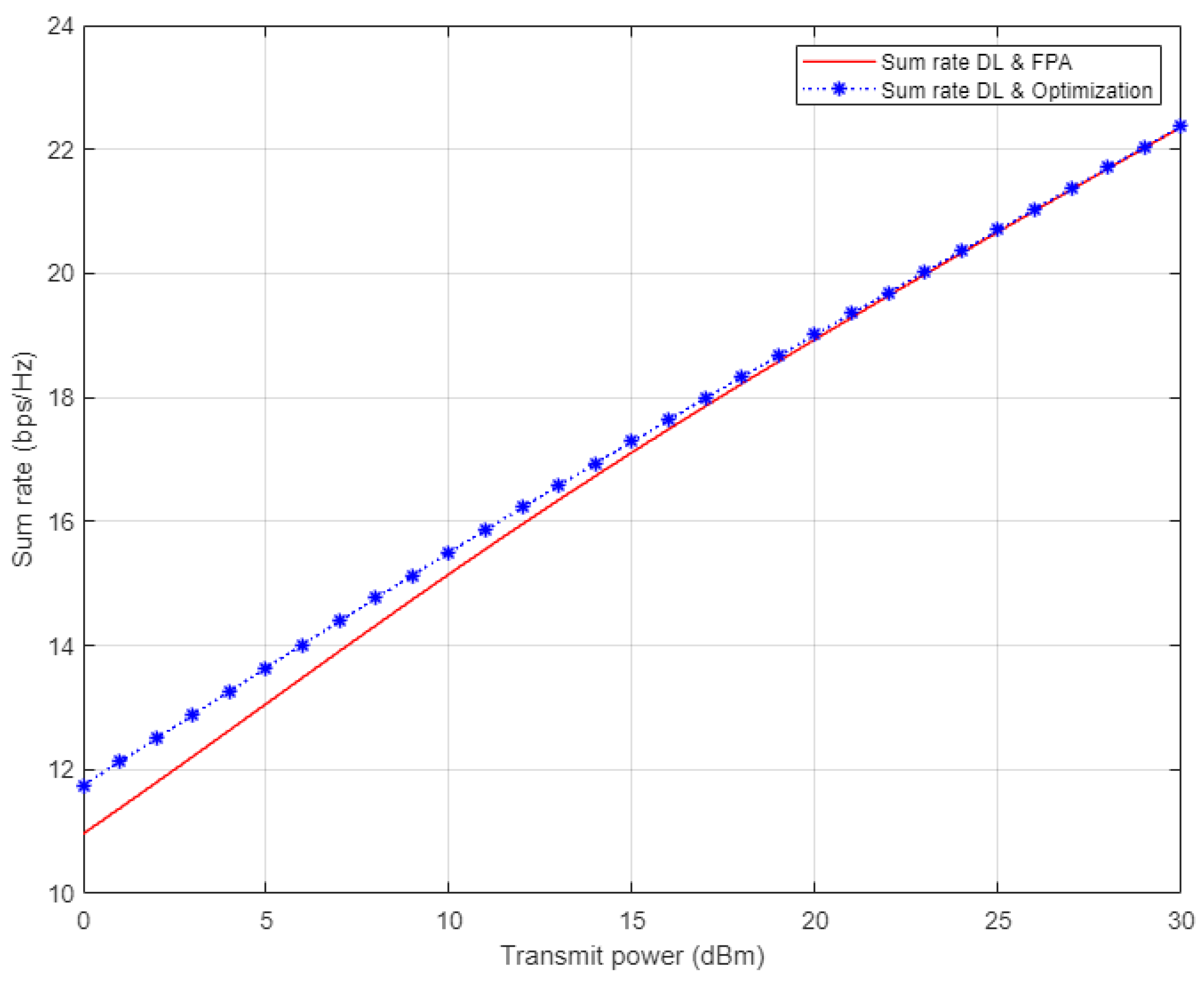
Figure 14, the simulation results for the sum rate for the three examined users in NOMA cell are shown. Each of the optimized power scheme and FPA scheme is incorporated with the proposed DL algorithm utilized for estimating the channel coefficients prior to calculating the rate for each user. On the basis of the simulation outcomes, it can be clearly noticed that the channel estimation based on DL combined with the optimized power scheme show little improvement in the sum rate compared to the FPA scenario when the applied power level is low. Starting from 15 dBm, both the optimized power and FPA schemes provide a comparable sum rate when our proposed DL channel estimation scheme is implemented.
In
Figure 15, the achievable user’s rates are simulated separately against the transmitted power when the optimized power and fixed power schemes are implemented, where the proposed DL is employed for channel parameter prediction for each user in the cell. The simulation outcomes for far and middle users indicate that both the FPA scheme and the optimized power scheme provide comparable rates, even when the DL algorithm is considered. This might be interpreted as that the control of the power is not always adequate to mitigate the effect of the interference, especially for far and middle users that suffer from fluctuating channel conditions. Unsurprisingly, simulation results for the near user demonstrate dominance in the attainable rate compared to middle and far users by more than 6 b/s/Hz. Additionally, near user results related to fixed power factors show a noticeably better rate compared to the optimized power scheme, which validate the results obtained in
Figure 12 and
Figure 13, for BER and outage probability metrics, where the FPA scheme revealed visible improvement compared to the optimized power scheme.
10. Conclusions and Future Work
In this work, the impact of the Deep Neural Network (DNN) in explicitly estimating the channel coefficients for each user in the NOMA cell is investigated, where the LSTM network is developed for complex data processing. In the proposed DL algorithm, the DNN model is trained online based on both the normalized channel statistics and the relationship between successive training sequences. The validity and efficiency of the proposed DL channel estimation scheme is emphasized by inspecting the proposed DNN model using the Rayleigh fading channel and Rician fading channel. Furthermore, we introduce a framework that investigates how the proposed channel estimation based on the DL and the power optimization scheme are jointly utilized for multiuser detection in the PD-NOMA system. To maximize the sum rate of the system users, we optimize the power coefficients allocated for each user on the basis of the overall power transmitted and the QoS constraints. A systematic mathematical analysis for the optimization problem is introduced and the Lagrange function and KKT conditions are employed to deduce the optimal power factors. The simulation results in terms of the BER, outage probability, sum rate, and individual capacity have verified that the proposed DL model-assisted NOMA can realize reliable performance compared to the conventional NOMA scheme, even when cell capacity is increased.
In future work, the performance of the proposed DNN model can be further explored in terms of single input, multi output (SIMO) or multi input, single output (MISO) for different types of fading channels and modulation schemes.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}