4.1. Experimental Setup
In this paper, the experiments were conducted on a high-end server equipped with a single Geforce RTX 2080Ti GPU, 32GB RAM, and an Intel i7-10700K CPU. We used the Tensorflow framework to implement the proposed system.
For the experiment with single-modal images, we randomly selected 2000 images as the training set and another 1000 images as the testing set. Similarly, for the experiments with multi-modal images, 2000 depth and infrared image pairs were used as a training set and another 1000 pairs were used as a testing set. The original images with a resolution of 640 × 480 were resized to 224 × 224 and then used for the training and testing of deep neural networks for classifying sidewalk conditions.
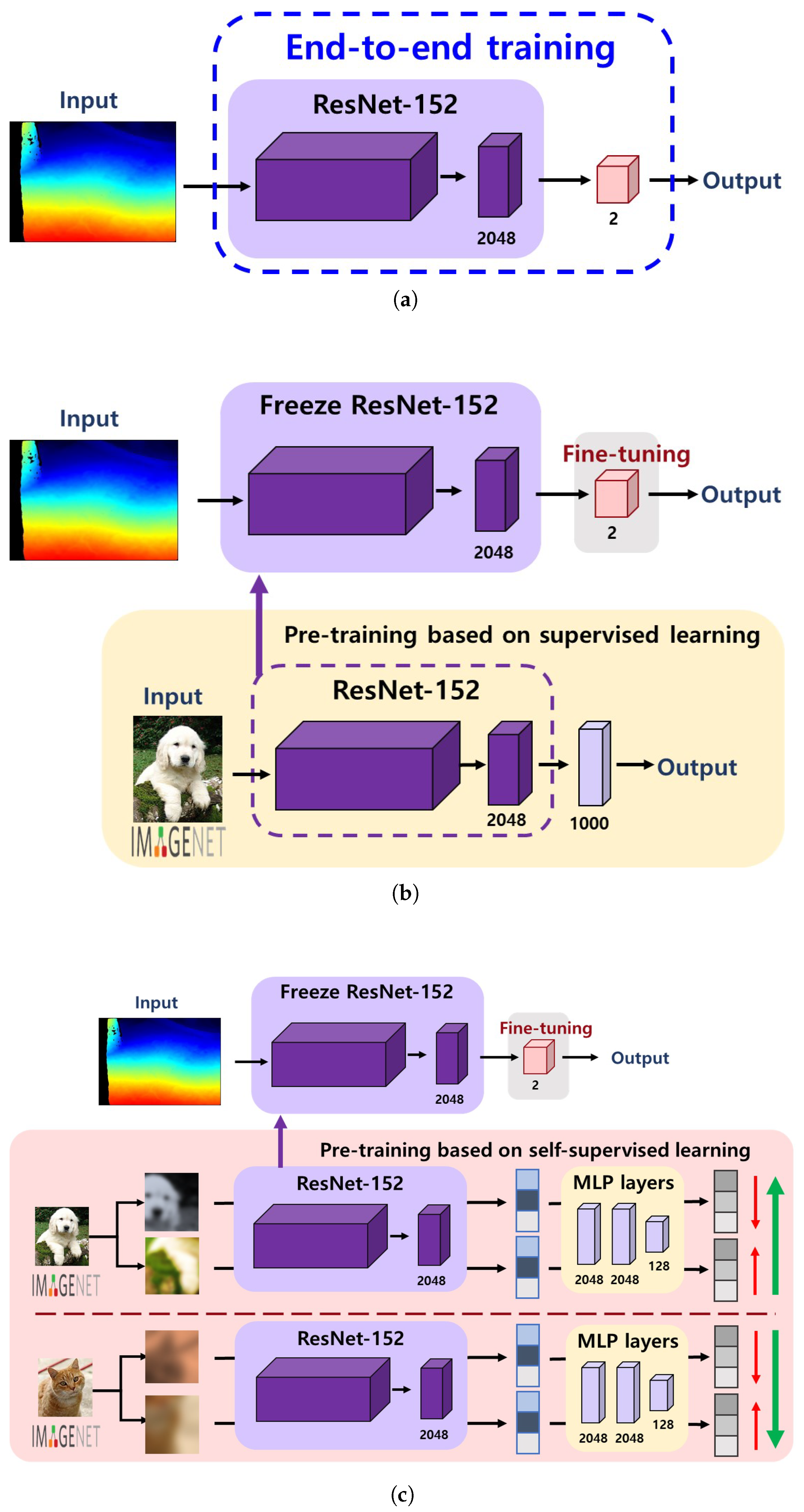
For the supervised learning from scratch (called Supervised hereafter) and transfer learning with supervised pre-trained models (called Transfer
supervised hereafter), the SGD optimizer with a learning rate of 0.0001 was used. With transfer learning with self-supervised pre-trained models (called Transfer
SSL hereafter) using late fusion, the SGD optimizer with a learning rate of 0.0005 was used. In the case of Transfer
SSL with single-modal data and early fusion approaches, the lars optimizer [
37] with a learning rate of 0.0001 was used. All the models were trained for 300 epochs with a batch size of 10, except Supervised with a late fusion approach (5).
4.2. Evaluation
In the experiment, we evaluated the performance of the proposed method trained with different learning strategies. In particular, to validate the robustness and effectiveness of self-supervised learning, we divided our dataset into the full dataset containing 100% of the training samples and a subset containing only 10% of the training samples and compared the performance of each method on both datasets. All reported values were averaged from 10 repetitive experiments.
First, we discuss the classification accuracies of each model on the full dataset.
Table 2 summarizes the validation accuracy of each model trained with 100% of the training data (i.e., 2000 images for single-modal and 2000 image pairs for multi-modal setups). The numbers in the table represent the mean accuracies and standard deviations. From
Table 2, we can observe the following results:
(1) The supervised learning from scratch approach showed the worst performance among the classification models. Specifically, it achieved a validation accuracy of 65.81% for the depth and 57.45% for the infrared modality. The use of multi-modal data was not helpful in increasing the performance of the Supervised approach, yielding 61.71% and 53.56% for the early and late fusion, respectively. It should be noted that this approach failed to achieve a high accuracy although it only utilized a set of images with labels from the target domain (i.e., road surface images). This can be due to the insufficient amount of data available for training a network which has a number of trainable parameters. This is also in line with the common observation that the supervised learning of CNNs from scratch requires a large amount of data from the target domain to have a successful performance [
38].
(2) All the classification models based on transfer learning outperformed the supervised learning from scratch model. Specially, Transfersupervised achieved a performance gain of 2.57%, 14.92%, 4.77%, and 16.32% in the depth-based, infrared-based, early fusion, and late fusion approaches, respectively. Additionally, the TransferSSL approaches showed a higher performance improvement of 4.77%, 14.07%, 6.42%, and 21.3% in the depth-based, infrared-based, early fusion, and late fusion approaches, respectively. These results validate the feasibility of utilizing the transfer learning approach based on the ImageNet database for our domain. It is also worth noting that the weights from the model pre-trained on the image dataset consisting of RGB images of general objects were effective for the depth/infrared images of the surface of sidewalks.
(3) The TransferSSL methods yielded performances comparable to or even better than Transfersupervised, even though they were based on the image representations learned from various pretext tasks without any image/class labels. Specifically, the depth-modality and early fusion approaches produced 1.65–2.2% better accuracies than Transfersupervised. Furthermore, the multi-modal approach with late fusion achieved the highest accuracy of 74.86%, outperforming all the other approaches. This implies that transfer learning using image representations/features learned from self-supervision tasks on a dataset containing objects and modalities that are significantly different from our target domain also works and can produce promising results. Since collecting training data for self-supervision tasks that do not require labels is relatively easy, we can also expect further performance improvement from enhanced image representations at a low cost.
(4) We found that a multi-modal fusion approach does not always work. The early fusion approach was not helpful in improving the performance of the training methods used in this study. No performance improvement was observed from the Supervised and Transfer
supervised approaches even though the late fusion was applied. Specifically, there was an average performance degradation of 4.0% for Supervised, 2.2% for Transfer
supervised, and 2.9% for Transfer
SSL with early fusion. Only Transfer
SSL when adopting a late fusion approach achieved a higher performance over single-modal approaches. It was also found that transfer learning-based approaches, which exploit the weights of the models pre-trained for learning image representations, resulted in a better performance with a late fusion approach (i.e., feature-level fusion) than with the early fusion approach. In sum, with 100% of the training data, we could observe the best classification accuracy using Transfer
SSL based on multi-modal data with a late fusion approach. Finally, the confusion matrices of all the networks trained with 100% of the training data can be found in
Figure A1,
Appendix A.
Second, to validate the effectiveness of image representations learned from self-supervised learning, we also conducted a performance evaluation using only 10% of the training data (i.e., 200 images for single-modal images and 200 image pairs for multi-modal images).
Table 3 summarizes the validation accuracy of each model trained with 10% of the training data. As expected, we could see that the performance of all the models drastically decreased as the amount of training data reduced. In particular, the Supervised approach reached an almost chance level. Transfer
supervised achieved an accuracy of 58–62%, which is approximately 8% less than the model trained with 100% data on average. The performance of the single-modal-based Transfer
SSL approach also decreased to 63.32% with a 7.73% drop on average, while they were still better than the Supervised (52.85% on average) and Transfer
supervised (61.37% on average) approaches. Most notably, Transfer
SSL with early fusion did not significantly suffer from a reduced amount of training data, yielding the highest accuracy of 64.45%. In contrast, we could observe a large performance drop of Transfer
SSL with the late fusion approach, from 74.86% (with 100% data) to 62.55% (with 10% data), which is, however, still better than the other approaches. For more details, the confusion matrices of all the networks trained with 10% of the training data are presented in
Figure A2,
Appendix A.
Table 4 summarizes the performance differences according to the amount of training data. Generally, transfer learning-based approaches showed less performance drops compared with Supervised approaches. It seems that Supervised with an infrared modality and a late fusion approach was less affected by the reduced training data; however, its performance was close to the chance level accuracy for both 100% and 10% data, which is not meaningful. In contrast, the Transfer
SSL approaches tended to show competitive accuracy with less performance drops, resulting in a more robust performance. However, as noted above, the late fusion approach of Transfer
SSL failed to preserve a high classification accuracy when the amount of training data was limited. This result is also related to the number of trainable parameters for each method, as summarized in
Table 5. The Supervised approach attempts to learn the features from scratch with a large number of trainable parameters (58 M); therefore, a large amount of training samples are essential for a successful training. As a result, the Supervised methods presented a large performance drop as well as the lowest accuracy (chance level) in our experiment. Transfer
SSL with a late fusion approach requires more trainable parameters as well as a more complicated architecture than other approaches, resulting in difficulties in training a model with a limited amount of data. Finally,
Figure 8a,b show the validation accuracy and loss of each model per epoch for both 100% and 10% training data setups. As shown in the figures, the Supervised approaches failed to produce a stable performance while transfer learning-based approaches worked better for both cases.
Finally,
Table 6 summarizes the inference time required for each method. It was shown that the most complex architectures (i.e., networks trained with multi-modal late fusion) consumed more time to make prediction results. Based on the result, we believe that our frameworks are efficient enough to be used in real-time scenarios (i.e., with at least 25–34 FPS) and can be more optimized by further enhancement.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}